【项目实战】Python基于BP神经网络算法实现家用热水器用户行为分析与事件识别-程序员宅基地
技术标签: MLP分类模型 python 机器学习 BP神经网络算法 项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
居民在使用家用热水器的过程中,会因为地区气候、不同区域和用户年龄性别差异等原因形成不同的使用习惯。家电企业若能深入了解其产品在不同用户群中的使用习惯,开发符合客户需求和使用习惯的功能,就能开拓新市场。
本项目将依据BP神经网络算法构建洗浴事件识别模型,进而对不同地区的用户的洗浴事件进行识别,然后根据识别结果比较不同客户群的客户使用习惯,以加深对客户需求的理解等。从而厂商便可以对不同的客户群提供最适合的个性化产品,改进新产品的智能化研发并制定相应的营销策略。
2.项目目标
自1988年中国第一台真正意义上的热水器诞生至今,该行业经历了翻天覆地的变化。随着入场企业的增多,热水器行业竞争愈发激烈,如何在众多的企业中脱颖而出,成了热水器企业发展的重中之重。从用户的角度出发,分析用户的使用行为,改善热水器的产品功能,是企业在竞争中脱颖而出的重要方法之一。
随着我国国内大家电品牌的进入和国外品牌的涌入,电热水器相关技术在过去20年间得到了快速发展,屡创新高。从首次提出封闭式电热水器的概念到水电分离技术的研发,再到漏电保护技术的应用及出水断电技术和防电墙技术专利的申请突破,如今高效能技术颠覆了业内对电热水器“高能耗”的认知。然而,当下的热水器行业也并非一片“太平盛世”,行业内正在上演一幕幕“弱肉强食”的“丛林法则”戏码,市场份额逐步向龙头企业集中,尤其是那些在资金、渠道和品牌影响力等方面拥有实力的综合家电品类巨头,它们正在不断“蚕食鲸吞”市场“蛋糕”。要想在该行业立足,只能走产品差异化路线,提升技术实力和产品质量,在功能卖点、外观等方面做出自身的特色。
国内某热水器生产厂商新研发的一种高端智能热水器,在状态发生改变或者有水流状态时,会采集各监控指标数据。本项目基于热水器采集的时间序列数据,根据水流量和停顿时间间隔,将顺序排列的离散的用水时间节点划分为不同大小的时间区间,每个区间都是一个可理解的一次完整的用水事件,并以热水器一次完整用水事件作为一个基本事件,将时间序列数据划分为独立的用水事件,并识别出其中属于洗浴的事件。基于以上工作,该厂商可从热水器智能操作和节能运行等方面对产品进行优化。
在热水器用户行为分析过程中,用水事件识别是最为关键的环节。根据该热水器生产厂商提供的数据,热水器用户用水事件划分与识别案例的整体目标如下:
1)根据热水器采集到的数据,划分一次完整用水事件。
2)在划分好的一次完整用水事件中,识别出洗浴事件。
3.项目过程
热水器用户用水事件划分与识别案例的总体流程如图所示:
热水器用户用水事件划分与识别项目的总体流程
热水器用户用水事件划分与识别项目主要包括以下5个步骤:
1)对热水器用户的历史用水数据进行选择性抽取,构建专家样本。
2)对步骤1形成的数据集,进行数据探索分析与预处理,包括探索水流量的分布情况,删除冗余属性,识别用水数据的缺失值,并对缺失值进行处理,然后根据建模的需要进行属性构造等。最后根据以上处理,对热水器用户用水样本数据建立用水事件时间间隔识别模型和划分一次完整的用水事件模型,接着在一次完整用水事件划分结果的基础上,剔除短暂用水事件、缩小识别范围等。
3)在步骤2得到的建模样本数据基础上,建立洗浴事件识别模型,对洗浴事件识别模型进行模型分析评价。
4)应用步骤3形成的模型结果,并对洗浴事件划分进行优化。
5)调用洗浴事件识别模型,对实时监控的热水器流水数据进行洗浴事件自动识别。
4.数据采集
本次建模数据来源于网络(本项目撰写人整理而成),数据如下:
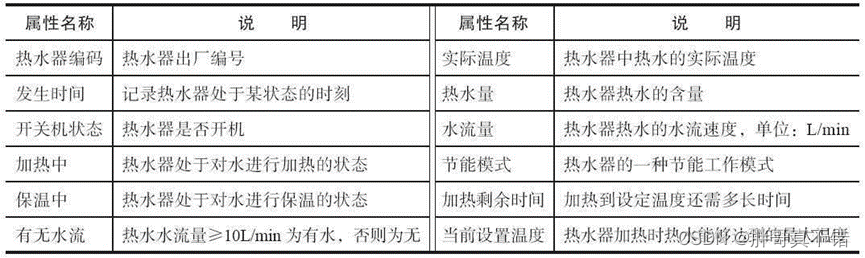
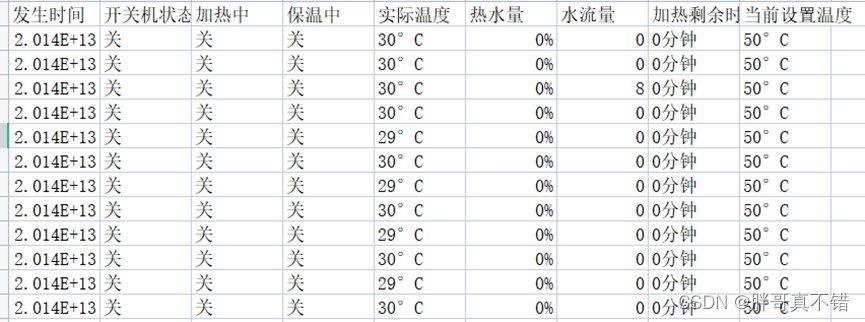
本项目对原始数据采用无放回随机抽样法,抽取200家热水器用户某段时间的用水记录作为原始建模数据。由于热水器用户不仅使用热水器来洗浴,还有洗手、洗脸、刷牙、洗菜、做饭等用水行为,所以热水器采集到的数据来自各种不同的用水事件。热水器采集的用水数据包含12个属性:热水器编码、发生时间、开关机状态、加热中、保温中、有无水流、实际温度、热水量、水流量、节能模式、加热剩余时间和当前设置温度等。其解释说明如表所示:
热水器数据属性说明
部分数据展示如下:
5.探索性数据分析
在热水器的使用过程中,热水器的状态会经常发生改变,如开机和关机、由加热转到保温、由无水流到有水流、水温由50℃变为49℃等。而智能热水器在状态发生改变或水流量非零时,每两秒就会采集一条状态数据。由于数据的采集频率较高,并且数据来自大量用户,因此数据总量非常大。
探索分析热水器的水流量状况,其中“有无水流”和“水流量”属性最能直观体现热水器的水流量情况,对这两个属性进行探索分析,关键代码如下:
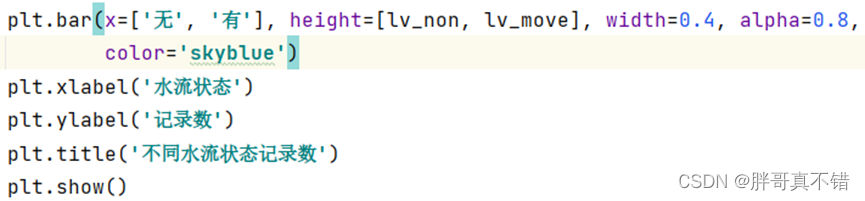
通过代码清单得到不同水流状态的记录条形图,如下图所示,无水流状态的记录明显比有水流状态的记录要多。
不同水流状态的记录条形图
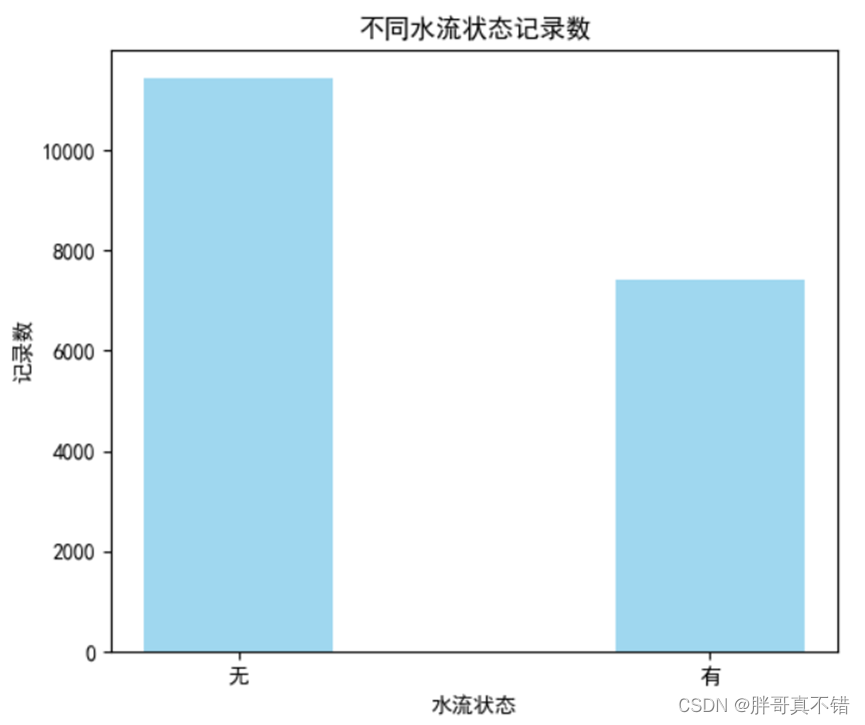
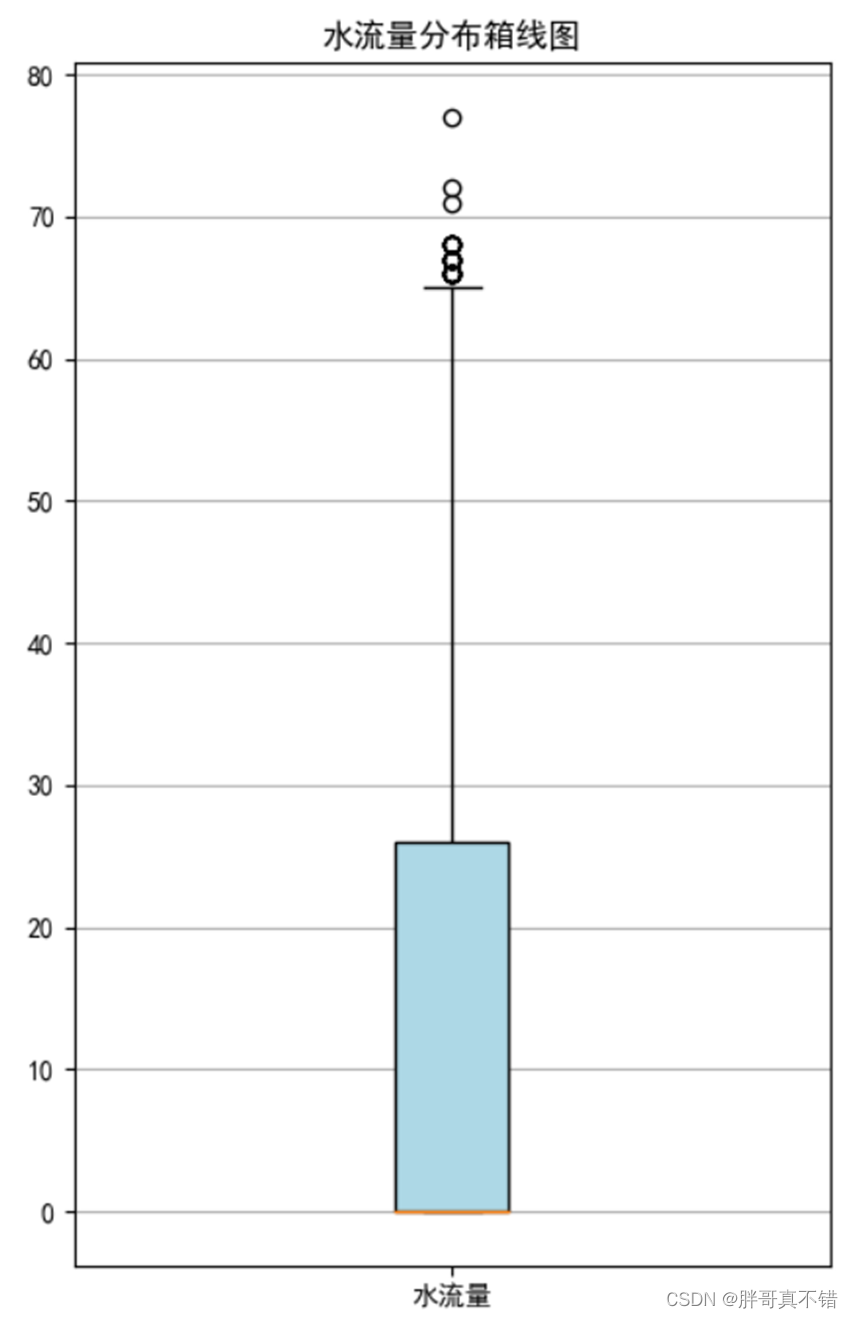
通过代码得到不同水流状态的记录箱型图,如下图所示,箱体贴近0,说明无水流量的记录较多,水流量的分布与水流状态的分布一致。
水流量分布箱型图
“用水停顿时间间隔”定义为一条水流量不为0的流水记录同下一条水流量不为0的流水记录之间的时间间隔。根据现场实验统计,两次用水过程的用水停顿间隔时长一般不大于4分钟。为了探究热水器用户真实用水停顿时间间隔的分布情况,统计用水停顿的时间间隔并做出频率分布表。通过频率分布表分析用户用水停顿时间间隔的规律性,具体的数据如表所示:
用水停顿时间间隔频数分布表(单位:分钟)
通过分析表可知,停顿时间间隔为0~0.3分钟的频率很高,根据日常用水经验可以判断其为一次用水时间中的停顿;停顿时间间隔为6~13分钟的频率较低,分析其为两次用水事件之间的停顿。根据现场实验统计用水停顿的时间间隔可知,两次用水事件的停顿时间间隔分布在3~7分钟。
6.数据预处理
6.1.属性归约
由于热水器采集的用水数据属性较多,本项目做以下处理。因为分析的主要对象为热水器用户,分析的主要目标为热水器用户洗浴行为的一般规律,所以“热水器编号”属性可以去除;因为在热水器采集的数据中,“有无水流”属性可以通过“水流量”属性反映出来,“节能模式”属性取值相同均为“关”,对分析无作用,所以可以去除。
删除冗余属性“热水器编号”“有无水流”“节能模式”,关键代码如下:
删除冗余属性后得到用来建模的属性如表所示:
删除冗余属性后部分数据列表
6.2.划分用水事件
热水器用户的用水数据存储在数据库中,记录了各种各样的用水事件,包括洗浴、洗手、刷牙、洗脸、洗衣、洗菜等,而且一次用水事件由数条甚至数千条的状态记录组成。所以本项目首先需要在大量的状态记录中划分出哪些连续的数据是一次完整的用水事件。
在用水状态记录中,水流量不为0,表明热水器用户正在使用热水;而水流量为0时,则表明热水器用户用热水时发生停顿或者用热水结束。对于任何一个用水记录,如果它的向前时差超过阈值T,则将它记为事件的开始编号;如果它的向后时差超过阈值T,则将其记为事件的结束编号。划分模型的符号说明如表所示。
一次完整用水事件模型构建符号说明表
一次完整用水事件的划分步骤如下:
1)读取数据记录,识别所有水流量不为0的状态记录,将它们的发生时间记为序列t1。
2)对序列t1构建其向前时差列和向后时差列,并分别与阈值进行比较。向前时差超过阈值T,则将它记为新的用水事件的开始编号;如果向后时差超过阈值T,则将其记为用水事件的结束编号。
循环执行步骤2,直到向前时差列和向后时差列与均值比较完毕,则结束事件划分。
用水事件划分主要分为两个步骤,即确定单次用水时长间隔,计算两条相邻记录的时间,实现代码如代码清单所示。
划分用水事件
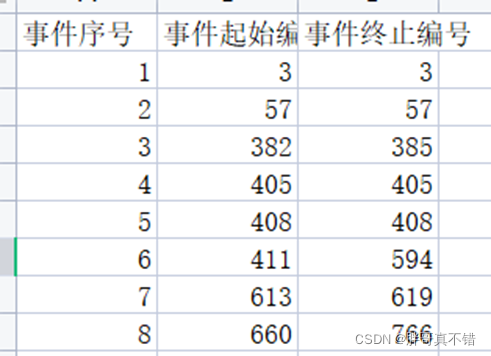
对热水器用户的用水数据进行划分,结果如表所示:
用水数据划分结果
6.3.确定单次用水事件时长阈值
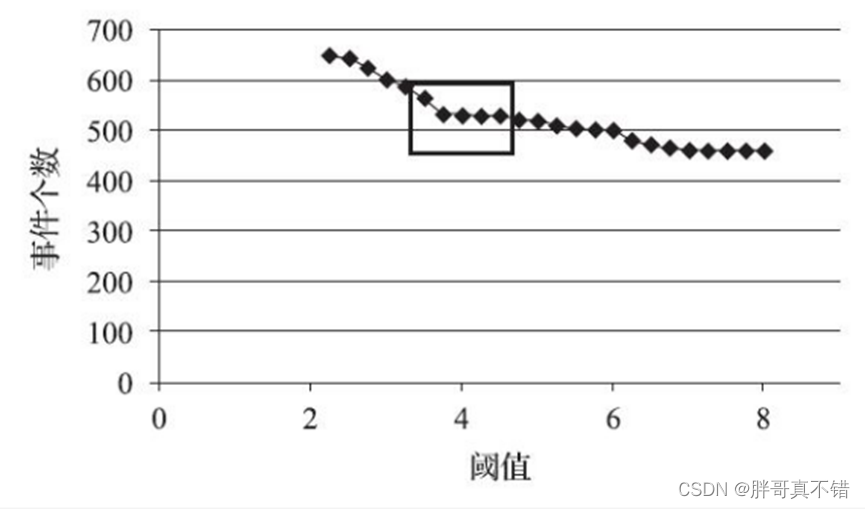
对某热水器用户的数据,根据不同的阈值划分用水事件,得到相应的事件个数,阈值变化与划分得到事件个数如表所示,阈值与划分事件个数关系如图所示:
某热水器用户家庭某时间段不同用水时间间隔阈值事件划分个数
阈值与划分事件个数的关系
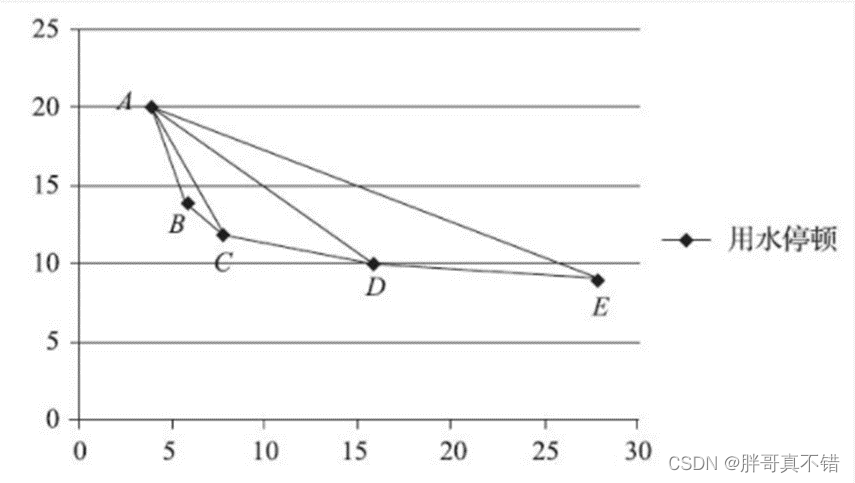
图为阈值与划分事件个数的散点图。图中某段阈值范围内,下降趋势明显,说明在该段阈值范围内,热水器用户的停顿习惯比较集中。如果趋势比较平缓,则说明热水器用户停顿热水的习惯趋于稳定,所以取该段时间开始的时间点作为阈值,既不会将短的用水事件合并,又不会将长的用水事件拆开。在图中,热水器用户停顿热水的习惯在方框中的位置趋于稳定,说明该热水器用户的用水停顿习惯用方框开始的时间点作为划分阈值会有好的效果。
曲线在图中,方框趋于稳定时,其方框开始的点的斜率趋于一个较小的值。为了用程序来识别这一特征,将这一特征提取为规则。图A可以说明如何识别上图方框中起始的时间。
每个阈值对应一个点,给每个阈值计算得到一个斜率指标,如图A所示。其中,A点是要计算的斜率指标点。为了直观展示,用表1-7所示的符号来进行说明。
图A 斜率计算图表
1-7 阈值寻优模型符号说明
将K作为A点的斜率指标,特别指出横坐标上的最后4个点没有斜率指标,因为找不出在它以后的4个更长的阈值。但这不影响对最优阈值的寻找,因为可以提高阈值的上限,以使最后的4个阈值不在考虑范围内。
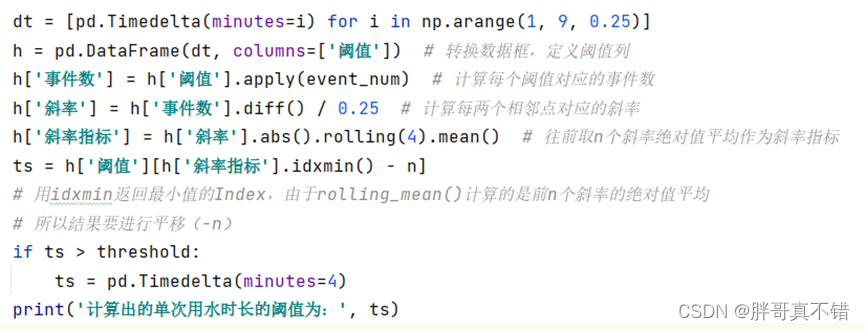
先统计出各个阈值下的用水事件的个数,再通过阈值寻优的方式找出最优的阈值,关键代码如下:
确定单次用水事件时长阈值
得到阈值优化的结果如下:
1)当存在一个阈值的斜率指标K<1时,则取阈值最小的点A(可能存在多个阈值的斜率指标小于1)的横坐标xA作为用水事件划分的阈值,其中K<1中的“1”是经过实际数据验证的一个专家阈值。
2)当不存在一个阈值的斜率指标K<1时,则找所有阈值中斜率指标最小的阈值;如果该阈值的斜率指标小于5,则取该阈值作为用水事件划分的阈值;如果该阈值的斜率指标不小于5,则阈值取默认值的阈值——4分钟。其中,“斜率指标小于5”中的“5”是经过实际数据验证的一个专家阈值。
6.4.属性构造
6.4.1构建用水时长与频率属性
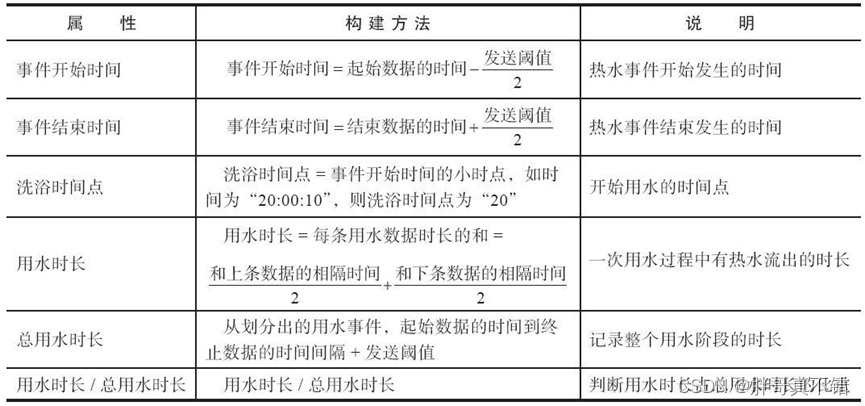
不同用水事件的用水时长是基础属性之一。例如,单次洗漱事件一般总时长在5分钟左右,而一次手洗衣物事件的时长则根据衣物多少而不同。根据用水时长这一属性可以构建如表所示的事件开始时间、事件结束时间、洗浴时间点、用水时长、总用水时长和用水时长/总用水时长这6个属性。
主要用水时长类属性构建说明
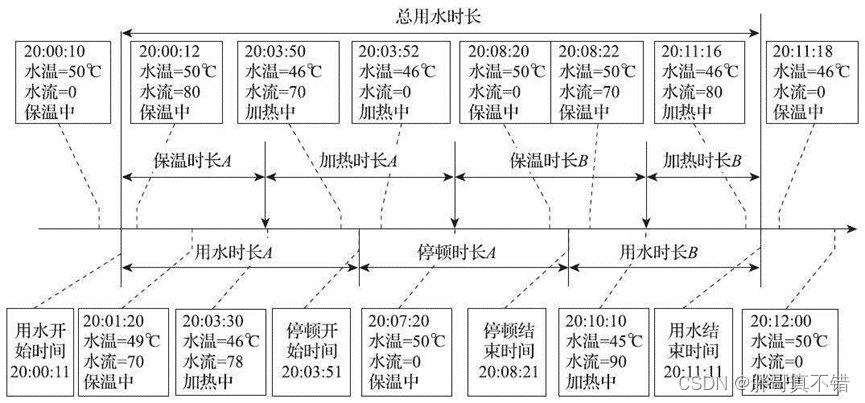
构建用水开始时间或结束时间两个特征时分别减去或加上了发送阈值(发送阈值是指热水器传输数据的频率的大小)。其原因以图B为例。在20:00:10时,热水器记录到的数据是数据还没有用水,而在20:00:12时,热水器记录的数据是有用水行为。所以用水开始时间在20:00:10~20:00:12之间,考虑到网络不稳定导致的网络数据传输延时数分钟或数小时之久等因素,取平均值会导致很大的偏差,综合分析构建“用水开始时间”为起始数据的时间减去“发送阈值”的一半。
图B 一次用水事件及相关属性说明
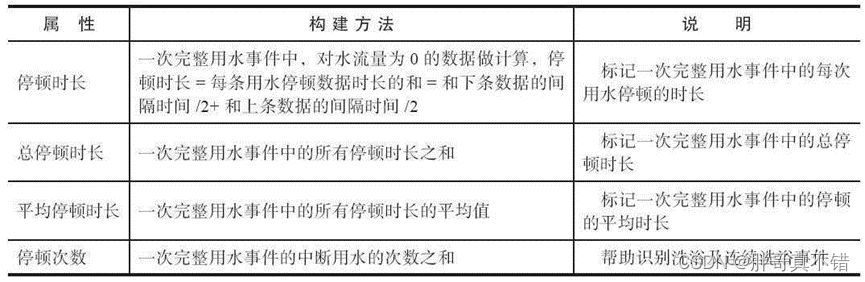
用水时长相关的属性只能区分出一部分用水事件,不同用水事件的用水停顿和频率也不同。例如,一次完整洗漱事件的停顿次数不多,停顿的时间长短不一,平均停顿时长较短;一次手洗衣物事件的停顿次数较多,停顿时间相差不大,平均停顿时长一般。根据这一属性,可以构建如表所示的停顿时长、总停顿时长、平均停顿时长、停顿次数4个属性。
主要用水频率类属性
构建用水时长与用水频率属性,关键代码如下:
构建用水时长与用水频率属性
6.4.2构建用水量与波动属性
除了用水时长、停顿和频率外,用水量也是识别该事件是否为洗浴事件的重要属性。例如,用水事件中的洗漱事件相比洗浴事件有停顿次数多、用水总量少、平均用水少的特点;手洗衣物事件相比于洗浴事件则有停顿次数多、用水总量多、平均用水量多的特点。根据这一原因可以构建出下表所示的两个用水量属性。
用水量属性构建说明
同时用水波动也是区分不同用水事件的关键。一般来说,在一次洗漱事件中,刷牙和洗脸的用水量完全不同;而在一次手洗衣物事件中,每次用水的量和停顿时间相差却不大。根据不同用水事件的这一特征可以构建下表所示的水流量波动和停顿时长波动两个特征。
用水波动属性构建说明
在用水时长和频率属性的基础之上构建用水量和用水波动属性,需要充分利用用水时长和频率属性,关键代码如下:
构建用水量和用水波动属性
6.5.筛选候选洗浴事件
洗浴事件的识别是建立在一次用水事件识别的基础上的,也就是从已经划分好的一次用水事件中识别出哪些一次用水事件是洗浴事件。
可以使用3个比较宽松的条件筛选掉那些非常短暂的用水事件,确定不可能为洗浴事件的数据就删除,剩余的事件称为“候选洗浴事件”。这3个条件是“或”的关系,也就是说,只要一次完整的用水事件满足任意一个条件,就被判定为短暂用水事件,即会被筛选掉。3个筛选条件如下:
1)一次用水事件中总用水量小于5升。
2)用水时长小于100秒。
3)总用水时长小于120秒。
基于构建的用水时长、用水量属性,筛选候选洗浴事件,关键代码如下:
筛选候选洗浴事件
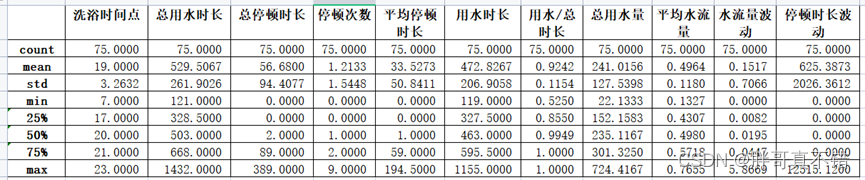
筛选前,用水事件数目总共为172个,经过筛选,余下75个用水事件。结合日志,最终用于建模的属性的总数为11个,其基本情况如下表所示:
属性基本情况
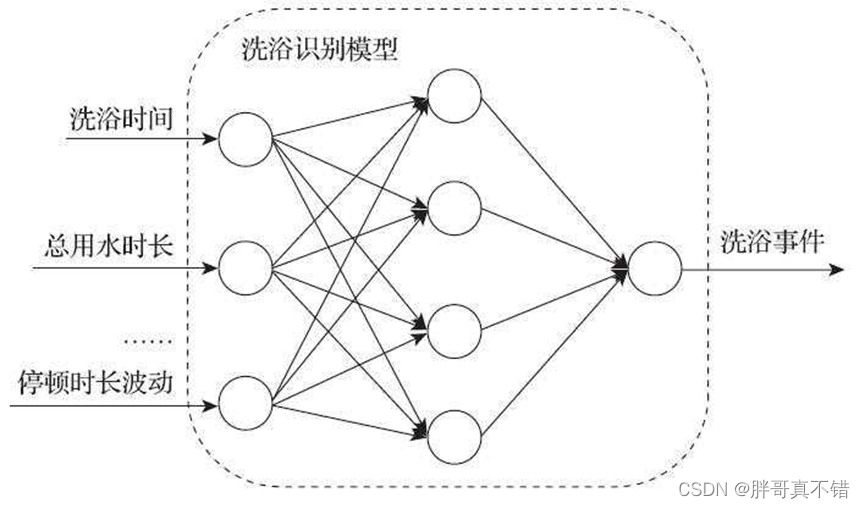
7.构建BP神经网络模型
根据建模样本数据建立BP神经网络模型识别洗浴事件。由于洗浴事件与普通用水事件在特征上存在不同,而且这些不同的特征要被体现出来。于是,根据热水器用户提供的用水日志,将其中洗浴事件的数据状态记录作为训练样本训练BP神经网络。然后根据训练好的BP神经网络来检验新采集的数据,具体过程如下图所示:
BP神经模型识别洗浴事件
训练BP神经网络的时候,选取了“候选洗浴事件”的11个属性作为BP神经网络的输入,分别为:洗浴时间点、总用水时长、总停顿时长、平均停顿时长、停顿次数、用水时长、用水时长/总用水时长、总用水量、平均水流量、水流量波动和停顿时长波动。训练BP神经网络时给定的输出为1与0,其中1代表该次事件为洗浴事件,0表示该次事件不是洗浴事件。是否为洗浴事件的标签的依据是热水器的用水记录日志。
构建BP神经网络模型需要注意数据本身属性之间存在的量级差异,因此需要进行标准化,消除量级差异。另外,为了便于后续应用模型,可以用joblib.dump函数保存模型,关键代码如下:
构建BP神经网络模型
在训练BP神经网络时,对神经网络的参数进行了寻优,发现含有两个隐层的神经网络训练效果较好,其中两个隐层的隐节点数分别为17和10时训练的效果较好。
根据样本,得到训练好的神经网络后,就可以用来识别对应的热水器用户的洗浴事件,其中待检测的样本的11个属性作为输入,输出层输出一个在[-1,1]范围内的值,如果该值小于0,则该事件不是洗浴事件,如果该值大于0,则该事件是洗浴事件。某热水器用户记录了两周的热水器用水日志,将前一周的数据作为训练数据,将后一周的数据作为测试数据,代入上述模型进行测试。
8.模型评估
结合模型评价的相关知识,使用精确率(precision)、召回率(recall)和F1值来衡量模型评价的效果较为客观、准确。同时结合ROC曲线,可以更加直观地评价模型的效果,关键代码如下:
8.1.评估指标
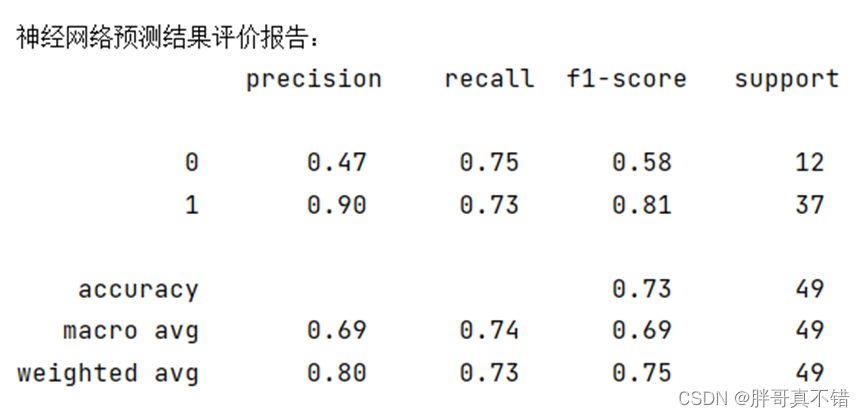
根据该热水器用户提供的用水日志判断事件是否为洗浴事件,多层神经网络模型识别结果报告如下表所示:
根据模型评估报告表以看出,在洗浴事件的识别上精确率(precision)达到73%,同时召回率(recall)达到了90%,F1分数80%,说明模型效果良好。
8.2.分类报告
通过上图可以看到,分类为0的F1值为0.58;分类为1的F1值为0.81,准确率为0.73.
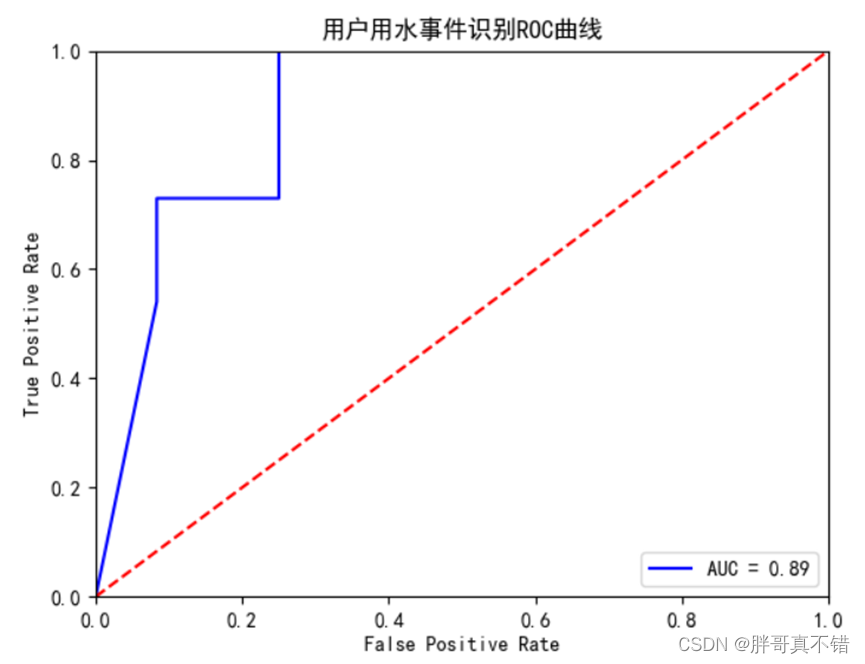
8.3.ROC曲线
从上图可以看到,此模型AUC值为0.89,说明模型效果良好。
9.结论与展望
综合上述结果,可以确定此次创建的模型是有效且效果良好的,能够用于实际的洗浴事件的识别中。














# 查看有无水流的分布 # 数据提取 lv_non = pd.value_counts(data['有无水流'])['无'] lv_move = pd.value_counts(data['有无水流'])['有'] # 绘制条形图 # 本次机器学习项目实战所需的资料,项目资源如下: 链接:https://pan.baidu.com/s/1dAyRohpE0eJamHdb1iOLJw 提取码:1xsk fig = plt.figure(figsize=(6, 5)) # 设置画布大小 plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 plt.rcParams['axes.unicode_minus'] = False plt.bar(x=['无', '有'], height=[lv_non, lv_move], width=0.4, alpha=0.8, color='skyblue') plt.xlabel('水流状态') plt.ylabel('记录数') plt.title('不同水流状态记录数') plt.show() # 查看水流量分布 water = data['水流量'] # 绘制水流量分布箱型图 fig = plt.figure(figsize=(5, 8)) plt.boxplot(water, patch_artist=True, labels=['水流量'], # 设置x轴标题 boxprops={'facecolor': 'lightblue'}) # 设置填充颜色 plt.title('水流量分布箱线图') # 显示y坐标轴的底线 plt.grid(axis='y') plt.show()
智能推荐
flask-login-程序员宅基地
文章浏览阅读170次。创建扩展对象实例from flask_login import LoginManagerlogin_manager = LoginManager()login_manager.login_view = 'auth.login'# 上面这一句是设置登录视图的名称,如果一个未登录用户请求一个只有登录用户才能访问的视图,# 则闪现一条错误消息,并重定向到这里设置的登录视图。# 如果未设置..._python flask please log in to access this page
html怎么控制top值为0,关于vue滚动scrollTop 赋值一直为0问题-程序员宅基地
文章浏览阅读428次。Vue中document.body.scrollTop的值总为零的解决办法最近在做vue的时候监听页面滚动发现document.body.scrollTop一直为0但是发现document.body.scrollTop一直是0。查资料发现是DTD的问题。页面指定了DTD,即指定了DOCTYPE时,使用document.documentElement。页面没有DTD,即没指定DOCTYPE时,使用d..._滚动给scrolltop赋值
kingbase数据库安装教程(初步使用)(人大金仓)-程序员宅基地
文章浏览阅读2.1k次,点赞25次,收藏21次。人大金仓数据库管理系统KingbaseES(简称:金仓数据库或KingbaseES)是北京人大金仓信息技术股份有限公司自主研制开发的具有自主知识产权的通用关系型数据库管理系统。_kingbase
vue基础笔试题_vue笔试题-程序员宅基地
文章浏览阅读1.2w次,点赞20次,收藏156次。ctions 选项用来定义事件处理方法,用于处理 state 数据。actions 类似于 mutations,不同之处在于 actions 是异步执行的,事件处理函数可以接收 {commit} 对象,完成 mutation 提交,从而方便 devtools 调试工具跟踪状态的 state 变化。..............._vue笔试题
isis协议配置和详解-程序员宅基地
文章浏览阅读1.1w次,点赞2次,收藏23次。isis是一种与ospf很相似的网络协议(属于动态路由协议),它被应用在巨大规模网络,如运营商以及银行等。同样的它也是基于链路状态算法,支持clnp网络,ip网络。与ospf不同的是,它是基于数据链路层报文传输,而ospf则是在ip层进行计算。它可以自动的发现远程网络,只要网络拓扑结构发生了变化,路由器就会相互交换路由信息,不仅能够自动获知新增加的网络,还可以在当前网络连接失败时找出备用路径。无类..._isis协议配置
Proxychains 手册_proxychains是什么-程序员宅基地
文章浏览阅读1.9k次。名称:Proxychains – 通过代理服务器进行连接语法:proxychains 描述:这个程序会强制所有使用特定tcp连接的客户端所引起的TCP连接走代理通道。它是一种跳板程序。这个软件和sockscap、premo、eborder异曲同工。2.0版支持SOCKS4、SOCKS5、HTTP类的代理。认证方法:socks-“user/pass”,http-“basic_proxychains是什么
随便推点
计算机科学与技术网上书店,计算机科学与技术毕业论文:基于web的网上书店.doc...-程序员宅基地
文章浏览阅读188次。本科毕业论文(设计)题 目 基于web的网上书店学生姓名专业名称 计算机科学与技术指导教师目录1、引言52、系统概述62.1概述62.2 开发平台73.需求分析73.1总体需求描述73.2系统总体功能图73.3系统需要实现的功能83.4业务流程图94.详细设计114.1数据库详细设计114.2建立数据库124.3页面详细设计:185用户手册225.1普通用户:225.2管理员:24参考文献3..._计算机科学与技术毕业设计网上书店
素数求和_输入一个正整数n和n个正整数,统计其中素数的和。-程序员宅基地
文章浏览阅读1.6k次。Description输入一个正整数N和N个正整数,统计其中素数的和。Input输入一个正整数N(1≤N≤100)和N个正整数(≥3),用空格分隔。Output输出所有素数,用空格隔开;再输出这些素数和。Sample Input10 4 5 8 12 13 24 34 37 20 885 1 5 8 12 13Sample Output5 13 37 s=555 13 s=..._输入一个正整数n和n个正整数,统计其中素数的和。
Oracle DB 使用RMAN创建备份2_rman 备份 生成两个文件-程序员宅基地
文章浏览阅读2.5k次。归档备份:概念归档备份:概念 如果需要在指定时间内保留联机备份,RMAN 通常会假定用户可能需要在自执行该备份以来到现在之间的任意时间执行时间点恢复。为了满足这一要求,RMAN 会在此时段内保留归档日志。但是,可能仅需要在指定的时间(如两年)内保留特定备份(并使其保持一致和可恢复)。用户不打算恢复到自执行该备份以后的某一时间点,只是希望能够正好恢复到执行该备_rman 备份 生成两个文件
JS实用技巧之断点调试详解_js断点调试-程序员宅基地
文章浏览阅读9.3k次,点赞9次,收藏58次。引言调试能力是一个程序员的生存根本,可是很多初学者却忽视调试。今天我们就来讨究一下JS的调试技巧。本文章将会详细列举JS相关的各种实用调试技巧。如果您是JS的初学者,那么这篇文章将对您有很大的帮助。为什么要调试?程序就是函数堆砌起来的,程序的运行就是函数的执行过程。而通过JS调试,我们可以更为直观的追踪到在程序运行中,函数的执行顺序,以及各个参数的变化。这样我们就可以快速的定位到问题所在。1. 什么是JS调试?在程序运行中,我们总会遇到各种bug,而通过代码的追踪代码的运行顺序从而定位到问题的过_js断点调试
记录一次kafka内存溢出,消费慢_kafka消费导致内存泄露-程序员宅基地
文章浏览阅读1k次。记录一次kafka内存溢出,消费慢_kafka消费导致内存泄露
前端学习week9-程序员宅基地
文章浏览阅读933次,点赞12次,收藏29次。数据存储在用户浏览器中设置、读取方便、甚至页面刷新不丢失数据容量较大,sessionStorage和localStorage约5M左右正则表达式是用于匹配字符串中正负组合的模式。在JavaScript中,正则表达式也是对象,通常用来查找、替换哪些符合正则表达式的文本作用:表单验证、过滤敏感词、字符串中提取我们想要的部分const 变量名 = /表达式/其中/ /是正则表达式字面量基于VueCli自定义创建项目架子安装脚手架创建项目。