使用cutlass实现多种精度的GEMM,支持cuda core与tensor core_cutlass gemm int8-程序员宅基地
技术标签: CUDA cuda tensor core cutlass nvidia
欢迎关注微信公众号InfiniReach,这里有更多AI大模型的前沿算法与工程优化方法分享
 下面实现了两份支持tensorcore 与cudacore 的代码,具体cutlass的安装,api的解读,gemm的原理部分,可以看https://mp.weixin.qq.com/s/FXuFljYMc-8Zb8pHf–GPA
下面实现了两份支持tensorcore 与cudacore 的代码,具体cutlass的安装,api的解读,gemm的原理部分,可以看https://mp.weixin.qq.com/s/FXuFljYMc-8Zb8pHf–GPA
cutlass gemm + cuda core
使用cutlass实现一个ampere架构下的GEMM,通过模版支持多种精度,多种layout等配置,支持cuda core
/**
* @file m2.cu
* @author your name ([email protected])
* @brief
* @version 0.1
* @date 2024-03-27
*
* @copyright Copyright (c) 2024
* 多精度GEMM
*/
#include <cstdio>
#include <omp.h>
#include <Eigen/Core>
#include <cuda_runtime_api.h>
#include "cutlass/cutlass.h"
#include "cutlass/gemm/device/gemm.h"
/// Define a CUTLASS GEMM template and launch a GEMM kernel.
template<
typename ElementInputA=float,
typename ElementInputB=float,
typename ElementOutput=float,
typename ElementAccumulator=float,
typename Major=cutlass::layout::ColumnMajor,
typename OperatorClass=cutlass::arch::OpClassSimt,
typename ArchTag=cutlass::arch::Sm80>
cudaError_t CutlassGemmCUDA(
int M,
int N,
int K,
float alpha,
ElementInputA const *A,
int lda,
ElementInputB const *B,
int ldb,
float beta,
ElementOutput *C,
int ldc) {
using CutlassGemm = cutlass::gemm::device::Gemm<ElementInputA, Major,
ElementInputB, Major,
ElementOutput, Major,
ElementAccumulator,
OperatorClass,
ArchTag>;
CutlassGemm gemm_operator;
typename CutlassGemm::Arguments args({
M, N, K}, // Gemm Problem dimensions
{
A, lda}, // Tensor-ref for source matrix A
{
B, ldb}, // Tensor-ref for source matrix B
{
C, ldc}, // Tensor-ref for source matrix C
{
C, ldc}, // Tensor-ref for destination matrix D (may be different memory than source C matrix)
{
alpha, beta}); // Scalars used in the Epilogue
//
// Launch the CUTLASS GEMM kernel.
//
cutlass::Status status = gemm_operator(args);
if (status != cutlass::Status::kSuccess) {
return cudaErrorUnknown;
}
return cudaSuccess;
}
template<typename T1=float, typename T2=float>
void AllocateDevMatrix(T1 **matrix, const int rows, const int columns, const T2 *host_ptr=nullptr) {
cudaError_t result;
size_t sizeof_matrix = sizeof(T1) * rows * columns;
// Allocate device memory.
result = cudaMalloc(reinterpret_cast<void **>(matrix), sizeof_matrix);
if (result != cudaSuccess) {
std::cerr << "Failed to allocate matrix: "
<< cudaGetErrorString(result) << std::endl;
}
cudaMemset(*matrix, 0, sizeof_matrix);
if(host_ptr != nullptr)
cudaMemcpy(*matrix, host_ptr, sizeof_matrix, cudaMemcpyHostToDevice);
}
template<typename T=float, int Major=Eigen::RowMajor, bool init = true>
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major>
InitData(const int rows, const int columns){
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major> x;
x.resize(rows, columns);
if constexpr (init) {
x.setRandom();
}
return x;
}
template<typename T>
struct wrapper_{
using type = T;};
template<>
struct wrapper_<float>{
using type = float;};
template<>
struct wrapper_<double>{
using type = double;};
template<>
struct wrapper_<cutlass::bfloat16_t>{
using type = Eigen::bfloat16;};
template<>
struct wrapper_<cutlass::half_t>{
using type = Eigen::half;};
template<typename T>
using wrapper = typename wrapper_<T>::type;
int main(int argc, char *argv[]) {
const int M = 128;
const int K = 512;
const int N = 1024;
omp_set_num_threads(omp_get_num_procs());
using OperatorClass = cutlass::arch::OpClassSimt;
using ArchTag = cutlass::arch::Sm80;
using ElementInputA = float;
using ElementInputB = float;
using ElementOutput = float;
using ElementAccumulator = float;
using Major = cutlass::layout::RowMajor;
ElementInputA *DevPtrA;
ElementInputB *DevPtrB;
ElementOutput *DevPtrC;
auto HostA = InitData<wrapper<ElementInputA>, Eigen::RowMajor, true>(M, K);
auto HostB = InitData<wrapper<ElementInputB>, Eigen::RowMajor, true>(K, N);
auto HostC = InitData<wrapper<ElementOutput>, Eigen::RowMajor, true>(M, N);
auto HostD = InitData<wrapper<ElementOutput>, Eigen::RowMajor, false>(M, N);
auto HostCutlassD = InitData<wrapper<ElementOutput>, Eigen::RowMajor, false>(M, N);
HostD = HostA * HostB + HostC;
AllocateDevMatrix<ElementInputA, wrapper<ElementInputA>>(&DevPtrA, M, K, HostA.data());
AllocateDevMatrix<ElementInputB, wrapper<ElementInputB>>(&DevPtrB, K, N, HostB.data());
AllocateDevMatrix<ElementOutput, wrapper<ElementOutput>>(&DevPtrC, M, N, HostC.data());
CutlassGemmCUDA<ElementInputA,
ElementInputB,
ElementOutput,
ElementAccumulator,
Major,
OperatorClass,
ArchTag>
(M, N, K,
1.,
DevPtrA, K,
DevPtrB, N,
1.,
DevPtrC, N
);
cudaDeviceSynchronize();
cudaMemcpy(HostCutlassD.data(), DevPtrC, HostCutlassD.size() * sizeof(ElementOutput),
cudaMemcpyDeviceToHost);
printf("Max error: %f\n", (float)((HostCutlassD - HostD).cwiseAbs().maxCoeff()));
cudaFree(DevPtrA);
cudaFree(DevPtrB);
cudaFree(DevPtrC);
return 0;
}
cmakelists.txt如下:
cmake_minimum_required(VERSION 3.22)
project(cutlassStudy CXX CUDA)
set(CMAKE_CUDA_STANDARD 17)
find_package(CUDA)
include(FindCUDA/select_compute_arch)
CUDA_DETECT_INSTALLED_GPUS(INSTALLED_GPU_CCS_1)
string(STRIP "${INSTALLED_GPU_CCS_1}" INSTALLED_GPU_CCS_2)
string(REPLACE " " ";" INSTALLED_GPU_CCS_3 "${INSTALLED_GPU_CCS_2}")
string(REPLACE "." "" CUDA_ARCH_LIST "${INSTALLED_GPU_CCS_3}")
message("-- nvcc generates code for arch ${CUDA_ARCH_LIST}")
SET(CMAKE_CUDA_ARCHITECTURES ${CUDA_ARCH_LIST})
find_package(Eigen3 REQUIRED)
find_package(OpenMP REQUIRED)
add_compile_options(-lineinfo)
add_executable(test test.cu)
target_link_libraries(test OpenMP::OpenMP_CXX)
cutlass gemm + tensor core
使用cutlass实现一个ampere架构下的GEMM,通过模版支持多种精度,多种layout等配置,支持tensor core
/**
* @file test.cu
* @author InfiniReach
* @brief
* @version 0.1
* @date 2024-03-27
*
* @copyright Copyright (c) 2024
*/
#include <cstdio>
#include <omp.h>
#include <Eigen/Core>
#include <cuda_runtime_api.h>
#include "cutlass/cutlass.h"
#include "cutlass/gemm/device/gemm.h"
#include "cutlass/util/command_line.h"
#include "cutlass/util/host_tensor.h"
#include "cutlass/util/reference/device/gemm.h"
#include "cutlass/util/reference/host/tensor_compare.h"
#include "cutlass/util/reference/host/tensor_copy.h"
#include "cutlass/util/reference/host/tensor_fill.h"
#include "cutlass/util/tensor_view_io.h"
#include "helper.h"
/// Define a CUTLASS GEMM template and launch a GEMM kernel.
template<
typename ElementInputA=float,
typename ElementInputB=float,
typename ElementOutput=float,
typename ElementAccumulator=float,
typename MajorA=cutlass::layout::RowMajor,
typename MajorB=cutlass::layout::ColumnMajor,
typename MajorC=cutlass::layout::RowMajor,
typename OperatorClass=cutlass::arch::OpClassSimt,
typename ArchTag=cutlass::arch::Sm80,
typename ShapeMMAThreadBlock=cutlass::gemm::GemmShape<128, 128, 16>,
typename ShapeMMAWarp=cutlass::gemm::GemmShape<64, 64, 16>,
typename ShapeMMAOp=cutlass::gemm::GemmShape<16, 8, 8>,
int NumStages=2>
cudaError_t CutlassGemmTensorOp(
int M,
int N,
int K,
float alpha,
ElementInputA const *A,
int lda,
ElementInputB const *B,
int ldb,
float beta,
ElementOutput *C,
int ldc) {
using ElementComputeEpilogue = ElementAccumulator;
// This code section describes how threadblocks are scheduled on GPU
using SwizzleThreadBlock = cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle<>; // <- ??
// This code section describes the epilogue part of the kernel
using EpilogueOp = cutlass::epilogue::thread::LinearCombination<
ElementOutput, // <- data type of output matrix
128 / cutlass::sizeof_bits<ElementOutput>::value, // <- the number of elements per vectorized
// memory access. For a byte, it's 16
// elements. This becomes the vector width of
// math instructions in the epilogue too
ElementAccumulator, // <- data type of accumulator
ElementComputeEpilogue>; // <- data type for alpha/beta in linear combination function
using Gemm = cutlass::gemm::device::Gemm<ElementInputA, MajorA,
ElementInputB, MajorB,
ElementOutput, MajorC,
ElementAccumulator,
OperatorClass,
ArchTag,
ShapeMMAThreadBlock,
ShapeMMAWarp,
ShapeMMAOp,
EpilogueOp,
SwizzleThreadBlock,
NumStages>;
cutlass::gemm::GemmCoord problem_size{
M, N, K};
// Split K dimension into 1 partitions
int split_k_slices = 1;
// Create a tuple of gemm kernel arguments. This is later passed as arguments to launch
// instantiated CUTLASS kernel
typename Gemm::Arguments arguments{
problem_size, // <- problem size of matrix multiplication
cutlass::TensorRef<ElementInputA const, MajorA>(A, lda), // <- reference to matrix A on device
cutlass::TensorRef<ElementInputB const, MajorB>(B, ldb), // <- reference to matrix B on device
cutlass::TensorRef<ElementOutput const, MajorC>(C, ldc), // <- reference to matrix C on device
cutlass::TensorRef<ElementOutput, MajorC>(C, ldc), // <- reference to matrix D on device
{
alpha, beta}, // <- tuple of alpha and beta
split_k_slices}; // <- k-dimension split factor
// Using the arguments, query for extra workspace required for matrix multiplication computation
size_t workspace_size = Gemm::get_workspace_size(arguments);
// Allocate workspace memory
cutlass::device_memory::allocation<uint8_t> workspace(workspace_size);
// Instantiate CUTLASS kernel depending on templates
Gemm gemm_op;
// Check the problem size is supported or not
cutlass::Status status = gemm_op.can_implement(arguments);
CUTLASS_CHECK(status);
// Initialize CUTLASS kernel with arguments and workspace pointer
status = gemm_op.initialize(arguments, workspace.get());
CUTLASS_CHECK(status);
status = gemm_op();
CUTLASS_CHECK(status);
}
template<typename T1=float, typename T2=float>
void AllocateDevMatrix(T1 **matrix, const int rows, const int columns, const T2 *host_ptr=nullptr) {
cudaError_t result;
size_t sizeof_matrix = sizeof(T1) * rows * columns;
// Allocate device memory.
result = cudaMalloc(reinterpret_cast<void **>(matrix), sizeof_matrix);
if (result != cudaSuccess) {
std::cerr << "Failed to allocate matrix: "
<< cudaGetErrorString(result) << std::endl;
}
cudaMemset(*matrix, 0, sizeof_matrix);
if(host_ptr != nullptr)
cudaMemcpy(*matrix, host_ptr, sizeof_matrix, cudaMemcpyHostToDevice);
}
template<typename T=float, int Major=Eigen::RowMajor, bool init = true>
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major>
InitData(const int rows, const int columns){
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major> x;
x.resize(rows, columns);
if constexpr (init) {
x.setRandom();
}
return x;
}
template<typename T>
struct wrapper_{
using type = T;};
template<>
struct wrapper_<float>{
using type = float;};
template<>
struct wrapper_<double>{
using type = double;};
template<>
struct wrapper_<cutlass::bfloat16_t>{
using type = Eigen::bfloat16;};
template<>
struct wrapper_<cutlass::half_t>{
using type = Eigen::half;};
template<typename T>
using wrapper = typename wrapper_<T>::type;
template<typename T>
struct major_{
static constexpr int type = -1;};
template<>
struct major_<cutlass::layout::RowMajor>{
static constexpr int type = static_cast<int>(Eigen::RowMajor);};
template<>
struct major_<cutlass::layout::ColumnMajor>{
static constexpr int type = static_cast<int>(Eigen::ColMajor);};
template<typename T>
static constexpr int major = major_<T>::type;
int main(int argc, char *argv[]) {
const int M = 128;
const int K = 512;
const int N = 1024;
omp_set_num_threads(omp_get_num_procs());
using OperatorClass = cutlass::arch::OpClassTensorOp;
using ArchTag = cutlass::arch::Sm80;
using ElementInputA = float;
using ElementInputB = float;
using ElementOutput = float;
using ElementAccumulator = float;
using MajorA = cutlass::layout::ColumnMajor;
using MajorB = cutlass::layout::RowMajor;
using MajorC = cutlass::layout::ColumnMajor;
using ShapeMMAThreadBlock=cutlass::gemm::GemmShape<128, 128, 16>;
using ShapeMMAWarp=cutlass::gemm::GemmShape<64, 64, 16>;
using ShapeMMAOp=cutlass::gemm::GemmShape<16, 8, 8>;
constexpr int NumStages=4;
auto HostA = InitData<wrapper<ElementInputA>, major<MajorA>, true>(M, K);
auto HostB = InitData<wrapper<ElementInputB>, major<MajorB>, true>(K, N);
auto HostC = InitData<wrapper<ElementOutput>, major<MajorC>, true>(M, N);
auto HostD = InitData<wrapper<ElementOutput>, major<MajorC>, false>(M, N);
auto HostCutlassD = InitData<wrapper<ElementOutput>, major<MajorC>, false>(M, N);
HostD = HostA * HostB + HostC;
ElementInputA *DevPtrA;
ElementInputB *DevPtrB;
ElementOutput *DevPtrC;
int lda = HostA.outerStride();
int ldb = HostB.outerStride();
int ldc = HostC.outerStride();
AllocateDevMatrix<ElementInputA, wrapper<ElementInputA>>(&DevPtrA, M, K, HostA.data());
AllocateDevMatrix<ElementInputB, wrapper<ElementInputB>>(&DevPtrB, K, N, HostB.data());
AllocateDevMatrix<ElementOutput, wrapper<ElementOutput>>(&DevPtrC, M, N, HostC.data());
CutlassGemmTensorOp<ElementInputA,
ElementInputB,
ElementOutput,
ElementAccumulator,
MajorA,
MajorB,
MajorC,
OperatorClass,
ArchTag,
ShapeMMAThreadBlock,
ShapeMMAWarp,
ShapeMMAOp,
NumStages>
(M, N, K,
1.,
DevPtrA, lda,
DevPtrB, ldb,
1.,
DevPtrC, ldc
);
cudaDeviceSynchronize();
cudaMemcpy(HostCutlassD.data(), DevPtrC, HostCutlassD.size() * sizeof(ElementOutput),
cudaMemcpyDeviceToHost);
printf("Max error: %f\n", (float)((HostCutlassD - HostD).cwiseAbs().maxCoeff()));
cudaFree(DevPtrA);
cudaFree(DevPtrB);
cudaFree(DevPtrC);
return 0;
}
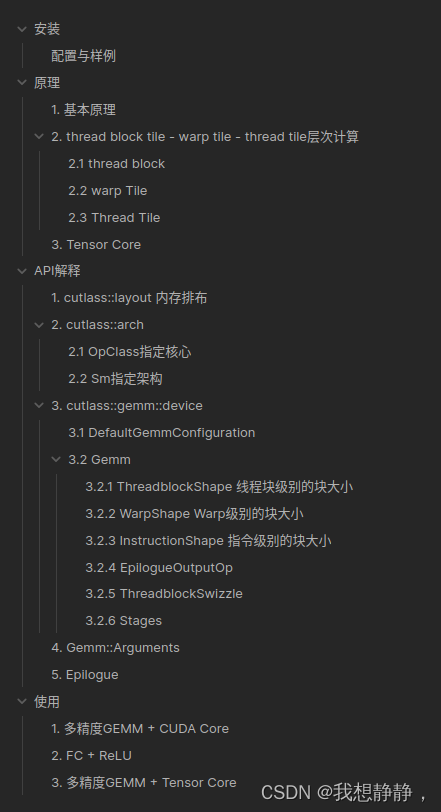
cutlass 安装,以及详细原理
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf