深度学习--- GAN网络原理解析-程序员宅基地
技术标签: 生成对抗网络 GAN 深度学习 Machine Learning & Algorithm
Generative Adversarial Network对抗生成网络,这是当下机器视觉比较热门的一个技术,由两部分组成生成器( G n e t G_{net} Gnet)和判别器( D n e t D_{net} Dnet)组成
GAN区别与传统的生成网络,生成的图片还原度高,主要缘于D网络基于数据相对位置和数据本身对 r e a l real real数据奖励,对 f a k e fake fake数据惩罚的缘故
1.GAN思想 & 与单个传统生成器和判别器的对比
1.1GAN的思想类似于"零和博弈",百度百科这样介绍:
零和游戏的原理如下:两人对弈,总会有一个赢,一个输,如果我们把获胜计算为得1分,而输棋为-1分。则若A获胜次数为N,B的失败次数必然也为N。若A失败的次数为M,则B获胜的次数必然为M。这样,A的总分为(N-M),B的总分为(M-N),显然(N-M)+(M-N)=0,这就是零和游戏的数学表达式。
也就是奖励获胜者,惩罚失败者,在GAN中就是奖励真实图片,且惩罚伪造图片,且奖励和惩罚同时发生,当然现在说这个有点早,往后看你会慢慢的发现这就是D网络的一个反馈机制
1.2单个生成器和判别器与GAN的对比
1.2.1 生成器(Generation)
就是利用模型对图片的学习,最终达到可以自己生成图片的目的
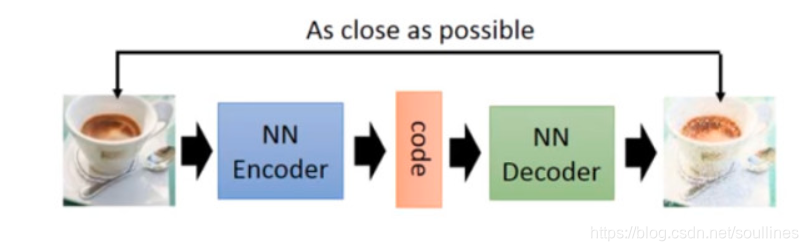
就像上图表示的就是生成器的一种(还有一种变分自编码器这里不做过多的赘述)
s t e p 1 : step1: step1:将图片传入解码器 NN-Encoder 转化为机器可以识别的array形式,然后通过 NN-Decoder生成图片 P i c f a k e Pic_{fake} Picfake
s t e p 2 : step2: step2:已知真实图片 P i c r e a l Pic_{real} Picreal,通过 l o s s loss loss函数 M S E MSE MSE,计算真实图片和生成图片的 l o s s loss loss,进而反馈网络
这样看起来好像是没有什么问题,但是需要注意一个问题,这里的 l o s s loss loss仅仅计算数据之间的差异,图片的像素 v a l val val不仅仅是数据的堆叠那么简单,同样相对位置(数据之间的相关性)也是很重要的一个部分,由于G网络没有办法学习到位置的相关性
所以 G e n e r a t i o n Generation Generation不能生成高还原度的图片
1.2.2 判别器(Discriminator)
简单来说就是一个判断 r e a l real real图片和 f a k e fake fake图片的二分类模型
i n p u t : x o u t p u t : y y ∈ [ 0 , 1 ] input:x output:y \;\;\;\;\; y\in[0,1] input:xoutput:yy∈[0,1]
Discriminator是一个卷积的神经网络,所以可以有效的区分图片的相对位置(即注重数据的相关性),但是由于Discriminator只对真实数据奖励(此时的 o u t p u t output output大),对伪造的数据惩罚(此时的 o u t p u t output output小)
所以随机数据的选取比较困难
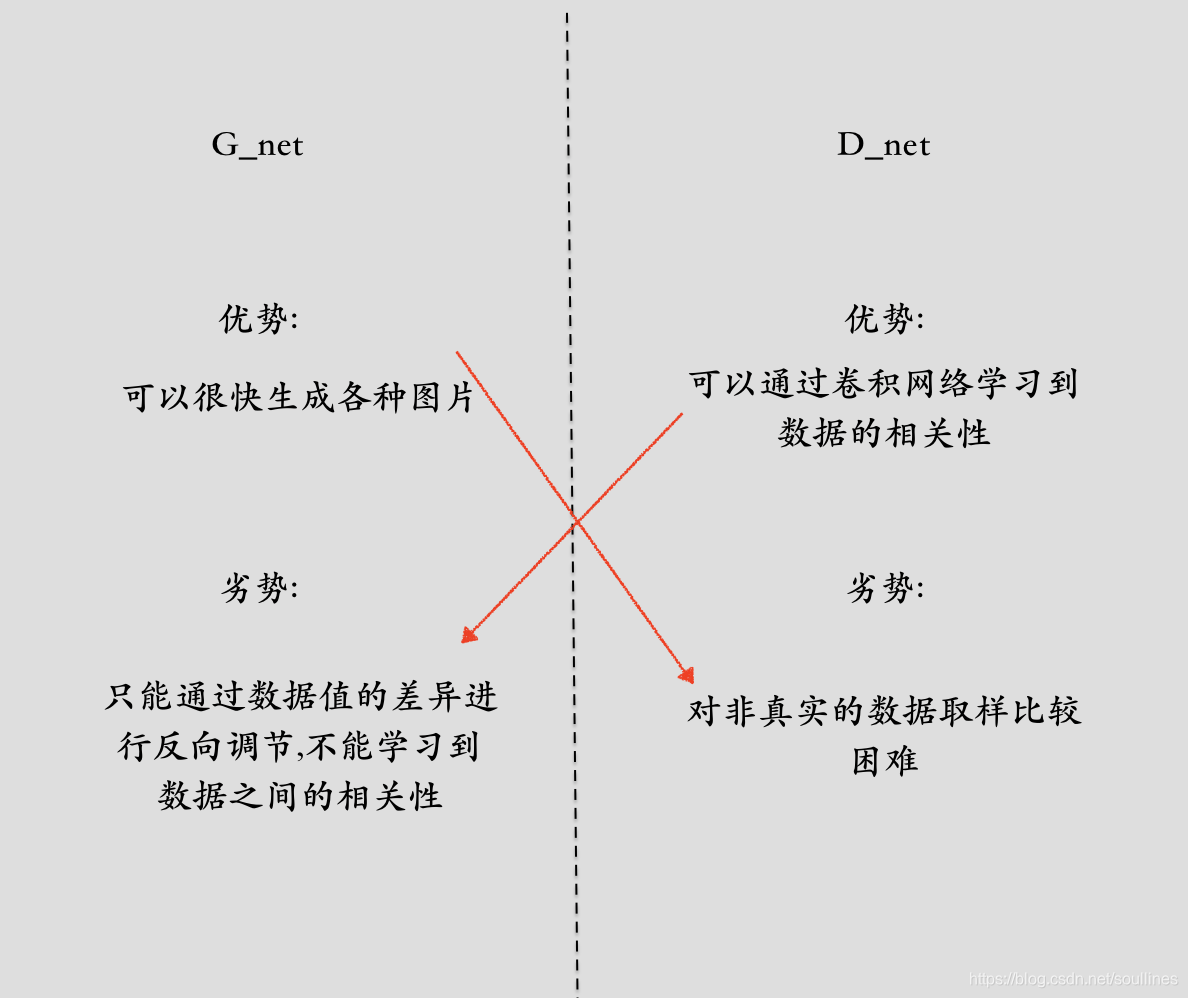
这样对比下 G 和 D的优劣:
这样来看 G网络和 D网络各有优缺点,但是刚刚好可以互补,所以GAN网络顺势而生
2.GAN原理
2.1 Generation
由于单一G网络不能学习到数据之间的相关性,所以G网络的反向传播依赖于D网络
对于生成器而言,它的目的是Generation的 o u t p u t output output要无限接近于真实的数据分布:
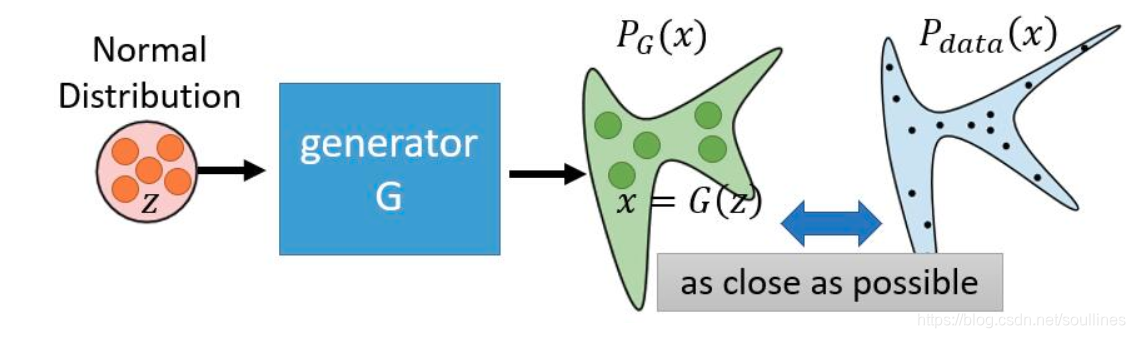
这里会用到极大似然估计:
s t e p 1 : step1: step1:给定真实的数据分布: P d a t a P_{data} Pdata,G网络 o u t p u t : x = G ( z ) output:x = G(z) output:x=G(z) ,这里的 z z z是G网络的 i n t p u t intput intput
s t e p 2 : step2: step2: 那么这个问题就变成一个求使G网络 o u t p u t output output无限接近于 P d a t a P_{data} Pdata这个真实分布的 θ \theta θ的极大似然估计求解过程
这里我们用 P ( x ; θ ) P(x;\theta) P(x;θ)表示G网络 o u t p u t output output与 P d a t a P_{data} Pdata相似的概率,所以G网络就是求
∀ θ ; P ( x ; θ ) \forall \theta;\;\;\;\;\ P(x;\theta) ∀θ; P(x;θ)最大 的过程;
下面是求解的过程:
θ ∗ = a r g m a x ∏ i = 1 m P G ( x i ; θ ) = a r g m a x ∑ i = 1 m l o g ( P G ( x i ; θ ) ) \theta^* = argmax\prod_{i=1}^m P_G(x^i;\theta)=argmax\sum_{i=1}^mlog(P_G(x^i;\theta)) θ∗=argmax∏i=1mPG(xi;θ)=argmax∑i=1mlog(PG(xi;θ))
≈ a r g m a x E x ∼ p d a t a [ l o g ( P G ( x i ; θ ) ) ] \approx argmaxE_{x \sim p_{data}}[log(P_G(x^i;\theta))] ≈argmaxEx∼pdata[log(PG(xi;θ))]
在这里我们要构建一个 K L − d i v e r g e n c e KL-divergence KL−divergence的形式,我们都知道个 K L − d i v e r g e n c e KL-divergence KL−divergence是描述两个概率之间差异的形式,上式后面加一个 ∫ x P d a t a ( x ) l o g ( P d a t a ( x ) d x \int_xP_{data}(x)log(P_{data}(x)dx ∫xPdata(x)log(Pdata(x)dx ,这是一个与 θ \theta θ无关的项所以不会影响后序结果,却可以辅助构建 K L − d i v e r g e n c e KL-divergence KL−divergence形式,所以上式可以这样变形
上式 = a r g m a x [ ∫ x P d a t a ( x ) l o g ( P G ( x i ; θ ) ) − ∫ x P d a t a ( x ) l o g ( P d a t a ( x ) d x ] = argmax[\int_xP_{data}(x)log(P_G(x^i;\theta)) -\int_xP_{data}(x)log(P_{data}(x)dx ] =argmax[∫xPdata(x)log(PG(xi;θ))−∫xPdata(x)log(Pdata(x)dx]
= a r g m a x K L ( P G ∣ ∣ P d a t a ) = argmaxKL(P_G||P_{data}) =argmaxKL(PG∣∣Pdata)
= a r g m n i K L ( P d a t a ∣ ∣ P G ) = argmniKL(P_{data}||P_G) =argmniKL(Pdata∣∣PG)
这样看来G网络的计算就是求解 a r g m n i G K L ( P d a t a ∣ ∣ P G ) argmni_GKL(P_{data}||P_G) argmniGKL(Pdata∣∣PG);但是 P G P_G PG的分布和 P d a t a P_{data} Pdata的差异(也就是 P d a t a 和 P G P_{data}和P_G Pdata和PG的 K L − d i v e r g e n c e KL-divergence KL−divergence),G网络是没有完全办法计算的(G网络不具备数据相关性的学习能力),需要用到D网络的卷积来进行有效计算 l o s s loss loss,所以接下来我们要引入D网络进行鉴别;
2.2 Discriminator
Discriminator鉴别器的机制是奖励真实样本,惩罚伪造样本,鉴别器需要获取G网络数据分布 P G P_G PG和真实数据分布 P d a t a P_{data} Pdata
- s t e p 1 : s a m p l e f r o m P d a t a s a m p l e f r o m P G step1: sample from P_{data} \;\;\; sample from P_G step1:samplefromPdatasamplefromPG
- s t e p 2 : step2: step2:这样我们就获取到了 r e a l real real和 f a k e fake fake的数据分布,用于D网络的 l o s s loss loss计算
下面给出D网络的 l o s s loss loss函数:
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ p G [ l o g ( 1 − D ( x ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x))] + E_{x\sim p_{G}}[log(1- D(x))] V(G,D)=Ex∼pdata[log(D(x))]+Ex∼pG[log(1−D(x))]
这里简单赘述下,上面成本函数的计算过程,后面会详细提到:
V(G,D)可以看做是一个组合的 l o s s loss loss函数
-
若 x x x是生成的数据 x ∼ x^{\sim} x∼, P d a t a ( x ∼ ) = 0 P G ( x ∼ ) = 1 P_{data}(x^\sim) = 0 \;\; P_{G}(x^\sim) = 1 Pdata(x∼)=0PG(x∼)=1,那么:
V ( G , D ) = E x ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] V(G,D)=E_{x\sim p_{G}}[log(1- D(x^\sim))] V(G,D)=Ex∼pG[log(1−D(x∼))]
-
若 x x x是真实的数据 x x x, P d a t a ( x ) = 1 P G ( x ) = 0 P_{data}(x) = 1 \;\; P_{G}(x) = 0 Pdata(x)=1PG(x)=0,那么:
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x ))] V(G,D)=Ex∼pdata[log(D(x))]
所以实际用到的:
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x))] + E_{x^\sim\sim p_{G}}[log(1- D(x^\sim))] V(G,D)=Ex∼pdata[log(D(x))]+Ex∼∼pG[log(1−D(x∼))]
下面是求解的过程:
正如上面所说Discriminator鉴别器的机制是奖励真实样本,惩罚伪造样本;所以D网络的训练过程就是迭代计算使得其 l o s s loss loss函数 V ( G , D ) V(G,D) V(G,D)最大化的过程;也就是 a r g m a x V ( D , G ) argmaxV(D,G) argmaxV(D,G)的过程;
为了方便计算出 V ( G , D ) V(G,D) V(G,D)的最大值,我们求解最优的 D ∗ D^* D∗(也就是 D ( x ) D(x) D(x)),D网络运行阶段G网络可以看做是固定不变的;
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ p G [ l o g ( 1 − D ( x ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x))] + E_{x\sim p_{G}}[log(1- D(x))] V(G,D)=Ex∼pdata[log(D(x))]+Ex∼pG[log(1−D(x))]
= ∫ x P d a t a ( x ) l o g D ( x ) d x + ∫ x P G ( x ) l o g ( 1 − D ( x ) ) d x = \int_xP_{data}(x)logD(x)dx + \int_xP_G(x)log(1-D(x))dx =∫xPdata(x)logD(x)dx+∫xPG(x)log(1−D(x))dx
= ∫ x [ P d a t a ( x ) l o g D ( x ) + ∫ x P G ( x ) l o g ( 1 − D ( x ) ) ] d x =\int_x[P_{data}(x)logD(x) + \int_xP_G(x)log(1-D(x))]dx =∫x[Pdata(x)logD(x)+∫xPG(x)log(1−D(x))]dx
令 a = P d a t a ( x ) D = D ( x ) b = P G ( x ) a=P_{data}(x) \;\;\; D = D(x) \;\;\; b = P_G(x) a=Pdata(x)D=D(x)b=PG(x)
则 V ( G , D ) = a l o g D + b l o g ( 1 − D ) V(G,D) = alogD + blog(1-D) V(G,D)=alogD+blog(1−D)
通过偏导来求上述公式的最大值:
∂ V ( G , D ) ∂ D = a D + b 1 − D = 0 \frac{\partial V(G,D)}{\partial D} = \frac{a}{D} + \frac{b}{1-D} = 0 ∂D∂V(G,D)=Da+1−Db=0
则: D = a / a + b D = a/a+b D=a/a+b
所以 D ∗ = P d a t a ( x ) / ( P d a t a ( x ) + P G ( x ) ) D^* = P_{data}(x) / (P_{data}(x) + P_G(x)) D∗=Pdata(x)/(Pdata(x)+PG(x)) 此为使 V ( D , G ) V(D,G) V(D,G)最大化的最优解
代入 V ( G , D ) V(G,D) V(G,D)
上式 = V ( G , D ∗ ) = V(G,D^*) =V(G,D∗)
= E x ∼ p d a t a [ l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) ] + E x ∼ p G [ l o g P G ( x ) P d a t a ( x ) + P G ( x ) ] = Ex\sim p_{data}[log\frac{P_{data}(x)}{P_{data}(x) + P_G(x)}] + Ex\sim p_{G}[log\frac{P_{G}(x)}{P_{data}(x) + P_G(x)}] =Ex∼pdata[logPdata(x)+PG(x)Pdata(x)]+Ex∼pG[logPdata(x)+PG(x)PG(x)]
= ∫ x P d a t a ( x ) l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) d x + ∫ x P G ( x ) l o g P G ( x ) P d a t a ( x ) + P G ( x ) d x = \int_xP_{data}(x)log\frac{P_{data}(x)}{P_{data}(x) + P_G(x)}dx + \int_xP_{G}(x)log\frac{P_{G}(x)}{P_{data}(x) + P_G(x)}dx =∫xPdata(x)logPdata(x)+PG(x)Pdata(x)dx+∫xPG(x)logPdata(x)+PG(x)PG(x)dx
= ∫ x P d a t a ( x ) l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) 2 ∗ 1 2 d x + ∫ x P G ( x ) l o g P G ( x ) P d a t a ( x ) + P G ( x ) 2 ∗ 1 2 d x = \int_xP_{data}(x)log\frac{P_{data}(x)}{\frac{P_{data}(x) + P_G(x)}{2}} * \frac{1}{2}dx + \int_xP_{G}(x)log\frac{P_{G}(x)}{\frac{P_{data}(x) + P_G(x)}{2}}* \frac{1}{2}dx =∫xPdata(x)log2Pdata(x)+PG(x)Pdata(x)∗21dx+∫xPG(x)log2Pdata(x)+PG(x)PG(x)∗21dx
= − 2 l o g 2 + ∫ x P d a t a ( x ) l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) 2 d x + ∫ x P G ( x ) l o g P G ( x ) P d a t a ( x ) + P G ( x ) 2 d x = -2log2 + \int_xP_{data}(x)log\frac{P_{data}(x)}{\frac{P_{data}(x) + P_G(x)}{2}}dx + \int_xP_{G}(x)log\frac{P_{G}(x)}{\frac{P_{data}(x) + P_G(x)}{2}}dx =−2log2+∫xPdata(x)log2Pdata(x)+PG(x)Pdata(x)dx+∫xPG(x)log2Pdata(x)+PG(x)PG(x)dx
这里需要提到J一个知识点:
-
J S D d i v e r g e n c e JSD divergence JSDdivergence 是 K L d i v e r g e n c e KL divergence KLdivergence 的对称平滑版本,表示了两个分布之间的差异,上式没有办法转化为 K L − d i v e r g e n c e KL-divergence KL−divergence.所以这里我们使用 J S D JSD JSD
-
J S D JSD JSD公式: J S D ( P ∣ ∣ Q ) = 1 2 D ( P ∣ ∣ M ) + 1 2 D ( Q ∣ ∣ M ) JSD(P||Q) = \frac{1}{2}D(P||M) + \frac{1}{2}D(Q||M) JSD(P∣∣Q)=21D(P∣∣M)+21D(Q∣∣M) M = 1 2 ( P + Q ) M = \frac{1}{2}(P+Q) M=21(P+Q)
上式 = − 2 l o g 2 + K L ( P d a t a ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) 2 ) + K L ( P G ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) 2 ) = -2log2 + KL(P_{data}(x)||\frac{P_{data}(x) + P_G(x)}{2}) + KL(P_{G}(x)||\frac{P_{data}(x) + P_G(x)}{2}) =−2log2+KL(Pdata(x)∣∣2Pdata(x)+PG(x))+KL(PG(x)∣∣2Pdata(x)+PG(x))
= − 2 l o g 2 + 2 J S D ( P ∣ ∣ Q ) = -2log2 + 2JSD(P||Q) =−2log2+2JSD(P∣∣Q)
在数学中可以证明(这里不详细赘述), J S D m a x = l o g 2 JSD_{max} = log2 JSDmax=log2
所以 V ( G , D ) V(G,D) V(G,D)最大值是0,最小值是 − 2 l o g 2 -2log2 −2log2;也就是说 J S D JSD JSD越大P和Q的差异越大, J S D JSD JSD越小P和Q的差异就越小
所以D网络最优的场景应当是:
m a x D ( G , D ) max_D(G,D) maxD(G,D)最小的情况,此时 P G = P d a t a P_G = P_{data} PG=Pdata也就是生成数据完全与真实数据相等
综上来看,GAN就是 θ G , θ D = a r g m i n G m a x D V ( G , D ) \theta_G,\;\theta_D = argmin_Gmax_DV(G,D) θG,θD=argminGmaxDV(G,D)的过程
3.GAN训练过程

这就是 GAN的整个训练过程,蓝色框是D网络的训练过程,红色框是G网络的训练过程
这里我们会注意到:
- D的 l o s s loss loss迭代过程中要趋向于最大,所以 θ d = θ d + η ∇ l o s s \theta_d = \theta_d + \eta \nabla loss θd=θd+η∇loss;
- G的 l o s s loss loss迭代过程中要趋向于最小,所以 θ d = θ d − η ∇ l o s s \theta_d = \theta_d - \eta \nabla loss θd=θd−η∇loss;
- 可以看出来一般情况下D网络每迭代多次,G网络仅迭代一次;主要原因G,D的反馈传播均依赖于D网络,G网络迭代一次,会让D网络的 l o s s loss loss较之前下降,所以D网络要调节多次使得D网络的 l o s s loss loss尽可能的大;
- D的 l o s s loss loss可以看做对D网络而言分辨 r e a l real real数据和 f a k e fake fake数据的损失,所以要最大化真实数据的期望 l o g D ( x ) logD(x) logD(x),同时最小化生成数据期望 l o g D ( x ∼ ) logD(x^\sim) logD(x∼),也就是最大化 l o g ( 1 − D ( x ∼ ) ) log(1-D(x^\sim)) log(1−D(x∼)),而 l o s s D = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] loss_D = E_{x\sim p_{data}}[log(D(x))] + E_{x^\sim\sim p_{G}}[log(1- D(x^\sim))] lossD=Ex∼pdata[log(D(x))]+Ex∼∼pG[log(1−D(x∼))],所以D的期望是最大化 l o s s loss loss
- 而G网络的 l o s s G = E x ∼ ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] loss_G = E_{x^\sim\sim p_{G}}[log(1- D(x^\sim))] lossG=Ex∼∼pG[log(1−D(x∼))],G网络的输入是没有 P d a t a P_{data} Pdata作为 i n p u t input input,所以G网络仅保留V的后半部分,也可以看做一个类别的二分类器.是计算生成图片与目标图片的距离;所以越小越好
4.GAN的优化
我们先来看下G网络loss的图像:
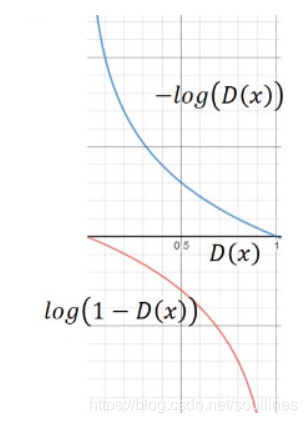
可以看到 原始的G网络的 l o s s = l o g ( 1 − D ( x ) ) loss = log(1-D(x)) loss=log(1−D(x)),首先我们知道我们初始化一般从0开始,而这个 l o s s loss loss在0附近梯度较小,从0->1,梯度越来越大;这显然不符合我们的习惯,我们期望的模型迭代应当是初期梯度较大,随着 e p o c h epoch epoch的增加梯度越来越小,这样有利于函数的收敛
所以我们可以把G网络的 l o s s loss loss函数转化为 − l o g ( D ( x ) ) -log(D(x)) −log(D(x))
以上是GAN基础学习中的一些感悟和整理,感谢阅读
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象