机器学习之数据集_机器学习数据集-程序员宅基地
技术标签: python 机器学习 人工智能 chatgpt
目录
所属专栏:人工智能
文中提到的代码如有需要可以私信我发给你
1、简介
当谈论数据集时,通常是指在机器学习和数据分析中使用的一组数据样本,这些样本通常代表了某个特定问题领域的实际观测数据。数据集可以用于开发、训练和评估机器学习模型,从而使模型能够从数据中学习并做出预测或分类。
数据集通常由以下几个组成部分组成:
- 特征(Features):也称为自变量、属性或输入变量,是用来描述每个数据样本的不同方面的数据。特征可以是数值型、类别型、文本型等。在监督学习中,特征被用来训练模型。
- 目标变量(Target Variable):也称为因变量、标签或输出变量,是我们希望模型预测或分类的值。在监督学习中,模型使用特征来预测或分类目标变量。
- 样本(Samples):每个样本是数据集中的一行,包含特征和目标变量的值。样本代表了问题领域中的一个观测点或数据点。
- 特征名称(Feature Names):如果数据集中的特征有名称,通常会提供一个特征名称列表,以便更好地理解和解释特征。
- 目标变量的类别(Target Variable Classes):对于分类问题,目标变量可能有多个类别,每个类别表示一个不同的类或标签。
- 数据集描述(Dataset Description):通常包括数据集的来源、数据采集方法、特征和目标变量的含义,以及数据的格式和结构等信息。
数据集可以在各种领域和问题中使用,例如医疗诊断、自然语言处理、计算机视觉、金融预测等。不同类型的数据集可能需要不同的预处理和特征工程步骤,以便为模型提供有意义的数据。
在机器学习中,一个常见的任务是将数据集划分为训练集和测试集,用于模型的训练和评估。这样可以确保模型在未见过的数据上能够进行泛化。数据集的质量和适用性对机器学习模型的性能和效果有很大影响,因此选择合适的数据集和进行有效的特征工程非常重要。
2、可用数据集
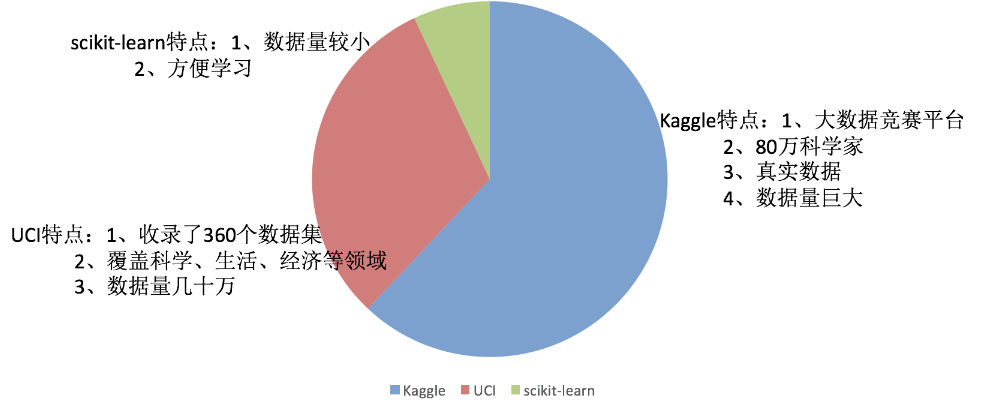
Kaggle网址:Find Open Datasets and Machine Learning Projects | Kaggle
UCI数据集网址: UCI Machine Learning Repository
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
Scikit-learn工具介绍:

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
安装:pip3 install Scikit-learn==0.19.1 (安装scikit-learn需要Numpy, Scipy等库)
Scikit-learn包含的内容:
scikitlearn接口
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
3、scikit-learn数据集API
- sklearn.datasets 加载获取流行数据集
- datasets.load_*() 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None) 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
3.1、小数据集
sklearn.datasets.load_iris() 加载并返回鸢尾花数据集

sklearn.datasets.load_boston() 加载并返回波士顿房价数据集
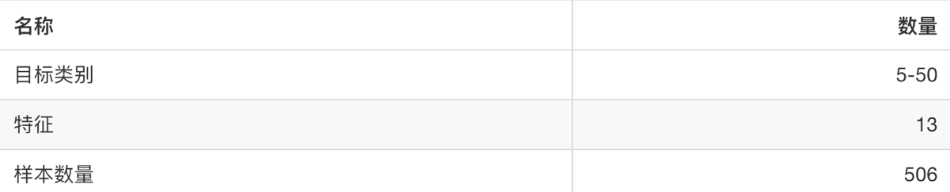
3.2、大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
-
- subset:'train'或者'test','all',可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
4、数据集使用
这里使用的是鸢尾花数据集

数据集返回值介绍:
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
from sklearn.datasets import load_iris
'''
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
'''
def getIris_1():
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
if __name__ == '__main__':
getIris_1()数据集划分:
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
数据集划分api:
sklearn.model_selection.train_test_split(arrays, *options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.model_selection import train_test_split # 数据集划分
'''
sklearn.model_selection.train_test_split(arrays, *options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
'''
def datasets_demo():
"""
对鸢尾花数据集的演示
:return: None
"""
# 1、获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
# 2、对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# 随机数种子
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("如果随机数种子一致:\n", x_train1 == x_train2)
return None
if __name__ == '__main__':
datasets_demo()智能推荐
view滑动冲突解决实战篇2(外部拦截法)_viewpage2外部拦截事件-程序员宅基地
文章浏览阅读1.1k次。继上篇内部拦截法需求还是跟上篇一样。只不过这次用外部拦截法来解决;只要在父容器添加如下代码就可以解决了滑动冲突,很简单,套模板就行 // 分别记录上次滑动的坐标(onInterceptTouchEvent) private int mLastXIntercept = 0; private int mLastYIntercept = 0; @Override public bo_viewpage2外部拦截事件
汇编 堆栈 变量存储 指针_汇编语言栈指针-程序员宅基地
文章浏览阅读2.5k次,点赞7次,收藏9次。本文章系作者原创,未经许可,不得转载。汇编 堆栈 变量存储 指针先说栈的概念,栈其实也是一种。。。。。先说内存的概念吧。。。。。额 先说计算机吧,简单来说的话,可以把计算机理解成由CPU,内存,硬盘组成,而CPU内部又包括一种叫做内部寄存器的东西,包括 数据寄存器: AX,BX,CX,DX; 段寄存器: CS,DS,ES,SS; 指针与变址寄存器SP,BP,SI,DI; ..._汇编语言栈指针
架构师之路:从码农到架构师你差了哪些_web架构师-程序员宅基地
文章浏览阅读1w次,点赞14次,收藏56次。转载自 架构师之路:从码农到架构师你差了哪些 Web应用,最常见的研发语言是Java和PHP。 后端服务,最常见的研发语言是Java和C/C++。 大数据,最常见的研发语言是Java和Python。 可以说,Java是现阶段中国互联网公司中,覆盖度最广的研发语言,掌握了Java技术体系,不管在成熟的大公司,快速发展的公司,还是创业阶段的公司,都能有立足之地。有..._web架构师
js sort排序_sort a<b-程序员宅基地
文章浏览阅读103次。/* 排序 >号 从小到大排序 <从大到小排序 */ list.sort(function(a, b) { return a.date < b.date ? 1 : -1; })如果是简单的list就直接 return a < b ? 1 : -1;即可,如果是list里面套的map,可让list按map里面的指定字段进行排揎。..._sort a
前端设置条件限制form表单提交到后端解决方案_jsp前端页面将表单是否提交成功作为限制条件-程序员宅基地
文章浏览阅读375次。<script src="js/jquery-1.8.3.min.js" type="text/javascript"></script> <script type="text/javascript"> function checkName() { var name = document.getElementB..._jsp前端页面将表单是否提交成功作为限制条件
计算机网络sequence number,TCP协议中SequenceNumber和Ack Numbe-程序员宅基地
文章浏览阅读1k次。Sequence Numberlzyws7393074532892018-04-25Number Sequenceqq_391789932452017-09-21理解TCP序列号(Sequence Number)和确认号(Acknowledgment Number)hebbely9822017-01-14Number Sequence(规律)l25336363712902017-07-18Numb..._ack num
随便推点
Z-Blog编辑器支持ppt导入-程序员宅基地
文章浏览阅读47次。图片的复制无非有两种方法,一种是图片直接上传到服务器,另外一种转换成二进制流的base64码目前限chrome浏览器使用首先以um-editor的二进制流保存为例:打开umeditor.js,找到UM.plugins['autoupload'],然后找到autoUploadHandler方法,注释掉其中的代码。加入下面的代码://判断剪贴板的内容是否包含文本//首先解释一下为什么要判断文本是不是为空//在ctrl+c word中的文字或者图片之后会返回1种(image/png)或者4种t
基于Unity3D的相机功能的实现(六)—— 上帝视角(王者荣耀视角)_unity overlook-程序员宅基地
文章浏览阅读4k次,点赞2次,收藏15次。在MOBA游戏中,上帝视角是一个很实用的功能。_unity overlook
用mac的chrome浏览器调试Android手机的网页-程序员宅基地
文章浏览阅读2.5k次,点赞2次,收藏2次。一、参考链接read chrome remote debugging documentation调出开发者选项二、设置android在安卓4.2及更新的版本中,默认情况下,【开发者选项】是隐藏的。要启用【开发者选项】,设置 -> 关于手机 -> 版本号,对着版本号点击7次。设置 -> 开发者选项 -> USB调试三、连接手机和电脑..._小米13链接mac chrome inspect
树莓派GPIO简单操作_树莓派怎么读取gpio口上的信息-程序员宅基地
文章浏览阅读637次。树莓派的GPIO操作被抽象为文件读写,下面以一个例子来说明GPIO操作。_树莓派怎么读取gpio口上的信息
【汽车电子】浅谈车载系统QNX_车机qnx虚拟化软件系统架构-程序员宅基地
文章浏览阅读1.7k次。QNX是一种商用的遵从POSIX规范的类Unix实时操作系统,目标市场主要是面向嵌入式系统。它可能是最成功的微内核操作系统之一。QNX是一种商用的类Unix实时操作系统,遵从POSⅨ规范,目标市场主要是嵌入式系统[1]。QNX成立于1980年,是加拿大一家知名的嵌入式系统开发商。QNX的应用范围极广,包含了:控制保时捷跑车的音乐和媒体功能、核电站和美国陆军无人驾驶Crusher坦克的控制系统[2],还有RIM公司的BlackBerry PlayBook平板电脑。_车机qnx虚拟化软件系统架构
信号发生器设计VHDL代码Quartus仿真_vhdl正弦波信号发生器-程序员宅基地
文章浏览阅读1k次,点赞20次,收藏22次。代码功能:信号发生器设计信号发生器由波形选择开关控制波形的输出,分别能输出正弦波、方汉和三角波三种波形,波形的周期为2秒(由40M有源晶振分频控制)。考虑程序的容量,每种波形在一个周期内均取16个取样点,每个样点数据是8位(数值范围:00000000~1111111)要求将D/A变换前的8位二进数据(以十进制方式)输出到数码管动态演示出来。_vhdl正弦波信号发生器