卷积神经网络解决拼图
Training a Neural Net on permutation invariant data is difficult. And a jigsaw puzzle is one of those.
在排列不变数据上训练神经网络非常困难。 拼图游戏就是其中之一。
什么是置换不变性? (What is Permutation Invariance?)
A function is a permutation invariant if its output does not change by changing the ordering of its input. Here is an example below.
如果函数的输出不通过更改其输入的顺序而改变,则该函数是置换不变式。 这是下面的例子。
1) f(x,y,z) = ax + by +cz2) f(x,y,z) = xyzThe output of the 1st function will change if we change the input order, but the output of the 2nd function will not change. So 2nd function is permutation invariant.
如果我们更改输入顺序,则第一个函数的输出将更改,但是第二个函数的输出将保持不变。 所以第二个函数是置换不变的。
Weights of the neural net maps to specific input units. When the input changes, the output will change too. So in order to learn this symmetry, weights should be such as that final output is unchanged even after changing the input. Which is not easy to learn by the feed-forward network.
神经网络的权重映射到特定的输入单位。 当输入改变时,输出也将改变。 因此,为了学习这种对称性,权重应确保即使更改输入后最终输出也不会更改。 前馈网络不容易学习。
A jigsaw puzzle is also permutation invariance. No matter what the ordering of puzzle pieces are the output would always be fixed. Here is an example of a 2x2 grid puzzle, which we would be trying to solve in this project.
拼图游戏也是排列不变性。 无论拼图块的顺序如何,输出始终是固定的。 这是一个2x2网格难题的示例,我们将在此项目中尝试解决该难题。

Solving a 3x3 grid puzzle is extremely difficult. The following are possible combinations of these puzzles.
解决3x3网格难题非常困难。 以下是这些难题的可能组合。
2x2 puzzle = 4! = 24 combinations3x3 puzzle = 9! = 362880 comb’nsTo solve a 3x3 puzzle the network has to predict one correct combination out of 362880. This is one more reason why 3x3 the puzzle is a tough one.
为了解决3x3难题,网络必须预测362880一种正确组合。 这是为什么3x3拼图很难解决的另一个原因。
Let’s move forward and try to solve a 2x2 Jigsaw puzzle.
让我们继续前进,尝试解决2x2拼图游戏。
您是如何获得数据的? (How did you get the data?)
There was not any public dataset available for Jigsaw Puzzles, so I had to create it myself. I created the data as follows.
拼图没有可用的公共数据集,因此我必须自己创建它。 我创建数据如下。
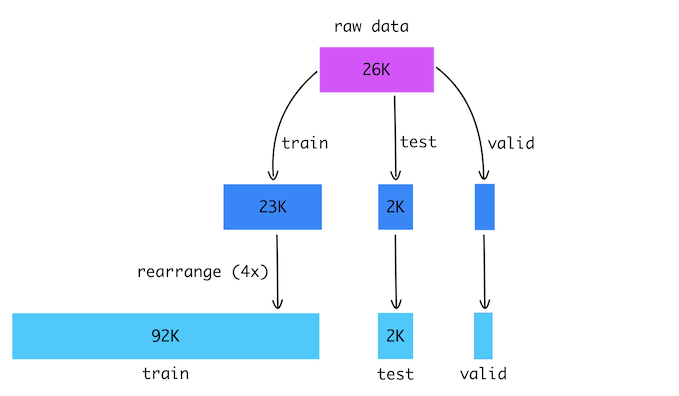
Took a raw dataset containing around
26Kanimal images.获取了包含约
26K动物图像的原始数据集。Cropped all images into a fixed size of
200x200.将所有图像裁剪为固定的
200x200尺寸。Split the images into
train,testandvalidationset.将图像分为
train,test和validation集。- Cut the images into 4 pieces and randomly rearranged them. 将图像切成4张并随机重新排列。
- For the training set, I have repeated the previous step 4 times to augment the data. 对于训练集,我已经重复了上一步4次以扩充数据。
- Finally, we have 92K training images and 2K testing images. I have also separated out 300 images for validation. 最后,我们有92K训练图像和2K测试图像。 我还分离出300张图像进行验证。
- The label is an integer array that denotes the correct position of each puzzle piece. 标签是一个整数数组,表示每个拼图的正确位置。
This dataset contains both 2x2 and 3x3 puzzle. You can find it here.
该数据集包含2x2和3x3拼图。 你可以在这里找到它。
但是数据看起来如何? (But how does the data look?)
Following is a data sample of 2x2 grid puzzle. Input is a 200x200 pixel image and label is an array of 4 integers, where each integer tells the correct position of each piece.
以下是2x2网格拼图的数据样本。 输入是一个200x200像素的图像,标签是一个由4个整数组成的数组,其中每个整数都表示每个片段的正确位置。
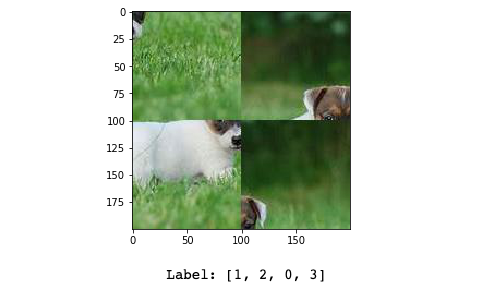
Our goal is to feed this image into a neural net and get an output which is a vector of 4 integers indicating the correct position of each piece.
我们的目标是将该图像输入到神经网络中,并得到一个输出,该输出是4个整数的向量,指示每个片段的正确位置。
您是如何设计网络的? (How did you design the Network?)
After trying more than 20 neural net architecture and a lot of trial and error I came up with an optimal design. Which is as follows.
在尝试了20多种神经网络体系结构和大量的反复试验之后,我想到了一个最佳设计。 如下。
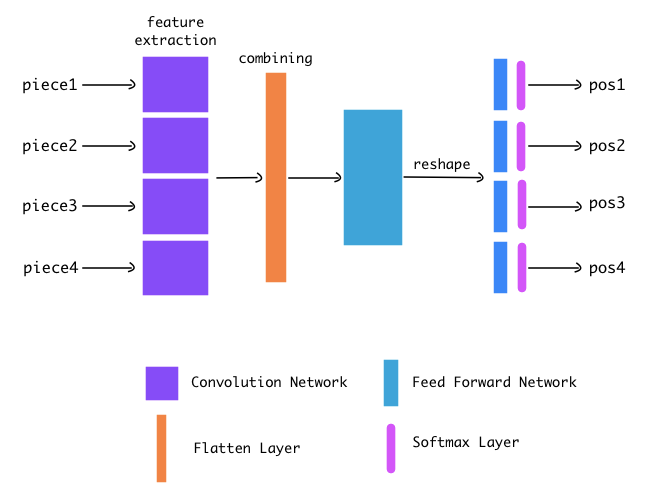
- First, extract each puzzle piece from the image (total 4). 首先,从图像中提取每个拼图(共4个)。
- Then pass each piece through the CNN. CNN extracts useful features and outputs a feature vector. 然后将每片穿过CNN。 CNN提取有用的特征并输出特征向量。
- We concatenate all 4 feature vectors into one using the Flatten layer. 我们使用Flatten层将所有4个特征向量连接为一个。
- Then we pass this combined vector through a feed-forward network. The last layer of this network gives us a 16 unit long vector. 然后,我们将此组合向量传递到前馈网络。 该网络的最后一层为我们提供了16个单位长的向量。
We reshape this 16 unit vector into a matrix of
4x4.我们将此16个单位向量重塑为
4x4的矩阵。
我们为什么要重塑? (Why do we reshape?)
In a normal classification task, neural networks output a score for each class. We convert that score into probability by applying a softmax layer. The class which has the highest probability value is our predicted class. This is how we do classification.
在正常的分类任务中,神经网络为每个类别输出分数。 我们通过应用softmax图层将得分转换为概率。 概率值最高的类别是我们的预测类别。 这就是我们的分类方法。
The situation is different here. We want to classify each piece into its correct position (0, 1, 2, 3). And there are 4 such pieces. So we need 4 vectors(for each piece) each having 4 scores(for each position), which is nothing but a 4x4 matrix. Where rows correspond to pieces and columns to score. Finally, we apply a softmax on this output matrix row-wise.
这里的情况有所不同。 我们想将每个片段分类到正确的位置(0, 1, 2, 3) 。 并且有4个这样的片断。 因此,我们需要4个向量(每个片段),每个向量具有4个得分(每个位置),这不过是一个4x4矩阵。 行对应于要评分的片段和列。 最后,我们在此输出矩阵上逐行应用softmax。
The following is the network diagram.
下面是网络图。
如何编码神经网络? (How to code the Neural Net?)
I am using Keras framework for this project. Following is the complete network implemented in the Keras. Which looks fairly simple.
我正在为此项目使用Keras框架。 以下是在Keras中实现的完整网络。 看起来很简单。
你能解释一下代码吗? (Can you explain the code?)
As you see, the input shape is (4,100,100,3). Means I am feeding 4 images(puzzle pieces) of shape (100,100,3) as an input to the network.
如您所见,输入形状为(4,100,100,3) 。 意思是我正在输入4个形状(100,100,3)图像(拼图(100,100,3)作为网络的输入。
As you see, I am using Time-Distributed(TD) layers. TD layer applies a given layer multiple times over an input. Here the TD layer will apply the same convolutional layer over 4 input images (line: 5, 9, 13, 17).
如您所见,我正在使用时间分布 (TD)层。 TD层在输入上多次应用给定层。 在此,TD层将在4个输入图像(行: 5、9、13、17)上应用相同的卷积层。
In order to use TD layers, we have to give one extra dimension in the input, over which TD layer applies a given layer multiple times. Here we are giving one extra dimension, which is the number of images. As a result, we get 4 feature vectors for all 4 image pieces.
为了使用TD层,我们必须在输入中提供一个额外的尺寸,在该尺寸上TD层会多次应用给定的层。 在这里,我们给出一个额外的维度,即图像的数量。 结果,我们获得了所有4个图像片段的4个特征向量。
Once the CNN feature extraction is done, we concatenate all the features using the Flatten layer (line: 21). Then pass the vector through a feed-forward network. Reshape the final output to a 4x4 matrix and apply a softmax (line 29, 30).
CNN特征提取完成后,我们使用Flatten层(第21行)将所有特征连接在一起。 然后将向量通过前馈网络。 将最终输出调整为4x4矩阵并应用softmax (第29、30行) 。
您能解释一下CNN架构吗? (Can you explain CNN architecture?)
This task is completely different from a normal classification task. In normal classification task network focuses more on the central region of the image. But in the case of Jigsaw, the edge information is much more important than the central one.
此任务与常规分类任务完全不同。 在正常分类任务网络中,重点更多地放在图像的中心区域。 但是对于拼图来说,边缘信息比中心信息重要得多。
So my CNN architecture is different from the usual one in the following ways.
因此,我的CNN架构在以下方面不同于通常的CNN架构。
填充 (Padding)
I am using some extra padding around the image before passing it through CNN (line: 3). And also padding the feature map before each convolution operation (padding = same) to protect as much edge info as possible.
在将图像通过CNN之前,我在图像周围使用了一些额外的填充 (第3行) 。 还要在每次卷积操作之前填充特征图( padding = same ),以保护尽可能多的边缘信息。
最大池 (MaxPooling)
I am avoiding pooling layers and using just one MaxPool layer to reduce the feature map size (line: 7). Pooling makes the Network translation invariance, which means even if you rotate of jiggle the object in the image, the network would still detect it. Which is good for any object classification task.
我避免使用池化图层,而只使用一个MaxPool图层来减小要素地图的大小(第7行) 。 池化使网络翻译不变,这 意味着即使您旋转图像中的对象,该网络仍会检测到它。 这对任何对象分类任务都是有好处的。
But here we don’t want the network to be translation invariance. Our network should be sensitive to variance. Since our edge information is very sensitive.
但是这里我们不希望网络成为翻译不变性 。 我们的网络应该对变化敏感。 由于我们的边缘信息非常敏感。
浅层网络 (Shallow Network)
We know that top layers in CNN extract feature like edges, corners, etc. And as we go deep, layers tend to extract features like shape, color distribution, etc. Which are not much relevant for our case, so creating a shallow network will help here.
我们知道CNN的顶层会提取诸如边缘,拐角等特征。随着深入,层倾向于提取诸如形状,颜色分布等特征。这与我们的情况无关,因此创建浅层网络会在这里帮助。
These all are the important details you need to know about CNN architecture. The rest of the network is fairly simple having 3 feed-forward layers, a reshape layer, and finally a softmax layer.
这些都是您需要了解的有关CNN架构的重要细节。 网络的其余部分非常简单,具有3个前馈层,一个重塑层和最后一个softmax层。
培训过程是什么? (What is the training process?)
Finally, I compile my model with sparse_categorical_crossentropy loss and adam optimizer. Our target would be a 4 unit vector telling the correct position of each piece.
最后,我使用sparse_categorical_crossentropy损失和adam优化器编译模型。 我们的目标将是一个4单位的向量,告诉每个工件正确的位置。
Target Vector: [[3],[0],[1],[2]]I trained the network for 5 epochs. I started with learning rate 0.001 and batch size 64. After each epoch, I am reducing the learning rate and increasing batch size.
我将网络训练了5个时期。 我从学习率0.001和批处理大小64 。 在每个时期之后,我都会降低学习率并增加批次大小。
结果如何? (How are the results?)
While prediction, our network outputs a 4x4 vector, then we select the index having a maximum value in each row, which is nothing but the predicted position. Thus we get a vector of length 4. Using this vector we can also re-arrange the puzzle pieces and visualize them.
在进行预测时,我们的网络会输出4x4向量,然后我们选择在每一行中具有最大值的索引,该索引不过是预测位置。 因此,我们得到一个长度为4的向量。使用该向量,我们还可以重新排列拼图并将它们可视化。
After training, I ran the model on 2K unseen puzzles, and the model was able to solve the 80% puzzle correctly. Which is quite fair.
训练后,我在2K看不见的谜题上运行了该模型,该模型能够正确解决80%的谜题。 这很公平。
Here are the few samples solved by the network.
这是网络解决的一些示例。

Following is the complete project hosted on GitHub.
以下是托管在GitHub上的完整项目。
If you enjoyed this article, then you should also check out the following article.
如果您喜欢这篇文章,那么还应该查看以下文章。
I will keep posting more such exciting projects in the future. You can also join my mailing list to get my latest content directly in your inbox. Thanks for reading!
将来,我将继续发布更多此类激动人心的项目。 你也可以加入 我的邮件列表,直接在您的收件箱中获取我的最新内容。 谢谢阅读!
翻译自: https://medium.com/@shivajbd/solving-jigsaw-using-neural-nets-cc543a5f025c
卷积神经网络解决拼图