PCA主成分分析原理及其python代码复现-程序员宅基地
技术标签: python 机器学习 python数据分析 开发语言
PCA(主成分分析)是什么
降维算法:保留原始数据的关键信息
注意:在降维过程中,维度通常是指特征的数量,而不是空间的维度。
主成分分析(PCA)是一个常见的特征提取方法,它通过找到数据中的主成分(方差最大的方向)来实现降维。
通俗理解,就是寻找新的坐标系,使得数据尽可能分布在一个或几个坐标轴上,同时尽可能保留原先数据分布的主要信息,使原先高维度的信息,在转换后能用低维度的信息来保存。而新坐标系的坐标轴,称为主成分(Principal components, PC),这也就是PCA的名称来源。
为什么找方差最大的方向?
在信号处理领域中认为信号具有较大的方差,噪声有较小的方差;信噪比就是信号与噪声的方差比,越大意味着数据的质量越好。
PCA(主成分分析)用来干什么的,好处
通过保留主要特征来捕捉数据的重要结构,使得模型更快收敛。
展开来说,PCA去除噪声和不重要的特征,将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息,而且可以提升数据处理的速度。
PCA(主成分分析)怎么实现的(三步)
PCA方法的总结
标准化(去中心化);
从协方差矩阵或相关矩阵中获取特征向量和特征值,或执行奇异值分解SVD;
按降序对特征值进行排序,并选择 k k k个与最大特征值相对应的特征向量,其中 k k k是新特征子空间的维数( k ≤ p k≤p k≤p);
将选择的 k k k个特征向量构造为投影矩阵 W W W;
通过 W W W对原始数据集 X X X进行变换,得到 k k k维特征子空间 Y Y Y。
准备数据集
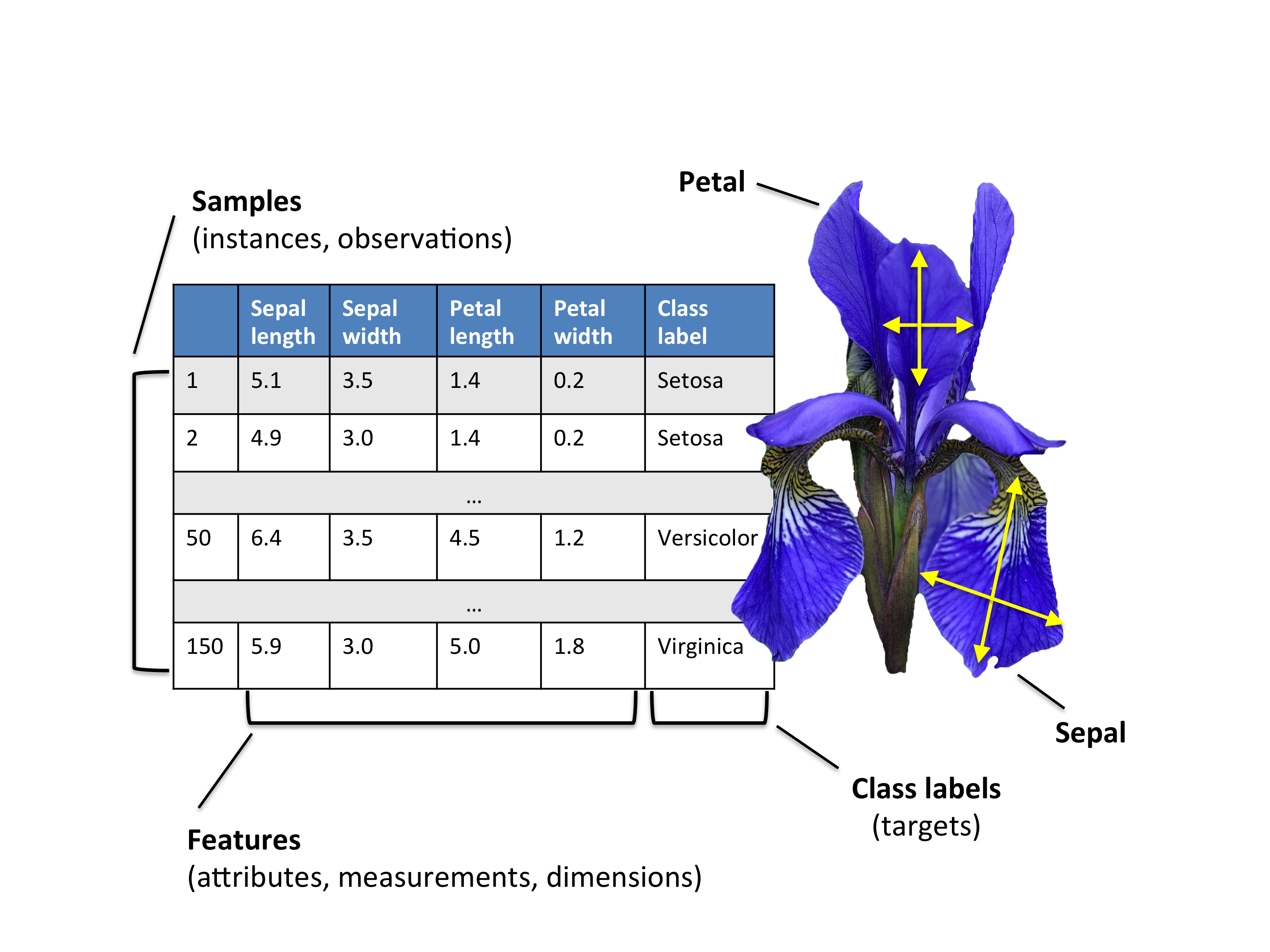
关于Iris数据集
scikit-learn中的鸢尾花数据集(Iris dataset),一共包含150张图片。
3种鸢尾花:山鸢尾(50张)、杂色鸢尾(50张)、维吉尼亚鸢尾(50张)。
4个特征:萼片长度(厘米)、萼片宽度(厘米)、花瓣长度(厘米)、花瓣宽度(厘米)。
加载数据集
加载数据集
import pandas as pd
# load-dataset
df = pd.read_csv(
filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None,
sep=',')
df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
df.dropna(how="all", inplace=True) # drops the empty line at file-end
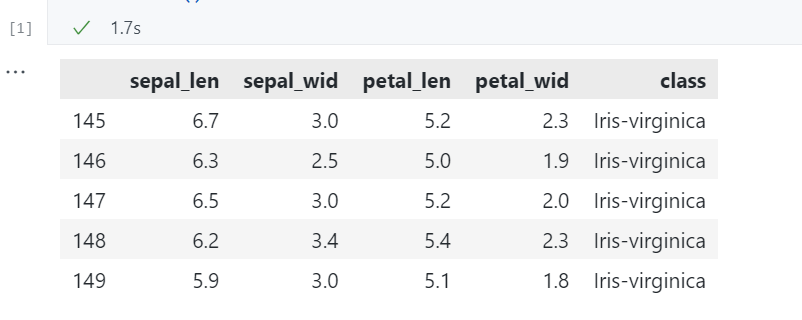
df.tail()
运行结果
划分成 数据 X X X、标签 y y y
# split data table into data X and class labels y
X = df.iloc[:, 0:4].values
y = df.iloc[:, 4].values
数据集为 150 × 4 150×4 150×4的矩阵,不同列代表不同特征,每行为1个样本,每个样本行x可以被描述为一个4维向量。
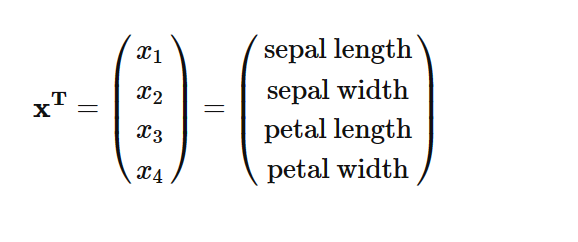
可视化数据分布
from matplotlib import pyplot as plt
import seaborn as sns
# 设置 seaborn 的样式为 whitegrid
sns.set_style("whitegrid")
label_dict = {
1: 'Iris-Setosa',
2: 'Iris-Versicolor',
3: 'Iris-Virgnica'}
feature_dict = {
0: 'sepal length [cm]',
1: 'sepal width [cm]',
2: 'petal length [cm]',
3: 'petal width [cm]'}
plt.figure(figsize=(8, 6))
for cnt in range(4):
plt.subplot(2, 2, cnt + 1)
for lab in ('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'):
plt.hist(X[y == lab, cnt],
label=lab,
bins=10,
alpha=0.3, )
plt.xlabel(feature_dict[cnt])
plt.legend(loc='upper right', fancybox=True, fontsize=8)
plt.tight_layout()
plt.show()
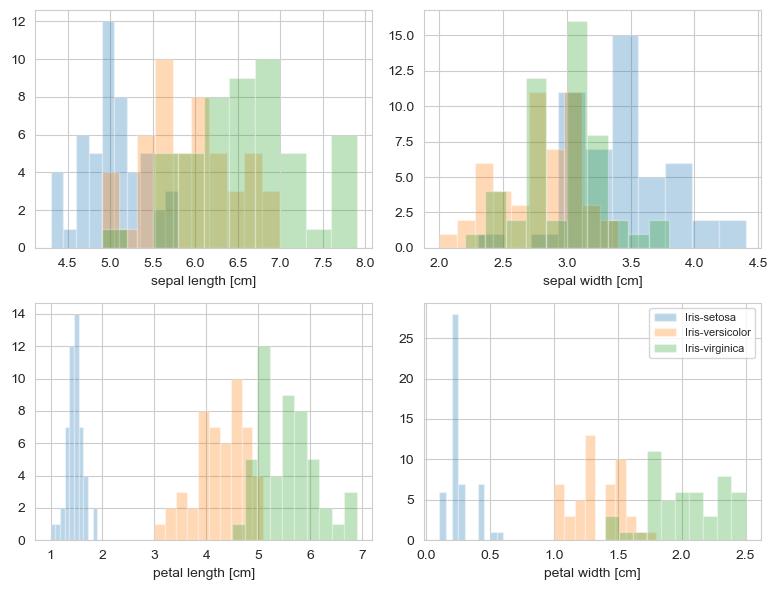
运行结果
标准化
归一化:将数据映射到[0,1]或[-1,1]区间范围内,不同特征的量纲不同,值范围大小不同,存在奇异值,对训练有影响。
标准化:将数据映射到满足标准正态分布的范围内,使数据满足均值为0,标准差为1。
去中心化:使数据满足均值为0,但对标准差没有要求。
每种方法对应的使用场景
1.若对数据的范围没有限定要求,则选择标准化进行数据预处理
2.若要求数据在某个范围内取值,则采用归一化。
3若数据不存在极端的极大极小值时,采用归一化。
4.若数据存在较多的异常值和噪音,采用标准化。
标准化过程如下:
1、计算每个特征(每一列,共p个特征)的均值 x i ˉ \bar{x_i} xiˉj和标准差 S j S_j Sj,公式如下: x i ˉ = 1 n ∑ i = 1 n x i j \bar{x_i}=\frac{1}{n}\sum_{i=1}^nx_{ij} xiˉ=n1i=1∑nxij S j = ∑ i = 1 n ( x i j − x j ˉ ) 2 n − 1 S_j=\sqrt{\frac{\sum_{i=1}^n(x_{ij}-\bar{x_j})^2}{n-1}} Sj=n−1∑i=1n(xij−xjˉ)2
2、将每个样本的每个特征进行标准化处理,得到标准化特征矩阵 X s t a n d X_{stand} Xstand:
X i j = x i j − x j ˉ S j X_{ij}=\frac{x_{ij}-\bar{x_j}}{S_j} Xij=Sjxij−xjˉ
X s t a n d = [ X 11 X 12 ⋯ X 1 p X 21 X 22 ⋯ X 2 p ⋮ ⋮ ⋱ ⋮ X n 1 X n 2 ⋯ X n p ] = [ X 1 , X 2 , ⋯ , X p ] X_{stand} = \begin{bmatrix} X_{11} & X_{12} & \cdots & X_{1p} \\ X_{21} & X_{22} & \cdots & X_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ X_{n1} & X_{n2} & \cdots & X_{np} \\ \end{bmatrix} = \left[ \mathbf{X}_1, \mathbf{X}_2, \cdots, \mathbf{X}_p \right] Xstand= X11X21⋮Xn1X12X22⋮Xn2⋯⋯⋱⋯X1pX2p⋮Xnp =[X1,X2,⋯,Xp]
标准化是沿着每个特征(即每列)独立进行的。换句话说,对于 X 中的每一列(即每一个特征),StandardScaler 会计算该列的均值和标准差,然后将该列中的每个值减去均值并除以标准差。
将数据单位厘米,转成单位尺度,且满足均值为0,标准差为1。
# 标准化(均值为0,标准差为1)
from sklearn.preprocessing import StandardScaler
X_std = StandardScaler().fit_transform(X)
第一步:特征分解——计算特征向量和特征值
第一种:特征分解
协方差矩阵(或相关矩阵)的特征向量和特征值代表PCA的“核心”:特征向量描述了数据的主要变化方向,而特征值则表示了在这些方向上的方差大小。
协方差矩阵
共p个特征,则计算得到的协方差矩阵为 p × p p×p p×p的方阵。
协方差矩阵计算公式
协方差矩阵 R R R:
R = [ r 11 r 12 ⋯ r 1 p r 21 r 22 ⋯ r 2 p ⋮ ⋮ ⋱ ⋮ r p 1 r p 2 ⋯ r p p ] R = \begin{bmatrix} r_{11} & r_{12} & \cdots & r_{1p} \\ r_{21} & r_{22} & \cdots & r_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ r_{p1} & r_{p2} & \cdots & r_{pp} \\ \end{bmatrix} R=
r11r21⋮rp1r12r22⋮rp2⋯⋯⋱⋯r1pr2p⋮rpp
两个特征 j、k 之间的协方差计算公式:
r j k = 1 n − 1 ∑ i = 1 n ( x i j − x ˉ j ) ( x i k − x ˉ k ) . r_{jk} = \frac{1}{n-1}\sum_{i=1}^{n}\left( x_{ij}-\bar{x}_j \right) \left( x_{ik}-\bar{x}_k \right). rjk=n−11i=1∑n(xij−xˉj)(xik−xˉk).
= 1 n − 1 ( ( X − x ˉ ) T ( X − x ˉ ) ) = \frac{1}{n-1} \left( (\mathbf{X} - \mathbf{\bar{x}})^T\;(\mathbf{X} - \mathbf{\bar{x}}) \right) =n−11((X−xˉ)T(X−xˉ))
其中, x ˉ \mathbf{\bar{x}} xˉ 是均值向量
x ˉ = 1 n ∑ i = 1 n x i . \mathbf{\bar{x}} = \frac{1}{n} \sum\limits_{i=1}^n x_{i}. xˉ=n1i=1∑nxi.
均值向量是⼀个p 维向量,其中该向量中的每个值代表数据集中特征列的样本均值。
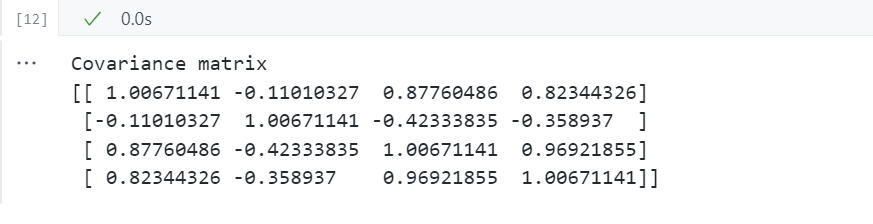
计算协方差矩阵
# 计算协方差矩阵
import numpy as np
mean_vec = np.mean(X_std, axis=0)
cov_mat = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0]-1)
print('Covariance matrix \n%s' %cov_mat)
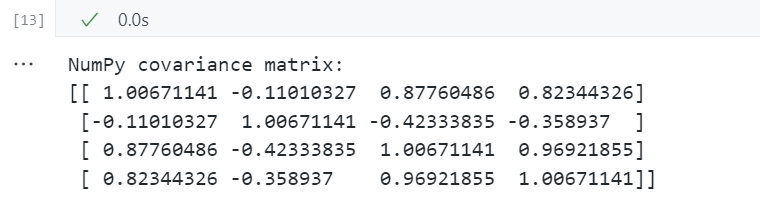
等价于np.cov
print('NumPy covariance matrix: \n%s' %np.cov(X_std.T))
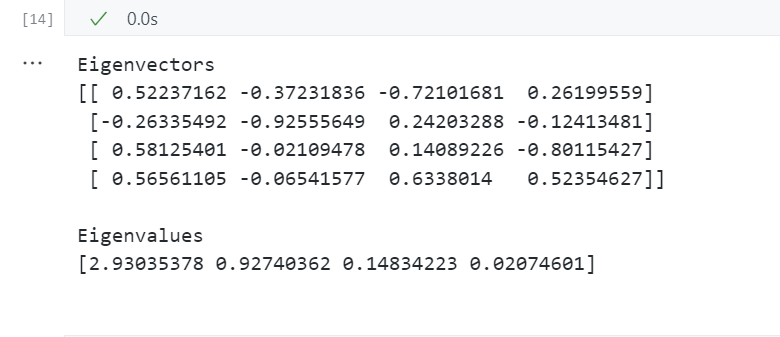
对协方差矩阵进行特征分解——计算特征向量、特征值
# 对协方差矩阵进行特征分解
cov_mat = np.cov(X_std.T) # 在标准化后的数据上,计算协方差矩阵
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print('Eigenvectors \n%s' %eig_vecs) # 特征向量
print('\nEigenvalues \n%s' %eig_vals) # 特征值
相关矩阵
特别是在“金融”领域,通常使用相关矩阵来代替协方差矩阵。但是,协方差矩阵的特征分解(如果输入数据已标准化)会产生与相关矩阵的特征分解相同的结果,因为相关矩阵可以理解为归一化的协方差矩阵。
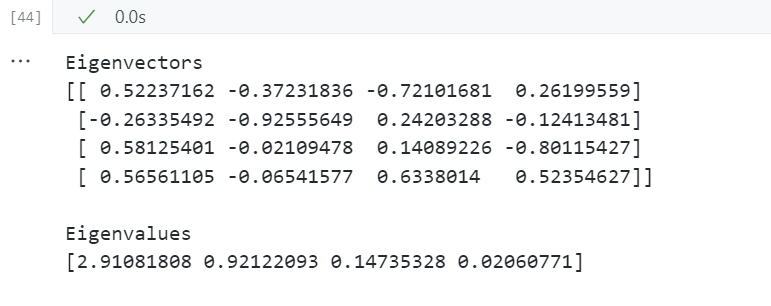
对相关矩阵进行特征分解——计算特征向量、特征值
对标准化后的数据
# 对标准化后的数据计算相关矩阵并进行特征分解
cor_mat1 = np.corrcoef(X_std.T) # 对标准化后的数据计算相关矩阵
eig_vals, eig_vecs = np.linalg.eig(cor_mat1)
print('Eigenvectors \n%s' %eig_vecs) # 特征向量
print('\nEigenvalues \n%s' %eig_vals) # 特征值
对原始数据
# 对原始数据计算相关矩阵并进行特征分解
cor_mat2 = np.corrcoef(X.T) # 对原始数据计算相关矩阵
eig_vals, eig_vecs = np.linalg.eig(cor_mat2)
print('Eigenvectors \n%s' %eig_vecs) # 特征向量
print('\nEigenvalues \n%s' %eig_vals) # 特征值
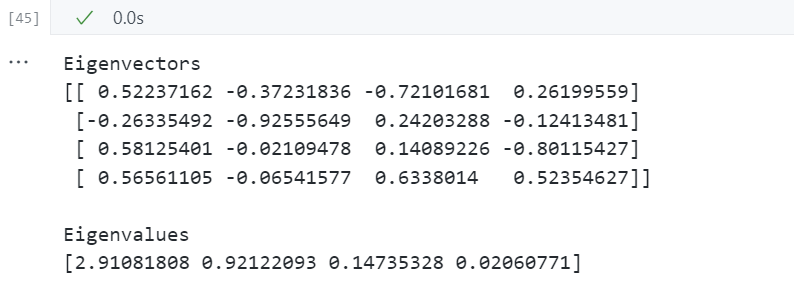
总结
以上三种方法的特征分解结果相同,即计算出的特征向量和特征值都一样:
数据标准化后协方差矩阵的特征分解;
数据标准化后相关矩阵的特征分解;
原始数据相关矩阵的特征分解。
第二种:奇异值分解SVD
PCA通过特征分解找到使方差最大化的正交基,实现数据的降维和特征提取。
然而,特征分解只适用于方阵(协方差矩阵为方阵),而现实中的数据矩阵往往不是方阵。这时,奇异值分解(SVD)就派上了用场。SVD是一种能适用于任意矩阵的分解方法,它并不要求分解的矩阵为方阵。
得到的左奇异矩阵 u u u是特征分解的特征向量;得到的奇异值 s s s与特征分解的特征值类似表示方差的大小。
# 奇异值分解SVD
u,s,v = np.linalg.svd(X_std.T)
u,s
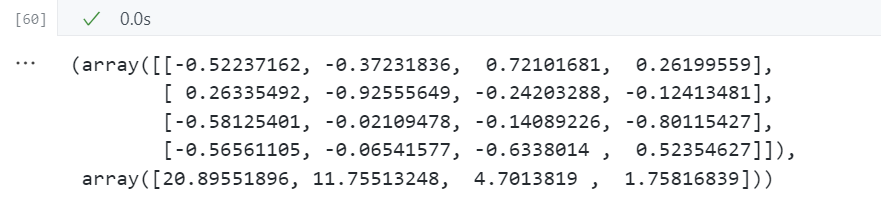
第二步:选择主成分
对特征进行排序
按降序对特征值进行排序,并选择 k k k个与最大特征值相对应的特征向量,其中 k k k是新特征子空间的维数( k ≤ p k≤p k≤p)
# Make a list of (eigenvalue, eigenvector) tuples
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
# Sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs.sort(key=lambda x: x[0], reverse=True)
# Visually confirm that the list is correctly sorted by decreasing eigenvalues
print('Eigenvalues in descending order:')
for i in eig_pairs:
print(i[0])
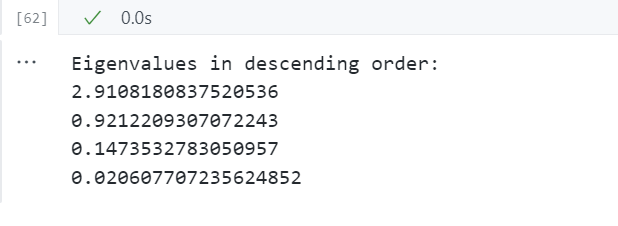
为新特征子空间选择多少个主成分(k值取多少)合适?
计算主成分贡献率及累计贡献率
第 i i i个主成分的贡献率, λ i \lambda_i λi代表第 i i i个特征向量的特征值:
λ i ∑ k = 1 p λ k \frac{\lambda_i}{\sum_{k=1}^{p}\lambda_k} ∑k=1pλkλi
前 i i i个主成分的累计贡献率:
∑ j = 1 i λ j ∑ k = 1 p λ k \frac{\sum_{j=1}^i{\lambda_j}}{\sum_{k=1}^{p}\lambda_k} ∑k=1pλk∑j=1iλj
一般取累计贡献率超过80%的特征值所对应的第一、第二、…、第m(m ≤ p)个主成分
tot = sum(eig_vals)
var_exp = [(i / tot)*100 for i in sorted(eig_vals, reverse=True)]
cum_var_exp = np.cumsum(var_exp)
plt.figure(figsize=(6, 4))
plt.bar(range(4), var_exp, alpha=0.5, align='center',
label='individual explained variance')
plt.step(range(4), cum_var_exp, where='mid',
label='cumulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
plt.tight_layout()
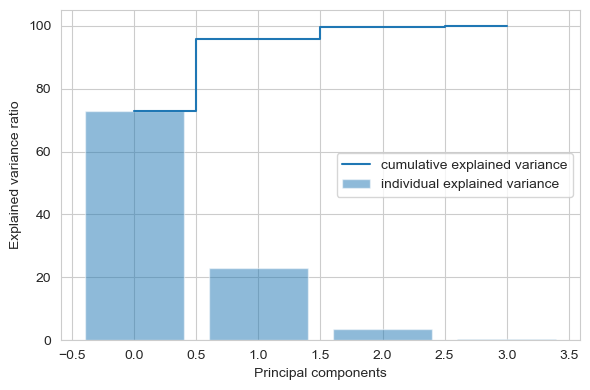
上图清楚地表明,大部分方差(准确地说是方差的72.77%)可以单独由第一个主成分来解释。第二个主成分仍然包含一些信息(23.03%),而第三和第四主成分可以安全地删除而不会丢失太多信息。前两个主成分合计包含95.8%的信息。
构建投影矩阵
将选择的 k k k个特征向量连接为投影矩阵 W W W,该矩阵用于将数据映射到新的特征子空间。
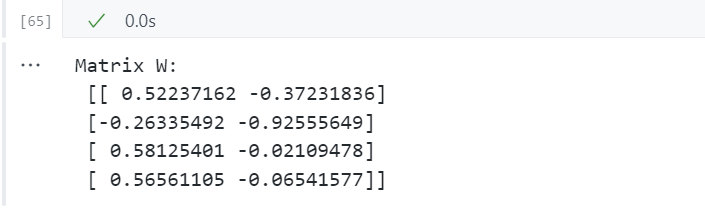
在这个例子里,选择具有最高特征值的前2个特征向量来构建我们的特征向量,将 4 维特征空间简化为 2 维特征子空间 p × k p×k p×k维投影矩阵 W W W。
matrix_w = np.hstack((eig_pairs[0][1].reshape(4,1),
eig_pairs[1][1].reshape(4,1)))
print('Matrix W:\n', matrix_w)
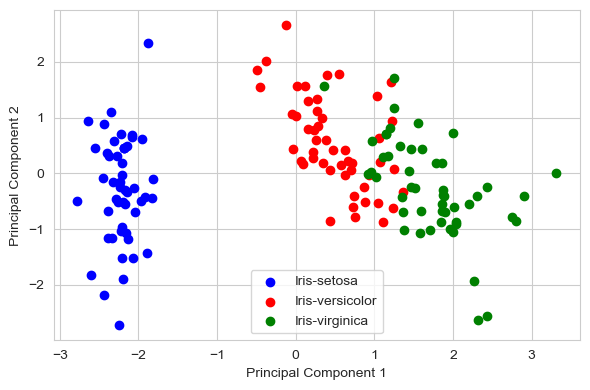
第三步:投影到新特征空间
通过投影矩阵 W W W对原始数据集 X X X进行变换,得到 k k k维特征子空间 Y Y Y。
在最后⼀步中,我们将使用4 × 2维投影矩阵 W W W通过方程 Y = X × W Y=X×W Y=X×W将样本转换到新的子空间,其中 Y Y Y是 150 × 2 150×2 150×2的矩阵。
Y = X_std.dot(matrix_w)
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(Y[y==lab, 0],
Y[y==lab, 1],
label=lab,
c=col)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(loc='lower center')
plt.tight_layout()
plt.show()
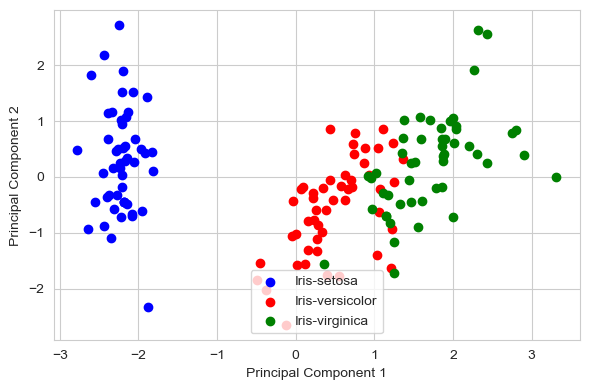
scikit-learn 库中的 PCA
from sklearn.decomposition import PCA as sklearnPCA
sklearn_pca = sklearnPCA(n_components=2)
Y_sklearn = sklearn_pca.fit_transform(X_std)
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(Y_sklearn[y==lab, 0],
Y_sklearn[y==lab, 1],
label=lab,
c=col)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(loc='lower center')
plt.tight_layout()
plt.show()
智能推荐
C. Foe Pairs_c. foe pairs time limit per test1 second memory li-程序员宅基地
文章浏览阅读1k次。C. Foe Pairstime limit per test1 secondmemory limit per test256 megabytesinputstandard inputoutputstandard outputYou are given a permutation p of length n. Al_c. foe pairs time limit per test1 second memory limit per test256 megabytes
Lite-HRNet 轻量级的HRNet 转onnx_hrnet 移动端-程序员宅基地
文章浏览阅读3.6k次,点赞4次,收藏20次。上个月cvpr2021出了轻量级的hrnet,依旧是MSRA的作品,这个系列都连着三年的cvpr了,太强了!假期结束才有想着去看看文章。简单看了看,发现flops降得好低啊,效果还不赖,于是尝试将模型转为onnx。关于文章内容的讲解,网上已经有不少了,例如Lite-HRNet讲解,主要的点是将ShuffleNet中的结构应用于HRNet中得到Naive Lite-HRNet,再用一个轻量级的单元conditional channel weighting替换可分离卷积中poinewise的1x1卷积,_hrnet 移动端
云服务器Linux 运行Docker容器并外部访问Mysql/MongoDB/_linux配置docker外部访问-程序员宅基地
文章浏览阅读1.2k次。1、Linux安装Docker操作系统说明我这里使用Xshell来远程连接主机。我的系统是CentOS7的版本,算是一个比较老的版本。没有用CentOS 8 的主要原因是服务器配置太低,达不到安装CentOS 8的要求。如果你使用的是Ubuntu系统或者其他版本的LInux系统,不用担心,安装方法几乎是一样的。因为这种安装方法是相对简单快速。开始安装Docker安装我们直接使用shell脚本来进行安装,安装脚本的地址如下。get.docker.com可以直接使用curl命令下载这个shel_linux配置docker外部访问
python将txt文件转为字符串_Python文件如何转换为字符串-程序员宅基地
文章浏览阅读5.6k次。Python文件如何转换为字符串一、最方便的方法是一次性读取文件中的所有内容并放置到一个大字符串中:all_the_text = open('thefile.txt').read( ) # 文本文件中的所有文本all_the_data = open('abinfile','rb').read( ) # 二进制文件中的所有数据为了安全起见,最好还是给打开的文件对象指定一个名字,这样在完..._python把txt文本变成字符串
搭建idea激活服务器_idea2023 license server-程序员宅基地
文章浏览阅读2.6k次。http://blog.lanyus.com/archives/174.html运行命令:nohup ./IntelliJIDEALicenseServer_linux_amd64 > info.log &服务器: http://vps.wiwikiky.top:1027关闭: lsof -i:1027 关闭相应的进程。..._idea2023 license server
python高斯噪声怎么去除_OpenCV 常用总结(Python)-程序员宅基地
文章浏览阅读3.5k次,点赞9次,收藏38次。最近一直在用cv2,记录一下常用的一些操作和代码吧。首先放OpenCV 的python官方文档链接:Welcome to OpenCV-Python Tutorials’s documentation!OpenCV 教程 - OpenCV 2.3.2 documentation主要用的模块大概分为以下几类:图片读写,2. 图像滤波,3.图像增强,4.阈值分割,5.形态学操作,当然还有其他。。。绪论..._如何去除高斯噪声
随便推点
2024届【校招】安全面试题和岗位总结(字节、百度、腾讯、美团等大厂)_百度安全工程师面试笔试-程序员宅基地
文章浏览阅读1.5w次,点赞8次,收藏64次。个人强烈感觉面试因人而异,对于简历上有具体项目经历的同学,个人感觉面试官会着重让你介绍自己的项目,包括但不限于介绍一次真实攻防/渗透/挖洞/CTF/代码审计的经历 => 因此对于自己的项目,面试前建议做一次复盘,最好能用文字描述出细节,在面试时才不会磕磕绊绊、或者忘了一些自己很得意的细节面试题会一直更新(大概,直到我毕业或者躺平为止吧...)包括一些身边同学(若他们同意的话)和牛客上扒拉下来的(若有,会贴出链接)还有自己的一些经历。_百度安全工程师面试笔试
新型数据中心如何实现节能降耗-程序员宅基地
文章浏览阅读373次。“数据中心的高能耗,不仅给企业带来了沉重的负担,也造成了全社会能源的巨大浪费。”中国数据中心节能技术委员会秘书长吕天文对记者表示,在当前中国数据中心建成后,电费占运维总成本60%-70%,而空调所用电费在其中占40%左右。吕天文说,此次会议的目的,就是围绕数据中心的节能增效、云计算和工业4.0产业互联网时代下的数据中心智慧运营,共同探讨数据中心基础设施..._数据中心怎样才能节能减耗步骤
C# MATLAB混合编程-程序员宅基地
文章浏览阅读79次。我附带把matlab配置过程也给大家上传上来。【转载】终于学会C#调用matlab函数了,原来这么简单(也可以下载附件查看)自己的配置:(1)Microsoft Visual Studio 2005(2)Matlab R2009a(3)iis 6.0第一步:首先安装Matlab;安装Visual Studio 2005或者更高版本;安装MCRInstall.exe,我安装完Matlab之后在这里找..._c# matlab混编
java.applet,浅谈java.applet 部分方法_java applet-程序员宅基地
文章浏览阅读863次。java.applet_java applet
Qt:甘特图控件_qt绘制甘特图-程序员宅基地
文章浏览阅读6.2k次,点赞6次,收藏60次。本文介绍了如何在Qt4中自定义View控件实现甘特图效果。_qt绘制甘特图
Mvi架构浅析-程序员宅基地
文章浏览阅读1.4k次。快速了解Mvi在项目中的使用_mvi