python内置函数和序列化-程序员宅基地
修改字符集
全局修改
点击window
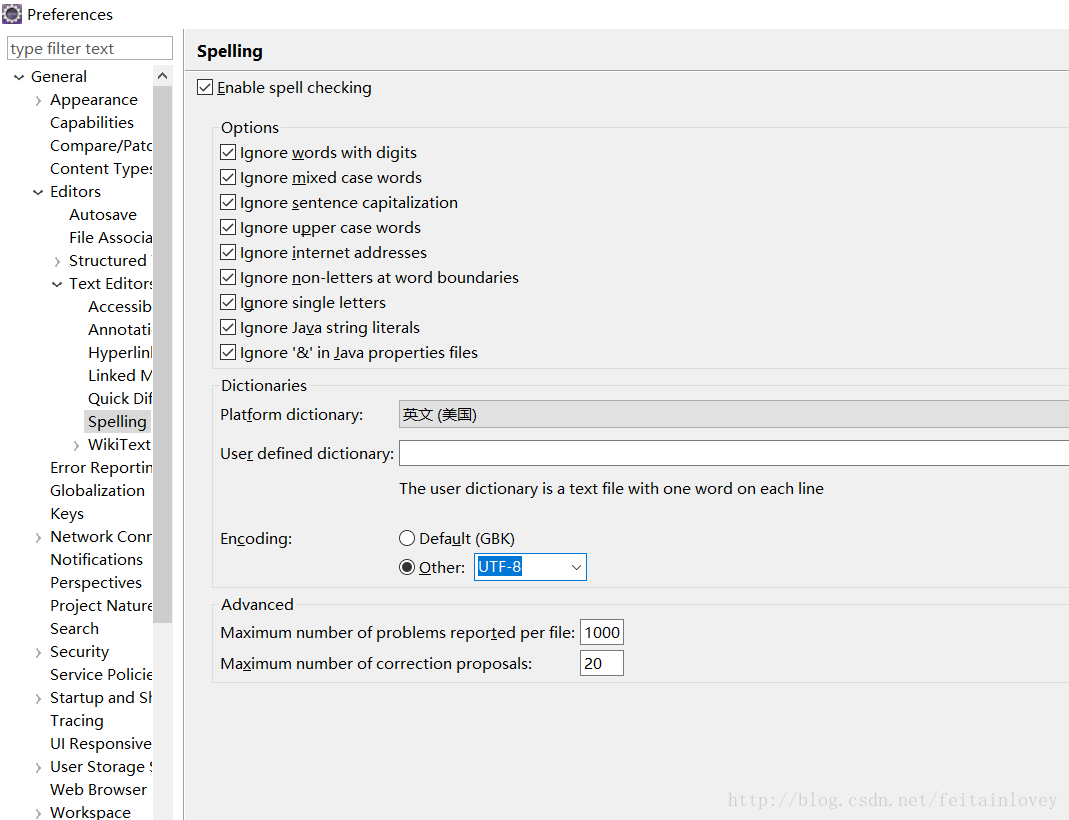
针对某一个工程
右键,有一个属性propertes
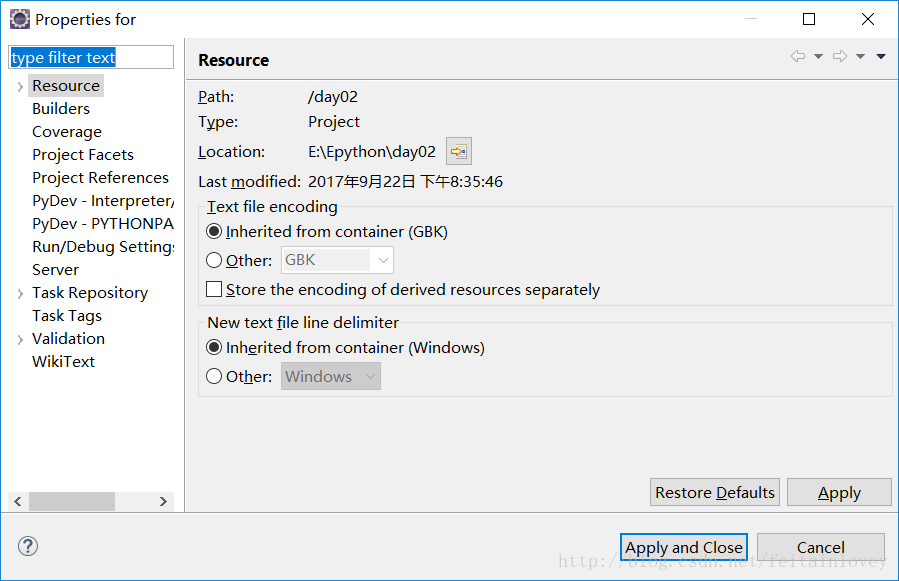
给某个文件,也就是前面加
也是右键属性,这里就不在说了
#模块的和模块的常用方法
- 至关重要的__init__.py
如果想导入成模块,一定要有这个文件 - 是否为主文件__name
if name == '\main__'
如果不是主文件返回模块文件路径+文件名 - 当前文件 :__doc__
返回模块级别的注释,函数级别的注释,是在函数下面加6个引号,中间写注释 - __file__:输出当前的路径
函数式编程
- 参数 def Fun(arg,*args,**kergs)
- 默认参数 print arg
- 可变参数 print *args print **kergs
一个是列表,一个是字典 - 返回值 return ‘success’
#!/usr/bin/env python #coding:utf-8 def login(username): if username == "alex": print "登录成功" else: print "登录失败" if __name__ == "__main__": user = raw_input('username:') login(user)yield
print range(10)
for item in xrange(10):
print item
#输出的时候并没有全部创建,他只是一个生成器,说明他没有写入内存中
#也就是说每一次创建就只创建一个整数
def foo():
yield 1
re = foo()
print re
输出:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
0
1
2
3
4
5
6
7
8
9
<generator object foo at 0x00000000030B8480>def fool():
yield 1
yield 2
yield 3
yield 4
#他的执行过程是,第一从从yield 1 执行,下一次直接从yield2开始执行
re = fool()
print re
#生成了一个生成器,每次遍历只生成一条
for item in re :
print item
结果:
<generator object fool at 0x0000000003248480>
1
2
3
4def ReadLines():
seek = 0
while True:
with open('E:/temp.txt','r') as f :
f.seek(seek)
date = f.readline()
if date:
seek = f.tell()
yield date
else:
return
print ReadLines()
for item in ReadLines():
print item 三元运算和lambda表达式
三元运算
- 代码实例:
result = ‘gt’ if 1>3 else ‘it’
print result - Lambda表达式()
代码实例:
a = lambda x,y: x+y
print a(1,2) - map函数()
map (lambda x:x*2,range(10))
意思就是将range的每个值赋给前边内置函数
- dir()列出当前文件内置的变量或者方法名,只列出key
- vars()和dir()不一样的是列出key和value
- type() 查看你所创建变量的类型
a = [] ,本质上是调用一个类,去生成一个列表,本质上是创建了一个类的实例,像tuple就是一个类的名字 - from file import demo
- reload(demo)
重新导入 - id()
查看变量的数据 - cmp()函数
cmp(x,y) 函数用于比较 2 个对象,如果 x< y 返回 -1,如果 x==y 返回 0,如果 x>y 返回 1。 - abs()取绝对值
- bool()将结果换算成布尔值
- divmod()
计算结果,将商和余数一元组的方式返回 - max([]) 最大值
- min([]) 最小值
- sum([]) 求和
- pow() 指数运算
- len() 计算长度(如果是中文则表示字节的长度)
- all(可迭代的对象) 可迭代对象所有的都为真,则返回Ture,否则返回False
- any(可迭代的对象) 有一个为真则返回Ture
- chr(65) 查看字符
- ord(‘a’) 查看ascall值
- hex() 16进制
- bin() 10进制
- oct() 8进制
- range()
- xrange()
- enumerate(
for k,v in enumerate([1,2,3,4]): print k,v 输出: 0 1 1 2 2 3 3 4#为程序增加一个序号 li = ['手表','汽车','房'] for item in enumerate(li,1): print item[0],item[1] #1为初始值 1 手表 2 汽车 3 房 - apply执行函数和函数的调用
def say():
print 'say in'
apply(say)
输出 ;say in - map函数() #遍历后面每一个序列的函数
map (lambda x:x*2,range(10))
意思就是将range的每个值赋给前边(可以是函数)lala = []; def foo(arg): return arg + 100 li = [11,22,33] lala = map(foo,li) print lala 结果: [111, 122, 133] #也可以使用 lala.append(item+100) temp = map (lambda arg:arg+100,li) - filter函数 #条件为真,将其加入序列中
temp = [] li = [11,22,33] def foo(arg): if arg <22: return True else: return False temp = filter(foo,li) print temp 将li序列中满足条件的返回temp序列中 结果:11 - reduce 累加(只能两个参数)
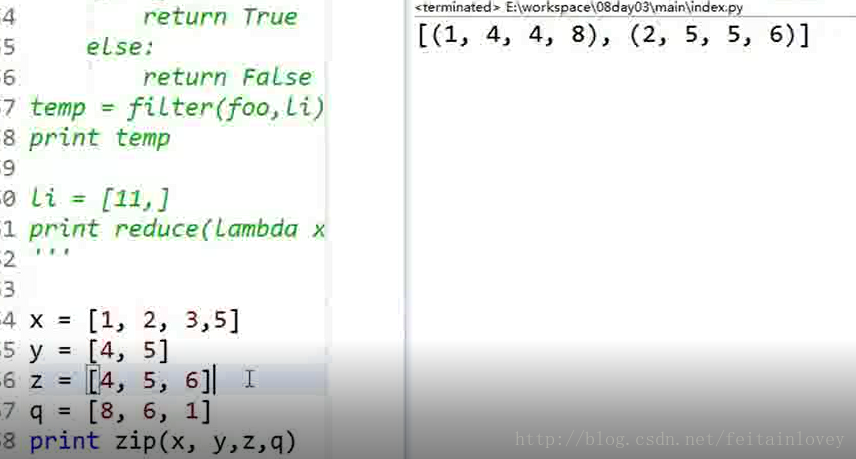
print reduce(lambda x,y:x+y,[1,2,3] ) 结果 6 将前一次的计算结果,传递为第二次计算的第一个参数 - zip 函数 #将列表中的第一个组成新的列表
x = [1,2,3]
y = [4,5,6]
z = [4,5,6]
print zip(x,y,z)
结果:
[(1, 4, 4), (2, 5, 5), (3, 6, 6)] - eval函数 #直接计算字符串类型的运算
a ='8*8' print eval(a) 结果:64字符串的格式化
s = 'i am {0},{1}'
print s.format('alex','xxx')
i am alex,xxx反射 通过字符串的形式导入模块,并以字符串的形式执行函数 (动态切换数据库连接)
不允许使用import os 导入,用temp的方法导入
temp = 'os' model = __import__(temp) print model print model.path 输出: <module 'os' from 'D:\pycharm\lib\os.pyc'> <module 'ntpath' from 'D:\pycharm\lib\ntpath.pyc'>
getattr就是在mysqlhelper模块中查找count函数
Function就等于调用的count函数
相应的有delattr()、hasattr()判断函数中是否含有相应的模块

#使用random生成验证码
它使用的是ascall的值进行生成的
import random
print random.random()
print random.randint(1,5)
#生成1-5之间的随机整数
print random.randrange(1,3)
#生成大于等于1,小于3的随机数import random
code = []
for i in range(6):
if i == random.randint(1,5):
code.append(str(random.randint(1,5)))
else:
temp = random.randint(65,90)
code.append(chr(temp))
print ''.join(code)#注意:join和+=的区别
join效率更高,+=每次都要在内存中请求一块空间,join只申请一次
md5加密
#!/usr/bin/env python
#coding:utf-8
import hashlib
hash=hashlib.md5()
hash.update('admin')
print hash.hexdigest()
print hash.digest()
21232f297a57a5a743894a0e4a801fc3
!#/)zW��C�JJ�¬�
#md5不能反解序列化和JSON
应用实例:(python 和python之间传输文件,单机游戏实时保存)
为什么要序列化?
一个程序将列表存在一个程序中,另一个程序使用这个文件的时候。使用序列化之后在让另一个程序去读取的话,使两个python程序之间内存数据之间的交换,两个独立的进程在内存中看,他们的内存空间不能互相访问,如果两个程序之间不仅仅只是简单的列表共享,还想其他数据交换,数据可能比较复杂。而且硬盘只能存字符串类型的数据,只能通过系列化,存入文件,另一个程序然后读取文件的内容,然后将其反序列化之后,在加载到内存中
序列化:把一个对象或(一个列表、字典),把对象通过Python特有的机制序列化,序列化就是以特殊的形式以过二进制的方式给对象加密,并且序列化之后可以反序列化。
序列化
import pickle
li = ['axex',11,22,'ok','sb']
print pickle.dumps(li)
print type(pickle.dumps(li))
输出结果:
(lp0
S'axex'
p1
aI11
aI22
aS'ok'
p2
aS'sb'
p3
a.
<type 'str'>
#是一个没有规则的字符串类型反序列化
import pickle
li = ['axex',11,22,'ok','sb']
dumpsed = pickle.dumps(li)
print type(dumpsed)
loadsed = pickle.loads(dumpsed)
print loadsed
print type(loadsed)
<type 'str'>
['axex', 11, 22, 'ok', 'sb']
<type 'list'>将列表序列化到一个文件中
import pickle
li = ['axex',11,22,'ok','sb']
pickle.dump(li,open('E:/temp.pk','w'))
result = pickle.load(open('E:/temp.pk','r'))
#将文件中反序列化JSON:一种标准化的数据格式,把不同格式的数据JSON化。
##两种序列化的区别
- pickle只能在python中使用
- JSON是所有的语言都支持的接口
- pickle 不但可以dump常规的数据类型,比如,字典、列表、集合,还可以序列化类、对象,基本上所有的类型都可以实现序列化,JSON只能序列化常规的数据类型。因为,在不同的语言中类的格式不同。
- pickle 序列化的序列的数据不可读,但是JSON的数据格式是用人眼可以看出来他的格式
import json name_dic = {'name':'wupeiqi','age':23} print json.dumps(name_dic) 输出结果:全部变成字符串 {"age": 23, "name": "wupeiqi"}
为什么多个了U呢,因为在存入内存中使用Unicode,你本事是utf-8,然后反序列化之后又变成Unicode

转载于:https://blog.51cto.com/13132323/2134808
智能推荐
赛效:怎么一键人像抠图-程序员宅基地
文章浏览阅读149次。2:人像图上传成功后自动进入抠图页面,我们点击下方的“下载图片”,可将抠图后的人像图下载到电脑本地。3:图片下载成功后,效果如下图所示。如果对抠图要求较高,可以自行修改细节。1:在人像抠图页面,点击下方的“本地上传”,将本地人像图片添加上去。”官网输入关键词,搜索查找相关教程。如果你想了解更多好用的。
4.html+css+javascript网页设计实例/“成都“旅游主题介绍/web前端期末大作业/-程序员宅基地
文章浏览阅读1k次,点赞23次,收藏21次。本实例为html+css+javascript代码。该实例里面有设置导航栏效果、动态轮播特效、DIV、Banner、表格、视频、注册、登录页面等实例比较全面,有助于各位大小朋友学习,本文以“成都”旅游为主题来设计实践,介绍如何通过从头开始设计旅游网站并将其转换为代码的过程。
PerfDog-移动端性能测试-基本使用_perfdog在跑性能的过程中能录屏吗-程序员宅基地
文章浏览阅读941次。常见的腾讯性能测试工具:腾讯gt、腾讯wetest、腾讯perfdog腾讯perfdog: https://perfdog.qq.com/一、介绍:移动全平台iOS/Android性能测试、分析工具平台。快速定位分析性能问题,提升APP应用及游戏性能和品质。手机无需ROOT/越狱,手机硬件、游戏及应用APP也无需做任何修改,极简化即插即用。Windows & Mac OS X平台PerfDog桌面应用程序版本都支持对iOS和Android设备进行测试。PC上PerfDog可多开,单PC可._perfdog在跑性能的过程中能录屏吗
Git远程仓库配置SSH(gitHub为例)_git 登录到gitlab ssh账户命令-程序员宅基地
文章浏览阅读1.6k次。git配置giehub远程仓库_git 登录到gitlab ssh账户命令
jsp执行原理(详解)_jsp页面运行原理-程序员宅基地
文章浏览阅读1.3w次,点赞8次,收藏65次。1. jsp的工作模式jsp的工作模式是***请求/相应模式***,客户端首先发出HTTP请求,jsp程序收到请求后会进行处理并返回处理结果。在一个jsp文件第一次被请求时,jsp引擎(容器)把该jsp文件转换成一个Servlet,而这个引擎本身也是一个Servlet。2. jsp的工作原理:客户端通过浏览器向服务器发出请求,在该请求中包含了请求的资源的路径,这样当服务器接收到该请求后就可以知道被请求的内容。服务器根据接收到的客户端的请求来加载相应的JSP文件。Web服务器中的J_jsp页面运行原理
java合一算法_Prolog语言的编译原理:合一算法-程序员宅基地
文章浏览阅读373次。Prolog语言的编译原理:合一算法分类:软考|更新时间:2016-07-08|来源:转载Prolog是一种基于谓词演算的程序设计语言。Prolog是一种说明性语言,它的基本意思是程序员着重于描述问题而不是指定一组指令来解决问题。Prolog程序是一组子句的集合,每个子句要么是事实要么是规则,子句表示属性或者个体之间的关系。Prolog的语法和谓词演算的语法接近。例如,下面是一些事实的例子:met..._prolog java
随便推点
HttpRequestUtil方法get、post、JsonToPost_httprequestutil.httpget-程序员宅基地
文章浏览阅读785次。java后台发起请求使用的工具类package com.cennavi.utils;import org.apache.http.Header;import org.apache.http.HttpResponse;import org.apache.http.HttpStatus;import org.apache.http.client.HttpClient;import org.apache.http.client.methods.HttpPost;import org.apach_httprequestutil.httpget
App-V轻量级应用程序虚拟化之三客户端测试-程序员宅基地
文章浏览阅读137次。在前两节我们部署了App-V Server并且序列化了相应的软件,现在可谓是万事俱备,只欠东风。在这篇博客里面主要介绍一下如何部署客户端并实现应用程序的虚拟化。在这里先简要的说一下应用虚拟化的工作原理吧!App-V Streaming 就是利用templateServer序列化出一个软件运行的虚拟环境,然后上传到app-v Server上,最后客户..._app-v 客户端
实时视频传输方案汇总-java_eclipse视频传输设计-程序员宅基地
文章浏览阅读4.6k次。实时视频传输方案汇总-java目录libstreamingh264jrtsp-h264-clientOpenFlowihmc-video-codecs目录libstreaminghttps://github.com/fyhertz/libstreamingIntroductionWhat it doeslibstreaming is an API that allows you, wi..._eclipse视频传输设计
unbantu上python安装步骤_如何在Ubuntu中安装Python 3.6?-程序员宅基地
文章浏览阅读230次。Python是增长最快的主要通用编程语言。原因有很多,比如它的可读性和灵活性,易于学习和使用,可靠和高效。有两个主要的Python版本被使用- 2和3 (Python的现在和未来);前者将看不到新的主要版本,而后者正在积极开发中,在过去几年已经看到了许多稳定的版本。Python 3的最新稳定版本是3.6版。Ubuntu 18.04和Ubuntu 17.10都预装了Python 3.6,这与老版本的..._ubuntu 14.04 安装python 3.6
NXP NFC Reader Library 移植思路_nxpnfcreader-程序员宅基地
文章浏览阅读1.1k次。记录 NXP 的 SDK 移植到 STM32 的过程,没有完成移植,中途暂停了。 _nxpnfcreader
分享几个适合新手的C/C++开源项目_c++项目-程序员宅基地
文章浏览阅读9.1k次,点赞10次,收藏147次。分享几个适合新手的C/C++开源项目今天主要给大家分享一些github内适合初学者练手的c/c++开源项目。所有项目均提供项目下载地址,无法使用github的读者,也可在公众号内回复:c开源项目 进行获取项目一:C-Plus-Plus项目介绍C-Plus-Plus是收录用 C++ 实现的各种算法的集合,并按照 MIT 许可协议进行授权。这些算法涵盖了计算机科学、数学和统计学、数据科学、机器学习、工程等各种主题。除外,你可能会发现针对同一目标的多个实现使用不同的算法策略和优化。支持环境:M_c++项目