Hadoop 集群搭建_hadoop集群规划-程序员宅基地
使用三台虚拟机,搭建一个 Hadoop 集群。
目录
一、centos7 Minimal 版本安装配置
Centos7 Minimal 版本基本配置记录_centos7minimal_YuBooy的博客-程序员宅基地
二、Hadoop 单节点安装
机器配置:(基础配置详看:Centos7 Minimal 版本基本安装配置)
| 主机名 |
hadoop101 |
hadoop102 |
hadoop103 |
| IP |
192.168.139.101 |
192.168.139.102 |
192.168.139.103 |
| 用户名 |
root |
root |
root |
| 密码 |
123 |
123 |
123 |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
先在 hadoop101 上配置:
① 修改主机名和映射 hosts 文件;
② 安装 JDK;安装 Hadoop 再克隆 hadoop102、hadoop103;
③ 克隆后再修改 hadoop102 、hadoop103 的主机名和 IP。
① 修改主机名和映射 hosts 文件
// 改主机名
hostnamectl set-hostname hadoop101
// 修改映射 hosts 文件
vim /etc/hosts
// 添加:
192.168.139.101 hadoop101
192.168.139.102 hadoop102
192.168.139.103 hadoop103
reboot修改windows的主机映射文件(hosts文件)
// C:\Windows\System32\drivers\etc 路径
// 添加:
192.168.139.101 hadoop101
192.168.139.102 hadoop102
192.168.139.103 hadoop103② 安装 JDK
非 minimal 版本需要先卸载自带的 JDK;minimal 版本不需要。
1.把 jdk、hadoop 包放到 /etc/sofware 目录下
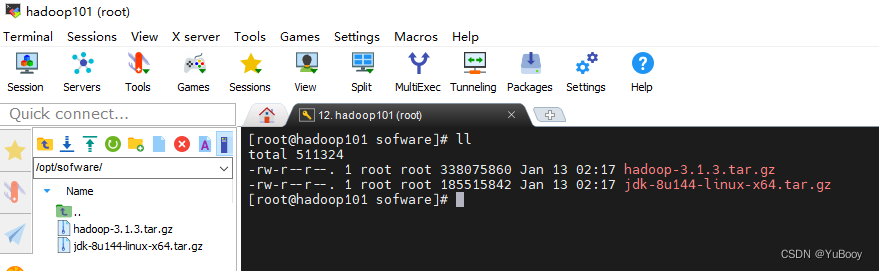
2.安装
// 解压JDK到/opt/module目录下
[root@hadoop101 sofware]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module
/
// 配置JDK环境变量
// (1)新建/etc/profile.d/my_env.sh文件
vim /etc/profile.d/my_env.sh
// (2)添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
// (3)source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile
// (4)测试JDK是否安装成功
java -version③ 安装 Hadoop
Hadoop下载地址:Index of /dist/hadoop/common/hadoop-3.1.3
/ 解压
cd /opt/sofware
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
// 将Hadoop添加到环境变量
//(1)打开/etc/profile.d/my_env.sh文件
vim /etc/profile.d/my_env.sh
// (2)添加如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
// (3)source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile
// (4)测试hadoop是否安装成功
hadoop versionHadoop目录结构:
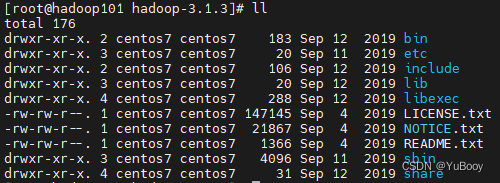
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
④ 本地模式测试(官方WordCount)
// 1.创建一个wcinput文件夹
mkdir /opt/module/hadoop-3.1.3/wcinput
// 2.创建一个word.txt文件
cd /opt/module/hadoop-3.1.3/wcinput
vim word.txt
// 3.添加如下内容:
hadoop yarn
hadoop mapreduce
yuyu
yuyu
// 4.执行程序
cd /opt/module/hadoop-3.1.3
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
// 5. 查看结果
cat wcoutput/part-r-00000
三、Hadoop 集群配置
| 主机名 |
hadoop101 |
hadoop102 |
hadoop103 |
| IP |
192.168.139.101 |
192.168.139.102 |
192.168.139.103 |
| 用户名 |
root |
root |
root |
| 密码 |
123 |
123 |
123 |
(1)克隆 hadoop102、hadoop103
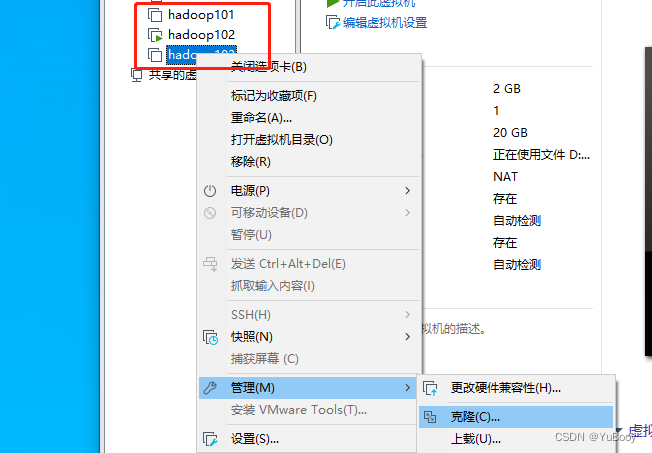
克隆之后修改 IP 和 主机名
// 修改 ip 102/103
vim /etc/sysconfig/network-scripts/ifcfg-ens33
// 修改主机名 hadoop102/hadoop103
hostnamectl set-hostname hadoop102
// 重启
reboot(2)群分发脚本xsync
① 安装 rsync(三台机器上都要装)
yum -y install rsync
# 启动服务与开机自启动
systemctl start rsyncd.service
systemctl enable rsyncd.service② 在 /root/bin 目录下创建 xsync 文件
cd /root/bin
vim xsync粘贴以下内容:
#!/bin/bash
#1. 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if [ $pcount -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103 ##更改自己的服务器域名
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
echo pdir=$pdir
#6. 获取当前文件的名称
fname=$(basename $file)
echo fname=$fname
#7. 通过ssh执行命令:在$host主机上递归创建文件夹(如果存在该文件夹)
ssh $host "mkdir -p $pdir"
#8. 远程同步文件至$host主机的$USER用户的$pdir文件夹下
rsync -av $pdir/$fname $USER@$host:$pdir
else
echo $file does not exists!
fi
done
done③ 给 xsync 添加权限:
chmod 777 xsync④ 添加全局变量
vim /etc/profile
在末尾添加:
PATH=$PATH:/root/bin
export PATH
退出,执行以下命令使其生效
source /etc/profile(3)root 用户免密登录配置
① 在 ~./ssh 目录下生成一对密钥(3个节点都要生成)
cd ~/.ssh
ssh-keygen -t rsa
# 输入该命令后会有提示,一直回车即可
# 如果提示 【-bash: cd: .ssh: 没有那个文件或目录】 直接 ssh-keygen -t rsa 生成密钥就行② hadoop101 节点中将公匙保存到 authorized_keys 文件中
[root@hadoop101 .ssh]# cat id_rsa.pub >> authorized_keys③ 登录 hadoop102 和 hadoop103 节点,将其公钥文件内容拷贝到 hadoop101 节点的 authorized_keys 文件中
# hadoop102 节点的公钥拷贝
[root@hadoop102 .ssh]# ssh-copy-id -i hadoop101
# hadoop103 节点的公钥拷贝
[root@hadoop103 .ssh]# ssh-copy-id -i hadoop101④ 在 hadoop101 节点中修改权限(~/.ssh 目录 和 authorized_keys 文件)
[root@hadoop101 .ssh]# chmod 700 ~/.ssh
[root@hadoop101 .ssh]# chmod 644 ~/.ssh/authorized_keys⑤ 将授权文件分发到其他节点上
# 拷贝到 hadoop102 节点上
[root@hadoop101 .ssh]# scp /root/.ssh/authorized_keys hadoop102:/root/.ssh/
# 拷贝到 hadoop103 节点上
[root@hadoop101 .ssh]# scp /root/.ssh/authorized_keys hadoop103:/root/.ssh/至此,免密码登录已经设定完成,注意第一次ssh登录时需要输入密码,再次访问时即可免密码登录
[root@hadoop101 .ssh]# ssh hadoop102
[root@hadoop101 .ssh]# ssh hadoop103(4)集群配置
1、集群部署规划
> NameNode 和 SecondaryNameNode 不要安装在同一台服务器
> ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上。
| 主机名 |
hadoop101 |
hadoop102 |
hadoop103 |
| IP |
192.168.139.101 |
192.168.139.102 |
192.168.139.103 |
| 用户名 |
root |
root |
root |
| 密码 |
123 |
123 |
123 |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2、配置文件说明
Hadoop配置文件分两类:默认配置文件 和 自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
① 默认配置文件:
| 默认文件 |
文件存放在Hadoop的jar包中的位置 |
| [core-default.xml] |
hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] |
hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] |
hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] |
hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
② 自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
3、配置集群
① 配置 core-site.xml
[root@hadoop101 hadoop]# cd $HADOOP_HOME/etc/hadoop
[root@hadoop101 hadoop]# vim core-site.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>② 配置 hdfs-site.xml
[root@hadoop101 hadoop]# vim hdfs-site.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>③ 配置 yarn-site.xml
[root@hadoop101 hadoop]# vim yarn-site.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>④ 配置 mapred-site.xml
[root@hadoop101 hadoop]# vim mapred-site.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>4、在集群上分发配置好的Hadoop配置文件
[root@hadoop101 hadoop]# xsync /opt/module/hadoop-3.1.3/etc/hadoop/5、去 102 和 103 上查看文件分发情况
[root@hadoop102 ~]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[root@hadoop103 ~]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml(5)群起集群
1、配置workers
[root@hadoop101 hadoop]# vim /opt/module/hadoop-3.1.3/etc/hadoop/workers【注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行】
添加如下内容:
hadoop101
hadoop102
hadoop103同步所有节点配置文件
[root@hadoop101 hadoop]# xsync /opt/module/hadoop-3.1.3/etc2、启动集群
① 第一次启动需要:在 hadoop101 节点格式化 NameNode
[root@hadoop101 hadoop-3.1.3]# cd /opt/module/hadoop-3.1.3/
[root@hadoop101 hadoop-3.1.3]# hdfs namenode -format【注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群是第一次启动,直接在 hadoop101 节点格式化 NameNode;如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化】
② 启动 HDFS(在 NameNode 节点:hadoop101)
[root@hadoop101 hadoop-3.1.3]# cd /opt/module/hadoop-3.1.3/
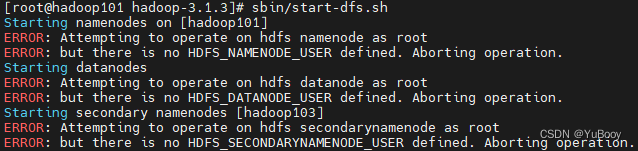
[root@hadoop101 hadoop-3.1.3]# sbin/start-dfs.sh如果启动遇到下面问题:
【ERROR: Attempting to operate on hdfs namenode as root】
解决方案:两种解决ERROR: Attempting to operate on hdfs namenode as root的方法_世幻水的博客-程序员宅基地
vim /etc/profile
#添加:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#使生效:
source /etc/profile
③ 在配置了 ResourceManager 的节点(hadoop102)启动YARN
[root@hadoop102 hadoop-3.1.3]# cd /opt/module/hadoop-3.1.3/
[root@hadoop102 hadoop-3.1.3]# sbin/start-yarn.sh④ Web 端查看 HDFS 的 NameNode
1.浏览器中输入:http://hadoop101:9870
2.查看HDFS上存储的数据信息
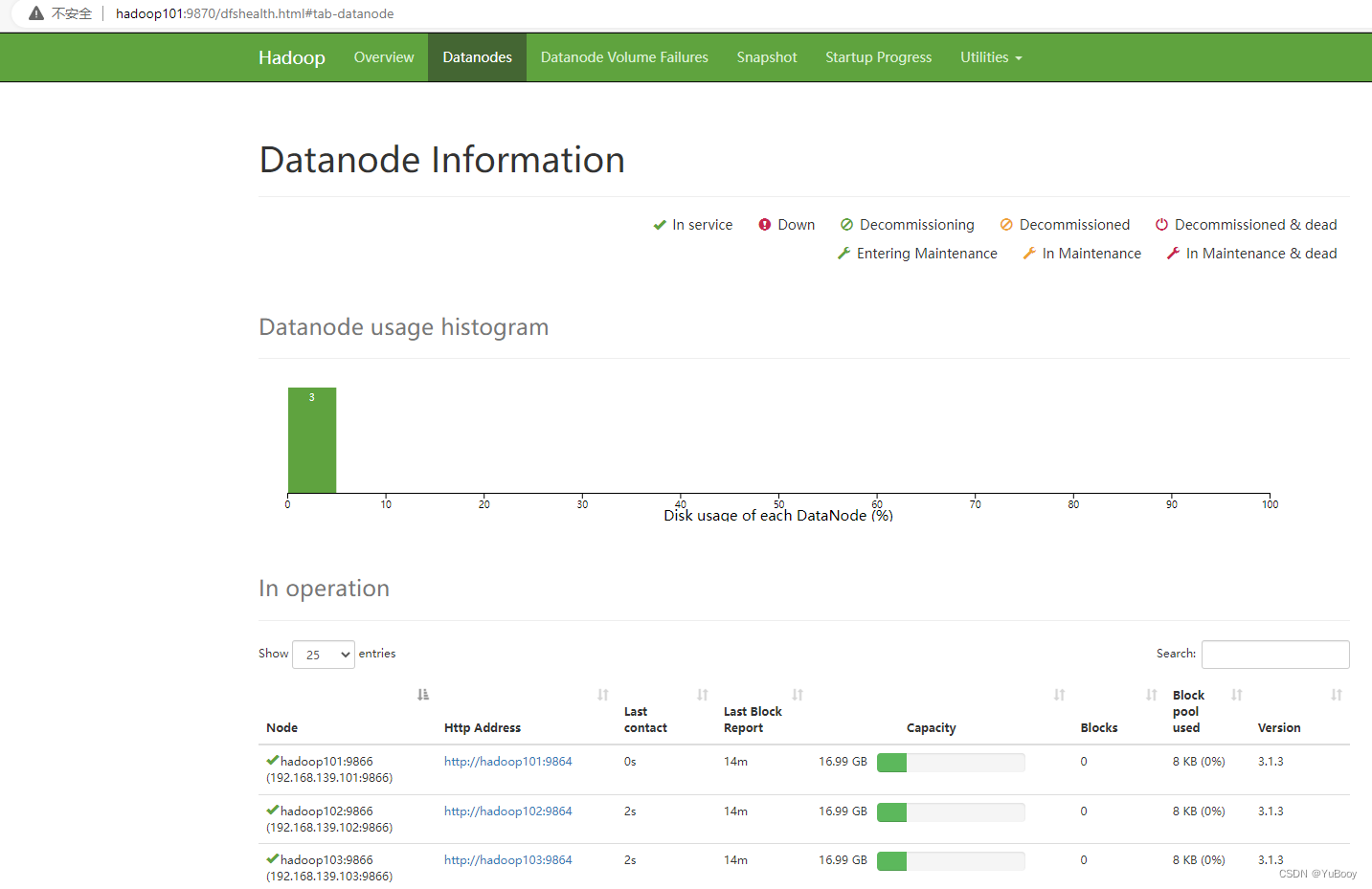
⑤ Web 端查看 YARN 的 ResourceManager
1.浏览器中输入:http://hadoop102:8088
2.查看YARN上运行的Job信息
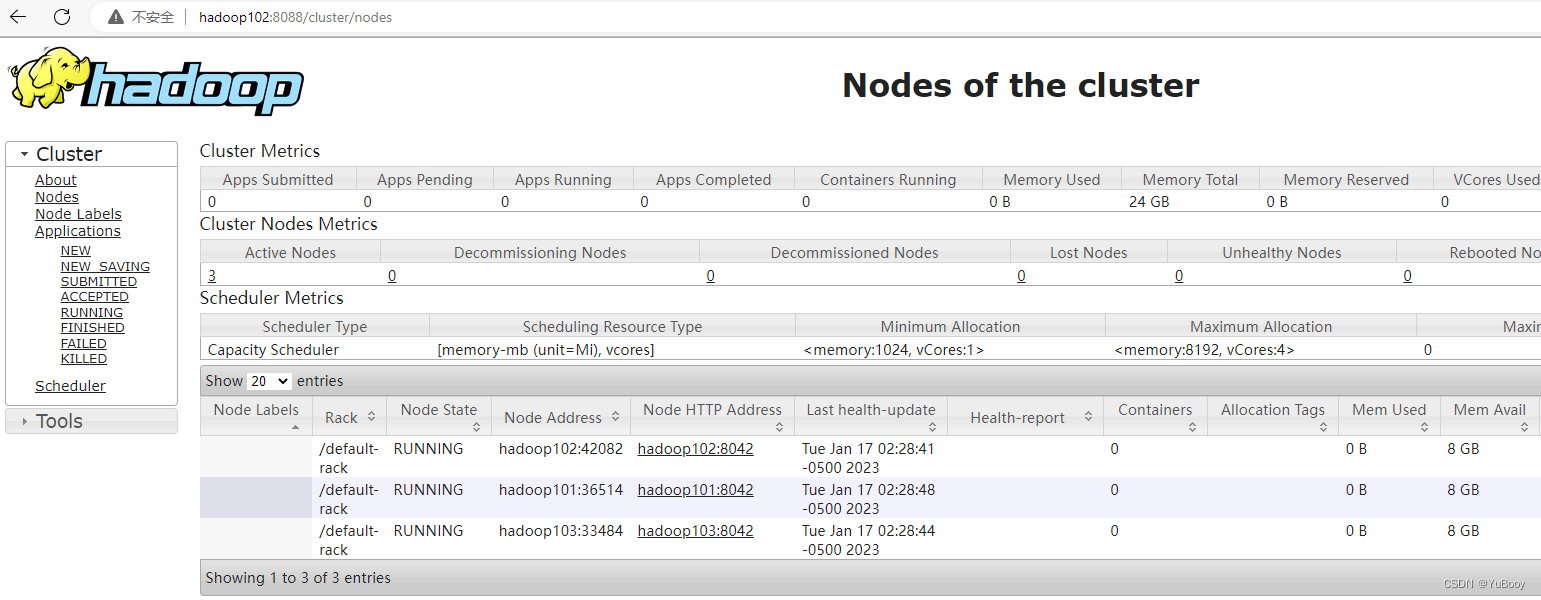
3、集群基本测试
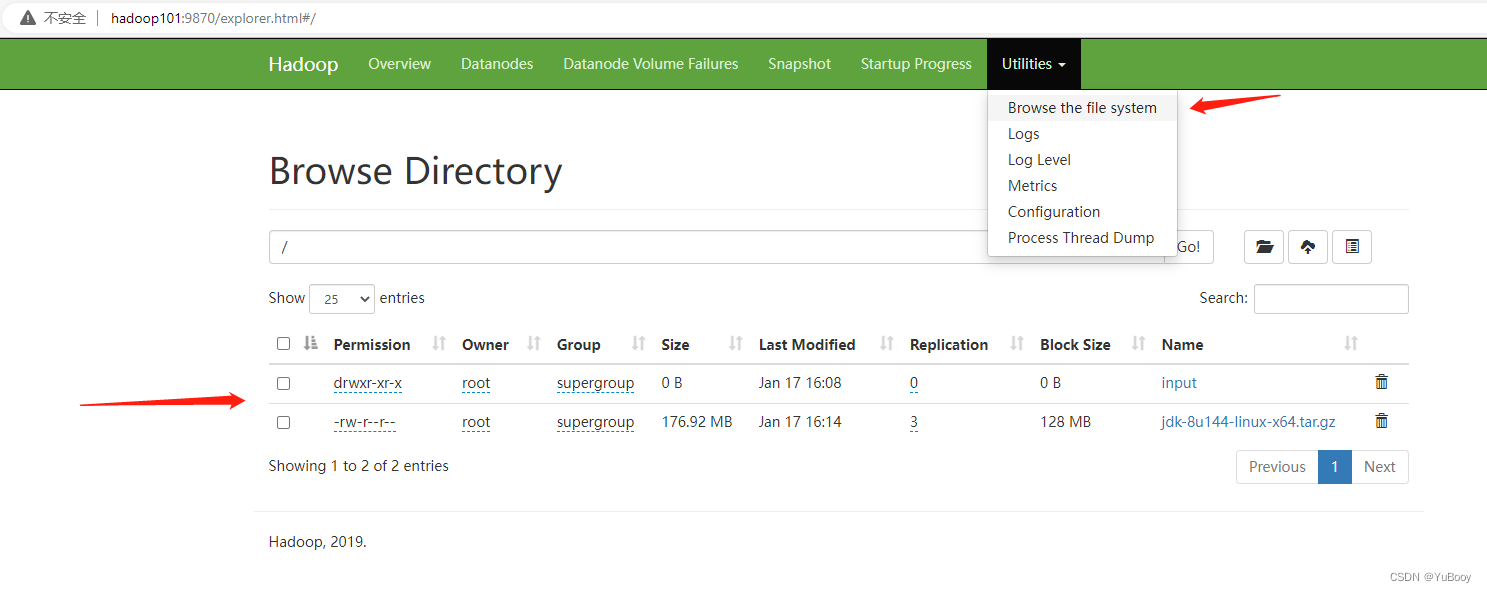
① 上传文件到集群
上传小文件
[root@hadoop101 ~]# hadoop fs -mkdir /input
[root@hadoop101 ~]# hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input上传大文件
[root@hadoop101 ~]# hadoop fs -put /opt/sofware/jdk-8u144-linux-x64.tar.gz /从 Web 页面查看上传的文件:
② 下载文件
[root@hadoop103 ~]# hadoop fs -get /jdk-8u144-linux-x64.tar.gz ./
③ 执行 wordcount 程序
[root@hadoop101 hadoop-3.1.3]# cd /opt/module/hadoop-3.1.3
[root@hadoop101 hadoop-3.1.3]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
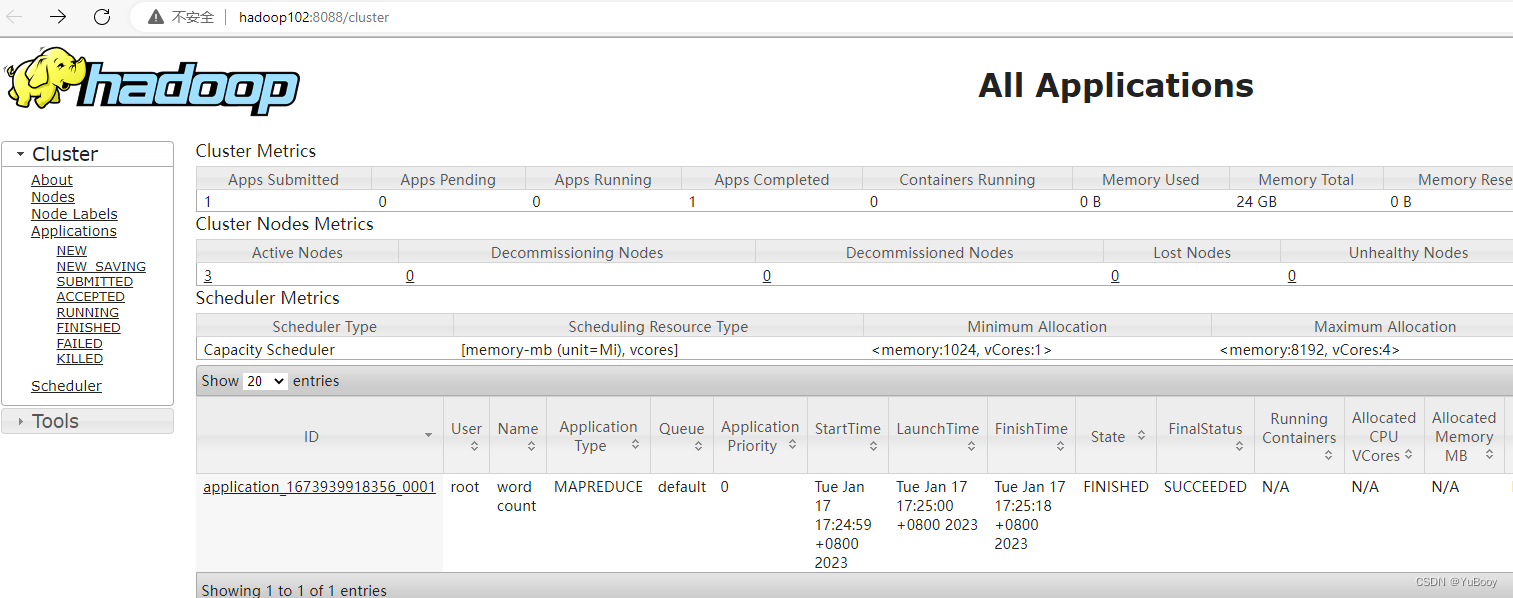
(6)集群启动/停止方式总结
1、各个模块分开启动/停止
① 整体启动 / 停止HDFS(需要在 NameNode 节点上执行)
start-dfs.sh / stop-dfs.sh
[root@hadoop101 hadoop-3.1.3]# /opt/module/hadoop-3.1.3/sbin/start-dfs.sh② 整体启动 / 停止YARN(需要在 ResourceManager 节点上执行)
start-yarn.sh / stop-yarn.sh
[root@hadoop102 hadoop-3.1.3]# /opt/module/hadoop-3.1.3/sbin/start-yarn.sh2、各个服务组件逐一启动/停止
① 分别启动 / 停止HDFS组件
hdfs --daemon start / stop namenode / datanode / secondarynamenode
② 启动 / 停止YARN
yarn --daemon start / stop resourcemanager / nodemanager
(7)常用端口号说明
| 端口名称 |
Hadoop2.x |
Hadoop3.x |
| NameNode内部通信端口 |
8020 / 9000 |
8020 / 9000/9820 |
| NameNode HTTP UI |
50070 |
9870 |
| MapReduce查看执行任务端口 |
8088 |
8088 |
| 历史服务器通信端口 |
19888 |
19888 |
参考: 资料来源:(尚硅谷)尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优)_哔哩哔哩_bilibili
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线