Logistic回归算法_tensorflow 随机梯度上升-程序员宅基地
技术标签: 机器学习基础算法学习
基于Logistic回归和Sigmoid函数的分类
对于二分类问题,需要找到这样一个函数,他对任意给定的输入输出0或1,海维赛德阶跃函数符合这一特性,但其在跳跃点处很难处理,因此我们用其他函数来代替,本章所用的函数为sigmoid函数该函数的表达式及图像如下所示
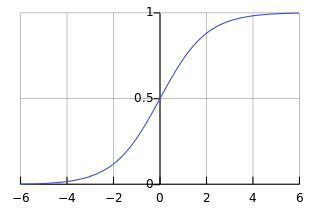
可以看到,当x趋于正无穷时,函数值趋近于1;当x趋于负无穷时,函数值趋近于0;
我们将输出大与0.5的归入1类,将输出小于0.5时归入0类。
假设输入数据的特征是(x0, x1, x2, …, xn),我们在每个特征上乘以一个回归系数 (w0, w1, w2, … , wn)
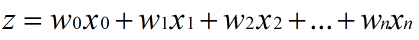
利用线性代数的知识,我们可以把式子简化为:
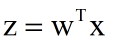
再将Z输入sigmoid函数就可以得到最终的值啦~
可以看到,式子中最重要的是要确定w(又称权重矩阵),那么应该怎么确定这个权重矩阵呢?
梯度上升法
梯度上升法的思想是:要找到某函数的最大值,最好的办法就是沿着该函数的梯度方向探寻。
梯度上升算法的公式如下,这里的f(w)为损失函数,关于损失函数的知识,可以参照吴恩达的机器学习视频或者网上的梯度上升算法的推导。损失函数代表了真实值与预测值之间的差异,我们对其求偏导即可得到权重矩阵的梯度,这里的alpha是学习率,学习率的选择是一项很大的学问,本章暂时给定学习率,只需知道选择合适的学习率是一个很重要的步骤,学习率太小会导致开销大,学习率太大会导致越来越偏离真实值。
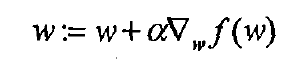
以下是梯度上升法的具体例子
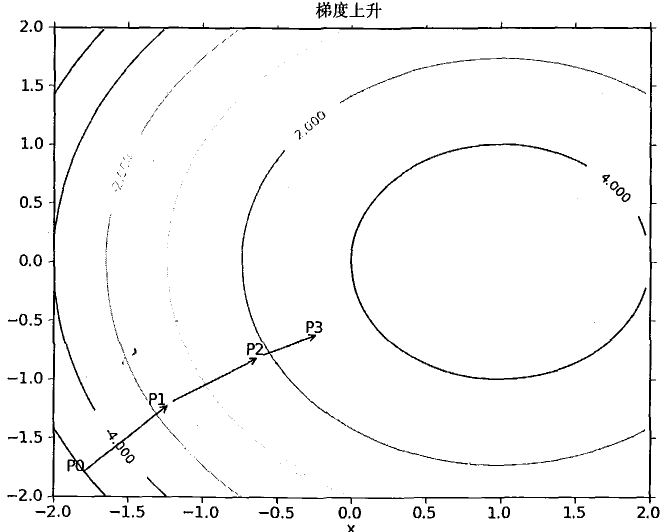
OK,有了理论支撑我们就可以开始写代码了
简单练习
作为练习,我们首先使用一个灰常简单的数据集
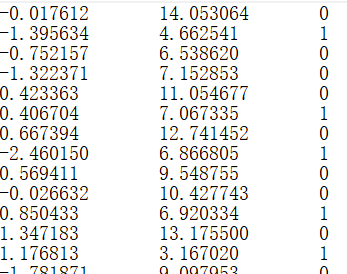
这是test.txt中的一小部分数据,可以看到数据有两个特征,最后有一个0,1的标签
先看一下我们需要导入的包,因为是从底层开始写,所以我们需要的特别简单(环境为python2.7)
from numpy import * ##实际不推荐这种写法
from math import exp
整个文档共有100个这样的数据,我们将其导入
def loaddataset():
datamat = []; labelmat = []
fr = open('testSet.txt')
for line in fr.readlines():
linearr = line.strip().split()
datamat.append([1.0,float(linearr[0]),float(linearr[1])])
labelmat.append(int(linearr[2]))
return datamat,labelmat
定义sigmoid函数
def sigmoid0(inX):
return 1.0/(1+exp(-inX))
然后写出梯度上升算法
"""未优化梯度上升算法"""
def gradascent(datamatin,classlabels):
datamatrix = mat(datamatin)
labelmat = mat(classlabels).transpose()
m,n = shape(datamatrix)
alpha = 0.001
maxcycles = 500
weights = ones((n,1))
for k in range(maxcycles):
h = sigmoid(datamatrix*weights)
error = (labelmat - h)
weights = weights + alpha*datamatrix.transpose()*error
plotbestfit(weights)
return weights
在运行之前,我们先对sigmoid函数做一个改写。可以看到传入sigmoid函数的参数dataamatrixweights是一个m1的矩阵,但是Python3.5并不支持用exp ()函数直接对矩阵进行操作。这一点书中并没有指出,算是一个勘误。以下给出风车自己的方法,这个方法有一点蠢,既然不支持直接对矩阵中的每个元素进行操作,那我们就先把它转换为numpy中的数组,然后用数组遍历的方法来进行每个元素的sigmoid操作,最后别忘记再把它转成矩阵。修改后的sigmoid()函数如下所示
"""求sigmoid"""
def sigmoid(data):
s = data.getA()
datatemp = [[ 1.0/(1+exp(-s[i][j])) for j in range(len(s[i]))]for i in range(len(s))]
datafinal = mat(datatemp)
return datafinal
好了,这就可以开始测试了
"""测试代码"""
dataarr,labelmat = loaddataset
print(gradascent(dataarr,labelmat))
输出如下:
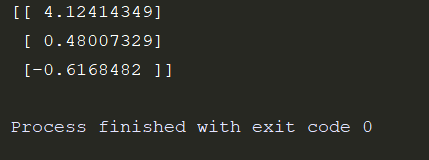
可以看到,我们的方法确实是有效的,但是写了这么久看到一行黑白的输出,是不是有些小失落,别急,我们来让这些数据可视化
绘制图形
这里直接给出代码,用到的只是一些基础的功能,搜索一下相关函数的功能很容易理解。风车也还在学进一步的图形绘制功能,一起加油~
"""画出决策边界"""
def plotbestfit(wei):
import matplotlib.pyplot as plt
weights = wei
datamat,labelmat = loaddataset()
dataarr = array(datamat)
n = shape(dataarr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelmat[i]) == 1:
xcord1.append(dataarr[i,1]);ycord1.append(dataarr[i,2])
else:
xcord2.append(dataarr[i,1]);ycord2.append(dataarr[i,2])
fig = plt.figure()
ax =fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x = arange(-3.0,3.0,0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x,y)
plt.xlabel('x1');plt.ylabel('x2');
plt.show()
我们在程序末尾加上
plotbestfit(gradascent(dataarr,labelmat))
运行得到如下图像
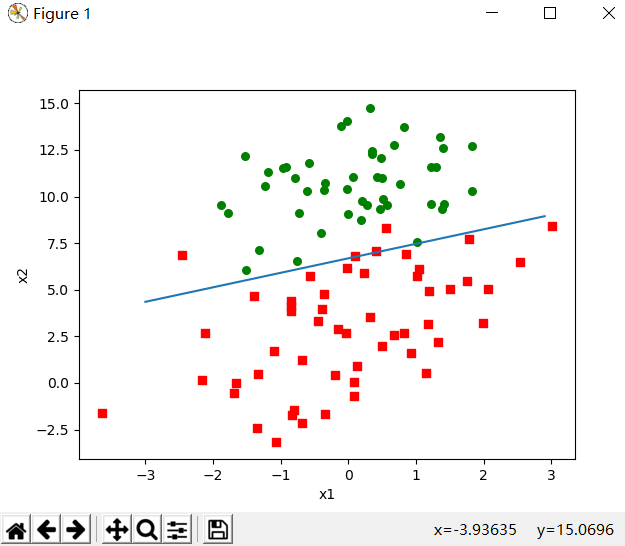
可以看到结果对数据的划分还是很令人满意的
随机梯度上升算法
梯度上升法给出的结果很棒,但其本身仍有有一定的不足。梯度上升算法在每次更新权重矩阵时都要便利整个数据集,我们给出的test.txt只有100个样例,但若是有数十亿个样本,那么这样的方式复杂度就太高了。因此我们有了随机梯度算法。随机梯度算法,顾名思义,每次随机的取一个值(为了方便,下面的样例按顺序取一个值)来对我们的权重矩阵进行更新。
随机梯度上升算法的代码如下
"""随机梯度上升算法"""
def stogradascent(datamatrix,classlabels,num=150):
m,n = shape(datamatrix)
weights = ones(n)
for j in range(num):
dataindex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001
randindex = int(random.uniform(0,len(dataindex)))
"""此处代码为自己修改"""
h = sigmoid0(sum(datamatrix[randindex]*weights))
"""sigmoid0()出现OverflowError:math range error"""
error = classlabels[randindex] - h
weights = weights + alpha * error * datamatrix[randindex]
del(dataindex[randindex])
return weights
这里的sigmoid0函数就是开头给出的
def sigmoid0(inX):
return 1.0/(1+exp(-inX))
这一次我们传入的值sum(datamatrix[randindex]weights)并不是一个矩阵,sum()函数内两个矩阵的大小分别为1n和n1,因此得到的是一个11的矩阵,我们用这个值来更新我们的权重矩阵weights。
最后输入测试代码
dataarr,labelmat = loaddataset()
weights = stogradascent(array(dataarr),labelmat)
plotbestfit(weights)
可以看到如下结果
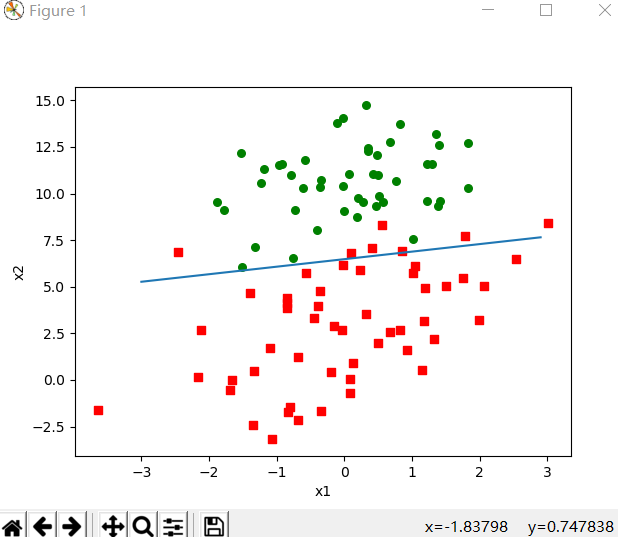
可以看到结果并没有梯度上升算法好,但这样的比较是不公平的,因为后者是在整个数据集上迭代了500次得到的,当然提升随机梯度算法的迭代次数num也能的到更好的结果。
小测试也做完了,这回来个实际应用吧!
从疝气病症预测病马的死亡率
给出的horseColicTraining.txt中每个样本有20个特征,并有一个标签,0代表未能存活,1代表可以存活。horseColicTest.txt作为测试集来判断我们训练出的模型的好坏。
话不多说,直接上代码
def classifyvector(inX,weights):
prob = sigmoid0(sum(inX*weights))
if prob > 0.5:return 1.0
else:return 0.0
def colicTest():
frTrain = open('horseColicTraining.txt')
frTest = open('horseColicTest.txt')
trainingSet = [];trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stogradascent(array(trainingSet),trainingLabels,1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr=[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyvector(array(lineArr),trainWeights)) != int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print("the error rata of this test is:%f" %errorRate)
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rata is:%f" %(numTests,errorSum/float(numTests)))
"""测试代码"""
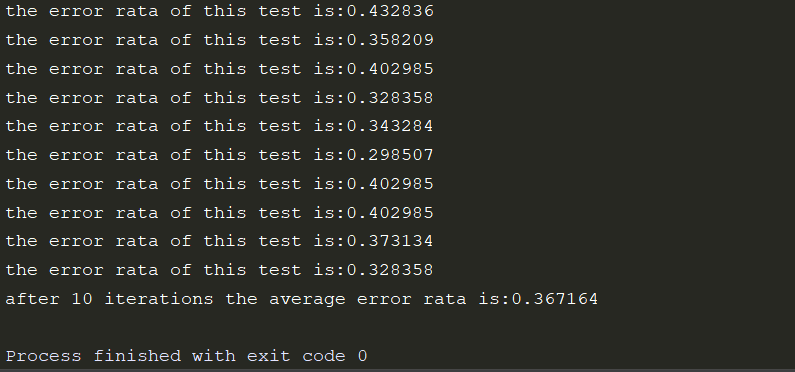
multiTest()
运行结果如下:
tensorflow实现
数据集
本次我们所使用的数据集,是MNIST数据集。MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集。它是NIST数据库的一个子集。其中每张图片固定大小为28281,最后的数字1表示一个通道,即灰度图。
我们首先导入一些必要的模块
import tensorflow as tf
import matplotlib.pyplot as plt
import input_data
mnist=input_data.read_data_sets("MNIST_data/",one_hot=True)
这里input_data.read_data_sets函数生成的类会自动将MNIST数据集划分为train,validation和test三个数据集,其中train中有55000张图片,validation集合内有5000张图片,这两个集合合起来就是MNIST的训练数据集。剩下的test集合中有10000张图片,这是MNIST的测试数据集。我们的每张图片将被处理成一个长度784(28281)一维数组。
解释一下one_hot,我们最后的分类有10个数字,我们采用二分类的模型,one_hot=True就是让其中的一个元素为1,其余元素为0,这样就将10分类简化为2分类啦~
我们可以打印MNIST数据集中的一张图片来看看效果
img = mnist.test.images[0]
image = img.reshape(28,28)
plt.imshow(image)
plt.show()
这里我们打印test数据集中的第一张图片,打印之前我们先通过reshape将其还原为一个28*28的像素矩阵,然后用matplotlib把他打印出来
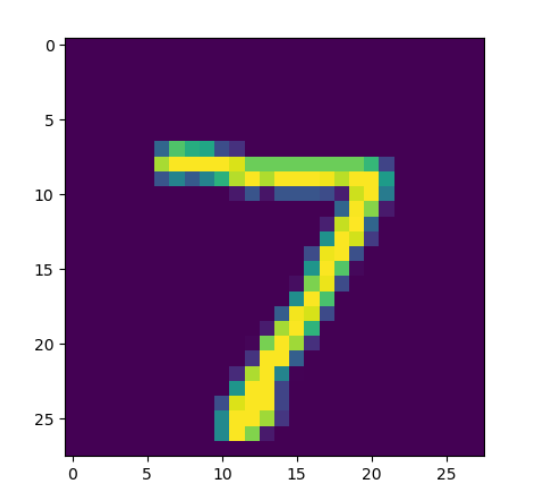
大概就是这个样子,但是其实际为一个灰度图,只有黑白两种颜色
实现SLogistic Regression
"""定义出一些参数"""
training_num = 20 #总共训练几轮
learning_rate = 0.01 #学习率
batch_size = 100 #每次取一部分图片,随机梯度上升
"""mnist Graph input"""
x = tf.placeholder("float",shape=[None,784])
y_ = tf.placeholder("float",shape=[None,10])
"""定义权重矩阵W和偏置b"""
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
"""softmax计算输出"""
y = tf.nn.softmax(tf.matmul(x,W) + b)
"""用交叉熵作为损失函数"""
cost = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices=1))
"""梯度下降优化器"""
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
我们定义了一些参数,这些参数在后面的过程中会用到,写在前面是为了在环境改变时能快速的做相应的调整。这里的reduce_sum根据函数名很容易知道是求和,而外面的的reduce_mean自然是求平均数,这里解释一下reduction_indices。这个参数表示函数处理的维度,若没有写则默认为None,即把输入的tensor降到0维,也就是一个数。
placeholder是一个占位符,在后面计算时需要给他相应的值。
创建Session
注意一定要有Session!!!不然上面所有的工作都只是创建了一个graph,实际并不做任何计算。我们需要用Session来计算图或图的一部分。
在开始之前还要对所有的变量进行初始化。
这里的batch_size每次取训练集中的一小部分,这样可以一定程度上增大最后到达全局最优的可能性,也相当于一个随机的梯度下降。我们用feed_dict将数据“喂给”前文所提到的占位符。
"""初始化所有变量"""
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
#训练20轮
for lun in range(training_num):
avg_cost = 0;
num = int(mnist.train.num_examples/batch_size)
for i in range(num):
batch = mnist.train.next_batch(batch_size)
c=sess.run([train_step,cost],feed_dict={
x:batch[0],y_:batch[1]})
avg_cost += c[1]/num
print("after %d training,the cost is %.9f" %(lun+1,avg_cost))
print("training over!")
"""测试其准确率"""
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print("Accuracy:",sess.run(accuracy, feed_dict={
x: mnist.test.images, y_: mnist.test.labels}))
准确率
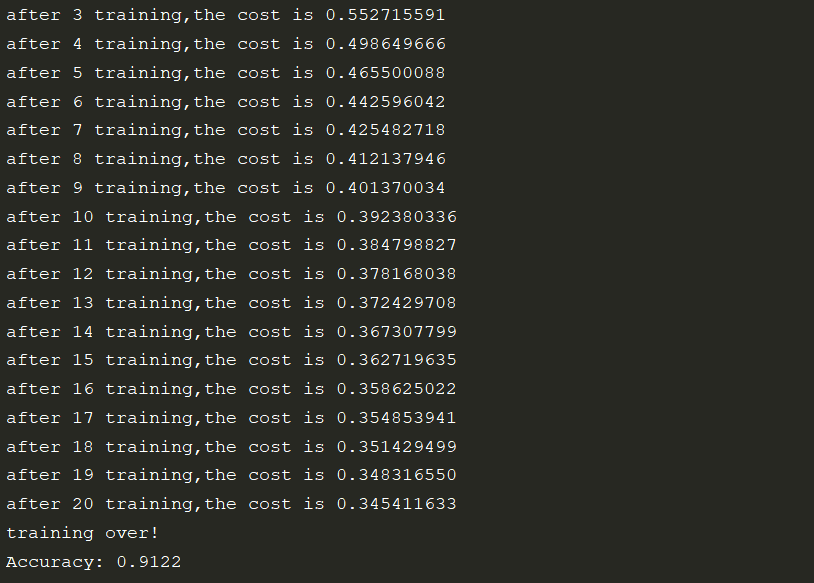
可以看到我们最后的准确率是91%左右,这个结果怎么样呢?很抱歉,91的准确率并不是很理想,不过也别灰心,这是我们的第一个算法,也是灰常灰常简单的一种,后面还有很多美妙神奇的算法等着我们去学习,加油吧,骚年!
风车是个渣渣,如果文章有什么错误,欢迎指出~
参考文献
周志华《机器学习》
李锐《机器学习实战》
智能推荐
CMake编译Nginx源码_cmake 编译 nginx-程序员宅基地
文章浏览阅读2k次。背景最近打算学习nginx源码,但使用clion IDE查看不支持跳转。因为源码是使用autotool维护的,而clion需要CMake管理项目。着手编译nginx源码。环境os : ubuntu 18.04nginx: nginx-1.16.1cmake: 3.10.2clion: 2019.2原生编译解压源码包后,执行configure命令。./configure --p..._cmake 编译 nginx
IDEA Missing package statement-程序员宅基地
文章浏览阅读1.6w次,点赞9次,收藏2次。如图所示,Demo1这个类名下面出现了红线,我完全是按照老师的文档来进行的,只有一个地方不一样我的模块里面本身没有.java文件,这个Demo1是我从别的地方搬过来的,只搬了Demo1.java导入包后先显示,没有配置相关的JDK,然后JDK配置完成后,就出现了这个问题。MIissng package statement / 缺少包语句https://blog.csdn.net/a_b..._missing package statement
beep.sys/Trojan.NtRootKit.1192,msplugplay 1005.sys/BackDoor.Pigeon.13201等2-程序员宅基地
文章浏览阅读249次。beep.sys/Trojan.NtRootKit.1192,msplugplay 1005.sys/BackDoor.Pigeon.13201等2endurer 原创2008-06-25 第1版(续1)先修正电脑日期,然后下载 DrWeb CureIt!扫描。同时下载 bat_do、FileInfo 提取文件信息,打包备份,延时删除。接着下载 瑞星卡卡安全助手清理恶意程序..._68d3795a-886f-46d0-977b-f0acd82c5966
清空Qtablewiget 表格的内容_tableweight 清空-程序员宅基地
文章浏览阅读3.2k次。 void QTableWidget::clear () [slot]//清空掉表格内所有内容,包括标题头Removes all items in the view. This will also remove all selections. The table dimensions stay the same. void QTableWidget::clearContents (..._tableweight 清空
Vim 插键及配置-程序员宅基地
文章浏览阅读99次。如果你觉得这个页面广告太多,欢迎移步博客阅读:Vim 插键及配置编辑器之神 —— Vim平日使用vim经常编辑文件,想想使用时的痛点,决定研究一下插件的使用。Vim的扩展通常也被成为bundle或插件。软件版本:Mac OS X 10.14.1vim 8.1插件安装-Vundle众多文章中都提到Vundle,那我就选用它好了!有一个 Vim 的插键网站,专门有相关插键的..._vim里的配置文件插入按键
多元回归预测 | Matlab基于卷积神经网络-门控循环单元CNN-GRU的Adaboost回归预测_适用回归的神经网络有哪些-程序员宅基地
文章浏览阅读1k次,点赞28次,收藏13次。卷积神经网络 (CNN) 和门控循环单元 (GRU) 是两种常用的深度学习模型,它们在图像识别和自然语言处理等领域取得了显著的成果。然而,对于一些特定的预测问题,单独使用这两种模型可能无法达到理想的效果。因此,本文将介绍一种基于Adaboost回归的预测算法,将CNN和GRU进行有效地融合,以提高预测的准确性。首先,让我们简要回顾一下CNN和GRU的基本原理。CNN是一种专门用于处理图像数据的神经网络模型,它通过卷积操作和池化操作来提取图像中的特征,并通过多层神经网络进行分类或回归预测。_适用回归的神经网络有哪些
随便推点
【应用】Docker-多容器部署Django+Vue项目(nginx+uwsgi+mysql)_容器 安装 vue-程序员宅基地
文章浏览阅读1.5k次,点赞27次,收藏28次。基于Linux CentOS 7系统(虚拟机),使用Docker,多容器部署Django+Vue项目整体部署用到了:Django+Vue+nginx+mysql+uwsgi先每一个容器单独部署,最后用Docker compose 语法整合,统一部署总结梳理放在前边,方便整体理解写项目部署步骤的时候,总有步骤”想当然“而没有展示出来。本文已尽可能展示所有的修改动作,希望文章对你有所帮助。至此,三个容器都已成功启动,可以在客户端用浏览器访问项目,并进行操作,来验证是否能够成功交互。_容器 安装 vue
在Spring boot中加入web.xml_springboot项目加载web.xml文件-程序员宅基地
文章浏览阅读5.1w次,点赞2次,收藏23次。公司有个项目,有两个子项目,两个独立的工程,我们组用的Spring boot,没有web.xml的,另一个项目组是用的liferay,有liferay6定制的tomcat7,做到中后期,客户说要放在一个tomcat里面,但是spring boot的war包放在liferay的tomcat下报错,特么只好去找怎么在spring boot里面搞个web.xml。。。先在java/webapp/WEB-_springboot项目加载web.xml文件
机器学习之常见机器学习算法---面试之常见机器学习算法简单思想梳理-程序员宅基地
文章浏览阅读109次。 前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考虑该岗位,毕竟在机器智能没达到人类水平之前,机器学习可以作为一种重要手段,而随着科技的不断发展,相信这方面的人才需求也会越来越大。 纵观IT行业的招聘岗位,机器学习之类..._你最喜欢的一个机器学习算法是哪个? (1)试简述它的训练过程。 (2)说说为什么
分布式基础,通俗易懂CAP?-程序员宅基地
文章浏览阅读48次。分布式系统非常关注三个指标:● 数据一致性● 系统可用性● 节点连通性与扩展性关于一致性数据“强一致性”,是希望系统只读到最新写入的数据,例如:通过单点串行化的方式,就能够达到这个效果。关于session一致性,DB主从一致性,DB双主一致性,DB与Cache一致性,数据冗余一致性,消息时序一致性,分布式事务一致性,库存扣减一致性,详...
机器视觉相机镜头光源选型_视觉选型工具-程序员宅基地
文章浏览阅读582次。镜头选型工具 - HiTools - 海康威视 Hikvision。_视觉选型工具
java 毛笔字,Photoshop设计唯美大气的毛笔字-程序员宅基地
文章浏览阅读248次。用PS快速实现毛笔字设计技巧,既然书法写得不好,那就通过设计来让它完美呈现,这种方法是个人常用的方法,也是立竿见影的实用技巧,希望大家喜欢与支持。既然毛笔字写得丑的已是事实,但我们有办法改变这个事实,就是通过设计来现实,别说这个想法万一能实现了呢,现在就是一万个肯定能现实。毛笔字的设计有很多种方法,这次以自己常用的而且是快速能出效果的方法分享给大家,希望大家喜欢,也希望大家支持。先看一下效果,如下..._java小毛笔