大数据基础hadoop / hive / hbase_hadoop、hbase、hive 原理-程序员宅基地
技术标签: 大数据
前言
大数据之hadoop / hive / hbase 的区别是什么?
1. hadoop
它是一个分布式计算+分布式文件系统,前者其实就是 MapReduce,后者是 HDFS 。后者可以独立运行,前者可以选择性使用,也可以不使用
2. hive
通俗的说是一个数据仓库,仓库中的数据是被hdfs管理的数据文件,它支持类似sql语句的功能,你可以通过该语句完成分布式环境下的计算功能,hive会把语句转换成MapReduce,然后交给hadoop执行。这里的计算,仅限于查找和分析,而不是更新、增加和删除。
它的优势是对历史数据进行处理,用时下流行的说法是离线计算,因为它的底层是MapReduce,MapReduce在实时计算上性能很差。它的做法是把数据文件加载进来作为一个hive表(或者外部表),让你觉得你的sql操作的是传统的表。
3. hbase
通俗的说,hbase的作用类似于数据库,传统数据库管理的是集中的本地数据文件,而hbase基于hdfs实现对分布式数据文件的管理,比如增删改查。也就是说,hbase只是利用hadoop的hdfs帮助其管理数据的持久化文件(HFile),它跟MapReduce没任何关系。
hbase的优势在于实时计算,所有实时数据都直接存入hbase中,客户端通过API直接访问hbase,实现实时计算。由于它使用的是nosql,或者说是列式结构,从而提高了查找性能,使其能运用于大数据场景,这是它跟MapReduce的区别。
总结:
hadoop是hive和hbase的基础,hive依赖hadoop,而hbase仅依赖hadoop的hdfs模块。
hive适用于离线数据的分析,操作的是通用格式的(如通用的日志文件)、被hadoop管理的数据文件,它支持类sql,比编写MapReduce的java代码来的更加方便,它的定位是数据仓库,存储和分析历史数据。
hbase适用于实时计算,采用列式结构的nosql,操作的是自己生成的特殊格式的HFile、被hadoop管理的数据文件,它的定位是数据库,或者叫DBMS。
hive可以直接操作hdfs中的文件作为它的表的数据,也可以使用hbase数据库作为它的表。
一、HADOOP基础
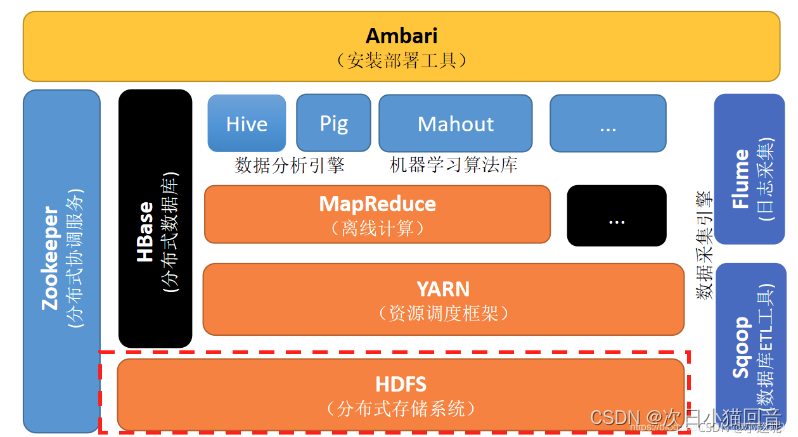
1.大数据基础组件HDFS -分布式存储
参考:(超详细)大数据Hadoop之HDFS组件_[root@hadoop100 sbin]# start-dfs.sh starting namen-程序员宅基地
HDFS全称为Hadoop Distributed File System,很简单Hadoop的分布式文件存储系统。
定义: HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务 器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭 之后就不需要改变。
HDFS 的组成节点:
HDFS是经典的Master和Slave架构,每一个HDFS集群包括一个NameNode和多个DataNode。
Master-Slave架构常见于分布式系统或数据库管理系统。Master-Slave架构具有可伸缩性和容错性,能够处理更多并发请求,并在主节点故障时通过从节点继续提供服务,提高系统的可用性和可靠性。
主节点(Master)负责整个系统的协调和管理,接收并分配任务给从节点(Slave)。
从节点执行主节点分配的任务,可能包括读取、计算或存储数据。在数据库系统中,从节点还负责数据的复制和备份,以提高系统的可用性和容错性。
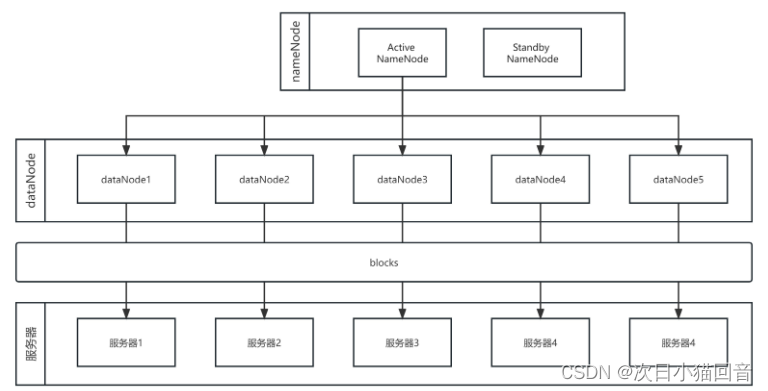
NameNode管理所有文件的元数据信息,并且负责与客户端交互。
DataNode负责管理存储在该节点上的文件。每一个上传到HDFS的文件都会被划分为一个或多个数据块,这些数据块根据HDFS集群的数据备份策略被分配到不同的DataNode上,位置信息交由NameNode统一管理。
Client客户端
1): 文件切分。文件上传HDFS时,Client将文件切分成一个一个的Block,然后进行上传;
2): 与NameNode交互,获取文件的位置信息;
3): 与DataNode交互,读取或者写入数据;
4): Client提供一些命令来管理HDFS,比如NameNode格式化;
5): Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
NameNode
用于管理文件系统的命名空间、维护文件系统的目录结构树以及元数据信息,记录写入的每个数据块(Block)与其归属文件的对应关系,处理客户端读写请求。
此信息以命名空间镜像(FSImage)和编辑日志(EditsLog)两种形式持久化在本地磁盘中。
命名空间镜像(FSImage)是文件系统的快照,包含所有文件、目录和属性信息,存储在本地磁盘上。系统启动时加载到内存,然后应用编辑日志(EditsLog)中的变更,以恢复到最新状态。编辑日志记录每次操作,如创建、删除、重命名等,顺序追加到文件中,用于恢复文件系统的变更历史。
DataNode
DataNode是文件的实际存放位置。
DataNode会根据NameNode或Client的指令来存储或者提供数据块,并且定期的向NameNode汇报该DataNode存储的数据块信息。
SecondaryNameNode节点(Standby NameNode):
并非NameNode的热备。当NameNode挂掉的时候,它并不 能马上替换NameNode并提供服务。
(在计算机系统中,热备Hot Standby是指在主要组件或设备发生故障时,系统能够迅速切换到备用组件或设备上,以继续提供服务。)
1): 定期把NameNode的 fsimage 和 edits 下载到本地,再将它们加载到内存并进行合并,最后把合并后新的 fsimage 返回NameNode
2): 做备份
3): 防止edits过大
4): 在紧急情况下,可辅助恢复NameNode。
Blocks
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数 ( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
HDFS将文件拆分成128 MB大小的数据块进行存储,这些Block可能存储在不同的节点上。HDFS可以存储更大的单个文件,甚至超过任何一个磁盘所能容纳的大小。一个Block默认存储3个副本(EMR Core节点如果使用云盘,则为2副本),以Block为粒度将副本存储在多个节点上。
为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置; (2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开 始位置所需的时间。导致程序在处理这块数据时,会非常慢。 总结:HDFS块的大小设置主要取决于磁盘传输速率。
2.MapReduce -离线计算
MapReduce 是一种编程模型,用于大规模数据集的并行处理。它由 Google 在 2004 年提出,并被广泛应用于大数据处理领域。MapReduce 的核心思想是将复杂的数据处理任务分解为两个主要的步骤:Map(映射)和 Reduce(归约),通过这两个步骤,可以在大量计算节点上分布式地处理和生成大数据集的结果。
Map 阶段:
在 Map 阶段,输入数据被分割成独立的块,这些块由 Map 函数处理。Map 函数对输入数据的每个块独立地执行操作,并将结果输出为一系列的键值对(key-value pairs)。这些键值对是中间结果,它们可以跨越网络传输到下一个阶段。
Reduce 阶段
Reduce 阶段跟随 Map 阶段,它接收来自 Map 阶段的中间结果。Reduce 函数对具有相同键(key)的值(value)进行合并操作,从而生成最终的输出。这个过程可以看作是对中间结果的一种归约(reduce),因此得名 Reduce。Reduce 阶段的输出是最终的处理结果,通常是按照键排序的。
MapReduce 的优势
- 可扩展性:MapReduce 模型可以轻松地扩展到处理 PB 级别的数据集。
- 容错性:MapReduce 框架能够自动处理节点故障,重新调度任务,并确保数据处理的完整性。
- 简化并行计算:开发者只需关注 Map 和 Reduce 函数的编写,而无需管理底层的并行计算和数据分布。
- 灵活性:MapReduce 适用于各种类型的数据处理任务,包括但不限于计数、排序、索引等。
MapReduce 的应用
MapReduce 模型最初是为处理搜索引擎的索引数据而设计的,但后来被广泛应用于各种大数据处理场景,如日志分析、基因组学研究、社交网络分析等。
结论
MapReduce 的思想是通过将大数据处理任务分解为简单的 Map 和 Reduce 操作,利用分布式计算资源并行处理数据,从而实现高效、可扩展和容错的数据处理能力。尽管 MapReduce 在某些情况下可能不如其他新兴的大数据处理框架(如 Apache Spark)灵活或高效,但它在大数据处理历史上仍然占有重要地位,并且为后续技术的发展奠定了基础。
3.Yarn - 资源调度
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台。
通过 ResourceManager、NodeManager、应用程序主管RM和容器Container之间的协作,实现灵活高效的资源管理和任务调度。
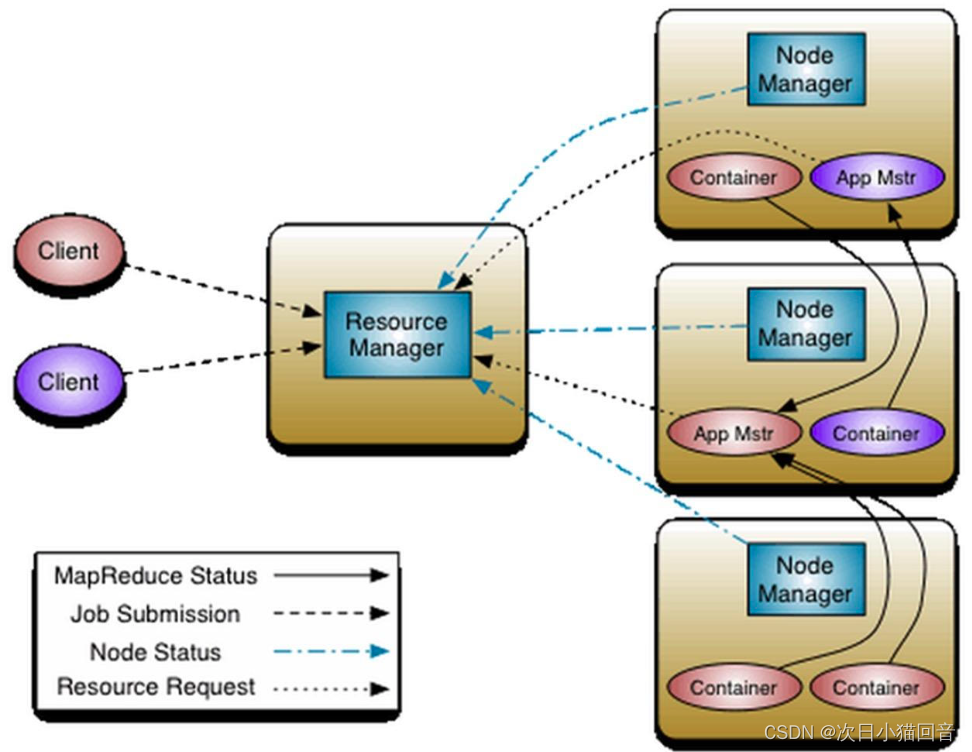
Yarn组成
ResourceManager(RM)资源管理器
ResourceManager 是整个 YARN 系统的主要组件,负责集群资源的管理和分配。它包含两个主要组件:调度器(Scheduler)和应用程序管理器(ApplicationManager)。
- 处理客户端请求;
- 监控NodeManager;
- 启动或监控ApplicationMaster;
- 资源的分配与调度
NodeManager(NM)节点管理器
NodeManager 是运行在集群节点上的代理,负责管理单个节点上的资源。
- 管理单个节点上的资源;
- 接受来自ResouceManager的命令;
- 启动/停止容器(Container)
- 处理来自ApplicationMaster的命令。
ApplicationMaster(AM)应用程序主管
每个在 YARN 上运行的应用程序都会有一个对应的 ApplicationMaster。它负责协调和管理应用程序的执行。一旦 ResourceManager 分配了资源,ApplicationMaster 就会与 NodeManager 通信,并向其请求启动容器来执行特定的任务。它还负责监控任务的执行进度、处理任务失败和重新启动任务等。
- 负责数据的切分;
- 为应用程序申请资源并分配给内部的任务;
- 任务的监控与容错。
Container容器
Container是yarn中的资源抽象,它封装了某个节点上的维度资源,如:内存、CPU、硬盘和网络等。每个容器由 NodeManager 在集群节点上启动和管理,它可以运行一个应用程序的特定任务或进程。
Yarn基本流程
- 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序
- ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7
- ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源
- 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务
- NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
- 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态
- 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己
二、Hive
参考:大数据之Hadoop的数据仓库Hive - 知乎 (zhihu.com)(超详细)大数据技术之Hive的实战_hive实战-程序员宅基地
Hive是基于Hadoop的数据仓库工具,由Facebook开发,在某种程度上可以看成是用户编程接口,本身并不存储和处理数据,依赖于HDFS存储数据,依赖MR处理数据,执行程序运行在Yarn上。有类SQL语言HiveQL,不完全支持SQL标准,如,不支持更新操作、索引和事务,其子查询和连接操作也存在很多限制。
1.Hive原理
Hive的运行原理是将查询转换为一系列MapReduce任务,在Hadoop集群上并行执行这些任务,并将结果返回给用户。这种并行处理的方式使得Hive能够高效地处理大规模的数据集。
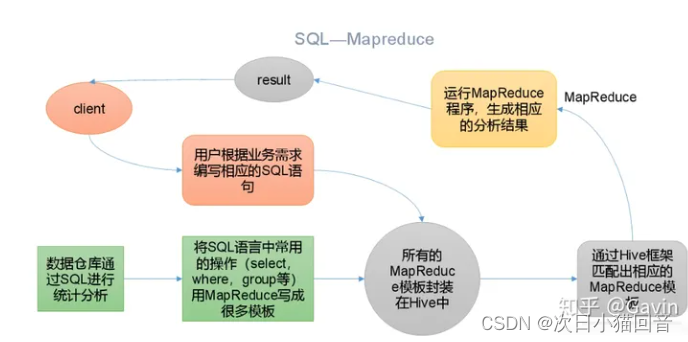
1. 元数据存储:Hive使用一个元数据存储来管理Hadoop文件系统中的数据。元数据存储包括表、分区、列和数据位置的信息。Hive使用这些元数据来解析和优化查询。
2. 查询解析和优化:当用户提交一个查询时,Hive首先会解析查询语句,并根据元数据来确定查询涉及的表、列和分区。然后,Hive会对查询进行优化,以尽量减少查询的开销。优化过程包括选择合适的查询计划、重写查询和推测执行等。
3. 查询执行:在查询执行阶段,Hive将查询转换为一系列Hadoop MapReduce任务。这些任务由Hive的查询执行引擎生成,并在Hadoop集群上运行。每个任务负责处理数据的一部分,并生成中间结果。
4. 结果返回:一旦所有的MapReduce任务完成,Hive会收集和合并中间结果,并将最终结果返回给用户。如果查询需要将结果保存到Hadoop文件系统中,Hive还会将结果写入指定的目录。
2.Hive的应用场景
Hive构建在Hadoop文件系统之上,Hive不提供实时的查询和基于行级的数据更新操作,不适合需要低延迟的应用,如联机事务处理(On-line Transaction Processing,OLTP)相关应用。
Hive适用于联机分析处理(On-Line Analytical Processing,OLAP),应用场景如图所示:

Hive是用于查询分布式大型数据集的数据仓库,相比于传统数据仓库,在大数据的查询上有其独特的优势,但同时也牺牲了一部分性能。
Hive与传统数据仓库的区别:
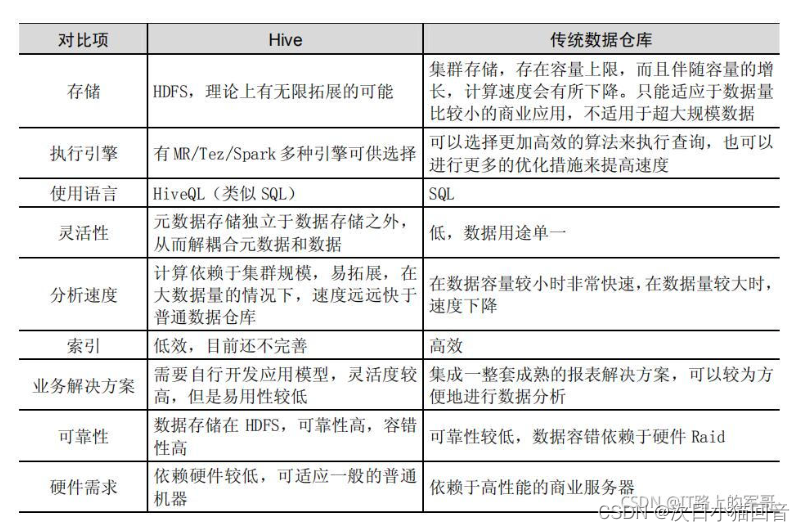
3.Hive结构

Hive主要由以下三个模块组成:
用户接口模块,含CLI、HWI、JDBC、Thrift Server等,用来实现对Hive的访问。CLI是Hive自带的命令行界面;HWI是Hive的一个简单网页界面;JDBC、ODBC以及Thrift Server可向用户提供进行编程的接口,其中Thrift Server是基于Thrift软件框架开发的,提供Hive的RPC通信接口。
驱动模块(Driver),含编译器、优化器、执行器等,负责把HiveQL语句转换成一系列MR作业,所有命令和查询都会进入驱动模块,通过该模块的解析变异,对计算过程进行优化,然后按照指定的步骤执行。
元数据存储模块(Metastore),是一个独立的关系型数据库,通常与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的Derby数据库实例。此模块主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。
4.Hive的数据存储模型
Hive主要包括三类数据模型:表(Table)、分区(Partition)和桶(Bucket)。
1)Hive的分区和分桶
Hive以数据库表的形式组织数据,便于高效查询分析。针对大数据集,Hive会对数据进行分区处理,例如按日期、地区等列值进行分区。分区以目录形式存在,提高了局部数据查询的效率。此外,Hive还可以将表或分区进一步组织为桶,桶是比分区更细的数据划分方式,每个桶是一个文件。用户可指定桶的个数,Hive根据哈希值将数据划分到不同桶中。分桶提供了额外的结构,在处理某些查询时可以提高效率,例如join操作和表的合并,使数据抽样更加高效。
2)Hive的托管表和外部表
Hive中的表分为两种:托管表(内部表)和外部表。托管表由Hive管理数据,而外部表仅记录数据路径,不移动数据至仓库目录。删除托管表会同时删除元数据和数据,而删除外部表只会删除元数据,保留数据在仓库外部。
选择使用哪种表取决于数据处理需求:托管表适用于完全由Hive处理的数据集,而外部表适用于需要与其他工具共享数据或组织成不同表的情况。
5.Hive在企业大数据分析平台中的应用
企业中一种常见的大数据分析平台部署框架:

Hive和Pig用于报表中心,Hive用于分析报表,Pig用于报表中数据的转换工作。
HBase用于在线业务,HDFS不支持随机读写操作,而HBase正是为此开发,可较好地支持实时访问数据。
Mahout提供一些可扩展的机器学习领域的经典算法实现,用于创建商务智能(BI)应用程序。
三、Hbase
参考:我终于看懂了HBase,太不容易了... - 知乎 (zhihu.com)

Apache HBase 是在HDFS的基础之上构建的 Hadoop 数据库,一个分布式、可伸缩的大数据存储。
HDFS是文件系统,而HBase是数据库。「可以把HBase当做是MySQL,把HDFS当做是硬盘。HBase只是一个NoSQL数据库,把数据存在HDFS上」。
数据库是一个以某种有组织的方式存储的数据集合。
1.为什么要用Hbase?
HBase可以以低成本来存储海量的数据并且支持高并发随机写和实时查询。
存储数据的”结构“可以地非常灵活,是一个NoSQL数据库
2.Hbase架构

1、Client客户端,它提供了访问HBase的接口,并且维护了对应的cache来加速HBase的访问。
2、Zookeeper存储HBase的元数据(meta表),无论是读还是写数据,都是去Zookeeper里边拿到meta元数据告诉给客户端去哪台机器读写数据
3、HRegionServer它是处理客户端的读写请求,负责与HDFS底层交互,是真正干活的节点。
总结大致的流程就是:client请求到Zookeeper,然后Zookeeper返回HRegionServer地址给client,client得到Zookeeper返回的地址去请求HRegionServer,HRegionServer读写数据后返回给client。

HRegionServer
- HRegionServer是真正干活的机器(用于与hdfs交互),我们HBase表用RowKey来横向切分表
- HRegion里边会有多个Store,每个Store其实就是一个列族的数据(所以我们可以说HBase是基于列族存储的)
- Store里边有Men Store和StoreFile(HFile),其实就是先走一层内存,然后再刷到磁盘的结构
Store
•Store是Region服务器的核心
•多个StoreFile合并成一个
•单个StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region
HLog
Zookeeper实时监测Region服务器状态。
一旦某服务器故障,Zookeeper通知Master。Master处理故障服务器上的遗留HLog文件,这些文件包含多个Region对象的日志。
系统拆分HLog数据,按照Region对象归类,发送给相应服务器。服务器收到分配的Region对象和相关日志,重新操作日志,将数据写入MemStore缓存,再刷新到磁盘文件,完成数据恢复。
共用日志提升写操作性能,但恢复时需分拆日志。
智能推荐
Java毕业设计 基于SpringBoot vue城镇保障性住房管理系统
首页 图片轮播 房源信息 房源详情 申请房源 公示信息 公示详情 登录注册 个人中心 留言反馈后台管理 登录 个人中心 修改密码 个人信息 用户管理 房屋类型 房源信息管理 房源申请管理 住房分配管理 留言板管理 轮播图管理 公示信息管理角色:用户 管理员大家可。
xhadmin多应用SaaS框架之智慧驾校H5+小程序v1.1.5正式发布!
xhadmin 是一套基于最新技术的研发的多应用 Saas 框架,支持在线升级和安装模块及模板,拥有良好的开发框架、成熟稳定的技术解决方案、提供丰富的扩展功能。为开发者赋能,助力企业发展、国家富强,致力于打造最受欢迎的多应用 Saas 系统。
【Vue3源码学习】— CH3.4 baseCreateRenderer 详解
在 baseCreateRenderer 中,定义了多种方法,例如 patch、mountComponent、updateComponent 等,这些方法各自承担不同的渲染任务。这些定义不直接执行任何操作,而是为后续的渲染流程提供必要的工具和函数。baseCreateRenderer 更像是一个配置和定义渲染器行为的场所,而具体的渲染逻辑则是在实际调用 render 方法时,按需执行这些预定义的方法。这样的设计不仅清晰地分离了配置与执行,也使得 Vue 渲染器可以灵活地适应不同的渲染需求和环境。
ROS1快速入门学习笔记 - 10服务数据的定义和使用
三个横线作为一个区分,上面是request,下面是response;创建完之后如下所示。
017、Python+fastapi,第一个Python项目走向第17步:ubuntu24.04 无界面服务器版下安装nvidia显卡驱动
新的ubuntu24.04正式版发布了,前段时间玩了下桌面版,感觉还行,先安装一个服务器无界面版本吧安装时有一个openssh选择安装,要不然就不能ssh远程,我就是没选,后来重新安装ssh。另外一个就是安装过程中静态ip设置下在etc/netplan 文件夹下,有一个yaml文件,我的是50-cloud-init.yaml,先用ip a看看network:ethernets:enp3s0:routes:version: 2。
不是阿里P8级大佬,岂能错过这篇MySQL运维内参?啃透涨薪so easy-程序员宅基地
文章浏览阅读176次。写在前面MySQL被设计为一个可移植的数据库,几乎在当前所有系统上都能运行,如Linux、Solaris、 FreeBSD、 Mac和Windows。尽管各平台在底层(如线程)实现方面都各有不同,但是MySQL基本上能保证在各平台上的物理体系结构的一致性。因此,用户应该能很好地理解MySQL数据库在所有这些平台上是如何运作的。由于工作的缘故,笔者的大部分时间需要与开发人员进行数据库方面的沟通,并对他们进行培训。不论他们是DBA,还是开发人员,似乎都对MySQL的体系结构了解得不够透彻。很多人喜欢把M_mysql运维内参
随便推点
K210与STM32之间的通信_k210与stm32通信-程序员宅基地
文章浏览阅读5.1k次,点赞2次,收藏70次。K210与STM32之间使用串口进行通信_k210与stm32通信
OpenHarmony语言基础类库【@ohos.util.List (线性容器List)】
而网上有关鸿蒙的开发资料非常的少,假如你想学好鸿蒙的应用开发与系统底层开发。你可以参考这份资料,少走很多弯路,节省没必要的麻烦。由两位前阿里高级研发工程师联合打造的《鸿蒙NEXT星河版OpenHarmony开发文档》里面内容包含了(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、音频、视频、WebGL、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、Harmony南向开发、鸿蒙项目实战等等)鸿蒙(Harmony NEXT)技术知识点。
[自学笔记] ESP32-C3 Micropython初次配置
2、本次测试了两款IDE,分别是"thonny-4.1.4.exe"和"uPyCraft-v1.0.exe"。Thonny支持中文及多语言。而uPyCraft-v1.0只支持英文语言。因此入门时选用了Thonny作为IDE。(注:1、测试过程中IDE正常连接ESP32C3简约版的虚拟串口。不受简约版无串口芯片的影响。
初识Electron,创建桌面应用
古有匈奴犯汉,晋室不纲,铁木夺宋,虏清入关,神舟陆沉二百年有余,中国之见灭于满清初非满人能灭之,能有之也因有汉奸以作虎怅,残同胞媚异种,始有吴三桂洪承畴,继有曾国藩袁世凯以为厉。今率堂堂之师,征讨汉贼袁氏筑共和之体,或免于我子子孙孙被异族奴役。---- 《讨汉贼袁世凯檄文》- DOMContentLoaded事件:此时浏览器已经完全加载了HTML文件,并且DOM树已经生成好了。- Load事件:此时浏览器已经将所有的资源都加载完毕,可以正确读取页面中的资源。补充知识:Electron 生命周期。
Xcode 15构建问题
将ENABLE_USER_SCRIPT_SANDBOXING设为“no”即可!
OpenVINO应用案例:部署YOLO模型到边缘计算摄像头_openvino yolo-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏23次。一、实现路径通过OpenVINO部署YOLO模型到边缘计算摄像头,其实现路径为:训练(YOLO)->转换(OpenVINO)->部署运行(OpenNCC)。二、具体步骤1、训练YOLO模型1.1 安装环境依赖有关安装详情请参阅 https://github.com/AlexeyAB/darknet#requirements-for-windows-linux-and-macos 。1.2 编译训练工具git clone https://github.com/AlexeyAB/da_openvino yolo