深度学习入门(二十六)卷积神经网络——池化层_卷积神经网络池化层计算-程序员宅基地
深度学习入门(二十六)卷积神经网络——池化层
前言
核心内容来自博客链接1博客连接2希望大家多多支持作者
本文记录用,防止遗忘
卷积神经网络——池化层
课件
池化层
卷积对位置敏感
检测垂直边缘:

1像素的移位导致0输出
需要一定程度的平移不变性
- 照明,物体位置,比例,外观等等因图像而异
二维最大池化
返回滑动窗口中的最大值
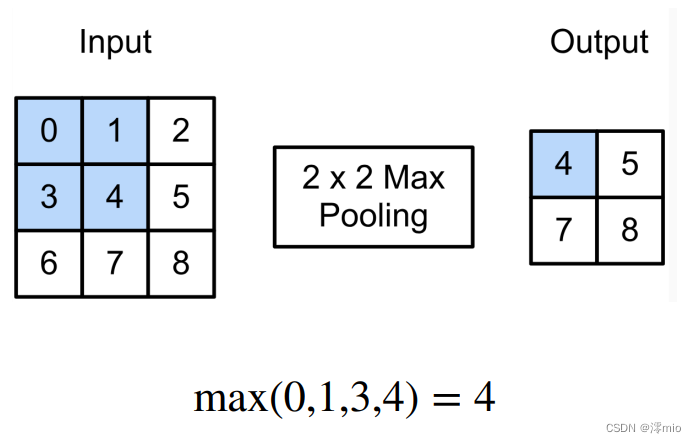

可以接受一个像素的移位填充、步幅和多个通道
- 池化层与卷积层类似,都具有填充和步幅
- 没有可学习的参数
- 在每个输入通道应用池化层以获得相应的输出通道
- 输出通道数=输入通道数
平均池化层
最大池化层:每个窗口中最强的模式信号
平均池化层:将最大池化层中的“最大”操作替换为“平均”

总结
- 池化层返回窗口中最大或平均值
- 缓解卷积层会位置的敏感性
- 同样有窗口大小、填充、和步幅作为超参数
教材
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。
而我们的机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以我们最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
此外,当检测较底层的特征时(例如之前讨论的边缘),我们通常希望这些特征保持某种程度上的平移不变性。例如,如果我们拍摄黑白之间轮廓清晰的图像X,并将整个图像向右移动一个像素,即Z[i, j] = X[i, j + 1],则新图像Z的输出可能大不相同。而在现实中,随着拍摄角度的移动,任何物体几乎不可能发生在同一像素上。即使用三脚架拍摄一个静止的物体,由于快门的移动而引起的相机振动,可能会使所有物体左右移动一个像素(除了高端相机配备了特殊功能来解决这个问题)。
本节将介绍池化(pooling)层,它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
1 最大池化层和平均池化层
与卷积层类似,池化层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。 然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。 相反,池运算是确定性的,我们通常计算池化窗口中所有元素的最大值或平均值。这些操作分别称为最大池化层(maximum pooling)和平均池化层(average pooling)。
在这两种情况下,与互相关运算符一样,池化窗口从输入张量的左上角开始,从左往右、从上往下的在输入张量内滑动。在池化窗口到达的每个位置,它计算该窗口中输入子张量的最大值或平均值。计算最大值或平均值是取决于使用了最大池化层还是平均池化层。

上图输出张量的高度为2,宽度为2。这四个元素为每个池化窗口中的最大值:
max ( 0 , 1 , 3 , 4 ) = 4 , max ( 1 , 2 , 4 , 5 ) = 5 , max ( 3 , 4 , 6 , 7 ) = 7 , max ( 4 , 5 , 7 , 8 ) = 8. \begin{split}\max(0, 1, 3, 4)=4,\\ \max(1, 2, 4, 5)=5,\\ \max(3, 4, 6, 7)=7,\\ \max(4, 5, 7, 8)=8.\\\end{split} max(0,1,3,4)=4,max(1,2,4,5)=5,max(3,4,6,7)=7,max(4,5,7,8)=8.池化窗口形状为 p × q p \times q p×q的池化层称为 p × q p \times q p×q池化层,池化操作称为池化。
回到本节开头提到的对象边缘检测示例,现在我们将使用卷积层的输出作为最大池化的输入。 设置卷积层输入为X,池化层输出为Y。 无论X[i, j]和X[i, j + 1]的值相同与否,或X[i, j + 1]和X[i, j + 2]的值相同与否,池化层始终输出Y[i, j] = 1。 也就是说,使用最大池化层,即使在高度或宽度上移动一个元素,卷积层仍然可以识别到模式。
在下面的代码中的pool2d函数,我们实现池化层的前向传播。 这类似于之前的corr2d函数。 然而,这里我们没有卷积核,输出为输入中每个区域的最大值或平均值。
import torch from torch import nn from d2l import torch as d2l def pool2d(X, pool_size, mode='max'): p_h, p_w = pool_size Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): if mode == 'max': Y[i, j] = X[i: i + p_h, j: j + p_w].max() elif mode == 'avg': Y[i, j] = X[i: i + p_h, j: j + p_w].mean() return Y我们可以构建上图的输入张量X,验证二维最大池化层的输出。
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) pool2d(X, (2, 2))输出:
tensor([[4., 5.], [7., 8.]])此外,我们还可以验证池化汇聚层。
pool2d(X, (2, 2), 'avg')输出:
tensor([[2., 3.], [5., 6.]])2 填充和步幅
与卷积层一样,池化层也可以改变输出形状。和以前一样,我们可以通过填充和步幅以获得所需的输出形状。 下面,我们用深度学习框架中内置的二维最大池化层,来演示池化层中填充和步幅的使用。 我们首先构造了一个输入张量X,它有四个维度,其中样本数和通道数都是1。
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) X输出:
tensor([[[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.], [12., 13., 14., 15.]]]])默认情况下,深度学习框架中的步幅与池化窗口的大小相同。 因此,如果我们使用形状为(3, 3)的池化窗口,那么默认情况下,我们得到的步幅形状为(3, 3)。
pool2d = nn.MaxPool2d(3) pool2d(X)输出
tensor([[[[10.]]]])填充和步幅可以手动设定。
pool2d = nn.MaxPool2d(3, padding=1, stride=2) pool2d(X)输出
tensor([[[[ 5., 7.], [13., 15.]]]])当然,我们可以设定一个任意大小的矩形池化窗口,并分别设定填充和步幅的高度和宽度。
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1)) pool2d(X)输出:
tensor([[[[ 5., 7.], [13., 15.]]]])3 多个通道
在处理多通道输入数据时,池化层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。 这意味着池化层的输出通道数与输入通道数相同。 下面,我们将在通道维度上连结张量X和X + 1,以构建具有2个通道的输入。
X = torch.cat((X, X + 1), 1) X输出;
tensor([[[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.], [12., 13., 14., 15.]], [[ 1., 2., 3., 4.], [ 5., 6., 7., 8.], [ 9., 10., 11., 12.], [13., 14., 15., 16.]]]])如下所示,池化后输出通道的数量仍然是2
pool2d = nn.MaxPool2d(3, padding=1, stride=2) pool2d(X)输出;
tensor([[[[ 5., 7.], [13., 15.]], [[ 6., 8.], [14., 16.]]]])4 小结
1、对于给定输入元素,最大池化层会输出该窗口内的最大值,平均池化层会输出该窗口内的平均值。
2、池化层的主要优点之一是减轻卷积层对位置的过度敏感。
3、我们可以指定池化层的填充和步幅。
4、使用最大池化层以及大于1的步幅,可减少空间维度(如高度和宽度)。
5、池化层的输出通道数与输入通道数相同。
智能推荐
Component One C# c1FlexGrid 帮助文档-程序员宅基地
文章浏览阅读4.6k次。Value-Mapped Lists(值映射列表) 功能描述:上述财产的ComboList确保单元格的值是从名单中挑选。由用户选择的值转换成列的适当类型和存储在网格,完全一样,如果用户已输入的值。在许多情况下,细胞能够承担来自明确列出的值,但是你想显示一个用户的实际价值的版本。例如,如果一个列包含的产品代码,您可能要存储的代码,但显示的产品名称来代替。这是通过的DataMa_c# c1flexgrid
1217 Arbitrage(最短路)_arbitrage is the use of discrepancies in currency-程序员宅基地
文章浏览阅读199次。ArbitrageProblem Description Arbitrage is the use of discrepancies in currency exchange rates to transform one unit of a currency into more than one unit of the same currency. For example, suppose tha_arbitrage is the use of discrepancies in currency
使用libjpeg库实现jpeg图片的缩放(缩略图)_libjpeg缩略图-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏12次。libjpeg库的交叉编译libjpeg库主要用于jpeg格式图片的编解码,其交叉编译过程如下1. 下载源码从官方网站http://www.ijg.org/files/ 下载libjpeg库的源码,本次编译过程使用的是 jpegsrc.v9a.tar.gz2. 解压源码2.1 切换到下载目录,执行 tar -xzvf jpegsrc.v9a.tar.g_libjpeg缩略图
Mysql 时间戳类型使用心得-程序员宅基地
文章浏览阅读209次。2019独角兽企业重金招聘Python工程师标准>>> ..._mysql 时间戳用什么类型合适
串口上升时间标准_JESD204B 串行接口时钟需要及其实现-程序员宅基地
文章浏览阅读221次。ChenAndyMNCsignalchainFAE摘要随着数模转换器的转换速率越来越高,JESD204B串行接口已经越来越多地广泛用在数模转换器上,其对器件时钟和同步时钟之间的时序关系有着严格需求。本文就重点讲解了JESD204B数模转换器的时钟规范,以及利用TI公司的芯片实现其时序要求。关键字:LMK04800,LMK04828,LMK1802,LMK01010,JESD204内容1.J..._204b接口支持哪种时钟
深度学习环境配置(pytorch)_mx330显卡能玩跑深度学习程序吗-程序员宅基地
文章浏览阅读2.3k次,点赞7次,收藏69次。显卡是一个硬件,需要有一个驱动才能够被我们计算机识别出来,在安装驱动的时候,会随着驱动安装一个叫做cuda driver的东西,cuda是可以让显卡进行并行运算的一个平台,当我们的计算机想利用显卡做一些并行运算的时候,它就可以通过cuda driver去操作显卡。那为什么需要虚拟环境呢,一个直接的原因,例如我们一个项目要用pytorch开发,而另一个要用tensorflow开发,这样,我们可以创建两个虚拟环境,在里面分别安装pytorch和tensorflow,两个虚拟环境中的包和库不会互相冲突。_mx330显卡能玩跑深度学习程序吗
随便推点
Python-Go python模块与包 - GO问题 - GO容量测试_python里的go是模块吗?-程序员宅基地
文章浏览阅读365次。python中自定义模块的简述模块 => python文件包 => 目录初始化 __init__.py => 初始化文件,当导入包的时候会自动执行python包中的文件是独立的,(与go区分)注意:当模块被导入的时候,模块中的代码都会被执行一次,建议每次导入模块的时候就导入模块的某个函数即可,否则很容易出现错误链接:https://pan.baidu.com/s/12jZiYPEmHDpWOQMlGTGEUQ?pwd=zouh提取码:zouh。_python里的go是模块吗?
Javascript 中 typeof 详解-程序员宅基地
文章浏览阅读68次。为什么80%的码农都做不了架构师?>>> ..._typeof content == 'boolean
Vue前端与Django后端实现前后端分离连接_vuedjango前后端分离-程序员宅基地
文章浏览阅读3.1k次,点赞9次,收藏31次。Vue前端与Django后端实现前后端分离连接_vuedjango前后端分离
问题解决之 RuntimeError: Couldn‘t load custom C++ ops. This can happen if your PyTorch XXX_runtimeerror: couldn't load custom c++ ops. this c-程序员宅基地
文章浏览阅读2.2w次,点赞11次,收藏66次。问题描述在深度学习环境 GPU 版 pytorch 下,运行代码出现报错,关键报错信息如下:RuntimeError: Couldn't load custom C++ ops. This can happen if your PyTorch and torchvision versions are incompatible, 大致的意思是说当前环境的 PyTorch 和 torchvision 版本不匹配,建议重新安装 PyTorch 和 torchvision。具体报错信息如下:Traceb_runtimeerror: couldn't load custom c++ ops. this can happen if your pytorch
极智开发 | 华为海思Hi35xx系列ARM32交叉编译opencv_海思 opencv 交叉编译-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。本教程详细记录了华为海思Hi35xx系列ARM32交叉编译opencv、zlib、libpng的方法。是上一篇x86环境源码编译opencv的姊妹篇。_海思 opencv 交叉编译
SpringBoot 数据库高效的数据访问及安全解决方案_springboot轻量数据库-程序员宅基地
文章浏览阅读1.9k次。随着互联网的飞速发展,网站流量越来越多,用户数据也越来越丰富,如何有效地存储、处理和检索数据成为了一个新的技术难题。Spring Boot 是 Spring 框架的一个轻量级开源框架,其在 JavaEE(Java Platform, Enterprise Edition)开发中扮演了重要角色。Spring Boot 提供了一种快速、方便的基于 Spring 的体系结构,从而使得 Java 开发人员能够更加关注业务逻辑而不是复杂的配置参数。_springboot轻量数据库