hive(一)hive的安装与基本配置_hive安装与配置详解-程序员宅基地
技术标签: hive
目录
一、前提:
安装hive所需要的虚拟机环境为虚拟机安装有Hadoop并且集群成功,同时Hadoop需要在启动状态下,同时需要安装有mysql。不需要有zookeeper和HA,由于HA中含有大量进程,启动会占用很多资源,建议不要有HA
二、安装步骤:
1、上传jar包至/usr/local/soft
将hive-3.1.2上传到虚拟机中的/usr/local/soft目录下
2、解压并重命名
tar -zxvf apache-hive-3.1.2-bin.tar.gz
# 重命名
mv apache-hive-3.1.2-bin hive-3.1.2/
3、配置环境变量
vim /etc/profile
#增加以下内容:
# HIVE_HOME
export HIVE_HOME=/usr/local/soft/hive-3.1.2/
export PATH=$PATH:$HIVE_HOME/bin
#保存退出 source 使其生效
source /etc/profile
三、配置HIVE文件
1、配置hive-env.sh
cd $HIVE_HOME/conf
# 复制命令
cp hive-env.sh.template hive-env.sh# 编辑
vim hive-env.sh# 增加如下内容
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/soft/hive-3.1.2/conf
2、配置hive-site.xml
上传hive-site.xml到conf目录:
hive-site.xml文件内容:
<configuration>
<property>
<!-- 查询数据时 显示出列的名字 -->
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<!-- 在命令行中显示当前所使用的数据库 -->
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<!-- 默认数据仓库存储的位置,该位置为HDFS上的路径 -->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 8.x -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=GMT</value>
</property>
<!-- 8.x -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- hiveserver2服务的端口号以及绑定的主机名 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
</configuration>3、配置日志
# 创建日志目录
cd $HIVE_HOME
mkdir log# 设置日志配置
cd confcp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties
# 修改以下内容:
property.hive.log.dir = /usr/local/soft/hive-3.1.2/log
4、修改默认配置文件
cp hive-default.xml.template hive-default.xml
5、上传MySQL连接jar包
上传 mysql-connector-java-5.1.37.jar 至 /usr/local/soft/hive/lib目录中
四、修改MySQL编码
修改mysql编码为UTF-8:
1、 编辑配置文件
vim /etc/my.cnf
2、加入以下内容:
[client]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_general_ci
3、 重启mysql
systemctl restart mysqld
五、初始化HIVE
schematool -dbType mysql -initSchema
六、进入hive
输入命令:hive
七、后续配置
修改mysql元数据库hive,让其hive支持utf-8编码以支持中文
登录mysql:
mysql -u root -p123456
切换到hive数据库:
use hive;
1).修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
2).修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
3).修改分区表参数,以支持分区键能够用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
4).修改索引注解(可选)
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
5).修改库注释字符集
alter table DBS modify column DESC varchar(4000) character set utf8;
八、测试hive
启动hive,直接输入命令:hive
在hive中创建filetest数据库
命令: create database filetest;
切换filetest数据库:use filetest;
hive中的几种存储格式
TextFile格式:文本格式
以TextFile格式创建students表:
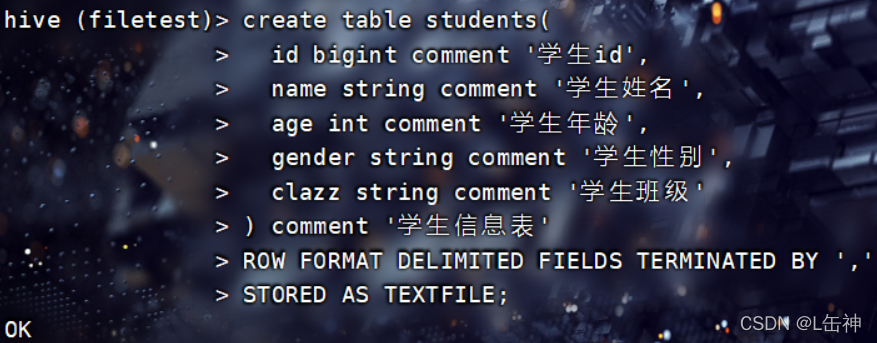
使用命令:desc students查看students表的各个字段:
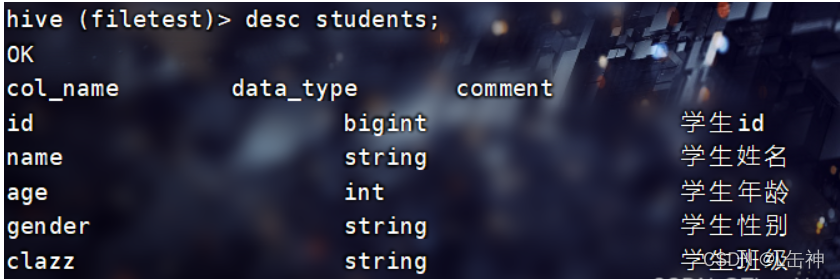
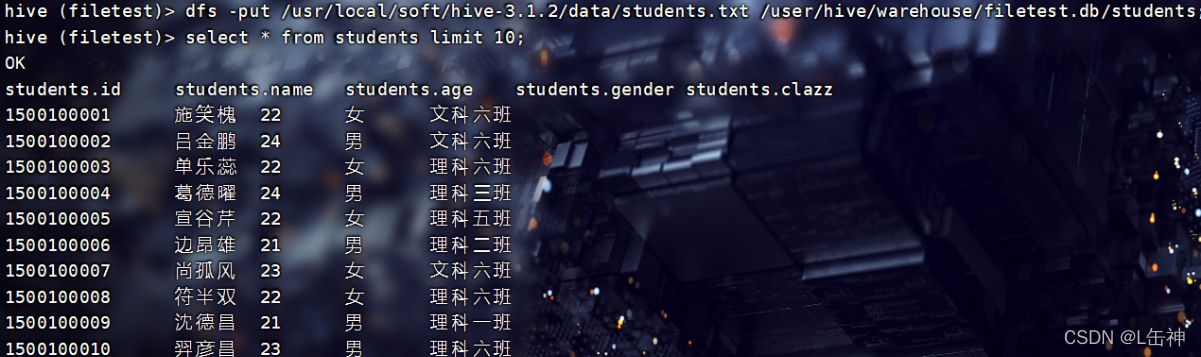
在hive根目录下创建一个文件夹data用于存放本地文件,将本地中的一个文本文件上传到hive根目录下的data中
向表中插入数据:
1、通过input命令将该data中的文本文件上传到hdfs中所创建的该表中,实现向该表中插入数据
在hive中可以使用hdfs中的命令:
查询结果:
2、通过普通的格式对表中进行插入数据
创建一个新的表stduents2,使用普通格式进行插入数据:
load data local inpath "/usr/local/soft/hive-3.1.2/data/students.txt" into table students2;
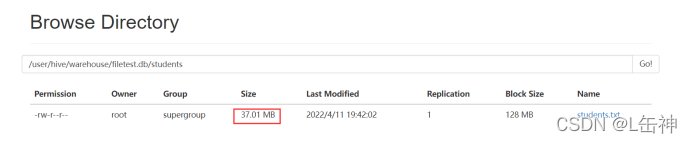
结果:

进入到hdfs中查看:发现两种插入方式对数据大小没有变化,都是37M:
RCFile:
Hadoop中第一个列文件格式
RCFile通常写操作较慢,具有很好的压缩和快速查询功能。
创建RCFile格式的表:
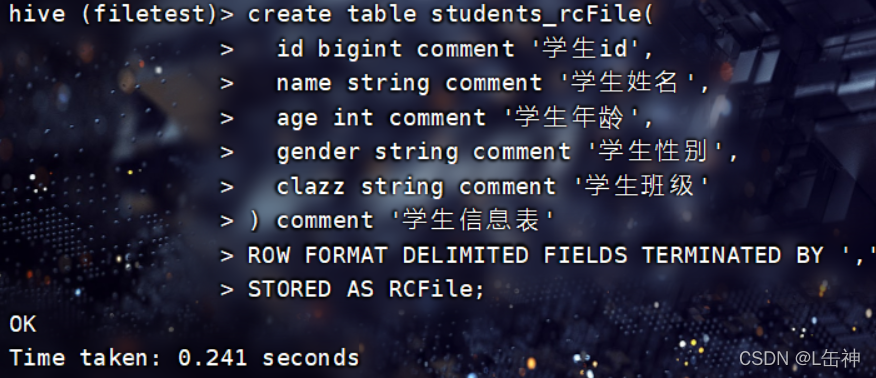
插入数据:
使用命令:
insert into table students_rcFile select * from students;
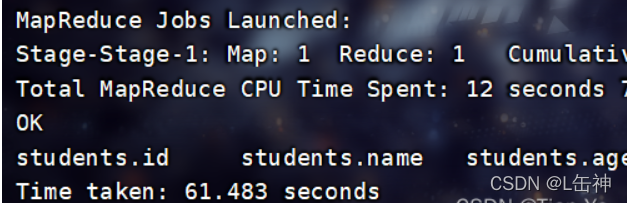
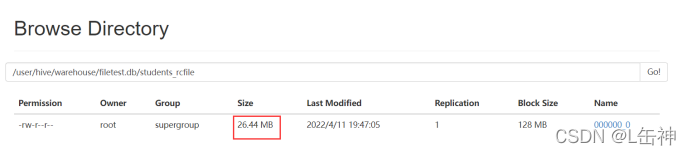
插入完成后,查看数据大小:为26.44M
ORCFile:
Hadoop0.11版本就存在的格式,不仅是一个列文件格式,而且有着很高的压缩比
创建ORCFile格式的表:
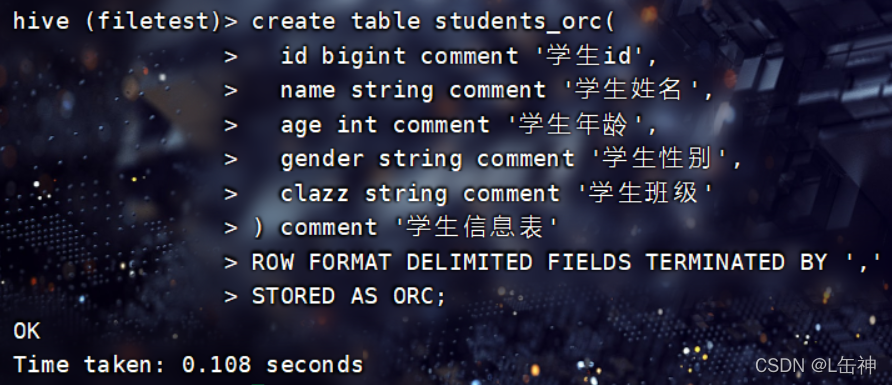
向表中插入数据:
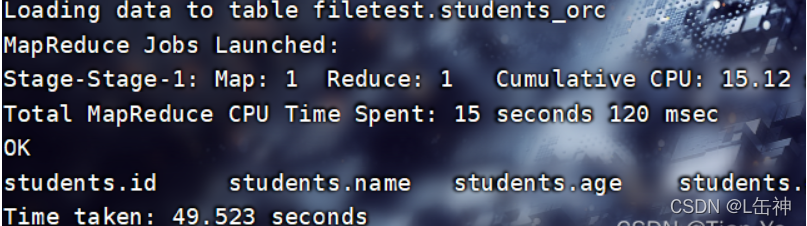
查看数据大小:被压缩为220.38KB

同时观察插入数据所用时间,ORCFile格式与RCFile格式插入数据相差时间不大
Parquet:
这是一种嵌套结构的存储格式,他与语言、平台无关
创建Parquet格式的表:
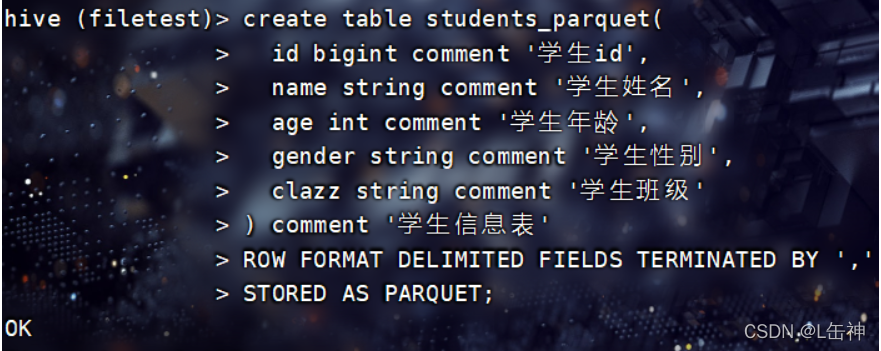
向表中插入数据:
insert into table students_parquet select * from students;
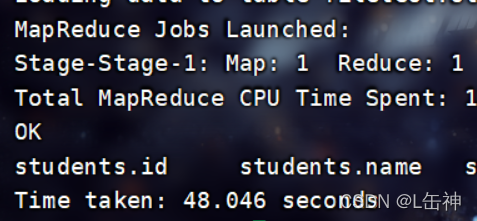
查看数据大小:为3M
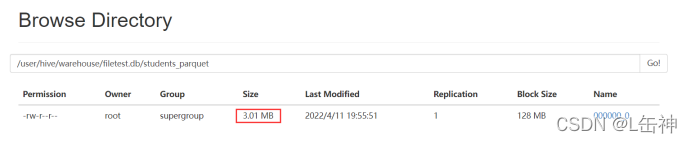
同时发现该格式在插入数据时所花费的时间比ORC格式所花费的时间更少。
其他格式:
SEQUENCEFILE格式:这是一个Hadoop API提供的一种二进制文件格式,实际生产中不使用
AVRO:是一种支持数据密集型的二进制文件格式,他的格式更为紧凑
九、配置JDBC连接
Hive中有两种命令模式:CLi模式和JDBC模式
Cli模式就是Shell命令行
JDBC模式就是Hive中的Java,与使用传统数据库JDBC的方式类似
开启JDBC连接:
进入到/usr/local/soft/hive-3.1.2/bin目录下,在bin目录下有一个hiveserver2文件,通过该文件开启JDBC连接:
输入命令:hive --service hiveserver2开启JDBC连接
一般情况下当出现四个Hive Session时就说明JDBC连接被开启了,也可以通过命令查看是否开启:
进入到 /usr/local/soft/hive-3.1.2/bin目录下:
输入:netstat -nplt | grep 10000
该输入的端口号为hive-site.xml中的hiveserver2服务的端口号
报错:
若输入该命令报错:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://master:10000:
Failed to open new session: java.lang.RuntimeException:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):
User: root is not allowed to impersonate root (state=08S01,code=0)
解决办法:
先关闭Hadoop集群:stop-all.sh
再进入到Hadoop 中的core-site.xml中添加如下内容:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
#以下是添加的内容:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>注意:这些内容需要添在加<configuration>...</configuration>中,否则无法生效
重新启动集群:start-all.sh
再次启动hiveserver2
hive --service hiveserver2
该过程较慢,需要等待
连接到JDBC
当启动JDBC连接后,会开启一个进程RunJar,使用jps命令就可查看
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby
连接到JDBC命令:
进入到 /usr/local/soft/hive-3.1.2/bin下,输入命令:
beeline -u jdbc:hive2://master:10000 -n root连接JDBC:
在JDBC中输入命令可以查看当前hive中的数据库:show databases;
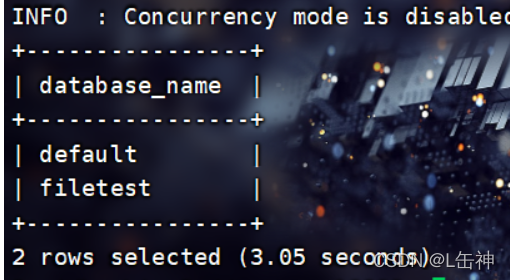
可以发现他与hive的区别在于他使用了一个表格式将databases显示出来
Hive中metastore是hive元数据的集中存放地,这里使用的是MySQL
智能推荐
苹果https java_apple登录 后端java实现最终版-程序员宅基地
文章浏览阅读298次。import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;import com.auth0.jwk.Jwk;import com.helijia.appuser.modules.user.vo.AppleCredential;import com.helijia.common.api.model.Api..._com.auth0.jwk.jwk
NLP学习记录(六)最大熵模型MaxEnt_顺序潜在最大熵强化学习(maxent rl)-程序员宅基地
文章浏览阅读4.7k次。原理在叧掌握关于未知分布的部分信息的情况下,符合已知知识的概率分布可能有夗个,但使熵值最大的概率分布最真实地反映了事件的的分布情况,因为熵定义了随机变量的不确定性,弼熵值最大时,随机变量最不确定,最难预测其行为。最大熵模型介绍我们通过一个简单的例子来介绍最大熵概念。假设我们模拟一个翻译专家的决策过程,关于英文单词in到法语单词的翻译。我们的翻译决策模型p给每一个单词或短语分配一..._顺序潜在最大熵强化学习(maxent rl)
计算机毕业设计ssm科研成果管理系统p57gs系统+程序+源码+lw+远程部署-程序员宅基地
文章浏览阅读107次。计算机毕业设计ssm科研成果管理系统p57gs系统+程序+源码+lw+远程部署。springboot基于springboot的影视资讯管理系统。ssm基于SSM高校教师个人主页网站的设计与实现。ssm基于JAVA的求职招聘网站的设计与实现。springboot校园头条新闻管理系统。ssm基于SSM框架的毕业生离校管理系统。ssm预装箱式净水站可视化信息管理系统。ssm基于SSM的网络饮品销售管理系统。
Caused by: org.xml.sax.SAXParseException; lineNumber: 38; columnNumber: 9; cvc-complex-type.2.3: 元素_saxparseexception; linenumber: 35; columnnumber: 9-程序员宅基地
文章浏览阅读1.6w次。不知道大家有没有遇到过与我类似的报错情况,今天发生了此错误后就黏贴复制了报错信息“Caused by: org.xml.sax.SAXParseException; lineNumber: 38; columnNumber: 9; cvc-complex-type.2.3: 元素 'beans' 必须不含字符 [子级], 因为该类型的内容类型为“仅元素”。”然后就是一顿的百度啊, 可一直都没有找到..._saxparseexception; linenumber: 35; columnnumber: 9; cvc-complex-type.2.3:
计算机科学与技术创新创业意见,计算机科学与技术学院大学生创新创业工作会议成功举行...-程序员宅基地
文章浏览阅读156次。(通讯员 粟坤萍 2018-04-19)4月19日,湖北师范大学计算机科学与技术学院于教育大楼学院会议室1110成功召开大学生创新创业工作会议。参与本次会议的人员有党总支副书记黄海军老师,创新创业学院吴杉老师,计算机科学与技术学院创新创业活动指导老师,15、16、17级各班班主任及学生代表。首先吴杉老师介绍了“互联网+”全国大学生创新创业大赛的相关工作进度,动员各级班主任充分做好“大学生创新创业大..._湖北师范 吴杉
【Android逆向】爬虫进阶实战应用必知必会-程序员宅基地
文章浏览阅读1.1w次,点赞69次,收藏76次。安卓逆向技术是一门深奥且充满挑战的领域。通过本文的介绍,我们了解了安卓逆向的基本概念、常用工具、进阶技术以及实战案例分析。然而,逆向工程的世界仍然在不断发展和变化,新的技术和方法不断涌现。展望未来,随着安卓系统的不断更新和加固,逆向工程将面临更大的挑战。同时,随着人工智能和机器学习技术的发展,我们也许能够看到更智能、更高效的逆向工具和方法的出现。由于篇幅限制,本文仅对安卓逆向技术进行了介绍和案例分析。
随便推点
Python数据可视化之环形饼图_数据可视化绘制饼图或圆环图-程序员宅基地
文章浏览阅读1.1k次。制作饼图还需要下载pyecharts库,Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。随着学习python的热潮不断增加,Python数据可视化也不停的被使用,那我今天就介绍一下Python数据可视化中的饼图。在我们的生活和学习中,编程是一项非常有用的技能,能够丰富我们的视野,为各行各业的领域提供了新的角度。环形饼图的制作并不难,主要是在于数据的打包和分组这里会有点问题,属性的标签可以去 这个网站进行修改。图中的zip压缩函数,并分组打包。_数据可视化绘制饼图或圆环图
SpringMVC开发技术~5~基于注解的控制器_jsp/servlet到controller到基于注解的控制器-程序员宅基地
文章浏览阅读325次。1 Spring MVC注解类型Controller和RequestMapping注释类型是SpringMVC API最重要的两个注释类型。基于注解的控制器的几个优点:一个控制器类可以控制几个动作,而一个实现了Controller接口的控制器只能处理一个动作。这就允许将相关操作写在一个控制器类内,从而减少应用类的数量基于注解的控制器的请求映射不需要存储在配置文件中,而是使用RequestM..._jsp/servlet到controller到基于注解的控制器
利用波特图来满足动态控制行为的要求-程序员宅基地
文章浏览阅读260次,点赞3次,收藏4次。相位裕量可以从增益图中的交越频率处读取(参见图2)。使用的开关频率、选择的外部元件(例如电感和输出电容),以及各自的工作条件(例如输入电压、输出电压和负载电流)都会产生巨大影响。图2所示为波特图中控制环路的增益曲线,其中提供了两条重要信息。对于图2所示的控制环路,这个所谓的交越频率出现在约80 kHz处。通过使用波特图,您可以查看控制环路的速度,特别是其调节稳定性。图2. 显示控制环路增益的波特图(约80 kHz时,达到0 dB交越点)。图3. 控制环路的相位曲线,相位裕量为60°。
Glibc Error: `_obstack@GLIBC_2.2.5‘ can‘t be versioned to common symbol ‘_obstack_compat‘_`_obstack@glibc_2.2.5' can't be versioned to commo-程序员宅基地
文章浏览阅读1.8k次。Error: `_obstack@GLIBC_2.2.5’ can’t be versioned to common symbol '_obstack_compat’原因:https://www.lordaro.co.uk/posts/2018-08-26-compiling-glibc.htmlThis was another issue relating to the newer binutils install. Turns out that all was needed was to initi_`_obstack@glibc_2.2.5' can't be versioned to common symbol '_obstack_compat
基于javaweb+mysql的电影院售票购票电影票管理系统(前台、后台)_电影售票系统javaweb-程序员宅基地
文章浏览阅读3k次。基于javaweb+mysql的电影院售票购票电影票管理系统(前台、后台)运行环境Java≥8、MySQL≥5.7开发工具eclipse/idea/myeclipse/sts等均可配置运行适用课程设计,大作业,毕业设计,项目练习,学习演示等功能说明前台用户:查看电影列表、查看排版、选座购票、查看个人信息后台管理员:管理电影排版,活动,会员,退票,影院,统计等前台:后台:技术框架_电影售票系统javaweb
分分钟拯救监控知识体系-程序员宅基地
文章浏览阅读95次。分分钟拯救监控知识体系本文出自:http://liangweilinux.blog.51cto.com0 监控目标我们先来了解什么是监控,监控的重要性以及监控的目标,当然每个人所在的行业不同、公司不同、业务不同、岗位不同、对监控的理解也不同,但是我们需要注意,监控是需要站在公司的业务角度去考虑,而不是针对某个监控技术的使用。监控目标1.对系统不间断实时监控:实际上是对系统不间..._不属于监控目标范畴的是 实时反馈系统当前状态