网络抓包工具_wireshark发包-程序员宅基地
Wireshark
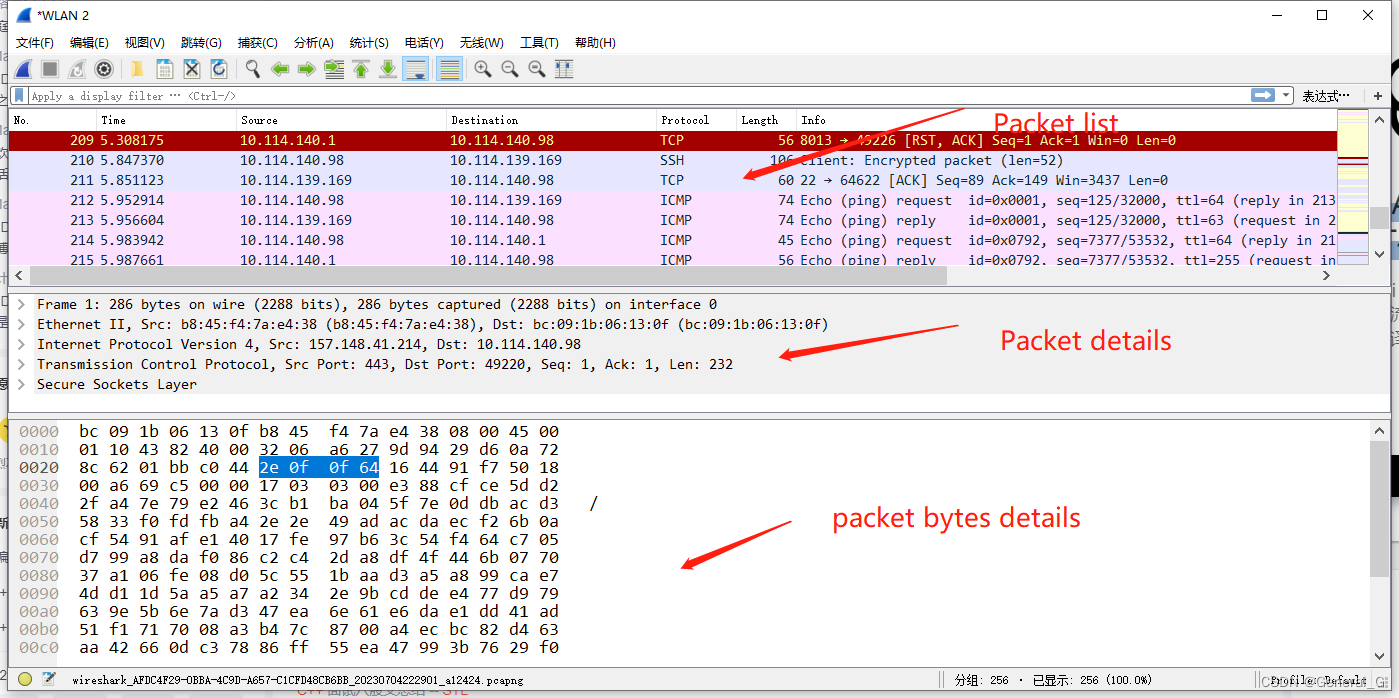
界面功能介绍
-
Wireshark菜单功能
- 编辑:
- 首选项(Preferences)
- 分析:
- 专家信息,在分析网络性能等方便经常用到,可以看到SYN总量的统计
- error::可以看到重传包等
- warning:
- note:
- chat:
- 专家信息,在分析网络性能等方便经常用到,可以看到SYN总量的统计
- 统计:
- 会话(conversation):可以看到一共建立了多少条连接,端口号等信息
- 编辑:
-
Wireshark Packet List面板,按网络模型排列
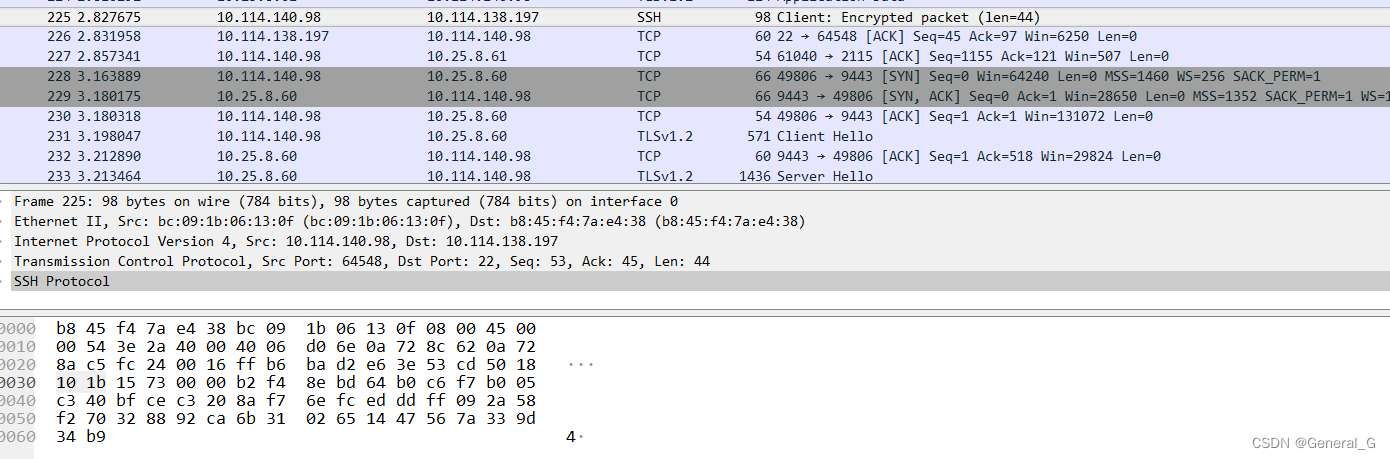
- Frame x:物理层的数据帧概况
- Ethernet:数据链路层以太网帧头部信息:
- Destination:目标mac地址
- Source:源mac地址
- Internet Protocol Version 4(网络层):
- Total Length:IP包的总长度,包括应用层数据长度和tcp头,ip头
- Flags:
- Time to live(TTL):初始值一般是64,每经过一个路由器就减1
- Protocol:上层协议
- Header checksum:头部数据的校验和:不知道干啥的
- Source:源IP地址
- Destination:目标IP地址
- Transmission Control Protocol(传输层),按TCP头顺序:
- Source Port/Destination:源/目标端口号
- [Stream index: 1]:
- [TCP Segment Len:1388]:
- Sequence number:序列号,【Next Sequence number:下一个要发送的序列号】
- Acknowledgement number:确认序列号
- Header Length:头部长度
- Flags:
- Window size value:这个值是滑动窗口的大小,这个值*window scale等于win值
- Calculated window size:这个值是真是的窗口大小
- Window size scaling factor:这个值应该是系数
- 三者之间的关系是:Calculated window size = Window size value * Window size scaling factor
- Checksum:TCP数据段的校验和
- Options:
- Window scale:三次握手时会把这个值告知对方,对方收到后把这个值当作2的指数,算出来的值作为接收窗口的系数(接受窗口*该系数就是真正的接收窗口值)
- SEQ/ACK analysis:
- iRTT:RTT时间,往返时间
- Bytes in flight:拥塞窗口大小
- Timestamps:
- Data(有可能是应用层,如NFS协议等)
- 其他操作:
- 添加列:需要添加的地方右键应用为列
-
Packet Bytes面板:以十六进制和ASCII格式显示数据包的信息状态栏:
- 专家信息
- 注释
- 包数
- Profile
-
Wireshark中的关键字
- Seq和Ack是随机生成的,wireshark将Seq和Ack的初始值都设为0,即用“相对值”代替“真实值”方便查看。使用Edit——Preferences——Protocols——TCP选项中的Relative Sequence Numbers来选择启用
- 在TCP中,同一台主机发出的包应该是连续的,即后一个包的seq等于前一个包的Seq+Len
- Ack可以理解为应答。A发给B的Ack是告诉B,我已收到你发的数据包,收到Ack号这里了,你下次要发Seq为Ack号的给我——B的Ack为A的Seq+Len
- Len:数据段的长度,不包含TCP头
-
WireShark中的标记
- TCP Out-of-Order:TCP传输过程中同一台主机发出的包是连续的,即后一个包的Seq等于前一个包的Seq+Len。当Wireshark发现后一个包的Seq小于前一个包的Seq+Len时就认为是乱序了,会提示TCP Out-of-Order。小跨度的乱序影响不大,但跨度大的乱序可能触发快速重传
- TCP Dup ACK:当乱序或丢包时,接收方会收到一些Seq号比期望值大的包,每次收到这个包就会Ack一次期望的Seq,以此提醒发送方,于是就产生了一些重复的Ack,Wireshark就会在这些重复的Ack上标记TCP Dup ACK
- TCP Fast Retransmission:当发送方收到三个或以上的TCP Dup ACK,就意识到之前发送的包可能丢了,于是快速重传(RFC规定)
- TCP Retransmission:如果一个包真丢了,又没有后续包可以在接收方触发Dup ACK,就不会快速重传,之中情况下只能等待超时重传,这类包被标记为TCP Retransmission
- TCP zerowindow:当Win等于0时就会被标记
- TCP window Full
- TCP segment of a reassembled PDU——不知道是干啥的
- Continuation to #
- Time-to-live exceeded
- TCP Previous segment not captured
-
Wireshark搜索/过滤
- 常用的关键字,“eq” 和 “==”等同,“and” 表示并且,“or”表示或者。“!" 和 "not” 都表示取反。
- 搜索字符串xxx:tcp contains “xxx”
- 按协议过滤,如:tcp,http等,直接输入,或tcp||http
- 按ip过滤:
- 按源IP过滤:ip.src==172.0.0.1 或ip.src eq 172.0.0.1
- 按目的IP过滤:ip.dst==172.0.0.1或ip.dst eq 172.0.0.1
- 直接按ip过滤:ip.addr == 172.0.0.1或ip.addr eq 172.0.0.1筛选出所有和这个ip相关的包
- 根据端口过滤
- tcp.port==965
- 只显示目标端口:tcp.dstport==5150
- 只显示来源端口:tcp.srcport == 80
- 过滤端口范围:tcp.port >= 1 and tcp.port <= 80
- 根据数据报中携带的信息搜索:
- 按报长过滤:tcp.len==12
- 按序号搜索:tcp.seq == 11230
- 根据流搜索:
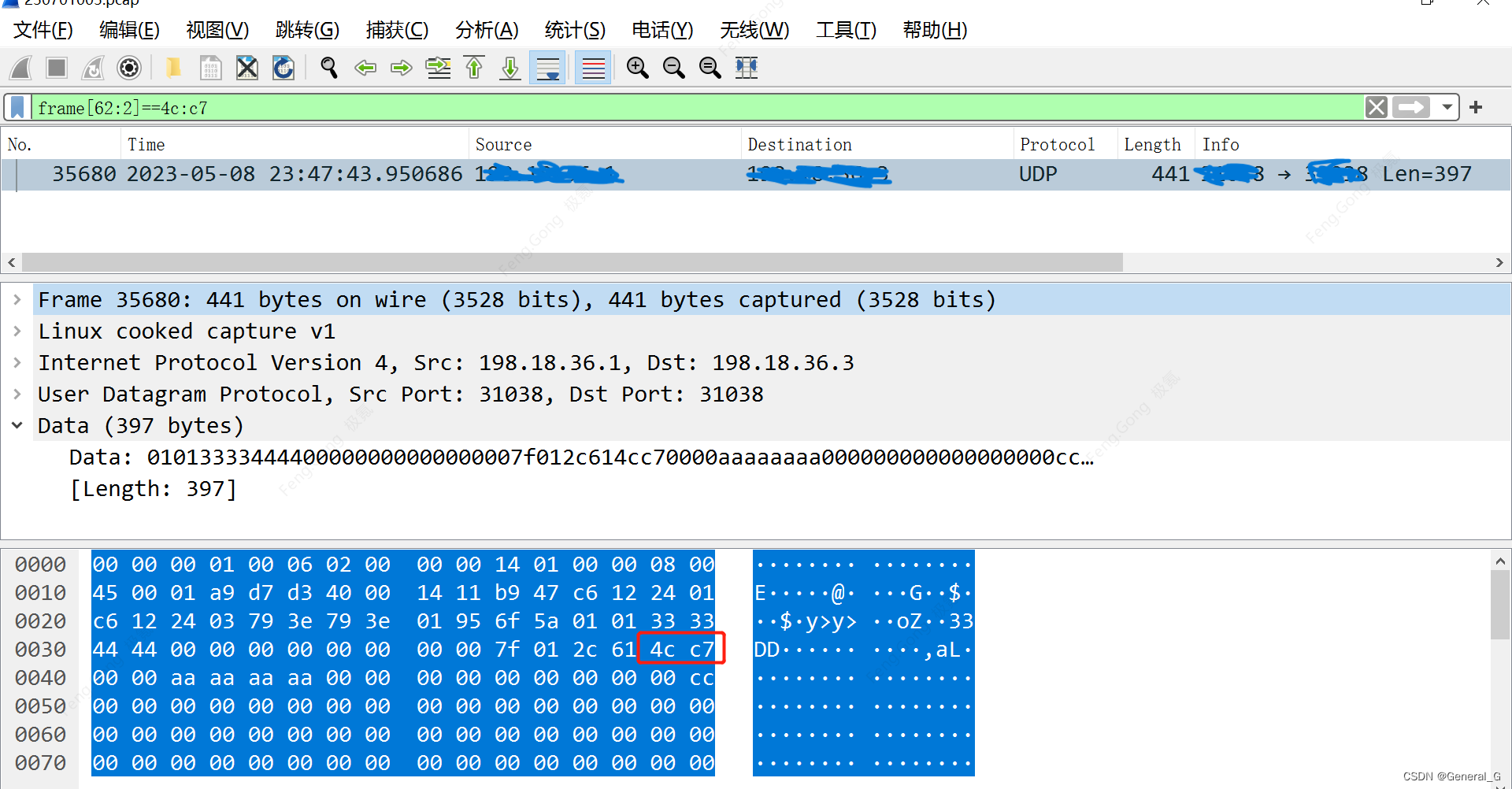
- 按字节过滤:二进制报文无法通过contains过滤,可以通过指定字节过滤,命令为
frame[m:n]==a:b:c。其中m为要过滤的前面的字节数,比如要过滤第14个字节,m就为13;n为要查找的字节数,a,b分别为要查找的值。举例如下,我要查找从第63个字节开始的2个字节分别为4c和c7的UDP报文,使用frame[62:2]==4c:c7过滤,同样,如果有Data数据,可以使用data[x:y]==a:b的形式过滤。
-
Wireshark的其他使用技巧:
- 在Packet Details面板中右键单击任何协议可以启动查看相关的wiki信息
ping的用法:问题汇总: - 计算在途数据报:发送方最后一个报的 seq+len 减去最后收到的ack
- 只要很少的丢包重传就足以对性能造成巨大影响
- 发送窗口和MSS有什么区别:发送窗口决定了一口气能发出去多少字节,MSS决定这些字节要分多少个包发完
- 在Packet Details面板中右键单击任何协议可以启动查看相关的wiki信息
-
问题汇总:
- 为何链路层名称为linux cooked capture?而不是Ethernet Ⅱ
因为包是在linux中使用tcpdump,且指定参数-i any来捕获设备上所有网卡上的包。它会把所有包的以太网头都换成linux cooked capture,wireshark对此解释为虚假的协议。
tcpdump抓包时,如果-i选项指定为一个网卡地址,那么抓取的数据包数据链路层是以太网头部;如果指定any,则以太网头部将被替换为linux cooked capture头部
- 为何链路层名称为linux cooked capture?而不是Ethernet Ⅱ
tcpdump
tcpdump --help
tcpdump version 4.99.1
libpcap version 1.10.1 (with TPACKET_V3)
OpenSSL 3.0.2 15 Mar 2022
Usage: tcpdump [-AbdDefhHIJKlLnNOpqStuUvxX#] [ -B size ] [ -c count ] [--count]
[ -C file_size ] [ -E algo:secret ] [ -F file ] [ -G seconds ]
[ -i interface ] [ --immediate-mode ] [ -j tstamptype ]
[ -M secret ] [ --number ] [ --print ] [ -Q in|out|inout ]
[ -r file ] [ -s snaplen ] [ -T type ] [ --version ]
[ -V file ] [ -w file ] [ -W filecount ] [ -y datalinktype ]
[ --time-stamp-precision precision ] [ --micro ] [ --nano ]
[ -z postrotate-command ] [ -Z user ] [ expression ]
参数:
- -i:指定网卡
- 所有网卡:any;
- 环回包:lo
- host:指定这台主机接收和发送的数据
- -s:指定抓到的每个包的前多少个字节,比如我只想抓每一个frame的前80个字节,就用-s 80,0表示抓取全部
- -w:保存到指定的文件中
- host xxx:指定抓取地址包含xxx的包
- src host xxx:指定抓取源地址为xxx的包
- dst host xxx:指定抓取目标地址为xxx的包
- 读取已保存的抓包文件:
- -r,会打印ip,port,传输层协议和length,如:
tcpdump -r mypcap.pcap,如果要打印详细信息需要加-X,如tcpdump -r 230710002.pcap -X
- -r,会打印ip,port,传输层协议和length,如:
https://www.cnblogs.com/f-ck-need-u/p/7064286.htmlhttps://www.cnblogs.com/lvdongjie/p/10911564.html7.TCP参数过滤tcp.flags 显示包含TCP标志的封包。tcp.flags.syn == 0x02 显示包含TCP SYN标志的封包。tcp.window_size == 0 && tcp.flags.reset != 1去掉重传的包:!(tcp.analysis.retransmission),重传:tcp.analysis.retransmission8.包内容过滤-----------------------------------------------tcp[20]表示从20开始,取1个字符tcp[20:]表示从20开始,取1个字符以上注: 些两虚线中的内容在我的wireshark(linux)上测试未通过。关键字过滤/查找:
* frame.number>21 && frame.number<25:过滤序号在(21, 25)内的报文
1、Wireshark的数据包详情窗口,如果是用中括号[]括起来的,表示注释,在数据包中不占字节2、在二进制窗口中,如“DD 3D”,表示两个字节,一个字节8位3、TCP数据包中,seq表示这个包的序号,注意,这个序号不是按1递增的,而是按tcp包内数据字节长度加上,如包内数据是21字节,而当前IP1发到IP2的包的seq是10的话,那下个IP1发到IP2的包的seq就是10+21=31——同一个方向看seq,这一个seq=上一个seq+len7、8、在网络不堵即滑动窗口一点都不堵的情况下,第一个包的ack号就是第二个包的seq号,如果堵了,由于是滑动窗口缓存处理队列,所以这个值会错开9、如果A发到B连续几个包,seq号不变,ack号一直在变大,说明A一直在收B的数据,一直在给B应答10、如果A发到B连续几个包,seq号一直变大,ack号一直没变,说明A一直在向B发数据,不用给B应答,而是在等B的应答11、可以接收多个数据包后,一次性给一个应答,不用每个数据包一一对应给应答12、发了一个包,很久没有收到应答后,会重发包,在Wireshark抓包工具提示“[TCP Retransmission]”,在数据包详情窗口点开可以看到是对哪个数据包的重传14、如果出现这个错误“[]”,说明乱序了,前一个包没有收到,收到后面的包了,这时也会重传包tcp segment of a seassembled PDU: 说明发送端发送的TCP缓存数据过大,需要进行分片发包,分片发包过程中,发送端发送的数据报文中的Ack(Acknowledgment number)编号保持一致retransmission:重传常见问题:为什么会发送RST?https://blog.csdn.net/u014774781/article/details/48349107https://blog.csdn.net/guowenyan001/article/details/11766929
智能推荐
Dynamic Proxy模式_dyproxy-程序员宅基地
文章浏览阅读966次。 Dynamic Proxy 是JDK 1.3 版本中新引入的一种代理机制。严格来讲,Dynamic Proxy本身并非一种模式,只能算是Proxy 模式的一种动态实现方式,不过为了与传统Proxy 模式相区分,这里暂且将其称为“Dynamic Proxy 模式”来泛指通过Dynamic Proxy 机制实现的Proxy 模式。 通过Decorator模式,我们可以改写接口_dyproxy
【Cisco Packet Tracer】运输层端口与DHCP的作用_cisco dhcp端口-程序员宅基地
文章浏览阅读1.7w次,点赞81次,收藏65次。这篇文章摘要将介绍人工智能在医疗领域的应用。随着技术的迅猛发展,人工智能在医疗诊断、治疗和研究方面展现出巨大的潜力。我们将深入探讨人工智能在医学影像解读上的应用,如何通过深度学习算法提高医生对X光、MRI等图像的准确性。_cisco dhcp端口
JavaScript----闭包函数-程序员宅基地
文章浏览阅读3.2k次,点赞5次,收藏16次。闭包函数 作用域链 优缺点_闭包函数
时序分解 | EEMD集合经验模态分解时间序列信号分解Matlab实现_eemd matlab-程序员宅基地
文章浏览阅读953次,点赞19次,收藏14次。信号去噪是信号处理中的一个重要课题,其目的是从含有噪声的信号中提取出有用信号。近年来,经验模态分解(EMD)算法因其在信号去噪方面的优异性能而备受关注。然而,传统EMD算法存在分解结果不稳定、易受噪声影响等问题。为了克服这些问题,本文提出了一种基于总体平均经验模态分解(EEMD)算法的信号去噪方法。_eemd matlab
Android腾讯微薄客户端开发八:微博查看(转播,对话,点评)-程序员宅基地
文章浏览阅读86次。Android如果是自己的微博,可以干掉它下面三幅图是转播,对话以及点评界面Java代码publicclassWeiboDetailActivityextendsActivity{privateDataHelperdataHelper;privateUserInfouser;p...
【lssvm分类】基于算术算法优化最小二乘支持向量机AOA-LSSVM实现数据分类附matlab-程序员宅基地
文章浏览阅读44次。在机器学习领域,支持向量机(Support Vector Machines,SVM)是一种广泛应用的分类算法。然而,传统的SVM算法在处理大规模数据集时存在一些问题,如计算复杂度高和内存占用大等。为了解决这些问题,一种基于算术算法优化的最小二乘支持向量机(AOA-LSSVM)被提出。AOA-LSSVM是一种改进的支持向量机算法,它通过对算术算法进行优化,提高了算法的效率和性能。它采用了最小二乘支持向量机(LSSVM)的思想,通过优化算法的求解过程,使得算法在处理大规模数据集时更加高效。_aoa-lssvm
随便推点
基于matlab的稀疏表示KSVD算法图像去噪_字典学习 稀疏编码 图像去噪-程序员宅基地
文章浏览阅读441次。稀疏表示KSVD算法是图像去噪问题中比较有效的方法之一,本文将详细介绍在matlab平台上如何使用KSVD算法进行图像去噪,并提供完整的源代码。KSVD算法是一种基于字典的稀疏表达方法,其核心思想是将待处理图像分解为一些基础元素的线性组合形式,即通过求解一个优化问题,来获取合适的基础元素和系数表达式。稀疏编码则负责计算每个字典元素的系数,使得最终重构得到的图像与原始图像之间的误差最小。2)初始化字典D,通常采用大小为[KxN]的随机矩阵,其中K表示字典中元素的数量,N表示图像块的大小。_字典学习 稀疏编码 图像去噪
golang基础 第3章 (struct,函数,方法,接口,泛型,类型集,类型)_go 泛型 struct-程序员宅基地
文章浏览阅读1k次,点赞19次,收藏25次。golang 基础之struct func 方法 接口 泛型_go 泛型 struct
socket.io-client的4.0封装使用-程序员宅基地
文章浏览阅读4.3k次,点赞2次,收藏10次。socket.io-client的二次封装,4.0版本,含有心跳连接、连接超时、连接错误等监听_socket.io-client
git基础教程(21)git restore还原改动-程序员宅基地
文章浏览阅读8.3k次,点赞3次,收藏2次。git restore <file>表示将在工作空间但是不在暂存区的文件撤销更改.git restore --staged <file>作用是将暂存区的文件从暂存区撤出,但不会更改文件。演示1:1、仓库初始状态:干净的仓库,下面有一个readme文件小静静@DESKTOP-MD21325 MINGW64 /d/test1/test1 (master)$ git statusOn branch masterYour branch is up to date with_git restore
远古项目实战丨用Python一秒搞定垃圾分类_python垃圾分类-程序员宅基地
文章浏览阅读1.7k次,点赞4次,收藏18次。这是一个严肃又欢乐的七月,哲学界迎来新拷问。传统古典哲学的代表,是门口的保安大叔,他提出了三个经典问题:“你是谁?你从哪儿来?要到哪儿去?而后现代主义哲学的四位代表人物冒了出来,发出直指人内心的提问。食堂大妈:你要饭吗?配钥匙师傅:你配吗?算命先生:你算什么东西?滴滴司机:你搞清楚自己的定位没有?从本月起,魔都正式步入生活垃圾强制分类的时代。个人一旦违规混合投放垃圾,将被处以最高200元的罚款。新兴哲学代表垃圾分类阿姨正式上岗:你是什么垃圾?_python垃圾分类
【机器学习】机器学习之数据清洗_数据清洗论文包括代码-程序员宅基地
文章浏览阅读1.9w次,点赞9次,收藏8次。在实验中探索数据清洗的重要性以及清洗过程中的一些关键步骤,理解数据清洗是一个必要的预处理过程,用来帮助从原始数据中去除不准确、不完整或不适用于模型的记录,以确保所使用的数据是准确、可靠且适合用于模型训练,也可以帮助发现和纠正数据中的错误、缺失和不一致之处,以提高数据的质量和准确性。_数据清洗论文包括代码