48个代码大模型汇总,涵盖原始、改进、专用、微调4大类_pangu-coder2-程序员宅基地
技术标签: 人工智能干货 代码生成大模型 深度学习 transformer 深度学习干货
代码大模型具有强大的表达能力和复杂性,可以处理各种自然语言任务,包括文本分类、问答、对话等。这些模型通常基于深度学习架构,如Transformer,并使用预训练目标(如语言建模)进行训练。
在对大量代码数据的学习和训练过程中,代码大模型能够提升代码编写的效率和质量,辅助代码理解和决策,在代码生成、代码补全、代码解释、代码纠错以及单元测试等任务中都表现出十分出色的能力。
为了帮大家深入掌握代码大模型的发展历程和挑战,我这次整理了相关的48个模型以供同学们学习,分为了4大类,包括原始LM、LM改进、专用LM,以及微调模型。
模型原文及代码需要的同学看文末
原始LM
1.Lamda: Language models for dialog applications
用于对话应用程序的语言模型
模型简介:LaMDA是一种专门用于对话的神经网络语言模型,通过预训练和微调,可以显著提高其安全性和事实依据。在安全性方面,使用少量众包工人注释的数据进行微调的分类器过滤候选响应可以提高模型的安全性。在事实依据方面,允许模型咨询外部知识源可以使生成的响应基于已知来源。

2.Palm: Scaling language modeling with pathways
使用路径缩放语言模型
模型简介:本文介绍了一种名为PaLM的540亿参数密集激活Transformer语言模型,使用Pathways新机器学习系统在多个TPU Pod上进行高效训练。作者通过数百个语言理解和生成基准测试展示了规模缩放的持续优势,PaLM在一些多步推理任务上实现了突破性的性能,超过了最新的细调最先进技术和人类平均水平。此外,PaLM在多语言任务和源代码生成方面也表现出强大的能力。

3.Gpt-neox-20b: An open-source autoregressive language model
一个开源的自回归语言模型
模型简介:论文介绍了一种200亿参数的自回归语言模型GPT-NeoX-20B,该模型在Pile上进行训练,并通过允许性许可证向公众免费提供其权重。GPT-NeoX-20B是目前提交时公开可用权重最大的密集自回归模型。在这项工作中,作者描述了该模型的架构和训练,并在一系列语言理解、数学和基于知识的任务上评估了其性能。作者发现GPT-NeoX-20B是一个非常强大的少样本推理器,当评估5个示例时,其性能比类似的GPT-3和FairSeq模型获得更多收益。

-
4.BLOOM: A 176b-parameter open-access multilingual language model
-
5.lama: Open and efficient foundation language models
-
6.GPT-4 technical report
-
7.lama 2: Open foundation and finetuned chat models
-
8.Textbooks are all you need II: phi-1.5 technical report
LM改进
1.Evaluating large language models trained on code
评估基于代码训练的大型语言模型
模型简介:Codex是一个用GPT模型微调的代码生成器,它在GitHub Copilot中有应用。在HumanEval评估集中,Codex的表现优于GPT-3和GPT-J。此外,通过从模型中重复采样,可以生成对困难提示的有效解决方案。然而,Codex存在局限性,例如难以处理描述长操作链的文档字符串以及将操作绑定到变量的能力。最后,作者讨论了部署强大的代码生成技术可能带来的更广泛的影响,包括安全、隐私和伦理问题。

2.Solving quantitative reasoning problems with language models
使用语言模型解决定量推理问题
模型简介:本文介绍了一种名为Minerva的大型语言模型,该模型在一般自然语言数据上进行预训练,并在技术内容上进行了进一步的训练。该模型在技术基准测试中实现了最先进的性能,而无需使用外部工具。作者还对物理学、生物学、化学、经济学和其他需要定量推理的科学领域的200多个本科水平的问题进行了评估,发现该模型可以正确回答近三分之一的问题。

3.Palm 2 technical report
Palm 2技术报告
模型简介:本文介绍了一种新型最先进的语言模型,该模型具有更好的多语言和推理能力,并且比其前身PaLM更计算高效。PaLM 2是一种基于Transformer的模型,使用多种目标进行训练。通过在英语和多语言语言以及推理任务上的广泛评估,作者证明PaLM 2在不同模型大小下对下游任务的质量有显著提高,同时表现出比PaLM更快和更高效的推理。

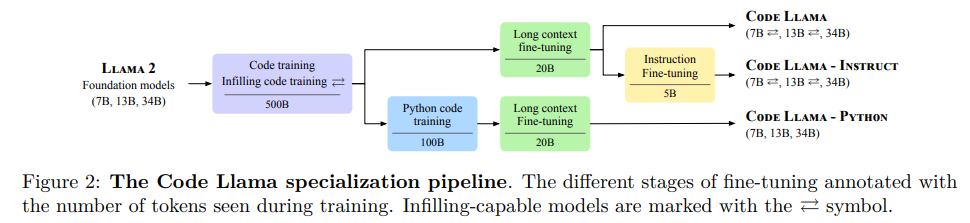
4.Code llama: Open foundation models for code
开放源代码模型
模型简介:论文提出了一个大型语言模型家族CodeLlama,可以生成代码,具有先进性能、开箱即用的填充能力以及对编程任务的指令跟随能力。作者提供了多种版本,覆盖各种应用,所有模型都在16k个令牌的序列上进行训练,并在最多100k个令牌的输入上有所改进。该模型在几个基准测试中表现出色,作者也发布了CodeLlama的Python版本。
专用LM
1. Learning and evaluating contextual embedding of source code
学习与评估源代码的上下文嵌入
模型简介:本文介绍了一种名为CuBERT的开源代码理解BERT模型,该模型使用GitHub上740万个Python文件的去重语料库进行预训练。作者还创建了一个包含五个分类任务和一个程序修复任务的开源基准测试集,类似于文献中提出的代码理解任务。作者将CuBERT与不同的Word2Vec标记嵌入、BiLSTM和Transformer模型以及已发布的最先进模型进行了比较,结果表明,即使使用较短的训练时间和较少的标记示例,CuBERT也能超越所有其他模型。

2.Codebert: A pre-trained model for programming and natural languages
一种用于编程和自然语言的预训练模型
模型简介:论文介绍了一种新的预训练模型CodeBERT,用于编程语言和自然语言。该模型使用基于Transformer的神经网络架构进行开发,并使用混合目标函数进行训练,以支持下游的自然语言代码搜索、代码文档生成等应用。作者通过微调模型参数在两个NL-PL应用上评估了CodeBERT的性能,结果表明,CodeBERT在这些任务上表现出色。

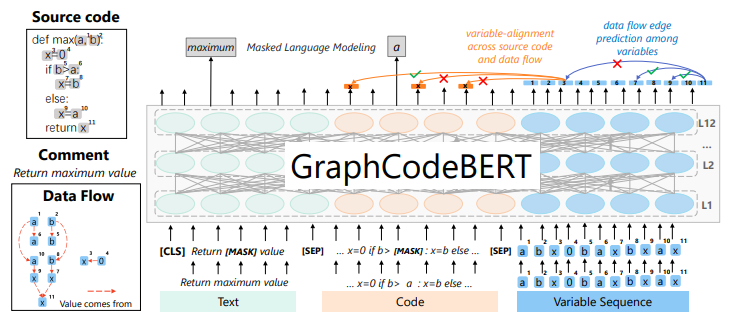
3.Graphcodebert: Pre-training code representations with data flow
基于数据流的代码表征预训练模型
模型简介:论文介绍了一种基于数据流的代码表征预训练模型Graphcodebert,该模型考虑了代码的内在结构。作者使用数据流作为语义级别的代码结构,而不是采用抽象语法树(AST)这样的语法级别的代码结构。作者还引入了两个结构感知的预训练任务,并在四个任务上评估了该模型,结果表明该模型在代码搜索、克隆检测、代码翻译和代码优化等任务上表现出色。
-
4.Syncobert: Syntax-guided multi-modal contrastive pre-training for code representation
-
5.CODE-MVP: learning to represent source code from multiple views with contrastive pre-training
-
6.Intellicode compose: code generation using transformer
-
7.Codexglue: A machine learning benchmark dataset for code understanding and generation
-
8.A systematic evaluation of large language models of code
-
9.Codegen: An open large language model for code with multi-turn program synthesis
-
10.CERT: continual pretraining on sketches for library-oriented code generation
-
11.Pangu-coder: Program synthesis with function-level language modeling
-
12.Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x
-
13.Textbooks are all you need
-
14.Codefuse-13b: A pretrained multi-lingual code large language model
-
15.Incoder: A generative model for code infilling and synthesis
-
16.Santacoder: don’t reach for the stars!
-
17.Starcoder: may the source be with you!
-
18.Multi-task learning based pre-trained language model for code completion
-
19.Unixcoder: Unified cross-modal pre-training for code representation
-
20.Pymt5: multi-mode translation of natural language and python code with transformers
-
21.Studying the usage of text-to-text transfer transformer to support code-related tasks
-
22.DOBF: A deobfuscation pre-training objective for programming languages
-
23.Unified pre-training for program understanding and generation
-
24.Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation
-
25.Sptcode: Sequence-to-sequence pre-training for learning source code representations
-
26.Competition-level code generation with alphacode
-
27.Natgen: generative pre-training by "naturalizing" source code
-
28.Codet5+: Open code large language models for code understanding and generation
代码微调
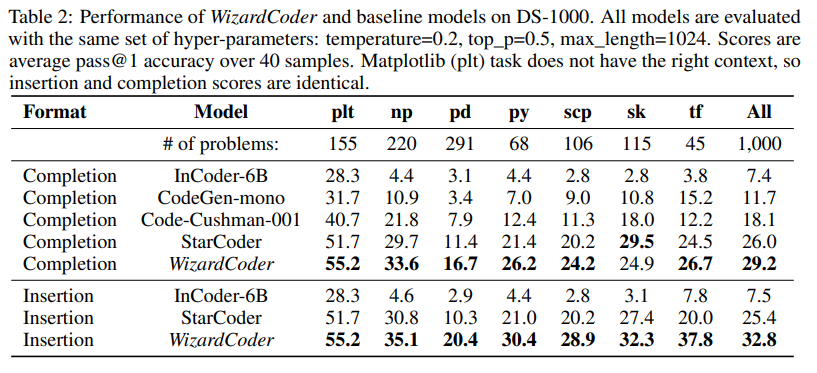
1.Wizardcoder: Empowering code large language models with evolinstruct
使用evolinstruct为大型语言模型提供动力
模型简介:本文介绍了WizardCoder模型,它通过将Evol-Instruct方法应用于代码领域,为大型语言模型提供了更强的能力。作者在四个著名的代码生成基准测试上进行了实验,结果表明该模型比其他开源的大型语言模型表现更好,甚至超过了一些封闭的语言模型。
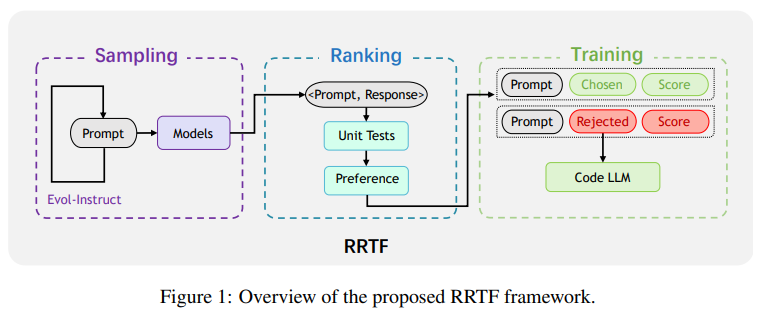
2.Pangu-coder2: Boosting large language models for code with ranking feedback
使用排名反馈提高大型语言模型的代码能力
模型简介:论文提出了一种新的RRTF(Rank Responses to align Test&Teacher Feedback)框架,可以有效且高效地提高预训练的大型语言模型的代码生成能力。在该框架下,作者提出了PanGu-Coder2,它在OpenAI HumanEval基准测试上达到了62.20%的pass@1。此外,通过对CoderEval和LeetCode基准测试进行广泛评估,作者表明PanGu-Coder2始终优于之前的所有Code LLM。
3.Octopack: Instruction tuning code large language models
指令调优代码大型语言模型
模型简介:该论文介绍了通过使用Git提交中的代码更改和人类指令,对大型语言模型进行指令调优的方法。这种方法利用了自然结构的Git提交,将代码更改与人类指令配对起来。他们编译了一个包含4TB数据的数据库CommitPack,涵盖了350种编程语言的Git提交。在16B参数的StarCoder模型上,与其他指令调优模型进行基准测试,该方法在HumanEval Python基准上取得了最佳性能(46.2% pass@1)。
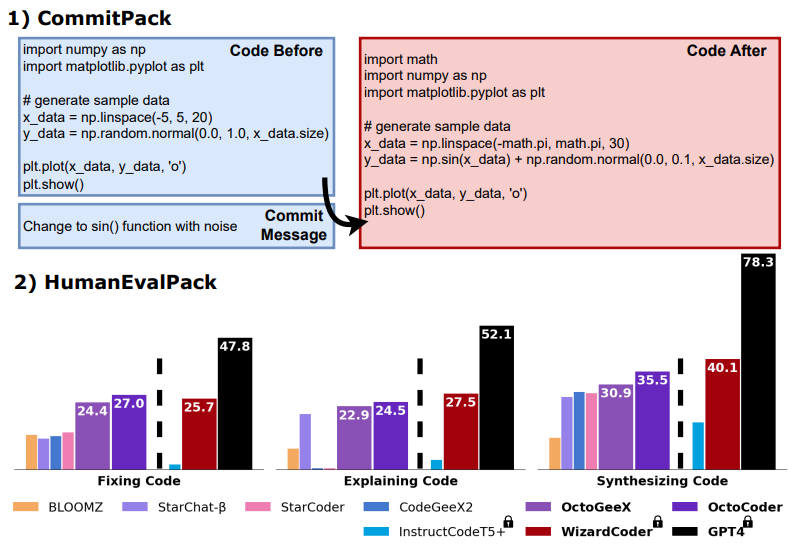
-
4.Mftcoder: Boosting code llms with multitask fine-tuning
-
5.Compilable neural code generation with compiler feedback
-
6.Coderl: Mastering code generation through pretrained models and deep reinforcement learning
-
7.Execution-based code generation using deep reinforcement learning
-
8.RLTF: reinforcement learning from unit test feedback
关注下方《学姐带你玩AI》
回复“代码大模型”领取模型原文及源码
码字不易,欢迎大家点赞评论收藏!
智能推荐
QT设置QLabel中字体的颜色_qolable 字体颜色-程序员宅基地
文章浏览阅读8k次,点赞2次,收藏6次。QT设置QLabel中字体的颜色其实,这是一个比较常见的问题。大致有几种做法:一是使用setPalette()方法;二是使用样式表;三是可以使用QStyle;四是可以在其中使用一些简单的HTML样式。下面就具体说一下,也算是个总结吧。第一种,使用setPalette()方法如下:QLabel *label = new QLabel(tr("Hello Qt!"));QP_qolable 字体颜色
【C#】: Import “google/protobuf/timestamp.proto“ was not found or had errors.问题彻底被解决!_import "google/protobuf/timestamp.proto" was not f-程序员宅基地
文章浏览阅读3.7k次。使用C# 作为开发语言,将pb文件转换为cs文件的时候相信很多人都会遇到一个很棘手的问题,那就是protoc3环境下,import Timestamp的问题,在头部 import “google/protobuf/timestamp.proto”;的时候会抛异常:google/protobuf/timestamp.proto" was not found or had errors;解决办法【博主「pamxy」的原创文章的分享】:(注:之后才发现,不需要添加这个目录也可以,因为timestamp.p_import "google/protobuf/timestamp.proto" was not found or had errors.
安卓抓取JD wskey + 添加脚本自动转换JD cookie_jd_wsck-程序员宅基地
文章浏览阅读4.1w次,点赞9次,收藏98次。一、准备工具: 1. app:VNET(抓包用)、京东; 安卓手机需要下载VNET软件。下载官网:https://www.vnet-tech.com/zh/ 2. 已安装部署好的青龙面板;二、抓包wskey: 1. 打开已下载的VNET软件,第一步先安装CA证书; 点击右下角三角形按钮(开始抓包按钮),会提示安装证书,点击确定即可,app就会将CA证书下载至手机里,随后在手机设置里进行安装,这里不同手机可能安装位置不同,具体..._jd_wsck
Mybatis-Plus自动填充失效问题:当字段不为空时无法插入_mybatisplus插入不放为空的字段-程序员宅基地
文章浏览阅读2.9k次,点赞7次,收藏3次。本文针对mybatis-plus自动填充第一次更新能正常填充,第二次更新无法自动填充问题。????mybatis-plus自动填充:当要填充的字段不为空时,填充无效问题的解决????先上一副官方的图:取自官方:https://mp.baomidou.com/guide/auto-fill-metainfo.html第三条注意事项为自动填充失效原因:MetaObjectHandler提供的默认方法的策略均为:如果属性有值则不覆盖,如果填充值为null则不填充以官方案例为例:```java_mybatisplus插入不放为空的字段
Matlab 生成exe执行文件_matlab exe-程序员宅基地
文章浏览阅读1w次,点赞25次,收藏94次。利用 Application Complier 完成MATLAB转exe文件_matlab exe
Android下集成Paypal支付-程序员宅基地
文章浏览阅读137次。近期项目需要研究paypal支付,官网上的指导写的过于复杂,可能是老外的思维和中国人不一样吧。难得是发现下面这篇文章:http://www.androidhive.info/2015/02/Android-integrating-paypal-using-PHP-MySQL-part-1/在这篇文章的基础上,查看SDK简化了代码,给出下面这个例子,..._paypal支付集成到anroid应用中
随便推点
MIT-BEVFusion系列五--Nuscenes数据集详细介绍,有下载好的图片_nuscense数据集-程序员宅基地
文章浏览阅读2.3k次,点赞29次,收藏52次。nuScenes 数据集 (pronounced /nu:ːsiː:nz/) 是由 Motional (以前称为 nuTonomy) 团队开发的自动驾驶公共大型数据集。nuScenes 数据集的灵感来自于开创性的 KITTI 数据集。nuScenes 是第一个提供自动驾驶车辆整个传感器套件 (6 个摄像头、1 个 LIDAR、5 个 RADAR、GPS、IMU) 数据的大型数据集。与 KITTI 相比,nuScenes 包含的对象注释多了 7 倍。_nuscense数据集
python mqtt publish_Python Paho MQTT:无法立即在函数中发布-程序员宅基地
文章浏览阅读535次。我正在实现一个程序,该程序可以侦听特定主题,并在ESP8266发布新消息时对此做出反应.从ESP8266收到新消息时,我的程序将触发回调并执行一系列任务.我在回调函数中发布了两条消息,回到了Arduino正在侦听的主题.但是,仅在函数退出后才发布消息.谢谢您的所有宝贵时间.我试图在回调函数中使用loop(1),超时为1秒.该程序将立即发布该消息,但似乎陷入了循环.有人可以给我一些指针如何在我的回调..._python 函数里面 mqtt调用publish方法 没有效果
win11怎么装回win10系统_安装win10后卸载win11-程序员宅基地
文章浏览阅读3.4w次,点赞16次,收藏81次。微软出来了win11预览版系统,很多网友给自己的电脑下载安装尝鲜,不过因为是测试版可能会有比较多bug,又只有英文,有些网友使用起来并不顺畅,因此想要将win11退回win10系统。那么win11怎么装回win10系统呢?今天小编就教下大家win11退回win10系统的方法。方法一:1、首先点击开始菜单,在其中找到“设置”2、在设置面板中,我们可以找到“更新和安全”3、在更新和安全中,找到点击左边栏的“恢复”4、恢复的右侧我们就可以看到“回退到上版本的win10”了。方法二:_安装win10后卸载win11
SQL Server菜鸟入门_sql server菜鸟教程-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏3次。数据定义_sql server菜鸟教程
Leetcode 数组(简单题)[1-1000题]_给定一个浮点数数组nums(逗号分隔)和一个浮点数目标值target(与数组空格分隔),请-程序员宅基地
文章浏览阅读1.9k次。1. 两数之和给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。示例:给定 nums = [2, 7, 11, 15], target = 9因为 nums[0] + nums[1] = 2 + 7 = 9所以返回 [0, 1]方法一..._给定一个浮点数数组nums(逗号分隔)和一个浮点数目标值target(与数组空格分隔),请
python性能优化方案_python 性能优化方法小结-程序员宅基地
文章浏览阅读152次。提高性能有如下方法1、Cython,用于合并python和c语言静态编译泛型2、IPython.parallel,用于在本地或者集群上并行执行代码3、numexpr,用于快速数值运算4、multiprocessing,python内建的并行处理模块5、Numba,用于为cpu动态编译python代码6、NumbaPro,用于为多核cpu和gpu动态编译python代码为了验证相同算法在上面不同实现..._np.array 测试gpu性能