DataFrame(13):DataFrame的排序与排名问题_dataframe 排序-程序员宅基地
技术标签: pandas python python排序 sort_index sort_value
1、说明
DataFrame中的排序分为两种,一种是对索引排序,一种是对值进行排序。
索引排序:sort_index();值排序:sort_values();值排名:rank()
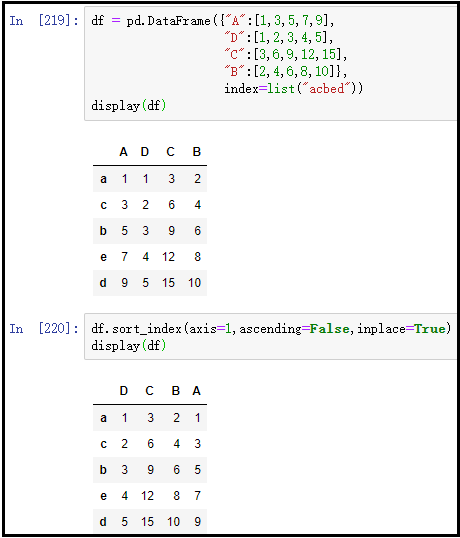
对于索引排序,涉及到对行索引、列索引的排序,并且还涉及到是升序还是降序。函数df.sort_index(axis= , ascending= , inplace=),需要特别注意这三个参数。axis表示对行操作,还是对列操作;ascending表示升序,还是降序操作。
对于值排序,同样也是涉及到行、列排序问题,升序、降序排列问题。函数df.sort_values(by= , axis= , ascending= , inplace=),也需要特别注意这几个参数,只是多了一个by操作,需要我们指明是按照哪一行或哪一列,进行排序的。
注意:axis=0表示对行操作,axis=1表示对列进行操作;ascending=True表示升序,ascending=False表示降序;inplace=True表示对原始DataFrame本身操作,因此不需要赋值操作,inplace=False相当于是对原始DataFrame的拷贝,之后的一些操作都是针对这个拷贝文件进行操作的,因此需要我们赋值给一个变量,保存操作后的结果。
2、索引排序:df.sort_index()
① 对行索引,进行升序排列
df = pd.DataFrame({
"A":[1,3,5,7,9],
"D":[1,2,3,4,5],
"C":[3,6,9,12,15],
"B":[2,4,6,8,10]},
index=list("acbed"))
display(df)
display(id(df))
df.sort_index(axis=0,ascending=True,inplace=True)
display(df)
display(id(df))
df1 = df.sort_index(axis=0,ascending=True)
display(df1)
display(id(df1))
结果如下:

② 对列索引,进行降序排列
df = pd.DataFrame({
"A":[1,3,5,7,9],
"D":[1,2,3,4,5],
"C":[3,6,9,12,15],
"B":[2,4,6,8,10]},
index=list("acbed"))
display(df)
df.sort_index(axis=1,ascending=False,inplace=True)
display(df)
结果如下:
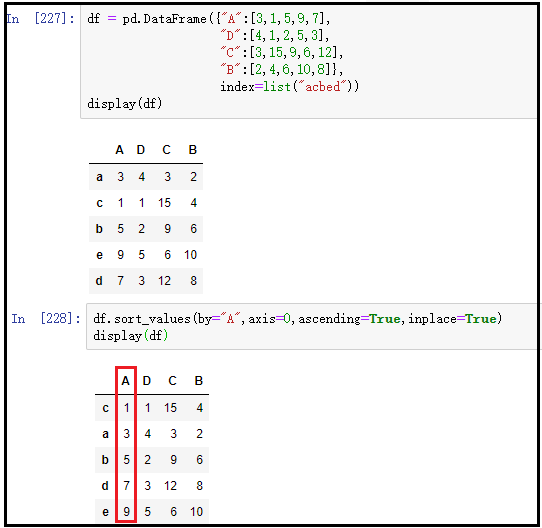
3、值排序:df.sort_values()
① 对某一列进行升序排列(有实际意义)
df = pd.DataFrame({
"A":[3,1,5,9,7],
"D":[4,1,2,5,3],
"C":[3,15,9,6,12],
"B":[2,4,6,10,8]},
index=list("acbed"))
display(df)
df.sort_values(by="A",axis=0,ascending=True,inplace=True)
display(df)
结果如下:
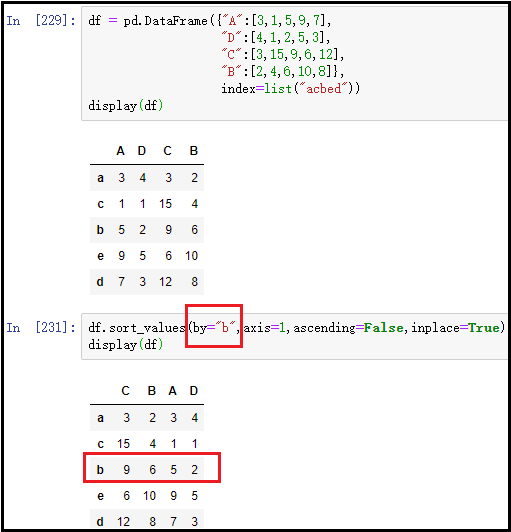
② 对某一行进行降序排列(实际意义不大)
df = pd.DataFrame({
"A":[3,1,5,9,7],
"D":[4,1,2,5,3],
"C":[3,15,9,6,12],
"B":[2,4,6,10,8]},
index=list("acbed"))
display(df)
df.sort_values(by="A",axis=1,ascending=False,inplace=True)
display(df)
结果如下:
③ 对多列进行联合排序(重要)
df = pd.DataFrame({
"A":[3,1,3,9,7],
"D":[666,1,888,5,3],
"C":[3,15,9,6,12],
"B":[2,4,6,10,8]},
index=list("acbed"))
display(df)
df.sort_values(by=["A","D"],axis=0,ascending=[True,False],inplace=True)
df
结果如下:
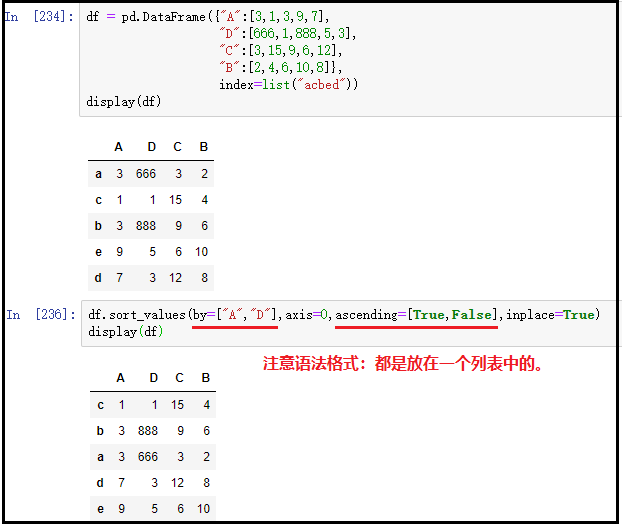
注意:上图中,我们分别按照A和D这个列进行排序,先按照A列做升序排列,当A列中具有相同值的时候,就按照D列做降序排列。
4、sort_values()中的na_position参数
na_position参数用于设定缺失值的显示位置,first表示缺失值显示在最前面;last表示缺失值显示在最后面。
df = pd.DataFrame({
"A":[10,8,np.nan,2,4],
"D":[1,7,5,3,8],
"B":[5,2,8,4,1]},
index=list("abcde"))
display(df)
df.sort_values(by="A",axis=0,inplace=True,na_position="first")
display(df)
df.sort_values(by="A",axis=0,inplace=True,na_position="last")
display(df)
结果如下:

5、“值排名”:rank()函数
1)rank()函数的常用参数说明
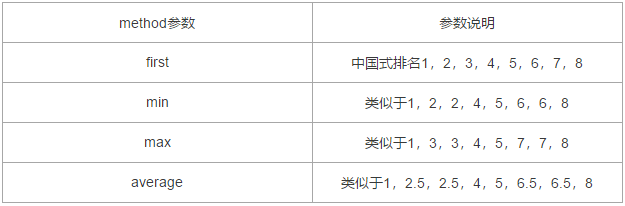
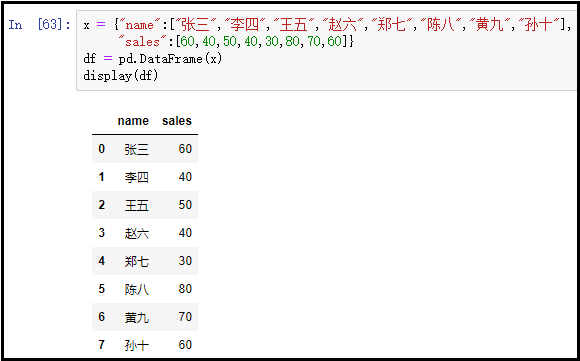
2)原始数据
x = {
"name":["张三","李四","王五","赵六","郑七","陈八","黄九","孙十"],
"sales":[60,40,50,40,30,80,70,60]}
df = pd.DataFrame(x)
display(df)
结果如下:
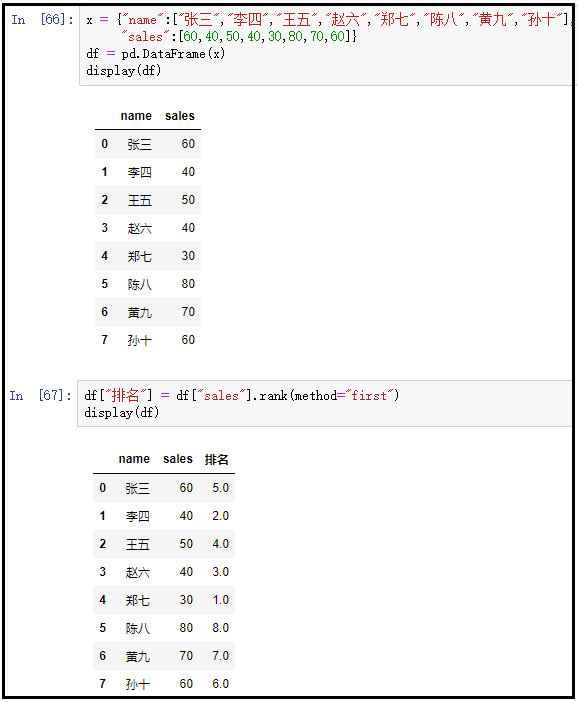
3)rank()函数使用如下
① method=“first”
x = {
"name":["张三","李四","王五","赵六","郑七","陈八","黄九","孙十"],
"sales":[60,40,50,40,30,80,70,60]}
df = pd.DataFrame(x)
display(df)
df["排名"] = df["sales"].rank(method="first")
display(df)
结果如下:
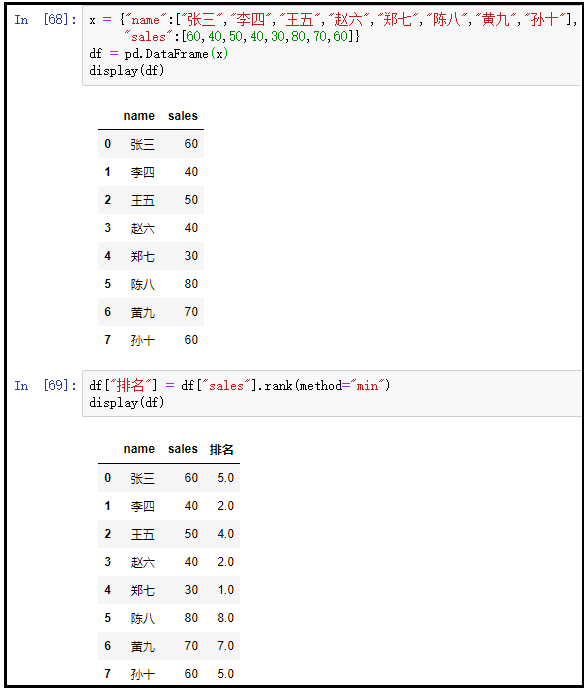
② method=“min”
x = {
"name":["张三","李四","王五","赵六","郑七","陈八","黄九","孙十"],
"sales":[60,40,50,40,30,80,70,60]}
df = pd.DataFrame(x)
display(df)
df["排名"] = df["sales"].rank(method="min")
display(df)
结果如下:
③ method=“max”
x = {
"name":["张三","李四","王五","赵六","郑七","陈八","黄九","孙十"],
"sales":[60,40,50,40,30,80,70,60]}
df = pd.DataFrame(x)
display(df)
df["排名"] = df["sales"].rank(method="max")
display(df)
结果如下:
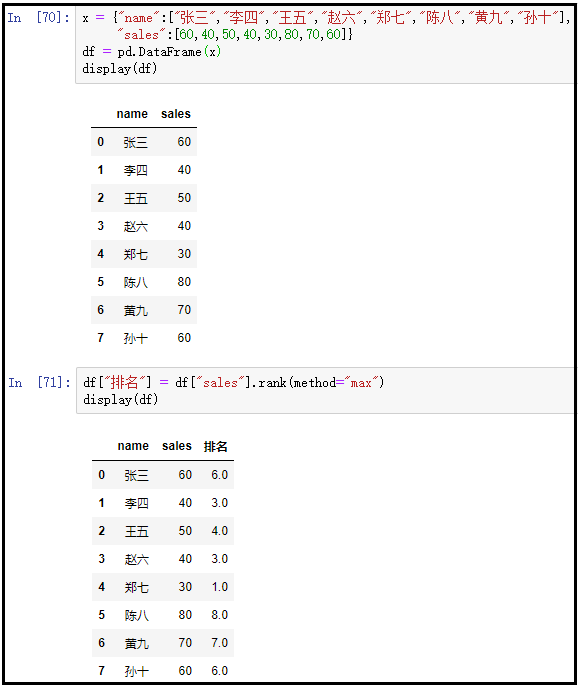
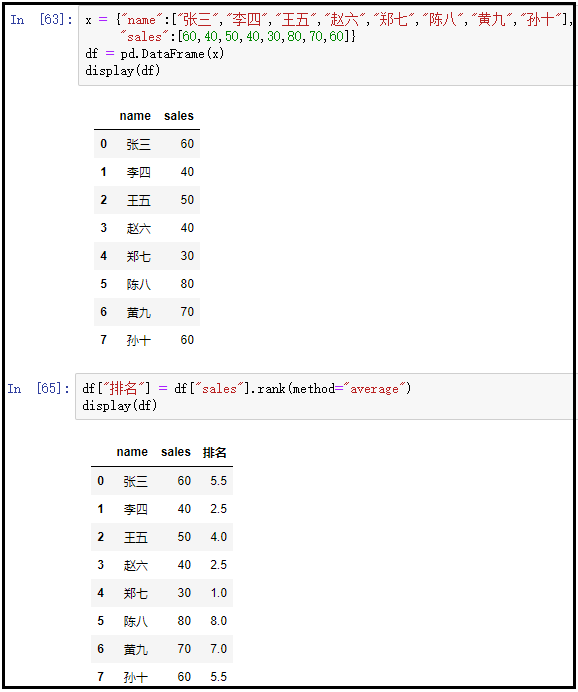
④ method=“average”
x = {
"name":["张三","李四","王五","赵六","郑七","陈八","黄九","孙十"],
"sales":[60,40,50,40,30,80,70,60]}
df = pd.DataFrame(x)
display(df)
df["排名"] = df["sales"].rank(method="average")
display(df)
结果如下:
智能推荐
在ubuntu 8.04下安装Oracle 11g二-程序员宅基地
文章浏览阅读408次。 在ubuntu 8.04下安装Oracle 11g2008年05月22日 星期四 11:02oracle 11g 数据库虽然提供了linux x86的版本,但是支持的linux版本只有Red Hat,Novell and Solaris 这几个,debian 和 ubuntu 不在支持之列,所以在ubuntu下安装就相对麻烦一些,请照着下文的方法一步一步的安装,不
初一计算机知识点下册,初一英语下册语法知识点全汇总-程序员宅基地
文章浏览阅读166次。新东方在线中考网整理了《初一英语下册语法知识点全汇总》,供同学们参考。一. 情态动词can的用法can+动词原形,它不随主语的人称和数而变化。1. 含有can的肯定句:主语+can+谓语动词的原形+其他。2. 含有can的否定句:主语+can't+动词的原形+其他。3. 变一般疑问句时,把can提前:Can+主语+动词原形+其他? 肯定回答:Yes,主语+can。否定回答:No,主语+can't...._七年级下册计算机知识点
NX/UG二次开发—其他—UFUN函数调用Grip程序_uf调用grip-程序员宅基地
文章浏览阅读3k次。在平时开发中,可能会遇到UFUN函数没有的功能,比如创建PTP的加工程序(我目前没找到,哪位大神可以指点一下),可以使用Grip创建PTP,然后用UFUN函数UF_call_grip调用Grip程序。具体如下截图(左侧UFUN,右侧Grip程序):..._uf调用grip
Android RatingBar的基本使用和自定义样式,kotlin中文教程_ratingbar样式修改-程序员宅基地
文章浏览阅读156次。第一个:原生普通样式(随着主题不同,样式会变)第二个:原生普通样式-小icon第三个:自定义RatingBar 颜色第四个:自定义RatingBar DrawableRatingBar 各样式实现===============原生样式原生样式其实没什么好说的,使用系统提供的style 即可<RatingBarstyle="?android:attr/ratingBarStyleIndicator"android:layout_width=“wrap_cont.._ratingbar样式修改
OpenGL环境搭建:vs2017+glfw3.2.1+glad4.5_vs2017的opengl环境搭建(完整篇)-程序员宅基地
文章浏览阅读4.6k次,点赞6次,收藏11次。安装vs2017:参考vs2017下载和安装。安装cmake3.12.3:cmake是一个工程文件生成工具。用户可以使用预定义好的cmake脚本,根据自己的选择(像是Visual Studio, Code::Blocks, Eclipse)生成不同IDE的工程文件。可以从它官方网站的下载页上获取。这里我选择的是Win32安装程序,如图所示:然后就是运行安装程序进行安装就行。配置glfw3...._vs2017的opengl环境搭建(完整篇)
在linux-4.19.78中使用UBIFS_ubifs warning-程序员宅基地
文章浏览阅读976次。MLC NAND,UBIFS_ubifs warning
随便推点
计算机系统内存储器介绍,计算机系统的两种存储器形式介绍-程序员宅基地
文章浏览阅读2.2k次。计算机系统的两种存储器形式介绍时间:2016-1-6计算机系统的存储器一般应包括两个部分;一个是包含在计算机主机中的主存储器,简称内存,它直接和运算器,控制器及输入输出设备联系,容量小,但存取速度快,一般只存放那些急需要处理的数据或正在运行的程序;另一个是包含在外设中的外存储器,简称外存,它间接和运算器,控制器联系,存取速度虽然慢,但存储容量大,是用来存放大量暂时还不用的数据和程序,一旦要用时,就..._计算机存储器系统采用的是主辅结构,主存速度快、容量相对较小,用于 1 分 程序,外
西门子PLC的编程工具是什么?_西门子plc编程软件-程序员宅基地
文章浏览阅读5.6k次。1. STEP 7(Simatic Manager):STEP 7或者Simatic Manager是西门子PLC编程最常用的软件开发环境。4. STEP 7 MicroWin:STEP 7 MicroWn是一款专门针对微型PLC(S7-200系列PLC)的编程软件,是Simatic Manager的简化版。如果需要与PLC系统配合使用,则需要与PLC编程工具进行配合使用。除了上述软件之外,西门子还提供了一些配套软件和工具,如PLC模拟器、硬件调试工具等,以帮助PLC编程人员快速地进行调试和测试。_西门子plc编程软件
HashMap扩容_hashma扩容-程序员宅基地
文章浏览阅读36次。【代码】HashMap扩容。_hashma扩容
Eclipse maven项目中依赖包不全,如何重新加载?_maven资源加载不全,怎么重新加载-程序员宅基地
文章浏览阅读2.9k次。1mvn dependency:copy-dependencies2 项目右键 -> Maven -> Disable Maven Nature3 项目右键 -> Configure -> Convert to Maven Project_maven资源加载不全,怎么重新加载
mysql dml全称中文_MySQL语言分类——DML-程序员宅基地
文章浏览阅读527次。DMLDML的全称是Database management Language,数据库管理语言。主要包括以下操作:insert、delete、update、optimize。本篇对其逐一介绍INSERT数据库表插入数据的方式:1、insert的完整语法:(做项目的过程中将字段名全写上,这样比较容易看懂)单条记录插入语法:insert into table_name (column_name1,......_dml的全称是
【小工匠聊Modbus】04-调试工具-程序员宅基地
文章浏览阅读136次。可以参考: http://git.oschina.net/jrain-group/ 组织下的Java Modbus支持库Modbus-系列文章1、虚拟成对串口(1)下载虚拟串口软件VSPD(可在百度中搜索)image.png(2)打开软件,添加虚拟串口。在设备管理中,看到如下表示添加成功。..._最好用的 modebus调试工具