以下用于数据存储领域的python第三方库是-『爬虫四步走』手把手教你使用Python抓取并存储网页数据!...-程序员宅基地
第一步:尝试请求
首先进入b站首页,点击排行榜并复制链接
https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3
现在启动Jupyter notebook,并运行以下代码
import requests
url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了下面三件事
导入
requests
使用
get方法构造请求
使用
status_code获取网页状态码
可以看到返回值是200,表示服务器正常响应,这意味着我们可以继续进行。
第二步:解析页面
在上一步我们通过requests向网站请求数据后,成功得到一个包含服务器资源的Response对象,现在我们可以使用.text来查看其内容

可以看到返回一个字符串,里面有我们需要的热榜视频数据,但是直接从字符串中提取内容是比较复杂且低效的,因此我们需要对其进行解析,将字符串转换为网页结构化数据,这样可以很方便地查找HTML标签以及其中的属性和内容。
在Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解.
Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单,使用pip install bs4安装即可,下面让我们用一个简单的例子说明它是怎样工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象,注意在使用时需要制定一个解析器,这里使用的是html.parser。
接着就可以获取其中的某个结构化元素及其属性,比如使用soup.title.text获取页面标题,同样可以使用soup.body、soup.p等获取任意需要的元素。
第三步:提取内容
在上面两步中,我们分别使用requests向网页请求数据并使用bs4解析页面,现在来到最关键的步骤:如何从解析完的页面中提取需要的内容。
在Beautiful Soup中,我们可以使用find/find_all来定位元素,但我更习惯使用CSS选择器.select,因为可以像使用CSS选择元素一样向下访问DOM树。
现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据,首先我们需要找到存储数据的标签,在榜单页面按下F12并按照下图指示找到
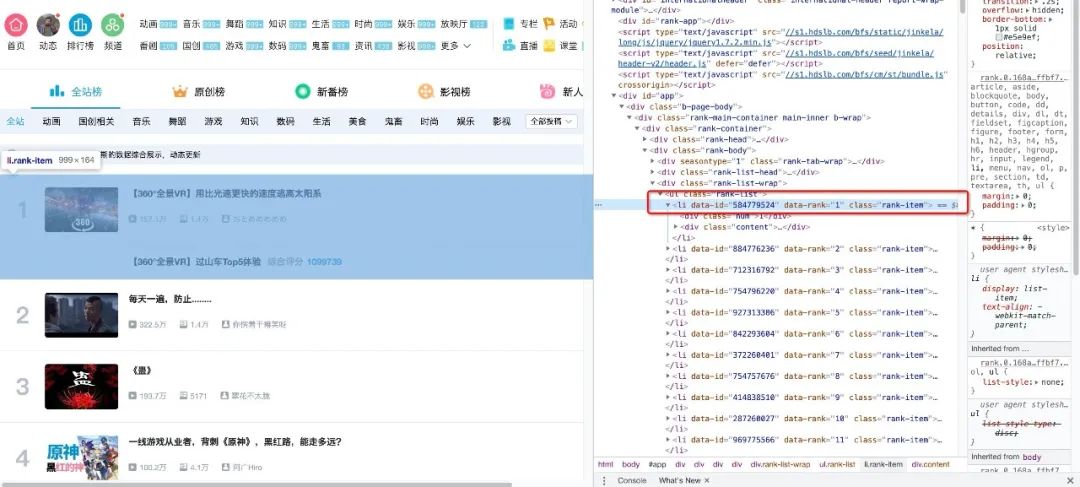
可以看到每一个视频信息都被包在class="rank-item"的li标签下,那么代码就可以这样写�
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们先使用soup.select('li.rank-item'),此时返回一个list包含每一个视频信息,接着遍历每一个视频信息,依旧使用CSS选择器来提取我们要的字段信息,并以字典的形式存储在开头定义好的空列表中。
可以注意到我用了多种选择方法提取去元素,这也是select方法的灵活之处,感兴趣的读者可以进一步自行研究。
第四步:存储数据
通过前面三步,我们成功的使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel中保存即可。
如果你对pandas不熟悉的话,可以使用csv模块写入,需要注意的是设置好编码encoding='utf-8-sig',否则会出现中文乱码的问题
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas的话,更是可以轻松将字典转换为DataFrame,一行代码即可完成
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
小结
至此我们就成功使用Python将b站热门视频榜单数据存储至本地,大多数基于requests的爬虫基本都按照上面四步进行。
不过虽然看上去简单,但是在真实场景中每一步都没有那么轻松,从请求数据开始目标网站就有多种形式的反爬、加密,到后面解析、提取甚至存储数据都有很多需要进一步探索、学习。
本文选择B站视频热榜也正是因为它足够简单,希望通过这个案例让大家明白爬虫的基本流程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
智能推荐
内存卡选购指南_tf卡三围-程序员宅基地
文章浏览阅读331次。TF卡也叫Micro SD卡。也就是小型SD卡。SD卡的三围大概是24mm3*2mm*2.1mm.而TF卡体积缩小到15mm*11mm*1mm.这里华为还推出了更小体积的NM存储卡,比TF卡更小。可以直接放在SIM卡里使用。但价格比较高。:最常用的存储卡设备。体积小,被广泛地于使用便携式装置上,例例如数码相机、平板电脑和多媒体播放器MP3,MP4,行车记录仪等。:主要用于相机等拍摄设备。体积比SD卡大,但安全性和稳定性传输速度上更高。当然价格也更高。_tf卡三围
Mybatis 与Mybatis-plus同时引入同一个项目中配置方法_mybatisplus和mybatis可以一起导入吗-程序员宅基地
文章浏览阅读8.1k次,点赞5次,收藏31次。原项目系统中已经引入了 Mybatis 和 pagehelper ,当引入Mybatis-plus 后启动项目报错 SqlSessionFactory 错误,排查原因后为依赖冲突导致,需排除部分jar包,并修改相关配置。5. 修改配置文件,将原 mybatis 改成 mybatis-plus。根据自己xml的实际路径修改。4.引入autoconfigure。3.引入Mybatis-plus。2. pagehelper 中。1.mybatis中。_mybatisplus和mybatis可以一起导入吗
Windows磁盘管理工具DiskPart创建VHD以及虚拟磁盘的挂载及盘符分配_vhd工具-程序员宅基地
文章浏览阅读2.3k次。使用diskpart磁盘工具创建VHD虚拟磁盘以及磁盘的挂载、格式化及驱动器盘符分配。_vhd工具
Qt Data Visualization_shadows are not yet supported for opengl es2-程序员宅基地
文章浏览阅读501次。Qt Data Visualization 专栏链接地址:Qt Data Visualization 3D可视化https://blog.csdn.net/qq_36583051/article/details/107627747Q3DBarshttps://blog.csdn.net/qq_36583051/article/details/107790125_shadows are not yet supported for opengl es2
python中keys返回什么类型_dict.viewkeys()返回的数据类型是什么?[Python2.7]-程序员宅基地
文章浏览阅读2.5k次。如果进入外壳:print type(dct.viewkeys())它将返回:dict_keys是一个Dictionary view对象,在Python 2.7中是新的。从PEP 3106:The dictionary methods keys(), values(), and items() are different in Python 3.x. They return an object ca..._dict.viewkeys方法
学堂在线Java程序设计编程题第一章节_学堂在线java程序设计清华大学 编程题答案-程序员宅基地
文章浏览阅读994次。字符串排序:用Java编写一个能对一组字符串按字典序升序排序的程序 输入为N和N行字符串,需要按行输出字符串升序排序的结果输入:3 Abc Abe Abd输出:Abc Abd Abeimport java.io.*;import java.util.*;import java.math.*;public class Main { public stati..._学堂在线java程序设计清华大学 编程题答案
随便推点
4.1uboot对设备树的支持——传递dtb给内核_uboot设备树和内核设备树-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏29次。本节讲述怎么把设备树(dtb)传给内核。uboot只要,然后在时,把这块内存的传给内核(通过寄存器)。_uboot设备树和内核设备树
echarts动态生成图片绘制在地图上,同时实现图片的点击事件_echarts地图上面贴图怎么让他触发下面的事件-程序员宅基地
文章浏览阅读2.7k次。**项目需求:**根据后台数据,生成pie,并绘制在地图上,点击pie时实现点击事件。一开始在div内生成echarts饼图,再通过经纬度将div放在指定位置,但是div的范围内地图自身的滚轮和双击事件失效,几经周折,找到了另一种解决方案:将div内的echarts饼图以图片的形式输出,隐藏掉当前div,再将图片通过经纬度绘制在地图上。当点击时,通过hitTest()判断是点击在地图上还是图片上..._echarts地图上面贴图怎么让他触发下面的事件
c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
文章浏览阅读186次。该系统基于C语言,运用了指针、结构体和文件读写等技术路线实现了一些功能:包括(输入学生数据,修改学生数据,查找学生资料,排列学生数据,保存学生成绩,调出学生成绩,显示学生资料等7个功能)1、首先,定义学生结构体:typedef struct Link{int number;char name[10];char sex[4];int Chinese;int English;int Match;..._goto endp
计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
文章浏览阅读4.7k次。网络应用的需求与传输层服务网络应用对传输服务的需求:数据丢失/可靠性某些网络应用能够容忍一定的数据丢失:网络电话某些网络应用要求百分之百可靠的数据传输:文件传输,telnet时间延迟有些应用只有在延迟足够低时才有效网络电话/网络游戏带宽:某些应用只是有在带宽达到最低要求时才有效:网络视频某些应用能够适应任何带宽-------弹性应用:eamilInternet提供的传输服务TCP服务:面向连接:客户机/服务器进程间需要建立连接可靠传输流量控制:发送方不会发送速度过快,超过接收_应用对网络需求
BEVFusion论文解读-程序员宅基地
文章浏览阅读2.3k次。本文将介绍MIT韩松课题组在自动驾驶方面的最新工作,他们提出了一种高效且通用的多任务多传感器融合框架BEVFusion。它统一了共享鸟瞰(BEV)表示空间中的多模态特征,很好地保留了几何信息和语义信息。_bevfusion
multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
文章浏览阅读1.7k次。实验一:单机放大器附件:实验前准备工作共发射极放大电路的分析与综合 一、电路原理图二、直流分析如图,β=2002. 欲使UCQ=6V,求:Pot1URc?Vcc?UCQ?12V?6V?6VICQ?ICQURc?1.176mA RCIBQ???5.882?AUCEQ?Vcc?IEQ?Re1?Re2??ICQR3?VCC?ICQ(R3?Re1?Re2)?4.68V UB?UBE?IEQ(Re1?Re2...