GNN在文本分类上的应用 | (3) TensorGCN_gnn文本分类-程序员宅基地
技术标签: 多图融合 图间传播 GNN在文本分类上的应用 TensorGCN
本篇博客是对论文《Tensor Graph Convolutional Networks for Text Classification》的阅读笔记。
图神经网络(GNN,Graph Neural Networks)用于图结构数据的深度学习架构,具有强大的表征建模能力,将端到端学习与归纳推理相结合,业界普遍认为其有望解决深度学习无法处理的因果推理、可解释性等一系列瓶颈问题。图神经网络在文本分类也有深入的应用,在本专栏第一篇博客中曾介绍了一篇AAA2019的论文TextGCN,本篇博客介绍的AAAI2020论文TensorGCN更近一步,TensorGCN在TextGCN基础上做了改进,进一步提高了文本分类的性能。TextGCN把语料库/数据集的所有文档和单词作为节点构建一个基于序列的异构图,TensorGCN同样把语料库/数据集的所有文档和单词作为节点分别构建基于语义、句法和序列的三个异构图,形成一个文本图张量,Tensor由此得名,另一个不同是,既然是多图处理,自然除了基本的各个图内传播,还有就是图间传播,整合以及协调各个异构图的信息,具体细节会在下文详细阐述。
目录
1. 摘要
本文研究了基于图神经网络在文本分类问题中的应用,并提出了一种新的框架TensorGCN(张量图卷积网络)。首先构造一个文本图张量来描述语义、句法和序列上下文信息。然后,对文本图张量进行两种传播学习。第一种是图内传播,用于在单个图中聚合来自邻域节点的信息。第二种是图间传播,用于协调图之间的异构信息。在基准数据集上进行的大量的实验表明了该框架的有效性。我们提出的TensorGCN为协调和集成来自不同类型图的异构信息提供了一种有效的方法。
2. 介绍
文本分类是自然语言处理领域最基本的任务之一。它可以简单地表示为X→y,其中X是一段文本(例如句子/文档),是对应的标签向量。文本表示学习是文本分类问题的第一步,也是必不可少的一步。与之前基于手工特征(词袋特征、稀疏词汇特征)等方法不同,现有的文本分类方法主要分为基于序列的学习模型与基于图的学习模型。基于序列的学习模型利用CNN或RNN从局部连续单词序列中捕获文本特征;基于图的学习模型根据单词之间的顺序/序列上下文关系构建文本图(TextGCN),然后采用图卷积网络(GCN)对文本图进行学习。
但是在文本分类任务中应该考虑更多的语境信息,比如语义和句法语境信息。因此,我们提出了一个新的基于图的文本分类框架TensorGCN(三个文本图:基于顺序/序列、语义、句法)。

首先构造基于语义,基于句法和基于顺序的三个文本图,以形成文本图张量。图张量分别用于获取语义上下文、句法上下文和序列上下文的文本信息。为了编码来自多个图的异构信息TensorGCN同时执行两种传播学习。对于每一层,各个(3个)文本图首先执行图内传播以聚集来自每个节点的邻居的信息。然后使用图间传播来协调各个图之间的异构信息。本文的贡献如下:
1)构造了一个文本图张量来分别描述具有语义、句法和顺序约束的上下文信息
2)提出了一种学习方法TensorGCN,用于协调和集成多个图中的异构信息。
3)在几个基准数据集上进行了大量的实验,说明了TensorGCN在文本分类中的有效性。
3. 方法
图卷积的定义可以查看第一篇博客,或者查看原文,这里不再赘述。
- 图张量的定义
为了研究方便,本文给出了图张量(由多个共享相同结点的图组成的,即每个图的节点集相同,边和权重不一样)的定义:
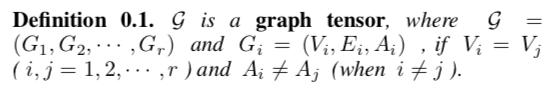
其中:
1)是图张量G中的第 i 个图
2)(
)是第i个图的节点集合
3)是第i个图的边集合
4)是第i个图的邻接矩阵(内部的值为节点间边的权重)
为方便起见,我们还将邻接矩阵打包成张量():
其中:
是图张量G中第i个图的邻接矩阵。
- 图特征张量
我们还将图特征打包成张量()
其中:
1)l表示GCN的层数
2)表示图张量G中第i 个图在GCN第l层的特征矩阵
3)图特征张量表示各个图的初始化特征矩阵
- 文本图张量构造
我们利用图张量来描述具有不同知识/语言属性的文本文档。在本文中,我们基于语义信息,句法依赖关系和局部序列上下文这三种不同的语言属性构建了词与词之间的边。并基于这些不同类型的单词-单词边,我们构造了一系列(3个)文本图来描述文本文档。
注意:每个图都是异构图(每个图都是针对整个语料库构建),包含两类节点,一个是语料库/数据集中的所有文档,另一个是语料库/数据集中的所有单词(去重)。每个图只有文档节点和单词节点以及单词节点和单词节点有边。其中如过一个单词出现在了某个文档中,则他们之间有一条边,边上的权重为单词的TF-IDF值(TF:该单词在该文档中出现的次数,IDF是总文档数比上包含该词的文档数再取log,TF-IDF= TF*IDF)。
下面对每个图详细讲解单词节点与单词节点之间的边以及权重的构建。
- 基于语义的图
我们提出了一种基于LSTM的方法来从文本文档构建基于语义的图,主要分为如下三步:
Step 1: 根据给定任务的训练数据对LSTM进行训练(例如,此处为文本分类)
Step 2: 使用LSTM为语料库的每个文档/句子中的所有单词获取语义特征/嵌入
Step 3:基于语料库上的单词语义嵌入计算单词-单词边权重

对于每个句子/文档,我们从训练的LSTM的输出中获得每个单词的语义特征/嵌入,并计算单词之间的余弦相似度。如果相似度值超过预定义阈值,则意味着这两个词在当前句子/文档中具有语义关系。我们统计在整个语料库中具有语义关系的每对单词的次数。每对词(基于语义的图中的节点)的边权重可以通过以下方式获得:
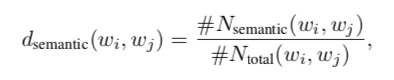
其中:
1)表示单词(节点)
之间的边权重
2)表示两个词在语料库/数据集中的所有句子/文档中具有语义关系的次数
3)表示两个词在整个语料库中出现在同一句子/文档中的次数。
- 基于句法的图
对于语料库中的每个句子/文档,我们首先使用Stanford CoreNLP解析器来提取词之间的依赖关系。虽然提取的依赖是有方向的,但为简单起见,我们将其视为无方向关系。与上面语义图中使用的策略类似,我们统计每对词在整个语料库中具有句法依赖性的次数,并通过以下方式计算每对词(基于句法的图中的节点)的边权重:

其中:
1)表示单词(节点)
之间的边权重
2)表示两个词在语料库/数据集中的所有句子/文档中具有句法依赖关系的次数
3)表示两个词在整个语料库中出现在同一句子/文档中的次数。
- 基于序列的图
序列上下文刻画了词与词之间的语言属性,在本文中,使用PMI,在整个语料库上使用滑动窗口(大小为20,每次右移一个单词位置)策略来描述这种序列上下文信息。每对词的边权重通过以下方式计算(和textGCN中的构图方法一样):
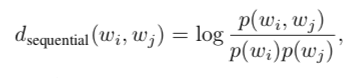
其中:
1)是单词对
)在同一滑动窗口中出现的概率,可以通过下式计算:

2)是整个文本语料库的滑动窗口总数
3)是单词对
在整个文本语料库的相同滑动窗口中出现的次数,即包含单词对
的滑动窗口数。
4)是单词
出现在文本语料库上固定窗口中的概率:
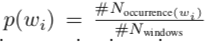
5):包含单词
的滑动窗口数。
- 图张量学习
初始模型:合并边+GCN
在本文中主要关注图张量,所有图共享相同的节点集,边是唯一的不同之处。因此,我们只需要通过汇集邻接(矩阵)张量(各个邻接矩阵维度相同,n*n)将边合并到一个图中:
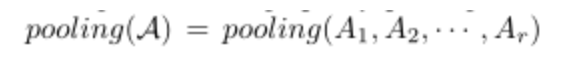
由于张量中的图是异构的,并且来自不同图的边权重不匹配,因此直接使用平均池化与最大池化是不可行的,因此,我们使用一种简单的边注意策略(edgewise attention strategy )来协调来自不同图的边权重。合并图的邻接矩阵可以表示为:
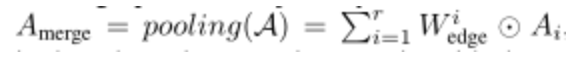
张量GCN
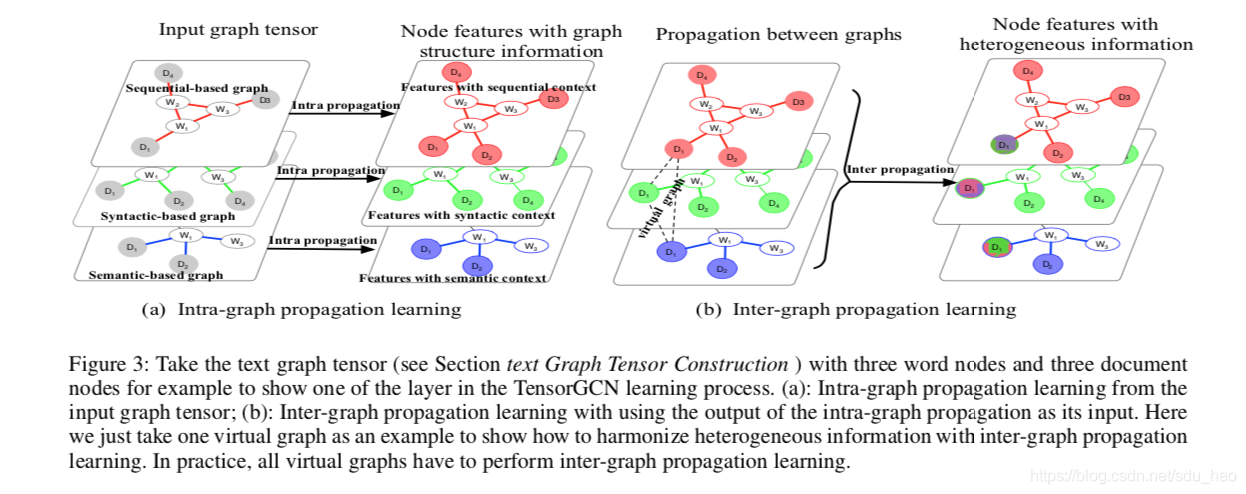
上面的初始模型采取了一种“粗鲁”的方式,将所有的图都放在同一个表示空间中,并将它们放到一个图中,在某种程度上破坏了张量的结构。我们利用图神经网络学习方式在不同的图之间传播信息,从而将单个图上的神经网络学习公式推广到图张量上的TensorGCN,可以直接在张量图上进行卷积学习。对于TensorGCN的每一层,文中执行两种传播学习:首先是各个图内传播,然后是图间传播。
我们以TensorGCN的第l层为例,节点特征的传播通过下式实现:
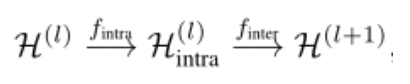
其中:
1),第l层的特征张量
2)分别表示图内传播和图间传播
A. 图内传播
图内传播学习是从图中每个节点的邻居那里聚集信息。因此,学习模式几乎与标准的GCN相同,唯一的区别是所有图都必须执行GCN学习,从而产生张量版的GCN。给定图邻接张量(上图中的(a)):
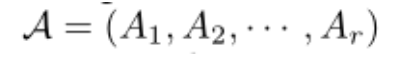
通过图内传播最终更新第l层中的第i(i=1,...,r ; 这里r=3)个图的特征如下:
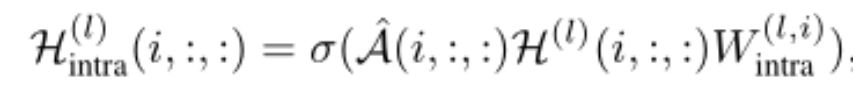
其中:
1)A是由一系列归一化对称邻接矩阵(并且引入了自连接)组成的归一化对称图邻接张量
2)是GCN第l层,第i个图对应的权重矩阵
B. 图间传播
图间传播学习是在张量中的不同图之间传播/交换信息(参见上图(b)),使得来自不同图的异构信息可以逐渐融合成一致的信息。为了实现这一目的,由于张量图中所有图实际上共享同一组相同的节点(节点相同,文档节点和单词节点,即相同),我们把图张量中每个图的对应节点连接起来构造一系列特殊的图,称为虚拟图(virtual graphs)。在我们定义的张量图中所有图共享同一组节点:
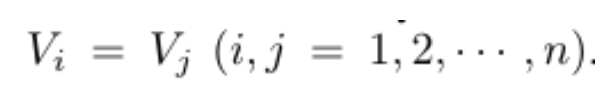
最终,我们会得到n个虚拟图(r个图对应(位置)的节点相互连接,总共有n个节点,所以会产生n个虚拟图,每个虚拟图r个节点,r个节点两两连接,不包括自连接;这里r=3)。n个虚拟图的边权重(都为1),得到一个新的图邻接张量。虚拟图上的图间信息传播学习域通过以下方式实现:
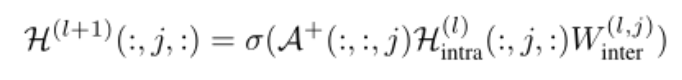
其中:
1)是图间传播的输出,也是TensorGCN中l+1层的输入特征张量/l层的输出特征张量
2)是图间传播的可训练权重矩阵
3)是既不用对称归一化也不添加自连接的第j个(j=1,...,n)虚拟图的邻接矩阵(对角线为0,其他位置为1);
(r=3)
4)虚拟图中的所有节点彼此连接,并且边权重被设置为1
在GCN的最后一层图间传播完成后,,其中
等于分类类别数。然后对r个图进行平均池化,得到最终的输出
,取出其中文档节点对应的部分,训练时(full-batch),再从文档节点中取出训练集对应的输出,和真实标签的one-hot向量作交叉熵损失,然后反向传播,计算梯度,更新参数;验证或测试时,再从文档节点中取出验证集/测试集对应的输出,和真实标签计算相关指标。
4. 实验
- 数据集
我们使用如下5个文本分类数据集验证我们模型的有效性:

- 实验结果
我们在基准数据集上进行了全面的实验,表3中给出的结果表明,我们提出的TensorGCN明显优于所有基线(包括一些最先进的嵌入学习和基于图的模型)。
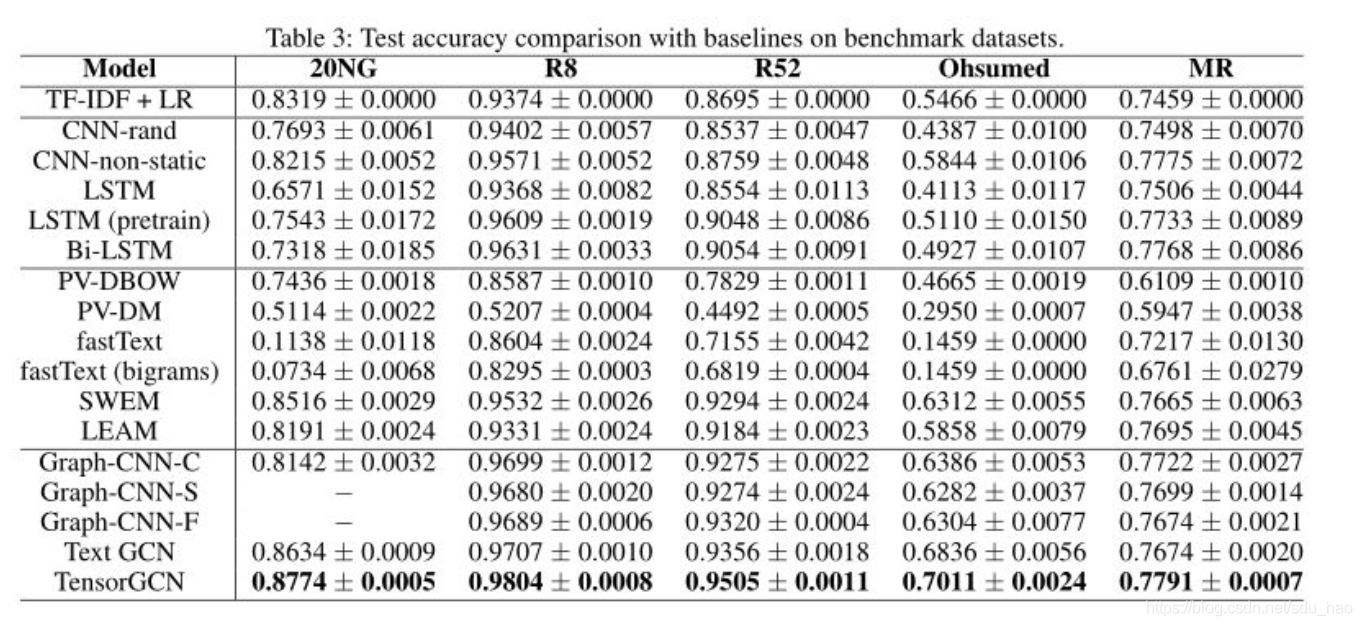
我们还检验并分析了我们构造的文本图张量的有效性。表4给出了单个文本图、两个图对以及所有三个图(图张量)的结果。

从表中可以看到,图张量具有最好的性能,并且每个数据集对各个文本图的侧重有所不同,比如句法图在MR数据集上有更重要的作用,各个文本图之间是互补的关系。
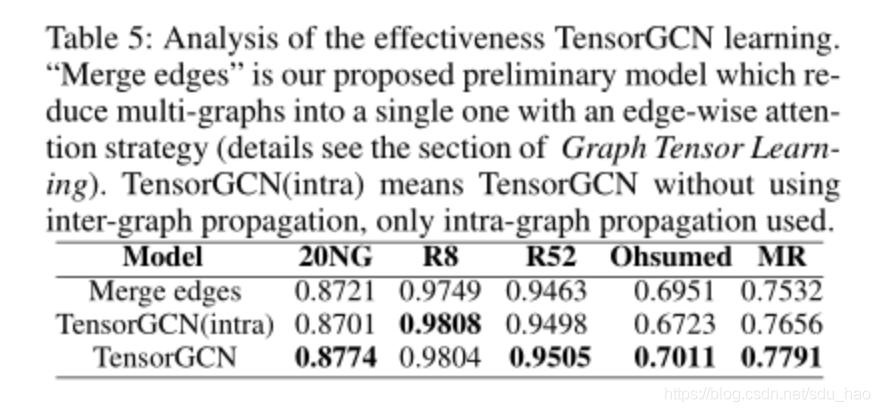
我们检验了TensorGCN学习的有效性,从表中可以看到TensorGCN在多图联合学习方面具有最好的性能结果,如下表所示:
5. 结论
在本文中,我们提出了一种文本图张量来捕捉语义、句法和序列上下文信息中的特征。实验结果表明,这些不同的上下文约束是相辅相成的,对文本表示学习非常重要。此外,我们将图卷积网络推广为张量型TensorGCN,通过图内和图间传播同时学习的策略,有效地协调和集成了多个图中的异构信息。
相比于TextGCN的只有一个基于序列的文本图,TensorGCN有基于语义、句法和序列的三个文本图形成图张量,而且将GCN扩展到TensorGCN,并增加了图间传播。其他属性上TensorGCN和TextGCN几乎没什么差别,TextGCN的缺点TensorGCN同样具备,比如无法为新文本分类(具体原因和更多改进思路可以查看第一篇博客)。
智能推荐
《多Agent系统引论》第1章 引言 小结_多agent系统引论第一章-程序员宅基地
文章浏览阅读895次,点赞27次,收藏17次。本文总结了《多Agent系统引论》的第一章引言部分,讨论了计算机发展趋势到Agent提出,Agent的研究前景、Agent的定义与进一步阅读的推荐读物。多Agent系统是当前业界比较火的发展方向,Agent又叫做智能体,随着大模型技术的兴起而被越来越多的人所关注。故作此文。_多agent系统引论第一章
【CSAPP】探究BombLab奥秘:Phase_5的解密与实战_csapp phase_5-程序员宅基地
文章浏览阅读9.4k次,点赞53次,收藏49次。该博文深入剖析了CSAPP(Computer Systems: A Programmer's Perspective)课程中的BombLab实验,着重探讨了实验中的关键阶段——Phase_5。作者通过逆向工程和实战经验,揭示了Phase_5的解密奥秘,探讨了在这个阶段学到的重要计算机系统原理。文章通过详实的解读和实例演示,为读者提供了深入理解计算机系统底层操作的机会,为攻克BombLab实验提供了实用的指南。通过分析实验过程中的挑战和解决方案,读者将更好地理解计算机系统的工作原理及程序设计的关键技术。_csapp phase_5
nginx-程序员宅基地
文章浏览阅读105次。1.什么是nginxNginx (engine x) 是一个高性能的HTTP和反向代理web服务器,使用c语言编写的一款web服务软件.Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,在BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。2.nginx的作用1.反向代理2.负载均衡。3.动静分离3.
java.io.IOException:Permission denied_java.io.ioexception: permission denied-程序员宅基地
文章浏览阅读419次,点赞7次,收藏11次。问题:在java代码中使用IO流,在windows下运行没有问题,部署到服务器是出现错误。解决方法:以宝塔面板为例,修改文件权限为。_java.io.ioexception: permission denied
pega(csa)_pega csa-程序员宅基地
文章浏览阅读1.8k次。pega的好处让软件写软件强化业务逻辑在对组织有意义的地方运行应用程序使用Pega的应用程序产品启动您的转换团队成员:1案例设计者(业务架构师和系统架构师):和课题专家还有利益相关者开发系统业务架构师:定义一个业务规则,服务等级协议和进程。是去理解用户需求和定义用户案例和特征的关键系统架构师:应用开发者进行面向对象的设计和应用的实现2课题专家设计一个业务逻辑3利益相关者帮助去复查,重定义和提供解决方法直接在应用中捕捉对象Direct capture of objective(DCO)_pega csa
Cannot start container web: iptables failed: iptables -t nat -A DOCKER -p tcp -d 0/0 --dport 32797_pmm iptables failed: iptables -t nat -a docker -p -程序员宅基地
文章浏览阅读377次。由于关闭了firewalld,然后启动docker出现报错docker 启动 web 示例报错如下:Error response from daemon: Cannot start container web: iptables failed: iptables -t nat -A DOCKER -p tcp -d 0/0 --dport 32797 -j DNAT --to-destinat..._pmm iptables failed: iptables -t nat -a docker -p tcp -d 0/0 --dport 443 -j
随便推点
Chapter2-软件构造过程和生命周期_iterative and agile systems development lifecycle -程序员宅基地
文章浏览阅读262次。Chapter22.1 Software Lifecycle and Configuration Management2.1.1 Software Development Lifecycle(SDLC)2.1.2 Traditional Software process models2.1.3 Agile development and eXtreme Programming(XP..._iterative and agile systems development lifecycle (sdlc
4.6 浮动定位方式float_c语言中float的左右浮动属性示例-程序员宅基地
文章浏览阅读1.1k次。4.6 浮动定位方式float使用float属性来进行浮动定位;使用clear属性可以清除这种浮动1.float属性(设定浮动)float属性的三个取值(1)left左浮动(2)right右浮动(3)none不浮动下面是一个向左浮动的例子float属性的两个用处(1)在图文混排的时候,如果你希望图片位于文字的左侧或者右侧,那就把图片对的float属性设为left或者right;(2)在做多列盒子布局的情况,可以根据需求让盒子向左或向右浮动。float属性的特点三个盒子,默认情况_c语言中float的左右浮动属性示例
OSS上传【下载乱码问题】_阿里云oss文件名乱码-程序员宅基地
文章浏览阅读468次,点赞6次,收藏6次。【代码】OSS上传下载乱码问题。_阿里云oss文件名乱码
【免费题库】华为OD机试C卷 - 数字字符串组合倒序(Java 代码+解析)-程序员宅基地
文章浏览阅读2.3k次。题目描述对数字,字符,数字串,字符串,以及数字与字符串组合进行倒序排列。字符范围:由 a 到 z, A 到 Z,数字范围:由 0 到 9符号的定义:“-”作为连接符使用时作为字符串的一部分,例如“20-years”作为一个整体字符串呈现;连续出现 2 个 “-” 及以上时视为字符串间隔符,如“out--standing”中的”–“视为间隔符,是 2 个独立整体字符串”out”和”standing”;除了 1,2 里面定义的字符以外其他的所有字符,都是非法字符,作为字符串的间隔符处理,倒序后
Android(14) ArrayAdapter(数组适配器)的三种方法-程序员宅基地
文章浏览阅读5w次,点赞36次,收藏138次。ArrayAdapter数组适配器用于绑定格式单一的数据,数据源可以是集合或者数组列表视图(ListView)以垂直的形式列出需要显示的列表项。实现过程:新建适配器->添加数据源到适配器->视图加载适配器第一种:直接用ListView组件创建列表每一行只有一行文字效果如图:activity_list布局:<?xml version="1.0" e..._arrayadapter
助力商家健康经营 创业者为水滴直播点赞-程序员宅基地
文章浏览阅读43次。近日,水滴直播平台登上了舆论的风口浪尖。有人认为水滴直播涉嫌侵犯隐私,但也有人表示这种互联网新生事物可以有效规避很多风险,值得鼓励,不应一棒子打死。记者采访时发现,很多商家、创业者对于水滴直播纷纷表示支持,并直言水滴直播为他们的经营带来了很大帮助。 邹志泉在北京丰台区经营着一家批发厂家直销男女内衣裤的店铺,平时就打开水滴直播,分享他在店铺的经营画面。面对水滴直播涉及隐私的提问,邹志泉明确表...