【AI实战】手把手教你深度学习文字识别(文字检测篇:基于MSER, CTPN, SegLink, EAST等方法)_深度学习 文字识别-程序员宅基地

文字检测是文字识别过程中的一个非常重要的环节,文字检测的主要目标是将图片中的文字区域位置检测出来,以便于进行后面的文字识别,只有找到了文本所在区域,才能对其内容进行识别。
文字检测的场景主要分为两种,一种是简单场景,另一种是复杂场景。其中,简单场景的文字检测较为简单,例如像书本扫描、屏幕截图、或者清晰度高、规整的照片等;而复杂场景,主要是指自然场景,情况比较复杂,例如像街边的广告牌、产品包装盒、设备上的说明、商标等等,存在着背景复杂、光线忽明忽暗、角度倾斜、扭曲变形、清晰度不足等各种情况,文字检测的难度更大。如下图:

本文将介绍简单场景、复杂场景中常用的文字检测方法,包括形态学操作、MSER+NMS、CTPN、SegLink、EAST等方法,并主要以ICDAR场景文字图片数据集介绍如何使用这些方法,如下图:
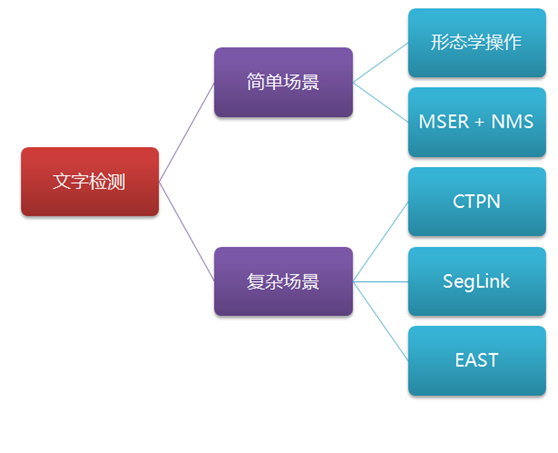
1、简单场景:形态学操作法
通过利用计算机视觉中的图像形态学操作,包括膨胀、腐蚀基本操作,即可实现简单场景的文字检测,例如检测屏幕截图中的文字区域位置,如下图:
其中,“膨胀”就是对图像中的高亮部分进行扩张,让白色区域变多;“腐蚀”就是图像中的高亮部分被蚕食,让黑色区域变多。通过膨胀、腐蚀的一系列操作,可将文字区域的轮廓突出,并消除掉一些边框线条,再通过查找轮廓的方法计算出文字区域的位置出来。主要的步骤如下:
- 读取图片,并转为灰度图
- 图片二值化,或先降噪后再二值化,以便简化处理
- 膨胀、腐蚀操作,突出轮廓、消除边框线条
- 查找轮廓,去除不符合文字特点的边框
- 返回文字检测的边框结果
通过OpenCV,便能轻松实现以上过程,核心代码如下:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
# 读取图片
imagePath = '/data/download/test1.jpg'
img = cv2.imread(imagePath)
# 转化成灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 利用Sobel边缘检测生成二值图
sobel = cv2.Sobel(gray, cv2.CV_8U, 1, 0, ksize=3)
# 二值化
ret, binary = cv2.threshold(sobel, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY)
# 膨胀、腐蚀
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 9))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (24, 6))
# 膨胀一次,让轮廓突出
dilation = cv2.dilate(binary, element2, iterations=1)
# 腐蚀一次,去掉细节
erosion = cv2.erode(dilation, element1, iterations=1)
# 再次膨胀,让轮廓明显一些
dilation2 = cv2.dilate(erosion, element2, iterations=2)
# 查找轮廓和筛选文字区域
region = []
contours, hierarchy = cv2.findContours(dilation2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
cnt = contours[i]
# 计算轮廓面积,并筛选掉面积小的
area = cv2.contourArea(cnt)
if (area < 1000):
continue
# 找到最小的矩形
rect = cv2.minAreaRect(cnt)
print ("rect is: ")
print (rect)
# box是四个点的坐标
box = cv2.boxPoints(rect)
box = np.int0(box)
# 计算高和宽
height = abs(box[0][1] - box[2][1])
width = abs(box[0][0] - box[2][0])
# 根据文字特征,筛选那些太细的矩形,留下扁的
if (height > width * 1.3):
continue
region.append(box)
# 绘制轮廓
for box in region:
cv2.drawContours(img, [box], 0, (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
该图像处理过程如下图所示:
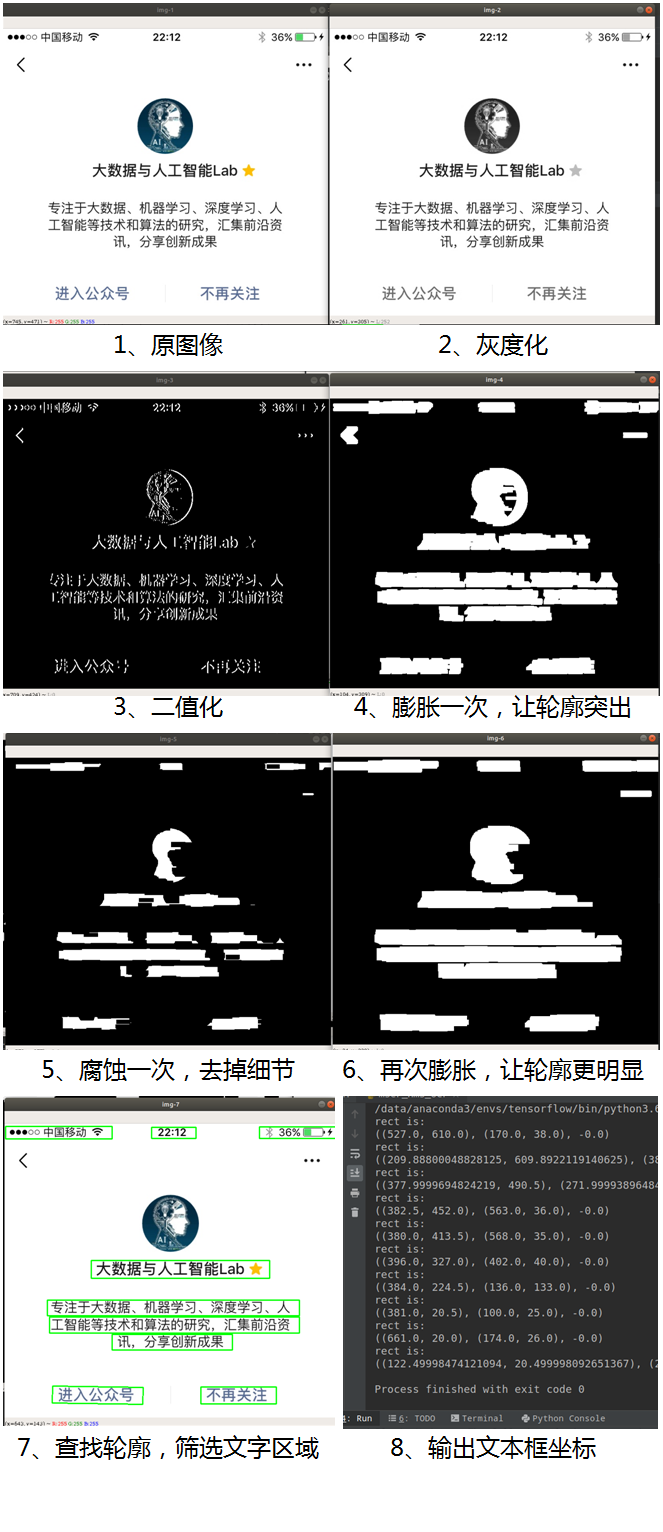
可以看到最终成功将图像中的文字区域检测出来了。
这种方法的特点是计算简单、处理起来非常快,但在文字检测中的应用场景非常有限,例如如果图片是拍照的,光线有明有暗或者角度有倾斜、纸张变形等,则该方法需要不断重新调整才能检测,而且效果也不会很好,如下图。例如上面介绍的代码是针对白底黑字的检测,如果是深色底白色字则需要重新调整代码,如果有需要,可再私信我交流。


2、简单场景:MSER+NMS检测法
MSER(Maximally Stable Extremal Regions,最大稳定极值区域)是一个较为流行的文字检测传统方法(相对于基于深度学习的AI文字检测而言),在传统OCR中应用较广,在某些场景下,又快又准。
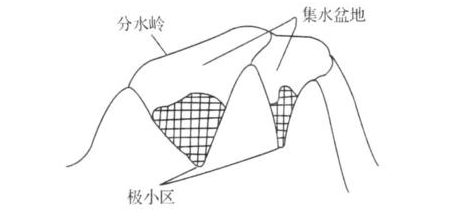
MSER算法是在2002提出来的,主要是基于分水岭的思想进行检测。分水岭算法思想来源于地形学,将图像当作自然地貌,图像中每一个像素的灰度值表示该点的海拔高度,每一个局部极小值及区域称为集水盆地,两个集水盆地之间的边界则为分水岭,如下图:
MSER的处理过程是这样的,对一幅灰度图像取不同的阈值进行二值化处理,阈值从0至255递增,这个递增的过程就好比是一片土地上的水面不断上升,随着水位的不断上升,一些较低的区域就会逐渐被淹没,从天空鸟瞰,大地变为陆地、水域两部分,并且水域部分在不断扩大。在这个“漫水”的过程中,图像中的某些连通区域变化很小,甚至没有变化,则该区域就被称为最大稳定极值区域。在一幅有文字的图像上,文字区域由于颜色(灰度值)是一致的,因此在水平面(阈值)持续增长的过程中,一开始不会被“淹没”,直到阈值增加到文字本身的灰度值时才会被“淹没”。该算法可以用来粗略地定位出图像中的文字区域位置。
听起来这个处理过程似乎非常复杂,好在OpenCV中已内置了MSER的算法,可以直接调用,大大简化了处理过程。
检测效果如下图:

检测后的结果是存在各种不规则的检测框形状,通过对这些框的坐标作重新处理,变成一个个的矩形框。如下图:

核心代码如下:
# 读取图片
imagePath = '/data/download/test2.jpg'
img = cv2.imread(imagePath)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
vis = img.copy()
orig = img.copy()
# 调用 MSER 算法
mser = cv2.MSER_create()
regions, _ = mser.detectRegions(gray) # 获取文本区域
hulls = [cv2.convexHull(p.reshape(-1, 1, 2)) for p in regions] # 绘制文本区域
cv2.polylines(img, hulls, 1, (0, 255, 0))
cv2.imshow('img', img)
# 将不规则检测框处理成矩形框
keep = []
for c in hulls:
x, y, w, h = cv2.boundingRect(c)
keep.append([x, y, x + w, y + h])
cv2.rectangle(vis, (x, y), (x + w, y + h), (255, 255, 0), 1)
cv2.imshow("hulls", vis)
从上图可以看出,检测框有很多是重叠的,大框里面有小框,框与框之间有交叉,有些框只是圈出了汉字的偏旁或者某些笔划,而我们期望是能圈出文字的外边框,这样便于后续的文字识别。为了处理这些很多重叠的大小框,一般会采用NMS方法(Non Maximu
智能推荐
python简易爬虫v1.0-程序员宅基地
文章浏览阅读1.8k次,点赞4次,收藏6次。python简易爬虫v1.0作者:William Ma (the_CoderWM)进阶python的首秀,大部分童鞋肯定是做个简单的爬虫吧,众所周知,爬虫需要各种各样的第三方库,例如scrapy, bs4, requests, urllib3等等。此处,我们先从最简单的爬虫开始。首先,我们需要安装两个第三方库:requests和bs4。在cmd中输入以下代码:pip install requestspip install bs4等安装成功后,就可以进入pycharm来写爬虫了。爬
安装flask后vim出现:error detected while processing /home/zww/.vim/ftplugin/python/pyflakes.vim:line 28_freetorn.vim-程序员宅基地
文章浏览阅读2.6k次。解决方法:解决方法可以去github重新下载一个pyflakes.vim。执行如下命令git clone --recursive git://github.com/kevinw/pyflakes-vim.git然后进入git克降目录,./pyflakes-vim/ftplugin,通过如下命令将python目录下的所有文件复制到~/.vim/ftplugin目录下即可。cp -R ...._freetorn.vim
HIT CSAPP大作业:程序人生—Hello‘s P2P-程序员宅基地
文章浏览阅读210次,点赞7次,收藏3次。本文简述了hello.c源程序的预处理、编译、汇编、链接和运行的主要过程,以及hello程序的进程管理、存储管理与I/O管理,通过hello.c这一程序周期的描述,对程序的编译、加载、运行有了初步的了解。_hit csapp
18个顶级人工智能平台-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏27次。来源:机器人小妹 很多时候企业拥有重复,乏味且困难的工作流程,这些流程往往会减慢生产速度并增加运营成本。为了降低生产成本,企业别无选择,只能自动化某些功能以降低生产成本。 通过数字化..._人工智能平台
electron热加载_electron-reloader-程序员宅基地
文章浏览阅读2.2k次。热加载能够在每次保存修改的代码后自动刷新 electron 应用界面,而不必每次去手动操作重新运行,这极大的提升了开发效率。安装 electron 热加载插件热加载虽然很方便,但是不是每个 electron 项目必须的,所以想要舒服的开发 electron 就只能给 electron 项目单独的安装热加载插件[electron-reloader]:// 在项目的根目录下安装 electron-reloader,国内建议使用 cnpm 代替 npmnpm install electron-relo._electron-reloader
android 11.0 去掉recovery模式UI页面的选项_android recovery 删除 部分菜单-程序员宅基地
文章浏览阅读942次。在11.0 进行定制化开发,会根据需要去掉recovery模式的一些选项 就是在device.cpp去掉一些选项就可以了。_android recovery 删除 部分菜单
随便推点
echart省会流向图(物流运输、地图)_java+echart地图+物流跟踪-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏6次。继续上次的echart博客,由于省会流向图是从echart画廊中直接取来的。所以直接上代码<!DOCTYPE html><html><head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width,initial-scale=1,minimum-scale=1,maximum-scale=1,user-scalable=no" /&_java+echart地图+物流跟踪
Ceph源码解析:读写流程_ceph 发送数据到其他副本的源码-程序员宅基地
文章浏览阅读1.4k次。一、OSD模块简介1.1 消息封装:在OSD上发送和接收信息。cluster_messenger -与其它OSDs和monitors沟通client_messenger -与客户端沟通1.2 消息调度:Dispatcher类,主要负责消息分类1.3 工作队列:1.3.1 OpWQ: 处理ops(从客户端)和sub ops(从其他的OSD)。运行在op_tp线程池。1...._ceph 发送数据到其他副本的源码
进程调度(一)——FIFO算法_进程调度fifo算法代码-程序员宅基地
文章浏览阅读7.9k次,点赞3次,收藏22次。一 定义这是最早出现的置换算法。该算法总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰。该算法实现简单,只需把一个进程已调入内存的页面,按先后次序链接成一个队列,并设置一个指针,称为替换指针,使它总是指向最老的页面。但该算法与进程实际运行的规律不相适应,因为在进程中,有些页面经常被访问,比如,含有全局变量、常用函数、例程等的页面,FIFO 算法并不能保证这些页面不被淘汰。这里,我_进程调度fifo算法代码
mysql rownum写法_mysql应用之类似oracle rownum写法-程序员宅基地
文章浏览阅读133次。rownum是oracle才有的写法,rownum在oracle中可以用于取第一条数据,或者批量写数据时限定批量写的数量等mysql取第一条数据写法SELECT * FROM t order by id LIMIT 1;oracle取第一条数据写法SELECT * FROM t where rownum =1 order by id;ok,上面是mysql和oracle取第一条数据的写法对比,不过..._mysql 替换@rownum的写法
eclipse安装教程_ecjelm-程序员宅基地
文章浏览阅读790次,点赞3次,收藏4次。官网下载下载链接:http://www.eclipse.org/downloads/点击Download下载完成后双击运行我选择第2个,看自己需要(我选择企业级应用,如果只是单纯学习java选第一个就行)进入下一步后选择jre和安装路径修改jvm/jre的时候也可以选择本地的(点后面的文件夹进去),但是我们没有11版本的,所以还是用他的吧选择接受安装中安装过程中如果有其他界面弹出就点accept就行..._ecjelm
Linux常用网络命令_ifconfig 删除vlan-程序员宅基地
文章浏览阅读245次。原文链接:https://linux.cn/article-7801-1.htmlifconfigping <IP地址>:发送ICMP echo消息到某个主机traceroute <IP地址>:用于跟踪IP包的路由路由:netstat -r: 打印路由表route add :添加静态路由路径routed:控制动态路由的BSD守护程序。运行RIP路由协议gat..._ifconfig 删除vlan