MTCNN(三)基于python代码的网络结构更改_更改点云模型网络结构python-程序员宅基地
背景:MTCNN的训练是在python上实现的,我们需要对其结构进行更改。
目的:读懂MTCNN的python代码。
目录
2.2.1 pnet = PNet({'data': image_pnet}, mode='test')
2.2.2 out_tensor_pnet = pnet.get_all_output()
4.2 wd=self.weight_decay_coeff
一、代码结构
1.1 tensorflow设置与设备设置
import os
os.environ['CUDA_VISIBLE_DEVICES']='1'
...
file_paths = get_model_filenames(args.model_dir)
with tf.device('/gpu:0'):
with tf.Graph().as_default():
config = tf.ConfigProto(allow_soft_placement=True)
with tf.Session(config=config) as sess:注意,关于GPU的device是在os.environ['CUDA_VISIBLE_DEVICES']='1'后面这个变量来更改的,而不是后面的with tf.device('/gpu:0'):,这个需要后面查找什么意思。
1.2 设置placeholder与out_tensor
image_pnet = tf.placeholder(
tf.float32, [None, None, None, 3])
pnet = PNet({'data': image_pnet}, mode='test')
out_tensor_pnet = pnet.get_all_output()
image_rnet = tf.placeholder(tf.float32, [None, 24, 24, 3])
rnet = RNet({'data': image_rnet}, mode='test')
out_tensor_rnet = rnet.get_all_output()
image_onet = tf.placeholder(tf.float32, [None, 48, 48, 3])
onet = ONet({'data': image_onet}, mode='test')
out_tensor_onet = onet.get_all_output()1.3 网络saver
saver_pnet = tf.train.Saver(
[v for v in tf.global_variables()
if v.name[0:5] == "pnet/"])
saver_rnet = tf.train.Saver(
[v for v in tf.global_variables()
if v.name[0:5] == "rnet/"])
saver_onet = tf.train.Saver(
[v for v in tf.global_variables()
if v.name[0:5] == "onet/"])
saver_pnet.restore(sess, file_paths[0])1.4 定义相应的网络fun
def pnet_fun(img): return sess.run(
out_tensor_pnet, feed_dict={image_pnet: img})
saver_rnet.restore(sess, file_paths[1])
def rnet_fun(img): return sess.run(
out_tensor_rnet, feed_dict={image_rnet: img})
saver_onet.restore(sess, file_paths[2])
def onet_fun(img): return sess.run(
out_tensor_onet, feed_dict={image_onet: img})1.5 用detect_face函数给出备选框
rectangles, points = detect_face(img, args.minsize,
pnet_fun, rnet_fun, onet_fun,
args.threshold, args.factor)
二、placeholder与out_tensor
2.1 tf.placeholder
tf.placeholder(dtype, shape=None, name=None)
placeholder,占位符,在tensorflow中类似于函数参数,运行时必须传入值。
image_pnet = tf.placeholder(tf.float32, [None, None, None, 3])意思就是类型为float32类型,四维的数组,最后一个维度为3。
image_rnet = tf.placeholder(tf.float32, [None, 24, 24, 3])
image_onet = tf.placeholder(tf.float32, [None, 48, 48, 3])
根据向量可以看出分别是12,24与48,但是第一层仅仅是在训练的时候用12*12来训练,所以维度为None
2.2 PNet,RNet,ONet
引入在from src.mtcnn import PNet, RNet, ONet
2.2.1 pnet = PNet({'data': image_pnet}, mode='test')
定义在src/mtcnn.py之中
#src/mtcnn.py
class PNet(NetWork):
def setup(self, task='data', reuse=False):
...
if self.mode == 'train':
...
else
...
self.out_put.append(self.get_output())pnet是具体化的PNet,其中的'data'对应于image_pnet,其中的mode对应于'train'的else
2.2.2 out_tensor_pnet = pnet.get_all_output()
#src/mtcnn.py
class NetWork(object):
...
def get_all_output(self):
return self.out_put
...
def get_output(self):
return self.terminals[-1]self.output是最终定义完网络结构之后的最终的输出。
针对Pnet,输入为image_pnet,输出为out_tensor_pnet
三、tf.train.saver模型的保存与恢复
https://www.cnblogs.com/denny402/p/6940134.html
https://blog.csdn.net/index20001/article/details/74322198
四、网络的结构定义

Pnet原始结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 12*12*3 |
conv1 prelu1 |
3*3*10 |
1 |
Valid |
| 10*10*10 |
pool1 | Maxpool 2*2 |
2 |
Same |
| 5*5*10 |
conv2 prelu2 |
3*3*16 |
1 |
Valid |
| 3*3*16 |
conv3 prelu3 |
3*3*32 |
1 |
Valid |
| 1*1*32 |
|
|
|
Pnet改进结构
| Feature size |
Kernel size |
Stride |
Padding |
| 12*12*3 |
3*3*10 |
1 |
Valid |
| 10*10*10 |
3*3*10 |
2 |
Same |
| 5*5*10 |
3*3*16 |
1 |
Valid |
| 3*3*16 |
3*3*32 |
1 |
Valid |
| 1*1*32 |
|
|
|
Pnet理想结构
| Feature size |
Kernel size |
Stride |
Padding |
| 12*12*3 |
3*3*10 |
1 |
same |
| 12*12*10 |
3*3*10 |
2 |
Same |
| 6*6*10 |
3*3*16 |
2 |
same |
| 3*3*16 |
3*3*32 |
1 |
same |
| 1*1*32 |
|
|
Pnet 最终结构
只有3×3的卷积(为保证输出的得分图与输入的映射,需要same与valid)
| Feature size |
name | Kernel size |
Stride |
Padding |
| 12*12*3 |
conv1 prelu1 |
3*3*10 |
1 |
Valid |
| 10*10*10 |
pool1_conv1 pool1_prelu1 |
3*3*16 |
2 |
Same |
| 5*5*16 |
conv2 prelu2 |
3*3*32 |
1 |
Valid |
| 3*3*32 |
conv3 prelu3 |
3*3*32 |
1 |
Valid |
| 1*1*32 |
|
|
|
注意!代码更改之后stride也变了,所以需要更改tools之中的generateBoundingBox的stride的尺度,及关于stride的映射。
最终训练结构:
<tf.Variable 'pnet/conv1/weights:0' shape=(3, 3, 3, 10) dtype=float32_ref>
<tf.Variable 'pnet/conv1/biases:0' shape=(10,) dtype=float32_ref>
<tf.Variable 'pnet/PReLU1/alpha:0' shape=(10,) dtype=float32_ref>
<tf.Variable 'pnet/pool1_conv1/weights:0' shape=(3, 3, 10, 16) dtype=float32_ref>
<tf.Variable 'pnet/pool1_conv1/biases:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'pnet/pool1_PReLU1/alpha:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'pnet/conv2/weights:0' shape=(3, 3, 16, 32) dtype=float32_ref>
<tf.Variable 'pnet/conv2/biases:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'pnet/PReLU2/alpha:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'pnet/conv3/weights:0' shape=(3, 3, 32, 32) dtype=float32_ref>
<tf.Variable 'pnet/conv3/biases:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'pnet/PReLU3/alpha:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'pnet/conv4-1/weights:0' shape=(1, 1, 32, 2) dtype=float32_ref>
<tf.Variable 'pnet/conv4-1/biases:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'pnet/conv4-2/weights:0' shape=(1, 1, 32, 4) dtype=float32_ref>
<tf.Variable 'pnet/conv4-2/biases:0' shape=(4,) dtype=float32_ref>
<tf.Variable 'pnet/conv4-3/weights:0' shape=(1, 1, 32, 10) dtype=float32_ref>
<tf.Variable 'pnet/conv4-3/biases:0' shape=(10,) dtype=float32_ref>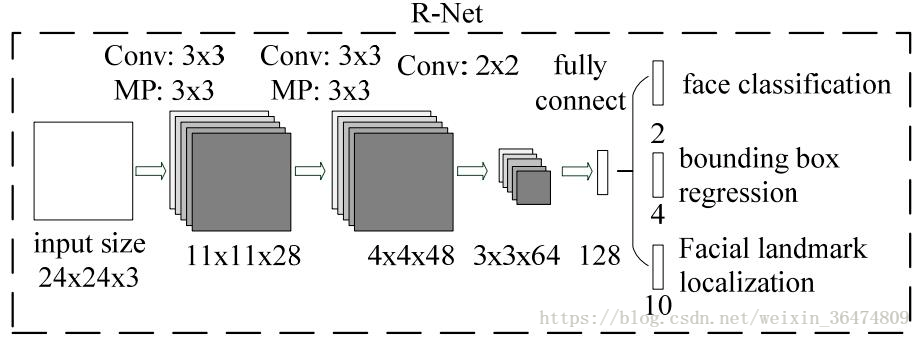
Rnet原始结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 24*24*3 |
conv1 prelu1 |
3*3*28 |
1 |
Valid |
| 22*22*28 |
pool1 | maxPool 3*3 |
2 |
Same |
| 11*11*28 |
conv2 prelu2 |
3*3*48 |
1 |
Valid |
| 9*9*48 |
pool2 | maxPool 3*3 |
2 |
valid |
| 4*4*48 |
conv3 prelu3 |
2*2*64 |
1 |
Valid |
| 3*3*64 |
|
|
|
Rnet改进结构
| Feature size |
Kernel size |
Stride |
Padding |
| 24*24*3 |
3*3*28 |
1 |
Valid |
| 22*22*28 |
3*3*28 |
2 |
Same |
| 11*11*28 |
3*3*48 |
1 |
Valid |
| 9*9*48 |
3*3*48 |
2 |
same |
| 5*5*48 |
3*3*64 |
1 |
valid |
| 3*3*64 |
|
|
|
Rnet最终结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 24*24*3 |
conv1 prelu1 |
3*3*28 |
1 |
Same |
| 24*24*28 |
pool1_conv1 pool1_prelu1 |
3*3*28 | 2 | Same |
| 12*12*28 | conv2 prelu2 |
3*3*48 | 1 | Same |
| 12*12*48 | pool2_conv3 poo2_prelu3 |
3*3*48 | 2 | Same |
| 6*6*48 | conv3 prelu3 |
3*3*64 | 2 | Same |
| 3*3*64 |
|
|
最终训练结构:
all trainable variables:
<tf.Variable 'rnet/conv1/weights:0' shape=(3, 3, 3, 28) dtype=float32_ref>
<tf.Variable 'rnet/conv1/biases:0' shape=(28,) dtype=float32_ref>
<tf.Variable 'rnet/prelu1/alpha:0' shape=(28,) dtype=float32_ref>
<tf.Variable 'rnet/pool1_conv1/weights:0' shape=(3, 3, 28, 28) dtype=float32_ref>
<tf.Variable 'rnet/pool1_conv1/biases:0' shape=(28,) dtype=float32_ref>
<tf.Variable 'rnet/pool1_prelu1/alpha:0' shape=(28,) dtype=float32_ref>
<tf.Variable 'rnet/conv2/weights:0' shape=(3, 3, 28, 48) dtype=float32_ref>
<tf.Variable 'rnet/conv2/biases:0' shape=(48,) dtype=float32_ref>
<tf.Variable 'rnet/prelu2/alpha:0' shape=(48,) dtype=float32_ref>
<tf.Variable 'rnet/pool2_conv3/weights:0' shape=(3, 3, 48, 48) dtype=float32_ref>
<tf.Variable 'rnet/pool2_conv3/biases:0' shape=(48,) dtype=float32_ref>
<tf.Variable 'rnet/poo2_prelu3/alpha:0' shape=(48,) dtype=float32_ref>
<tf.Variable 'rnet/conv3/weights:0' shape=(3, 3, 48, 64) dtype=float32_ref>
<tf.Variable 'rnet/conv3/biases:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'rnet/prelu3/alpha:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'rnet/conv4/weights:0' shape=(576, 128) dtype=float32_ref>
<tf.Variable 'rnet/conv4/biases:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'rnet/prelu4/alpha:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'rnet/conv5-1/weights:0' shape=(128, 2) dtype=float32_ref>
<tf.Variable 'rnet/conv5-1/biases:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'rnet/conv5-2/weights:0' shape=(128, 4) dtype=float32_ref>
<tf.Variable 'rnet/conv5-2/biases:0' shape=(4,) dtype=float32_ref>
<tf.Variable 'rnet/conv5-3/weights:0' shape=(128, 10) dtype=float32_ref>
<tf.Variable 'rnet/conv5-3/biases:0' shape=(10,) dtype=float32_ref>
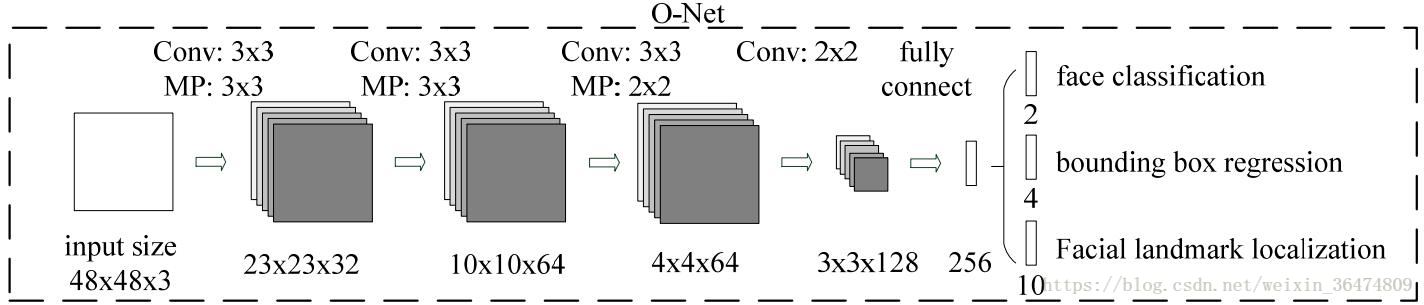
Onet原始结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 48*48*3 |
conv1 prelu1 |
3*3*32 |
1 |
Valid |
| 46*46*32 |
pool1 | maxPool 3*3 |
2 |
Same |
| 23*23*32 |
conv2 prelu2 |
3*3*64 |
1 |
Valid |
| 21*21*64 |
pool2 | maxPool 3*3 |
2 |
valid |
| 10*10*64 |
conv3 prelu3 |
3*3*64 |
1 |
Valid |
| 8*8*64 |
pool3 | maxPool 2*2 | 2 |
Same |
| 4*4*64 | conv4 prelu4 |
2*2*128 | 1 | valid |
| 3*3*128 |
Onet最终采用结构
因其参数量较小,最终采用 (mAP=58.58%)?
| Feature size |
name | Kernel size |
Stride |
Padding |
| 48*48*3 |
conv1 prelu1 |
3*3*32 |
1 |
Same |
| 48*48*32 | conv2 prelu2 |
3*3*32 | 2 |
Same |
| 24*24*32 |
conv3 prelu3 |
3*3*64 | 1 |
Same |
| 24*24*64 |
conv4_ prelu4_ |
3*3*64 | 2 |
Same |
| 12*12*64 |
conv5_ prelu5_ |
3*3*128 | 2 |
Same |
| 6*6*128 |
conv6_ prelu6_ |
3*3*128 | 2 |
Same |
| 3*3*128 |
<tf.Variable 'onet/conv1/weights:0' shape=(3, 3, 3, 32) dtype=float32_ref>
<tf.Variable 'onet/conv1/biases:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'onet/prelu1/alpha:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'onet/conv2/weights:0' shape=(3, 3, 32, 32) dtype=float32_ref>
<tf.Variable 'onet/conv2/biases:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'onet/prelu2/alpha:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'onet/conv3/weights:0' shape=(3, 3, 32, 64) dtype=float32_ref>
<tf.Variable 'onet/conv3/biases:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'onet/prelu3/alpha:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'onet/conv4_/weights:0' shape=(3, 3, 64, 64) dtype=float32_ref>
<tf.Variable 'onet/conv4_/biases:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'onet/prelu4_/alpha:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'onet/conv5_/weights:0' shape=(3, 3, 64, 128) dtype=float32_ref>
<tf.Variable 'onet/conv5_/biases:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/prelu5_/alpha:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/conv6_/weights:0' shape=(3, 3, 128, 128) dtype=float32_ref>
<tf.Variable 'onet/conv6_/biases:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/prelu6_/alpha:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/conv5/weights:0' shape=(1152, 256) dtype=float32_ref>
<tf.Variable 'onet/conv5/biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/prelu5/alpha:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/conv6-1/weights:0' shape=(256, 2) dtype=float32_ref>
<tf.Variable 'onet/conv6-1/biases:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'onet/conv6-2/weights:0' shape=(256, 4) dtype=float32_ref>
<tf.Variable 'onet/conv6-2/biases:0' shape=(4,) dtype=float32_ref>
<tf.Variable 'onet/conv6-3/weights:0' shape=(256, 10) dtype=float32_ref>
<tf.Variable 'onet/conv6-3/biases:0' shape=(10,) dtype=float32_ref>
Onet改进结构,只有same的3×3卷积,增加参数量可以增加mAP=59.85%
| Feature size |
Kernel size |
Stride |
Padding |
| 48*48*3 |
3*3*32 |
1 |
Same |
| 48*48*32 |
3*3*64 |
2 |
Same |
| 24*24*64 |
3*3*64 |
1 |
Same |
| 24*24*64 |
3*3*128 |
2 |
Same |
| 12*12*128 |
3*3*256 |
2 |
Same |
| 6*6*256 |
3*3*128 |
2 |
Same |
| 3*3*128 |
Onet layer 8层卷积结构,只有same的3×3卷积mAP=64.19%
| Feature size |
Kernel size |
Stride |
Padding |
| 48*48*3 |
3*3*32 |
1 |
Same |
| 48*48*32 |
3*3*64 |
2 |
Same |
| 24*24*64 |
3*3*128 |
1 |
Same |
| 24*24*128 |
3*3*256 |
2 |
Same |
| 12*12*256 | 3*3*256 | 1 | Same |
| 12*12*256 | 3*3*256 | 1 | Same |
| 12*12*256 |
3*3*256 |
2 |
Same |
| 6*6*256 |
3*3*128 |
2 |
Same |
| 3*3*128 |
最终训练参数
<tf.Variable 'onet/conv1/weights:0' shape=(3, 3, 3, 32) dtype=float32_ref>
<tf.Variable 'onet/conv1/biases:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'onet/prelu1/alpha:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'onet/conv2/weights:0' shape=(3, 3, 32, 64) dtype=float32_ref>
<tf.Variable 'onet/conv2/biases:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'onet/prelu2/alpha:0' shape=(64,) dtype=float32_ref>
<tf.Variable 'onet/conv3/weights:0' shape=(3, 3, 64, 128) dtype=float32_ref>
<tf.Variable 'onet/conv3/biases:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/prelu3/alpha:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/conv4_/weights:0' shape=(3, 3, 128, 256) dtype=float32_ref>
<tf.Variable 'onet/conv4_/biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/prelu_/alpha:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/conv5_/weights:0' shape=(3, 3, 256, 256) dtype=float32_ref>
<tf.Variable 'onet/conv5_/biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/prelu5_/alpha:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/conv6_/weights:0' shape=(3, 3, 256, 256) dtype=float32_ref>
<tf.Variable 'onet/conv6_/biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/prelu6_/alpha:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/conv7_/weights:0' shape=(3, 3, 256, 256) dtype=float32_ref>
<tf.Variable 'onet/conv7_/biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/prelu7_/alpha:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/conv4/weights:0' shape=(2, 2, 256, 128) dtype=float32_ref>
<tf.Variable 'onet/conv4/biases:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/prelu4/alpha:0' shape=(128,) dtype=float32_ref>
<tf.Variable 'onet/conv5/weights:0' shape=(1152, 256) dtype=float32_ref>
<tf.Variable 'onet/conv5/biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/prelu5/alpha:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'onet/conv6-1/weights:0' shape=(256, 2) dtype=float32_ref>
<tf.Variable 'onet/conv6-1/biases:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'onet/conv6-2/weights:0' shape=(256, 4) dtype=float32_ref>
<tf.Variable 'onet/conv6-2/biases:0' shape=(4,) dtype=float32_ref>
<tf.Variable 'onet/conv6-3/weights:0' shape=(256, 10) dtype=float32_ref>
<tf.Variable 'onet/conv6-3/biases:0' shape=(10,) dtype=float32_ref>
4.1 conv之中的定义
#src/mtcnn.py in class NetWork(object):
def conv(self, inp, k_h, k_w, c_o, s_h, s_w, name,
task=None, relu=True, padding='SAME',
group=1, biased=True, wd=None):
self.validate_padding(padding)
c_i = int(inp.get_shape()[-1])
assert c_i % group == 0
assert c_o % group == 0
def convolve(i, k): return tf.nn.conv2d(
i, k, [1, s_h, s_w, 1], padding=padding)
with tf.variable_scope(name) as scope:
kernel = self.make_var(
'weights', shape=[
k_h, k_w, c_i / group, c_o])
if group == 1:
output = convolve(inp, kernel)
else:
input_groups = tf.split(inp, group, 3)
kernel_groups = tf.split(kernel, group, 3)
output_groups = [convolve(i, k) for i, k in
zip(input_groups, kernel_groups)]
output = tf.concat(output_groups, 3)
if (wd is not None) and (self.mode == 'train'):
self.weight_decay[task].append(
tf.multiply(tf.nn.l2_loss(kernel), wd))
if biased:
biases = self.make_var('biases', [c_o])
output = tf.nn.bias_add(output, biases)
if relu:
output = tf.nn.relu(output, name=scope.name)
return outputpadding='SAME'就是输入输出一样大,‘VALID’就是不进行padding
几个数字分别为卷积核的大小,卷积核的个数,卷积核时的stride
4.2 wd=self.weight_decay_coeff
网络中有的有此语句,有的没有此语句,该语句全都在后几层。
# src/mtcnn.py in class class NetWork(object):
# in def conv
if (wd is not None) and (self.mode == 'train'):
self.weight_decay[task].append(
tf.multiply(tf.nn.l2_loss(kernel), wd))是对权重的步长的设置,应该对结果没有太大影响。
智能推荐
IPv6: link local 地址fe80;link-layer address_思科交换机ipv6 address fe80::2ff:120:1 link-local-程序员宅基地
文章浏览阅读2.3k次。对于RTPROT_BOOT类型,一方面通过ioctl接口(如route命令)添加的路由proto字段会设置为RTPROT_BOOT;此外,如果使能了IP地址自动配置功能,内核可在启动过程中通过DHCP或者RARP等获取IP地址信息,此时,在添加与之相关的路由时,路由项也会使用RTPROT_BOOT类型。例如对于RTPROT_KERNEL类型,内核函数fib_magic添加的路由的protocol固定为RTPROT_KERNEL。在为内核接口添加IP地址时,触发此函数,用于添加相关的直连路由。_思科交换机ipv6 address fe80::2ff:120:1 link-local
天津大学计算机考研复试上机,天津大学计算机学院2015年硕士研究生复试上机说明...-程序员宅基地
文章浏览阅读373次。1、程序可以采用DEVC++或VC++作为编译器。评测系统所使用编译器为GCC/G++4.5.0,某些在VC6.0中可以编译通过的写法实际上并不符合标准,此时提交到在线测评系统时可能会得到CompileError。推荐使用DevCpp开发环境。编程时应该采用标准ANSIC/C++语法,不要使用VC的一些不标准的写法。2、如果写C语言程序,一定要保存为扩展名为.c再编译,不要保存扩展名.cp..._考研复试上机用的编译器是什么
详解XML节点属性排序_xml节点排序-程序员宅基地
文章浏览阅读4.3k次。用python实现“对xml节点中的属性进行排序”_xml节点排序
mysql 压缩包安装( windows)_mysql windows zip安装-程序员宅基地
文章浏览阅读542次。mysql 压缩包安装(windows)_mysql windows zip安装
详解.NET中的动态编译技术_动态编译技术的基本原理-程序员宅基地
文章浏览阅读755次。代码的动态编译并执行是一个.NET平台提供给我们的很强大的工具用以灵活扩展(当然是面对内部开发人员)复杂而无法估算的逻辑,并通过一些额外的代码来扩展我们已有 的应用程序。这在很大程度上给我们提供了另外一种扩展的方式(当然这并不能算是严格意义上的扩展,但至少为我们提供了一种思路)。动态代码执行可以应用在诸如模板生成,外加逻辑扩展等一些场合。一个简单的例子,为了网站那的响应速度,HTML静态页面往往是我们最好的选择,但基于数据驱动的网站往往又很难用静态页面实现,那么将_动态编译技术的基本原理
GEF入门系列(三、应用实例)_gef直线拖动-程序员宅基地
文章浏览阅读2.5k次。构造一个GEF应用程序通常分为这么几个步骤:设计模型、设计EditPart和Figure、设计EditPolicy和Command,其中EditPart是最主要的一部分,因为在实现它的时候不可避免的要使用到EditPolicy,而后者又涉及到Command。现在我们来看个例子,它的功能非常简单,用户可以在画布上增加节点(Node)和节点间的连接,可以直接编辑节点的名称以及改变节点的位置,用户可以撤_gef直线拖动
随便推点
Python编写简单的学生管理系统_test_student.py-程序员宅基地
文章浏览阅读1w次,点赞9次,收藏47次。Python编写简单的学生管理系统一共两个文件,其中一个定义函数,另一个是主程序,调用函数,运行程序CMS.py'''编写“学生信息管理系统”,要求如下:必须使用自定义函数,完成对程序的模块化学生信息至少包含:姓名、年龄、学号,除此以外可以适当添加必须完成的功能:添加、删除、修改、查询、退出'''# 定义一个列表用来存储多个学生信息stuList = []# 定义系统..._test_student.py
【看表情包学Linux】文件描述符 | 重定向 Redirection | dup2 函数 | 缓冲区的理解 (Cache)_重定向要刷新缓冲区函数-程序员宅基地
文章浏览阅读2.1k次,点赞72次,收藏65次。在上一章中,我们已经把 fd 的基本原理搞清楚了。本章我们将开始探索 fd 的应用特征,探索文件描述符的分配原则。讲解重定向,上一章是如何使用 fflush 把内容变出来的,介绍 dup2 函数,追加重定向和输入重定向的知识。最后我们讲解缓冲区,研究缓冲区的刷新策略。_重定向要刷新缓冲区函数
【深度学习】因果推断与机器学习的高级实践 | 数学建模_问题根因 分析 机器学习-程序员宅基地
文章浏览阅读1.5w次,点赞106次,收藏76次。当前,以深度学习为核心的机器学习和人工智能技术迅猛发展,给人们生产生活带来了巨大的深刻变化。人工智能在带来巨大机遇的同时,也蕴含着风险和挑战。现阶段以数据驱动、关联学习为模式的机器学习方法倾向于在数据驱动下对变量之间关联关系进行统计建模,缺乏以知识指导机制实现变量之间“由果溯因”的因果推断与分析有效方法,导致其普遍存在解释性不强、稳定性不高等问题。复杂数据中变量之间关联关系有三种来源:因果关联(Causation)、混淆偏差(Confounding Bias)和选择偏差(Selection Bias)。_问题根因 分析 机器学习
Prometheus入门与实战_prometheus 入门-程序员宅基地
文章浏览阅读276次。1.Prometheus介绍 1.什么是监控? 从技术角度来看,监控是度量和管理技术系统的工具和过程,但监控也提供从系统和应用程序生成的指标到业务价值的转换。这些指标转换为用户体验的度量,为业务提供反_prometheus 入门
YOLOv3训练自己的数据(linux)_imagenet预训练权重yolov3-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏14次。一、下载相关文件1.下载预训练权重文件YOLOv3使用在Imagenet上预训练好的模型参数的基础上继续训练。下载链接为https://pjreddie.com/media/files/darknet53.conv.74或使用wget命令下载:wget https://pjreddie.com/media/files/darknet53.conv.742.下载YOLOv3..._imagenet预训练权重yolov3
【vue】vue-Router 常见面试题_vue-router面试题-程序员宅基地
文章浏览阅读1w次,点赞15次,收藏160次。【vue】vue-Router 常见面试题文章目录【vue】vue-Router 常见面试题一、vue-Router基本使用二、常见面试题1.vue-router 路由钩子函数是什么 执行顺序是什么2. vue-router 动态路由是什么 有什么问题(1) params 方式(2) query 方式(3) params 和 query 的区别3.$route 和 $router 的区别4.Vue-Router 的懒加载如何实现5.vue-router 中常用的路由模式hash 模式history 模式6_vue-router面试题