CAFFE源码学习笔记之内积层-inner_product_layer_caffe innerproduct-程序员宅基地
技术标签: CAFFE源码
一、前言
内积层实际就是全连接。经过之前的卷积层、池化层和非线性变换层,样本已经被映射到隐藏层的特征空间之中,而全连接层就是将学习到的特征又映射到样本分类空间。虽然已经出现了全局池化可以替代全连接,但是仍然不能说全连接就不能用了。
二、源码分析
1、成员变量
全连接的输入时一个M*K的矩阵,权重是K*N的矩阵,所以输出是一个M*N的矩阵
int M_;//num_input
int K_;//C*H*W
int N_;//N_ = num_output
bool bias_term_;
Blob<Dtype> bias_multiplier_;
bool transpose_; ///< if true, assume transposed weights```
2、layersetup
权重是K*N的矩阵:(C*H*W)*num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num_output = this->layer_param_.inner_product_param().num_output();//输出
bias_term_ = this->layer_param_.inner_product_param().bias_term();
transpose_ = this->layer_param_.inner_product_param().transpose();
N_ = num_output;
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
// Dimensions starting from "axis" are "flattened" into a single
// length K_ vector. For example, if bottom[0]'s shape is (N, C, H, W),
// and axis == 1, N inner products with dimension CHW are performed.
K_ = bottom[0]->count(axis);
// Check if we need to set up the weights
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// Initialize the weights
vector<int> weight_shape(2);
if (transpose_) {
weight_shape[0] = K_;
weight_shape[1] = N_;
} else {
weight_shape[0] = N_;
weight_shape[1] = K_;
}
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// If necessary, intiialize and fill the bias term
if (bias_term_) {
vector<int> bias_shape(1, N_);
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
} // parameter initialization
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
3、reshape
输入是一个M*K的矩阵:num_input*(C*H*W)
经过转换:top_shape.resize(axis + 1)
输出是M*N的矩阵:
num_input∗num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Figure out the dimensions
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
const int new_K = bottom[0]->count(axis);
CHECK_EQ(K_, new_K)
<< "Input size incompatible with inner product parameters.";
// The first "axis" dimensions are independent inner products; the total
// number of these is M_, the product over these dimensions.
M_ = bottom[0]->count(0, axis);//num_input
// The top shape will be the bottom shape with the flattened axes dropped,
// and replaced by a single axis with dimension num_output (N_).
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1);
top_shape[axis] = N_;
top[0]->Reshape(top_shape);
// Set up the bias multiplier
if (bias_term_) {
vector<int> bias_shape(1, M_);
bias_multiplier_.Reshape(bias_shape);
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data());
}
}
3、前向计算
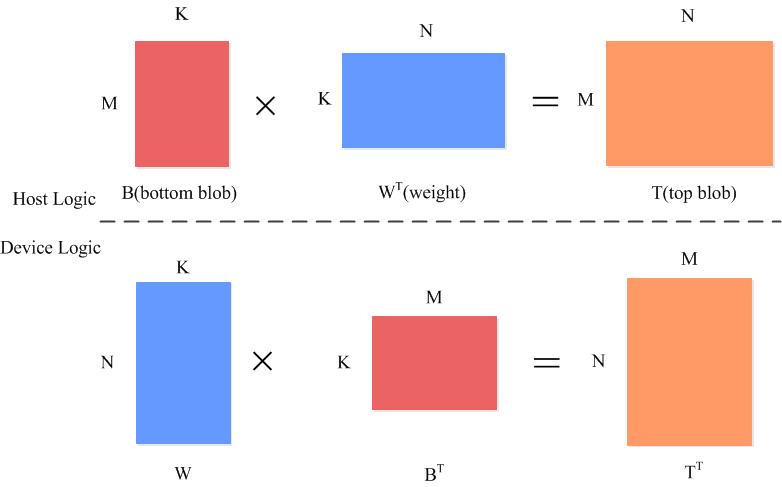
直接调用矩阵内积函数caffe_gpu_gemm
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
const Dtype* weight = this->blobs_[0]->gpu_data();
if (M_ == 1) {
caffe_gpu_gemv<Dtype>(CblasNoTrans, N_, K_, (Dtype)1.,weight, bottom_data, (Dtype)0., top_data);//这个是向量内积函数
if (bias_term_)
caffe_gpu_axpy<Dtype>(N_, bias_multiplier_.cpu_data()[0],this->blobs_[1]->gpu_data(), top_data);
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans,transpose_ ? CblasNoTrans : CblasTrans,M_, N_, K_, (Dtype)1.,bottom_data, weight, (Dtype)0., top_data);
if (bias_term_)
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,bias_multiplier_.gpu_data(),this->blobs_[1]->gpu_data(), (Dtype)1., top_data);
}
}4、反向传播
对参数求偏导
∂loss∂wkj=∂loss∂zk∗∂zk∂wkj=∂loss∂zk∗uj
转换成向量:
∂loss∂Wj==∂loss∂Z∗uj
转换成矩阵:
∂loss∂W==∂loss∂ZT∗U
即 layer_blobs_=topdiff∗bottom_data
对输出求偏导:
公式:
∂loss∂uj=∑n=Mk∂loss∂zk∗∂zk∂uj
转化为向量
∂loss∂UT=∂loss∂ZT∗W
M为需要分的类别数
转换成矩阵的形式:
∂loss∂U=∂loss∂Z∗W
即
bottom_diff=top_diff∗layer_blobs_
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (this->param_propagate_down_[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
const Dtype* bottom_data = bottom[0]->gpu_data();
// Gradient with respect to weight
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
K_, N_, M_,
(Dtype)1., bottom_data, top_diff,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
N_, K_, M_,
(Dtype)1., top_diff, bottom_data,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
}
}
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bias
caffe_gpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff,
bias_multiplier_.gpu_data(), (Dtype)1.,
this->blobs_[1]->mutable_gpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bottom data
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
}
}
}智能推荐
程序员的办公桌上,都出现过哪些神奇的玩意儿 ~_程序员展示刀,产品经理展示枪-程序员宅基地
文章浏览阅读1.9w次,点赞113次,收藏57次。我要买这些东西,然后震惊整个办公室_程序员展示刀,产品经理展示枪
霍尔信号、编码器信号与电机转向-程序员宅基地
文章浏览阅读1.6w次,点赞7次,收藏63次。霍尔信号、编码器信号与电机转向从电机出轴方向看去,电机轴逆时针转动,霍尔信号的序列为编码器信号的序列为将霍尔信号按照H3 H2 H1的顺序组成三位二进制数,则霍尔信号翻译成状态为以120°放置霍尔为例如不给电机加电,使用示波器测量三个霍尔信号和电机三相反电动势,按照上面所说的方向用手转动电机得到下图① H1的上升沿对应电机q轴与H1位置电角度夹角为0°,..._霍尔信号
个人微信淘宝客返利机器人搭建教程_怎么自己制作返利机器人-程序员宅基地
文章浏览阅读7.1k次,点赞5次,收藏36次。个人微信淘宝客返利机器人搭建一篇教程全搞定天猫淘宝有优惠券和返利,仅天猫淘宝每年返利几十亿,你知道么?技巧分享:在天猫淘宝京东拼多多上挑选好产品后,按住标题文字后“复制链接”,把复制的淘口令或链接发给机器人,复制机器人返回优惠券口令或链接,再打开天猫或淘宝就能领取优惠券啦下面教你如何搭建一个类似阿可查券返利机器人搭建查券返利机器人前提条件1、注册微信公众号(订阅号、服务号皆可)2、开通阿里妈妈、京东联盟、拼多多联盟一、注册微信公众号https://mp.weixin.qq.com/cgi-b_怎么自己制作返利机器人
【团队技术知识分享 一】技术分享规范指南-程序员宅基地
文章浏览阅读2.1k次,点赞2次,收藏5次。技术分享时应秉持的基本原则:应有团队和个人、奉献者(统筹人)的概念,同时匹配团队激励、个人激励和最佳奉献者激励;团队应该打开工作内容边界,成员应该来自各内容方向;评分标准不应该过于模糊,否则没有意义,应由客观的基础分值以及分团队的主观综合结论得出。应有心愿单激励机制,促进大家共同聚焦到感兴趣的事情上;选题应有规范和框架,具体到某个小类,这样收获才有目标性,发布分享主题时大家才能快速判断是否是自己感兴趣的;流程和分享的模版应该有固定范式,避免随意的格式导致随意的内容,评分也应该部分参考于此;参会原则,应有_技术分享
自动化测试 ——自动卸载软件_msiexec.exe /x-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏9次。在平常的测试工作中,经常要安装软件,卸载软件, 即繁琐又累。 安装和卸载完全可以做成自动化。 安装软件我们可以通过自动化框架,自动点击Next,来自动安装。 卸载软件我们可以通过msiexec命令行工具自动化卸载软件_msiexec.exe /x
【Python】操作MySQL_python mysql表操作-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏18次。在 MySQL 中,存储过程或函数中的查询有时会返回多条记录,而使用简单的 SELECT 语句,没有办法得到第一行、下一行或前十行的数据,这时可以使用游标来逐条读取查询结果集中的记录。游标在部分资料中也被称为光标。_python mysql表操作
随便推点
JAVA反射机制原理及应用和类加载详解-程序员宅基地
文章浏览阅读549次,点赞30次,收藏9次。我们前面学习都有一个概念,被private封装的资源只能类内部访问,外部是不行的,但这个规定被反射赤裸裸的打破了。反射就像一面镜子,它可以清楚看到类的完整结构信息,可以在运行时动态获取类的信息,创建对象以及调用对象的属性和方法。
Linux-LVM与磁盘配额-程序员宅基地
文章浏览阅读1.1k次,点赞35次,收藏12次。Logical Volume Manager,逻辑卷管理能够在保持现有数据不变的情况下动态调整磁盘容量,从而提高磁盘管理的灵活性/boot分区用于存放引导文件,不能基于LVM创建PV(物理卷):基于硬盘或分区设备创建而来,生成N多个PE,PE默认大小4M物理卷是LVM机制的基本存储设备,通常对应为一个普通分区或整个硬盘。创建物理卷时,会在分区或硬盘的头部创建一个保留区块,用于记录 LVM 的属性,并把存储空间分割成默认大小为 4MB 的基本单元(PE),从而构成物理卷。
车充产品UL2089安规测试项目介绍-程序员宅基地
文章浏览阅读379次,点赞7次,收藏10次。4、Dielecteic voltage-withstand test 介电耐压试验。1、Maximum output voltage test 输出电压试验。6、Resistance to crushing test 抗压碎试验。8、Push-back relief test 阻力缓解试验。7、Strain relief test 应变消除试验。2、Power input test 功率输入试验。3、Temperature test 高低温试验。5、Abnormal test 故障试验。
IMX6ULL系统移植篇-系统烧写原理说明_正点原子 imx6ull nand 烧录-程序员宅基地
文章浏览阅读535次。镜像烧写说明_正点原子 imx6ull nand 烧录
Gradle配置阿里云Maven镜像仓库地址_gradle 配置阿里镜像-程序员宅基地
文章浏览阅读1.8k次。搭建maven本地仓库参考博客_gradle 配置阿里镜像
SSRF服务器端请求伪造-程序员宅基地
文章浏览阅读1.7k次,点赞2次,收藏3次。SSRF服务器端请求伪造SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造恶意数据,形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统,正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统 SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制,比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等SSRF常见场景_ssrf服务器端请求伪造