haproxy + keepalived 使用 kubeadm 部署高可用Kubernetes 集群_keepalived haproxy 6443-程序员宅基地
技术标签: kubernetes 网络 k8s docker
本文完全参考以下 2 个博文,操作过程和中途的注解也完全抄写自博文1,版本差异之处做了一些修正,在此先感谢以下2位博主!
人家写的时候是 v1.14.1 ,我这里已经是 1.22.2 版本
我这里完全按照前一个博文一步一步的操作并记录,前面原理和拓扑图省略
官网文档
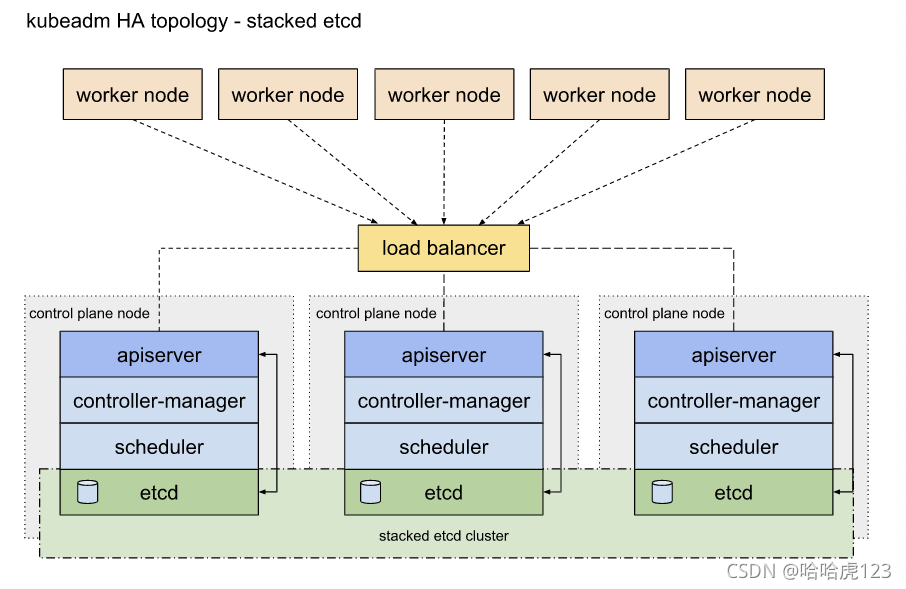
高可用拓扑选项
这里介绍了 2 种设置 HA 集群方式
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行
我这里应该是第一种方式:堆叠(Stacked) etcd 拓扑是这样的
基本配置
设置主机名,配置/etc/hosts
分别配置 5 个节点主机名,便于识别
hostnamectl set-hostname master0-140
hostnamectl set-hostname master1-141
hostnamectl set-hostname master2-142
hostnamectl set-hostname node3-143
hostnamectl set-hostname node4-144
以下操作在所有节点执行
修改/etc/hosts
cat >> /etc/hosts << EOF
192.168.0.140 master0-140
192.168.0.141 master1-141
192.168.0.142 master2-142
192.168.0.143 node3-143
192.168.0.144 node4-144
EOF
开启firewalld防火墙并允许所有流量
systemctl start firewalld && systemctl enable firewalld
firewall-cmd --set-default-zone=trusted
firewall-cmd --complete-reload
本人练习时简单粗暴的关掉了
systemctl disable firewalld && systemctl stop firewalld
关闭selinux
sed -i ‘s/^SELINUX=enforcing$/SELINUX=disabled/’ /etc/selinux/config && setenforce 0
关闭swap
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak | grep -v swap > /etc/fstab
加载IPVS模块
在所有的Kubernetes节点执行以下脚本(若内核大于4.19替换nf_conntrack_ipv4为nf_conntrack):
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
执行脚本
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
安装相关管理工具
yum install ipset ipvsadm -y
配置内核参数
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
vm.swappiness=0
EOF
sysctl --system
安装并配置docker
以下操作在所有节点执行
安装依赖软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
添加Docker repository,这里改为国内阿里云yum源
yum-config-manager
–add-repo
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装docker-ce
yum update -y && yum install -y docker-ce
创建 /etc/docker 目录
mkdir /etc/docker
配置 daemon.
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"registry-mirrors": ["https://uyah70su.mirror.aliyuncs.com"]
}
EOF
#注意,由于国内拉取镜像较慢,配置文件最后追加了阿里云镜像加速配置。
mkdir -p /etc/systemd/system/docker.service.d
重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
安装负载均衡
kubernetes master 节点运行如下组件:
kube-apiserver
kube-scheduler
kube-controller-manager
运行HA容器
使用的容器镜像为睿云智合开源项目breeze相关镜像,具体使用方法请访问:
https://github.com/wise2c-devops
其他选择:haproxy镜像也可以使用dockerhub官方镜像,但keepalived未提供官方镜像,可自行构建或使用dockerhub他人已构建好的镜像,本次部署全部使用breeze提供的镜像。
在3个master节点以容器方式部署haproxy,容器暴露6444端口,负载均衡到后端3个apiserver的6443端口,3个节点haproxy配置文件相同。
以下操作在 master0-140 节点执行。
创建haproxy启动脚本
编辑start-haproxy.sh文件,修改Kubernetes Master节点IP地址为实际Kubernetes集群所使用的值(Master Port默认为6443不用修改):
mkdir -p /data/lb
cat > /data/lb/start-haproxy.sh << "EOF"
#!/bin/bash
MasterIP1=192.168.0.140
MasterIP2=192.168.0.141
MasterIP3=192.168.0.142
MasterPort=6443
docker run -d --restart=always --name HAProxy-K8S -p 6444:6444 \
-e MasterIP1=$MasterIP1 \
-e MasterIP2=$MasterIP2 \
-e MasterIP3=$MasterIP3 \
-e MasterPort=$MasterPort \
wise2c/haproxy-k8s
EOF
创建keepalived启动脚本
编辑start-keepalived.sh文件,修改虚拟IP地址VIRTUAL_IP、虚拟网卡设备名INTERFACE、虚拟网卡的子网掩码NETMASK_BIT、路由标识符RID、虚拟路由标识符VRID的值为实际Kubernetes集群所使用的值。(CHECK_PORT的值6444一般不用修改,它是HAProxy的暴露端口,内部指向Kubernetes Master Server的6443端口)
cat > /data/lb/start-keepalived.sh << "EOF"
#!/bin/bash
VIRTUAL_IP=192.168.0.149
INTERFACE=eth0
NETMASK_BIT=24
CHECK_PORT=6444
RID=10
VRID=160
MCAST_GROUP=224.0.0.18
docker run -itd --restart=always --name=Keepalived-K8S \
--net=host --cap-add=NET_ADMIN \
-e VIRTUAL_IP=$VIRTUAL_IP \
-e INTERFACE=$INTERFACE \
-e CHECK_PORT=$CHECK_PORT \
-e RID=$RID \
-e VRID=$VRID \
-e NETMASK_BIT=$NETMASK_BIT \
-e MCAST_GROUP=$MCAST_GROUP \
wise2c/keepalived-k8s
EOF
复制启动脚本到其他2个master节点
其实我这里是直接克隆了3 个虚拟机
[root@master1-141 ~]# mkdir -p /data/lb
[root@master2-142 ~]# mkdir -p /data/lb
[root@master0-140 ~]# scp start-haproxy.sh start-keepalived.sh 192.168.0.141:/data/lb/
[root@master1-141 ~]# scp start-haproxy.sh start-keepalived.sh 192.168.0.142:/data/lb/
分别在3个master节点运行脚本启动haproxy和keepalived容器
sh /data/lb/start-haproxy.sh && sh /data/lb/start-keepalived.sh
验证HA状态
查看容器运行状态
这里是后写的文章,所以,加上 grep wise2c 过滤一下
docker ps |grep wise2c
bed21035ec30 wise2c/keepalived-k8s "/usr/bin/keepalived…" 27 hours ago Up 26 hours Keepalived-K8S
df33e240a515 wise2c/haproxy-k8s "/docker-entrypoint.…" 27 hours ago Up 26 hours 0.0.0.0:6444->6444/tcp, :::6444->6444/tcp HAProxy-K8S
查看网卡绑定的vip 为192.168.0.149
[root@master0-140 ~]# ip a | grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 192.168.0.140/24 brd 192.168.0.255 scope global noprefixroute eth0
12: veth03e184a5@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
[root@master1-141 ~]# ip a | grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 192.168.0.141/24 brd 192.168.0.255 scope global noprefixroute eth0
[root@master2-142 ~]# ip a | grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 192.168.0.142/24 brd 192.168.0.255 scope global noprefixroute eth0
inet 192.168.0.149/24 scope global secondary eth0
查看监听端口为6444
[root@master0-140 ~]# netstat -tnlp | grep 6444
tcp 0 0 0.0.0.0:6444 0.0.0.0:* LISTEN 24025/docker-proxy
tcp6 0 0 :::6444 :::* LISTEN 24031/docker-proxy
keepalived配置文件中配置了vrrp_script脚本,使用nc命令对haproxy监听的6444端口进行检测,如果检测失败即认定本机haproxy进程异常,将vip漂移到其他节点。
所以无论本机keepalived容器异常或haproxy容器异常都会导致vip漂移到其他节点,可以停掉vip所在节点任意容器进行测试。
因为我这里已经漂移到了 master2-142 ,所以,就在 master2-142 上测试
[root@master2-142 ~]# docker ps -a |grep HAProxy
178dc49114c3 wise2c/haproxy-k8s "/docker-entrypoint.…" 27 hours ago Up 27 hours 0.0.0.0:6444->6444/tcp, :::6444->6444/tcp HAProxy-K8S
[root@master2-142 ~]# docker stop HAProxy-K8S
HAProxy-K8S
3 个节点服务器上,重复以上 ip 检查,可以看到vip漂移到master1-141节点
[root@master1-141 ~]# ip a | grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 192.168.0.141/24 brd 192.168.0.255 scope global noprefixroute eth0
inet 192.168.0.149/24 scope global secondary eth0
验证完成,再恢复 master2-142 节点的 HAProxy-K8S ,以免后续节外生枝
[root@master2-142 ~]# docker start HAProxy-K8S
HAProxy-K8S
关于haproxy和keepalived配置文件可以在github源文件中参考Dockerfile,或使用docker exec -it xxx sh命令进入容器查看,容器中的具体路径:
/etc/keepalived/keepalived.conf
/usr/local/etc/haproxy/haproxy.cfg
负载均衡部分配置完成后即可开始部署kubernetes集群。
安装kubeadm
以下操作在所有节点执行
使用阿里云yum源进行替换
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装kubeadm、kubelet、kubectl
yum install -y kubeadm kubelet kubectl
systemctl enable kubelet && systemctl start kubelet
创建初始化配置文件
可以使用如下命令生成初始化配置文件
后续 yaml 文件统一放到 working 目录,便于查看管理
mkdir working && cd working
kubeadm config print init-defaults > kubeadm-config.yaml
根据实际部署环境修改信息
[root@master0-140 working]# cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.0.140
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
# wzh 20211028 name: node
name: master0-140
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
# add by wzh 20211111
controlPlaneEndpoint: "192.168.0.149:6444"
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.22.0
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
配置说明:
name: 同 /etc/hosts 中统一设置的 hostname 一致,便于查看
controlPlaneEndpoint:为vip地址和haproxy监听端口6444
imageRepository:由于国内无法访问google镜像仓库k8s.gcr.io,这里指定为阿里云镜像仓库registry.aliyuncs.com/google_containers
podSubnet:指定的IP地址段与后续部署的网络插件相匹配,这里需要部署flannel插件,所以配置为10.244.0.0/16
mode: ipvs:最后追加的配置为开启ipvs模式。
初始化master0-140节点
这里追加tee命令将初始化日志输出到kubeadm-init.log中以备用(可选)。
kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log
该命令指定了初始化时需要使用的配置文件,其中添加 --upload-certs 参数可以在后续执行加入节点时自动分发证书文件。
初始化示例
[root@master0-140 working]# cat kubeadm-init.log
[init] Using Kubernetes version: v1.22.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
...
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.0.149:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:0b905eab6e0725c7716b7192320c2da5e08bc1b53ec8f95595e863dfe2db1eb5 \
--control-plane --certificate-key 3842381e324ab05dbd777f3c18ce13ce1c3cfcf95842523fc426c61640165c01
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.149:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:0b905eab6e0725c7716b7192320c2da5e08bc1b53ec8f95595e863dfe2db1eb5
说明:
无论是初始化失败或者集群已经完全搭建成功,你都可以直接执行kubeadm reset命令清理集群或节点,然后重新执行kubeadm init或kubeadm join相关操作即可。
配置kubectl命令
无论在master节点或node节点,要能够执行kubectl命令必须进行以下配置:
root用户执行以下命令
cat << EOF >> ~/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
执行生效
source ~/.bashrc
普通用户执行以下命令(参考init时的输出结果)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown ( i d − u ) : (id -u): (id−u):(id -g) $HOME/.kube/config
等集群配置完成后,可以在所有master节点和node节点进行以上配置,以支持kubectl命令。
针对node节点,复制任意master节点/etc/kubernetes/admin.conf到本地。
查看当前状态
[root@master0-140 working]# kubectl -n kube-system get pod
...
没有初始状态下的 pod 列表了,全部是 running
如果从零开始安装的话,到这里的时候 oredns-XXX 应该是 Pending
因为还没有安装网络插件
[root@master0-140 working]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
[root@master1-141 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
[root@master2-142 working]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
我这里3 个master 节点服务器同时在操作,前面测试 HAProxy-K8S 的时候, VIP 已经漂移到了 master2-142,所以,只有 master2-142 的 scheduler 是 Healthy
安装网络插件
kubernetes支持多种网络方案,这里简单介绍常用的flannel和calico安装方法,选择其中一种方案进行部署即可。
以下操作在master0-140 节点执行即可。
安装flannel网络插件:
https://github.com/flannel-io/flannel
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,它的功能是
让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址
Flannel 使用etcd存储配置数据和子网分配信息
由于kube-flannel.yml文件指定的镜像从coreos镜像仓库拉取,可能拉取失败,可以从dockerhub搜索相关镜像进行替换,另外可以看到yml文件中定义的网段地址段为10.244.0.0/16。
10.244.0.0/16 必需和前面kubeadm-config.yaml 中一致,只要不手工去修改,缺省两者是一致的!如果前面修改,这里也必须修改
下载配置文件
curl https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml -O
我这里保持了 image: quay.io/coreos/flannel:v0.15.0 没有改变,可以 pull 成功
如果pull 失败,可以将 quay.io 替换为 quay-mirror.qiniu.com 或者其他镜像
kubectl apply -f kube-flannel.yml
再次查看node和 Pod状态,全部为Running,重点关注 flannel
[root@master0-140 working]# kubectl -n kube-system get pod |grep flannel
kube-flannel-ds-288kc 1/1 Running 0 28h
kube-flannel-ds-6spxm 1/1 Running 1 (28h ago) 28h
kube-flannel-ds-7zffk 1/1 Running 0 28h
kube-flannel-ds-hvjgf 1/1 Running 0 27h
kube-flannel-ds-k5c4s 1/1 Running 0 27h
加入master节点
从初始化输出或kubeadm-init.log中获取命令
kubeadm join 192.168.0.149:6444 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:0b905eab6e0725c7716b7192320c2da5e08bc1b53ec8f95595e863dfe2db1eb5 --control-plane --certificate-key 3842381e324ab05dbd777f3c18ce13ce1c3cfcf95842523fc426c61640165c01
注意这里的master 地址 192.168.0.149 是 VIP 地址,不是 3 个master 原始ip
VIP 是一个HAproxy虚拟的ip地址
返回的结果
...
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
注意最后的提示 ,照做!
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown ( i d − u ) : (id -u): (id−u):(id -g) $HOME/.kube/config
加入worker节点
从kubeadm-init.log中获取命令
kubeadm join 192.168.0.149:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:db4fa095ac275bd1501a646cde566aceb28c00b67790a8a4b848fda7e84b2ee
和前面 master 加入不一样!
验证集群状态
查看nodes运行情况
[root@master0-140 working]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master0-140 Ready control-plane,master 2d v1.22.2 192.168.0.140 <none> CentOS Linux 7 (Core) 3.10.0-1160.31.1.el7.x86_64 docker://20.10.9
master1-141 Ready control-plane,master 2d v1.22.2 192.168.0.141 <none> CentOS Linux 7 (Core) 3.10.0-1160.31.1.el7.x86_64 docker://20.10.9
master2-142 Ready control-plane,master 2d v1.22.2 192.168.0.142 <none> CentOS Linux 7 (Core) 3.10.0-1160.31.1.el7.x86_64 docker://20.10.9
node3-143 Ready <none> 76m v1.22.2 192.168.0.143 <none> CentOS Linux 7 (Core) 3.10.0-1160.31.1.el7.x86_64 docker://20.10.9
node4-144 Ready <none> 73m v1.22.2 192.168.0.144 <none> CentOS Linux 7 (Core) 3.10.0-1160.31.1.el7.x86_64 docker://20.10.9
查看service
[root@master0-140 working]# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 28
验证IPVS
查看kube-proxy日志,第一行输出Using ipvs Proxier.
[root@master0-140 working]# kubectl -n kube-system get pod |grep kube-proxy
kube-proxy-2xft8 1/1 Running 0 28h
kube-proxy-kvtj5 1/1 Running 0 28h
kube-proxy-pg9nw 1/1 Running 0 28h
kube-proxy-rlffv 1/1 Running 0 28h
kube-proxy-tsqjx 1/1 Running 0 28h
[root@master0-140 working]# kubectl -n kube-system logs -f kube-proxy-kvtj5
E1111 07:55:25.299013 1 node.go:161] Failed to retrieve node info: Get "https://192.168.0.149:6444/api/v1/nodes/master1-141": net/http: TLS handshake timeout
I1111 07:55:26.454329 1 node.go:172] Successfully retrieved node IP: 192.168.0.141
I1111 07:55:26.454576 1 server_others.go:140] Detected node IP 192.168.0.141
W1111 07:55:26.454676 1 server_others.go:565] Unknown proxy mode "", assuming iptables proxy
I1111 07:55:27.207393 1 server_others.go:206] kube-proxy running in dual-stack mode, IPv4-primary
I1111 07:55:27.207458 1 server_others.go:212] Using iptables Proxier.
I1111 07:55:27.207486 1 server_others.go:219] creating dualStackProxier for iptables.
W1111 07:55:27.207532 1 server_others.go:495] detect-local-mode set to ClusterCIDR, but no IPv6 cluster CIDR defined, , defaulting to no-op detect-local for IPv6
I1111 07:55:27.209522 1 server.go:649] Version: v1.22.0
...
I1111 07:55:27.370807 1 shared_informer.go:247] Caches are synced for endpoint slice config
I1111 07:55:27.370912 1 shared_informer.go:247] Caches are synced for service config
查看代理规则
[root@master0-140 working]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
etcd集群
执行以下命令查看etcd集群状态
因为漂移到了 master1-141 ,所以只有他是 healthy
[root@master0-140 working]# kubectl -n kube-system exec etcd-master1-141 -- etcdctl \
> --endpoints=https://192.168.0.141:2379 \
> --cacert=/etc/kubernetes/pki/etcd/ca.crt \
> --cert=/etc/kubernetes/pki/etcd/server.crt \
> --key=/etc/kubernetes/pki/etcd/server.key endpoint health
返回结果
https://192.168.0.141:2379 is healthy: successfully committed proposal: took = 24.844032ms
etcdctl v3 命令有改变,请查看使用 etcdctl说明
https://www.bookstack.cn/read/docker_practice-v1.1.0/etcd-etcdctl.md
最简单的 version 命令一定是没有改变的!
kubectl -n kube-system exec etcd-master1-141 -- etcdctl \
--endpoints=https://192.168.0.141:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key version
验证HA
随机关机一个 master 节点,再查看 ip a | grep eth0
VIP会自动漂移!
和前面测试使用 docker stop 其实是一样的
智能推荐
Linux 下清空Oracle监听日志_linux清理oracle监听日志-程序员宅基地
文章浏览阅读3.5k次。Linux 下清空Oracle监听日志_linux清理oracle监听日志
R语言RCurl爬虫(多线程爬虫)-高评分豆瓣图书_rcurl 批量获取url-程序员宅基地
文章浏览阅读2.6k次,点赞4次,收藏22次。R语言爬虫-高评分图书(豆瓣)# R语言爬虫-高评分图书(豆瓣)本篇文章依然延续之前的爬虫类型文章,多次实操有助于对于代码的理解和技术的提升。此次爬取的是豆瓣上高评分的图书,每一次爬取都会给大家提供一份有价值、有意义的东西,每一次都有所提升,我是ERIC,希望喜欢这方面技术的或者对于发表的内容感兴趣都可以相互交流,共同提升。 (此篇爬虫数据采集后只进行了简单的可视化分析,未进..._rcurl 批量获取url
去掉txt文件内的换行符-程序员宅基地
文章浏览阅读5.8k次。在txt文件内,直接用^p来搜索换行符并不行,所以有时候面对很多行数字(如手机号)的时候,如果想去掉换行符,我就粘贴到word里,再替换。但是这样效率很慢,粘一万条手机号都要等很久,后来通过搜索找到一个好办法,把txt文件另存为html文件,里边的换行符就会删除掉,变成了空格,这时候我们只要把html文件里内容重新粘回txt文档,把空格替换掉就可以了,速度很快。转载于:https..._txt里有怎么消除
SpotMicro 12自由度四足机器人制作(两套方案)-程序员宅基地
文章浏览阅读4k次,点赞8次,收藏56次。提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、方案确立二、使用步骤1.引入库2.读入数据总结前言老板想做个大号的四足,让我先做个小的练练手,两套方案均基于树莓派。一、方案确立大致情况如下方链接所示。前面的动态图是基于ROS-kinectic系统,后面的图是树莓派原生系统。二、使用步骤1.引入库代码如下(示例):import numpy as npimport pandas as pdimport matplotlib.pyplot as plti_spotmicro
【愚公系列】2023年07月 Python自动化办公之win32com操作excel-程序员宅基地
文章浏览阅读6k次。python中能操作Excel的库主要有以下9种:本文主要针对win32com读取 写入 修改 操作Excel进行详细介绍win32com是Python的一个模块,它提供了访问Windows平台上的COM组件和Microsoft Office应用程序的能力。通过该模块,Python程序可以与Windows平台上的其他应用程序交互,例如实现自动化任务、自动化报告生成等功能。_win32com
sql审核工具 oracle,Oracle SQL Developer工具-程序员宅基地
文章浏览阅读326次。Oracle SQL Developer工具下载解压了Oracle SQL Developer工具,运行时,启动不了,报错信息如下:---------------------------Unable to create an instance of the Java Virtual MachineLocated at path:\jdk\jre\bin\client\jvm.dll--------..._开源oracle sql审核工具
随便推点
Hack the BTRSys1(Boot2Root Challenge)【VulnHub靶场】渗透测试实战系列1_welcome to the boot2root ctf, morpheus:1. you play-程序员宅基地
文章浏览阅读1.2k次。靶场下载地址:BTRSys: v1下载完毕之后直接导入到VMWare,看下设置了DHCP,那就在内网网段~~接着就打开内网的另外一台攻击机器Kali,首先搜集一下信息,Zenmap开始扫描,其实也就是nmap包装了一个UI界面。Okay,扫描结果出来了,看下图:主要提供了下面三个服务端口:vsftd,这个应该版本有点老,可以exploit一下,小本本记下来 ss..._welcome to the boot2root ctf, morpheus:1. you play trinity, trying to invest
antd date-picker 默认时间设置问题_a-date-picker 默认值-程序员宅基地
文章浏览阅读1.3w次,点赞7次,收藏8次。一.官网给出的例子<template> <div> <a-date-picker :default-value="moment('2015/01/01', dateFormat)" :format="dateFormat"/> <br /> <a-date-picker :default-value="moment('01/01/2015', dateFormatList[0])" :format="dateFormatList"/_a-date-picker 默认值
python已知两边求第三边_已知两边求第三边公式-程序员宅基地
文章浏览阅读2.4k次。各位家长好,我是家长无忧(jiazhang51.cn)专栏作者,七玥老师全文共计549字,建议阅读2分钟如果是三角形是直角三角形,了解两侧,可以用勾股定理求出第三边。如果是三角形是一般三角形(钝角、钝角三角形),那这一标准下只有求出第三边的范畴:两边之和超过第三边,两侧之差低于第三边。求边公式计算只了解两侧相同假如一个是底部一个是腰得话,这个是正三角形,第三边就等于腰。假如只了解等腰三角形腰长,那..._输入两边长度自动得出第三边长度 并排序
达梦数据库--学习总结-程序员宅基地
文章浏览阅读697次。达梦概述:1. 达梦:达梦数据库管理系统是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,简称DM。2. 2019年新一代达梦数据库管理系DM8发布。(二)特点:1. 通用性:达梦数据库管理系统兼容多种硬件体系,可运行于X86、X64、SPARC、POWER等硬件体系之上。2. 高性能:支持列存储、数据压缩、物化视图等面向联机事务分析场景的优化选项。3. 高可用:可配置数据守护系统(主备),自动快速故障恢复,具有强大的容灾处理能力。_达梦数据库
神经网络(优化算法)_nnet-程序员宅基地
文章浏览阅读1.2w次。神经网络(优化算法)人工神经网络(ANN),简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。人工神经网络从以下四个方面去模拟人的智能行为:_nnet
<video>标签及属性说明_video标签-程序员宅基地
文章浏览阅读5.5w次,点赞56次,收藏300次。实例HTML <video> 标签一段简单的 HTML5 视频:<video src="video.mp4" controls="controls">您的浏览器不支持 video 标签。</video>属性性 值 描述 autoplay autoplay 如果出现该属性,则视频在就绪后马上播放。 controls controls 如果出现该属性,则向用户显示控件,比如播放按钮。 height_video标签