算法设计与分析知识点整理-程序员宅基地
技术标签: 算法 算法设计与分析 动态规划 学习总结 知识点整理
前言
本文是针对算法设计与分析这门课的知识点整理,内容多来源于教科书以及我看到的一些优秀博文,其中我最推崇是《labuladong的算法小抄》,它的内容让我眼前一亮,不同于教科书的死板套路,它从不一样的角度去解读学习算法,语言通俗易懂,让我受益匪浅。
我特别喜欢其中说的一句话
计算机解决问题其实没有任何奇技淫巧,它唯一的解决办法就是穷举,穷举所有可能性。算法设计无非就是先思考“如何穷举”,然后再追求“如何聪明地穷举”。
一、算法的基本概念
算法是求解问题的一系列计算步骤,用来将输入数据转换为输出结果。
1.算法的基本特征
- 有限性
- 确定性
- 可行性
- 输入性
- 输出性
2.算法设计需要满足的目标
- 正确性
- 可使用性
- 可读性
- 健壮性
- 高效率和低存储需求
3.算法和程序的区别
一、形式不同
1、算法:算法在描述上一般使用半形式化的语言。
2、程序:程序是用形式化的计算机语言描述的。
二、性质不同
1、算法:算法是解决问题的步骤。
2、程序:程序是算法的代码实现。
三、特点不同
1、算法:算法要依靠程序来完成功能。
2、程序:程序需要算法作为灵魂。
二、时间复杂度计算
1.大O表示法
"大O表示法"表示程序的执行时间或占用空间随数据规模的增长趋势。大O表示法就是将代码的所有步骤转换为关于数据规模n的公式项,然后排除不会对问题的整体复杂度产生较大影响的低阶系数项和常数项。
- 只关注循环执行次数最多的那段代码
- 加法法则(总复杂度等于量级最大的那段代码的复杂度)
- 乘法法则(嵌套代码复杂度等于内外代码复杂度的乘积)
2.最坏和平均情况
指算法在所有输入I下的所执行基本语句的最多执行次数和平均次数
3.根据递归方程求解时间复杂度
3.1 根据递归树求解
①画递归图
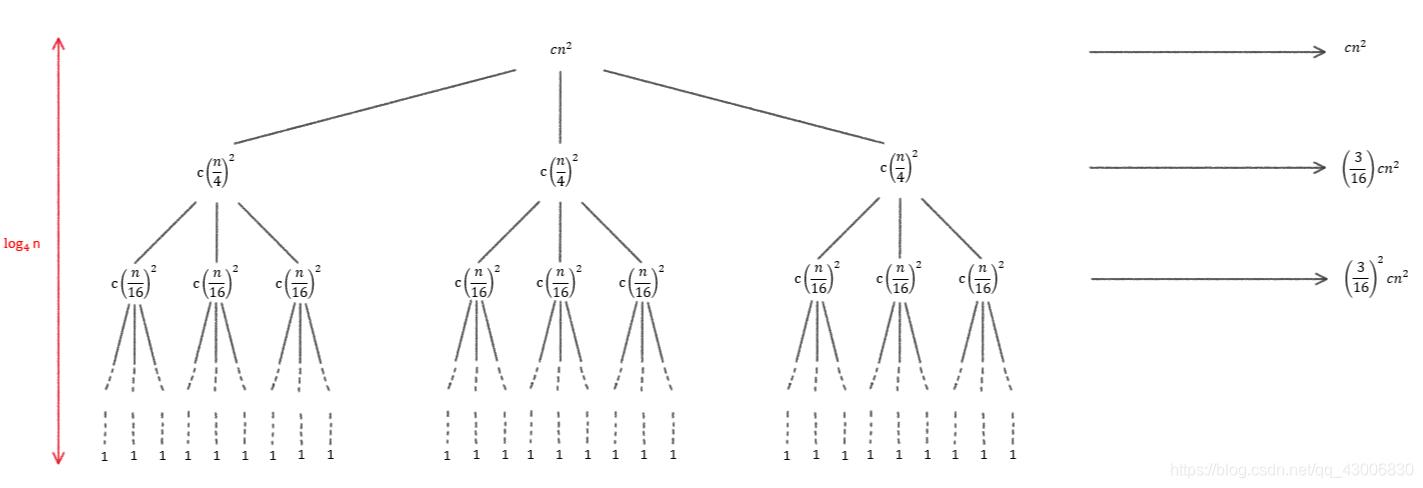
②相加化简得时间复杂度
3.2 根据主方法求解
主定理:a ≥ 1 和 b > 1,是常数,f ( n )是一个函数,T(n)是定义在非负整数上的递归式:
T(n) = aT(n/b) + f(n),
- 若对某个常数 ε>0 有 f ( n ) = O ( n l o g b a − ε ) f(n) = O(nlog_ba-ε) f(n)=O(nlogba−ε),则 T ( n ) = Θ ( n l o g b a ) T(n) = Θ(nlog_ba) T(n)=Θ(nlogba) 。
- 若 f ( n ) = Θ ( n l o g b a ) f(n) = Θ(nlog_ba) f(n)=Θ(nlogba),则 T ( n ) = Θ ( n l o g b a ∗ l g n ) T(n) = Θ(nlog_ba*lgn) T(n)=Θ(nlogba∗lgn)。
- 若对某个常数 ε>0 有 f ( n ) = Ω ( n l o g b a + ε ) f(n) = Ω(nlog_ba+ε) f(n)=Ω(nlogba+ε),且对某个常数 c<1 和所有足够大的 n 有 a f ( n / b ) ≤ c f ( n ) af(n/b) ≤ cf(n) af(n/b)≤cf(n),则 T ( n ) = Θ ( f ( n ) ) T(n) = Θ(f(n)) T(n)=Θ(f(n)) 。
三、六大算法
计算机解决问题其实没有任何奇技淫巧,它唯一的解决办法就是穷举,穷举所有可能性。算法设计无非就是先思考“如何穷举”,然后再追求“如何聪明地穷举”。
------《labuladong的算法小抄》
1.分治法
1.1 算法思路
先「分」后「治」,先按照运算符将原问题拆解成多个子问题,然后通过子问题的结果来合成原问题的结果。
1.2 适用范围
- 该问题的规模缩小到一定的程度就可以容易地解决
- 该问题可以分解成若干个规模较小的相似问题
- 利用该问题分解出的子问题可以合并为该问题的解
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题
1.3 基本步骤
①分解出若干个子问题
②求解子问题
③子问题合并
2.回溯法(DFS)
2.1 算法思路
解决一个回溯问题,实际上就是一个决策树的遍历过程。(其实就是穷举,如果配合着剪枝技巧就是聪明的穷举)
注:DFS使用的数据结构是栈,往往利用递归来解决(递归调用利用的就是系统栈)
2.2 算法步骤
①针对给定的问题确定解空间
②确定结点的拓展搜索规则
③以深度优先搜索(DFS)的方式搜索解空间树,并在搜索过程中可以采用剪枝函数来避免无效搜索。
2.3 算法框架
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径, 选择列表)
撤销选择
2.4 算法技巧
①剪枝函数——聪明的穷举
对于一些明显不符合题意的分支进行剪枝,避免无效穷举。
②数组交换
这个用于解空间为全排列树的情况,而且保存路径的方式为数组,此时可以对数组数据进行交换来保证排列中的每个元素不同。
3.分枝限界法(BFS)
虽然不喜欢官方的定义,但是为了更好理解这个名字,还是要了解以下概念:
分枝——使用广度优先的策略
限界——使用限界函数计算函数值(可以理解为权重)来决定遍历顺序
3.1 算法思路
和回溯法一样都是穷举决策树,不过分支限界法使用**广度优先遍历(BFS) **的方式穷举。
这种穷举方式使分支限界法有以下特点:
①BFS 找到的路径一定是最短的,但代价就是空间复杂度可能比 DFS 大很多
②适用于找到某种意义下的最优解(其实也可以选择遍历决策树找到找到符合条件的解,但是这样一来时间复杂度和DFS一样,但是空间复杂度却高了很多,得不偿失)
③在找最优解中,BFS往往时间复杂度更低,但空间复杂度更高(不需要像DFS那样遍历所有节点,但代价就是需要额外空间来存储至少一层的结点)
④往往用队列/优先队列的数据结构
3.2 算法框架
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
/* 划重点:更新步数在这里 */
step++;
}
}
3.3 算法技巧
①优先队列
优先弹出更优的结点,这样可以更快找到最优解。
②双向 BFS 优化
传统的 BFS 框架就是从起点开始向四周扩散,遇到终点时停止;而双向 BFS 则是从起点和终点同时开始扩散,当两边有交集的时候停止。
在算法实现上还有技巧,每次扩散结点时选择较小一端(较小的队列),如果我们每次都选择一个较小的集合进行扩散,那么占用的空间增长速度就会慢一些,效率就会高一些。
不过,双向 BFS 也有局限,因为你必须知道终点在哪里。
4.贪心法
4.1 算法思路
并不从全局最优上考虑,而是每次都做当前的局部最优选择。
虽然贪心不是对所有问题都能够得到全局最优解,但事实上很多问题都能够得到。
4.2 适用范围
使用贪心算法需要满足以下性质:
① 贪心选择性质
该性质是说所求问题的整体最优解可以通过一系列局部最优的选择来达到。而要确定一个问题是否具有这种性质,必须证明每一步所做的贪心选择最终会导致全局最优解。
②最优子结构性质
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。这种性质是问题可用动态规划或贪心解决的重要特征。
4.3 算法求解过程
①建立数学模型描述问题
②把求解的问题分成若干个子问题
③把每个子问题求解,得到子问题的局部最优解
④把子问题的局部最优解合成原来解问题的一个解
4.4 算法证明
其实很多时候我们能凭借生活经验和直觉判断出这就是个贪心问题,但是解题是最难的便是证明它。
我们可以去证明问题的贪心选择性质和最优子结构性质来证明贪心算法的正确性。
最优子结构的证明思路:
a) 定义子问题空间,做出一个选择从而产生一个或多个子问题。子问题空间的定义结合需要求解的目标和选择后子问题的描述刻画来考虑。
b) 利用“剪切-粘贴”证明作为最优解的组成部分的每个子问题的解也是它本身的最优解。如果子问题的解不是最优解,将其替换为对应的最优解从而一定能得到原问题一个更优的解,这与最初的解是原问题的最优解的前提假设矛盾,因此最优子结构得证。
贪心选择性质的证明思路:
贪心的本质是局部最优解能产生全局最优解,即产生两个子问题S1和S2时,可以直接解决子问题S1(在子问题S1中,使用贪心策略选择a作为局部最优解)然后对子问题S2进行分解,最终可以合并为全局最优解。
因此,要证明贪心选择性质只需要证明存在一个最优解是通过当前贪心选择策略得到的,反过来,即证明通过非贪心策略得到的原问题的最优解中也一定包含局部最优解a。
Exchange Argument方法
定义通过非贪心策略的选择可以得到的一个最优解A,将最优解中的元素和当前贪心策略会选择的元素逐个交换后得到的解A’并不比
A差(假设贪心策略会选择的元素在当前最优解中未被选择,通过“剪切-粘贴”证明得到的仍是最优解),可以证明存在原问题的最优解可以通过贪心选择得到。
5.动态规划
5.1 算法思路
把多阶段过程转化为一系列单阶段问题,并利用各阶段之间的关系逐个求解。
5.2 从穷举角度看动态规划
以下摘自《labuladong的算法小抄》
首先,动态规划问题的一般形式就是求最值。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多。
既然是要求最值,核心问题是什么呢?求解动态规划的核心问题是穷举。因为要求最值,肯定要把所有可行的答案穷举出来,然后在其中找最值呗。
动态规划这么简单,就是穷举就完事了?我看到的动态规划问题都很难啊!
首先,动态规划的穷举有点特别,因为这类问题存在「重叠子问题」,如果暴力穷举的话效率会极其低下,所以需要「备忘录」或者「DP table」来优化穷举过程,避免不必要的计算。
而且,动态规划问题一定会具备「最优子结构」,才能通过子问题的最值得到原问题的最值。
另外,虽然动态规划的核心思想就是穷举求最值,但是问题可以千变万化,穷举所有可行解其实并不是一件容易的事,只有列出正确的「状态转移方程」,才能正确地穷举。
计算机解决问题其实没有任何奇技淫巧,它唯一的解决办法就是穷举,穷举所有可能性。算法设计无非就是先思考“如何穷举”,然后再追求“如何聪明地穷举”。
列出状态转移方程,就是在解决“如何穷举”的问题。之所以说它难,一是因为很多穷举需要递归实现,二是因为有的问题本身的解空间复杂,不那么容易穷举完整。
备忘录、DP table 就是在追求“如何聪明地穷举”。用空间换时间的思路,是降低时间复杂度的不二法门,除此之外,试问,还能玩出啥花活?
5.3 适用范围
①最优化原理(最优子结构性质)
问题的最优解所包含的子问题的解也是最优的
②无后效性
某阶段的状态一旦确定,就不受这个状态以后决策的影响。
③有重叠子问题
子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到。
5.4 算法框架
# 初始化 base case
dp[0][0][...] = base
# 进行状态转移
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 求最值(选择1,选择2...)
5.5 三种常用思路(解题步骤)
下述思路往往是递进的关系
①暴力递归
暴力递归可不简单,要想暴力递归出解法,首先得知道状态转移方程
状态转移方程是用于前后阶段关系的
如何列出正确的状态转移方程?
1、确定 base case
2、确定「状态」,也就是原问题和子问题中会变化的变量
3、确定「选择」,也就是导致「状态」产生变化的行为
4、明确 dp 函数/数组的定义。
明确上述几点后,我们就能根据其写出状态转移方程,根据状态转移方程我们也就能很快写出对应的递归代码。
②带备忘录的递归
由于重叠子问题的存在,暴力递归的效率往往很低,原因在于会重复对某些状态进行递归。因此我们自然而然就想到可以通过备忘录的形式把每个状态的值记录下来,等下次再用到的时候就不用大费周章再去递归一遍,而是直接拿。
很显然「备忘录」大大减小了子问题数目,完全消除了子问题的冗余,做到了“聪明的穷举”。
③dp 数组的迭代解法
dp 数组的迭代解法和递归的思路很像,也是需要一个dp数组来记录状态,不过递归解法往往是一个自上而下的过程,而它是自下而上层层迭代的过程——由先前的状态迭代往后得出后面的状态。
这种自下而上的思路往往不符合人的惯性思维,解题时往往要搞清楚状态之间的先后关系,必须先遍历初始的状态,再根据状态慢慢演变得出后续的状态,在得到答案之前,它需要遍历所有状态。
当然这种解法往往存在一种技巧——状态压缩(或者叫做滚动数组),如果计算状态 dp[i][j] 需要的都是 dp[i][j] 相邻的状态,那么就可以使用状态压缩技巧,将二维的 dp 数组转化成一维,将空间复杂度从 O(N^2) 降低到 O(N)。
总结
递归写法往往更符合人的思考方式,可以更容易写出答案,自上而下的解法可以只对需要的状态求解,在一定程度上提高效率。
dp数组的迭代解法是一种自下而上的解题思路,需要明确状态的先后关系,往往不太符合人的思考方式,得到答案之前需要遍历所有状态。不过它可以用状态压缩/滚动数组的技巧来降低空间复杂度。
在解动态规划问题时,我们可以先从暴力递归入手,逐步去优化写出最终的答案,一般写到带备忘录的递归即可。
6.概率算法
6.1 数值概率算法
常用于解决数值计算的问题。该算法往往只能得到问题的近似解,并且该计算解的精度一般随着计算时间的增加而不断提高。
6.2 蒙特卡罗算法
蒙特卡罗算法用于求问题的准确解。蒙特卡洛算法1945年由冯诺依曼行核武模拟提出的。它是以概率和统计的理论与方法为基础的一种数值计算方法,它是双重近似:一是用概率模型模拟近似的数值计算,二是用伪随机数模拟真正的随机变量的样本。
当所求解问题是某种随机事件出现的概率,或者是某个随机变量的期望值时,通过某种“实验”的方法,以这种事件出现的频率估计这一随机事件的概率,或者得到这个随机变量的某些数字特征,并将其作为问题的解。
蒙特卡罗算法能求得问题的一个解,但这个解未必是正确的。求得正确解的概率依赖于算法所用的时间。算法所用的时间越多,得到正确解的概率就越高。蒙特卡罗算法的主要缺点就在于此。一般情况下,无法有效判断得到的解是否肯定正确。
示例问题:根据伪随机数求π
6.3 拉斯维加斯算法
拉斯维加斯算法不会得到不正确的解,一旦用拉斯维加斯算法找到一个解,那么这个解肯定是正确的。但是有时候用拉斯维加斯算法可能找不到解。与蒙特卡罗算法类似。拉斯维加斯算法得到正确解的概率随着它用的计算时间的增加而提高。对于所求解问题的任一实例,用同一拉斯维加斯算法反复对该实例求解足够多次,可使求解失效的概率任意小。
示例问题:求解n皇后
6.4 舍德伍算法
舍伍德算法总能求得问题的一个解,且所求得的解总是正确的。当一个确定性算法在最坏情况下的计算复杂性与其在平均情况下的计算复杂性有较大差别时,可以在这个确定算法中引入随机性将它改造成一个舍伍德算法,消除或减少问题的好坏实例间的这种差别。舍伍德算法精髓不是避免算法的最坏情况行为,而是设法消除这种最坏行为与特定实例之间的关联性。
四、计算复杂性理论
1.图灵机模型
图灵机是一种数学计算模型,它定义了一个抽象机器,该抽象机器根据规则表来操纵带子上的符号。尽管该模型很简单,但是在任何给定计算机算法的情况下,都可以构建出模拟该算法逻辑的图灵机。
简单点说,图灵机就是一个模拟算法运行的抽象机器。它是这样定义的:
- 有一个无限长度的磁带,这个磁带被分成了一个接一个的单元格,磁带被用于写入字母和符号。
- 一个读写磁带的磁头,这个磁头负责控制堆磁带的写入和左右移动。
- 一个状态寄存器,用来存储图灵机的状态。
- 一个指令表,可以根据机器当前所处的状态和磁带上当前的符号,指示机器进行特定的操作。比如:擦除或者写入一个符号、向左或者向右移动磁头。
①确定图灵机
在确定性图灵机(DTM)中,其控制规则规定了在任何给定情况下最多只能执行一个动作。
确定性图灵机具有转换功能,对于磁带头下的给定状态和符号,该转换功能指定了三件事:
要写入磁带的符号,头部应移动的方向(向左,向右或都不向),以及有限控制的后续状态。
例如,状态3的磁带上的X可能会使DTM在磁带上写Y,将磁头向右移动一个位置,然后切换到状态5。
①非确定图灵机
在理论计算机科学中,非确定性图灵机(NTM)是一种理论计算模型,其控制规则在某些给定情况下指定了多个可能的动作。 也就是说,NTM的下一个状态不是完全由其动作和它所看到的当前符号决定的(不同于确定性图灵机)。
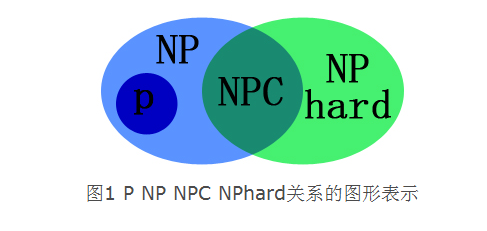
3.P、NP、NPC类问题
P问题:有多项式时间算法,算得很快的问题。
NP问题:算起来不确定快不快的问题,但是我们能在多项式时间内验证得出一个正确解的问题
NP-complete问题:存在这样一个NP问题,所有的NP问题都可以约化成它。换句话说,只要解决了这个问题,那么所有的NP问题都解决了。
NP-hard问题:比NP问题都要难的问题。
参考博文:
对上述框架思维的总结和概述 :: labuladong的算法小抄 (gitee.io)
用递归树方法求解递归式_疙瘩村村书记-程序员宅基地_递归树求解递归方程
智能推荐
node.js中mysql批量更新的三种方法_node mysql批量更新-程序员宅基地
文章浏览阅读8.9k次,点赞8次,收藏32次。在文章开始之前,我们先说下node.js中的mysql批量插入的方法,我们可以使用如下方法批量插入:var mysql = require('mysql')var values = [ [1, 'hu', 2], [2, 'ke', 0], [3, 'yi', 1]]var connection = mysql.createConnection({ host: 'loca..._node mysql批量更新
Git / 版本 / 分支 / 提测 ,一些常识&流程梳理。_统一分支提测-程序员宅基地
文章浏览阅读3w次。<< 写此文的缘由下午有同学,在群里问了几个问题。突然发现,大家对开发代码完事后,执行测试前的步骤、流程及具体细节不是很清楚 。之前招聘过程中,也发现很多同学,确实对这块的知识有欠缺 。特别是很多公司,由于开发同学,对测试同学的能力不太相信,让测试同学,介入的环节非常少 。什么都帮测试搞定了,测试只需在哪等着版本放到测试环境,调试通了,去执行测试即可 。从老徐的角度,对一个测试从业者的..._统一分支提测
MFC模拟AutoCAD 在单文本视图窗口任意位置输入文字_mfc 输入文字-程序员宅基地
文章浏览阅读1.2k次。本文介绍如果通过MFC编程实现模拟AutoCAD 在单文本视图窗口任意位置输入文字。先在VS2017中建一个名为FormatDemo单文档工程,在FormatDemoView.h中声明如下变量:public: COLORREF mColor; UINT linetype; LOGFONT logfont; CEdit mEdit; UINT drawType; CWnd* pwnd; BOOL drawTextFlag; CString str; CPoint mPoint;_mfc 输入文字
xstream 反序列化漏洞研究与修复_xstream不安全的序列号-程序员宅基地
文章浏览阅读4.5k次,点赞5次,收藏10次。文章目录1、简介2、举例3、漏洞4、修复1、简介xstream是一个用于序列化和反序列化的java库,主要是java对象和xml之间相互转换。XStream反序列化同fastjson这种不一样的地方是fastjson会在反序列化的时候主动去调用getters和setters,而XStream的反序列化过程中赋值都有Java的反射机制来完成,所以并没有这样主动调用的特性。特点使用方便 - XStream的API提供了一个高层次外观,以简化常用的用例无需创建映射 - XStream的API提供了默_xstream不安全的序列号
Java中BigDecimal异常Non-terminating decimal expansion; no exact representable decimal result_bigdecimal non-terminating decimal expansion; no e-程序员宅基地
文章浏览阅读3.6w次,点赞21次,收藏38次。异常描述:Exception in thread "main" java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.问题原因:因为BigDecimal的divide方法出现了无限循环小数解决办法:指定保留小数限定,如data.divide(da..._bigdecimal non-terminating decimal expansion; no exact representable decimal
SAP FICO 创建及修改成本中心_sap 更改成本中心 货币-程序员宅基地
文章浏览阅读2.9k次。业务要求 SAP 与OA 对接,客户从OA填完数据后在SAP端创建成本中心BAPI_COSTCENTER_CREATEMULTIPLE示例代码data:is_import TYPE zfis_oa_cos_cent_create_import.data:es_export TYPE zfis_oa_cos_cent_create_export.DATA: lt_costcenterlist TYPE TABLE OF bapi0012_ccinputlist, ls__sap 更改成本中心 货币
随便推点
How to enable the use of 'Ad Hoc Distributed Queries' by using sp_configure_a system administrator can enable the use of 'ad h-程序员宅基地
文章浏览阅读1.7k次。 转自:http://www.kodyaz.com/articles/enable-Ad-Hoc-Distributed-Queries.aspx If you are planning to use OpenRowset queries in order to connet to remote database servers or if you have already implemented OpenRowset queries as a solutio_a system administrator can enable the use of 'ad hoc distributed queries' by
NavigationBar 背景色设置_navigationbar背景色-程序员宅基地
文章浏览阅读1k次。一、设置导航条颜色 iOS 7.0及以上版本,使用下面的函数设置背景图片,图片需要提供320*64的1、2、3倍图 - (void)setBackgroundImage:(nullableUIImage *)backgroundImage forBarPosition:(UIBarPosition)barPosition barMetrics:(UIBarMetrics)b_navigationbar背景色
spring小结_spring团队多少人-程序员宅基地
文章浏览阅读2.3k次。spring 下载下载地址:http://repo.spring.ioSPRING框架——由来和发展 Spring是java平台上的一个开源应用框架。它的第一个版本是由Rod Johnson写出来的。Rod在他的Expert One-On-One Java EE Design and Development(Java企业应用设计与开发的专家一对一)一书中首次发布了这个_spring团队多少人
Win7电脑连接Win10\Win11共享打印机提示0x0000011b的解决办法_win7系统连接win10系统共享打印机提示0x000000011b-程序员宅基地
文章浏览阅读579次。Win7电脑连接Win10\Win11作为共享打印机服务器时,能看到打印机,但连接失败,详细信息显示0x0000011b的解决办法。_win7系统连接win10系统共享打印机提示0x000000011b
ExtJs知识点概述_ext4.5框架-程序员宅基地
文章浏览阅读1.4w次,点赞6次,收藏18次。1.前言ExtJS的前身是YUI(Yahoo User Interface)。经过不断的发展与改进,ExtJS现在已经成功发布到了ExtJS 6版本,是一套目前最完整和最成熟的javascript基础库之一,利用ExtJS构建的WEB应用具有与桌面程序一样的标准用户界面和操作方式,并能够跨不同的浏览器平台使用。就目前的市场趋势,现在用户对体验的要求越来越高。涌现出很多优秀的前台java_ext4.5框架
ES6语法新特性_es6语法 特性-程序员宅基地
文章浏览阅读996次,点赞4次,收藏12次。ES6语法新特性为什么要学习 ES6let 关键字不允许重复声明块儿级作用域(局部变量):不存在变量提升:不影响作用域链:let案例:点击div更改颜色应用场景const 关键字声明必须赋初始值:不允许重复声明:值不允许修改:块儿级作用域(局部变量):应用场景:变量和对象的解构赋值应用场景:模板字符串应用场景:简化对象和函数写法为什么要学习 ES6ES6 的版本变动内容最多,具有里程碑意义;ES6 加入许多新的语法特性,编程实现更简单、高效;ES6 是前端发展趋势,就业必备技能;let 关键字_es6语法 特性