总结:HBase原理篇-程序员宅基地
技术标签: 数据库 big data hbase HBase
目录
1、ZooKeeper,Master和 RegionServer协同工作
HBase的名字的来源于Hadoop database,即hadoop数据库,基于Google Bigtable的开源实现。
不同于一般的关系数据库,HBase是非结构化数据存储的数据库,而且它是基于列的而不是基于行的模式。利用Hadoop HDFS作为其文件存储系统,底层基于LSM数据结构进行存储,因此写入性能很强,读取性能较差。
利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。
一、什么是列式数据库?
详情看下:https://blog.csdn.net/coderising/article/details/100021718
列式数据库是针对行数据库而言的,行式数据库是以一行数据作为一个存储单元,而列式数据库是以一列数据为一个存储单元,针对hbase来说,一行数据的某一个列值就是一个存储单元。
其实上面这么说也不严谨,HBase是按照Rowkey顺序存储,一个Rowkey可能存储多行数据(比如有10列数据,其实HBase存的就是10行),如下所示:一个rowkey其实存储了多行的数据:

列式数据库与行式数据库特点
列式数据库:高压缩比
行式数据库:低压缩比
列式数据库与行式数据库分别适用什么场景?
列式数据库:更新少,表之间关联少,事务支持不好,插入多,简单查询
行式数据库:更新多,支持事务
二、架构
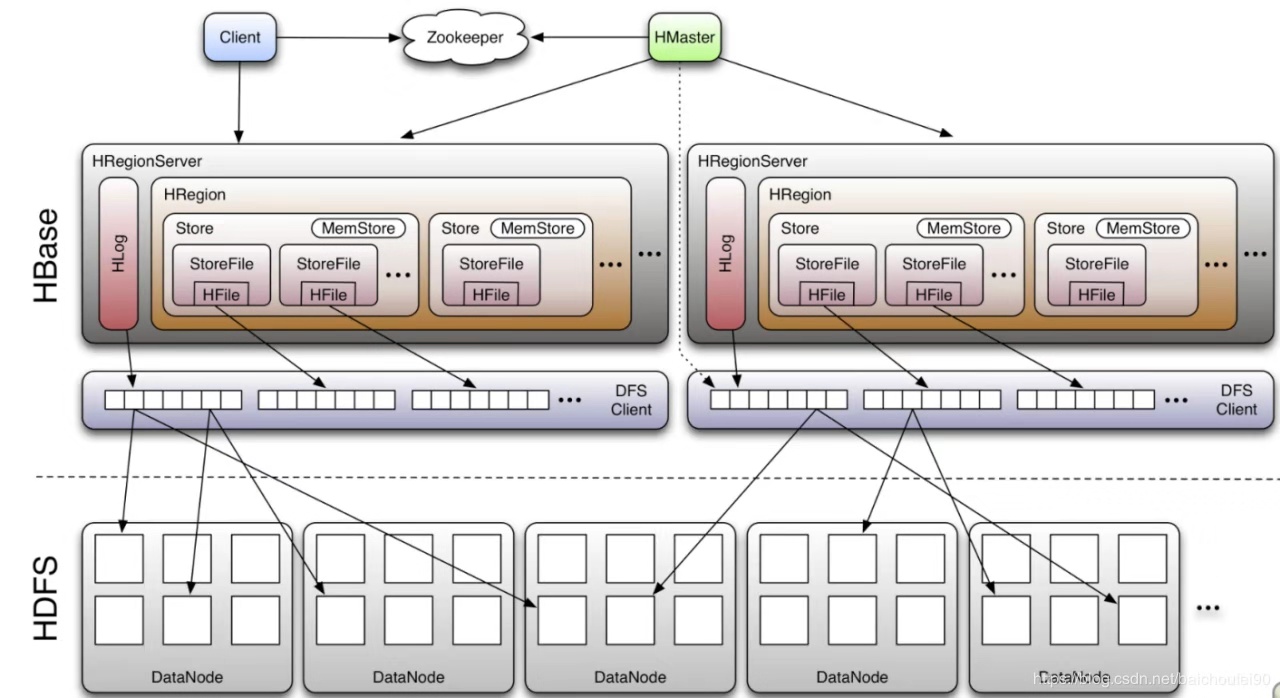
1、从架构看HBase与HDFS
HBase是基于强大的HDFS存储,HBase是通过DFS client去操作HDFS。详细参考:DFSClient技术内幕
所以,HBase其实就是通过SDK,将数据存储到HDFS。
2、HBase有WAL为什么还能存储的那么快?
WAL即预写日志。
从架构图可以看到,WAL的实现即HLog,HLog也是存储在HDFS。
基本原理是在数据写入之前首先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。之所以能够提升写性能,是因为WAL将一次随机写转化为了一次顺序写加一次内存写。
3、为什么要有WAL?
为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的MemStore和HLog
MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
4、HBase的后台服务程序有哪些?
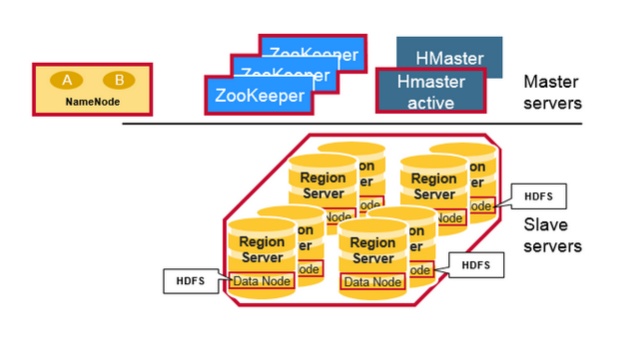
物理上看,HBase系统有3种类型的后台服务程序,分别是HRegionServer,HMaster和Zookeeper。
-
HRegionServer负责实际数据的读写。当访问数据时,客户端与HBase的RegionServer直接通信。
-
HMaster管理Region的位置,DDL(新增和删除表结构)。
-
Zookeeper负责维护和记录整个HBase集群的状态。
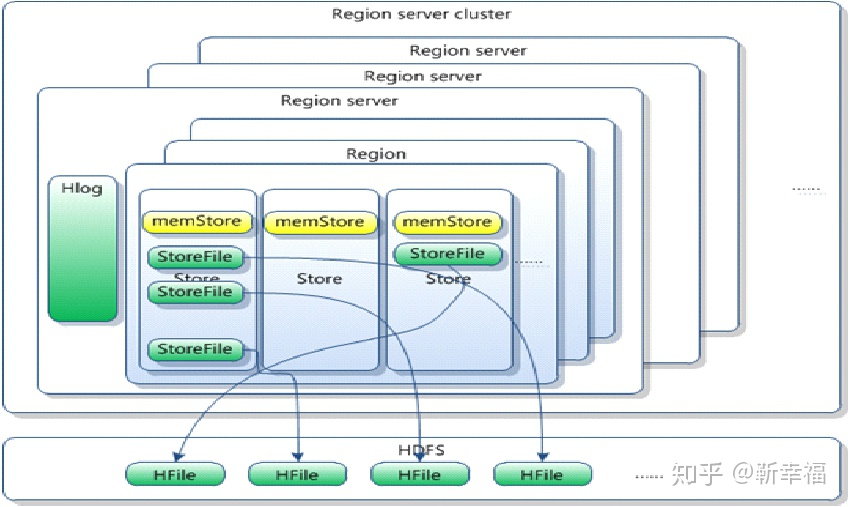
三、HBase RegionServer
1、HDFS与RS同节点部署情况
每个 RegionServer都把自己的数据存储在HDFS中, 如果一个服务器既是RegionServer又是HDFS的Datanode,那么这个RegionServer的数据会把其中一个副本存储在本地的HDFS中,加速访问速度。但是, 如果是一个新迁移来的Region,这个region的数据并没有本地副本,直到HBase运行compaction,才会把一个副本迁移到本地的Datanode上面。
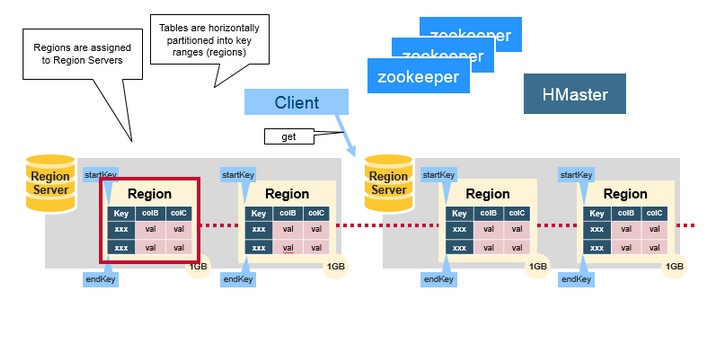
2、RegionServer与Region
HBase的表根据Row Key的区域分成多个Region。而RegionServer负责管理多个Region,RegionServer负责本机上所有region的读写操作。
一个RegionServer最多可以管理1000个region。
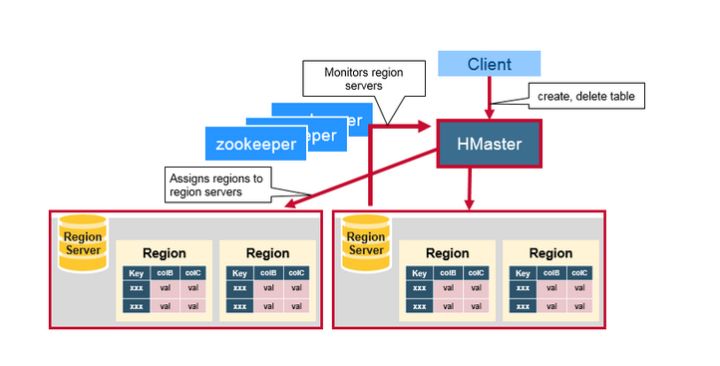
四、HMaster
HMaster主要负责分配region和操作DDL(如新建和删除表)等,HBase Master的功能:
- 协调Region server
- 在集群处于数据恢复或者动态调整负载时,分配Region到某一个RegionServer中
- 管控集群, 监控所有RegionServer的状态(实际是zookeeper监控RegionServer是否存活。HBase的master节点监控这些临时节点的是否存在,可以发现新加入RegionServer和判断已经存在的RegionServer宕机。)
- 提供DDL相关的API,新建(create),删除(delete)和更新(update)表结构。
五、ZooKeeper
Zookeepper是一个分布式的无中心的元数据存储服务。Zookeeper探测和记录HBase集群中服务器的状态信息。如果Zookeeper发现服务器宕机,它会通知HBase的master节点。在生产环境部署Zookeeper至少需要3台服务器, 用来满足Zookeeper的核心算法Paxos的最低要求。
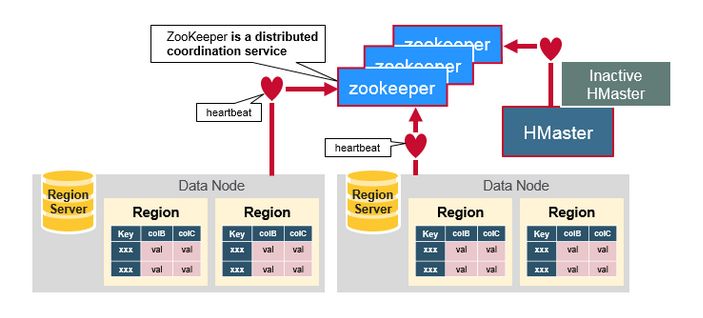
1、ZooKeeper,Master和 RegionServer协同工作
Zookeepr负责维护集群的memberlist,哪台服务器在线,哪台服务器宕机都由Zookeeper探测和管理。
Region server节点与HMaster集群节点主动连接Zookeeper,维护一个Session连接。这个session要求定时发送heartbeat,向Zookeeper说明自己在线,并没有宕机。
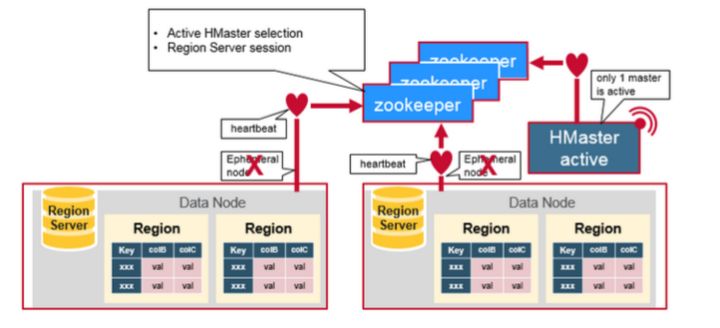
所有RegionServer都尝试连接Zookeeper, 并在这个session中建立一个临时节点(如果这个session断开,临时节点被自动删除)。HBase的master节点监控这些临时节点的是否存在,可以发现新加入RegionServer和判断已经存在的RegionServer宕机。
为了高可用需求,HBase的master也有多个,这些master节点也同时向Zookeeper注册临时节点。Zookeeper把第一个成功注册的master节点设置成active状态,而其他master node处于inactive状态。
如果Zookeeper规定时间内,没有收到active的master节点的heartbeat,连接session超时,对应的临时节也自动删除。之前处于Inactive的master节点得到通知, 马上变成active状态, 立即提供服务。
同样, 如果Zookeeper没有及时收到RegionServer的heartbeat,session过期,临时节点删除。HBase master得知RegionServer宕机,启动数据恢复方案。
六、其它基本概念
- Row Key:格式为byte array,是表中每条记录的“主键”,方便快速查找。Table中所有行都按照row key排列,因此row key的设计非常重要。
- Column Family:列族,拥有一个名称(string),包含一个或者多个相关列。每个column family存储在HDFS上的一个单独文件中。
- Column:属于某一个column family,列名定义为family:qualifier,其中qualifier可以是任意的字符串。每个column family可以有上百万个columns。
- Version Number:类型为Long,默认值是系统时间戳,可由用户自定义。
- Value(Cell):都是Byte array,没有类型。每个cell中的数据可以有多个版本,默认是3个。
- HFile:每个HFile存储的是一个表中一个列族的数据,也就是说,当一个表中有多个列簇时,针对每个列簇插入数据,最后产生的数据是多个HFile
-
Store:一个Store包含了一个MemStore和0个或多个StoreFile。其中MemStroe是一个内存数据结构,StoreFile是文件系统级别的数据结构。Store是由Region去管理的,用于维护列族的数据。 对于一个HBase的表,设计了几个列族,那么对于任何一个Region而言就会有几个Store。这也是HBase被称为列族式数据库的原因。 同时HBase会以Store大小来判断,是否需要去切分Region。
七、HBase内存数据存储结构
下图可以大致看出来:
1、rowkey的value是list数据结构,即有多列。
2、Column的value也是list数据结构,即每列有多个版本。

八、LSM tree
https://my.oschina.net/weiweiblog/blog/3121923
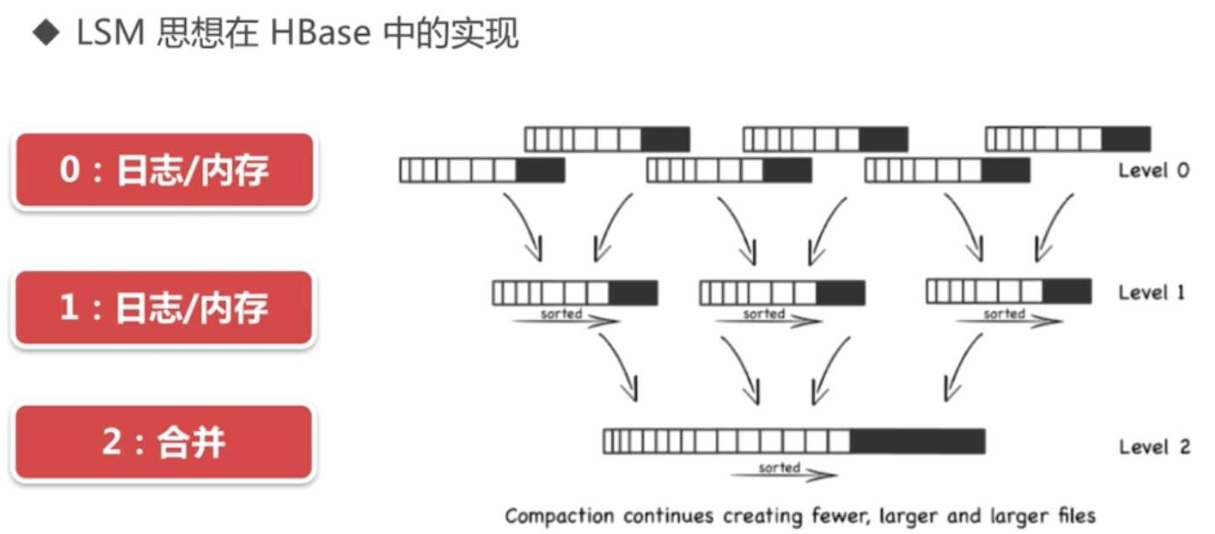
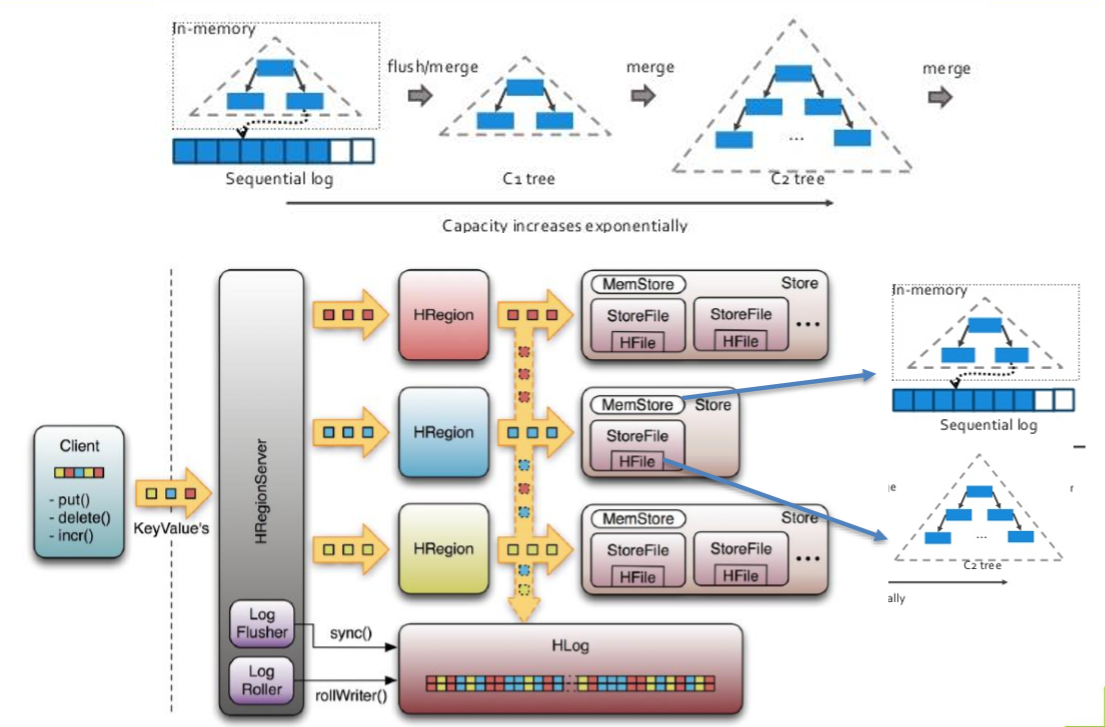
九、HBase的强一致性和HDFS的多副本
假设HDFS的副本存储策略,也就是dfs.replication的值为3(默认值就是3)
这样所有存储在HDFS上的文件都有3个副本。那么,HBase的存储实例,也就是HFile也有3个副本。那么当某一个RegionServer崩溃时,并不用担心数据的丢失,因为数据是存储在HDFS上,哪怕崩溃的RegionServer所在的DataNode上有一个副本,在其他DataNode上也还有2个副本。
那么也许你要问,既然有3个副本,如何保证HBase的强一致性呢?
HFile是已经持久化在磁盘上了,而HFile是不能改变的(这个时候暂时把删除数据这个操作放到一边,相关内容请看下面的Note),一旦在某一个DataNode上生成一个HFile后就会异步更新到其他两个DataNode上,这3个HFile是一模一样的。
那也许你又要问,那我的数据是不断更新当中啊!
更新的数据是放在Memstore,只有当Memstore里的数据达到阈值,或者时间达到阈值,就会flush到磁盘上,生成HFile,而一旦生成HFile就是不可改变的(compaction,split就是后话啦)。
这里再提一下WAL的一致性
WAL是Write-Ahead logging,这个是Memstore里的数据在RegionServer崩溃时得以恢复的保证。WAL的实现是HLog,HLog也是存储在HDFS上的,所以HRegionServer崩溃了也不会导致HLog的丢失,它也有备份。
每一次更新都会调用写日志的sync()方法,这个调用强迫写入日志的更新都会被文件系统确认。
| 当前的sync()的实现是管道写,也就是HDFS写数据、生成副本的默认方式,这意味着当修改被写入时,它会被发送到第一个DataNode进行存储。一旦成功,第一个DataNode就会把修改发送到另一个DataNode来进行相同的工作。只有3个DataNode都已经确认了写操作,客户端才被允许继续进行; 另一种存储修改的方法是多路写,也就是写入被同时送到3台机器上。当所有主机确认了写操作后,客户端才可以继续。 两种方法的优缺点: 管道写需要时间去完成,所以它有很高的延迟,但是它能更好地利用网络带宽;多路写有着比较低的延迟,因为客户端只需要等待最慢的DataNode确认(假设其余都已成功确认)。但是写入需要共享发送服务器的网络带宽,这对于有着很高负载的系统来说是一个瓶颈。 目前有正在进行的工作能让HDFS支持上面两种方式。 |
Note:当客户端提交删除操作的时候,数据不是真正的删除,只是做了一个删除标记(delete marker,又称母被标记),表明给定行已经被删除了,在检索过程中,这些删除标记掩盖了实际值,客户端读不到实际值。直到发生compaction的时候数据才会真正被删除。
WAL默认是开启的,可以使用下边的语句关闭:
Mutation.setDurability(Durability.SKIP_WAL)
Put/Append/Increment/Delete都是Mutation的子类,都有setDurability。关闭WAL可以让数据导入更快一些,但是一般不建议这么做。
不过有一个折中方案,异步写入WAL来实现提高写入性能;正常的WAL(同步)都是在数据来到Region时候先放入内存中,这些改动会立刻被写入WAL,就算只有一个改动也会调用HDFS接口来同步数据。而异步写入会等到条件满足的时候才写入WAL,这里主要使用hbase.regionserver.optionallogflushinterval,也就是每隔多长时间将数据写入WAL,默认1s。设置方式也是setDurability:
Mutation.setDurability(Durability.ASYNC_WAL)
但是异步写入没有事务保证,所以除非对系统性能要求极高,对数据一致性要求不高,并且系统的性能总是出现在WAL上的时候才需要考虑异步写入。
十、Storefile和Hfile
- HStore对应了table中的一个CF列族。
- HStore包含MemStore和StoreFile(底层实现是HFile)。
- 当其中一个CF的Memstore达到阈值flush时,所有其他CF的也会被flush(所以会产生很多小文件,需要合并),每次Memstore Flush,会为每个CF都创建一个新的StoreFile,每个CF同时刷新的目的是为了一个region的数据存储在一个服务器节点上。
- 由于(3)的原因,导致了StoreFile的大小不一样,当StoreFile文件数量增长到一定阈值,会触发compact操作,将多个StoreFile合并成一个StoreFile
- StoreFile以HFile格式保存在HDFS上。HFile是Hadoop的二进制格式文件。实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile。
HFile文件的特点:
1)HFile由DataBlock、Meta信息(Index、BloomFilter)、Info等信息组成。
2)整个DataBlock由一个或者多个KeyValue组成。(注:value是指一个单元格,key指的并不是rowkey)
KeyValue: HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:
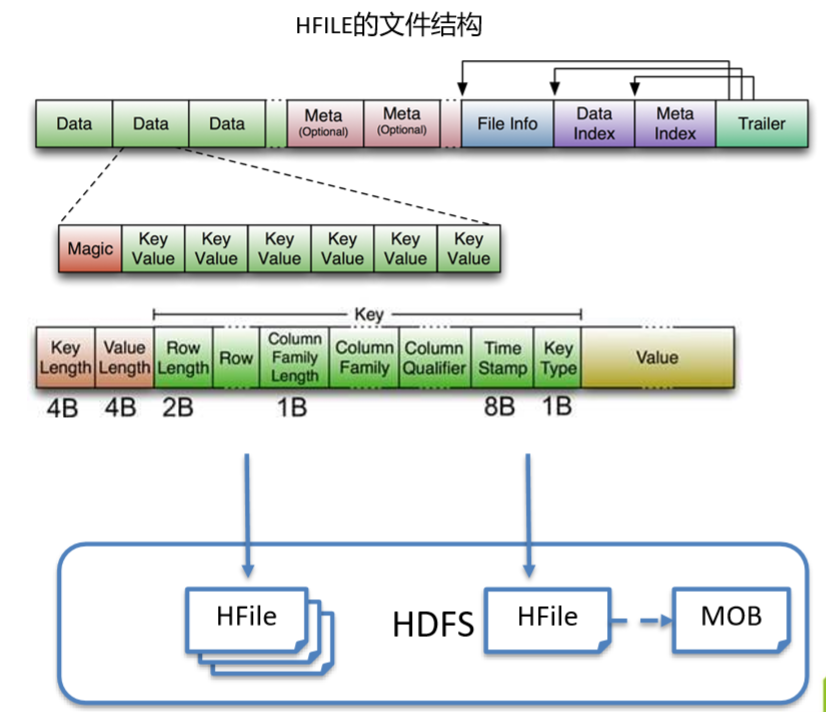
开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,Row Length表示RowKey的长度,Row指的是 RowKey即行键,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
结论:key中包含rowkey信息,列族信息,列信息,时间戳,他们确定唯一的cell单元.
3)在文件内按照Key排序。
十一、HBase与其它nosql数据库对比
es:倒排索引,
mysql:B+tree
hbase:LSM-Tree
redis:
tidb:
十二、Hbase在系统中的使用情况
1、入HBase流程
通过Flink任务消费Kafka数据,批量写入HBase;
Flink任务名称:Hubble2HBaseByESJob
下发任务的名称:Hubble2hbase_sdk_copy_copy
任务资源配置:
TaskManager个数: 50
TaskManager内存(G): 5G
JobManager内存(G): 5G
TaskManager Slot个数: 2
2、遇到的问题:消费延时,造成Kafka数据积压
原因:
1、定期小文件合并成大文件的时候,会造成写入能力降低,从而导致Kafka数据积压(目前HBase服务方一个月合并一次数据)
2、大集群下其它HBase服务影响了我们的HBase服务,这也比较常见
3、写入热点
十三、HBase数据的删除和更新
追加。
删除操作:通过新增一条一模一样的数据,但是key type会标记成Delete状态。等到进行compact操作的时候会进行真正的删除操作。
更新操作:也会重新插入一条新的数据来代替在原来数据上修改。新的数据的timestamp会大于老的数据,这样读取的时候,判断时间戳就可以取出最新的数据了。
由于HBase底层依赖HDFS,对于HBase删除操作来说,HBase无法在查询到之前的数据并进行修改,只能顺序读写,追加记录。因此为了更新或删除数据,HBase会插入一条一模一样的新的数据,但是key type会标记成Delete状态,以标记该记录被删除了。在读取的时候如果取到了是Delete,而且时间是最新的,那么这条记录肯定是被删掉了。
每一个单元格或者KeyValue在HFile中的格式如下:
row length + row key + family length + column family + column qualifier + timestamp + key type
同样,进行更新操作的时候,也会重新插入一条新的数据来代替在原来数据上修改。新的数据的timestamp会大于老的数据,这样读取的时候,判断时间戳就可以取出最新的数据了。
由于HBase这样的删除和更新机制,如果后面没有一个对于过期数据处理的机制,会导致过期数据越来越大,因此后面的compact操作中的major compact就顺便将过期的数据删除掉了。
对于标记为删除的数据,直接删除。对于不同时间戳的多条数据,根据其保存的最大版本数据,删除过期的数据。当然做major compact的原因不仅仅能够删除过期数据,还有其他原因,比如合并数量过多的HFile,具体机制以后再分析。
参考文章:
智能推荐
《构建之法》第一次作业-程序员宅基地
文章浏览阅读134次。这个作业属于哪个课程这个作业要求在哪里我在这个课程的目标是理解软件开发流程,为以后的项目开发做好知识储备这个作业在哪个具体方面帮助我实现目标通过大量的阅读和查阅资料对专业有更深的认知,借鉴前辈们的经验之谈来更明确自己的想法我的博客地址icjy1.建立博客,介绍自己这是我的第一篇博客,而此时的我已经是一名软件工程专业的大三学生了。虽说读..._刘伊凡北航
华为鸿蒙能与车互联吗,华为鸿蒙上车,关于车联网的想象有多少?-程序员宅基地
文章浏览阅读6.1k次。尚未生在江湖,但江湖都是你的传说。这句话用来形容华为的鸿蒙 OS 再合适不过了。于是在众人瞩目中,华为鸿蒙系统终于揭开了面纱。8 月 9 日,华为消费者业务今天在其全球开发者大会上正式发布了基于微内核的面向全场景的分布式操作系统——鸿蒙 OS,其英文名 HarmonyOS,意为 " 和谐 ",华为消费者业务 CEO 余承东表示,是希望给世界带来更多和谐和方便," 未来的操作系统应当是微内核架构,可..._鸿蒙系统能车载安卓系统联网吗
OpenCV中的随机数与随机种子_opencv rand-程序员宅基地
文章浏览阅读1.8k次,点赞3次,收藏7次。我们先从在C/C++中的随机数与随机种子说起。rand()、srand()rand()可以生成一个0~RAND_MAX之间的一个随机数,返回值是一个unsigned int类型值。rand函数不是真正的随机数生成器,而srand()会设置供rand()使用的随机数种子。如果你在第一次调用rand()之前没有调用srand(),那么系统会为你自动调用srand()。而使用同种子相同的数调用..._opencv rand
三天刷完《剑指OFFER编程题》--Java版本实现(第二天)_剑指offer java版-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏4次。正在更新中。。。。。。。。。剑指offer --Python版本的实现:剑指offer(1/3)第一大部分剑指offer(2/3)第二大部分剑指offer(3/3)第三大部分27.字符串的排列输入一个字符串,按字典序打印出该字符串中字符的所有排列。例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba。输入描述:输入一个字符串,长度不超过9(可能有字符重复),字符只包括大小写字母。递归法,问题.._剑指offer java版
计算机视觉迎来GPT时刻!UC伯克利三巨头祭出首个纯CV大模型!-程序员宅基地
文章浏览阅读282次。点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【视觉和Transformer】微信交流群扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文,强烈推荐!在CVer微信公众号后台回复:LVM,即可下载论文pdf和代码链接!快学起来!转载自:机器之心仅靠视觉(像素)模型能走多远?UC 伯克利、约..._三巨头视觉大模型
qcc514x-qcc304x调试笔记-PIO相关操作_qcc304x 注册中断-程序员宅基地
文章浏览阅读720次,点赞2次,收藏5次。相关PIO接口#define PIOS_PER_BANK 32U#define PioCommonPioBank(_pio) ((_pio) / PIOS_PER_BANK)#define PioCommonPioMask(_pio) (1UL << ((_pio) % PIOS_PER_BANK))uint32 PioSetDir32Bank(uint16 bank, uint32 mask, uint32 dir);uint32 PioSet32Bank(uint16_qcc304x 注册中断
随便推点
报名进入倒计时!让表格识别大赛承包您的硬核夏日(附保姆级参赛锦囊)_表计识别算法比赛-程序员宅基地
文章浏览阅读232次。截至9月8日 万元奖金+入职机会!好未来表格识别大赛自6月拉开序幕,来自全球各地的232+支队伍加入了这场技术派对,近300位社会各界的开发者们在云端切磋算法技艺,期待给这个夏天留下最硬核的记忆!目前赛程已过半,报名截至9月8日,盼君入席!只有真实的行业场景,才能考验开发者真正的实力!表格在教育场景中分布广泛,种类繁多。对表格结构的还原和内容的识别,能帮助计算机更好的理解表格,在教学内容生产、智能解答等场景下,具有非常重要的应用价值。本次大赛的赛题聚焦于教育场景下的表格识别技术,提供教育场景..._表计识别算法比赛
Ubuntu 应用之 截图工具-flameshot_ububtu用libreoffice截图-程序员宅基地
文章浏览阅读707次,点赞4次,收藏3次。Ubuntu 18自带有截图工具,但是使用方式以及使用功能都不是很理想。还好在GitHub上有flameshot这么一款强大的linux截图工具。下载地址:https://github.com/flameshot-org/flameshot直接下载“Download zip”安装方式:下载后打开终端,具体安装命令如下:sudo apt-get install flameshot启动后,长成这个样子,每一个紫色小圈圈都代表一个功能, 是不是很强大如果觉得每次启动不方._ububtu用libreoffice截图
解决“ ModuleNotFoundError: No module named ‘tensorflow.examples‘ “_modulenotfounderror: no module named 'tensorflow.e-程序员宅基地
文章浏览阅读1.2w次,点赞5次,收藏31次。这个问题是我在用tensorflow做mnist数据集案例,程序在pycharm 2019.3.1运行时出现的问题.原因是tensorflow中没有examples解决方法首先找到对应tensorflow的文件,我的是在D:\python3\Lib\site-packages\tensorflow(python的安装目录),进入tensorflow文件夹,发现没有examples文件夹。我们可以进入github下载:https://github.com/tensorflow/tensorflow_modulenotfounderror: no module named 'tensorflow.examples
【转】在ubuntu12.04中安装wine和sourceinsight-程序员宅基地
文章浏览阅读46次。PS:用wine其实还可以在Linux下运行其他Windows软件,比如BeyondCompare,过程是一样的原文网址:http://www.2cto.com/os/201408/322370.html1.安装winesudo apt-get install wine2.安装source insight将source insight安装的可执行文件复制到ubuntu...
Javascript初级教程(适合新手)_js入门教程-程序员宅基地
文章浏览阅读1.7k次。1)定义变量的三要素 :var 变量名 = 初始化值;2)定义所有的变量都是var,而且var可以省略不写!3)js中,变量可以重复定义的,后面的值将前面的值覆盖!在js中定义函数的格式function 函数名(参数名1,参数名2,....){完成的函数的逻辑return 结果;//返回结果调用函数:赋值调用:var 变量名= 函数名(实际参数1,实际参数2..)以下为简单的函数实例var m = prompt("请输入一个数")_js入门教程
GTC 2024 火线评论:DPU 重构文件存储访问_dpu分布式存储-程序员宅基地
文章浏览阅读874次,点赞11次,收藏9次。在多样化的 GPU 存储类型的利用上,不管是块存储的 NVMe 卷作为节点内的高速缓存,还是共享文件存储作为 CPU/GPU 内存的全局缓存存储,最终通过基于对象存储的数据湖来统一治理,这些存储类型的需求和定位都跟 XSKY 的产品定位和路线图高度符合。对于国内领先的分布式存储厂商来说,我们同样认为,不仅是 Nvidia BlueField 系列产品可以提供这样的方式,这样的需求应该可以在普遍的 DPU 产品中实现并被利用,有效的提高 DPU 在存储协议上的多样化支持,并带来共享文件存储的安全性所需。_dpu分布式存储