科研训练第十八周——关于Attention的盘复_ian模型-程序员宅基地
1.相关论文阅读
传送门:《Interactive Attention Networks for Aspect-Level Sentiment Classification》
1.1. introduction
略(如果你不了解ABSC任务)
1.2. motivation
虽说是前几年的工作,但是这个part现在读起来,昂有种穿越的赶脚,大概是NLP发展比较快叭
- 基于特征工程SVM之类的,人工设计特征代价过大
- 基于深度学习的,40%的ABSC分类错误是由于没有考虑target导致的,而大多现有的工作忽视了对于目标target的建模
1.3. model
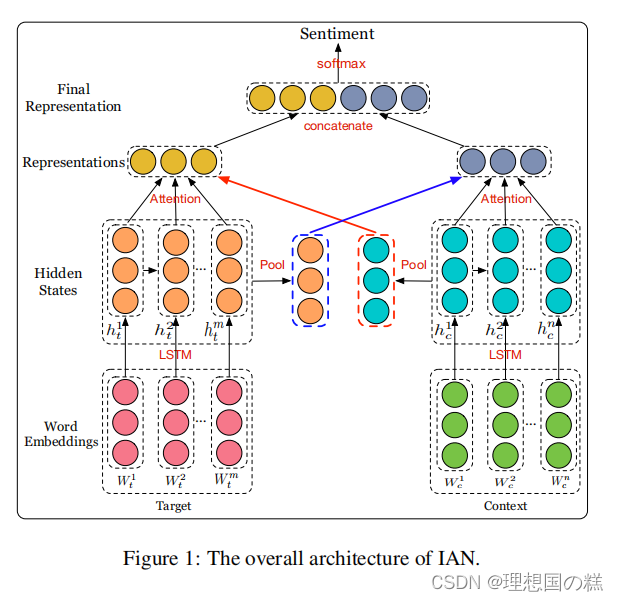
原文(机翻):
Ian模型由两部分组成,它们可以交互式地建模目标和上下文。以单词嵌入为输入,我们利用LSTM网络分别获取目标和上下文在单词水平上的隐藏状态。我们利用目标的隐藏状态和上下文的隐藏状态的平均值来监督注意向量的生成,利用注意机制来捕获上下文和目标中的重要信息。通过这种设计,目标和上下文可以影响交互式地生成它们的表示。最后,将目标表示和上下文表示连接为最终表示,并输入一个softmax函数,用于方面级情绪分类
大概思路是LSTM分别输出target和context的隐层表示,Attention的监督体现在,针对特定taget去关注特定的上下文,针对特定文本关注target,最终左右表示向量拼接起来是为了提高维度来增加准确率,用softmax输出情感分类结果。
具体步骤
1、词嵌入
2、LSTM处理获取最终表示
LSTM的公式(会的可以略过,不理解的戳这里)
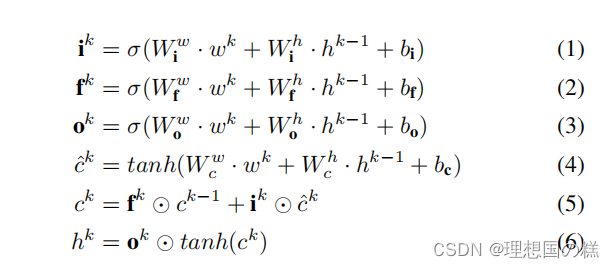
利用平均池化的方式(也就是隐层结点计算结果分别取平均)获得target以及context的表示:
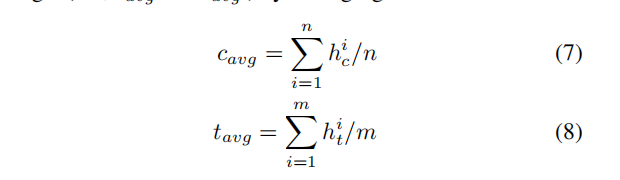
3、注意力机制分配权重
如何计算注意力向量,以模型图右侧为例子:
依靠LSTM计算得出的上下文隐层表示 h c h_c hc和左侧池化得到的target目标表示 t a v g t_{avg} tavg来生成注意力向量
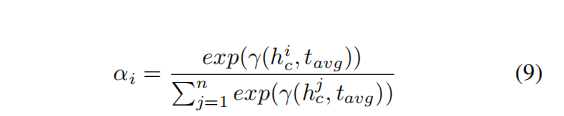
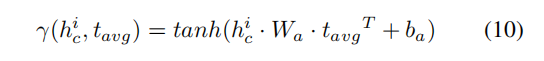
同理可以得到左侧的注意力向量:
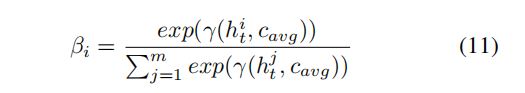
将每个词对应的注意力向量和它对应的LSTM生成的隐层向量结合,得到最终的表示如下 c r c_r cr是右侧生成的, t r t_r tr是左侧生成的
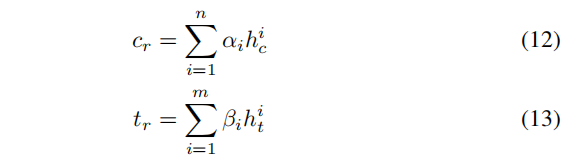
4、 将 c r c_r cr以及 t r t_r tr拼接起来,作为最后的表示,用softmax做分类~
1.4. conclusion
消融实验结果:
这部分还没有结束复现,下周填一下坑
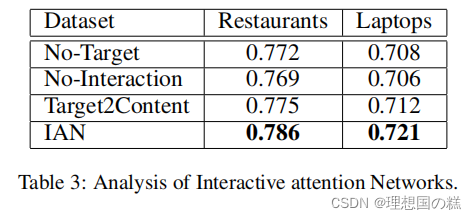
与其他模型的对比实验结果:
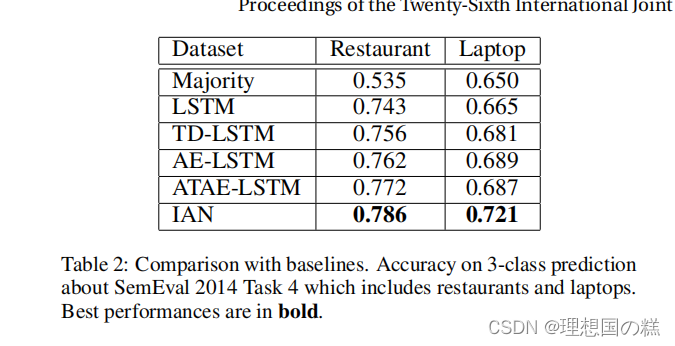
原文(机翻):
在本文中,我们设计了一个交互式注意网络(Ian)模型。Ian的主要思想是使用两个注意网络来交互式地建模目标和内容。Ian模型可以密切关注目标和上下文中的重要部分,并能很好地生成目标和上下文的表示。然后,Ian从在其他方法中总是被忽略的目标表示中获益。在SemEval2014上的实验验证,Ian可以学习目标和内容的有效特征,并为判断目标情绪极性提供足够的信息。案例研究还表明,Ian可以合理地注意那些对判断目标的情绪极性很重要的词汇。
2. 复现工作
2.0 preparation
Data:SemEval 2014
Embedding:GloVe
2.1. code
github代码链接,如果你愿意给我一颗小星星,刚学写得比较菜啦,有些报错和连接问题所以git用得不是很好,另外模型部分还有很多问题,有幸得话欢迎大佬指正或者讨论
模型部分:
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
from utils.layers import DynamicLSTM,Attention
class MYIAN(nn.Module):
def __init__(self,embedding_matrix,opt):
"""
初始化模型
:param embedding_matrix:
"""
super(MYIAN,self).__init__()
self.opt=opt
self.embed=nn.Embedding.from_pretrained(torch.tensor(embedding_matrix,dtype=torch.float))
self.target_lstm=DynamicLSTM(opt.embed_dim,opt.hidden_dim,num_layers=1,batch_first=True)
self.context_lstm=DynamicLSTM(opt.embed_dim,opt.hidden_dim,num_layers=1,batch_first=True)
self.target_attention=Attention(opt.hidden_dim)
self.context_attention=Attention(opt.hidden_dim)
self.dense=nn.Linear(opt.hidden_dim*2,opt.polarities_dim)
def forward(self,inputs):
text,target=inputs[0],inputs[1]
context_len=torch.sum(text!=0,dim=-1)
target_len=torch.sum(target!=0,dim=-1)
"""lstm"""
context=self.embed(text)
target=self.embed(target)
context_hidden_list,(_,_)=self.context_lstm(context,context_len)
target_hidden_list,(_,_)=self.target_lstm(target,target_len)
"""pool"""
target_len=torch.as_tensor(target_len,dtype=torch.float).to(self.opt.device)
target_pool=torch.sum(target_hidden_list,dim=1)
target_pool=torch.div(target_pool,target_len.view(target_len.size(0),1))
context_len = torch.as_tensor(context_len, dtype=torch.float).to(self.opt.device)
context_pool = torch.sum(context_hidden_list, dim=1)
context_pool = torch.div(context_pool, target_len.view(context_len.size(0), 1))
"""attention"""
target_final,_=self.target_attention(target_hidden_list,context_pool)# target是k context_pool是q
target_final=target_final.squeeze(dim=1)
context_final,_=self.context_attention(context_hidden_list,target_pool)# context是k target是q--->对于特定的
context_final=context_final.squeeze(dim=1)
"""合并"""
x=torch.cat((target_final,context_final),dim=-1)
"""分类"""
out=self.dense(x)
return out
关于保存实验参数(仅仅是超参数的设置以及实验正确率):
一直想做,但是一直懒癌……其实写个Demo也不难,毕竟比起每次手动记录实验结果的时间消耗,这个还是比较划算der~
import csv
def my_log(opt):
file = './log/logging.csv'
'''表头'''
# namelist4 = ['model_name', 'dataset', 'optimizer', 'initializer', 'lr',
# 'dropout','l2reg','num_epoch','batch_size','log_step',
# 'embed_dim','hidden_dim','position_dim','max_length','device',
# 'repeats','max_test_acc','max_f1'
# ]
# df = pd.read_csv(file, header=None, names=namelist4)
# df.to_csv(file, index=False)
with open(file,'a+') as f:
csv_write = csv.writer(f)
data_row = [opt.model_name,opt.dataset,opt.optimizer,opt.initializer,opt.learning_rate,
opt.dropout,opt.l2reg,opt.num_epoch,opt.batch_size,opt.log_step,
opt.embed_dim,opt.hidden_dim,opt.position_dim,opt.max_length,opt.device,
opt.repeats,opt.max_test_acc,opt.max_test_f1]
csv_write.writerow(data_row)
2.1.1 实验中遇到的编程以及环境问题记录
其实问题不大,但是循环起来的时候一直在输出warn就很难受
报错代码:
context_len = torch.tensor(context_len, dtype=torch.float).to(self.opt.device)
改成:
context_len = torch.as_tensor(context_len, dtype=torch.float).to(self.opt.device)
2.2. results
改一改参数的话,应该会更高一点
目前用的优化器都是Adam
SGD+动量可以收敛但是效果不佳(基本在50%+范围浮动)
Laptop:
| 模型 | test_acc | test_f1 |
|---|---|---|
| LSTM | 0.691 | 0.603 |
| IAN | 0.719 | 0.660 |
Restaurant:
| 模型 | test_acc | test_f1 |
|---|---|---|
| LSTM | 0.748 | 0.613 |
| IAN | 0.750 | 0.615 |
2.2.1. others
因为ML结课作业的扩展部分是自己实现了一下几种深度学习常见的优化器,所以额外试着跑了一下不同优化器对于模型收敛的影响:
不知道是不是自己代码实验做得不够多的原因,总觉得优化器的设置也属于一个比较大的研究方向
SGD和ASGD基本上没有办法收敛emm比较让人费解,不知道是不是Attention的那边的模型不适合SGD这种的收敛。
-
sgd-lr(不加动量1e-5会在开始的时候严重震荡,虽然大体方向是正确的,但是效果很糟糕(值得一提的是,不加动量的sgd对于LSTM单一模型的影响影响不大,LSTM在同样设置下可以正常且较为快速地收敛)[Laptop测试集acc:0.53 f1:0.23]
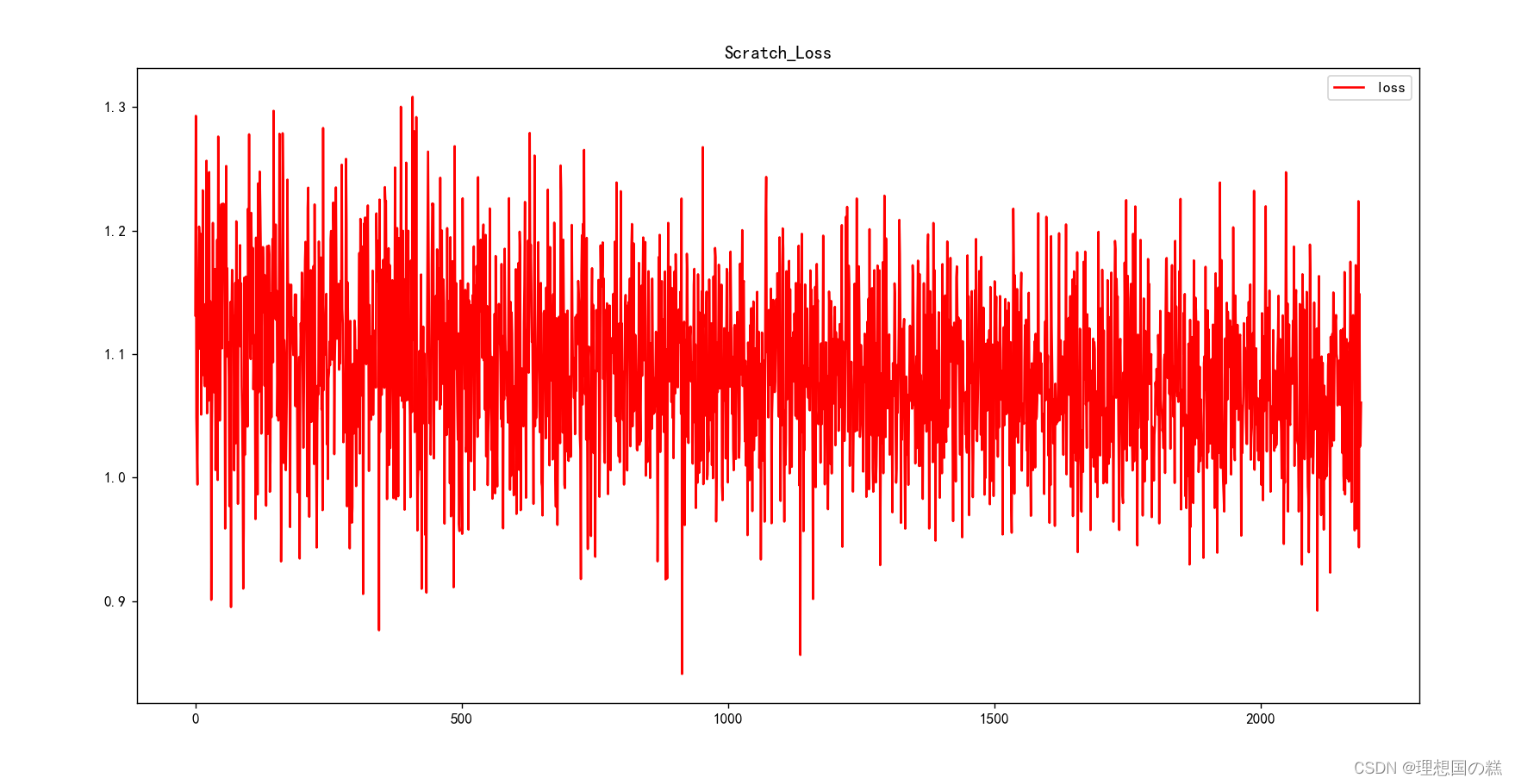
按照论文的说法,加入momentum动量之后可以有效收敛:acc 0.539 f1 0.268
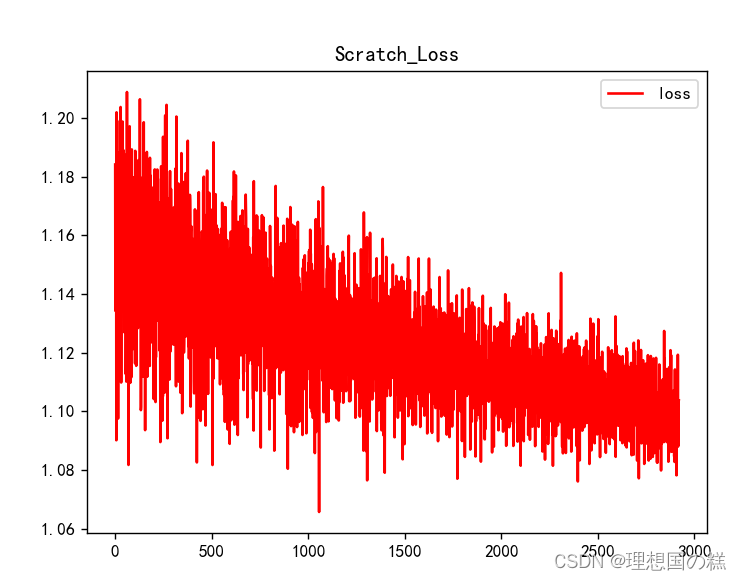
-
Adamax相同参数下的效果比较好[Laptop测试集acc:0.697 f1:0.622]
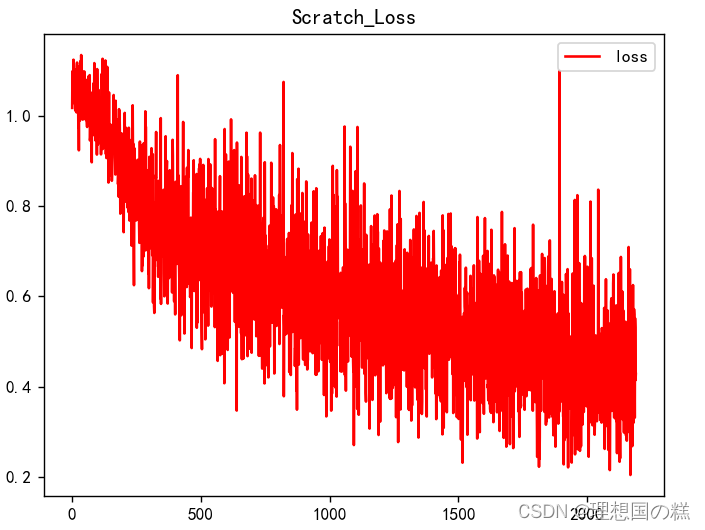
2.3 analysis
总体来讲,IAN相对于LSTM的提升效果没有特别大幅度(emmmmmmm不应该吖,还得改代码看看哪里出问题了,上一篇博文里我自己实现的LSTM最好的效果在Restaurant也是70%+,平均结果是65%,这篇用的LSTM是torch自带的组件),但是Attention机制的引入确实比单独的LSTM要好很多
Attention机制的讲解
【复习Attention基础的话暂时戳这里叭】
这个坑emm应该得等下周补一下,主要是目前接触的attention计算公式不是很多
可以忽视的碎碎念:
然后捏,发现这一周零零总总居然开了五次会议(好叭有些可能不算会议性质,并且一次比一次长)……放假了又好像没有完全放……
Attention是暑假也做过的工作,当时浅薄地过了一下模型,个中原理推敲得不细致以至于回忆起来基本没啥印象(机器人考试还考了这个,忘记真是不应该),借这个机会正好好好过一下,反正寒假还是蛮长滴
本周结束了一个小game,赎身的感觉很好,但是也发现了自己学习上的诸多毛病。很感慨的是数据挖掘的任务和平时做实验还有课程有很大的区别,对于数据本身预处理部分可能有时候比模型更重要(前提是选模型的方向要对哈)。
智能推荐
Vue在启动项目时报错 ValidationError: webpack Dev Server Invalid Options-程序员宅基地
文章浏览阅读2.2k次。#Vue项目开发报错欢迎使用Markdown编辑器你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。新的改变我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:全新的界面设计 ,将会带来全新的写作体验;在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 _webpack dev server invalid options
android驱动开发书籍推荐,2024年Android春招面试经历-程序员宅基地
文章浏览阅读287次,点赞3次,收藏3次。都说三年是程序员的一个坎,能否晋升或者提高自己的核心竞争力,这几年就十分关键。技术发展的这么快,从哪些方面开始学习,才能达到高级工程师水平,最后进阶到Android架构师/技术专家?我总结了这 5大块;我搜集整理过这几年阿里,以及腾讯,字节跳动,华为,小米等公司的面试题,把面试的要求和技术点梳理成一份大而全的“ Android架构师”面试 Xmind(实际上比预期多花了不少精力),包含知识脉络 + 分支细节。
浅谈分布式光伏电站的运维管理-程序员宅基地
文章浏览阅读610次,点赞18次,收藏18次。十四五”期间,随着“双碳”目标提出及逐步落实,本就呈现出较好发展势头的分布式光伏发展有望大幅提速。就“十四五”光伏发展规划,国家发改委能源研究所可再生能源发展中心副主任陶冶表示,“双碳”目标意味着国家产业结构的调整,未来10年,新能源装机将保持在110GW以上的年增速,这里面包含集中式光伏电站和分布式光伏电站。相较于集中式电站来说,分布式对土地等自然资源没有依赖,各个地方的屋顶就是分布式电站的形成基础,在碳中和方案的可选项中,分布式光伏由于其灵活性必将被大力发展,目前已有河北、甘肃、安徽、浙江、陕西等
如何搭建反欺诈策略与模型-程序员宅基地
文章浏览阅读1.7k次。转载自https://www.jianshu.com/p/fd447413e335信用风险与反欺诈哪个更加重要?为什么是先讲策略再谈模型?一个完整的反欺诈流程如何搭建?如何说服CEO接受模型测试成本?在一本财经商学院举办的第二期风控闭门课程上,天创信用首席科学家陈黎明一一做出解答。以下是她现场分享的部分干货:01基本概念今天我讲的主要课题是“反欺诈策略和模型”。为什么要把策略放前面呢?因为不管是拍脑袋决定,还是通过数据挖掘出来,反欺诈一般是先有策略,然后通过数据的积累,慢慢去构建模型。首先讲一下
hive表新增字段,指定新增字段位置,删除字段_hive 新增字段-程序员宅基地
文章浏览阅读5.6k次。经验证,hive中修改字段顺序并没有将字段对应的值移动,只是单纯的修改字段名,如果是空表(没有数据),可以使用以上两步;其中CASCADE选项为选填的字段,但是对于分区表,一定要加上,否则其历史分区的元数据信息(metadata)将无法正常更新,导致访问历史分区时会报莫名的错误。背景:项目中,客户使用hive内表,由于逻辑变更,原hive表结构需要调整,新增字段。如果已经添加了字段,可以修改字段时,在修改字段名时带上,在修改回来。实际上,使用alter语句,把保留的字段全部列出来,删除的字段不要列出来。_hive 新增字段
Hudi - Could not create payload for class_error -1 (00000) : while preparing sql: upsert int-程序员宅基地
文章浏览阅读357次。测试 insert 时,hoodie.datasource.write.payload.class 有影响,而 hoodie.compaction.payload.class.class 没有影响,即使设置为错误值。_error -1 (00000) : while preparing sql: upsert into driver_point("id","latit
随便推点
复现一个老漏洞 Discuz!7.2 faq.php 注入漏洞 分析原理_discuz 7.2 faq.php 注入漏洞全自动利用工具-程序员宅基地
文章浏览阅读4k次。源码~ http://pan.baidu.com/s/1gfkvJrXpoc/faq.php?action=grouppermission&gids[99]=%27&gids[100][0]=)%20and%20(select%201%20from%20(select%20count(*),concat(version(),floor(rand(0)*2))x%20fr..._discuz 7.2 faq.php 注入漏洞全自动利用工具
ubuntu系统禁用自带Nouveau驱动_ubuntu禁用nouveau-程序员宅基地
文章浏览阅读1.9w次,点赞12次,收藏70次。Nouveau是由第三方为NVIDIA显卡开发的一个开源3D驱动,让Linux更容易的应对各种复杂的NVIDIA显卡环境,安装完Linux系统即可进入桌面并且有不错的显示效果,所以,很多Linux发行版默认集成了Nouveau驱动,在使用NVIDIA显卡时默认安装Nouveau驱动。但是用户除了想让正常显示图形界面外很多时候还需要一些其他功能,Nouveau驱动不能完成,同时还会对..._ubuntu禁用nouveau
吴恩达 机器学习 线性回归与逻辑回归中代价函数在MATLAB中具体实现总结_matlab机器学习代价函数-程序员宅基地
文章浏览阅读1.4k次。作为一个对线代已经不那么熟悉,机器学习方面也是零基础的小白,在做EX1和EX2的时候,最让我感到困难的就是代价函数cost Function、梯度在MATLAB中究竟应该是怎样的形式根据吴恩达老师给出的形式一. 线性回归1.普通线性回归预测函数H代价函数具体的MATLAB实现这里是另一种方法,二选一即可这里的采用的是向量化编程,无论是单一变量还是多变量都是适用的。梯度下降具..._matlab机器学习代价函数
ChatGPT加持,需求分析再无难题-程序员宅基地
文章浏览阅读857次,点赞21次,收藏23次。写清楚需求:在给出提示词的时候,我们通过添加场景、添加角色,让我们的需求更加明确。将复杂的任务拆分为更简单的子任务:需求分析本身就是一个复杂的过程,我们需要逐步拆解,并纠正GPT的回复,引导GPT给到更多的信息。系统的测试变化:在返回信息过程中,如果返回信息不满足需求,或者有偏差,需要测试回复信息,并予以修正。角色扮演:在给出提示词的过程中,我们告诉GPT,需要以一个测试工程师的角色给出对应的测试点。
在C++中如何暂停(等待)时间?_c++怎么让程序暂停几秒-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏14次。大家都知道,我们会做倒计时装置,而倒计时装置就需要暂停(等待)时间。如何实现这个功能呢?_c++怎么让程序暂停几秒
2021年我的互联网秋招算法岗总结!-程序员宅基地
文章浏览阅读688次,点赞2次,收藏7次。↑↑↑关注后"星标"Datawhale每日干货&每月组队学习,不错过Datawhale干货作者:李金泽,清华大学,Datawhale作者前言一晃接近三个月..._李金泽 清华大学论文