【深度学习】计算图像数据集的均值和标准差(mean、std)用于 transform 标准化(Imagefolder)_计算所有图像的均值与标准差值-程序员宅基地
技术标签: python 深度学习 # Python 均值算法 使用说明
【深度学习】计算图像数据集的均值和标准差(mean、std)用于 transform 标准化
文章目录
1. 介绍
相信大家对每一个图像数据集预处理时都免不了一个normalize的步骤,在使用pytorch中torchvision.transoforms.Normalize()这个方法很好的帮助我们进行标准化的处理。可是他需要图像各个通道的均值以及标准差的参数,那我们要如何求呢?
- ImageFolder,需要有特定格式
- 自己实现,无需特定格式
2. 方法
2.1 ImageFolder,需要有特定格式
这时候要求我们传参为父目录,下面必须得有子目录。
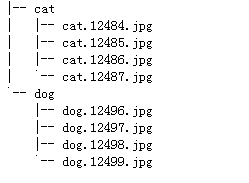
- 比如数据集一共包括两个类别:cat、dog,每个类别包括四张图片。所有的图片按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名。保存如下,dataset下有两个目录如下:
import torch
from torchvision.datasets import ImageFolder
def getStat(train_data):
'''
Compute mean and variance for training data
:param train_data: 自定义类Dataset(或ImageFolder即可)
:return: (mean, std)
'''
print('Compute mean and variance for training data.')
print(len(train_data))
train_loader = torch.utils.data.DataLoader(
train_data, batch_size=1, shuffle=False, num_workers=0,
pin_memory=True)
mean = torch.zeros(3)
std = torch.zeros(3)
for X, _ in train_loader:
for d in range(3):
mean[d] += X[:, d, :, :].mean()
std[d] += X[:, d, :, :].std()
mean.div_(len(train_data))
std.div_(len(train_data))
return list(mean.numpy()), list(std.numpy())
if __name__ == '__main__':
train_dataset = ImageFolder(root='dataset', transform=None)
print(getStat(train_dataset))
2.2 自己实现,无需特定格式
直接传入想要求的数据集目录即可,
import os
from PIL import Image
import numpy as np
import tqdm
def main(path):
# 数据集通道数
img_channels = 3
img_names = os.listdir(path)
cumulative_mean = np.zeros(img_channels)
cumulative_std = np.zeros(img_channels)
for img_name in tqdm.tqdm(img_names, total=len(img_names)):
img_path = os.path.join(path, img_name)
img = np.array(Image.open(img_path)) / 255.
# 对每个维度进行统计,Image.open打开的是HWC格式,最后一维是通道数
for d in range(3):
cumulative_mean[d] += img[:, :, d].mean()
cumulative_std[d] += img[:, :, d].std()
mean = cumulative_mean / len(img_names)
std = cumulative_std / len(img_names)
print(f"mean: {
mean}")
print(f"std: {
std}")
if __name__ == '__main__':
main("dataset/cat")
3. ImageFolder解析
ImageFolder是一个通用的数据加载器,数据集应当按照指定的格式进行存储。
3.1 数据集构造格式
比如数据集一共包括两个类别:cat、dog,每个类别包括四张图片。所有的图片按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名。dataset下有两个目录如下:
3.2 使用方法
from torchvision.datasets import ImageFolder
dataset=ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
3.2.1 参数
- root:在root指定的路径下寻找图片,比如,
import torchvision.datasets
dataset = ImageFolder('./dataset')
- transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象,比如,
import torchvision.datasets
transform = transforms.Compose([
transforms.Grayscale(),
transforms.Resize([28, 28]),
transforms.ToTensor(),
transforms.Normalize(mean=(0,0,0),std=(1,1,1))
])
dataset = ImageFolder('./dataset',transform=transform)
- target_transform:对label的转换。
3.2.2 成员变量
可以通过成员变量查看ImageFolder返回的内容。
- classes:根据分的文件夹的名字来确定的类别,如[‘cat’, ‘dog’]。
- class_to_idx:按顺序为这些类别定义索引为0,1…,如{‘cat’: 0, ‘dog’: 1}。
- imgs:返回从所有文件夹中得到的图片的路径以及其类别,一个列表,列表中的每个元素都是一个(img-path, class_index)的元组,如
- [(‘./dataset/cat/cat.12484.jpg’, 0), (‘./dataset/cat/cat.12487.jpg’, 0), (‘./dataset/dog/dog.12498.jpg’, 1), (‘./dataset/dog/dog.12499.jpg’, 1)]
3.2.3 ImageFolder返回的对象
如果不进行transform,返回PIL Image对象,进行transform,返回tensor。
- ImageFolder的返回值,
- 第一维代表的是第几张图片(所有类别的图片顺序排列),如dataset[0]代表第0张图片,即(‘./data/cat/cat.12484.jpg’, 0)。
- 第二维只有0和1两个值,0返回图片数据,1返回label。
智能推荐
python-18-正则表达式_python18-程序员宅基地
文章浏览阅读6.2k次。01-导入模块这里需要先写一个demo.pyclass Person(object): def __init__(self, name): self.name = name def eat(self, food): print(self.name + '正在吃' + food) def sleep(self): print(self.name + '正在睡觉')_p = Person('zhangsan')# p._python18
大型情感剧集Selenium:4_老中医教你(单/多/下拉框)选项定位-程序员宅基地
文章浏览阅读262次。又要开篇叨叨昨天没有更新,但因为下大雨没撸串,陪孩子玩了下前一天写的Flask开发猜数字小游戏---聪明的奥特曼,发现代码有些bug,进行了修改,另外只是名字叫聪明的奥特曼,我的俩爷不买账啊,没办法,将成功的alert改为展示奥特曼的图片,才把他俩打发。至于做对?别逗了,我都改成猜1-4了都各种错,就急着点完了看奥特曼,真是气死我了.....今天讲什么讲什么标题说了,讲sel..._python 根据title定位选项框
前端提高篇(九十四):jQuery鼠标事件-程序员宅基地
文章浏览阅读833次,点赞26次,收藏26次。javascript是前端必要掌握的真正算得上是编程语言的语言,学会灵活运用javascript,将对以后学习工作有非常大的帮助。掌握它最重要的首先是学习好基础知识,而后通过不断的实战来提升我们的编程技巧和逻辑思维。这一块学习是持续的,直到我们真正掌握它并且能够灵活运用它。如果最开始学习一两遍之后,发现暂时没有提升的空间,我们可以暂时放一放。继续下面的学习,javascript贯穿我们前端工作中,在之后的学习实现里也会遇到和锻炼到。真正学习起来并不难理解,关键是灵活运用。
IntelliJ:idea怎么设置eclipse快捷键_idea修改快捷键为eclipse-程序员宅基地
文章浏览阅读1k次。idea怎么设置eclipse快捷键_idea修改快捷键为eclipse
世界时间经纬_世界主要城市经纬度及时区列表-程序员宅基地
文章浏览阅读4.7k次。◎欧洲各地经纬度简表国家 城市 经度 纬度 时区 罗马尼亚 布加勒斯特 东经26:06 北纬44:26 +2保加利亚 索非亚 东经23:19 北纬42:41 +2希腊 雅典 东经23:43 北纬37:58 +2希腊 斯巴达 东经22:25 北纬37:05 +2马其顿 斯科普里 东经21:28 北纬42:00 +2波兰 华沙 东经21:00 北纬52:15 +1南斯拉夫 贝尔格莱德 东经20:30 ..._全球城市经纬度
ZOJ 2112 Dynamic Rankings (动态第k大,树状数组套主席树)_动态第k大 树状数组套平衡树-程序员宅基地
文章浏览阅读294次。题目链接:题目大意:询问一个区间的第k大 但是有操作会对某个位置的值进行改变 即动态第k大思路:树状数组套主席树普通主席树装未修改的数据树状数组套主席树装的是修改的数据,即修改操作在树状数组中进行#include #include #include #include #include #include #include #include #include _动态第k大 树状数组套平衡树
随便推点
LSF系统介绍_lsf分组-程序员宅基地
文章浏览阅读1.4w次。LSF系统介绍http://scc.ustc.edu.cn/zh_CN/ 中科大超算中心http://www.sccas.cn/gb/index.html 中科院超算中心http://www.ssc.net.cn/ 上涨超算中心LSF简介LSF(Load Sharing Facility)是分布资源管理的工具,用来调度、监视、分析联网计算机的负载。目的通过集中监控和调度,充分共享计算机的CPU_lsf分组
鸿蒙开发初体验-程序员宅基地
文章浏览阅读5.1k次。/ 今日科技快讯 /近日,字节跳动回应:由美国CFIUS调查及“总统令”引发对TikTok的大量关注与报道,其中有很多猜测和不实信息。真实情况是, 我们确实在与一些公司探讨合作方..._鸿蒙的开发
python 获取窗口句柄 模拟 点击按钮,python和pywin32实现窗口查找、遍历和点击-程序员宅基地
文章浏览阅读9.9k次,点赞5次,收藏45次。1.如何利用句柄操作windows窗体首先,获得窗体的句柄 win32api.FindWindows()第二,获得窗体中控件的id号,spy++第三,根据控件的ID获得控件的句柄(hwnd) GetDlgItem(hwnd,loginID)最后,利用控件句柄进行操作python可以通过win32api轻松获取控件的属性值通过标签找到主窗口句柄,然后通过主句柄获取下属控件句柄#-*- codin..._python 获取窗口句柄 模拟 点击按钮
以集群方式运行pyspark_spark.yarn.appmasterenv.pyspark_python-程序员宅基地
文章浏览阅读2.4k次。一、背景说明 单机执行pyspark(python on spark)非常简单,只要在脚本所在服务器上部署个python环境或Anaconda这种集成运行环境,再通过python3命令执行就完了。 而想将python提交到spark集群中运行,则有两种方法,一种是在每个spark结点上部署python环境,在spark低版本与python集成没那么完善的时候,集群结点数又不多的情况下,的确可以这么干(实际上我就这么干过),这种方式比较大的优势是每次执行pyspark任务时,不用分发python环_spark.yarn.appmasterenv.pyspark_python
Android修行手册 - 实现POI上万行的大数据量Excel读写操作,解决内存溢出_android 读取超大excel文件-程序员宅基地
文章浏览阅读1.5k次,点赞15次,收藏11次。搞过POI的都知道,在处理Excel文件时,POI提供了两种模式:用户模式和SAX事件驱动模式。用户模式API丰富使用起来相对简单,但当遇到大文件、大量数据或复杂格式时,可能会导致内存溢出。因此,官方推荐使用SAX事件驱动模式来解析大型Excel文件。开始想解决方法之前,我们要先知道 Excel2003与Excel2007 的区别。_android 读取超大excel文件
cordova通过原生实现自定义功能_cordova 连拍-程序员宅基地
文章浏览阅读1w次。先闲谈说下最近的微信要出的小程序吧,感觉确实很牛逼,革命说不上吧但是也是一个新的大的机遇。不得不承认腾讯有两个相当好的平台,一个是QQ,一个是微信,毕竟人数基数大,任何新的东西都会带来相当多的机会和挑战。那个小程序好像是基于react native,也是一种混合架构。最近整理整理下混合架构的知识,有时间也好好学习去。 好了开始正题吧。 最近研究cordova通过原生_cordova 连拍