tensorflow学习笔记(十九):分布式Tensorflow-程序员宅基地
技术标签: tensorflow tensorflow学习笔记
最近在学习怎么分布式Tensorflow训练深度学习模型,看官网教程看的云里雾里,最终结合着其它资料,终于对分布式Tensorflow有了些初步了解.
gRPC (google remote procedure call)
分布式Tensorflow底层的通信是gRPC
gRPC首先是一个RPC,即远程过程调用,通俗的解释是:假设你在本机上执行一段代码num=add(a,b),它调用了一个过程 call,然后返回了一个值num,你感觉这段代码只是在本机上执行的, 但实际情况是,本机上的add方法是将参数打包发送给服务器,然后服务器运行服务器端的add方法,返回的结果再将数据打包返回给客户端.
Cluster.Job.Task
Job是Task的集合.
Cluster是Job的集合
为什么要分成Cluster,Job,和Task呢?
首先,我们介绍一下Task:Task就是主机上的一个进程,在大多数情况下,一个机器上只运行一个Task.
为什么Job是Task的集合呢? 在分布式深度学习框架中,我们一般把Job划分为Parameter和Worker,Parameter Job是管理参数的存储和更新工作.Worker Job是来运行ops.如果参数的数量太大,一台机器处理不了,这就要需要多个Tasks.
Cluster 是 Jobs 的集合: Cluster(集群),就是我们用的集群系统了
如何创建集群
从上面的描述我们可以知道,组成Cluster的基本单位是Task(动态上理解,主机上的一个进程,从静态的角度理解,Task就是我们写的代码).我们只需编写Task代码,然后将代码运行在不同的主机上,这样就构成了Cluster(集群)
如何编写Task代码
首先,Task需要知道集群上都有哪些主机,以及它们都监听什么端口.tf.train.ClusterSpec()就是用来描述这个.
tf.train.ClusterSpec({
"worker": [
"worker_task0.example.com:2222",# /job:worker/task:0 运行的主机
"worker_task1.example.com:2222",# /job:worker/task:1 运行的主机
"worker_task2.example.com:2222"# /job:worker/task:3 运行的主机
],
"ps": [
"ps_task0.example.com:2222", # /job:ps/task:0 运行的主机
"ps_task1.example.com:2222" # /job:ps/task:0 运行的主机
]})这个ClusterSec告诉我们,我们这个Cluster(集群)有两个Job(worker.ps),worker中有三个Task(即,有三个Task执行Tensorflow op操作)
然后,将ClusterSpec当作参数传入到 tf.train.Server()中,同时指定此Task的Job_name和task_index.
#jobName和taskIndex是函数运行时,通过命令行传递的参数
server = tf.train.Server(cluster, job_name=jobName, task_index=taskIndex)下面代码描述的是,一个cluster中有一个Job,叫做(worker), 这个job有两个task,这两个task是运行在两个主机上的
#在主机(10.1.1.1)上,实际是运行以下代码
cluster = tf.train.ClusterSpec({
"worker": ["10.1.1.1:2222", "10.1.1.2:3333"]})
server = tf.train.Server(cluster, job_name="local", task_index=0)
#在主机(10.1.1.2)上,实际运行以下代码
cluster = tf.train.ClusterSpec({
"worker": ["10.1.1.1:2222", "10.1.1.2:3333"]})
server = tf.train.Server(cluster, job_name="local", task_index=1)tf.trian.Server干了些什么呢?
首先,一个tf.train.Server包含了: 本地设备(GPUs,CPUs)的集合,可以连接到到其它task的ip:port(存储在cluster中), 还有一个session target用来执行分布操作.还有最重要的一点就是,它创建了一个服务器,监听port端口,如果有数据传过来,他就会在本地执行(启动session target,调用本地设备执行运算),然后结果返回给调用者.
我们继续来写我们的task代码:在你的model中指定分布式设备
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(...)
biases_1 = tf.Variable(...)
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(...)
biases_2 = tf.Variable(...)
with tf.device("/job:worker/task:0"): #映射到主机(10.1.1.1)上去执行
input, labels = ...
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
with tf.device("/job:worker/task:1"): #映射到主机(10.1.1.2)上去执行
input, labels = ...
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
# ...
train_op = ...
with tf.Session("grpc://10.1.1.2:3333") as sess:#在主机(10.1.1.2)上执行run
for _ in range(10000):
sess.run(train_op)with tf.Session("grpc://..")是指定gprc://..为master,master将op分发给对应的task
写分布式程序时,我们需要关注一下问题:
(1) 使用In-graph replication还是Between-graph replication
In-graph replication:一个client(显示调用tf::Session的进程),将里面的参数和ops指定给对应的job去完成.数据分发只由一个client完成.
Between-graph replication:下面的代码就是这种形式,有很多独立的client,各个client构建了相同的graph(包含参数,通过使用tf.train.replica_device_setter,将这些参数映射到ps_server上.)
(2)同步训练,还是异步训练
Synchronous training:在这种方式中,每个graph的副本读取相同的parameter的值,并行的计算gradients,然后将所有计算完的gradients放在一起处理.Tensorlfow提供了函数(tf.train.SyncReplicasOptimizer)来处理这个问题(在Between-graph replication情况下),在In-graph replication将所有的gradients平均就可以了
Asynchronous training:自己计算完gradient就去更新paramenter,不同replica之间不会去协调进度
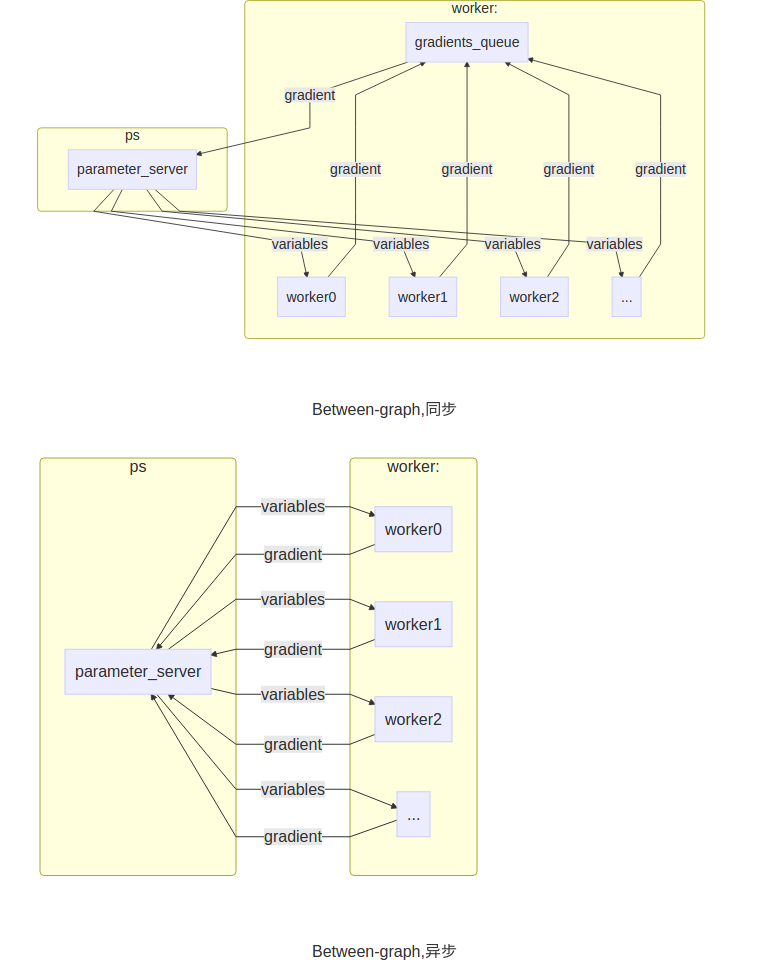
(3)
一个完整的例子,来自官网链接:
import tensorflow as tf
# Flags for defining the tf.train.ClusterSpec
tf.app.flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
# Flags for defining the tf.train.Server
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS由于是相同的代码运行在不同的主机上,所以要传入job_name和task_index加以区分,而ps_hosts和worker_hosts对于所有主机来说,都是一样的,用来描述集群的
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({
"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()我们都知道,服务器进程如果执行完的话,服务器就会关闭.为了是我们的ps_server能够一直处于监听状态,我们需要使用server.join().这时,进程就会block在这里.至于为什么ps_server刚创建就join呢:原因是因为下面的代码会将参数指定给ps_server保管,所以ps_server静静的监听就好了.
elif FLAGS.job_name == "worker":
# Assigns ops to the local worker by default.
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):tf.train.replica_device_setter(ps_tasks=0, ps_device='/job:ps', worker_device='/job:worker', merge_devices=True, cluster=None, ps_ops=None)),返回值可以被tf.device使用,指明下面代码中variable和ops放置的设备.
example:
# To build a cluster with two ps jobs on hosts ps0 and ps1, and 3 worker
# jobs on hosts worker0, worker1 and worker2.
cluster_spec = {
"ps": ["ps0:2222", "ps1:2222"],
"worker": ["worker0:2222", "worker1:2222", "worker2:2222"]}
with tf.device(tf.replica_device_setter(cluster=cluster_spec)):
# Build your graph
v1 = tf.Variable(...) # assigned to /job:ps/task:0
v2 = tf.Variable(...) # assigned to /job:ps/task:1
v3 = tf.Variable(...) # assigned to /job:ps/task:0
# Run compute这个例子是没有指定参数worker_device和ps_device的,你可以手动指定
继续代码注释,下面就是,模型的定义了
# Build model...variables and ops
loss = ...
global_step = tf.Variable(0)
train_op = tf.train.AdagradOptimizer(0.01).minimize(
loss, global_step=global_step)
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
# Create a "supervisor", which oversees the training process.
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
logdir="/tmp/train_logs",
init_op=init_op,
summary_op=summary_op,
saver=saver,
global_step=global_step,
save_model_secs=600)
# The supervisor takes care of session initialization, restoring from
# a checkpoint, and closing when done or an error occurs.
with sv.managed_session(server.target) as sess:
# Loop until the supervisor shuts down or 1000000 steps have completed.
step = 0
while not sv.should_stop() and step < 1000000:
# Run a training step asynchronously.
# See `tf.train.SyncReplicasOptimizer` for additional details on how to
# perform *synchronous* training.
_, step = sess.run([train_op, global_step])
# Ask for all the services to stop.
sv.stop()考虑一个场景(Between-graph),我们有一个parameter server(存放着参数的副本),有好几个worker server(分别保存着相同的graph的副本).更通俗的说,我们有10台电脑,其中一台作为parameter server,其余九台作为worker server.因为同一个程序在10台电脑上同时运行(不同电脑,job_name,task_index不同),所以每个worker server上都有我们建立的graph的副本(replica).这时我们可以使用Supervisor帮助我们管理各个process.Supervisor的is_chief参数很重要,它指明用哪个task进行参数的初始化工作.sv.managed_session(server.target)创建一个被sv管理的session
if __name__ == "__main__":
tf.app.run()To start the trainer with two parameter servers and two workers, use the following command line (assuming the script is called trainer.py):
# On ps0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=0
# On ps1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=1
# On worker0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=0
# On worker1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=1可以看出,我们只需要写一个程序,在不同的主机上,传入不同的参数使其运行
参考博客:
[1] http://weibo.com/ttarticle/p/show?id=2309403987407065210809
[2] http://weibo.com/ttarticle/p/show?id=2309403988813608274928
[3] http://blog.csdn.net/luodongri/article/details/52596780
智能推荐
【深度学习】归一化_深度学习 那些情况 要做 归一化-程序员宅基地
文章浏览阅读1.8w次,点赞8次,收藏11次。 以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过 $ \sigma(WX+b) $ 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。 这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。_深度学习 那些情况 要做 归一化
微信小程序支付接口实现(java后台)_小程序后台java支付接口-程序员宅基地
文章浏览阅读1.2w次,点赞12次,收藏101次。#(Notice:以下所有经验也是我根据网上的经验整理的,如有侵权可以联系我删除,QQ 654303408。 有问题讨论也可联系我,QQ同上。)#(Tips:我是第一次开发,一个刚毕业的java工程师,我觉得我并非天赋异禀,我能学会,相信聪敏的你,一定可以)#(PS:目前微信拥有无可撼动的人口基数,越来越多的项目开发是基于微信小程序,或者APP。但是支付方式无非两种,一种是支付宝,一种是微信支..._小程序后台java支付接口
python web server_用Python建立最简单的web服务器-程序员宅基地
文章浏览阅读27次。第一个python Web程序——简单的Web服务器。与其它Web后端语言不同,Python语言需要自己编写Web服务器。如果你使用一些现有的框架的话,可以省略这一步;如果你使用Python CGI编程的话,也可以省略这一步;用Python建立最简单的web服务器利用Python自带的包可以建立简单的web服务器。在DOS里cd到准备做服务器根目录的路径下,输入命令:python -m Web服务..._pyjwt webserver
【图像重建指标 Metrics】均方误差RMSE及平均绝对误差MAE的定义和区别_rmse与mae有换算公式吗-程序员宅基地
文章浏览阅读1.3w次,点赞3次,收藏23次。RMSE和MAE能很好的反应图像的重建结果与真实结果间的差异。_rmse与mae有换算公式吗
Kotlin Gradle Junit单元测试print输出控制台_gradle 打印日志 system. out.print-程序员宅基地
文章浏览阅读3.4k次。背景默认情况下,Gradle 单元测试,是无法使用 System.out.println 这样打印变量信息的,这会让我们debug变得非常麻烦。百度网上很多方案,,但都比较麻烦,也很容易踩坑,。换了个搜索姿势,google了下,原来方案如此简单。解决在你的模块下的build.gradle.kts添加如下的配置:tasks.withType<Test> { this.testLogging { this.showStandardStreams = true _gradle 打印日志 system. out.print
Android基本组件之服务Service_安卓如果设置组服务-程序员宅基地
文章浏览阅读167次。Service的开启与关闭1.继承Service类2.在AndroidManifest.xml中注册<service android:name=".MyService" android:enabled="true" android:exported="true"></service>直接创建Service的话,前两步会自动执行3.通过Contex.startSer..._安卓如果设置组服务
随便推点
sqlmap的使用--绕过--自带脚本tamper_sqlmap绕过脚本-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏11次。sqlmap在默认的的情况下除了使用char()函数防止出现单引号,没有对注入的数据进行修改,还可以使用–tamper参数对数据做修改来绕过waf等设备。命令格式:sqlmap -u [url] --tamper [模块名]通过使用whereis sqlmap查看sqlmap安装路径,自带的脚本一般是在usr/share/sqlmap/tamper下,我的是1.6.3版本一共有66个自带脚本下边引一些常用的脚本:apostrophemask.py适用数据库:ALL作用_sqlmap绕过脚本
换行分隔符_分隔符 换行-程序员宅基地
文章浏览阅读1.7k次。windows:\r\nlinux:\rmac:\n_分隔符 换行
waves效果器_混音选择困难2,Waves均衡器全介绍与理论使用心得-程序员宅基地
文章浏览阅读4.2k次,点赞2次,收藏8次。喜欢「音乐杂谈」这个主题的朋友可以关注我的头条号,将会在不定期发表一些音乐理论以外的音乐话题的文章或者是音乐知识的干货 。(此文为混音师天职老师 发布于今日头条的原创文章,转载请告知并注明出处)通篇写作整理下来差不多花了7个小时,不管怎样,施舍点个赞吧。哈哈哈!继上一次「音乐杂谈41」混音选择困难第一期,给大家介绍了Waves全家桶的大部分压缩器之后,本篇,我们将来看看,Waves全家桶的大部分均..._waves功能详解
在Android中播放音频和视频_android 播放语言视频-程序员宅基地
文章浏览阅读2.8k次。Android媒体包提供了可管理各种媒体类型的类。这些类可提供用于执行音频和视频操作。除了基本操作之外,还可提供铃声管理、脸部识别以及音频路由控制。本文说明了音频和视频操作。本文简介媒体包提供了可管理各种媒体类型的类。这些类可提供用于执行音频和视频操作。除了基本操作之外,还可提供铃声管理、脸部识别以及音频路由控制。本文说明了音频和视频操作。范围:_android 播放语言视频
Sublime and Markdown-程序员宅基地
文章浏览阅读2.7k次。Sublime & Markdown文章目录Sublime & Markdown安装 Sublime设置 Sublime安装插件Package ControlMarkdownEditingMarkdown PreviewLiveReloadauto-saveOmniMarkupPreviewerEvernote插件&主题插入图片Ctrl+vHTML语法Markdown语法...
android uboot log,RK3288 Android 8.1系统uboot logo过渡到kernel logo会花一下-程序员宅基地
文章浏览阅读695次。在调试RK3288 Android 8.1系统遇到一个问题:开机启动uboot logo过渡到kernel log的过程中会花掉直到没有显示,再出现kernel logo。分析:打印串口log时发现,uboot阶段显示一切正常,进入kernel以后就开始花掉了然后变成没有显示了,感觉像是慢慢掉电了一样,再继续查看log发现如下打印:[ 0.363167] Registered fiq deb..._mtk 转屏后 logo uboot 转kernel 显示异常