大小端介绍,你知道常用的VS2019内存中字节序存储的顺序吗?_大端存储和小端存储-程序员宅基地
目录
一、引入大小端
在我们经常使用的VS2019编译器使用过程过,我们经常会查看变量的内存
例如
int main()
{
int a = 10;
int b = -10;
return 0;
}
内存: 0x00 00 00 0a
我们观察编译器中的字节序
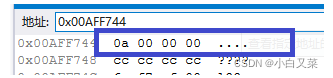

内存:0xff ff ff f6
编译器中的字节序:
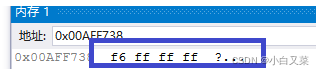
我们再看一个:
int main()
{
int a = 0x11223344;
return 0;
} 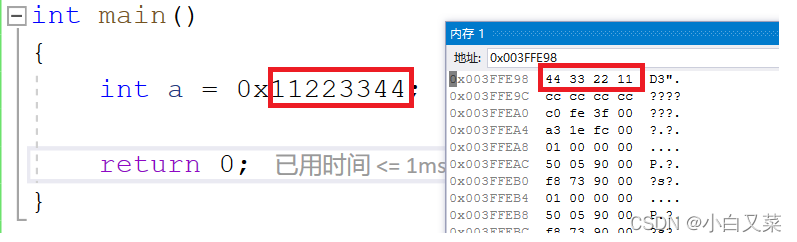
我们发现编译器中的存储方式与我们写出来的地址存储的顺序相反,怎么解释这种现象呢?我们就引入了大小端存储。
二、什么是大小端?
大端(存储)模式:是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中。
小端(存储)模式:是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
我们其实可以知道,超过一个字节序就会有排放的顺序问题。

错乱的顺序我们不好处理,所以就只剩下了正着存储和倒着存储。
因此我们定义:

通俗来说:

三、为什么会有大端和小端?
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
四、测试当前机器的字节序
我们知道存储方式无非大端存储和小端存储两种方式

因此我们可以用1来进行举例,我们知道1在内存中

无非一下两种存储方式
因此我们可以发现,我们可以通过第一个字节来进行判断,如果是1,则是小端存储;如果是0则是大端存储。
代码实现:
int main()
{
int a = 1;
char* p =(char*) &a;//int*
if (*p == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
} 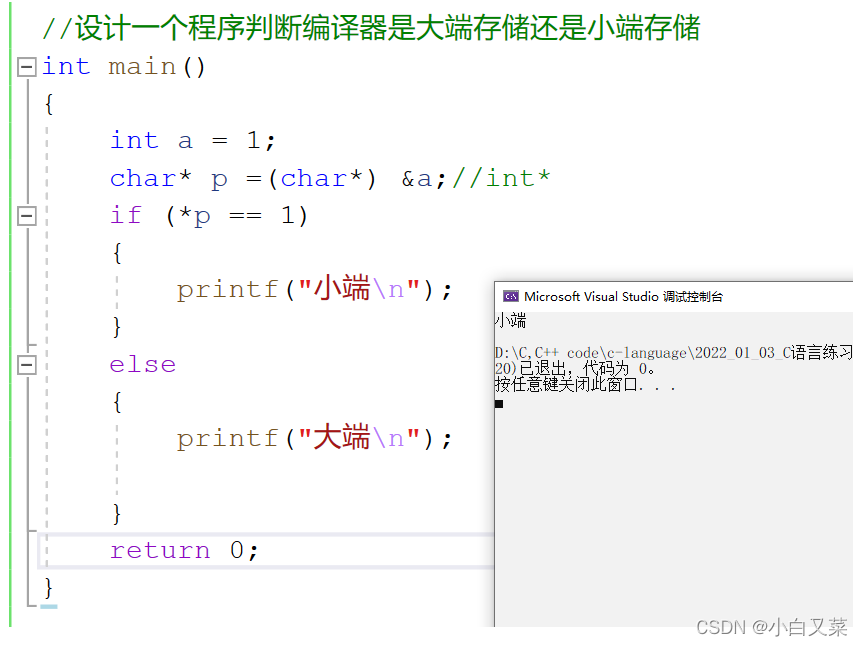
我们能够发现Vs2019是小端存储。
我们可以将代码进行优化:
int check_sys()
{
int a = 1;
char* p = (char*)&a;
/*if (1 == *p)
return 1;
else
return 0;*/
/*return *p;*/
return *(char*)&a;
}
int main()
{
int ret = check_sys();//返回1是小端,返回0是大端
if (1 == ret)
printf("小端\n");
else
printf("大端\n");
return 0;
}我们也可以直接看内存:


我们发现是倒着存,所以推断出是小端。
结论:通过本篇博客的总结,我们知道了当前编译器是大端存储还是小端存储,对我们以后的学习分析过程也会有很大的帮助。
如果你还不知道你经常使用的编译器是怎样的存储方式。小伙伴们快测试起来吧~
最后,大家觉得本篇文章对你有所帮助的话,点赞收藏+关注哦~
智能推荐
2024年最新Android面试精讲,附小技巧,快手android面试经验-程序员宅基地
文章浏览阅读254次,点赞3次,收藏3次。其实Android开发的知识点就那么多,面试问来问去还是那么点东西。所以面试没有其他的诀窍,只看你对这些知识点准备的充分程度。so,出去面试时先看看自己复习到了哪个阶段就好。上面分享的腾讯、头条、阿里、美团、字节跳动等公司2019-2021年的高频面试题,博主还把这些技术点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,上面只是以图片的形式给大家展示一部分。Android学习PDF+学习视频+面试文档+知识点笔记【Android思维脑图(技能树)】知识不体系。
《书生·浦语大模型实战营》第四节课《XTuner 微调 LLM:1.8B、多模态、Agent》课程笔记-程序员宅基地
文章浏览阅读523次,点赞16次,收藏20次。2024年3月开始参加《书生·浦语大模型实战营》第一节课《书生·浦语大模型全链路开源体系》第二节课《轻松玩转书生·浦语大模型趣味 Demo》第三节课《茴香豆:搭建你的 RAG 智能助理》第五节课《LMDeploy 量化部署 LLM 实践》这是《书生·浦语大模型实战营》第四节课《XTuner 微调 LLM:1.8B、多模态、Agent》课程笔记想利用底座模型应用到自己的特定领域当中,应用到一个特定的下游任务当中,表现是不如针对领域内训练的模型,所以需要进行领域内微调。
Matlab仿真偶极子天线激励_天线matlab吸收边界条件-程序员宅基地
文章浏览阅读4k次,点赞4次,收藏25次。%文件描述:三维偶极子源激励,PML吸收边界,采用矩阵赋值%激励描述:高斯脉冲%激励位置:空间中心位置%介质描述:自由空间clear all;close all;clc;%设置初始条件NSTEPS=80;%时间步IE=40;JE=40;KE=40;%仿真空间大小ic=IE/2;jc=JE/2;kc=KE/2;%观察点位置ra_y=1.0;ra_x=1.0;%方向比例系数nx..._天线matlab吸收边界条件
计算机毕业设计hadoop+spark+hive汽车评价情感分析 新能源汽车推荐系统 汽车数据分析可视化 新能源汽车推荐系统 汽车爬虫 机器学习 深度学习 人工智能 知识图谱 大数据毕业设计-程序员宅基地
文章浏览阅读783次,点赞19次,收藏9次。计算机毕业设计hadoop+spark+hive汽车评价情感分析 新能源汽车推荐系统 汽车数据分析可视化 新能源汽车推荐系统 汽车爬虫 机器学习 深度学习 人工智能 知识图谱 大数据毕业设计
论文复现——PFLD——人脸关键点检测_pfld人臉關鍵點檢測-程序员宅基地
文章浏览阅读5.2k次,点赞21次,收藏92次。PFLD:A Pratical Facial Landmark Detector论文下载1. 网络简介人脸关键点检测任务是很多人脸相关任务的基础,比如换脸、人脸变换、人脸识别等等;现实中,人脸通常暴露在复杂环境中,同样的人脸图像可能因为姿势、表情、光线以及遮挡等问题而非常不同。采集同一个人在不同环境不同姿势情况下的数据集理论上可行,但是实际操作很难实现,因为所需的训练数据量太大了。作者总结了人脸关键点问题的四个难点:局部变量影响(Local Variation):表情、局部光照、阴_pfld人臉關鍵點檢測
java实现抽奖需求分析_Java开发游戏抽奖算法有哪些?-程序员宅基地
文章浏览阅读199次。Java开发游戏抽奖算法有哪些?抽奖算法根据需求而定,游戏抽奖算法在指定奖品的集合中,每个奖品根据对对应概率进行抽取。Java开发游戏抽奖算法主要有随机数一一对应、离散法Alias算法等。一、随机数一一对应1、随机数算法原理:将n个奖品编号0~n-1,其中各类奖品的概率通过其数量体现,最后程序产生0~n-1之间的随机数便是抽中的奖品编号。例如:苹果手机概率1%,网站会员20%,折扣券20%,很遗憾..._抽奖小游戏需求分析
随便推点
3 行代码写出 8 个接口,开挂了?网友:绝对不可能!!!-程序员宅基地
文章浏览阅读187次。点击上方“Java精选”,选择“设为星标”别问别人为什么,多问自己凭什么!下方留言必回,有问必答!每天08:35更新文章,每天进步一点点...肯定有不少人会想:这怎么可能呢?就算用几乎...
CNN卷积层神经元数量、连接数量、权重数量的计算_输入层神经元数量-程序员宅基地
文章浏览阅读2.8w次,点赞10次,收藏53次。1. 神经元的数量:和输入层类似,输出维度是多少,神经元就有多少feature map大小 * feature map数量2. 连接数量:全连接:输入层神经元数量*输出层神经元数量CNN局部连接: 故由于局部连接机制,卷积层的连接数为:局部连接的输入层神经元数*卷积层神经元数以alexnet为例:在第一个卷积层,神经元使用的感受野尺寸F=_输入层神经元数量
解决Android studio呈卡死的现象_android studio 打開時進度卡主-程序员宅基地
文章浏览阅读1.5w次,点赞3次,收藏3次。AS卡死问题修复_android studio 打開時進度卡主
2023年上半年系统规划与管理师下午真题及答案解析-程序员宅基地
文章浏览阅读247次,点赞3次,收藏6次。(25分)小李是跨国公司新任命的IT服务经理,帮助提升中国区总部的IT服务管理水平。中国区总部的运维管理体系运营了近三年,内外部环境发生了很多变化,其中:(1)内部变化包括团队组织结构调整、部分团队精简改为外包支持、IT服务工作承接了一部分原来由海外团队支持的内容等;(2)外部变化包括部分项目的业务连续性要求提升、部分项目的安全等级必须满足国家要求等。
中国进入科研黄金时代,通用超算云服务填补算力缺口_高校科研教学算力缺口-程序员宅基地
文章浏览阅读295次。“自主创新”是十四五规划献策中呼声最高的关键词之一。而在十四五规划中,也提出要坚持创新在我国现代化建设全局中的核心地位,把科技自立自强作为国家发展的战略支撑。尤其是十九届五中全会,审议通过了将实现关键核心技术重大突破,进入创新型国家前列列为国家二〇三五年远景目标。在加强自主创新中,科研R&D经费投入是重要的保障,我国在2018年就已经实现R&D经费总量全球第二,而2019年全国R&D经费投入同比增长12.5%,占GDP的2.23%。当前,无论是从十四五规划对自主创..._高校科研教学算力缺口
【挖洞经验】url重定向漏洞绕过-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏11次。 url重定向绕过方式 俗话说的好,上有政策,下有对策,url重定向的绕过姿势也越来越多样化。普通url重定向方法测试不成功,换个姿势,说不定可以再次绕过。 这里总结下成功的绕过方式。 (1) 使用#或者@或者?或者\来绕过 这个是比较常见的绕过方式,利用程序或者浏览器..._url重定向漏洞绕过