pandas DataFrame 用法--查看和选择数据_pandas中对dataframe的数据如何进行查询-程序员宅基地
技术标签: python 后端 # Python 数据分析 开发语言
目录
1. 使用 .head() 查看 DataFrame 头部数据
2. 使用 .tail() 查看 DataFrame 尾部数据
3. 使用 .describe() 查看 DataFrame 统计数据
在使用各种api之前,先创建测试使用数据:
代码:
import numpy as np
import pandas as pd
dict_data={"a":list("abcdef"),"b":list("defghi"),"c":list("ghijkl")}
df=pd.DataFrame.from_dict(dict_data)
df运行结果:
Out[1]:
| a | b | c | |
|---|---|---|---|
| 0 | a | d | g |
| 1 | b | e | h |
| 2 | c | f | i |
| 3 | d | g | j |
| 4 | e | h | k |
| 5 | f | i | l |
1. 使用 .head() 查看 DataFrame 头部数据
.head([n]) 用法如下,如果 n 为空,则默认为 5
In [12]: df.head(0)
Out[12]:
In [13]: df.head(1)
Out[13]:
a b c 0 a d g In [16]: df.head(3)
Out[16]:
a b c 0 a d g 1 b e h 2 c f i
2. 使用 .tail() 查看 DataFrame 尾部数据
.tail([n]),如果 n 为空,则默认为 5
In [18]: df.tail(0)
Out[18]:
In [19]: df.tail(1)
Out[19]:
a b c 5 f i l In [20]: df.tail(3)
Out[20]:
a b c 3 d g j 4 e h k 5 f i l
3. 使用 .describe() 查看 DataFrame 统计数据
.describe 语法如下
Help on function describe in module pandas.core.generic:
describe(self: 'FrameOrSeries', percentiles=None, include=None, exclude=None, datetime_is_numeric=False) -> 'FrameOrSeries'
Generate descriptive statistics.
Descriptive statistics include those that summarize the central
tendency, dispersion and shape of a
dataset's distribution, excluding ``NaN`` values.
Analyzes both numeric and object series, as well
as ``DataFrame`` column sets of mixed data types. The output
will vary depending on what is provided. Refer to the notes
below for more detail.
Parameters
----------
percentiles : list-like of numbers, optional
The percentiles to include in the output. All should
fall between 0 and 1. The default is
``[.25, .5, .75]``, which returns the 25th, 50th, and
75th percentiles.
include : 'all', list-like of dtypes or None (default), optional
A white list of data types to include in the result. Ignored
for ``Series``. Here are the options:
- 'all' : All columns of the input will be included in the output.
- A list-like of dtypes : Limits the results to the
provided data types.
To limit the result to numeric types submit
``numpy.number``. To limit it instead to object columns submit
the ``numpy.object`` data type. Strings
can also be used in the style of
``select_dtypes`` (e.g. ``df.describe(include=['O'])``). To
select pandas categorical columns, use ``'category'``
- None (default) : The result will include all numeric columns.
exclude : list-like of dtypes or None (default), optional,
A black list of data types to omit from the result. Ignored
for ``Series``. Here are the options:
- A list-like of dtypes : Excludes the provided data types
from the result. To exclude numeric types submit
``numpy.number``. To exclude object columns submit the data
type ``numpy.object``. Strings can also be used in the style of
``select_dtypes`` (e.g. ``df.describe(include=['O'])``). To
exclude pandas categorical columns, use ``'category'``
- None (default) : The result will exclude nothing.
datetime_is_numeric : bool, default False
Whether to treat datetime dtypes as numeric. This affects statistics
calculated for the column. For DataFrame input, this also
controls whether datetime columns are included by default.
.describe() 默认是对数值类进行统计
In [21]: df.describe()
Out[21]:
a b c count 6 6 6 unique 6 6 6 top a e j freq 1 1 1
也可以通过 include=object 来获得对其他的统计
例如当前数据

获得两种不同的结果

4. 使用 .T 查看 DataFrame 转置数据
In [24]: df.TOut[24]:
0 1 2 3 4 5 a a b c d e f b d e f g h i c g h i j k l
5. at 函数:通过行名和列名来取值
先创建数据吧
import pandas as pd
import pdb
#pdb.set_trace()
dict_data={"X":list("abcdef"),"Y":list("defghi"),"Z":list("ghijkl")}
df=pd.DataFrame.from_dict(dict_data)
df.index=["A","B","C","D","E","F"]
df生成如下 DataFrame
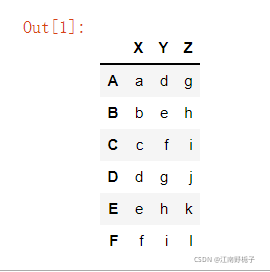
用法太简单了,直接把 at 和 iat 都运行上。
# A 行 X 列数据,必须两个数据都输入,否则报错
print(df.at["A","X"])
# 第二 行 第二 列数据,序号从0开始
print(df.iat[2,2]) 运行结果
a i
6.iat 函数:通过行号和列号来取值
请参考7,请注意 at 是按照行名和列名来定位某个元素,而 iat 是按照行号和列号来定位某个元素。
7. loc函数主要通过 行标签 索引行数据
当前 df 如下
loc 非常简单,直接看完代码就明白了
# 指定行名和列名的方式,和at的用法相同
print(df.loc["A","X"],"\n","*"*20)
# 可以完整切片,这是 at 做不到的
print(df.loc[:,"X"],"\n","*"*20)
# 可以从某一行开始切片
print(df.loc["B":,"X"],"\n","*"*20)
# 可以只切某一列
print(df.loc["B",:],"\n","*"*20)
# 和指定上一条代码效果是一样的
print(df.loc["B"],"\n","*"*20)运行结果
a ******************** A a B b C c D d E e F f Name: X, dtype: object ******************** B b C c D d E e F f Name: X, dtype: object ******************** X b Y e Z h Name: B, dtype: object ******************** X b Y e Z h Name: B, dtype: object ********************
8. iloc函数主要通过行号、索引行数据
当前 df 如下
和 iloc 用法非常类似,直接看代码吧,不再多说
# 指定行号和列号的方式,和 loc 的用法相同
print(df.iloc[0,0],"\n","*"*20)
# 可以完整切片
print(df.iloc[:,0],"\n","*"*20)
# 可以从某一行开始切片
print(df.iloc[1:,0],"\n","*"*20)
# 可以只切某一列
print(df.iloc[1,:],"\n","*"*20)
# 和指定上一条代码效果是一样的
print(df.iloc[1],"\n","*"*20)运行结果
a ******************** A a B b C c D d E e F f Name: X, dtype: object ******************** B b C c D d E e F f Name: X, dtype: object ******************** X b Y e Z h Name: B, dtype: object ******************** X b Y e Z h Name: B, dtype: object ********************
9.ix——通过行标签或者行号索引行数据
ix 是基于loc和iloc 的混合,但是现在已经被弃用了。说实话我很喜欢这种弃用,确实它能做的事情,用上面的 loc 和 iloc 也能做到,就不再赘述。
10. 使用布尔索引查看符合要求的数据
当前 df 如下
使用 df[] 切片取出符合筛选条件的数据,& 是条件与,| 是条件或。
# 取一行数据,这行数据符合两个条件。
# 1)Y 列 字符的 ASCI 码大于字符 g,
# 2)Z 列 字符的 ASCI 码小于字符 x,
print(df[(df["Y"].str.lower()>"g")&(df["Z"].str.lower()<"x")],"\n","*"*20)
# 取出任意一个数据有"a"的一行
print(df[(df["X"].str.lower()=='a')|(df["Y"].str.lower()=='a')|(df["Z"].str.lower()=='a')])运行结果还是挺理想的
X Y Z E e h k F f i l ******************** X Y Z A a d g
11. 使用 sample() 查看随机数据
语法:DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
参数说明:
n:这是一个可选参数, 由整数值组成, 并定义生成的随机行数。
frac:它也是一个可选参数, 由浮点值组成, 并返回浮点值*数据帧值的长度。不能与参数n一起使用。
replace:由布尔值组成,默认值是false。如果为true, 则返回带有替换的样本。
权重:它也是一个可选参数, 由类似于str或ndarray的参数组成。默认值”无”将导致相等的概率加权。
random_state:它也是一个可选参数, 由整数或numpy.random.RandomState组成。如果值为int, 则为随机数生成器或numpy RandomState对象设置种子。
axis:它也是由整数或字符串值组成的可选参数。 0或”行”和1或”列”。
这里只介绍最简单的用法。
print("*"*20)
print(df.sample())
print("*"*20)
print(df.sample())
print("*"*20)
print(df.sample())
print("*"*20)
print(df.sample())运行结果每次都不一样
******************** X Y Z A a d g ******************** X Y Z F f i l ******************** X Y Z A a d g ******************** X Y Z B b e h
12. 使用 isin() 查看数据是否符合条件
语法:dataframe.isin(values),values 可以是dataframe,也可以是一列数据。
#可以整个 dataframe 进行比较
df2=df.copy()
print(id(df)) # 此处用 id ,是为了注明两个dataframe 内存已经不一样了
print(id(df2))
df["G"]=list("MKLHGF")
df2.isin(df)运行结果
X Y Z A True True True B True True True C True True True D True True True E True True True F True True True
取一列进行比较
#取G列 进行值比较
df.G.isin(list("MKLHGF"))运行结果
A True B True C True D True E True F True Name: G, dtype: bool
13. 使用 .shape 查看查看行数和列数
太简单了
In [23]: df.shapeOut[23]:
(6, 3)
14. 使用 .info() 查看索引、数据类型和内存信息
In [21]: df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 6 entries, 0 to 5 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 a 6 non-null object 1 b 6 non-null object 2 c 6 non-null object dtypes: object(3) memory usage: 272.0+ bytes
'''
要是大家觉得写得还行,麻烦点个赞或者收藏吧,想给博客涨涨人气,非常感谢!
'''
智能推荐
【jQuery 冻结任意行列】冻结任意行和列的jQuery插件-程序员宅基地
文章浏览阅读417次。 实现原理:创建多个div,div之间通过css实现层叠,每个div放置当前表格的克隆。例如:需要行冻结时,创建存放冻结行表格的div,通过设置z-index属性和position属性,让冻结行表格在数据表格的上层。同理,需要列冻结时,创建存放冻结列表格的div,并放置在数据表格的上层。如果需要行列都冻结时,则除了创建冻结行、冻结列表格的div,还需要创建左上角的固定行列表格的d..._列冻结列解冻jquery
第二周项目4求一个正整数的各位数字之和_输入一个整数求各位数字之和时间复杂度-程序员宅基地
文章浏览阅读1.2k次。问题及描述:/* *Copyright(c++)2015,烟台大学计算机学院 *All rights reserved, *文件名称:test.cpp *作 者:程梦莹 *完成日期:2015年9月12日 *版本号:v1.0 *问题描述:计算任一输入的正整数的各位数字之和,并分析算法的时间复杂度 *输入描述:一个整数 */#include_输入一个整数求各位数字之和时间复杂度
微型计算机原理与接口实验报告,微型计算机原理及接口技术实验报告.docx-程序员宅基地
文章浏览阅读3.6k次。成都理工大学微型计算机原理及接口技术实验报告学 院 : 核技术与自动化工程学院专 业 : 电气工程及其自动化班 级 :学 号 :姓 名 :指导老师 :完成时间 :实验一 EMU 8086软件的使用1、实验目的通过对emu8086的使用,来理解《微型计算机原理及接口技术》课本上的理论知识,加深对知识的运用,以及emu8086交互式学习汇编语言(Assembly ..._微机原理与接口技术emu8086课题总结
如何在Vue中使用百度地图API来创建地图应用程序。_百度地图js api3.0怎么转换成vue-程序员宅基地
文章浏览阅读450次,点赞3次,收藏3次。Vue是一款流行的JavaScript框架,它提供了一种简单而灵活的方式来构建交互式的Web前端应用程序。在许多Web应用程序中,地图显示和地理位置信息都是必不可少的功能。而百度地图是一款流行的地图服务提供商,提供了一系列API来帮助开发者创建交互式的地图应用程序。本篇教程将介绍如何在Vue应用程序中使用百度地图API来创建地图应用程序。通过本篇教程,您将学习到如下内容:如何获得百度地图AK密钥如何在Vue中引入百度地图API如何在Vue中使用百度地图API来创建地图应用程序。_百度地图js api3.0怎么转换成vue
计算机毕业设计(77)php小程序毕设作品之维修保养汽车小程序系统_汽车保养php后台项目-程序员宅基地
文章浏览阅读326次。本课题主要目标是设计并能够实现一个基于微信汽车维修保养小程序系统,前台用户使用小程序,小程序使用微信开发者工具开发;后台管理使用基PP+MySql的B/S架构,开发工具使用phpstorm;:基于微信汽车维修保养小程序系统是计算机技术与汽修店维修保养管理相结合的产物,通过微信小程序维修和保养系统实现了对汽修店维修保养的高效管理。随着计算机技术的不断提高,计算机已经深入到社会生活的各个角落;而采用人工维修保养预约的方法,不仅效率低,易出错,手续繁琐,而且耗费大量人力。_汽车保养php后台项目
FPGA采集AD7606全网最细讲解 提供串行和并行2套工程源码和技术支持-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏270次。AD7606是一款非常受欢迎的AD芯片,因为他支持8通道同时采集数据,采样深度16位,已经很不错了,虽然采样率只有200 kSPS,但对电压等低速数据源的采集而言已经完全足够了,该芯片在电压检测等项目中有着广泛应用。本文详细描述了设计方案,工程代码编译通过后上板调试验证,可直接项目移植,适用于在校学生、研究生项目开发,也适用于在职工程师做项目开发,可应用于AD数据采集领域_ad7606
随便推点
使用pako.js压缩、解压数据-程序员宅基地
文章浏览阅读4.7k次。pako.js压缩和解压请求参数和响应数据_pako.js
markdown模板(个人使用)_markdown 模板-程序员宅基地
文章浏览阅读4.8k次,点赞6次,收藏25次。自用CSDN的markdown模板_markdown 模板
Playing with a Freight robot: Part 1-程序员宅基地
文章浏览阅读78次。1. Freight robotThe Fetch and Freight Research Edition Robots are indoor laboratory robots.Coordinate SystemThe coordinate frames for all links in the Fetch and Freight are defined with pos...
linux编程常用指令_linux实现代码的指令-程序员宅基地
文章浏览阅读154次。一、网络函数(1)htons(2)inet_addr 点格式转换为无符号长整型 ina.sin_addr.s_addr = inet_addr("132.241.5.10");(3)inet_ntoa 无符号长整型转换为点格式 struct in_addr addr1; ulong l1; l1= inet_addr("192.168.0.74"..._linux实现代码的指令
memmove函数_void *memmove(void *dest, const void *src, size_t -程序员宅基地
文章浏览阅读1.1k次。在这个例子中,字符串"hello world!"被移动,使得输出为 “hello hello world!是一个标准库函数,用于 C++ 中的内存操作。它主要用于在内存中移动或复制字节。可以处理源内存区和目标内存区重叠的情况。如果源内存区和目标内存区重叠,此函数会返回指向目标内存区的指针。仍然可以正确地复制字节,而。_void *memmove(void *dest, const void *src, size_t n);
2013最新版Subversion 1.7.10 for Windows x86 + Apache 2.4.4 x64 安装配置教程+错误解决方案...-程序员宅基地
文章浏览阅读140次。一 、工作环境 操作系统:Windows Server 2008 R2 SP1 x64 Apache版本:2.4.4 Subversion版本: Setup-Subversion-1.7.10.msi TortoiseSVN版本:TortoiseSVN-1.7.13.24257-x64-svn-1.7.10.msi +LanguagePack_1.7.13.24257..._windows subversion x64