Netty 1-程序员宅基地

可以越过HTTP/UDP/TCP 直接操作ip层 数据链路层 可以实现的
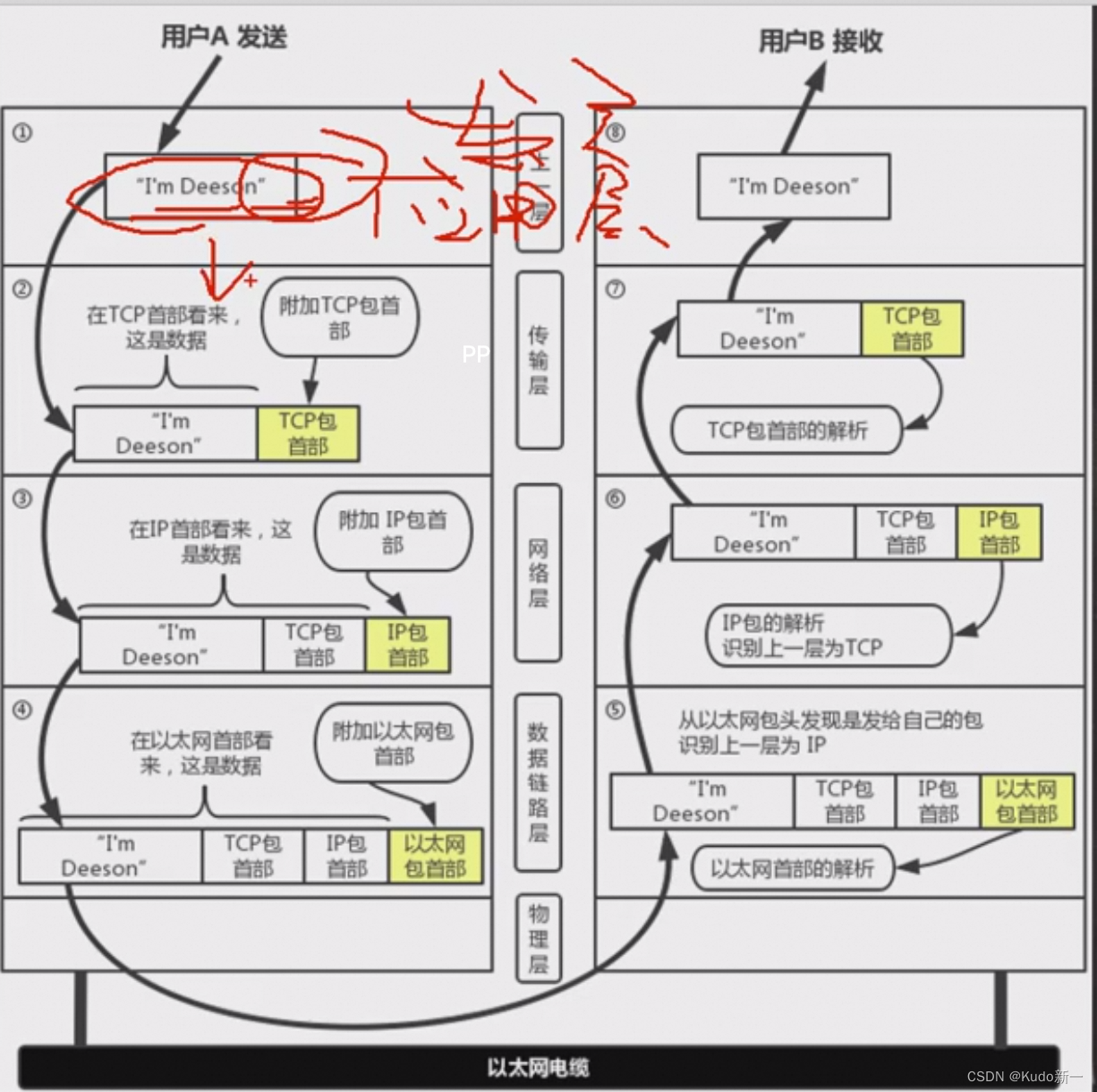
信息传送过程:
补充:
Mac地址和硬件是绑定的
DHCP服务器负责动态分配ip地址,通过ARP协议广播,请求ip地址
端口工作在传输层
因为存放端口号只有2字节16位,端口号为0表示本机

客户端分配的端口号从10000开始,随机分配。
这个说法不对,除了tcp=6协议号,4元组确定tcp连接【唯一性】,和端口没有半毛钱关系所以能保持百万连接,理论上最大2^32 * 2^16
那客户端只能保持65535个TCP连接对吗?
客户端一个端口号是可以复用的 支持连接不同服务器 因为目标ip地址都是不一样的 所以这个说法也是错的

三次握手
TCP为什么可靠?
因为连接的双方都必须要维护一个序列号,防止丢包,丢包了就要进行重传【有超时重传机制(与RTT有关)、快速重传、滑动窗口、keep-alive】
如果三次握手改成2次可以吗?
谢希仁版《计算机网络》中的例子是这样的,“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”
亦或者客户端无法确定服务端有没有收到自己的请求。
发起握手都是客户端,接收握手都是服务器
1.客户端发送的报文有什么内容?
SYN=1,seq=x,进入SYN_SENT状态;
2.服务器发送的报文有什么内容?
SYN=1,ACK=1,ack_no=x+1,seq=y,进入SYN_REVD状态;
3.客户端发送的报文有什么内容?
ACK=1,ack_no=y+1,进入连接建立状态;
服务器收到后也进入连接建立状态;
之后就可以通信了


TCP3次握手漏洞
一旦连接满了就会拒绝所有连接,DDOS一种。

特性:
流量控制、全双工、滑动窗口、RTT【超时重传】【MYSQL是应用层的半双工】
Http是应用层协议,要基于TCP协议
丢包可能:路由协议RIP默认15跳最远,16跳即为不可达
四次挥手
发起挥手可以是客户端也可以是服务器

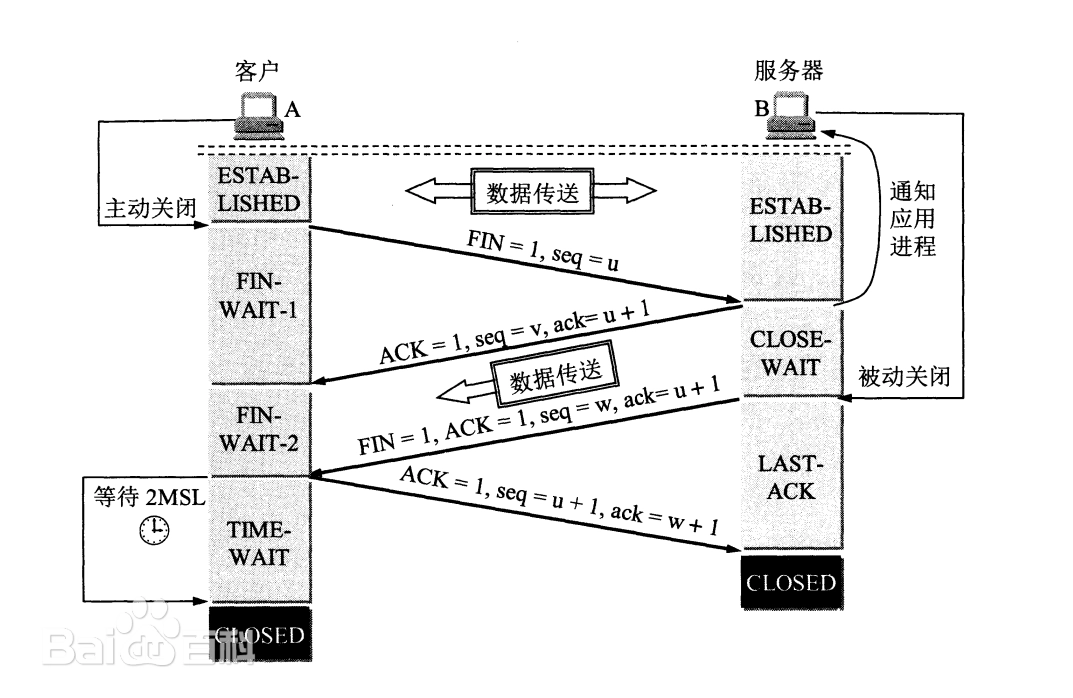
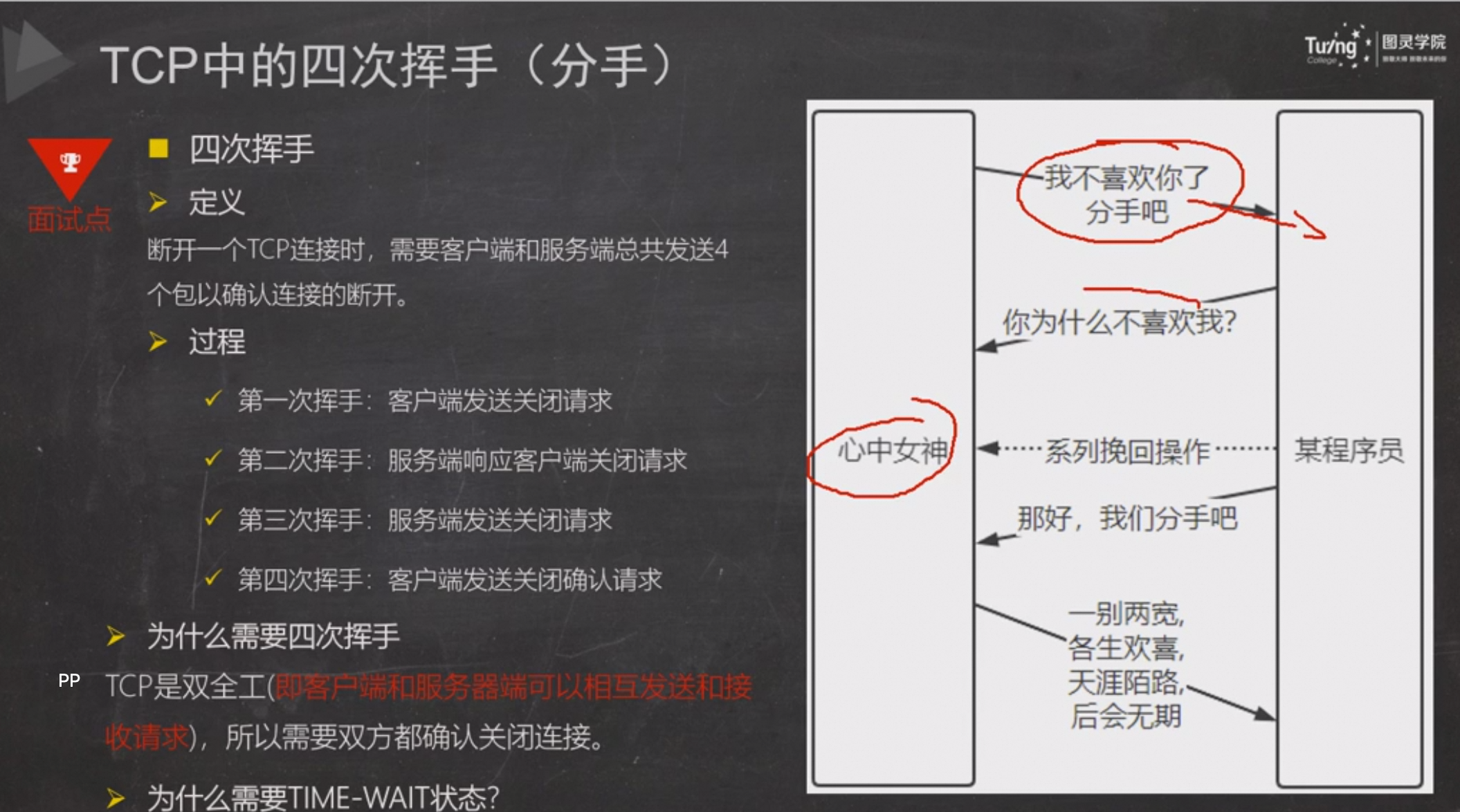
为什么要四次挥手?
关键就在于FIN标志位
关键在于TCP连接是双向的,每个方向必须单独进行关闭。在第二次挥手时,即使接收方此时也准备好关闭连接,它也不能将自己的FIN和对之前FIN的ACK合并为一个单一的段,因为它需要给前一个FIN一个单独的ACK作为响应,以确保连接的另一端知道其FIN已被成功接收。
小贴士:当然如果对方没有消息要发送可以将二三步骤合二为一

为什么需要TIME-WAIT状态?
表示收到了对方的FIN报文,并发送出了ACK报文【因为有可能丢失 对方就需要重发FIN报文 然后我们也就需要重发ACK报文】,就等2MSL【2*IP报文在因特网的最长存活时间】后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。 同时还有避免报文混乱情况,上一次的报文被新的TCP连接接收到了
为什么Mysql产生大量TIME-WAIT状态?【只产生于主动关闭连接这一端】
程序代码中没有主动close连接,导致服务器端主动关闭连接,所以导致服务器大量处于TIME-WAIT状态,连接没被释放,资源被耗尽。
在Navicat关闭mysql的时候并不是在TCP层的关闭,而是mysql应用层的关闭,然后mysql收到客户端的命令后,主动发起关闭。

UDP协议
使用广泛:
DNS域名服务器、视频/音频通话、

UDT【TCP能做的不能做的都做了】

QUIC【基于UDP】


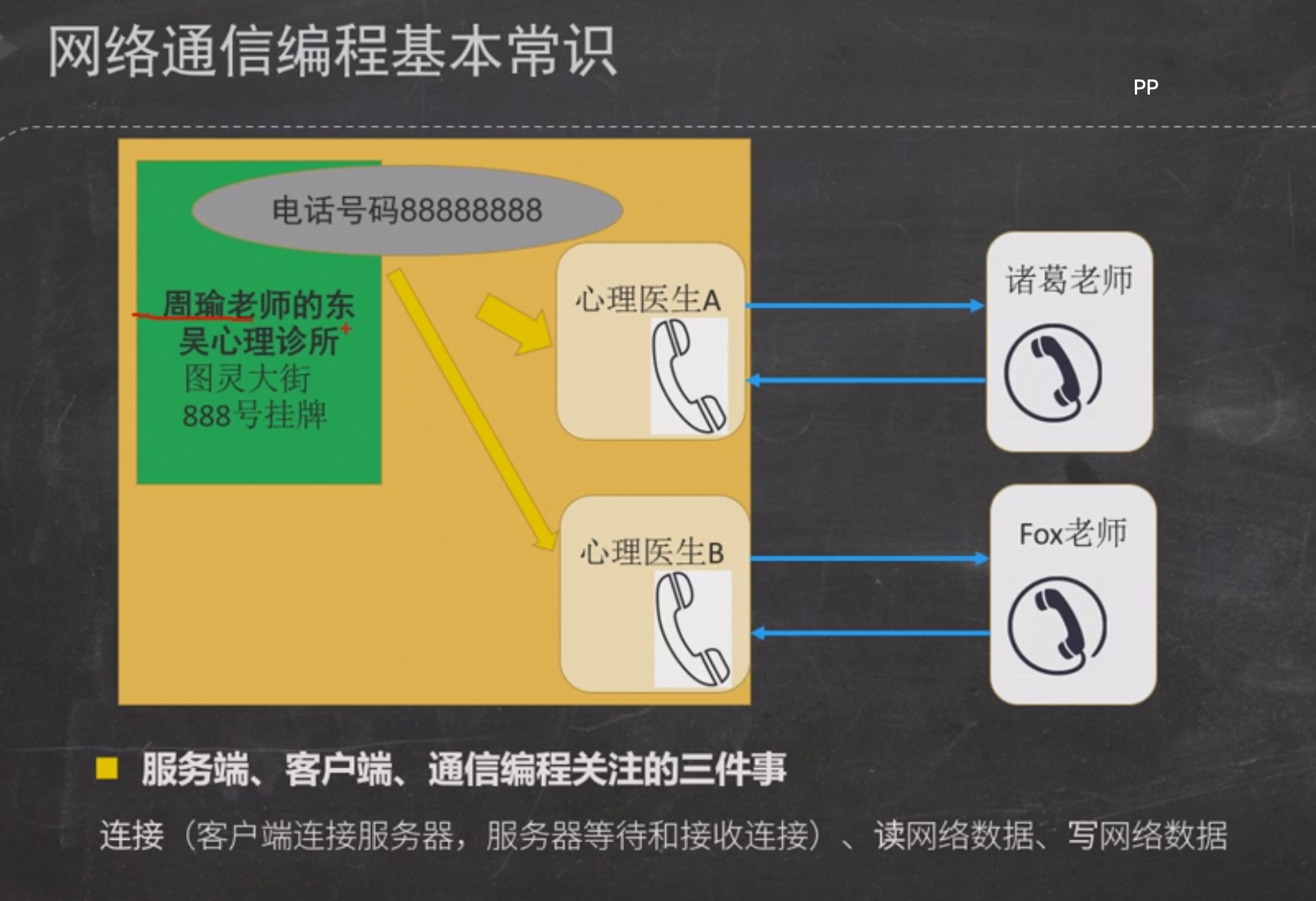
Socket

对服务端来说,ServerSocket只是个场所,不负责读写,只负责接收客户端的连接【东吴心理诊所】,需要绑定某个ip地址【要在888大街挂牌】,还要绑定一个端口【电话号码88888888】,会新启动一个个的socket来和客户端通信【心理医生A/B】
BIO【面向流的 输入/输出流】
阻塞IO【
- ServerSocketChannel.accept 会在没有连接建立时让线程暂停
- SocketChannel.read 会在通道中没有数据可读时让线程暂停
- 等待数据写入完成:当服务器向客户端发送数据时,如果客户端读取数据的速度慢或者网络缓慢,服务器线程会在
write方法调用上阻塞,直到所有数据被发送完毕。
】
accept()接收客户端的连接,accept - 服务器端成功接受客户端连接时触发的事件
客户端有个socket会专门发起连接操作,ServerSocket接收连接后产生新的socket和客户端的socket通信

服务器代码

客户端代码
服务端改进
服务器放在一个线程里做所有事肯定是不合适的,于是接收到一个客户端连接就新启动一个线程

改进2:一个线程维护一个客户端
accept()返回值是个Socket,也就是服务器和客户端通信的那个Socket【缺点:1w个客户端要启动1w个线程】

改进3:线程池版本【伪异步IO】
缺点:同时处理的线程数就被线程池的最大线程数限制死了,同时阻塞模式下,线程仅能处理一个连接

NIO
NIO 非阻塞IO【JDK1.4后加入】
一、三大组件简介
Channel【数据传输双向通道】与Buffer【内存缓冲区 暂存Channel数据】
Java NIO系统的核心在于:通道(Channel)和缓冲区(Buffer)。通道表示打开到 IO 设备(例如:文件、套接字)的连接。若需要使用 NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理
简而言之,通道负责传输,缓冲区负责存储
常见的Channel有以下四种,其中FileChannel主要用于文件传输,其余三种用于网络通信
- FileChannel【文件传输】
- DatagramChannel【UDP编程】
- SocketChannel【TCP数据传输通道 服务器/客户端都能用】
- ServerSocketChannel【TCP数据传输通道 服务器专用】
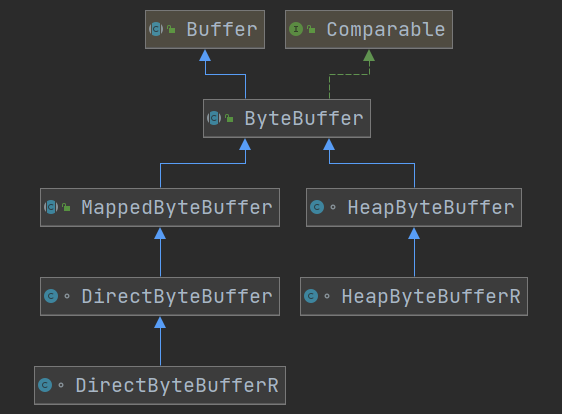
Buffer有以下几种,其中使用较多的是ByteBuffer
- 【抽象类】ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
1、Selector【选择器】
在使用Selector之前,处理socket连接还有以下两种方法
使用多线程技术【NIO出现之前 怎么开发服务器端程序】
为每个连接分别开辟一个线程,分别去处理对应的socke连接
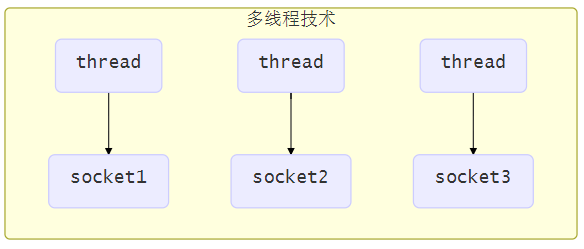
这种方法存在以下几个问题
- 【Windows默认一个线程占用1MB线程 如果来1000个客户端就1个G】内存占用高
- 每个线程都需要占用一定的内存,当连接较多时,会开辟大量线程,导致占用大量内存
- 线程上下文切换成本高
- 只适合连接数少的场景
- 连接数过多,会导致创建很多线程,从而出现问题
使用线程池技术
使用线程池,让线程池中的线程去处理连接
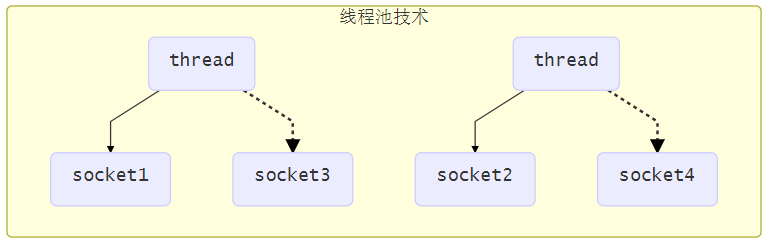
这种方法存在以下几个问题
- 阻塞模式下,线程仅能处理一个连接
- 线程池中的线程获取任务(task)后,只有当其执行完任务Socket1之后(断开连接后),才会去获取并执行下一个任务Socket3
- 若socket连接一直未断开,则其对应的线程无法处理其他socket连接【即使该Socket什么操作都没做 没有任何读写操作】
- 仅适合短连接场景
- 短连接即建立连接发送请求并响应后就立即断开,使得线程池中的线程可以快速处理其他连接
- 早期Tomcat就采取线程池版阻塞设计,因为http连上去就发个请求返回响应就断开了
使用选择器
selector 的作用就是配合一个线程来管理多个 channel(fileChannel因为是阻塞式的,所以无法使用selector),获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,当一个channel中没有执行任务时,可以去执行其他channel中的任务,线程始终有活干。适合连接数多,但流量较少的场景
一旦一个事件发生了,Selector就会配合一个线程,让线程来负责读写操作,Channel是工作在非阻塞模式下。第
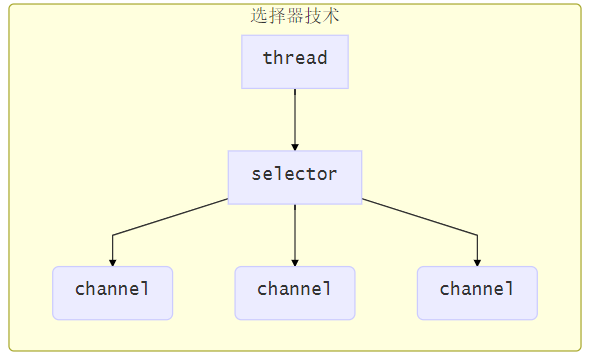
若事件未就绪,调用 selector 的 select() 方法会阻塞线程,直到 channel 发生了就绪事件。这些事件就绪后,select 方法就会返回这些事件交给 thread 来处理
2、ByteBuffer
使用案例
使用方式
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- flip会使得buffer中的limit变为position,position变为0
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或者compact()切换至写模式
- 调用clear()方法时position=0,limit变为capacity
- 调用compact()方法时,会将缓冲区中的未读数据压缩到缓冲区前面
- 重复以上步骤
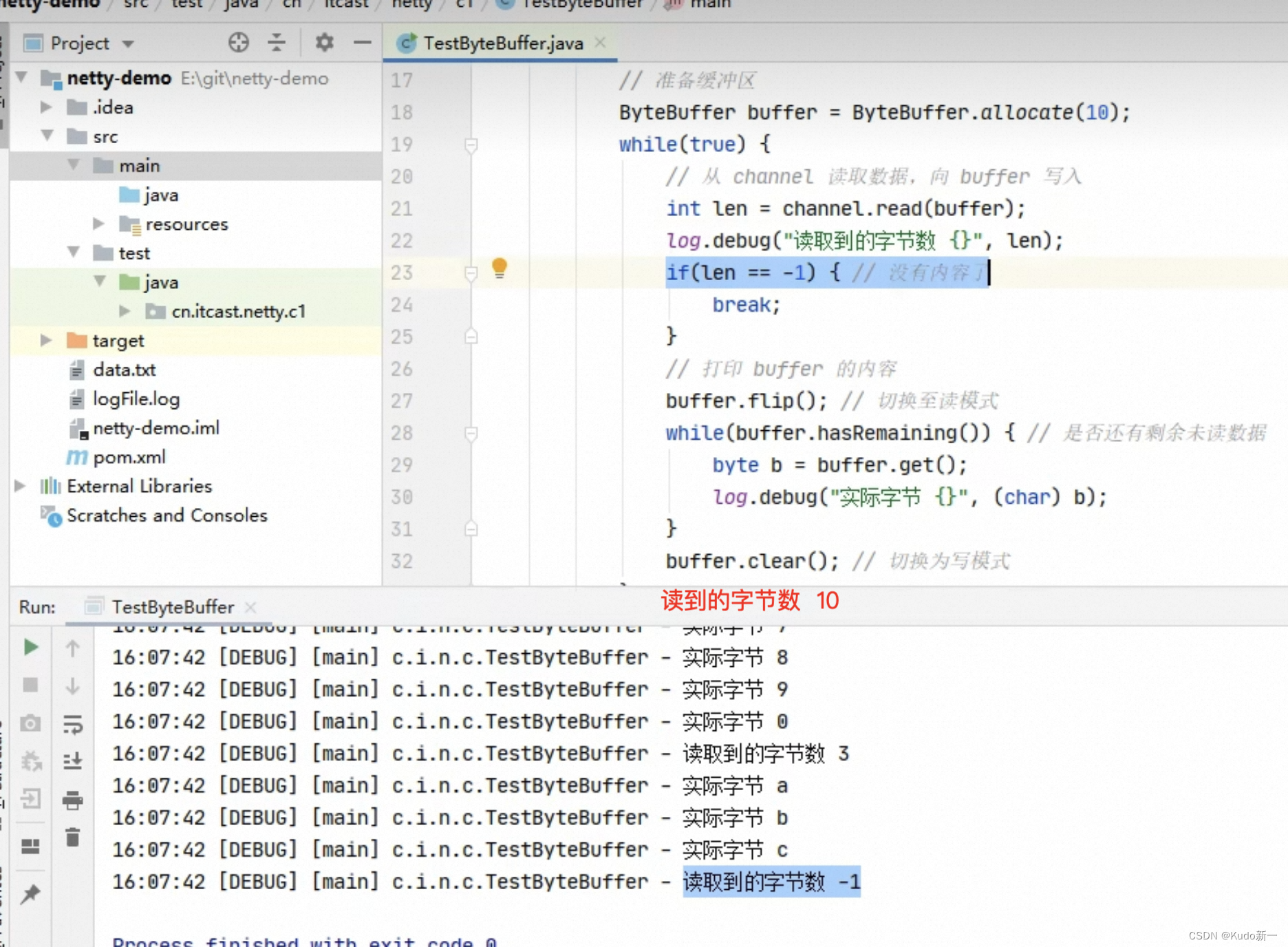
使用ByteBuffer读取文件中的内容
public class TestByteBuffer {
public static void main(String[] args) {
// 获得FileChannel
try (FileChannel channel = new FileInputStream("stu.txt").getChannel()) {
// 获得缓冲区 ByteBuffer不能去new,要用静态方法来获得 划分一块内存指定大小10字节
ByteBuffer buffer = ByteBuffer.allocate(10);
int hasNext = 0;
StringBuilder builder = new StringBuilder();
// 从Channel读取数据 然后写入buffer 分多次读取 如果读到-1表示结束了
while((hasNext = channel.read(buffer)) > 0) {
// 切换至读模式 不切读不出来数据的 limit=position, position=0
buffer.flip();
// 检查buffer中是否还有剩余数据
while(buffer.hasRemaining()) {
// 每次读一个字节
builder.append((char)buffer.get());
}
// 切换成写模式 不切写不进去 position=0, limit=capacity
buffer.clear();
}
System.out.println(builder.toString());
} catch (IOException e) {
}
}
}
打印结果
0123456789abcdef

核心属性

切换为读模式后,position重新指向0,limit也变为4【因为上面就只写入了4个字节】

读完后,如果有新记录要写了,再调用一次clear,切换到写模式,指针回到0位置,limit表示有这么多空白可以写,
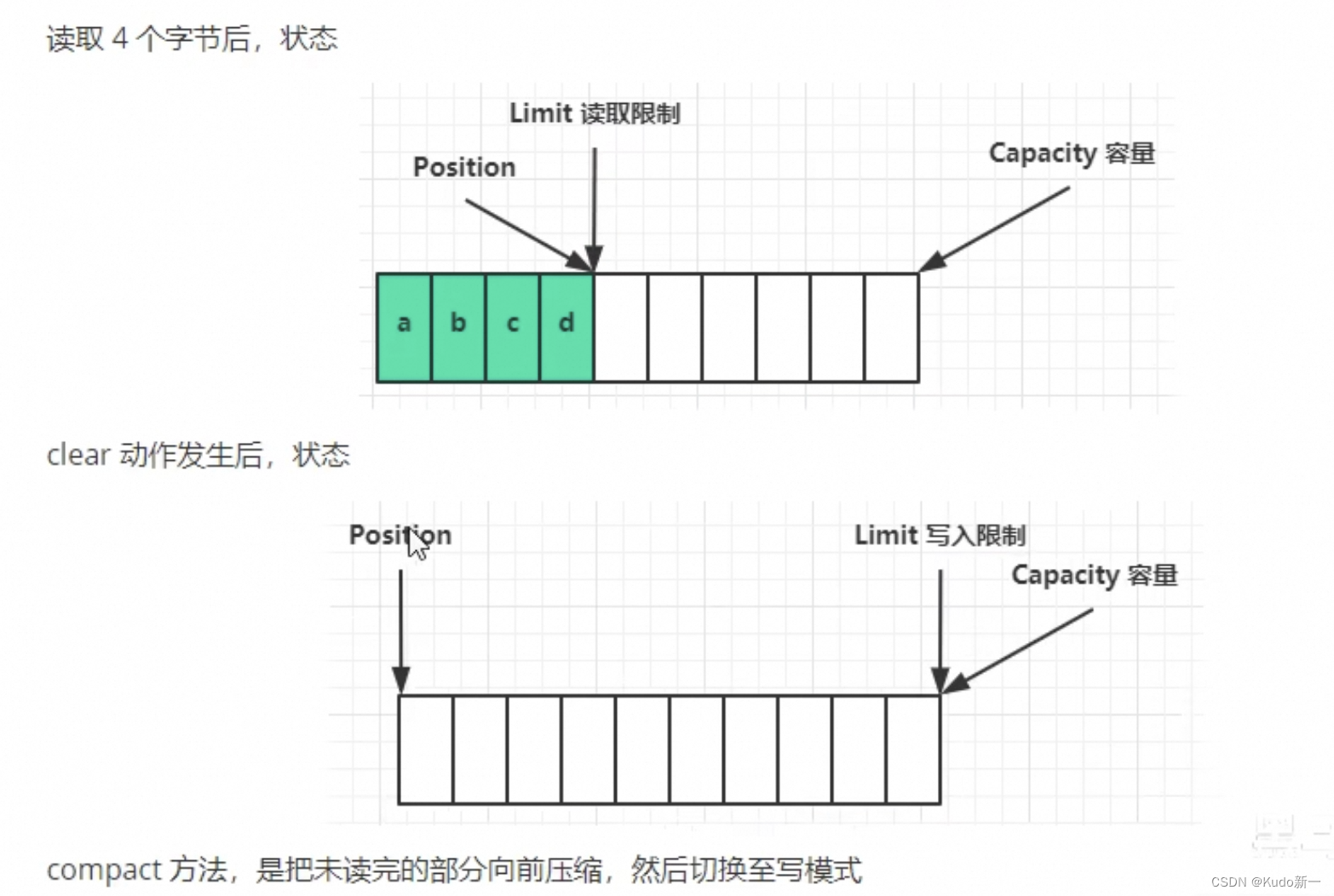
当前只读了a和b,然后指针在c ,limit在d后面。
现在未读完立马写,clear是从头开始写如果太长会把c、d覆盖掉
compact()方法会把剩余的c、d往前移,然后position移到d后面,从d开始写,limit移动到最后

字节缓冲区的父类Buffer中有几个核心属性,如下
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
// 读写指针 读到哪写到哪 有个索引下标
private int position = 0;
// 应该读/写多少字节
private int limit;
// 容量 缓冲区能装多少数据
private int capacity; - capacity:缓冲区的容量。通过构造函数赋予,一旦设置,无法更改
- limit:缓冲区的界限。位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量
- position:下一个读写位置的索引(类似PC)。缓冲区的位置不能为负,并且不能大于limit
- mark:记录当前position的值。position被改变后,可以通过调用reset() 方法恢复到mark的位置。
以上四个属性必须满足以下要求
mark <= position <= limit <= capacity
核心方法
put()方法
- put()方法可以将一个数据放入到缓冲区中。
- 进行该操作后,postition的值会+1,指向下一个可以放入的位置。capacity = limit ,为缓冲区容量的值。
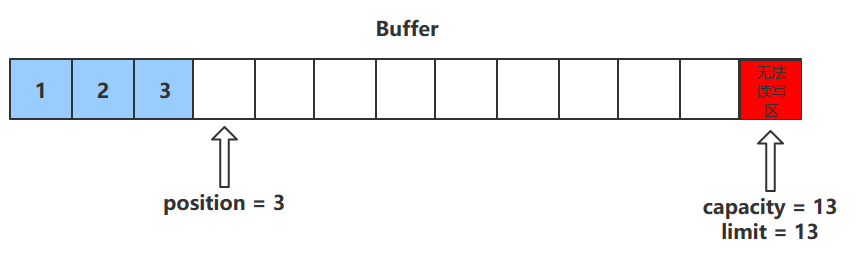
flip()方法
- flip()方法会切换对缓冲区的操作模式,由写->读 / 读->写
- 进行该操作后
- 如果是写模式->读模式,position = 0 , limit 指向最后一个元素的下一个位置,capacity不变
- 如果是读->写,则恢复为put()方法中的值
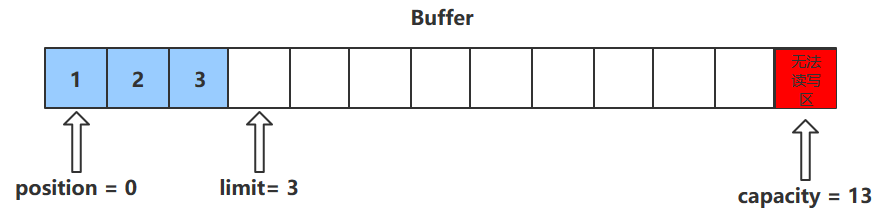
get()方法
- get()方法会读取缓冲区中的一个值
- 进行该操作后,position会+1,如果超过了limit则会抛出异常
- 注意:get(i)方法不会改变position的值
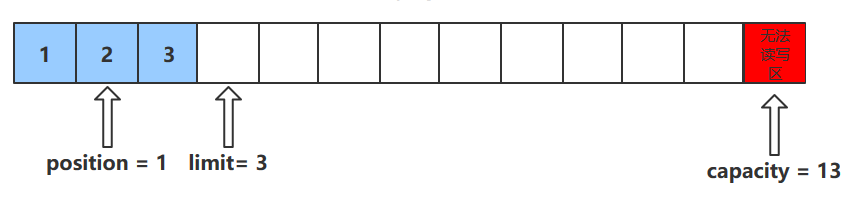
rewind()方法
- 该方法只能在读模式下使用
- rewind()方法后,会恢复position、limit和capacity的值,变为进行get()前的值
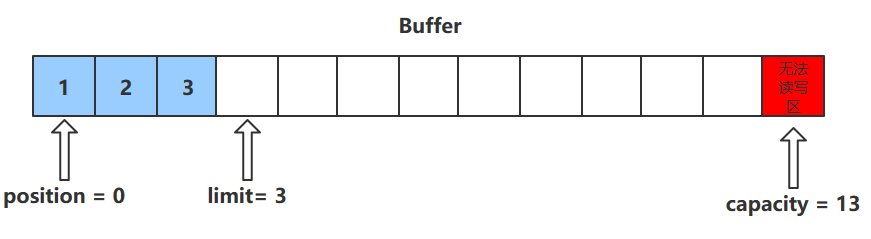
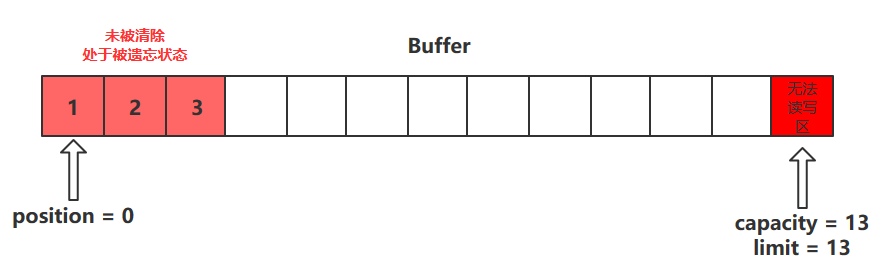
clean()方法
- clean()方法会将缓冲区中的各个属性恢复为最初的状态,position = 0, capacity = limit
- 此时缓冲区的数据依然存在,处于“被遗忘”状态,下次进行写操作时会覆盖这些数据
mark()和reset()方法
- mark()方法会将postion的值保存到mark属性中
- reset()方法会将position的值改为mark中保存的值
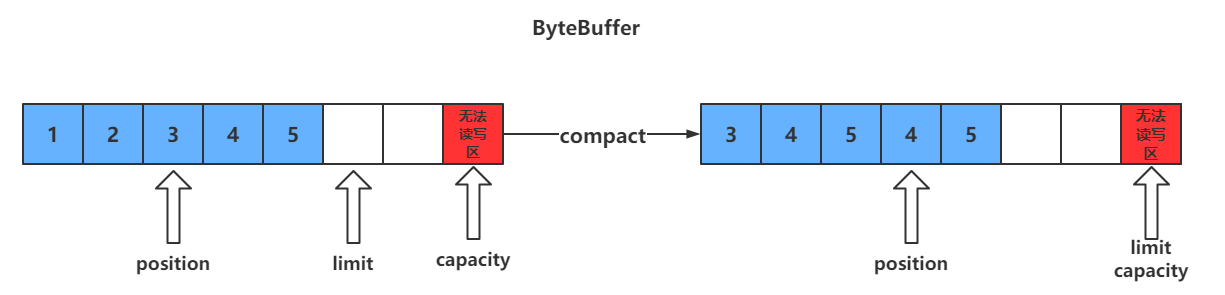
compact()方法
此方法为ByteBuffer的方法,而不是Buffer的方法
- compact会把未读完的数据向前压缩,然后切换到写模式
- 数据前移后,原位置的值并未清零,写时会覆盖之前的值
clear() VS compact()
clear只是对position、limit、mark进行重置,而compact在对position进行设置,以及limit、mark进行重置的同时,还涉及到数据在内存中拷贝(会调用arraycopy)。所以compact比clear更耗性能。但compact能保存你未读取的数据,将新数据追加到为读取的数据之后;而clear则不行,若你调用了clear,则未读取的数据就无法再读取到了
所以需要根据情况来判断使用哪种方法进行模式切换
方法调用及演示
ByteBuffer调试工具类
需要先导入netty依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.51.Final</version>
</dependency>Copyimport java.nio.ByteBuffer;
import io.netty.util.internal.MathUtil;
import io.netty.util.internal.StringUtil;
import io.netty.util.internal.MathUtil.*;
/**
* @author Panwen Chen
* @date 2021/4/12 15:59
*/
public class ByteBufferUtil {
private static final char[] BYTE2CHAR = new char[256];
private static final char[] HEXDUMP_TABLE = new char[256 * 4];
private static final String[] HEXPADDING = new String[16];
private static final String[] HEXDUMP_ROWPREFIXES = new String[65536 >>> 4];
private static final String[] BYTE2HEX = new String[256];
private static final String[] BYTEPADDING = new String[16];
static {
final char[] DIGITS = "0123456789abcdef".toCharArray();
for (int i = 0; i < 256; i++) {
HEXDUMP_TABLE[i << 1] = DIGITS[i >>> 4 & 0x0F];
HEXDUMP_TABLE[(i << 1) + 1] = DIGITS[i & 0x0F];
}
int i;
// Generate the lookup table for hex dump paddings
for (i = 0; i < HEXPADDING.length; i++) {
int padding = HEXPADDING.length - i;
StringBuilder buf = new StringBuilder(padding * 3);
for (int j = 0; j < padding; j++) {
buf.append(" ");
}
HEXPADDING[i] = buf.toString();
}
// Generate the lookup table for the start-offset header in each row (up to 64KiB).
for (i = 0; i < HEXDUMP_ROWPREFIXES.length; i++) {
StringBuilder buf = new StringBuilder(12);
buf.append(StringUtil.NEWLINE);
buf.append(Long.toHexString(i << 4 & 0xFFFFFFFFL | 0x100000000L));
buf.setCharAt(buf.length() - 9, '|');
buf.append('|');
HEXDUMP_ROWPREFIXES[i] = buf.toString();
}
// Generate the lookup table for byte-to-hex-dump conversion
for (i = 0; i < BYTE2HEX.length; i++) {
BYTE2HEX[i] = ' ' + StringUtil.byteToHexStringPadded(i);
}
// Generate the lookup table for byte dump paddings
for (i = 0; i < BYTEPADDING.length; i++) {
int padding = BYTEPADDING.length - i;
StringBuilder buf = new StringBuilder(padding);
for (int j = 0; j < padding; j++) {
buf.append(' ');
}
BYTEPADDING[i] = buf.toString();
}
// Generate the lookup table for byte-to-char conversion
for (i = 0; i < BYTE2CHAR.length; i++) {
if (i <= 0x1f || i >= 0x7f) {
BYTE2CHAR[i] = '.';
} else {
BYTE2CHAR[i] = (char) i;
}
}
}
/**
* 打印所有内容
* @param buffer
*/
public static void debugAll(ByteBuffer buffer) {
int oldlimit = buffer.limit();
buffer.limit(buffer.capacity());
StringBuilder origin = new StringBuilder(256);
appendPrettyHexDump(origin, buffer, 0, buffer.capacity());
System.out.println("+--------+-------------------- all ------------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), oldlimit);
System.out.println(origin);
buffer.limit(oldlimit);
}
/**
* 打印可读取内容
* @param buffer
*/
public static void debugRead(ByteBuffer buffer) {
StringBuilder builder = new StringBuilder(256);
appendPrettyHexDump(builder, buffer, buffer.position(), buffer.limit() - buffer.position());
System.out.println("+--------+-------------------- read -----------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), buffer.limit());
System.out.println(builder);
}
private static void appendPrettyHexDump(StringBuilder dump, ByteBuffer buf, int offset, int length) {
if (MathUtil.isOutOfBounds(offset, length, buf.capacity())) {
throw new IndexOutOfBoundsException(
"expected: " + "0 <= offset(" + offset + ") <= offset + length(" + length
+ ") <= " + "buf.capacity(" + buf.capacity() + ')');
}
if (length == 0) {
return;
}
dump.append(
" +-------------------------------------------------+" +
StringUtil.NEWLINE + " | 0 1 2 3 4 5 6 7 8 9 a b c d e f |" +
StringUtil.NEWLINE + "+--------+-------------------------------------------------+----------------+");
final int startIndex = offset;
final int fullRows = length >>> 4;
final int remainder = length & 0xF;
// Dump the rows which have 16 bytes.
for (int row = 0; row < fullRows; row++) {
int rowStartIndex = (row << 4) + startIndex;
// Per-row prefix.
appendHexDumpRowPrefix(dump, row, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + 16;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(" |");
// ASCII dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append('|');
}
// Dump the last row which has less than 16 bytes.
if (remainder != 0) {
int rowStartIndex = (fullRows << 4) + startIndex;
appendHexDumpRowPrefix(dump, fullRows, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + remainder;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(HEXPADDING[remainder]);
dump.append(" |");
// Ascii dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append(BYTEPADDING[remainder]);
dump.append('|');
}
dump.append(StringUtil.NEWLINE +
"+--------+-------------------------------------------------+----------------+");
}
private static void appendHexDumpRowPrefix(StringBuilder dump, int row, int rowStartIndex) {
if (row < HEXDUMP_ROWPREFIXES.length) {
dump.append(HEXDUMP_ROWPREFIXES[row]);
} else {
dump.append(StringUtil.NEWLINE);
dump.append(Long.toHexString(rowStartIndex & 0xFFFFFFFFL | 0x100000000L));
dump.setCharAt(dump.length() - 9, '|');
dump.append('|');
}
}
public static short getUnsignedByte(ByteBuffer buffer, int index) {
return (short) (buffer.get(index) & 0xFF);
}
}mark & reset

get(i) 不会影响position

调用ByteBuffer的方法
public class TestByteBuffer {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向buffer中写入1个字节的数据 这里也可以用put方法写入 不用channel了
buffer.put((byte)97);
// 使用工具类,查看buffer状态
ByteBufferUtil.debugAll(buffer);
// 向buffer中写入4个字节的数据
buffer.put(new byte[]{98, 99, 100, 101});
ByteBufferUtil.debugAll(buffer);
// 获取数据
buffer.flip();
ByteBufferUtil.debugAll(buffer);
System.out.println(buffer.get());
System.out.println(buffer.get());
ByteBufferUtil.debugAll(buffer);
// 使用compact切换模式
buffer.compact();
ByteBufferUtil.debugAll(buffer);
// 再次写入
buffer.put((byte)102);
buffer.put((byte)103);
ByteBufferUtil.debugAll(buffer);
}
}
运行结果
// 向缓冲区写入了一个字节的数据,此时postition为1
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 00 00 00 00 00 00 00 00 00 |a......... |
+--------+-------------------------------------------------+----------------+
// 向缓冲区写入四个字节的数据,此时position为5
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 调用flip切换模式,此时position为0,表示从第0个数据开始读取
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 读取两个字节的数据
97
98
// position变为2
+--------+-------------------- all ------------------------+----------------+
position: [2], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 调用compact切换模式,此时position及其后面的数据被压缩到ByteBuffer前面去了
// 此时position为3,会覆盖之前的数据
+--------+-------------------- all ------------------------+----------------+
position: [3], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 63 64 65 64 65 00 00 00 00 00 |cdede..... |
+--------+-------------------------------------------------+----------------+
// 再次写入两个字节的数据,之前的 0x64 0x65 被覆盖
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 63 64 65 66 67 00 00 00 00 00 |cdefg..... |
+--------+-------------------------------------------------+----------------+不切读模式直接读就是索引4的位置,读到的就是0

DirectByteBuffer记得释放
put()
往buffer里写数据

一口气读4个

字符串与ByteBuffer的相互转换
方法一
编码:字符串调用getByte方法获得byte数组,将byte数组放入ByteBuffer中
解码:先调用ByteBuffer的flip方法,然后通过StandardCharsets的decoder方法解码
public class Translate {
public static void main(String[] args) {
// 准备两个字符串
String str1 = "hello";
String str2 = "";
ByteBuffer buffer1 = ByteBuffer.allocate(16);
// 通过字符串的getByte方法获得字节数组,放入缓冲区中
buffer1.put(str1.getBytes());
ByteBufferUtil.debugAll(buffer1);
// 将缓冲区中的数据转化为字符串
// 切换模式
buffer1.flip();
// 通过StandardCharsets解码,获得CharBuffer,再通过toString获得字符串
// 会自动切换到读模式
str2 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(str2);
ByteBufferUtil.debugAll(buffer1);
}
}
运行结果
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [16]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f 00 00 00 00 00 00 00 00 00 00 00 |hello...........|
+--------+-------------------------------------------------+----------------+
hello
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f 00 00 00 00 00 00 00 00 00 00 00 |hello...........|
+--------+-------------------------------------------------+----------------+Copy方法二
编码:通过StandardCharsets的encode方法获得ByteBuffer,此时获得的ByteBuffer为读模式,无需通过flip切换模式
解码:通过StandardCharsets的decoder方法解码
public class Translate {
public static void main(String[] args) {
// 准备两个字符串
String str1 = "hello";
String str2 = "";
// 通过StandardCharsets的encode方法获得ByteBuffer
// 此时获得的ByteBuffer为读模式,无需通过flip切换模式
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode(str1);
ByteBufferUtil.debugAll(buffer1);
// 将缓冲区中的数据转化为字符串
// 通过StandardCharsets解码,获得CharBuffer,再通过toString获得字符串
str2 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(str2);
ByteBufferUtil.debugAll(buffer1);
}
}Copy运行结果
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+
hello
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+Copy方法三
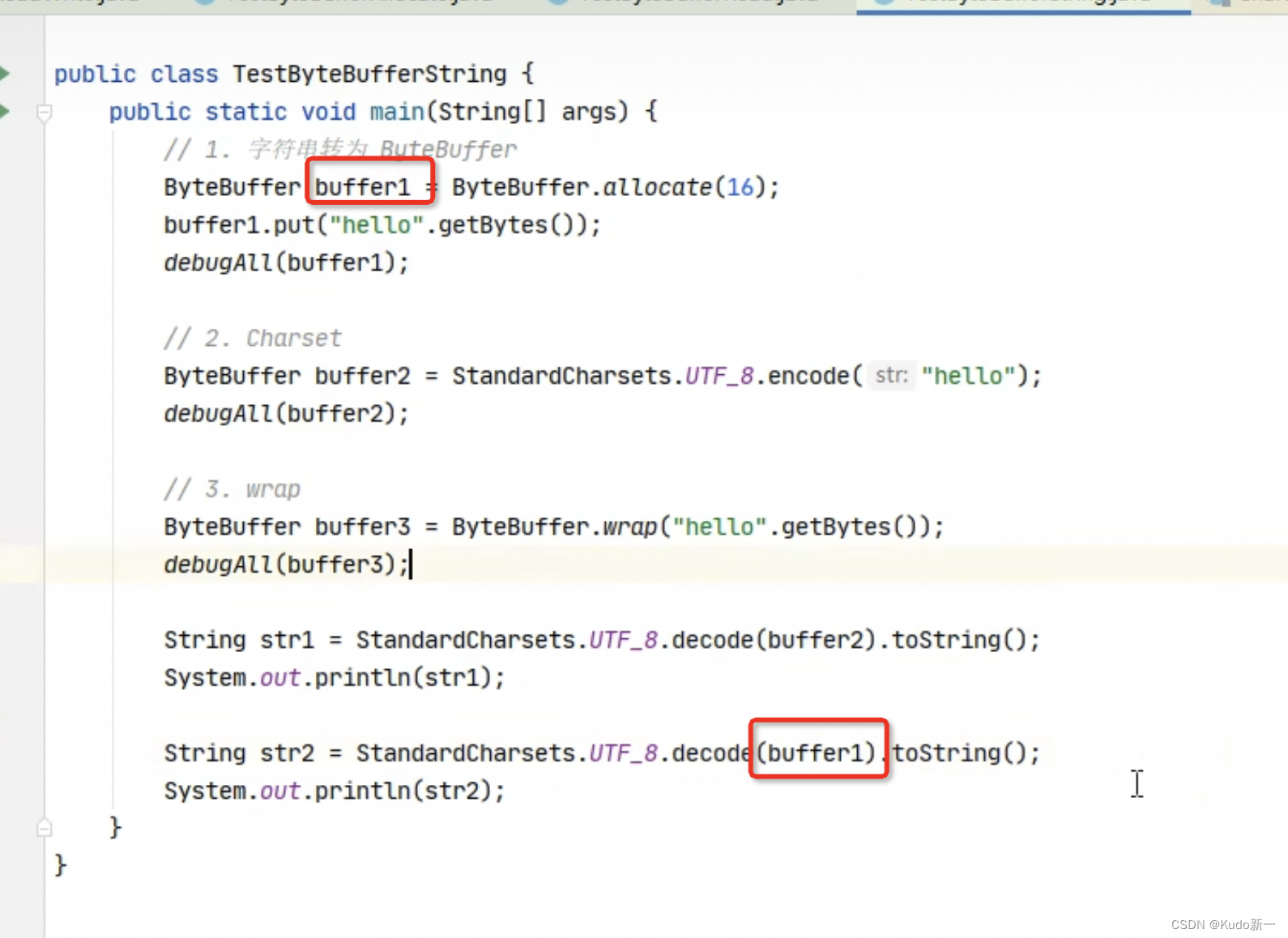
编码:字符串调用getByte()方法获得字节数组,将字节数组传给ByteBuffer的wrap()方法,通过该方法获得ByteBuffer。同样无需调用flip方法切换为读模式
解码:通过StandardCharsets的decoder方法解码
public class Translate {
public static void main(String[] args) {
// 准备两个字符串
String str1 = "hello";
String str2 = "";
// 通过StandardCharsets的encode方法获得ByteBuffer
// 此时获得的ByteBuffer为读模式,无需通过flip切换模式
ByteBuffer buffer1 = ByteBuffer.wrap(str1.getBytes());
ByteBufferUtil.debugAll(buffer1);
// 将缓冲区中的数据转化为字符串
// 通过StandardCharsets解码,获得CharBuffer,再通过toString获得字符串
str2 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(str2);
ByteBufferUtil.debugAll(buffer1);
}
}
没有切换到读模式 这里就会读不到
运行结果
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+
hello
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
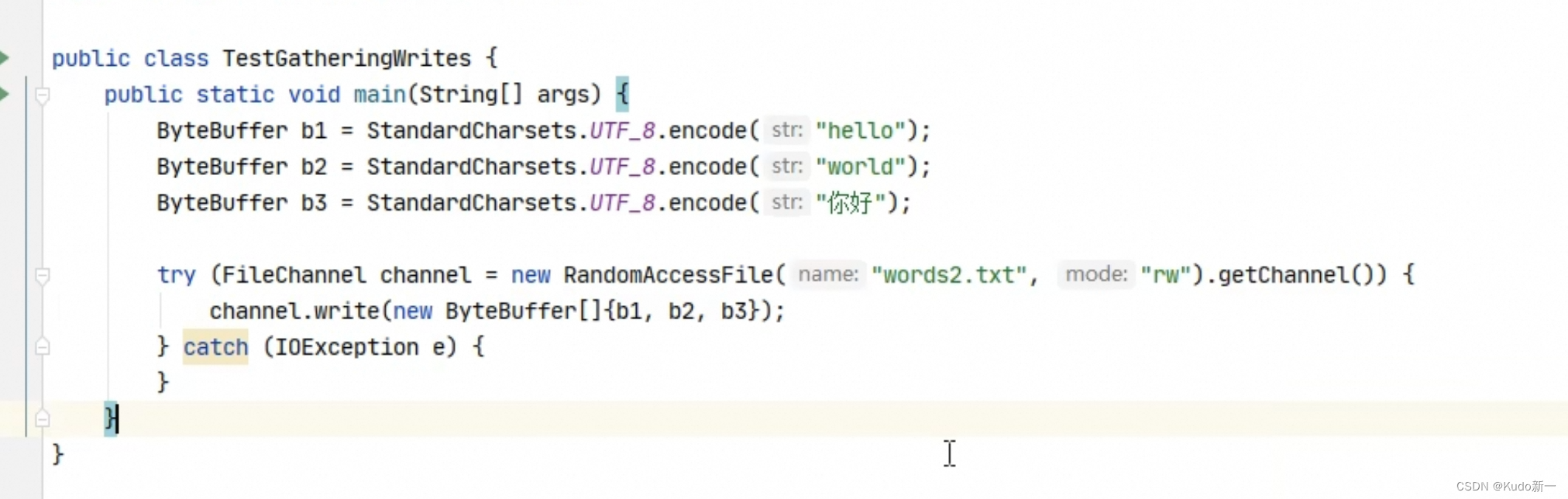
+--------+-------------------------------------------------+----------------+分散读取
一次性读到3个ByteBuff

3个都要切换到读模式

集中写
channel一次写入一组buffer
优点:
减少数据在ByteBuffer间的拷贝,减少数据复制次数,变相提高效率

粘包与半包

现象
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔
但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为
- Hello,world\n
- I’m Nyima\n
- How are you?\n
变成了下面的两个 byteBuffer (粘包,半包)
- Hello,world\nI’m Nyima\nHo
- w are you?\n
出现原因
粘包
发送方在发送数据时,并不是一条一条地发送数据,而是将数据整合在一起,当数据达到一定的数量后再一起发送。这就会导致多条信息被放在一个缓冲区中被一起发送出去
半包
接收方的缓冲区的大小是有限的,当接收方的缓冲区满了以后,就需要将信息截断,等缓冲区空了以后再继续放入数据。这就会发生一段完整的数据最后被截断的现象
所以该怎么实现这个split方法呢?

解决办法
- 通过get(index)方法遍历ByteBuffer,遇到分隔符时进行处理。注意:get(index)不会改变position的值
- 记录该段数据长度,以便于申请对应大小的缓冲区
- 将缓冲区的数据通过get()方法写入到target中
- 调用compact方法切换模式,因为缓冲区中可能还有未读的数据
public class ByteBufferDemo {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(32);
// 模拟粘包+半包
buffer.put("Hello,world\nI'm Nyima\nHo".getBytes());
// 调用split函数处理
split(buffer);
buffer.put("w are you?\n".getBytes());
split(buffer);
}
private static void split(ByteBuffer buffer) {
// 首先肯定要先切换为读模式才能读缓冲区
buffer.flip();
// 读模式下找到读上限 就是limit指针位置
for(int i = 0; i < buffer.limit(); i++) {
// 遍历寻找分隔符
// get(i)不会移动position
if (buffer.get(i) == '\n') {
// 缓冲区长度 换行符的索引+1减去起始索引
// 比如abcde\n 这里c开始起始索引【position】2 5+1-2 = 4【缓冲区长度】
int length = i+1-buffer.position();
// 既不能太长也不能太短 和消息长度一样正合适
ByteBuffer target = ByteBuffer.allocate(length);
// 将前面的内容写入target缓冲区
for(int j = 0; j < length; j++) {
// 将buffer中的数据写入target中 get()只会读一个字节往后移
target.put(buffer.get());
}
// 打印查看结果
ByteBufferUtil.debugAll(target);
}
}
// 读了2个字符 然后没读到换行符
// 切换为写模式,但是缓冲区可能未读完,\nHo可能会被覆盖这里需要使用compact
// 这样下次就能拼接在一起了
buffer.compact();
}
}运行结果
+--------+-------------------- all ------------------------+----------------+
position: [12], limit: [12]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 65 6c 6c 6f 2c 77 6f 72 6c 64 0a |Hello,world. |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [10], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 49 27 6d 20 4e 79 69 6d 61 0a |I'm Nyima. |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [13], limit: [13]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 6f 77 20 61 72 65 20 79 6f 75 3f 0a |How are you?. |
+--------+-------------------------------------------------+----------------+
二、文件编程
1、FileChannel
工作模式
FileChannel只能在阻塞模式下工作,所以无法搭配Selector使用
获取
不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有 getChannel 方法
- 通过 FileInputStream 获取的 channel 只能读
- 通过 FileOutputStream 获取的 channel 只能写
- 通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定【指定rw既能读也能写】
读取
通过 FileInputStream 获取channel,通过read方法将数据写入到ByteBuffer中
read方法的返回值表示读到了多少字节,若读到了文件末尾则返回-1
int readBytes = channel.read(buffer);
可根据返回值判断是否读取完毕
while(channel.read(buffer) > 0) {
// 进行对应操作
...
}
写入
因为channel也是有大小的,所以 write 方法并不能保证一次将 buffer 中的内容全部写入 channel 所以要用到while循环。必须需要按照以下规则进行写入
// 通过hasRemaining()方法查看缓冲区中是否还有数据未写入到通道中
// channel有写能力上限
while(buffer.hasRemaining()) {
channel.write(buffer);
}
关闭
通道需要close,一般情况通过try-with-resource进行关闭,最好使用以下方法获取strea以及channel,避免某些原因使得资源未被关闭
public class TestChannel {
public static void main(String[] args) throws IOException {
try (FileInputStream fis = new FileInputStream("stu.txt");
FileOutputStream fos = new FileOutputStream("student.txt");
FileChannel inputChannel = fis.getChannel();
FileChannel outputChannel = fos.getChannel()) {
// 执行对应操作
...
}
}
}
位置
position
channel也拥有一个保存读取数据位置的属性,即position
long pos = channel.position();Copy可以通过position(int pos)设置channel中position的值
long newPos = ...;
channel.position(newPos);Copy设置当前位置时,如果设置为文件的末尾
- 这时读取会返回 -1
- 这时写入,会追加内容,但要注意如果 position 超过了文件末尾,再写入时在新内容和原末尾之间会有空洞(00)
强制写入
操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘,而是等到缓存满了以后将所有数据一次性的写入磁盘。可以调用 force(true) 方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘
2、两个Channel传输数据
前情提要
在 Java 中,try-catch 用来捕获并处理异常。而 try() 括号中的语法是 Java 7 中引入的 try-with-resources 语句,它用于自动管理资源(例如文件流、数据库连接等),确保它们在使用完毕后被正确关闭,避免资源泄露。
下面是两种语句的对比:
普通的 try-catch 语句:
FileReader reader = null;
try {
reader = new FileReader("somefile.txt");
// 使用 reader 进行文件读取操作
} catch (IOException e) {
e.printStackTrace(); // 处理异常
} finally {
if (reader != null) {
try {
reader.close(); // 显示关闭资源
} catch (IOException e) {
e.printStackTrace();
}
}
}在这个例子中,你需要在 finally 块中显式地关闭 FileReader,确保不会有资源泄露。
try-with-resources 语句:
try (FileReader reader = new FileReader("somefile.txt")) {
// 使用 reader 进行文件读取操作
} catch (IOException e) {
e.printStackTrace(); // 处理异常
}在 try-with-resources 语句的例子中,FileReader 被声明在 try() 括号内。这意味着它是一个资源,Java 会自动在 try 块执行完毕后关闭这个资源,无论是正常退出还是因为异常退出。这种语法消除了手动关闭资源的需要,并减少了因为资源泄露导致的错误。
在 try() 括号里你可以放置任何实现了 AutoCloseable 或 Closeable 接口的对象。这些接口要求实现一个 close() 方法,JVM 会自动调用这个方法来关闭资源。常见的资源包括文件流(FileInputStream, FileOutputStream 等)、数据库连接(Connection)、网络连接等。
使用 try-with-resources 语句可以让代码更加简洁,并且自动处理资源关闭,因此更容易编写正确的资源管理代码。这是处理需要关闭的资源的推荐方式。
transferTo方法
使用transferTo方法可以快速、高效地将一个channel中的数据传输到另一个channel中,但一次只能传输2G的内容
transferTo底层使用了零拷贝技术
public class TestChannel {
public static void main(String[] args){
try (FileInputStream fis = new FileInputStream("stu.txt");
FileOutputStream fos = new FileOutputStream("student.txt");
FileChannel inputChannel = fis.getChannel();
FileChannel outputChannel = fos.getChannel()) {
// 参数:从哪开始传数据起始位置,传输数据的大小,目的channel往哪传
// 返回值为传输的数据的字节数
// transferTo一次只能传输2G的数据 效果好 底层会用操作系统零拷贝进行优化
inputChannel.transferTo(0, inputChannel.size(), outputChannel);
} catch (IOException e) {
e.printStackTrace();
}
}
}当传输的文件大于2G时,需要使用以下方法进行多次传输
public class TestChannel {
public static void main(String[] args){
try (FileInputStream fis = new FileInputStream("stu.txt");
FileOutputStream fos = new FileOutputStream("student.txt");
FileChannel inputChannel = fis.getChannel();
FileChannel outputChannel = fos.getChannel()) {
// 比如文件5G
long size = inputChannel.size();
// 还剩余多少字节没传 此时也是5G
long capacity = inputChannel.size();
// 分多次传输
while (capacity > 0) {
// transferTo返回值为实际传输了的字节数 一开始从0开始传 第二次就是size-capacity capacity变3G
// 参数:从哪开始传数据起始位置,传输数据的大小【实际只传了2G】,目的channel往哪传
capacity -= inputChannel.transferTo(size-capacity【0】, capacity, outputChannel);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
3、Path与Paths
- Path 用来表示文件路径
- Paths 是工具类,用来获取 Path 实例
Path source = Paths.get("1.txt"); // 相对路径 不带盘符 使用 user.dir 环境变量来定位 1.txt
Path source = Paths.get("d:\\1.txt"); // 绝对路径 代表了 d:\1.txt 反斜杠需要转义
Path source = Paths.get("d:/1.txt"); // 绝对路径 同样代表了 d:\1.txt
Path projects = Paths.get("d:\\data", "projects"); // 代表了 d:\data\projectsCopy.代表了当前路径..代表了上一级路径
例如目录结构如下
d:
|- data
|- projects
|- a
|- b
代码
Path path = Paths.get("d:\\data\\projects\\a\\..\\b");
System.out.println(path);
System.out.println(path.normalize()); // 正常化路径 会去除 . 以及 ..
输出结果为
d:\data\projects\a\..\b
d:\data\projects\b
4、Files
查找
检查文件是否存在
Path path = Paths.get("helloword/data.txt");
System.out.println(Files.exists(path));Copy创建
创建一级目录
Path path = Paths.get("helloword/d1");
Files.createDirectory(path);
- 如果目录已存在,会抛异常 FileAlreadyExistsException
- 不能一次创建多级目录,否则会抛异常 NoSuchFileException
创建多级目录用
Path path = Paths.get("helloword/d1/d2");
Files.createDirectories(path);
拷贝及移动
拷贝文件
Path source = Paths.get("helloword/data.txt");
Path target = Paths.get("helloword/target.txt");
// 类似于TransformTo 性能差不多
Files.copy(source, target);
- 如果文件已存在,会抛异常 FileAlreadyExistsException
如果希望用 source 覆盖掉 target,需要用 StandardCopyOption 来控制
Files.copy(source, target, StandardCopyOption.REPLACE_EXISTING);
移动文件
Path source = Paths.get("helloword/data.txt");
Path target = Paths.get("helloword/data.txt");
Files.move(source, target, StandardCopyOption.ATOMIC_MOVE);Copy- StandardCopyOption.ATOMIC_MOVE 保证文件移动的原子性
删除
删除文件
Path target = Paths.get("helloword/target.txt");
Files.delete(target);
- 如果文件不存在,会抛异常 NoSuchFileException
删除目录
Path target = Paths.get("helloword/d1");
// 目录还有内容会抛异常
Files.delete(target);
- 如果目录还有内容,会抛异常 DirectoryNotEmptyException
遍历
可以使用Files工具类中的walkFileTree(Path, FileVisitor)方法,其中需要传入两个参数
- Path:文件起始路径
- FileVisitor:文件访问器,使用访问者模式
- 接口的实现类SimpleFileVisitor有四个方法
- preVisitDirectory:访问目录前的操作
- visitFile:访问文件的操作
- visitFileFailed:访问文件失败时的操作
- postVisitDirectory:访问目录后的操作
- 接口的实现类SimpleFileVisitor有四个方法
在 Java 中,匿名类可以访问其外部作用域中的变量。然而,对于 Java 8 之前的版本,有一个重要的限制:匿名类只能访问被声明为 final 的局部变量,或者实际上不再改变的变量(即事实上的 final)。这意味着,你不能在匿名类内部改变这些局部变量的值。
这个限制的原因在于生命周期的差异。当一个匿名类的实例被创建时,它可以捕获并使用创建它的方法的局部变量。但是,这个匿名类的对象可能在方法结束后仍然存在(比如,如果它被赋值给了一个外部的变量),而局部变量的生命周期是直到方法执行完毕为止。为了解决这个差异,Java 实现了一个隐藏的特性:它会将这些变量的副本传递给匿名类的实例。
如果局部变量被允许在匿名类内部改变,那么原始变量和匿名类内部的副本可能会出现不一致。为了避免这种情况,Java 要求这些变量必须是 final 的,或者事实上不被改变,以保证变量的一致性。
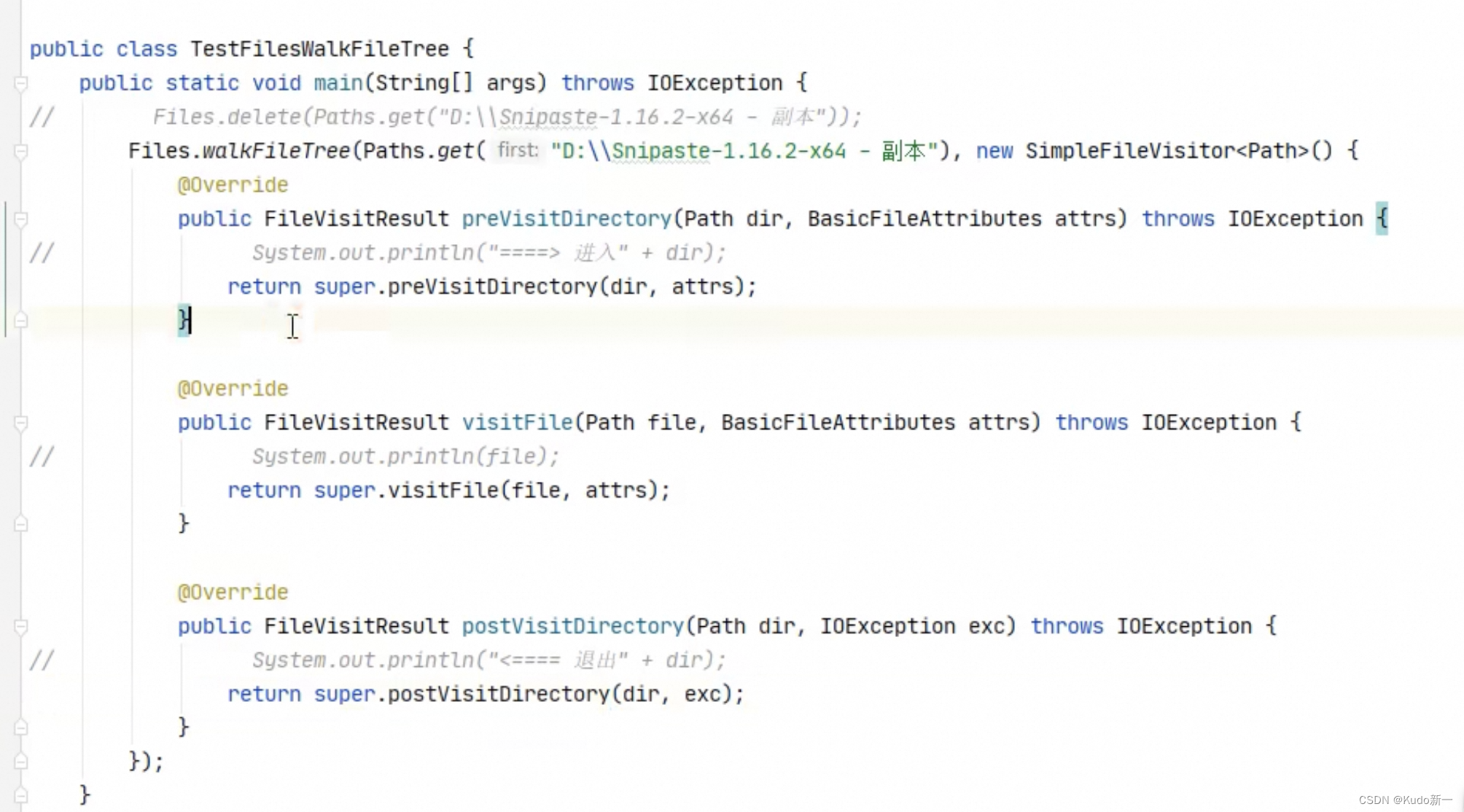
public class TestWalkFileTree {
public static void main(String[] args) throws IOException {
Path path = Paths.get("F:\\JDK 8");
// 文件目录数目
AtomicInteger dirCount = new AtomicInteger();
// 文件数目
AtomicInteger fileCount = new AtomicInteger();
// 参数:起点的路径,遍历到后要执行的操作,
Files.walkFileTree(path, new SimpleFileVisitor<Path>(){
// 遍历到文件前执行的方法
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println("===>"+dir);
// 增加文件目录数
dirCount.incrementAndGet();
return super.preVisitDirectory(dir, attrs);
}
// 遍历到文件时执行的方法
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println(file);
// 增加文件数
fileCount.incrementAndGet();
return super.visitFile(file, attrs);
}
});
// 打印数目
System.out.println("文件目录数:"+dirCount.get());
System.out.println("文件数:"+fileCount.get());
}
}
运行结果如下
...
===>F:\JDK 8\lib\security\policy\unlimited
F:\JDK 8\lib\security\policy\unlimited\local_policy.jar
F:\JDK 8\lib\security\policy\unlimited\US_export_policy.jar
F:\JDK 8\lib\security\trusted.libraries
F:\JDK 8\lib\sound.properties
F:\JDK 8\lib\tzdb.dat
F:\JDK 8\lib\tzmappings
F:\JDK 8\LICENSE
F:\JDK 8\README.txt
F:\JDK 8\release
F:\JDK 8\THIRDPARTYLICENSEREADME-JAVAFX.txt
F:\JDK 8\THIRDPARTYLICENSEREADME.txt
F:\JDK 8\Welcome.html
文件目录数:23
文件数:279删除多级目录及其目录下文件
遍历子目录一堆文件,先进文件夹时,不操作,然后操作删除,退出后再删除当前这个文件夹

整理后
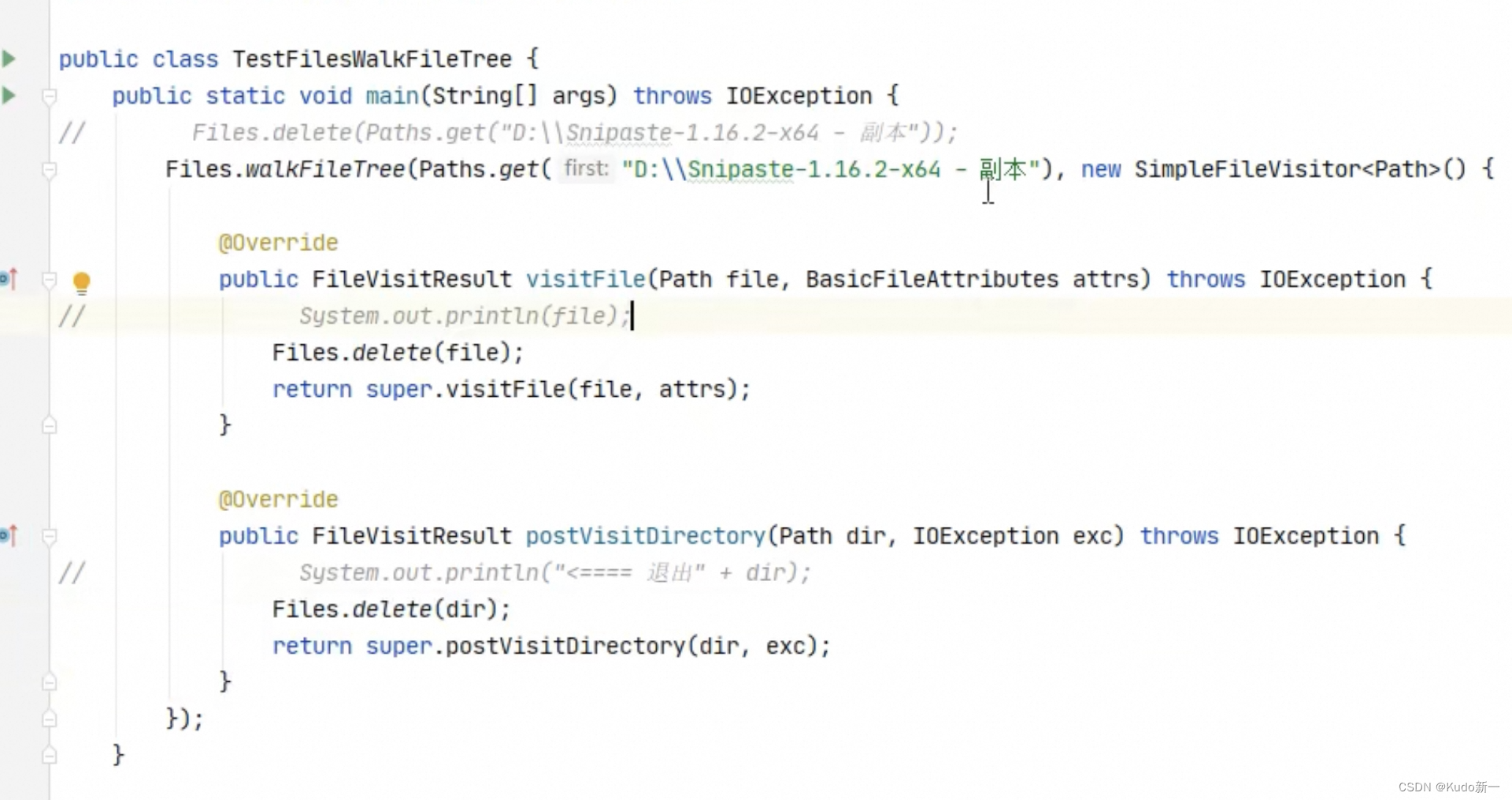
拷贝多级目录


三、网络编程
1、阻塞【线程不能很好工作 某个方法执行都会影响另外方法执行】
- 阻塞模式下,相关方法都会导致线程暂停
- ServerSocketChannel.accept 会在没有连接建立时让线程暂停
- SocketChannel.read 会在通道中没有数据可读时让线程暂停
- 阻塞的表现其实就是线程暂停了,暂停期间不会占用 cpu,但线程相当于闲置
- 单线程下,阻塞方法之间相互影响,几乎不能正常工作,需要多线程支持
- 但多线程下,有新的问题,体现在以下方面
- 32 位 jvm 一个线程 320k,64 位 jvm 一个线程 1024k,如果连接数过多,必然导致 OOM,并且线程太多,反而会因为频繁上下文切换导致性能降低
- 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间 inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接
服务端代码
public class Server {
public static void main(String[] args) {
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(16);
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
// 为服务器通道绑定端口
server.bind(new InetSocketAddress(8080));
// 用户存放连接的集合
ArrayList<SocketChannel> channels = new ArrayList<>();
// 循环接收连接
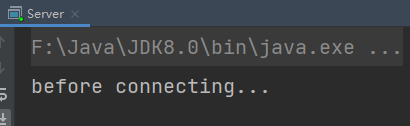
while (true) {
System.out.println("before connecting...");
// 没有连接时,会阻塞线程
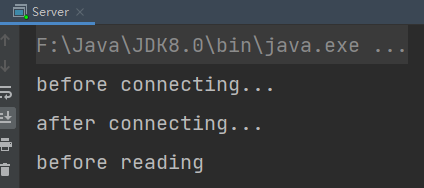
SocketChannel socketChannel = server.accept();
System.out.println("after connecting...");
channels.add(socketChannel);
// 循环遍历集合中的连接
for(SocketChannel channel : channels) {
System.out.println("before reading");
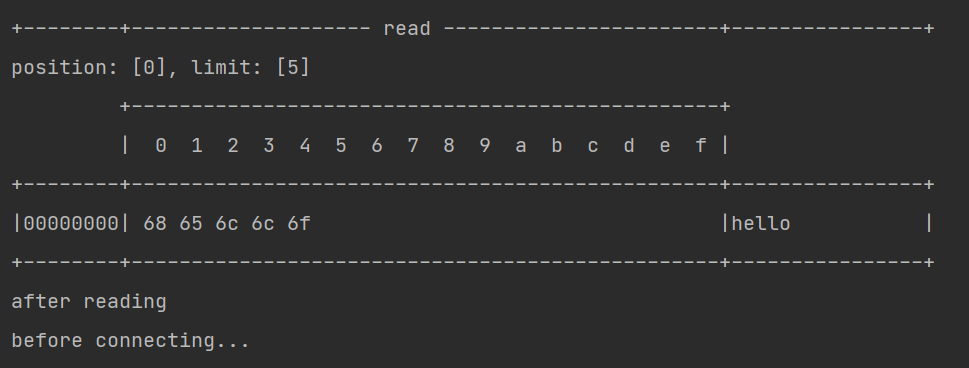
// 处理通道中的数据
// 当通道中没有数据可读时,会阻塞线程
channel.read(buffer);
buffer.flip();
ByteBufferUtil.debugRead(buffer);
buffer.clear();
System.out.println("after reading");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
客户端代码
public class Client {
public static void main(String[] args) {
try (SocketChannel socketChannel = SocketChannel.open()) {
// 和服务器建立连接
socketChannel.connect(new InetSocketAddress("localhost", 8080));
System.out.println("waiting...");
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果
- 客户端-服务器建立连接前:服务器端因accept阻塞
- 客户端-服务器建立连接后,客户端发送消息前:服务器端因通道为空被阻塞
- 客户端发送数据后,服务器处理通道中的数据。再次进入循环时,再次被accept阻塞
- 之前的客户端再次发送消息,服务器端因为被accept阻塞,无法处理之前客户端发送到通道中的信息
服务器也就收不到这条hi了,只有当新的客户端连接再进来才能收到 。

2、非阻塞
-
可以通过ServerSocketChannel的configureBlocking(false)方法将获得连接设置为非阻塞的。此时若没有连接,accept会返回null
-
可以通过SocketChannel的configureBlocking(false)方法将从通道中读取数据设置为非阻塞的。若此时通道中没有数据可读,read会返回0
服务器代码如下【使用NIO来理解阻塞模式】
public class Server {
public static void main(String[] args) {
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(16);
// 1.获得服务器通道 ServerSocketChannel代表一个服务器对象 open()获得对象
try(ServerSocketChannel server = ServerSocketChannel.open()) {
// 2.为服务器绑定监听端口 这样客户端才知道要转发给哪个端口
server.bind(new InetSocketAddress(8080));
// 3.用户存放连接的集合
ArrayList<SocketChannel> channels = new ArrayList<>();
// 循环接收连接
while (true) {
// 设置为非阻塞模式,没有连接时返回null,不会阻塞线程
// 设置为非阻塞模式 影响的是accept方法 线程还会继续运行
server.configureBlocking(false);
// 3次握手,建立与客户端的连接,会返回个SocketChannel
// Channel都是数据读写通道,跟客户端进行读写操作,与客户端进行通信
// accept默认是个阻塞方法,会让线程暂停 停止运行
// 客户端连接建立后,线程才会继续运行
SocketChannel socketChannel = server.accept();
// 通道不为空时才将连接放入到集合中
if (socketChannel != null) {
System.out.println("after connecting...");
channels.add(socketChannel);
}
// 循环遍历集合中的连接,处理所有客户端的数据
for(SocketChannel channel : channels) {
// 处理通道中的数据
// 设置为非阻塞模式,若通道中没有数据,会返回0,不会阻塞线程
channel.configureBlocking(false);
// 从缓冲区读取数据 这个read()也是个阻塞方法,线程停止运行
// 只有客户端发送数据,才会继续往下运行
int read = channel.read(buffer);
if(read > 0) {
buffer.flip();
ByteBufferUtil.debugRead(buffer);
// 读完后切换为写模式 再重新接受数据
buffer.clear();
System.out.println("after reading");
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}这样写存在一个问题,因为设置为了非阻塞,会一直执行while(true)中的代码,CPU一直处于忙碌状态,会使得性能变低,所以实际情况中不使用这种方法处理请求
3、Selector
多路复用
单线程可以配合 Selector 完成对多个 Channel 可读写事件的监控,这称之为多路复用
- 多路复用仅针对网络 IO,普通文件 IO 无法利用多路复用
- 如果不用 Selector 的非阻塞模式,线程大部分时间都在做无用功,而 Selector 能够保证
- 有可连接事件时才去连接
- 有可读事件才去读取
- 有可写事件才去写入
- 限于网络传输能力,Channel 未必时时可写,一旦 Channel 可写,会触发 Selector 的可写事件
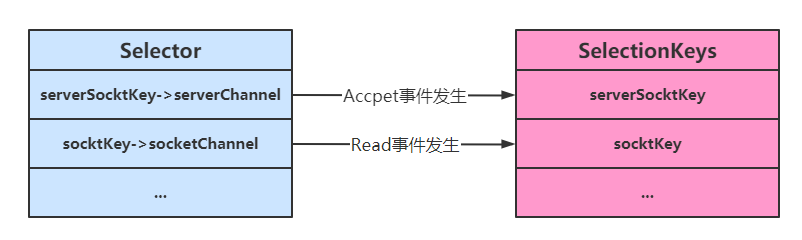
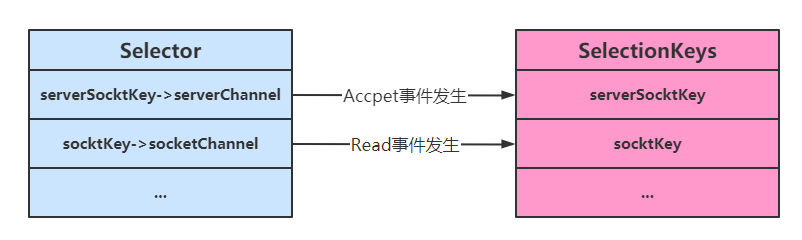
4、使用及Accpet事件
selectionKey是个管理员,管的是ServerSocketChannel,如果SocketChannel也想被管理,还得注册新的selectionKey。

要使用Selector实现多路复用,服务端代码如下改进
public class SelectServer {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
// 创建选择器selector,可以管理多个channel
Selector selector = Selector.open();
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 将通道注册到选择器中,并设置感兴趣的事件
server.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 若没有事件就绪,线程会被阻塞,反之不会被阻塞。从而避免了CPU空转
// 返回值为就绪的事件个数
int ready = selector.select();
System.out.println("selector ready counts : " + ready);
// 获取所有事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型
if(key.isAcceptable()) {
// 获得key对应的channel
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
System.out.println("before accepting...");
// 获取连接并处理,而且是必须处理,否则需要取消
SocketChannel socketChannel = channel.accept();
System.out.println("after accepting...");
// 处理完毕后移除
iterator.remove();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
步骤解析
- 获得选择器Selector
Selector selector = Selector.open();Copy- 将通道设置为非阻塞模式,并注册到选择器中,并设置感兴趣的事件
- channel 必须工作在非阻塞模式
- FileChannel 没有非阻塞模式,因此不能配合 selector 一起使用
- 绑定的事件类型可以有
- connect - 客户端连接成功时触发【客户端那边的】
- accept - 服务器端成功接受客户端连接时触发
- read - 数据可读入时触发,有因为接收能力弱,数据暂不能读入的情况
- write - 数据可写出时触发,有因为发送能力弱,数据暂不能写出的情况
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 写法1 0表示不关心任何事件
server.register(selector, 0 ,null);
server.interestOps(SelectionKey.OP_ACCEPT);
// 写法2 将通道注册到选择器中,并设置感兴趣的事件 它只关心accept事件
server.register(selector, 0 ,SelectionKey.OP_ACCEPT);-
通过Selector监听事件,并获得就绪的通道个数,若没有通道就绪,线程会被阻塞
-
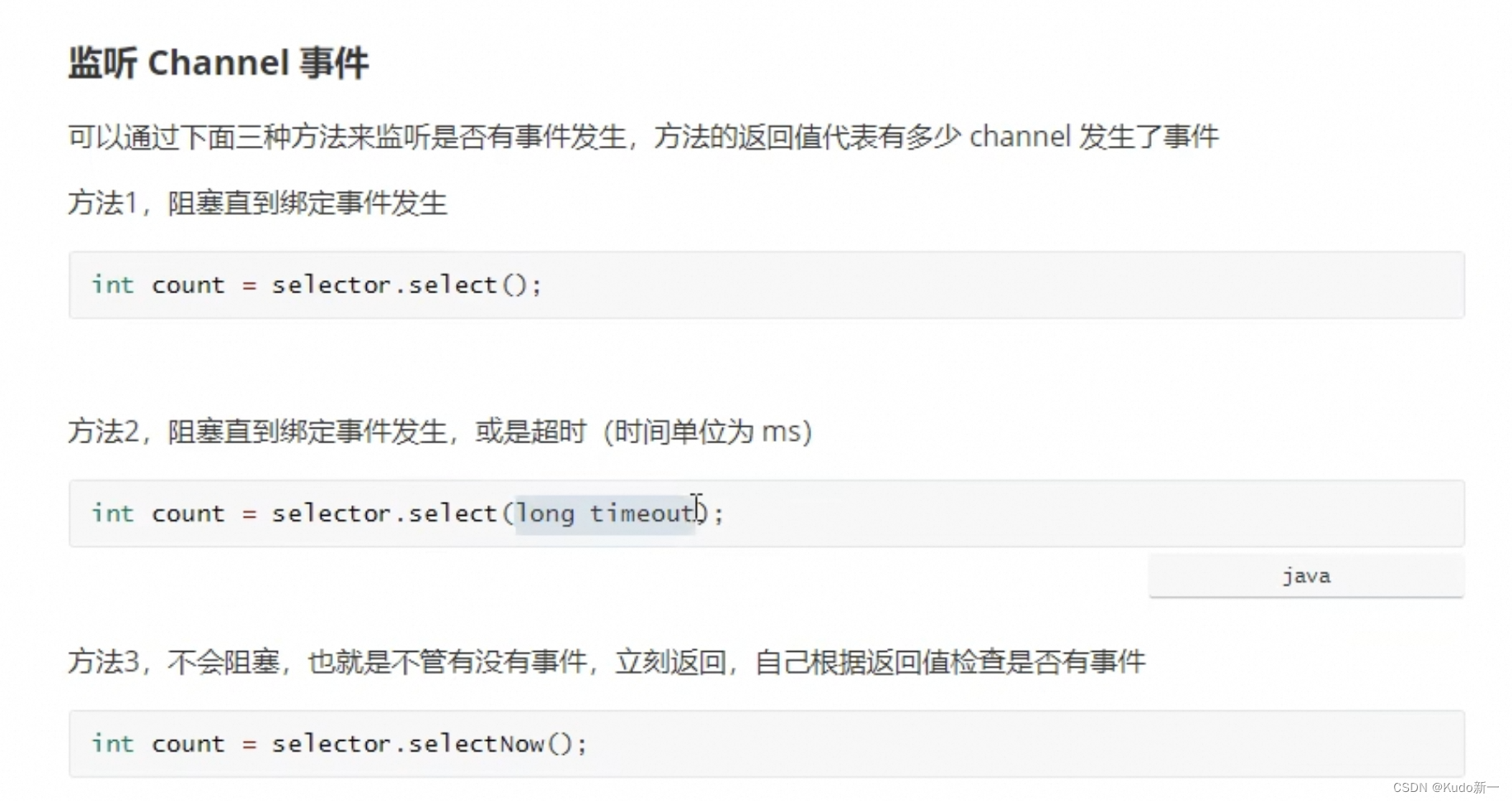
阻塞直到绑定事件发生 没有事件发生就会让
selector阻塞 有事件发生才会恢复运行int count = selector.select(); -
阻塞直到绑定事件发生,或是超时(时间单位为 ms)
int count = selector.select(long timeout); -
不会阻塞,也就是不管有没有事件,立刻返回,自己根据返回值检查是否有事件
int count = selector.selectNow();
-
-
获取就绪事件并得到对应的通道,然后进行处理
// 获取可读可写可连接的所有事件 所有发生的事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型,此处为Accept类型
if(key.isAcceptable()) {
// 获得key对应的channel 是哪个channel发生了事件 这里强转是因为返回是父类型
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
// 因为发生连接了 所以获取连接并处理,而且是必须处理,否则需要取消
SocketChannel socketChannel = channel.accept();
// 处理完毕后移除
iterator.remove();
}
}
事件发生后能否不处理
事件发生后,要么处理,要么取消(cancel),不能什么都不做,否则下次该事件仍会触发,这是因为 nio 底层使用的是水平触发

补充

再来一个客户端连接也还是这个key来处理
5、Read事件
- 在Accept事件中,若有客户端与服务器端建立了连接,需要将其对应的SocketChannel设置为非阻塞,并注册到选择其中
- 添加Read事件,触发后进行读取操作
public class SelectServer {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
// 创建选择器
Selector selector = Selector.open();
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 将通道注册到选择器中,并设置感兴趣的实践
server.register(selector, SelectionKey.OP_ACCEPT);
// 为serverKey设置感兴趣的事件
while (true) {
// 若没有事件就绪,线程会被阻塞,反之不会被阻塞。从而避免了CPU空转
// 返回值为就绪的事件个数
int ready = selector.select();
System.out.println("selector ready counts : " + ready);
// 获取所有事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型 区分事件类型
if(key.isAcceptable()) {
// 获得key对应的channel
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
System.out.println("before accepting...");
// 获取连接
SocketChannel socketChannel = channel.accept();
System.out.println("after accepting...");
// 设置为非阻塞模式,同时将连接的通道也注册到选择其中
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
// 处理完毕后移除
iterator.remove();
} else if (key.isReadable()) {
// 拿到触发读事件的channel
SocketChannel channel = (SocketChannel) key.channel();
System.out.println("before reading...");
channel.read(buffer);
System.out.println("after reading...");
buffer.flip();
ByteBufferUtil.debugRead(buffer);
buffer.clear();
// 处理完毕后移除
iterator.remove();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}一个Selector key关注只读,一个Selector key关注accept的事件
空指针问题分析:

每次有事件只会往绿色的这个集合里加,并不会删除。
当事件处理完,就会去掉事件上的标识,但key还会留着

此时又把关心只读事件的Selector key管理员注册进来

如果没有新事件进来就会阻塞在selector.select()了
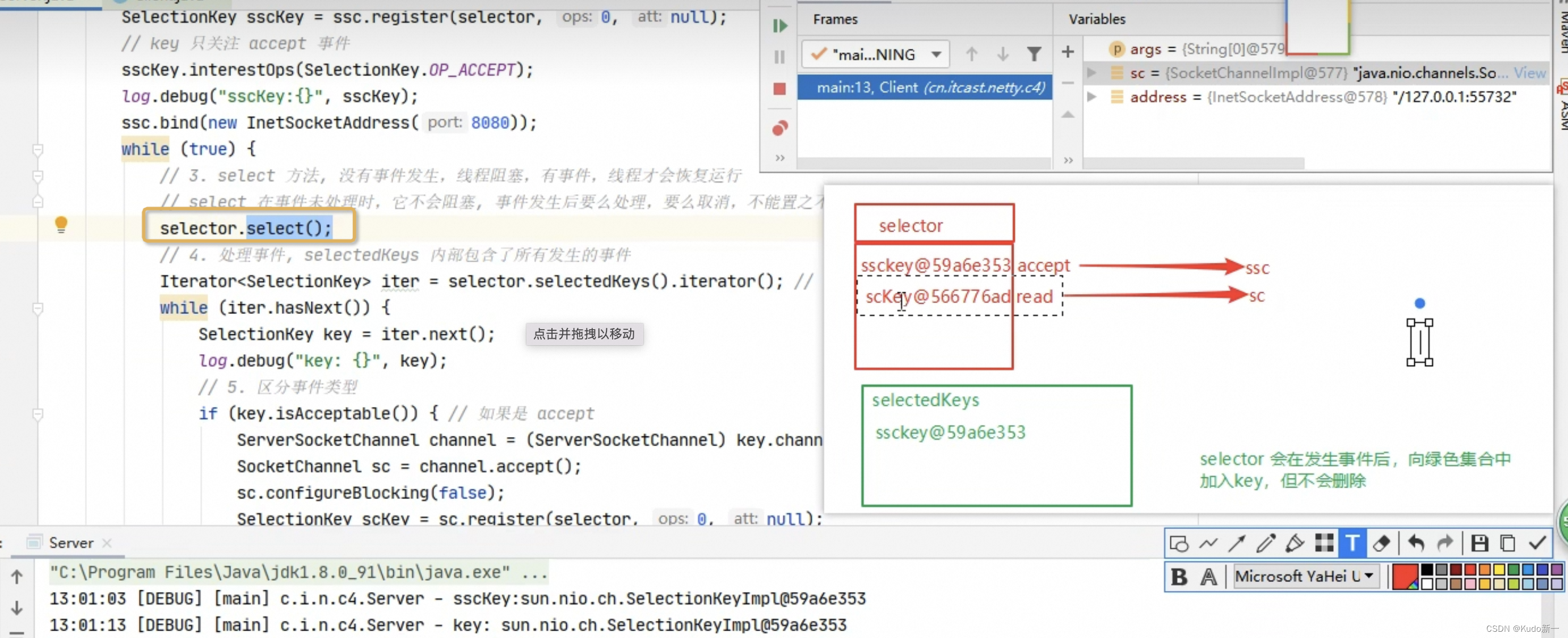
此时客户端发送数据,就来新事件了,然后被sc这个管理员监测到了,然后把key加入绿色集合
然后接下来开始遍历,第一次循环拿到的是个空事件,所以这个accept()在没有连接建立的情况下返回是个null,于是43行就报错空指针异常了。

所以处理完一个key要把他移除掉

删除事件
当处理完一个事件后,一定要调用迭代器的remove方法移除对应事件,否则会出现错误。原因如下
以我们上面的 Read事件 的代码为例
-
当调用了 server.register(selector, SelectionKey.OP_ACCEPT)后,Selector中维护了一个集合,用于存放SelectionKey以及其对应的通道
// WindowsSelectorImpl 中的 SelectionKeyImpl数组 private SelectionKeyImpl[] channelArray = new SelectionKeyImpl[8];Copypublic class SelectionKeyImpl extends AbstractSelectionKey { // Key对应的通道 final SelChImpl channel; ... }Copy
-
当选择器中的通道对应的事件发生后,selecionKey会被放到另一个集合中,但是selecionKey不会自动移除,所以需要我们在处理完一个事件后,通过迭代器手动移除其中的selecionKey。否则会导致已被处理过的事件再次被处理,就会引发错误
断开处理
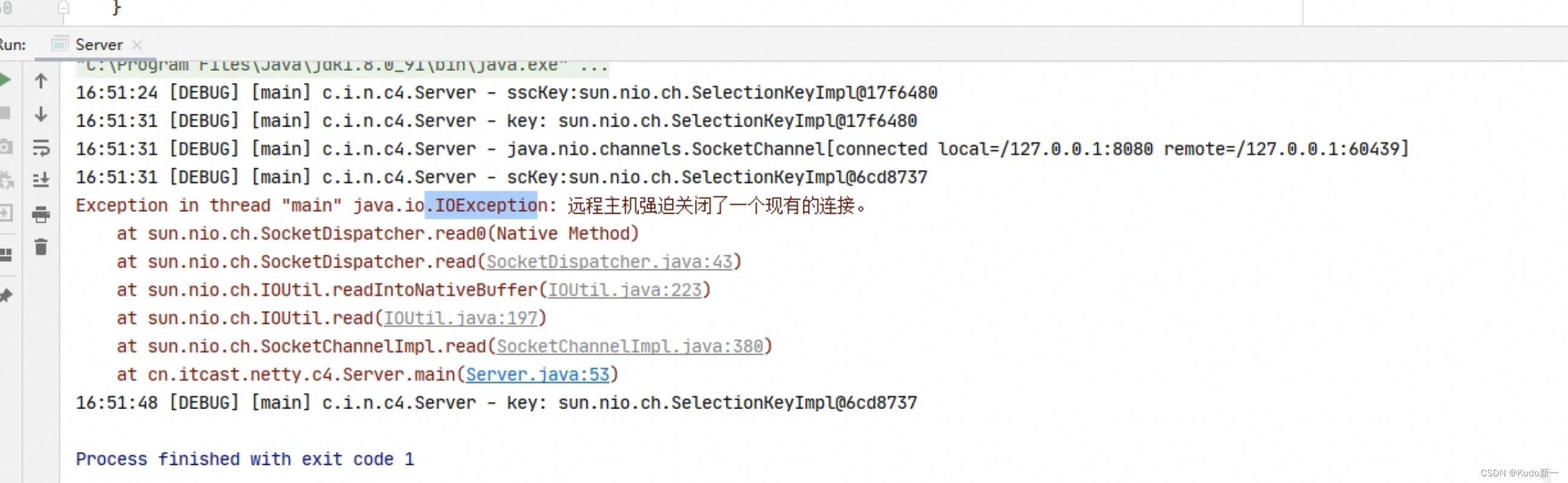
当客户端与服务器之间的连接断开时,会给服务器端发送一个读事件,对异常断开和正常断开需要加以不同的方式进行处理
-
正常断开
-
正常断开时,服务器端的channel.read(buffer)方法的返回值为-1,所以当结束到返回值为-1时,需要调用key的cancel方法取消此事件,并在取消后移除该事件
int read = channel.read(buffer); // 断开连接时,客户端会向服务器发送一个写事件,此时read的返回值为-1 if(read == -1) { // 取消该事件的处理 像发生异常一样取消事件处理 key.cancel(); // 服务端也需要断开 close() channel.close(); } else { ... } // 取消或者处理,都需要移除key iterator.remove();
-
-
异常断开
- 异常断开时,会抛出IOException异常, 在try-catch的catch块中捕获异常并调用key的cancel方法即可
try{
}catch(Exception e){
- // 把key从Selector key集合里反注册【删掉】因为客户端断开了 将key取消【遍历到的Socket channel注册进Selector key集合里的】
- key.cancle();
}
此时就不会陷入死循环 影响到其他客户端

消息边界
不处理消息边界存在的问题
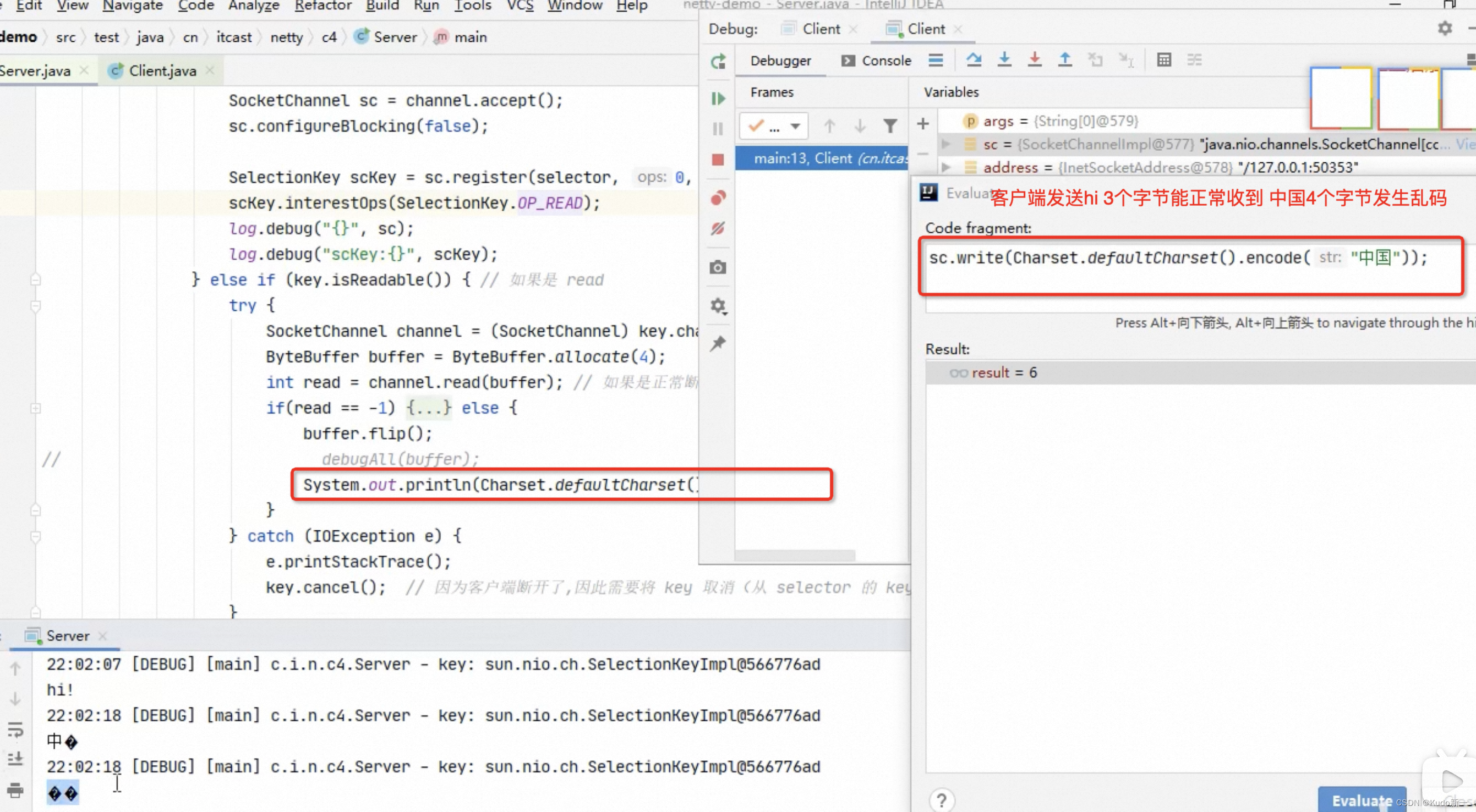
将缓冲区的大小设置为4个字节,发送2个汉字6个字节(你好),通过decode解码并打印时,会出现乱码
ByteBuffer buffer = ByteBuffer.allocate(4);
// 解码并打印
System.out.println(StandardCharsets.UTF_8.decode(buffer));Copy你�
��Copy这是因为UTF-8字符集下,1个汉字占用3个字节,此时缓冲区大小为4个字节,一次读时间无法处理完通道中的所有数据,所以一共会触发两次读事件。这就导致 你好 的 好 字被拆分为了前半部分和后半部分发送,解码时就会出现问题
处理消息边界
传输的文本可能有以下三种情况
- 文本大于缓冲区大小
- 此时需要将缓冲区进行扩容
- 发生半包现象
- 发生粘包现象
解决思路大致有以下三种
- 固定消息长度,数据包大小一样,服务器按预定长度读取,当发送的数据较少时,需要将数据进行填充,直到长度与消息规定长度一致。缺点是浪费带宽
- 另一种思路是按分隔符拆分,缺点是效率低,需要一个一个字符地去匹配分隔符
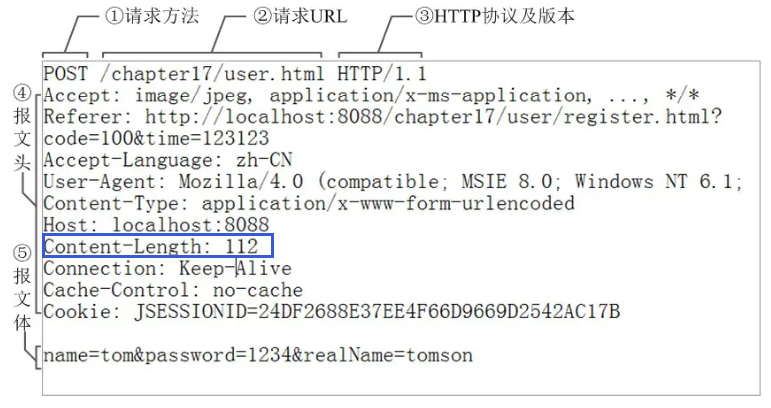
- TLV 格式,即 Type 类型、Length 长度、Value 数据(也就是在消息开头用一些空间存放后面数据的长度),如HTTP请求头中的Content-Type与Content-Length。类型和长度已知的情况下,就可以方便获取消息大小,分配合适的 buffer,缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量
- Http 1.1 是 TLV 格式
- Http 2.0 是 LTV 格式
下文的消息边界处理方式为第二种:按分隔符拆分
附件与扩容
Channel的register方法还有第三个参数:附件,可以向其中放入一个Object类型的对象,该对象会与登记的Channel以及其对应的SelectionKey绑定,可以从SelectionKey获取到对应通道的附件
public final SelectionKey register(Selector sel, int ops, Object att)Copy可通过SelectionKey的attachment()方法获得附件
ByteBuffer buffer = (ByteBuffer) key.attachment();
我们需要在Accept事件发生后,将通道注册到Selector中时,对每个通道添加一个ByteBuffer附件,让每个通道发生读事件时都使用自己的通道,避免与其他通道发生冲突而导致问题
// 设置为非阻塞模式,同时将连接的通道也注册到选择其中,同时设置附件
socketChannel.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16);
// 添加通道对应的Buffer附件
socketChannel.register(selector, SelectionKey.OP_READ, buffer);
当Channel中的数据大于缓冲区时,需要对缓冲区进行扩容操作。此代码中的扩容的判定方法:Channel调用compact方法后,的position与limit相等,说明缓冲区中的数据并未被读取(容量太小),此时创建新的缓冲区,其大小扩大为两倍。同时还要将旧缓冲区中的数据拷贝到新的缓冲区中,同时调用SelectionKey的attach方法将新的缓冲区作为新的附件放入SelectionKey中
// 如果缓冲区太小,就进行扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity()*2);
// 将旧buffer中的内容放入新的buffer中
ewBuffer.put(buffer);
// 将新buffer作为附件放到key中
key.attach(newBuffer);
}
改造后的服务器代码如下
public class SelectServer {
public static void main(String[] args) {
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
// 创建选择器
Selector selector = Selector.open();
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 将通道注册到选择器中,并设置感兴趣的事件
server.register(selector, SelectionKey.OP_ACCEPT);
// 为serverKey设置感兴趣的事件
while (true) {
// 若没有事件就绪,线程会被阻塞,反之不会被阻塞。从而避免了CPU空转
// 返回值为就绪的事件个数
int ready = selector.select();
System.out.println("selector ready counts : " + ready);
// 获取所有事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型
if(key.isAcceptable()) {
// 获得key对应的channel
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
System.out.println("before accepting...");
// 获取连接
SocketChannel socketChannel = channel.accept();
System.out.println("after accepting...");
// 设置为非阻塞模式,同时将连接的通道也注册到选择其中,同时设置附件
socketChannel.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16);
socketChannel.register(selector, SelectionKey.OP_READ, buffer);
// 处理完毕后移除
iterator.remove();
} else if (key.isReadable()) {
SocketChannel channel = (SocketChannel) key.channel();
System.out.println("before reading...");
// 通过key获得附件(buffer)
ByteBuffer buffer = (ByteBuffer) key.attachment();
int read = channel.read(buffer);
if(read == -1) {
key.cancel();
channel.close();
} else {
// 通过分隔符来分隔buffer中的数据
split(buffer);
// 如果缓冲区太小,就进行扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity()*2);
// 将旧buffer中的内容放入新的buffer中
buffer.flip();
newBuffer.put(buffer);
// 将新buffer放到key中作为附件
key.attach(newBuffer);
}
}
System.out.println("after reading...");
// 处理完毕后移除
iterator.remove();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static void split(ByteBuffer buffer) {
buffer.flip();
for(int i = 0; i < buffer.limit(); i++) {
// 遍历寻找分隔符
// get(i)不会移动position
if (buffer.get(i) == '\n') {
// 缓冲区长度
int length = i+1-buffer.position();
ByteBuffer target = ByteBuffer.allocate(length);
// 将前面的内容写入target缓冲区
for(int j = 0; j < length; j++) {
// 将buffer中的数据写入target中
target.put(buffer.get());
}
// 打印结果
ByteBufferUtil.debugAll(target);
}
}
// 切换为写模式,但是缓冲区可能未读完,这里需要使用compact
buffer.compact();
}
}
ByteBuffer的大小分配
- 每个 channel 都需要记录可能被切分的消息,因为 ByteBuffer 不能被多个 channel 共同使用,因此需要为每个 channel 维护一个独立的 ByteBuffer
- ByteBuffer 不能太大,比如一个 ByteBuffer 1Mb 的话,要支持百万连接就要 1Tb 内存,因此需要设计大小可变的 ByteBuffer
- 分配思路可以参考
- 一种思路是首先分配一个较小的 buffer,例如 4k,如果发现数据不够,再分配 8k 的 buffer,将 4k buffer 内容拷贝至 8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能
- 参考实现 Java Resizable Array
- 另一种思路是用多个数组组成 buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗
- 一种思路是首先分配一个较小的 buffer,例如 4k,如果发现数据不够,再分配 8k 的 buffer,将 4k buffer 内容拷贝至 8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能
6、Write事件【向客户端发送数据】

服务器端不能一次性发完所有数据 返回0表示写不了 这样不符合非阻塞思想
当发送缓冲区满了写不了内容的时候就去处理别的事件比如读,这样是最好的。
所以要把while改成if 然后关注可写事件,当缓冲区空了就会自动触发可写事件
selector就会往下运行 不会阻塞在selector.select()。


服务器通过Buffer向通道中写入数据时,可能因为通道容量小于Buffer中的数据大小,导致无法一次性将Buffer中的数据全部写入到Channel中,这时便需要分多次写入,具体步骤如下
-
执行一次写操作,向将buffer中的内容写入到SocketChannel中,然后判断Buffer中是否还有数据
-
若Buffer中还有数据,则需要将SockerChannel注册到Seletor中,并关注写事件,同时将未写完的Buffer作为附件一起放入到SelectionKey中
int write = socket.write(buffer); // 通道中可能无法放入缓冲区中的所有数据 判断是否有剩余内容 if (buffer.hasRemaining()) { // 注册到Selector中,关注可写事件,并将buffer【未写完的事件】添加到key的附件中 不然下次数据从哪来? socket.configureBlocking(false); socket.register(selector, SelectionKey.OP_WRITE, buffer); } -
添加写事件的相关操作
key.isWritable(),对Buffer再次进行写操作- 每次写后需要判断Buffer中是否还有数据(是否写完)。若写完,需要移除SelecionKey中的Buffer附件,避免其占用过多内存,同时还需移除对写事件的关注
SocketChannel socket = (SocketChannel) key.channel(); // 获得buffer ByteBuffer buffer = (ByteBuffer) key.attachment(); // 执行写操作 int write = socket.write(buffer); System.out.println(write); // 如果已经完成了写操作,需要移除key中的附件,同时不再对写事件感兴趣 if (!buffer.hasRemaining()) { key.attach(null); key.interestOps(0); }
整体代码如下
public class WriteServer {
public static void main(String[] args) {
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
server.configureBlocking(false);
//防止非阻塞模式下无谓的轮询
Selector selector = Selector.open();
//注册时就指定关注的事件
server.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 有事件发生时selector才会向下运行
selector.select();
//拿到所有发生的事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 处理后就移除事件
iterator.remove();
// 检查事件类型 accept就建立连接
if (key.isAcceptable()) {
// 获得客户端的通道
SocketChannel socket = server.accept();
// 写入数据
StringBuilder builder = new StringBuilder();
for(int i = 0; i < 500000000; i++) {
builder.append("a");
}
//直接把刚才的字符集转成ByteBuffer 这样就不用计算容量了
ByteBuffer buffer = StandardCharsets.UTF_8.encode(builder.toString());
// 先执行一次Buffer->Channel的写入,如果未写完,就添加一个可写事件
// 返回值代表实际写入的字节数
int write = socket.write(buffer);
System.out.println(write);
// 通道中可能无法放入缓冲区中的所有数据
if (buffer.hasRemaining()) {
// 注册到Selector中,关注可写事件,并将buffer添加到key的附件中
socket.configureBlocking(false);
socket.register(selector, SelectionKey.OP_WRITE, buffer);
}
} else if (key.isWritable()) {
SocketChannel socket = (SocketChannel) key.channel();
// 获得buffer
ByteBuffer buffer = (ByteBuffer) key.attachment();
// 执行写操作
int write = socket.write(buffer);
System.out.println(write);
// 如果已经完成了写操作,需要移除key中的附件,同时不再对写事件感兴趣
if (!buffer.hasRemaining()) {
key.attach(null);
key.interestOps(0);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
网络编程总结


selector配合单线程完成对事件的监控,只有事件发生了才会让你的线程继续运行
不会让线程白忙活。局限性:仅针对网络IO

方法2: 比如1秒内就算没时间发生会继续向下运行
方法3: 不阻塞 立刻返回事件数量

7、优化
多线程优化
充分利用多核CPU,分两组选择器
- 单线程配一个选择器(Boss),专门处理 accept 事件
- 创建 cpu 核心数的线程(Worker),每个线程配一个选择器,轮流处理 read 事件
实现思路
-
创建一个负责处理Accept事件的Boss线程,与多个负责处理Read事件的Worker线程
-
Boss线程执行的操作
-
接受并处理Accepet事件,当Accept事件发生后,调用Worker的register(SocketChannel socket)方法,让Worker去处理Read事件,其中需要根据标识robin去判断将任务分配给哪个Worker
// 创建固定数量的Worker Worker[] workers = new Worker[4]; // 用于负载均衡的原子整数 AtomicInteger robin = new AtomicInteger(0); // 负载均衡,轮询分配Worker workers[robin.getAndIncrement()% workers.length].register(socket);Copy -
register(SocketChannel socket)方法会通过同步队列完成Boss线程与Worker线程之间的通信,让SocketChannel的注册任务被Worker线程执行。添加任务后需要调用selector.wakeup()来唤醒被阻塞的Selector
public void register(final SocketChannel socket) throws IOException { // 只启动一次 if (!started) { // 初始化操作 } // 向同步队列中添加SocketChannel的注册事件 // 在Worker线程中执行注册事件 queue.add(new Runnable() { @Override public void run() { try { socket.register(selector, SelectionKey.OP_READ); } catch (IOException e) { e.printStackTrace(); } } }); // 唤醒被阻塞的Selector // select类似LockSupport中的park,wakeup的原理类似LockSupport中的unpark selector.wakeup(); }Copy
-
-
Worker线程执行的操作
- 从同步队列中获取注册任务,并处理Read事件
实现代码
public class ThreadsServer {
public static void main(String[] args) {
try (ServerSocketChannel server = ServerSocketChannel.open()) {
// 当前线程为Boss线程
Thread.currentThread().setName("Boss");
server.bind(new InetSocketAddress(8080));
// 负责轮询Accept事件的Selector
Selector boss = Selector.open();
server.configureBlocking(false);
server.register(boss, SelectionKey.OP_ACCEPT);
// 创建固定数量的Worker
Worker[] workers = new Worker[4];
// 用于负载均衡的原子整数
AtomicInteger robin = new AtomicInteger(0);
for(int i = 0; i < workers.length; i++) {
workers[i] = new Worker("worker-"+i);
}
while (true) {
boss.select();
Set<SelectionKey> selectionKeys = boss.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// BossSelector负责Accept事件
if (key.isAcceptable()) {
// 建立连接
SocketChannel socket = server.accept();
System.out.println("connected...");
socket.configureBlocking(false);
// socket注册到Worker的Selector中
System.out.println("before read...");
// 负载均衡,轮询分配Worker
workers[robin.getAndIncrement()% workers.length].register(socket);
System.out.println("after read...");
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
static class Worker implements Runnable {
private Thread thread;
private volatile Selector selector;
private String name;
private volatile boolean started = false;
/**
* 同步队列,用于Boss线程与Worker线程之间的通信
*/
private ConcurrentLinkedQueue<Runnable> queue;
public Worker(String name) {
this.name = name;
}
public void register(final SocketChannel socket) throws IOException {
// 只启动一次
if (!started) {
thread = new Thread(this, name);
selector = Selector.open();
queue = new ConcurrentLinkedQueue<>();
thread.start();
started = true;
}
// 向同步队列中添加SocketChannel的注册事件
// 在Worker线程中执行注册事件
queue.add(new Runnable() {
@Override
public void run() {
try {
socket.register(selector, SelectionKey.OP_READ);
} catch (IOException e) {
e.printStackTrace();
}
}
});
// 唤醒被阻塞的Selector
// select类似LockSupport中的park,wakeup的原理类似LockSupport中的unpark
selector.wakeup();
}
@Override
public void run() {
while (true) {
try {
selector.select();
// 通过同步队列获得任务并运行
Runnable task = queue.poll();
if (task != null) {
// 获得任务,执行注册操作
task.run();
}
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while(iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// Worker只负责Read事件
if (key.isReadable()) {
// 简化处理,省略细节
SocketChannel socket = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(16);
socket.read(buffer);
buffer.flip();
ByteBufferUtil.debugAll(buffer);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}Copy四、NIO与BIO
1、Stream与Channel
- stream 不会自动缓冲数据,channel 会利用系统提供的发送缓冲区、接收缓冲区(更为底层)
- stream 仅支持阻塞 API,channel 同时支持阻塞、非阻塞 API,网络 channel 可配合 selector 实现多路复用
- 二者均为全双工,即读写可以同时进行
- 虽然Stream是单向流动的,但是它也是全双工的
2、IO模型
- 同步:线程自己去获取结果(一个线程)
- 例如:线程调用一个方法后,需要等待方法返回结果
- 异步:线程自己不去获取结果,而是由其它线程返回结果(至少两个线程)
- 例如:线程A调用一个方法后,继续向下运行,运行结果由线程B返回
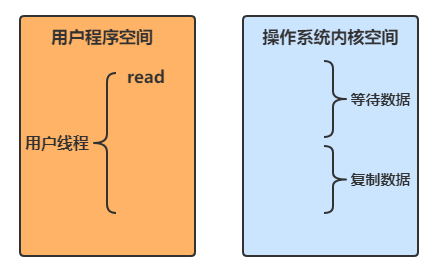
当调用一次 channel.read 或 stream.read 后,会由用户态切换至操作系统内核态来完成真正数据读取,而读取又分为两个阶段,分别为:
-
等待数据阶段
-
复制数据阶段

根据UNIX 网络编程 - 卷 I,IO模型主要有以下几种
阻塞IO
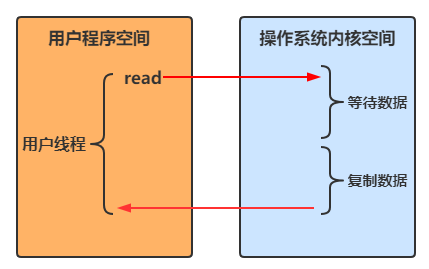
- 用户线程进行read操作时,需要等待操作系统执行实际的read操作,此期间用户线程是被阻塞的,无法执行其他操作
非阻塞IO

- 用户线程在一个循环中一直调用read方法,若内核空间中还没有数据可读,立即返回
- 只是在等待阶段非阻塞
- 用户线程发现内核空间中有数据后,等待内核空间执行复制数据,待复制结束后返回结果
多路复用
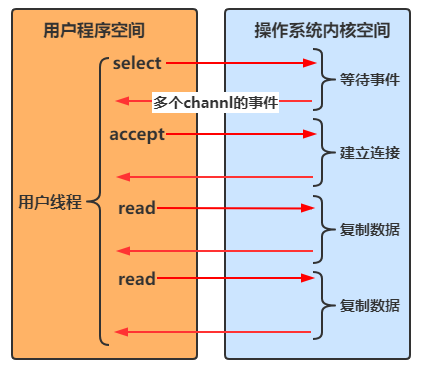
Java中通过Selector实现多路复用
- 当没有事件是,调用select方法会被阻塞住
- 一旦有一个或多个事件发生后,就会处理对应的事件,从而实现多路复用
多路复用与阻塞IO的区别
- 阻塞IO模式下,若线程因accept事件被阻塞,发生read事件后,仍需等待accept事件执行完成后,才能去处理read事件
- 多路复用模式下,一个事件发生后,若另一个事件处于阻塞状态,不会影响该事件的执行
异步IO
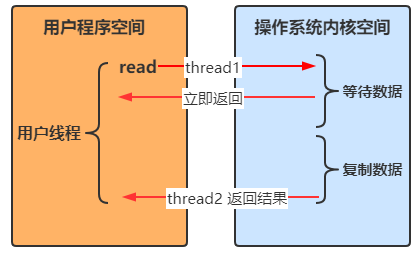
- 线程1调用方法后理解返回,不会被阻塞也不需要立即获取结果
- 当方法的运行结果出来以后,由线程2将结果返回给线程1
3、零拷贝
零拷贝指的是数据无需拷贝到 JVM 内存中,同时具有以下三个优点
- 更少的用户态与内核态的切换
- 不利用 cpu 计算,减少 cpu 缓存伪共享
- 零拷贝适合小文件传输
传统 IO 问题
传统的 IO 将一个文件通过 socket 写出
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);Copy内部工作流如下
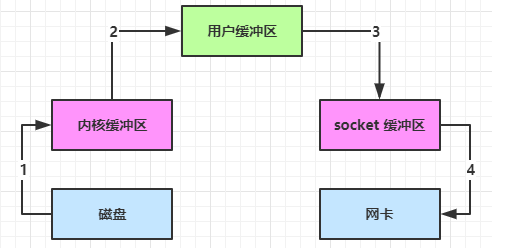
-
Java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 Java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 CPU
DMA 也可以理解为硬件单元,用来解放 cpu 完成文件 IO -
从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 CPU 会参与拷贝,无法利用 DMA
-
调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,CPU 会参与拷贝
-
接下来要向网卡写数据,这项能力 Java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 CPU
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
NIO 优化
通过 DirectByteBuf
- ByteBuffer.allocate(10)
- 底层对应 HeapByteBuffer,使用的还是 Java 内存
- ByteBuffer.allocateDirect(10)
- 底层对应DirectByteBuffer,使用的是操作系统内存
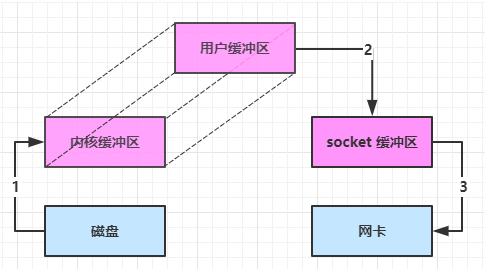
大部分步骤与优化前相同,唯有一点:Java 可以使用 DirectByteBuffer 将堆外内存映射到 JVM 内存中来直接访问使用
- 这块内存不受 JVM 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- Java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuffer 对象被垃圾回收,将虚引用加入引用队列
- 当引用的对象ByteBuffer被垃圾回收以后,虚引用对象Cleaner就会被放入引用队列中,然后调用Cleaner的clean方法来释放直接内存
- DirectByteBuffer 的释放底层调用的是 Unsafe 的 freeMemory 方法
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- DirectByteBuffer 对象被垃圾回收,将虚引用加入引用队列
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
进一步优化1
以下两种方式都是零拷贝,即无需将数据拷贝到用户缓冲区中(JVM内存中)
底层采用了 linux 2.1 后提供的 sendFile 方法,Java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据
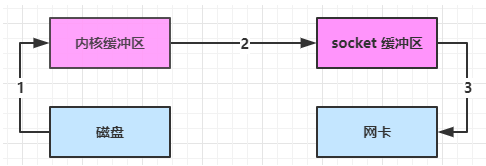
-
Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 CPU
-
数据从内核缓冲区传输到 socket 缓冲区,CPU 会参与拷贝
-
最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 CPU
这种方法下
- 只发生了1次用户态与内核态的切换
- 数据拷贝了 3 次
进一步优化2
linux 2.4 对上述方法再次进行了优化
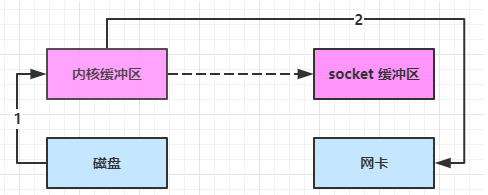
-
Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 CPU
-
只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
-
使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 CPU
整个过程仅只发生了1次用户态与内核态的切换,数据拷贝了 2 次
4、AIO
AIO 用来解决数据复制阶段的阻塞问题
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统(Kernel)提供支持
- Windows 系统通过 IOCP 实现了真正的异步 IO
- Linux 系统异步 IO 在 2.6 版本引入,但其底层实现还是用多路复用模拟了异步 IO,性能没有优势
智能推荐
论文阅读笔记——野外和非侵入性遗传方法评估棕熊种群规模_棕熊 微卫星标记-程序员宅基地
文章浏览阅读497次。论文阅读笔记论文简介标题期刊情况论文内容摘要介绍论文简介标题英文:《An evaluation of field and non-invasive genetic methodsto estimate brown bear (Ursus arctos) population size》翻译:《野外和非侵入性遗传方法评估棕熊种群规模》期刊情况期刊:《Biological Conservation》期刊情况:2020年影响因子:4.711JCR分区 / 中科院分区:Q1 / 2区审_棕熊 微卫星标记
如何将手机变成一个(Linux)服务器_手机改服务器-程序员宅基地
文章浏览阅读2.2w次,点赞16次,收藏103次。看到就是赚到_手机改服务器
java double转String,去掉科学计数法_数值类型转成字符串后,不要用科学计数法-程序员宅基地
文章浏览阅读1.8k次。在数值型double转String格式时,如果同时遇到数值较大的double和小数位较多的double处理方法:double a = 123456789.10001;double b = 1.987654321;System.out.println("a: " + a);System.out.println("b: " + b);java.text.NumberFormat NF = java.text.NumberFormat.getInstance();//设置数值的小数部分所允许的最大._数值类型转成字符串后,不要用科学计数法
Fiddler抓包—手机app抓包_fiddler 移动端 app抓包-程序员宅基地
文章浏览阅读1.3k次。Fiddler抓包工作原理正常情况下,手机app是直接向服务器请求数据的,如果通过Fiddler抓包那么需要通过Fiddler,再向服务器请求数据。当app数据传到Fiddler,那么可以将请求的数据进行修改。比如app请求"123456",那么Fiddler可以将这一串数字改成"1",再发给服务器。此时服务器接收到的数据就是"1"。服务器返回数据到app和请求数据是一样的道理。Fid..._fiddler 移动端 app抓包
【200326】R语言read.table的用法以及报错line 6 did not have 15 elements 读取的项目数必需是列数的倍数-程序员宅基地
文章浏览阅读1.9w次,点赞10次,收藏32次。以2020美赛C题数据为例data <- read.table("D:\\mm\\Problem_C_Data\\hair_dryer.tsv" ,header = T, sep ="\t",dec = ".",quote="",comment.char = "",na.strings = c("NA"),fill=T)因为是tsv:Tab-separated values即制表符..._读取的项目数必需是列数的倍数
在使用Notepad++ WinSCP SFTP遇到的连接失败问题分析_如何使用notepad连接服务器一直失败-程序员宅基地
文章浏览阅读5.5k次。终于解决了一个困扰我几次的问题。在此经验分享一下,希望能帮到遇到同样问题的朋友。问题的起因是想使用Notepad++连接SFTP服务器,无法成功建立连接,总是停在通过验证后。Notepad++中的NppFTP插件一直显示”NppFTP - connecting“,无法取消,也不能进行其他操作。[NppFTP] Everything initializedConnecting_如何使用notepad连接服务器一直失败
随便推点
Vue组件开发——异步组件_vue2 defineasynccomponent-程序员宅基地
文章浏览阅读566次。一、引入我们在讲异步组件之前,我们再来回顾一下webpack打包时的分包操作。我们可以使用import()异步加载模块来实现分包操作。import函数的返回值是一个Promise,所以我们可以使用then进行下一步处理。如下图所示为打包后的文件目录,因为我们如果同步加载math.js文件,此时就不存在中间的文件,此时当浏览器请求资源时,就会很慢。二、vue中的异步组件通过上面的webpack配置我们明白了为什么要进行分包操作,此时我们想一个问题,如果一个网站的页面在用户第一次浏览器时就将全部页面_vue2 defineasynccomponent
解决ToolBox升级IDEA后导致之前配置的插件消失问题(附:IDEA2020版本前后配置文件地址)【修理篇】_toolbox 下载的ide没有copy之前的插件进来-程序员宅基地
文章浏览阅读2.5k次。【修理篇】ToolBox升级IDEA后之前配置的插件消失问题(附:IDEA2020版本前后配置文件地址) 在IDEA的插件配置地址都是可配置的,通过修改idea.properties可指定插件和logs的地址等这个配置文件地址在IDEA2020.1版本后出现了一些变化。如下:2020.1版本之前:配置文件地址在IDEA安装目录的bin目录下。2020.1版本之后:在此版本之后有两种方法。1.从C盘\User\Administrator里开始找AppData\Roaming\JetBra_toolbox 下载的ide没有copy之前的插件进来
File Monitor on WinRT-程序员宅基地
文章浏览阅读48次。http://lunarfrog.com/blog/filesystem-change-notifications Use CreateFileQueryWithOptions to add file monitor(win32 use file watcher).* By default it FolderDepth is Shallow(root folder only), D..._file monitor on window server
vue2 + electron 用超简单方法搭建前端桌面应用_vue 2.0 安装electron-程序员宅基地
文章浏览阅读564次。vue2 + electron 非常简单的搭建方法_vue 2.0 安装electron
【初学者】SVG图片加载失败,求解_解析失败 (带有png备选的svg(mathml可通过浏览器插件启用)-程序员宅基地
文章浏览阅读2.6k次。最近在做期末作业,用Jekyll架站,前几天添加的svg图片还能加载,今天就不能了在hbuilder上是这样写的,前几天添加的svg图片还能加载,今天就不能了。用chrome检查是这样的请问应该怎么解决?..._解析失败 (带有png备选的svg(mathml可通过浏览器插件启用)
html2canvas (踩坑) 网络图片显示不出来&生成图片只有一半或者空白&文字显示不出来问题处理_htm2canvas 图片只有左边一半-程序员宅基地
文章浏览阅读1.8w次,点赞7次,收藏13次。这里只提供解决思路,代码就不粘贴出来了图片显示不出来就像大多数人说的一样,HTML中的图片产生了跨域,可以将网络图片转为base64后修改img 的src属性值,添加图片允许跨域的属性。调用html2canvas的API时,将跨域参数设置为true,允许跨域。图片生成显示不全,只有半截或者空白在有滚动的页面,产生了滚动条后,生成的图片可能会只有一半或者空白。答案只有一个,那就是要把html2canvas的配置项参数中,scrollx,scrolly都设置为0,问题就解决了。 o゚*。o恭_htm2canvas 图片只有左边一半