异常检测(三)之线性模型_print(x, correlation=true)-程序员宅基地
技术标签: data mining
线性模型即线性方法,本文介绍线性回归与主成成分分析2种方法
对数据进行线性建模的两个前提:
- 近似线性相关假设
因变量与所有自变量存在线性关系,且与每一个自变量之间都存在线性关系的假设 - 子空间假设
子空间假设认为数据是镶嵌在低维子空间中的,线性方法的目的是找到合适的低维子空间使得异常点(o)在其中区别于正常点(n)。
- 数据可视化
首先,确定数据集适应的模型,因此需要对数据进行可视化
采用的数据集为breast-cancer-unsupervised-ad数据集,下载地址:
数据集包下载
观察数据,打印出前5行,共31列,最右边的列为标签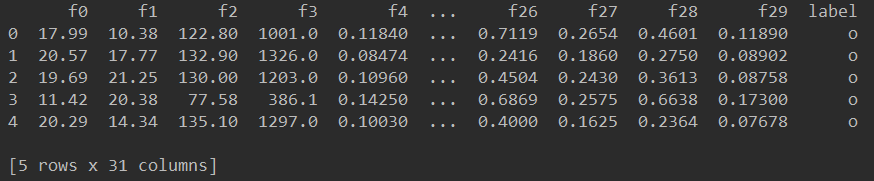
使用train.tail()函数,观察数据尾部,得到一共367行数据
使用train.describe()函数,得到数据的最大值最小值等统计量,如下图

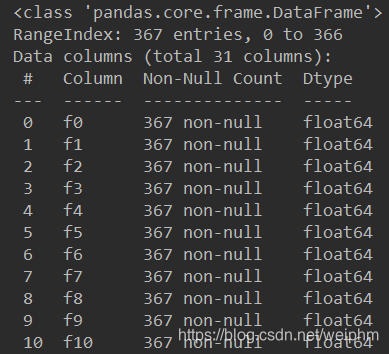
使用train.info()函数,每一列数据的类型和数量,可见每一列都是367个数据,类型是64位,如下图
得到数据的特征,首先计算相关系数,即计算线性数据的相关系数。
numeric_features = ['f' + str(i) for i in range(30)]
print(numeric_features)
## 1) 相关性分析
numeric = train_data[numeric_features]
correlation = numeric.corr()
print(correlation)#相关系数
f , ax = plt.subplots(figsize = (14, 14))
sns.heatmap(correlation,square = True)
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
plt.show()
f = pd.melt(train_data, value_vars=numeric_features)#列数据合并为行数据
print(f)
g = sns.FacetGrid(f, col="variable", col_wrap=6, sharex=False, sharey=False)#结构化多绘图网格,col_wrap=6-6列,是否共享x轴或者y轴
g = g.map(sns.distplot, "value", hist=False, rug=True)
sns.set()
#主要展现的是变量两两之间的关系
sns.pairplot(train_data[numeric_features],size = 2 ,kind ='scatter',diag_kind='kde')#对于特征使用散点图
plt.savefig('correlation.png')
plt.show()
facetgrid:多网格,不共享x或者y轴
pairplot:
kind:用于控制非对角线上的图的类型,可选"scatter"与"reg"
diag_kind:控制对角线上的图的类型,可选"hist"与"kde"
最终输出为:
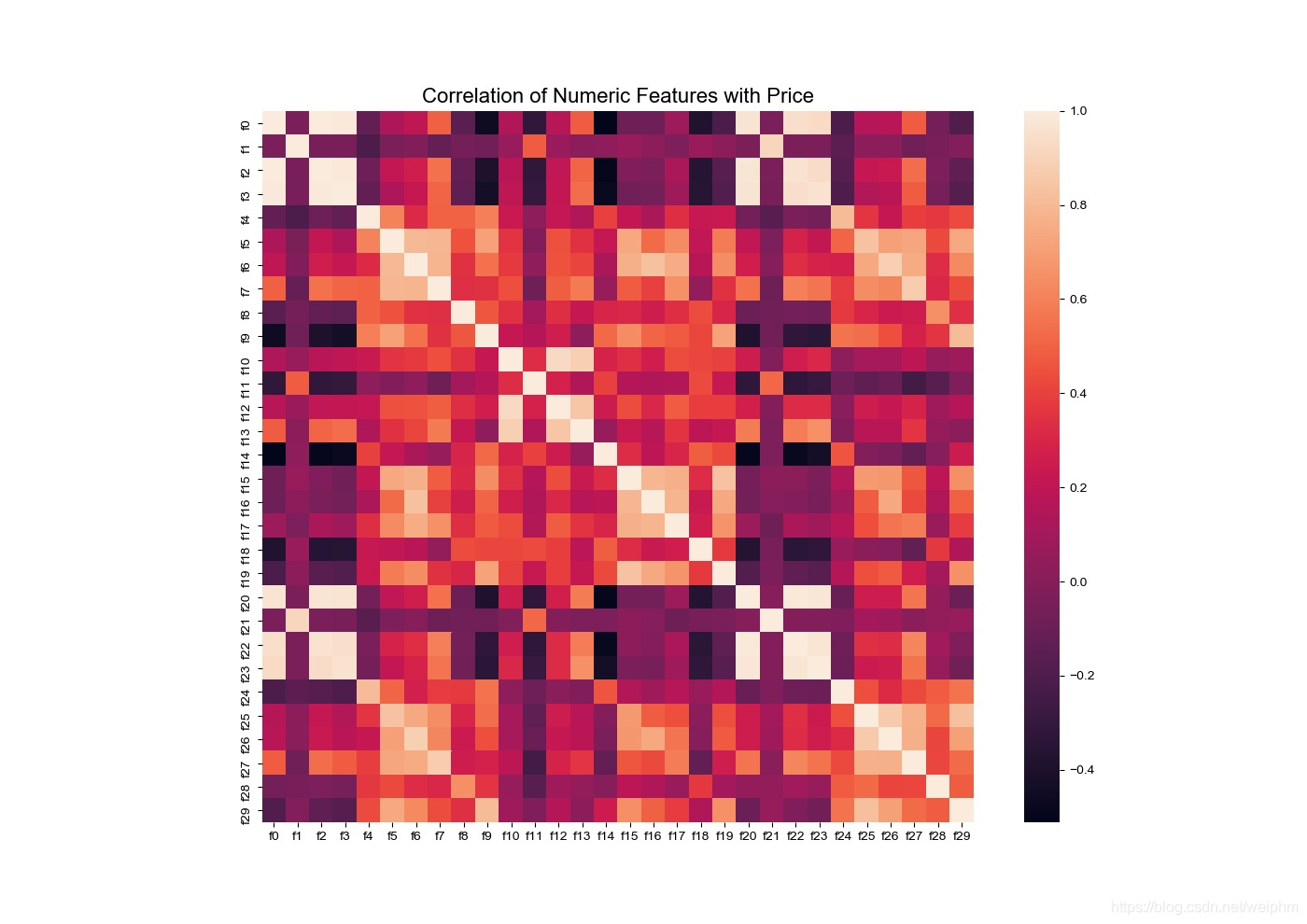
热力图,相关系数
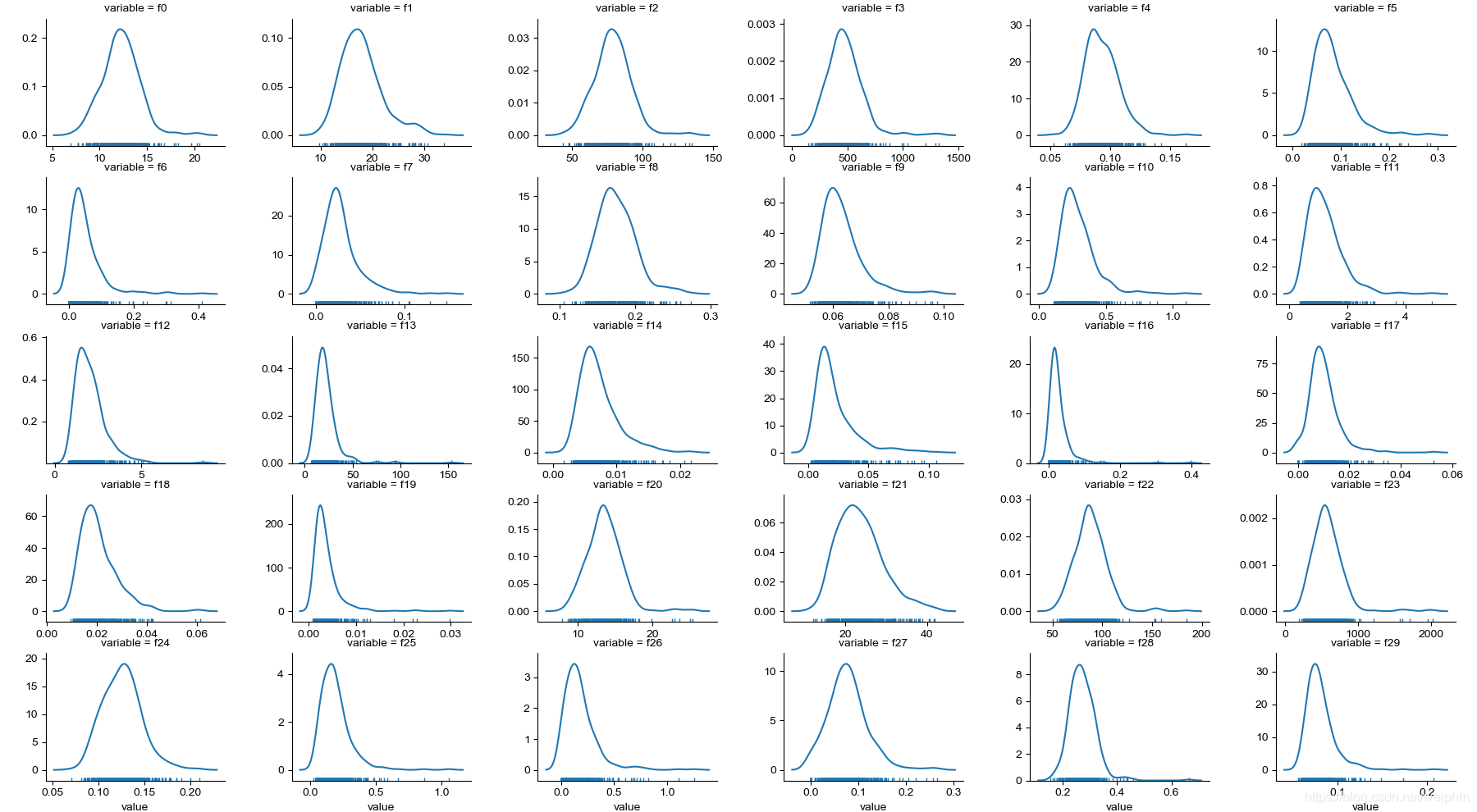
facegrid输出,30,30个特征的分布

pairplot输出,30*30,两两之间
接着使用降维方法:TSNE
t-SNE(t-distributed stochastic neighbor embedding)是用于降维的一种机器学习算法,是由 Laurens van der Maaten 等在08年提出来。此外,t-SNE 是一种非线性降维算法,非常适用于高维数据降维到2维或者3维,进行可视化。该算法可以将对于较大相似度的点,t分布在低维空间中的距离需要稍小一点;而对于低相似度的点,t分布在低维空间中的距离需要更远。
其主要用于可视化,很难用于其他目的,t-SNE没有唯一最优解,且没有预估部分。点击这里查看更多有关tsne的介绍
init:字符串,可选(默认值:“random”)嵌入的初始化。可能的选项是“随机”和“pca”。 PCA初始化不能用于预先计算的距离,并且通常比随机初始化更全局稳定
#数据降维可视化
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, init='pca', random_state=0)
result = tsne.fit_transform(numeric)
x_min, x_max = np.min(result, 0), np.max(result, 0)
#对结果进行标准化
result = (result - x_min) / (x_max - x_min)
label = train_data['label']
fig = plt.figure(figsize = (7, 7))
#f , ax = plt.subplots()
color = {
'o':0, 'n':7}#8种颜色
for i in range(result.shape[0]):
plt.text(result[i, 0], result[i, 1], str(label[i]),
color=plt.cm.Set1(color[label[i]] / 10.),#颜色
fontdict={
'weight': 'bold', 'size': 9})#字体
plt.xticks([])
plt.yticks([])
plt.title('Visualization of data dimension reduction')
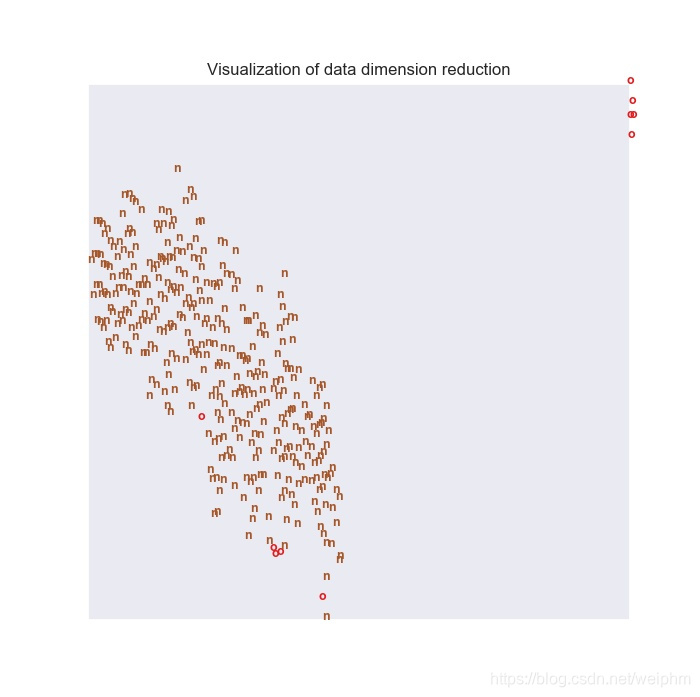
可以看到上面的图非常奇怪。。。
确实也分开了,接下来使用pca看看效果:
- PCA提取特征
首先用pyod库生成example,这里选择生成30维的数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pyod as py
from pyod.utils.data import generate_data
from pyod.models.pca import PCA
from pyod.utils.example import visualize
from pyod.utils.data import evaluate_print
import seaborn as sns
#生成数据 维度30
x_train,y_train=generate_data(
n_train=500, n_features=30,
train_only=True,behaviour='old',offset=10)
outlier_fraction = 0.1
再将数据转换成dataframe格式,看看数据之间的关联性
#转换为dataframe
df_train = pd.DataFrame(x_train)
numeric_features = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29]
print(numeric_features)
numeric = df_train[numeric_features]
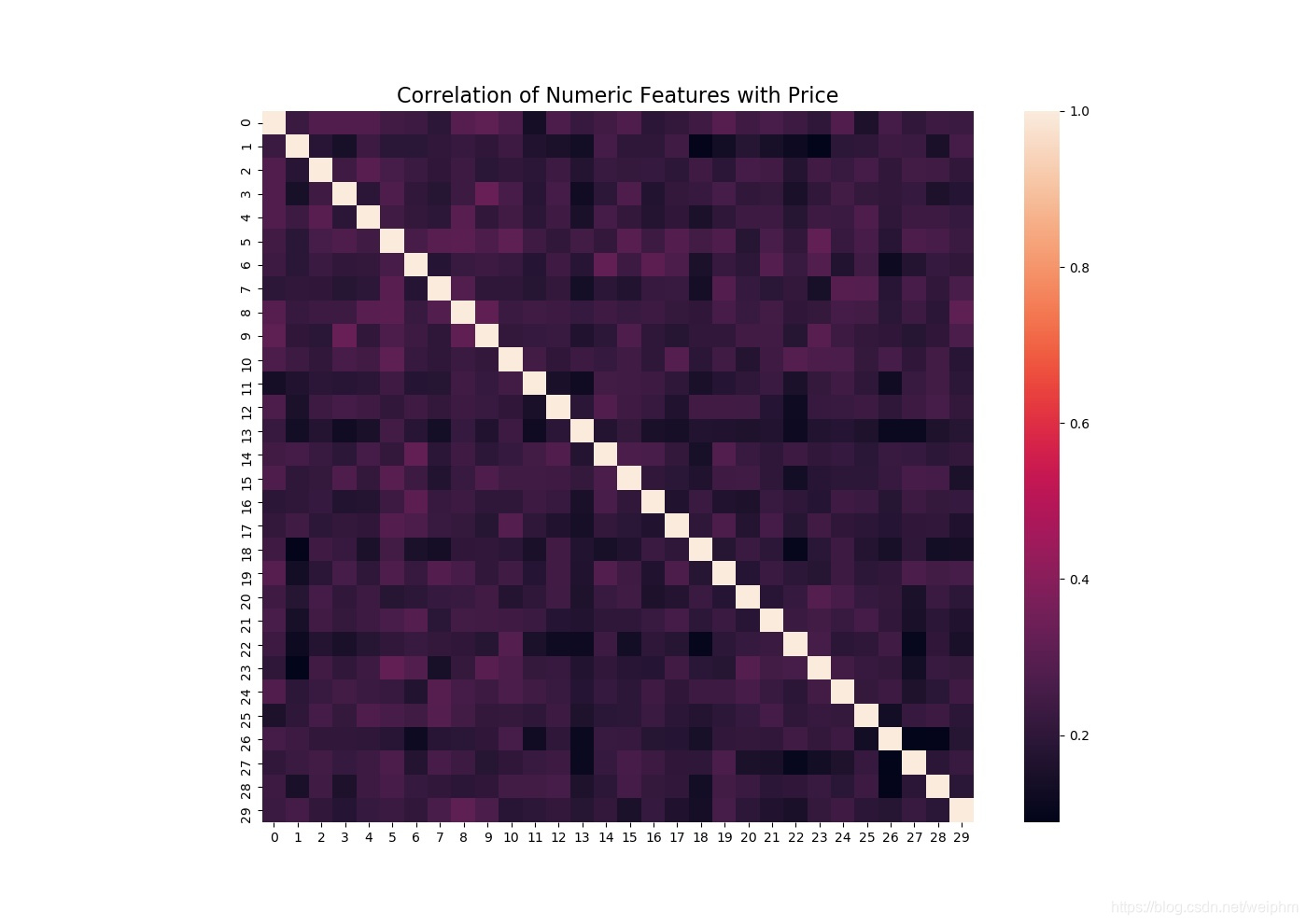
correlation = numeric.corr()#相关系数
f , ax = plt.subplots(figsize = (14, 14))
sns.heatmap(correlation,square = True)
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
plt.show()
f = pd.melt(df_train, value_vars=numeric_features)#列数据合并为行数据
print(f)
g = sns.FacetGrid(f, col="variable", col_wrap=6, sharex=False, sharey=False)#结构化多绘图网格,col_wrap=6-6列,是否共享x轴或者y轴
g = g.map(sns.distplot, "value", hist=False, rug=True)
sns.set()
#主要展现的是变量两两之间的关系
sns.pairplot(df_train[numeric_features],size = 2 ,kind ='scatter',diag_kind='kde')#对于特征使用散点图
plt.savefig('correlation.png')
plt.show()
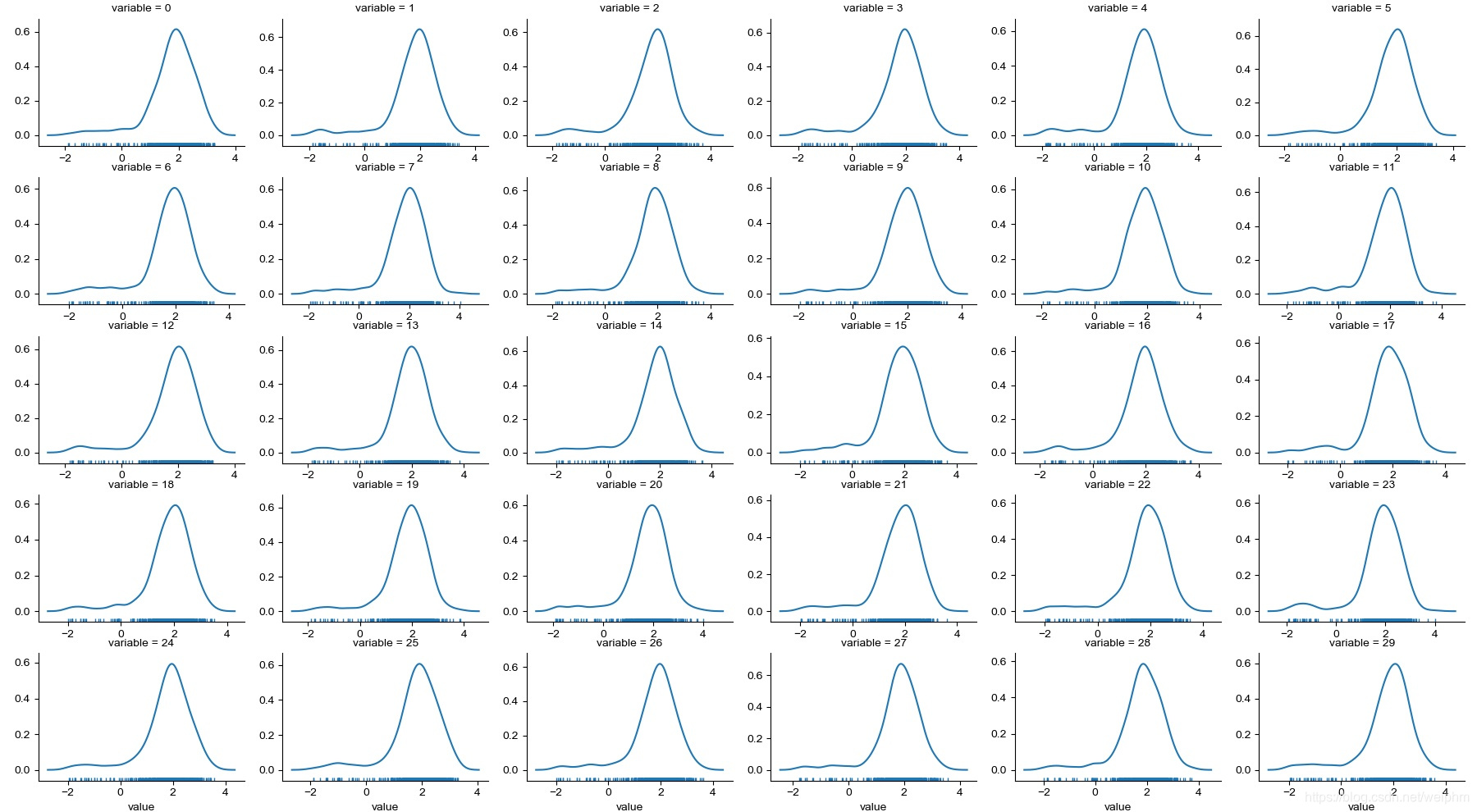

随后对数据进行PCA分析
df_train['y'] = y_train
#定义异常值点
x_outliers, x_inliers = py.utils.data.get_outliers_inliers(x_train,y_train)
n_inliers = len(x_inliers)
n_outliers = len(x_outliers)
sns.scatterplot(x=0, y=1, hue='y', data=df_train)
plt.show()
xx , yy = np.meshgrid(np.linspace(-10, 10, 200), np.linspace(-10, 10, 200))
#使用PCA
classifiers = {
'Principal component analysis (PCA)': PCA(n_components=2,contamination=outlier_fraction)
}
for i, (clf_name, clf) in enumerate(classifiers.items()):
clf.fit(x_train)
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
# get the prediction on the test data
clf_name = 'PCA'
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
# print(precision_score(y_train,y_train_pred))
sns.scatterplot(x=0, y=1, hue=y_train_scores, data=df_train, palette='RdBu_r')
plt.show()

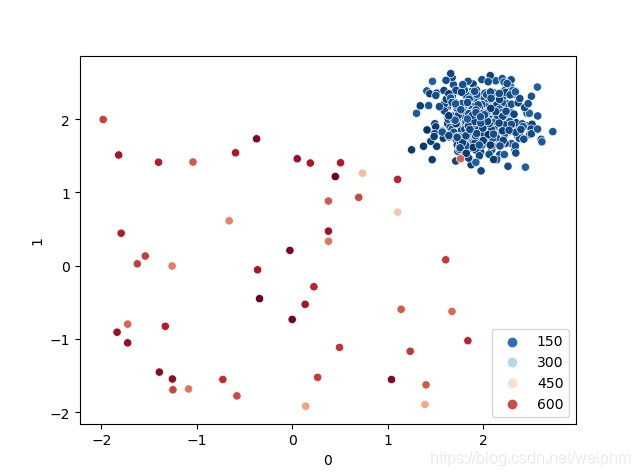
可见效果良好。
智能推荐
Docker 快速上手学习入门教程_docker菜鸟教程-程序员宅基地
文章浏览阅读2.5w次,点赞6次,收藏50次。官方解释是,docker 容器是机器上的沙盒进程,它与主机上的所有其他进程隔离。所以容器只是操作系统中被隔离开来的一个进程,所谓的容器化,其实也只是对操作系统进行欺骗的一种语法糖。_docker菜鸟教程
电脑技巧:Windows系统原版纯净软件必备的两个网站_msdn我告诉你-程序员宅基地
文章浏览阅读5.7k次,点赞3次,收藏14次。该如何避免的,今天小编给大家推荐两个下载Windows系统官方软件的资源网站,可以杜绝软件捆绑等行为。该站提供了丰富的Windows官方技术资源,比较重要的有MSDN技术资源文档库、官方工具和资源、应用程序、开发人员工具(Visual Studio 、SQLServer等等)、系统镜像、设计人员工具等。总的来说,这两个都是非常优秀的Windows系统镜像资源站,提供了丰富的Windows系统镜像资源,并且保证了资源的纯净和安全性,有需要的朋友可以去了解一下。这个非常实用的资源网站的创建者是国内的一个网友。_msdn我告诉你
vue2封装对话框el-dialog组件_<el-dialog 封装成组件 vue2-程序员宅基地
文章浏览阅读1.2k次。vue2封装对话框el-dialog组件_
MFC 文本框换行_c++ mfc同一框内输入二行怎么换行-程序员宅基地
文章浏览阅读4.7k次,点赞5次,收藏6次。MFC 文本框换行 标签: it mfc 文本框1.将Multiline属性设置为True2.换行是使用"\r\n" (宽字符串为L"\r\n")3.如果需要编辑并且按Enter键换行,还要将 Want Return 设置为 True4.如果需要垂直滚动条的话将Vertical Scroll属性设置为True,需要水平滚动条的话将Horizontal Scroll属性设_c++ mfc同一框内输入二行怎么换行
redis-desktop-manager无法连接redis-server的解决方法_redis-server doesn't support auth command or ismis-程序员宅基地
文章浏览阅读832次。检查Linux是否是否开启所需端口,默认为6379,若未打开,将其开启:以root用户执行iptables -I INPUT -p tcp --dport 6379 -j ACCEPT如果还是未能解决,修改redis.conf,修改主机地址:bind 192.168.85.**;然后使用该配置文件,重新启动Redis服务./redis-server redis.conf..._redis-server doesn't support auth command or ismisconfigured. try
实验四 数据选择器及其应用-程序员宅基地
文章浏览阅读4.9k次。济大数电实验报告_数据选择器及其应用
随便推点
灰色预测模型matlab_MATLAB实战|基于灰色预测河南省社会消费品零售总额预测-程序员宅基地
文章浏览阅读236次。1研究内容消费在生产中占据十分重要的地位,是生产的最终目的和动力,是保持省内经济稳定快速发展的核心要素。预测河南省社会消费品零售总额,是进行宏观经济调控和消费体制改变创新的基础,是河南省内人民对美好的全面和谐社会的追求的要求,保持河南省经济稳定和可持续发展具有重要意义。本文建立灰色预测模型,利用MATLAB软件,预测出2019年~2023年河南省社会消费品零售总额预测值分别为21881...._灰色预测模型用什么软件
log4qt-程序员宅基地
文章浏览阅读1.2k次。12.4-在Qt中使用Log4Qt输出Log文件,看这一篇就足够了一、为啥要使用第三方Log库,而不用平台自带的Log库二、Log4j系列库的功能介绍与基本概念三、Log4Qt库的基本介绍四、将Log4qt组装成为一个单独模块五、使用配置文件的方式配置Log4Qt六、使用代码的方式配置Log4Qt七、在Qt工程中引入Log4Qt库模块的方法八、获取示例中的源代码一、为啥要使用第三方Log库,而不用平台自带的Log库首先要说明的是,在平时开发和调试中开发平台自带的“打印输出”已经足够了。但_log4qt
100种思维模型之全局观思维模型-67_计算机中对于全局观的-程序员宅基地
文章浏览阅读786次。全局观思维模型,一个教我们由点到线,由线到面,再由面到体,不断的放大格局去思考问题的思维模型。_计算机中对于全局观的
线程间控制之CountDownLatch和CyclicBarrier使用介绍_countdownluach于cyclicbarrier的用法-程序员宅基地
文章浏览阅读330次。一、CountDownLatch介绍CountDownLatch采用减法计算;是一个同步辅助工具类和CyclicBarrier类功能类似,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。二、CountDownLatch俩种应用场景: 场景一:所有线程在等待开始信号(startSignal.await()),主流程发出开始信号通知,既执行startSignal.countDown()方法后;所有线程才开始执行;每个线程执行完发出做完信号,既执行do..._countdownluach于cyclicbarrier的用法
自动化监控系统Prometheus&Grafana_-自动化监控系统prometheus&grafana实战-程序员宅基地
文章浏览阅读508次。Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,_-自动化监控系统prometheus&grafana实战
React 组件封装之 Search 搜索_react search-程序员宅基地
文章浏览阅读4.7k次。输入关键字,可以通过键盘的搜索按钮完成搜索功能。_react search