数据湖在大数据场景下应用和实施方案调研笔记(增强版)-程序员宅基地
技术标签: java 编程语言 hadoop 数据库 大数据
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

在读本文前你应该看过这些:
本篇一个总结的增强版。
网上目前关于 Flink 集成 Hudi、IceBerg的资料较少,社区建设不够完善。且因为迭代版本原因,代码过期严重。后面我会专门写一篇Flink连接Hudi、IceBerg等的文章。
炒作概念还是未来趋势?
数据湖是目前比较热的一个概念,许多企业都在构建或者计划构建自己的数据湖。但是在计划构建数据湖之前,搞清楚什么是数据湖,明确一个数据湖项目的基本组成,进而设计数据湖的基本架构,对于数据湖的构建至关重要。关于什么是数据湖?有不同的定义。
Wikipedia上说数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件,包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)。AWS定义数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。
微软的定义就更加模糊了,并没有明确给出什么是Data Lake,而是取巧的将数据湖的功能作为定义,数据湖包括一切使得开发者、数据科学家、分析师能更简单的存储、处理数据的能力,这些能力使得用户可以存储任意规模、任意类型、任意产生速度的数据,并且可以跨平台、跨语言的做所有类型的分析和处理。
关于数据湖的定义其实很多,但是基本上都围绕着以下几个特性展开。
1、 数据湖需要提供足够用的数据存储能力,这个存储保存了一个企业/组织中的所有数据。
2、 数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
3、 数据湖中的数据是原始数据,是业务数据的完整副本。数据湖中的数据保持了他们在业务系统中原来的样子。
4、 数据湖需要具备完善的数据管理能力(完善的元数据),可以管理各类数据相关的要素,包括数据源、数据格式、连接信息、数据schema、权限管理等。
5、 数据湖需要具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习;同时,还需要提供一定的任务调度和管理能力。
6、 数据湖需要具备完善的数据生命周期管理能力。不光需要存储原始数据,还需要能够保存各类分析处理的中间结果,并完整的记录数据的分析处理过程,能帮助用户完整详细追溯任意一条数据的产生过程。
7、 数据湖需要具备完善的数据获取和数据发布能力。数据湖需要能支撑各种各样的数据源,并能从相关的数据源中获取全量/增量数据;然后规范存储。数据湖能将数据分析处理的结果推送到合适的存储引擎中,满足不同的应用访问需求。
8、 对于大数据的支持,包括超大规模存储以及可扩展的大规模数据处理能力。
综上,个人认为数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。
不同企业的典型应用
目前在生产上可以用的经验不多,笔者个人在调研技术方案时参考了目前市面上公开的众多资料,供团队在数据架构设计和选型上进行参考。
华为生产场景数据湖平台建设实践
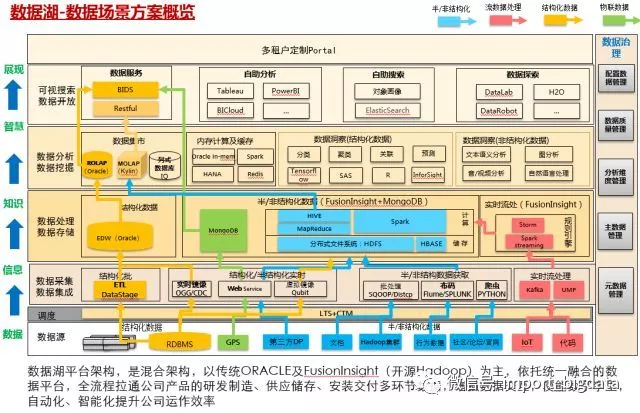
该平台围绕数据分如下三大逻辑模块:

典型数据应用场景按应用场景,对数据流程、处理平台进行的标注:
(绿色)结构化数据通过批处理、虚拟镜像到Hive数据,再通过Kylin预处理将数据储存在Cube中,封装成RESTAPI服务,提供高并发亚秒级查询服务,监测物料质量情况;
(红色)IoT数据,通过sensor采集上报到MQS,走storm实时分拣到HBase,通过算法模型加工后进行ICT物料预警监测;
(黄色)条码数据通过ETLloader到IQ列式数据湖,经过清洗加工后,提供千亿规模条码扫描操作。
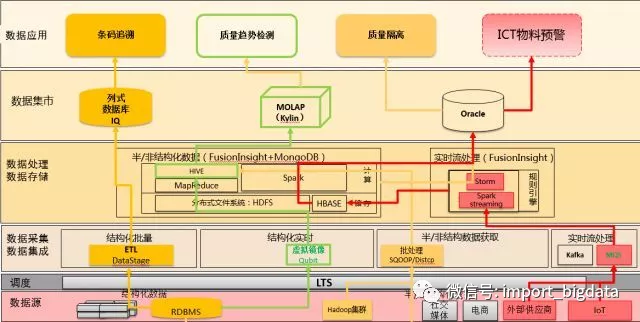
非结构化质检图片数据:
通过web前台、数据API服务,进行图片数据的上传及查询,图片需要有唯一ID作为标示,确保可检索。海量图片数据以ID为rowkey,储存于Hbase平台,提供快速储存及查询能力。数据资产上有以下方面的构建:
统一索引描述非结构数据,方便数据检索分析。
增加维护及更新时间作为对象描述字段(图片类型、像素大小、尺寸规格)。非对象方式及数字化属性编目(全文文本、图像、声音、影视、超媒体等信息),自定义元数据。
不同类型的数据可以形成了关联并处理非结构化数据。

实时金融数据湖的应用
在功能上,包括数据源、统一的数据接入、数据存储、数据开发、数据服务和数据应用。
第一,数据源。不仅仅支持结构化数据,也支持半结构化数据和非结构化数据。
第二,统一数据接入。数据通过统一数据接入平台,按数据的不同类型进行智能的数据接入。
第三,数据存储。包括数据仓库和数据湖,实现冷热温智能数据分布。
第四,数据开发。包括任务开发,任务调度,监控运维,可视化编程。
第五,数据服务。包括交互式查询,数据 API,SQL 质量评估,元数据管理,血缘管理。
第六,数据应用。包括数字化营销,数字化风控,数据化运营,客户画像。

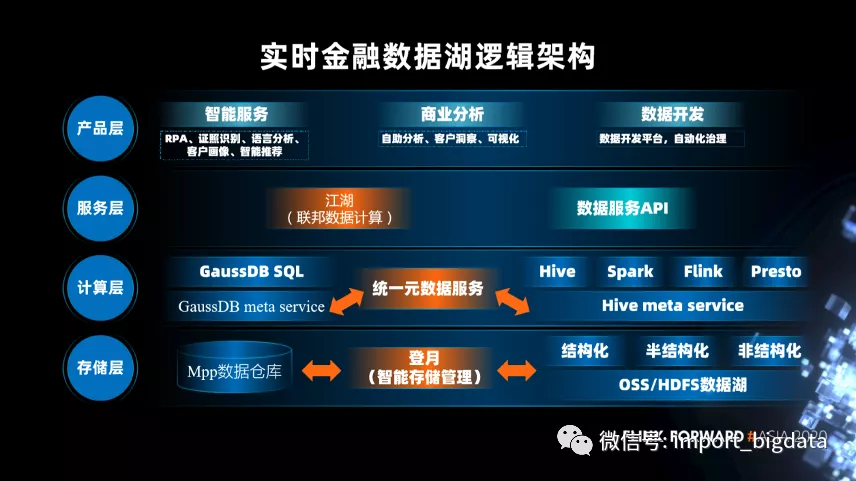
在逻辑上,实时金融数据湖的逻辑架构主要有 4 层,包括存储层、计算层、服务层和产品层。
在存储层,有 MPP 数据仓库和基于 OSS/HDFS 的数据湖,可以实现智能存储管理。
在计算层,实现统一的元数据服务。
在服务层,有联邦数据计算和数据服务 API 两种方式。其中,联邦数据计算服务是一个联邦查询引擎,可以实现数据跨库查询,它依赖的就是统一元数据服务,查询的是数据仓库和数据湖中的数据。
在产品层,提供智能服务:包 RPA、证照识别、语言分析、客户画像、智能推荐。商业分析服务:包括自助分析、客户洞察、可视化。数据开发服务:包括数据开发平台,自动化治理。
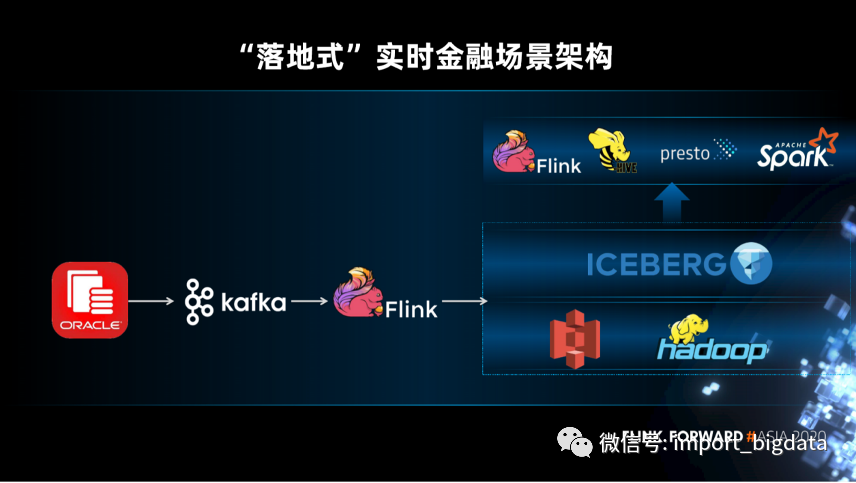
整个实时场景架构:
数据源被实时接入到 Kafka 之后,Flink 可以实时处理 Kafka 的数据,并将处理的结果写入到数据湖中。数据湖整体基于开源方案搭建,数据的存储是用的 HDFS 和 S3,表格式用的是 Iceberg。Flink 读取完 Kafka 的数据之后进行实时处理,这时候可以把处理的中间结果写入到数据湖中,然后再进行逐步处理,最终得到业务想要的结果。处理的结果可以通过查询引擎对接应用,包括 Flink、Spark、Presto 等。

Soul的Delta Lake数据湖应用实践
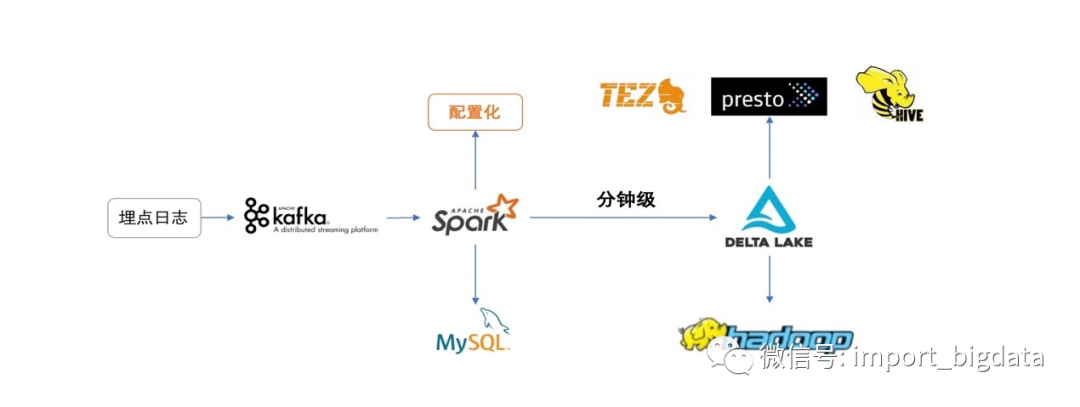
数据由各端埋点上报至Kafka,通过Spark任务分钟级以Delta的形式写入HDFS,然后在Hive中自动化创建Delta表的映射表,即可通过Hive MR、Tez、Presto等查询引擎直接进行数据查询及分析。
我们基于Spark,封装了通用化ETL工具,实现了配置化接入,用户无需写代码即可实现源数据到Hive的整体流程接入。并且,为了更加适配业务场景,我们在封装层实现了多种实用功能:
实现了类似Iceberg的hidden partition功能,用户可选择某些列做适当变化形成一个新的列,此列可作为分区列,也可作为新增列,使用SparkSql操作。如:有日期列date,那么可以通过 'substr(date,1,4) as year' 生成新列,并可以作为分区。
为避免脏数据导致分区出错,实现了对动态分区的正则检测功能,比如:Hive中不支持中文分区,用户可以对动态分区加上'\w+'的正则检测,分区字段不符合的脏数据则会被过滤。
实现自定义事件时间字段功能,用户可选数据中的任意时间字段作为事件时间落入对应分区,避免数据漂移问题。
嵌套Json自定义层数解析,我们的日志数据大都为Json格式,其中难免有很多嵌套Json,此功能支持用户选择对嵌套Json的解析层数,嵌套字段也会被以单列的形式落入表中。
实现SQL化自定义配置动态分区的功能,解决埋点数据倾斜导致的实时任务性能问题,优化资源使用,此场景后面会详细介绍。
数据湖方案调研
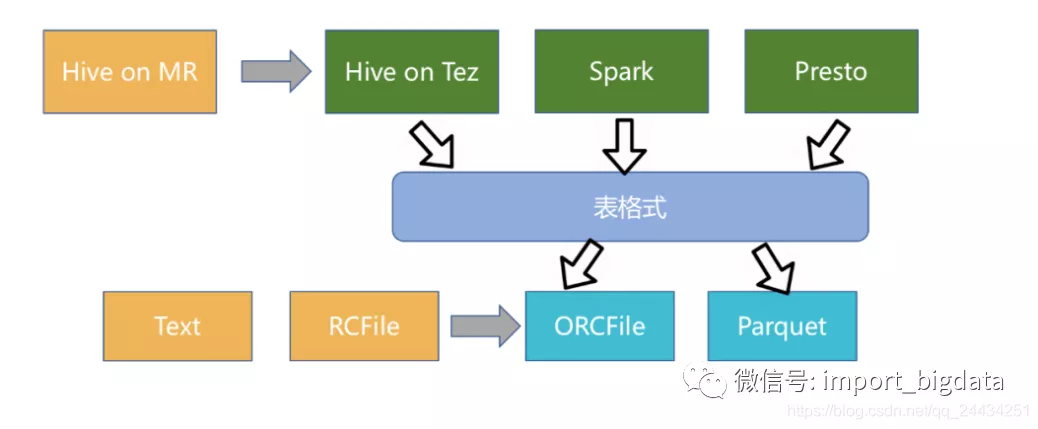
1、Iceberg
Iceberg 作为新兴的数据湖框架之一,开创性的抽象出“表格式”table format"这一中间层,既独立于上层的计算引擎(如Spark和Flink)和查询引擎(如Hive和Presto),也和下层的文件格式(如Parquet,ORC和Avro)相互解耦。
此外 Iceberg 还提供了许多额外的能力:
ACID事务;
时间旅行(time travel),以访问之前版本的数据
完备的自定义类型、分区方式和操作的抽象
列和分区方式可以进化,而且进化对用户无感,即无需重新组织或变更数据文件
隐式分区,使SQL不用针对分区方式特殊优化
面向云存储的优化等
Iceberg的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。
所以 Iceberg 的架构更加的优雅,对于数据格式、类型系统有完备的定义和可进化的设计。
但是 Iceberg 缺少行级更新、删除能力,这两大能力是现有数据组织最大的卖点,社区仍然在优化中。
2、Hudi
Hudi 是什么?
一般来说,我们会将大量数据存储到HDFS/S3,新数据增量写入,而旧数据鲜有改动,特别是在经过数据清洗,放入数据仓库的场景。
且在数据仓库如 hive中,对于update的支持非常有限,计算昂贵。
另一方面,若是有仅对某段时间内新增数据进行分析的场景,则hive、presto、hbase等也未提供原生方式,而是需要根据时间戳进行过滤分析。
Apache Hudi 代表 Hadoop Upserts and Incrementals,能够使HDFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
Hudi数据集通过自定义的 inputFormat 兼容当前 Hadoop 生态系统,包括 Apache Hive,Apache Parquet,Presto 和 Apache Spark,使得终端用户可以无缝的对接。
如下图,基于 Hudi 简化的服务架构,分钟级延迟。

Hudi 存储的架构

如上图,最下面有一个时间轴,这是 Hudi 的核心。
Hudi 会维护一个时间轴,在每次执行操作时(如写入、删除、合并等),均会带有一个时间戳。
通过时间轴,可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据。这样可以避免扫描更大的时间范围,并非常高效地只消费更改过的文件(例如在某个时间点提交了更改操作后,仅 query 某个时间点之前的数据,则仍可以 query 修改前的数据)。
如上图的左边,Hudi 将数据集组织到与 Hive 表非常相似的基本路径下的目录结构中。
数据集分为多个分区,每个分区均由相对于基本路径的分区路径唯一标识。
如上图的中间部分,Hudi 以两种不同的存储格式存储所有摄取的数据。
读优化的列存格式(ROFormat):仅使用列式文件(parquet)存储数据。在写入/更新数据时,直接同步合并原文件,生成新版本的基文件(需要重写整个列数据文件,即使只有一个字节的新数据被提交)。此存储类型下,写入数据非常昂贵,而读取的成本没有增加,所以适合频繁读的工作负载,因为数据集的最新版本在列式文件中始终可用,以进行高效的查询。
写优化的行存格式(WOFormat):使用列式(parquet)与行式(avro)文件组合,进行数据存储。在更新记录时,更新到增量文件中(avro), 然后进行异步(或同步)的compaction,创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以appending 的模式写入增量文件中。但是在读取数据集时,需要将增量文件与旧文件进行合并,生成列式文件。
3、DeltaLake
传统的 lambda 架构需要同时维护批处理和流处理两套系统,资源消耗大,维护复杂。基于 Hive 的数仓或者传统的文件存储格式(比如 parquet / ORC),都存在一些难以解决的问题:
小文件问题
并发读写问题
有限的更新支持
海量元数据(例如分区)导致 metastore 不堪重负

如上图,Delta Lake 是 Spark 计算框架和存储系统之间带有 Schema 信息的存储中间层。它有一些重要的特性:
设计了基于 HDFS 存储的元数据系统,解决 metastore 不堪重负的问题;
支持更多种类的更新模式,比如 Merge / Update / Delete 等操作,配合流式写入或者读取的支持,让实时数据湖变得水到渠成;
流批操作可以共享同一张表;
版本概念,可以随时回溯,避免一次误操作或者代码逻辑而无法恢复的灾难性后果。
Delta Lake 是基于 Parquet 的存储层,所有的数据都是使用 Parquet 来存储,能够利用 parquet 原生高效的压缩和编码方案。
Delta Lake 在多并发写入之间提供 ACID 事务保证。每次写入都是一个事务,并且在事务日志中记录了写入的序列顺序。
事务日志跟踪文件级别的写入并使用乐观并发控制,这非常适合数据湖,因为多次写入/修改相同的文件很少发生。在存在冲突的情况下,Delta Lake 会抛出并发修改异常以便用户能够处理它们并重试其作业。
Delta Lake 其实只是一个 Lib 库,不是一个 service,不需要单独部署,而是直接依附于计算引擎的,但目前只支持 spark 引擎,使用过程中和 parquet 唯一的区别是把 format parquet 换成 delta 即可,可谓是部署和使用成本极低。
数据湖技术比较

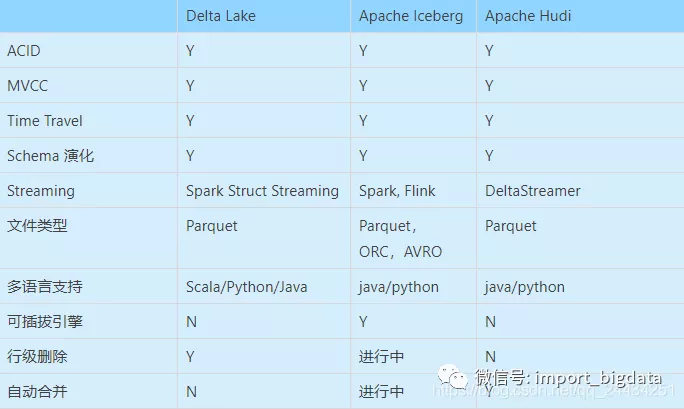
总结



Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
4万字长文 | ClickHouse基础&实践&调优全视角解析
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan