nlopt非线性优化算法整理-程序员宅基地
最近做项目想引入NLopt到C++里进行非线性优化,但是好像C++的文档不是很详细,官网关于C的文档介绍得更多一些,关于具体的例程也所讲甚少,这篇博客介绍例程介绍得比较详细:
另外一些例子可以在nlopt目录下的nlopt\test找到相关的测试文件:
有py、c++、c、matlab的文件。
但是具体要使用什么算法呢?感觉官网的博客写得比较繁杂,这里自己做一下整理(如果有错误和遗漏的话欢迎指出),首先所有的算法都是放在nlopt.h头文件里的:
typedef enum {
/* Naming conventions:
NLOPT_{G/L}{D/N}_*
= global/local derivative/no-derivative optimization,
respectively
*_RAND algorithms involve some randomization.
*_NOSCAL algorithms are *not* scaled to a unit hypercube
(i.e. they are sensitive to the units of x)
*/
NLOPT_GN_DIRECT = 0,
NLOPT_GN_DIRECT_L,
NLOPT_GN_DIRECT_L_RAND,
NLOPT_GN_DIRECT_NOSCAL,
NLOPT_GN_DIRECT_L_NOSCAL,
NLOPT_GN_DIRECT_L_RAND_NOSCAL,
NLOPT_GN_ORIG_DIRECT,
NLOPT_GN_ORIG_DIRECT_L,
NLOPT_GD_STOGO,
NLOPT_GD_STOGO_RAND,
NLOPT_LD_LBFGS_NOCEDAL,
NLOPT_LD_LBFGS,
NLOPT_LN_PRAXIS,
NLOPT_LD_VAR1,
NLOPT_LD_VAR2,
NLOPT_LD_TNEWTON,
NLOPT_LD_TNEWTON_RESTART,
NLOPT_LD_TNEWTON_PRECOND,
NLOPT_LD_TNEWTON_PRECOND_RESTART,
NLOPT_GN_CRS2_LM,
NLOPT_GN_MLSL,
NLOPT_GD_MLSL,
NLOPT_GN_MLSL_LDS,
NLOPT_GD_MLSL_LDS,
NLOPT_LD_MMA,
NLOPT_LN_COBYLA,
NLOPT_LN_NEWUOA,
NLOPT_LN_NEWUOA_BOUND,
NLOPT_LN_NELDERMEAD,
NLOPT_LN_SBPLX,
NLOPT_LN_AUGLAG,
NLOPT_LD_AUGLAG,
NLOPT_LN_AUGLAG_EQ,
NLOPT_LD_AUGLAG_EQ,
NLOPT_LN_BOBYQA,
NLOPT_GN_ISRES,
/* new variants that require local_optimizer to be set,
not with older constants for backwards compatibility */
NLOPT_AUGLAG,
NLOPT_AUGLAG_EQ,
NLOPT_G_MLSL,
NLOPT_G_MLSL_LDS,
NLOPT_LD_SLSQP,
NLOPT_LD_CCSAQ,
NLOPT_GN_ESCH,
NLOPT_GN_AGS,
NLOPT_NUM_ALGORITHMS /* not an algorithm, just the number of them */
} nlopt_algorithm;
注释里讲得很清楚:
- NLOPT_{G/L}{D/N}_* = global/local derivative/no-derivative optimization,
respectively
算法的命名,G/L表示全局/局部优化,D/N表示有导数和无导数优化)
- *_RAND algorithms involve some randomization.
*_RAND 为随机算法
- *_NOSCAL algorithms are not scaled to a unit hypercube
(i.e. they are sensitive to the units of x)
*_NOSCAL不对问题进行标准化或缩放到单位超立方体(unit hypercube)。标准化或缩放是一种常见的预处理步骤,用于将优化问题的变量范围映射到单位超立方体(每个变量的范围为[0, 1])。这种标准化可以使不同变量的范围保持一致,从而更容易进行优化。但有的问题并不适合进行这种缩放。
简单做了一个表总结吧(按照文档梳理的):
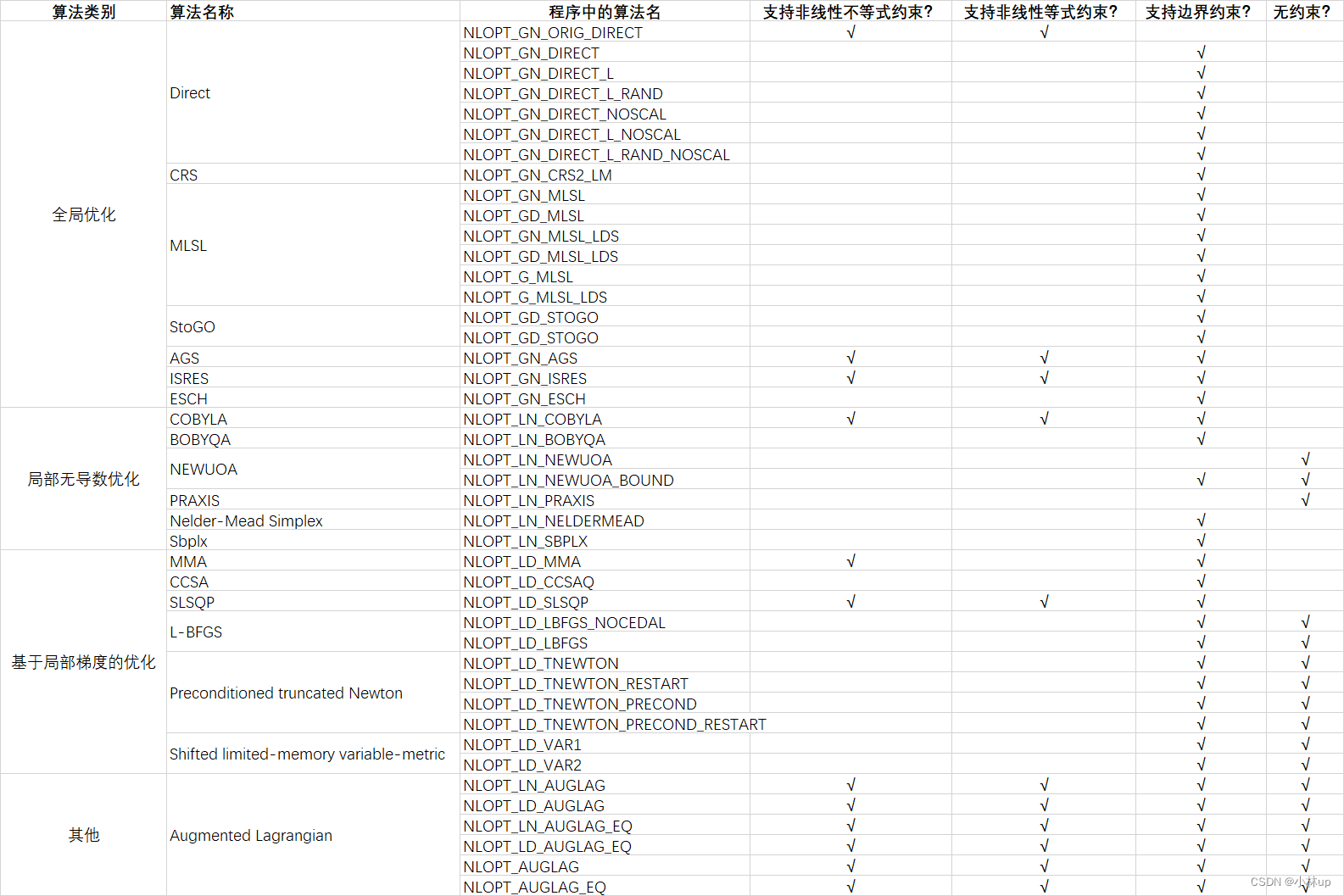
下面都是从文档里面摘录出来的,个人觉得有用的信息保留了下来,具体的算法参考的哪个参考文献还是建议读者去官网的文档查看:
NLopt Algorithms
1. 全局优化
NLopt所有全局优化算法都要求对所有优化参数指定边界约束。
- 支持非线性不等式约束的算法:
NLOPT_GN_ISRES、NLOPT_GN_AGS和NLOPT_GN_ORIG_DIRECT - 支持非线性等式约束的算法:
NLOPT_GN_ISRES。 - 可以通过将它们与增广Lagrange方法相结合,可以将任何算法应用于非线性约束问题。
- tips: 在运行全局优化之后,可以使用全局最优解作为局部优化的起点,以将最优解“打磨”到更高的精度。(许多全局优化算法更注重搜索全局参数空间,而不是精确找到局部最优解的位置。)
1.1 Direct算法
- Direct算法实现了多个版本,在NLopt里实现的版本主要有:
NLOPT_GN_DIRECT = 0,
NLOPT_GN_DIRECT_L,
NLOPT_GN_DIRECT_L_RAND,
NLOPT_GN_DIRECT_NOSCAL,
NLOPT_GN_DIRECT_L_NOSCAL,
NLOPT_GN_DIRECT_L_RAND_NOSCAL,
Direct方法只处理边界约束,并且实际上需要有限的边界约束(它们不适用于无约束问题)。它们不处理任意的非线性约束。它们的思想都是基于将搜索区域系统地划分为越来越小的超矩形来进行确定性确定性搜索。
- Direct_L版本的算法“更偏向于局部搜索”,因此对于没有太多局部最小值的函数来说,它更有效。作者推荐优先使用
NLOPT_GN_DIRECT_L。 NLOPT_GN_DIRECT_L_RAND_NOSCAL是Direct_L版本算法的随机化变体,使用随机化来帮助决定近似平局的情况下使用一些随机化来决定下一个要分割的维度。- Direct和Direct_L算法首先将边界约束重新缩放为超立方体,这样在搜索过程中所有维度都具有相等的权重。这里又分为有缩放和无缩放版本,默认的是使用有缩放版本,使用无缩放版本的情况在于:
- 如果你的维度权重不相等,例如如果你的搜索空间是“长而狭窄”的,并且你的函数在所有方向上的变化速度大致相同,那么最好使用这些算法的无缩放变体,包括
NLOPT_GNL_DIRECT_NOSCAL、NLOPT_GN_DIRECT_L_NOSCAL和NLOPT_GN_DIRECT_L_RAND_NOSCAL指定。对于无缩放变体最适合原始的Direct算法,因为Direct_L的设计在某种程度上依赖于搜索区域是一个超立方体(这导致被分割的超矩形只有一小部分边长)
- 如果你的维度权重不相等,例如如果你的搜索空间是“长而狭窄”的,并且你的函数在所有方向上的变化速度大致相同,那么最好使用这些算法的无缩放变体,包括
1.2 CRS(Controlled Random Search)算法
NLopt的CRS算法(尤其是CRS2变体)进行了“局部突变”修改。
- CRS算法和遗传算法相似,因为它们都从随机的点“总体”开始,然后通过启发式规则随机“演化”这些点。在这种情况下,“进化”有点类似于随机的Nelder-Mead算法。相关论文里的CRS结果似乎很大程度上是经验性的。此算法仅支持边界约束问题。它在NLopt实现的版本是:
NLOPT_GN_CRS2_LM
- CRS算法的初始总体大小在 n 个维度中默认为 10×(n+1),初始总体大小可以通过
nlopt_set_population函数进行更改;初始总体必须至少为 n+1。
1.3 MLSL(Multi-Level Single-Linkage)算法
MLSL算法通过一系列从随机起始点开始的局部优化(使用其他一些局部优化算法)来进行全局优化,它是一种“多起点”算法。该算法仅支持有边界约束的问题。在NLopt里实现的版本主要有:
NLOPT_GN_MLSL,
NLOPT_GD_MLSL,
NLOPT_GN_MLSL_LDS,
NLOPT_GD_MLSL_LDS,
...
NLOPT_G_MLSL,
NLOPT_G_MLSL_LDS,
- 后缀有LDS的算法为修改的MLSL算法,它使用Sobol’低差异序列(LDS)代替伪随机数,据称可以提高收敛速度。基于LDS的MLSL为
NLOPT_G_MLSL_LDS,而无LDS的MLSL(使用伪随机数,目前通过Mersenne twister算法)使用NLOPT_G_MLSL表示。 - MLSL的局部搜索部分可以使用NLopt中的任何其他算法,特别是可以使用基于梯度的算法(D)或无导数的算法(N)。局部搜索使用由
nlopt_opt_set_local_optimizer设置的导数/非导数算法。 - MLSL的区别在于“聚类”启发式方法,这有助于它避免重复搜索相同的局部最优值,并且在理论上可以保证在有限数量的局部最小化中找到所有局部最优值。
- 默认情况下,如果没有为局部优化算法设置停止容差,MLSL的默认设置为ftol_rel= 1 0 − 15 10^{-15} 10−15和xtol_rel= 1 0 − 7 10^{-7} 10−7用于局部搜索。请注意,为这些局部搜索设置相对较大的容差是完全合理的。
- 默认情况下,MLSL的每次迭代会采样4个随机的新试验点,但可以使用
nlopt_set_population函数进行更改。 - 可以先运行MLSL进行全局优化,然后在最后使用更低的容差使用MLSL的结果作为起始点运行另一个局部优化,实现高精度"优化"最优解。
1.4 StoGO算法
StoGO是一种全局优化算法,通过系统地将搜索空间(必须有边界约束)通过分支定界技术划分为较小的超矩形,并使用基于梯度的局部搜索算法(一种BFGS变体)对其进行搜索,可选择包含一些随机性(因此有"Sto",代表"stochastic")。该算法仅支持有边界约束的问题。在NLopt里实现的版本主要有:
NLOPT_GD_STOGO,
NLOPT_GD_STOGO_RAND,
NLOPT_GD_STOGO是StoGO的标准算法,NLOPT_GD_STOGO_RAND是算法的随机变体。- StoGO是用C++编写的,这意味着只有在启用C++算法时才会包含它,使用的时候必须使用
-lnlopt_cxx而不是-lnlopt
1.5 AGS算法
NLopt使用的AGS算法改编自ags_nlp_solver,AGS算法可以处理任意的目标函数和非线性不等式约束,此外,边界约束也是需要被包含的。为了保证收敛性,目标函数和约束条件应满足指定超矩形上的Lipschitz条件。AGS是一种无导数算法,它使用希尔伯特曲线将源问题转化为一元问题。该算法将一元空间划分为区间,通过使用后验概率生成新的点。在每次试验中,AGS依次尝试评估约束条件。如果某个约束在该点处被违反,后续的约束将不会被评估。如果所有约束条件都得到满足,即试验点是可行的,AGS将评估目标函数。因此,一些约束条件(除了第一个)和目标函数可以在搜索超矩形中部分未定义。在NLopt里实现的版本主要有:
NLOPT_GN_AGS
- AGS 在 NLopt 中由
NLOPT_GN_AGS指定。AGS 的其他参数无法从公共 NLOpt 接口进行调整,它在ags.h中声明和描述。此外,AGS 源文件中还给出了解决约束问题的示例。 - 当空间维数大于 5 时,机器算术的局限性不允许为 Hilbert 构建紧密近似,因此 AGS 的这种实现在这个意义上受到限制。它最多支持 10 个维度,但在 6 个或更多维度的情况下,该方法可以提前停止。
- AGS 和 StoGO 一样,是用 C++ 编写的,但它需要 C++11。如果库是使用 C++ 构建的,并且编译器支持 C++11,则也会构建 AGS。
- 目前NLOpt里的AGS不支持向量约束。
1.6 ISRES(Improved Stochastic Ranking Evolution Strategy)算法
ISRES算法用于非线性约束的全局优化(至少是半全局优化;虽然它具有逃离局部最优解的启发式方法,但目前是否存在收敛证明还不知道),该方法支持任意的非线性不等式和等式约束以及边界约束。在NLopt里实现的版本主要有:
NLOPT_GN_ISRES,
该进化策略基于突变规则(对数正态步长更新和指数平滑)和差分变异(一种类似Nelder-Mead的更新规则)的组合,对于没有非线性约束的问题,适应度排序仅通过目标函数进行,当包含非线性约束时,采用了Runarsson和Yao提出的随机排序方法。
- ISRES的种群大小在n维中默认为20×(n+1),可以使用
nlopt_set_population函数进行更改。
1.7 ESCH(evolutionary algorithm)算法
ESCH是用于全局优化的改进进化算法,该方法仅支持边界约束(无非线性约束)。在NLopt里实现的版本主要有:
NLOPT_GN_ESCH
2. 局部无导数优化
目前只有 NLOPT_LN_COBYLA原生地支持任意非线性不等式和相等约束;其余的仅支持有约束或无约束的问题。但是,可以通过将它们与增强拉格朗日方法相结合,它们中的任何一个都可以应用于非线性约束问题。
使用局部无导数算法时,必须考虑优化器以何种方式决定初始步长。默认情况下,NLopt 会启发式地选择此初始步长,但这可能并不总是最佳选择。如果遇到问题,可以修改初始步长。
2.1 COBYLA(Constrained Optimization BY Linear Approximations)算法
COBYLA算法可以用于具有非线性不等式和相等约束的无导数优化。它通过 n+1 个点的单纯形(以 n 维为单位)构造目标函数和约束的连续线性近似,并在每一步的信任区域中优化这些近似值。在NLopt里实现的版本主要有:
NLOPT_LN_COBYLA
- NLopt对COBYLA算法进行了一些修改:首先,纳入了所有 NLopt 终止标准。其次,添加了对边界约束的显式支持(尽管原始的 COBYLA 可以将绑定约束作为线性约束进行处理,但有时它会采取违反绑定约束的步骤)。第三,如果预测的更新大致正确且单纯形正常,则允许增加信任区域半径,该建议似乎可以提高收敛速度。第四,在COBYLA算法中伪随机化单纯形步骤,通过避免意外采取不改善条件反射的步骤来提高鲁棒性(这似乎有时会发生在主动约束下);但是,该算法仍然是确定性的(使用确定性种子)。此外,支持不同参数中的初始步长不相等(通过内部重新缩放与初始步长成比例的参数的简单方法),当不同参数具有非常不同的尺度时,这一点很重要。
- 底层 COBYLA 代码仅支持不等式约束。相等约束会自动转换为成对的不等式约束,在这种情况下,似乎不会引起问题。
2.2 BOBYQA算法
BOBYQA算法从 M. J. D. Powell 的 BOBYQA 子程序派生的算法,转换为 C 语言并针对 NLopt 停止标准进行了修改。它使用迭代构造的目标函数二次近似执行无导数边界约束优化(由于 BOBYQA 构造了目标的二次近似,因此对于不可两次微分的目标函数,它可能表现不佳)。在NLopt里实现的版本主要有:
NLOPT_LN_BOBYQA
- BOBYQA 接口支持不同参数中不相等的初始步长(通过内部重新缩放与初始步长成比例的参数的简单方法),这在不同参数具有非常不同的尺度时非常重要。
2.3 NEWUOA算法
NEWUOA 算法是从 M. J. D. Powell 的 NEWUOA 子程序派生的算法,转换为 C 并针对 NLopt 停止标准进行了修改。原始 NEWUOA 使用迭代构造的目标函数二次近似执行无导数无约束优化。该算法在很大程度上被 2.2所述的BOBYQA算法所取代(它针对边界约束以及一些数值稳定性和收敛增强功能进行了修改)。在NLopt里实现的版本主要有:
NLOPT_LN_NEWUOA,
NLOPT_LN_NEWUOA_BOUND,
NLOPT_LN_NEWUOA为原始算法 ,并且仅支持无约束问题。NLOPT_LN_NEWUOA_BOUND为NLopt提供的一个变体,它允许有效处理边界约束。- 在最初的 NEWUOA 算法中,Powell 通过截断共轭梯度算法求解了球形信任区域中的二次子问题(在例程 TRSAPP 和 BIGLAG 中)。在NLopt的边界约束变体中则对这些子问题使用 MMA 算法来求解它们,同时使用边界约束和球形信任区域。原则上,也应该以类似的方式更改 BIGDEN 子程序(因为 BIGDEN 也近似地求解了一个信任区域子问题),但Nlopt的算法只是将其结果截断到边界(这可能会给出次优收敛,但 BIGDEN 在实践中很少被调用)。
- NEWUOA 算法要求参数空间的维数 n ≥ 2,即实现不处理一维优化问题。
2.4 PRAXIS(PRincipal AXIS)算法
PRAXIS算法最初是为无约束优化而设计的,它使用Richard Brent 的“主轴方法”进行“PRAXIS”无梯度局部优化。在NLopt里实现的版本主要有:
NLOPT_LN_PRAXIS,
- 在 NLopt 中,边界约束在 PRAXIS 中通过违反约束时返回无穷大 (Inf) 的简单方式“实现”(这是自动完成的,不必在自己的函数中执行此操作)。这似乎有效,但似乎大大减慢了收敛速度。所以如果有边界约束,则最好使用 COBYLA 或 BOBYQA。
2.5 Nelder-Mead Simplex算法
NLopt实现了原始的 Nelder-Mead 单纯形算法,在NLopt里实现的版本主要有:
NLOPT_LN_NELDERMEAD
- NLopt实现了对边界约束的显式支持
- 每当一个新点位于约束约束之外时,Box 主张将其“刚好在”约束内移动一些固定的小距离 1 0 − 8 10^{−8} 10−8左右。在约束内使用固定距离有什么好处,特别是当最优值就位于约束上时,所以在这种情况下,NLopt选择可以将点精确地移动到约束上。这种方式(或通过 Box 的方法)实现边界约束的危险在于,可能会将单纯形折叠成低维子空间。无论如何,通过重新启动,单纯形的这种崩溃在某种程度上得到了改善,例如在下面的 Subplex 算法中使用 Nelder-Mead 时。
2.6 Sbplx (based on Subplex)算法
Subplex(Nelder-Mead 的变体,在一系列子空间上使用 Nelder-Mead)据称比原来的 Nelder-Mead 更有效、更强大,同时保留了后者具有不连续目标的设置(然而还不知道有任何证据表明 Subplex 是全局收敛的,也许它可能会在某些目标上失败)。在NLopt里实现的版本主要有:
NLOPT_LN_SBPLX
- NLopt实现了对边界约束的显式支持
3. 基于局部梯度的优化
算法概览:
- 支持任意非线性不等式约束:只有 MMA 和 SLSQP 。
- 支持非线性等式约束:只有 SLSQP。
- 支持边界约束或无约束的问题:其余算法。
- 但是,通过将它们与下面的增强拉格朗日方法相结合,它们中的任何一个都可以应用于非线性约束问题。
3.1 MMA (Method of Moving Asymptotes) 和CCSA算法
全局收敛的移动渐近线方法 (MMA) 算法被用于基于梯度的局部优化,包括非线性不等式约束(但不是相等约束),注意:“全局收敛”并不意味着该算法收敛到全局最优;它意味着它保证从任何可行的起点收敛到某个局部最小值。在NLopt里实现的版本主要有:
NLOPT_LD_MMA
NLOPT_LD_CCSAQ
- MMA 算法在每个点 x 处,使用 f 的梯度和约束函数形成局部近似,加上二次“惩罚”项,使近似“保守”(精确函数的上限)。精确的近似MMA形式很难用几句话来描述,因为它包括非线性项,由距离x一定距离的极点组成(在当前信任区域之外),几乎是一种Padé近似。主要的一点是,近似既是凸的,又是可分离的,因此用对偶方法求解近似优化变得微不足道。优化近似值会导致新的候选点 x。在候选点评估目标和约束。如果近似值确实是保守的(候选点处实际函数的上限),则该过程将在新的 x 处重新启动。否则,近似值将变得更加保守(通过增加惩罚项)并重新优化。
- CCSA 算法,它不是构造局部 MMA 近似,而是构造简单的二次近似(或者更确切地说,仿射近似加上二次惩罚项以保持保守)。对于大多数问题,它似乎与 MMA 具有相似的收敛率。对于二次变量,NLopt实现了预处理的可能性:在局部模型中包括用户提供的 Hessian 近似。全局收敛仍然是有保证的,并且如果预处理器是真实Hessian的良好近似(至少对于最大特征值的特征向量),则可以大大提高收敛性。
- 上述的两个算法支持使用
nlopt_set_param设置内部参数:inner_maxeval:如果 ≥ 0,则给出算法的最大“内部”迭代次数,其中它试图确保其近似值是“保守的”;默认值为0(无限制)。如果梯度或目标函数的不准确性阻碍了算法的进展,可以为该参数指定一个有限的数值(如5或10)dual_algorithm(默认值为NLOPT_LD_MMA)、dual_ftol_rel(默认值为 1 0 − 14 10^{-14} 10−14)、dual_ftol_abs(默认值为0 )、dual_xtol_rel(默认值为0 )、dual_xtol_abs(默认值为0 ):这些参数用于指定算法在内部求解其近似目标的“对偶”优化问题。由于这个辅助求解不需要对用户的目标函数进行评估,通常它足够快,可以在不太关心细节的情况下以高精度解决它。然而,在高维问题中,您可能会注意到MMA/CCSA在优化步骤之间花费了很长时间,在这种情况下,您可能希望增加或进行其他更改。如果未指定这些参数,NLopt将使用子优化器算法中的参数(如果已指定),否则使用这里指定的默认值。verbosity:如果大于0,则导致算法在每次迭代时打印内部状态信息。
3.2 SLSQP算法
SLSQP算法是用于**非线性约束梯度优化(支持不等式和等式约束)**的顺序二次规划(SQP)。该问题被视为一系列受约束的最小二乘问题,但是这样的最小二乘问题等价于二次规划问题。该算法通过BFGS更新优化目标函数的连续二阶(二次/最小二乘)近似,并使用约束的一阶(仿射)近似。在NLopt里实现的版本主要有:
NLOPT_LD_SLSQP
- NLopt中对该算法进行了以下更改:
- 将代码转换为C语言并进行手动清理。修改为可重入(保留了反向通信接口,但在数据结构中显式保存状态)。
- 使用NLopt风格的接口包装了反向通信接口,并添加了NLopt的停止条件。修正了不精确的线搜索,以便在第一步中计算函数和梯度,因为这样可以避免在不精确的线搜索在单步后结束时为相同点再次计算函数+梯度。
- 由于舍入误差有时会使SLSQP的参数略微超出边界约束(NLopt不允许此情况),添加了检查以将参数强制限制在边界内。
- 对于等式约束数等于问题维度的情况,修复了LSEI子程序中的一个错误(未初始化变量的使用)。
- 对于具有无限下界/上界的情况,修改了LSQ子程序以处理这些约束(在这种情况下,这些约束将被省略)。
- 由于SLSQP代码使用了密集矩阵方法(普通BFGS,而不是低存储BFGS),在n维空间中,它需要 O ( n 2 ) O(n^2) O(n2)的存储空间和 O ( n 3 ) O(n^3) O(n3)的时间,这使得它在优化超过几千个参数时变得不太实用。
3.3 Low-storage BFGS算法
原始的L-BFGS算法基于通过Strang递归进行变量度量更新。在NLopt里实现的版本主要有:
NLOPT_LD_LBFGS_NOCEDAL,
NLOPT_LD_LBFGS,
- 该算法的一个参数是梯度数量M(用来记住先前优化的步骤step)。增加M会增加内存要求,但可能加快收敛速度。NLopt默认情况下将M设置为启发式值,但可以通过
nlopt_set_vector_storage函数进行更改。
3.4 Preconditioned truncated Newton算法
预条件截断牛顿(Preconditioned truncated Newton)算法在NLopt里实现的版本主要有:
NLOPT_LD_TNEWTON,
NLOPT_LD_TNEWTON_RESTART,
NLOPT_LD_TNEWTON_PRECOND,
NLOPT_LD_TNEWTON_PRECOND_RESTART,
- NLopt包含了预条件截断牛顿(Preconditioned truncated Newton)算法的几种变体:
- 首先是通过低存储BFGS算法进行预条件的变体,其中包括最陡下降法重新启动,指定为
NLOPT_LD_TNEWTON_PRECOND_RESTART。 - 其次是简化版本(没有重新启动的算法),分别是
NLOPT_LD_TNEWTON_PRECOND(没有重新启动)、NLOPT_LD_TNEWTON_RESTART(没有预条件)和NLOPT_LD_TNEWTON(没有重新启动或预条件的最简化版本)。
- 首先是通过低存储BFGS算法进行预条件的变体,其中包括最陡下降法重新启动,指定为
- 该算法的一个参数是梯度数量M(用来记住先前优化的步骤step)。增加M会增加内存要求,但可能加快收敛速度。NLopt默认情况下将M设置为启发式值,但可以通过
nlopt_set_vector_storage函数进行更改。
3.5 Shifted limited-memory variable-metric算法
移位有限存储变量度量(Shifted limited-memory variable-metric)算法在NLopt里实现的版本主要有:
NLOPT_LD_VAR1,
NLOPT_LD_VAR2,
NLOPT_LD_VAR2使用二阶方法,而NLOPT_LD_VAR1使用一阶方法。- 该算法的一个参数是梯度数量M(用来记住先前优化的步骤step)。增加M会增加内存要求,但可能加快收敛速度。NLopt默认情况下将M设置为启发式值,但可以通过
nlopt_set_vector_storage函数进行更改。
4. Augmented Lagrangian算法
NLopt中有一个算法可以适用于上述所有类别,具体取决于指定的辅助优化算法,即增广拉格朗日方法(Augmented Lagrangian algorithm)。它的思路是将目标函数和非线性不等式/等式约束(如果有)组合成一个单一的函数:基本上是目标函数加上对任何违反约束的“惩罚”。然后,将这个修改后的目标函数传递给另一个没有非线性约束的优化算法。如果这个子问题的解违反了约束条件,那么惩罚的大小就会增加,然后重复这个过程;最终,该过程必须收敛到所需的解(如果存在)。它在NLopt里实现的版本主要有:
NLOPT_LN_AUGLAG,
NLOPT_LD_AUGLAG,
NLOPT_LN_AUGLAG_EQ,
NLOPT_LD_AUGLAG_EQ,
NLOPT_AUGLAG,
NLOPT_AUGLAG_EQ,
- 辅助优化算法由函数
nlopt_set_local_optimizer指定(不要忘记为这个辅助优化器设置一个停止容差!)由于所有实际的优化都在这个辅助优化器中进行,指定的辅助算法决定了优化是基于梯度还是无导数。实际上,甚至可以为辅助优化器指定一个全局优化算法,以进行全局非线性约束优化(尽管为该辅助全局优化器指定一个良好的停止准则比较困难)。 - 在NLopt中,增广拉格朗日方法被定义为
NLOPT_AUGLAG。另一个变体NLOPT_AUGLAG_EQ只对等式约束使用惩罚函数,而将不等式约束直接传递给辅助算法处理;在这种情况下,辅助算法必须处理不等式约束(例如MMA算法或COBYLA算法)。
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线