三天刷完《剑指OFFER编程题》--Java版本实现(第二天)_剑指offer java版-程序员宅基地
正在更新中。。。。。。。。。

剑指offer --Python版本的实现:
剑指offer(1/3)第一大部分
剑指offer(2/3)第二大部分
剑指offer(3/3)第三大部分
----------------------------------------------------
《剑指offer》Java版本实现:
《剑指offer》Java版本-第一天
《剑指offer》Java版本-第二天
《剑指offer》Java版本-第三天
27.字符串的排列
输入一个字符串,按字典序打印出该字符串中字符的所有排列。
例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba。
输入描述:
输入一个字符串,长度不超过9(可能有字符重复),字符只包括大小写字母。递归法,问题转换为先固定第一个字符,求剩余字符的排列;求剩余字符排列时跟原问题一样。
递归算法实现:
(1) 遍历出所有可能出现在第一个位置的字符(即:依次将第一个字符同后面所有字符交换);
(2) 固定第一个字符,求后面字符的排列(即:在第1步的遍历过程中,插入递归进行实现)。
以"abc"为例
1.第一次进到这里是ch=['a','b','c'],list=[],i=0,我称为 状态A ,即初始状态
那么j=0,swap(ch,0,0),就是['a','b','c'],进入递归,自己调自己,只是i为1,交换(0,0)位置之后的状态我称为 状态B
i不等于2,来到这里,j=1,执行第一个swap(ch,1,1),这个状态我称为 状态C1 ,再进入递归函数,此时标记为T1,i为2,那么这时就进入上一个if,将"abc"放进list中
-------》此时结果集为["abc"]
2.执行完list.add之后,遇到return,回退到T1处,接下来执行第二个swap(ch,1,1),状态C1又恢复为状态B
恢复完之后,继续执行for循环,此时j=2,那么swap(ch,1,2),得到"acb",这个状态我称为C2,然后执行递归函数,此时标记为T2,发现i+1=2,所以也被添加进结果集,此时return回退到T2处往下执行
-------》此时结果集为["abc","acb"]
然后执行第二个swap(ch,1,2),状态C2回归状态B,然后状态B的for循环退出回到状态A
// a|b|c(状态A)
// |
// |swap(0,0)
// |
// a|b|c(状态B)
// / \
// swap(1,1)/ \swap(1,2) (状态C1和状态C2)
// / \
// a|b|c a|c|b
3.回到状态A之后,继续for循环,j=1,即swap(ch,0,1),即"bac",这个状态可以再次叫做状态A,下面的步骤同上
-------》此时结果集为["abc","acb","bac","bca"]
// a|b|c(状态A)
// |
// |swap(0,1)
// |
// b|a|c(状态B)
// / \
// swap(1,1)/ \swap(1,2) (状态C1和状态C2)
// / \
// b|a|c b|c|a
4.再继续for循环,j=2,即swap(ch,0,2),即"cab",这个状态可以再次叫做状态A,下面的步骤同上
-------》此时结果集为["abc","acb","bac","bca","cab","cba"]
// a|b|c(状态A)
// |
// |swap(0,2)
// |
// c|b|a(状态B)
// / \
// swap(1,1)/ \swap(1,2) (状态C1和状态C2)
// / \
// c|b|a c|a|b
5.最后退出for循环,结束。
import java.util.ArrayList;
import java.util.List;
import java.util.Collections;
public class Solution {
public ArrayList<String> Permutation(String str) {
List<String> list = new ArrayList();
if (str.length() == 0) return (ArrayList)list;
permutationHelper(str.toCharArray(), 0, list); // 递归实现
Collections.sort(list);
return (ArrayList)list;
}
private void permutationHelper(char[] cs, int i, List<String> list){
if (i == cs.length-1){ // 如果索引是最后一位的话
String s = String.valueOf(cs);
if (!list.contains(s)){ // 防止有重复的字符串,如输入为 aab时
list.add(s);
return;
}
}else{
for (int j = i; j < cs.length; j++){
swap(cs, i, j);
permutationHelper(cs, i+1, list);
swap(cs, i, j); // 回溯法,恢复之前字符串顺序,达到第一位依次跟其他位交换的目的
}
}
}
private void swap(char[] cs, int i, int j){ // 交换两个字符
char temp;
temp = cs[i];
cs[i] = cs[j];
cs[j] = temp;
}
}28.数组中出现次数超过一半的数字
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。如果不存在则输出0。
#使用哈希表 思路: 使用hash,key是数字,value是出现的次数
import java.util.Map;
import java.util.HashMap;
public class Solution {
public int MoreThanHalfNum_Solution(int [] array) {
if (array.length == 0) return 0;
HashMap<Integer, Integer> map = new HashMap();
for (int i = 0; i < array.length; i++){
int num = array[i];
if (map.containsKey(num)){ // 如果原map中key值存在,则 + 1
map.put(num, map.get(num)+1);
}else{
map.put(num, 1);
}
}
for (Map.Entry<Integer, Integer> entry: map.entrySet()){ // 遍历所有的索引和值
if (entry.getValue() > array.length/2){
return entry.getKey();
}
}
return 0;
}
}29.最小的k个数
输入n个整数,找出其中最小的K个数。
例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,。
备注:
找到最小的n 个数值,使用最大堆
找到最大的n 个数值,使用最小堆
利用堆排序,O(N logK),适合处理海量数据
(1) 遍历输入数组,将前k个数插入到堆中;
(2) 继续从输入数组中读入元素做为待插入整数,并将它与堆中最大值比较:如果待插入的值比当前已有的最大值小,则用这个数替换当前已有的最大值;如果待插入的值比当前已有的最大值还大,则抛弃这个数,继续读下一个数。
这样动态维护堆中这k个数,以保证它只储存输入数组中的前k个最小的数,最后输出堆即可。
使用PriorityQueue当作Heap,每次返回最大的值,所以使用最大堆实现;
import java.util.Queue;
import java.util.PriorityQueue;
import java.util.Collections;
import java.util.ArrayList;
public class Solution {
public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) {
ArrayList<Integer> res = new ArrayList();
int size = input.length;
if (size == 0 || size < k || k <= 0) return res;
Queue<Integer> q = new PriorityQueue(k, Collections.reverseOrder()); // 最大堆
for (int i = 0; i < size; i++){
if (i+1 <= k){ // 如果不够k个数值,则放进最大堆中,最大堆会自动排序
q.add(input[i]);
}else{
if (input[i] < q.peek()){ // 如果最大堆中最大值小于 数组的值,则删除最大值
q.poll();
q.add(input[i]);
}
}
}
while(!q.isEmpty()){
res.add(q.poll());
}
return res;
}
}30.连续数组的最大和
HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学。今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向量全为正数的时候,问题很好解决。但是,如果向量中包含负数,是否应该包含某个负数,并期望旁边的正数会弥补它呢?
例如:{6,-3,-2,7,-15,1,2,2},连续子向量的最大和为8(从第0个开始,到第3个为止)。给一个数组,返回它的最大连续子序列的和,你会不会被他忽悠住?(子向量的长度至少是1)
链接:https://www.nowcoder.com/questionTerminal/459bd355da1549fa8a49e350bf3df484?f=discussion
使用动态规划
F(i):以array[i]为末尾元素的子数组的和的最大值,子数组的元素的相对位置不变
F(i)=max(F(i-1)+array[i] , array[i])
res:所有子数组的和的最大值
res=max(res,F(i))
如数组[6, -3, -2, 7, -15, 1, 2, 2]
初始状态:
F(0)=6
res=6
i=1:
F(1)=max(F(0)-3,-3)=max(6-3,3)=3
res=max(F(1),res)=max(3,6)=6
i=2:
F(2)=max(F(1)-2,-2)=max(3-2,-2)=1
res=max(F(2),res)=max(1,6)=6
i=3:
F(3)=max(F(2)+7,7)=max(1+7,7)=8
res=max(F(2),res)=max(8,6)=8
i=4:
F(4)=max(F(3)-15,-15)=max(8-15,-15)=-7
res=max(F(4),res)=max(-7,8)=8
以此类推
最终res的值为8
public class Solution {
public int FindGreatestSumOfSubArray(int[] array) {
int res = array[0];
int maxValue = array[0];
for (int i = 1; i < array.length; i++){
maxValue = Math.max(array[i], array[i] + maxValue);
res = Math.max(res, maxValue);
}
return res;
}
}31.整数1出现的个数
求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?
为此他特别数了一下1~13中包含1的数字有1、10、11、12、13因此共出现6次,但是对于后面问题他就没辙了。ACMer希望你们帮帮他,并把问题更加普遍化,可以很快的求出任意非负整数区间中1出现的次数(从1 到 n 中1出现的次数)。
1. 使用暴力的解法,将全部 0- n的数值保存到StringBuffer中,然后遍历它,如果等于 字符 '1', 则count+1;
public class Solution {
public int NumberOf1Between1AndN_Solution(int n) {
// 直接使用暴力的解法:
StringBuffer sb = new StringBuffer();
for (int i = 1; i<= n; i++){
sb.append(i);
}
String str = sb.toString();
int count = 0;
for (int i = 0; i< str.length(); i++){
if (str.charAt(i) == '1') count++;
}
return count;
}
}2. 找规律的方法:
我们以 345 这个数值作为例子找规律:
2.1 个位上1 出现的规律:
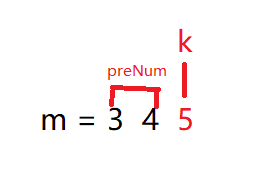
要求得 个位上 1 出现的次数,毫无疑问,它是和 百位、千位高位上的数字是相关的。
计算m 中个位出现的次数,看图 k(个位数)是大于1的,所以肯定会出现1,
第一种情况:k > 0
所以有: 001,011,021, 。。。 101,。。341 【注意: 此时不考虑其它位出现的次数】
00 到 34 共出现 35 次。 即 preNum + 1
第二种情况:k == 0:【即假如,m = 340的情况下】
我们知道340 个位上肯定是没有 1的,但是 0 到 339 会出现个位为1的情况呀,所以此时计算339个位上 1 出现的数量,是等价于340出现的数量
所以有:001,011,021.。。。331
00 到 33 共出现 34 次 ,即 preNum
总结:
设个位出现次数为:count
如果 k > 0, count = preNum + 1;
如果 k = 0, count = preNum ;
2.2 十位上1 出现的规律:
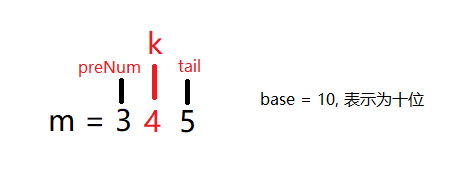
第一种情况: k > 1
出现的情况为: 01X, 11X, 21X, 31X , 其中 X 个位也会出现 10次,即 0-9, 4 乘以 10 为 40
0 到 3 共出现 40 次。即 (preNum + 1) * base
第二种情况: k == 0 【假如 m = 305】
同个位数找规律一样,我们也可以将 305 等价于 295,那此时 k 不为0,所以也可以套用 k > 1的规律
所以出现的次数为:01X, 11X, 21X , 其中 X 个位也会出现 10次, 3 乘以 10 为 30 , 即 preNum * base
第三种情况: k == 1 【假如 m = 315】
此时,这种情况下就与 个位数的值相关了,
我们知道 m=305时,十位出现1 的次数为 30次
306 - 309十位没有出现1, 310-315出现了 6次。
所以出现 30 + 6 次 即 preNum * base + tail + 1
总结:
设个位出现次数为:count
如果 k > 1, count = (preNum + 1) * base;
如果 k == 0, count = preNum * base ;
如果 k == 1, count = preNum * base + tail + 1 ;
2.3 十位的规律可以推广到百位、千位
例子:
- 534 = (个位1出现次数)+(十位1出现次数)+(百位1出现次数)
=(53*1+1)+(5*10+10)+(0*100+100)= 214
百位1出现次数为什么为100 呢?【100, 101, ---- 199】 100次
- 530 = (53*1)+(5*10+10)+(0*100+100) = 213
- 504 = (50*1+1)+(5*10)+(0*100+100) = 201
- 514 = (51*1+1)+(5*10+4+1)+(0*100+100) = 207
- 10 = (1*1)+(0*10+0+1) = 2
public class Solution {
public int NumberOf1Between1AndN_Solution(int n) {
int count = 0, base = 1;
int round = n;
while (round > 0){
int k = round % 10; // 获取
round /= 10;
count += round * base;
if (k == 1){
count += (n % base) + 1; // n 保存起来,用以计算 tail 的值
}else if (k > 1){
count += base;
}
base *= 10; // 更新base 的值, 计算十位,百位,千位的值
}
return count;
}
}32. 把数组排成最小数
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323。
这里自定义一个比较大小的函数,比较两个字符串s1, s2大小的时候,先将它们拼接起来,比较s1+s2,和s2+s1那个大,如果s1+s2大,那说明s2应该放前面,所以按这个规则,s2就应该排在s1前面。(类似于排序算法)
比如: s1 = 32, s2 = 321, 先将两者字符串转换成数字,比较 s1 + s2 = 32321, 和 s2 + s1 = 32132的数字的大小,
如果前者比较大的话,将s1 和 s2交换。
代码这里使用了一个小技巧:
int pre = Integer.valueOf(numbers[i] +"" + numbers[j]); // 将数字转换为字符串,拼接,再转换成数字
import java.util.ArrayList;
public class Solution {
public String PrintMinNumber(int [] numbers) {
String res = "";
for (int i = 0; i < numbers.length; i++){
for (int j = i+1; j < numbers.length; j++){
int pre = Integer.valueOf(numbers[i] +"" + numbers[j]); // 将数字转换为字符串,拼接,再转换成数字
int tail = Integer.valueOf(numbers[j] +"" + numbers[i]);
if (pre > tail){
int temp;
temp = numbers[i];
numbers[i] = numbers[j];
numbers[j] = temp;
}
}
}
for (int i = 0; i < numbers.length; i++){
res += numbers[i];
}
return res;
}
}33.丑数
丑数的定义:把只包含质因子2、3和5的数称作丑数(Ugly Number)。
例如6、8都是丑数,但14不是,因为它包含质因子7。 习惯上我们把1当做是第一个丑数。求按从小到大的顺序的第N个丑数。
首先从丑数的定义我们知道,一个丑数的因子只有2,3,5,那么丑数p = 2 ^ x * 3 ^ y * 5 ^ z,换句话说一个丑数一定由另一个丑数乘以2或者乘以3或者乘以5得到,那么我们从1开始乘以2,3,5,就得到2,3,5三个丑数,在从这三个丑数出发乘以2,3,5就得到4,6,10,6,9,15,10,15,25九个丑数,我们发现这种方法得到重复的丑数,而且我们题目要求第N个丑数。
(1)丑数数组: 1
乘以2的队列:2
乘以3的队列:3
乘以5的队列:5
选择三个队列头最小的数2加入丑数数组,同时将该最小的数乘以2,3,5放入三个队列;
(2)丑数数组:1,2
乘以2的队列:4
乘以3的队列:3,6
乘以5的队列:5,10
此时可能出现,乘以5 的数值大于 乘以3 的数值,所以要取 乘以3和乘以5的最小值
选择三个队列头最小的数3加入丑数数组,同时将该最小的数乘以2,3,5放入三个队列;
(3)丑数数组:1,2,3
乘以2的队列:4,6
乘以3的队列:6,9
乘以5的队列:5,10,15
选择三个队列头里最小的数4加入丑数数组,同时将该最小的数乘以2,3,5放入三个队列;
import java.util.ArrayList;
public class Solution {
public int GetUglyNumber_Solution(int index) {
if (index <= 0) return 0;
ArrayList<Integer> res = new ArrayList();
res.add(1);
int i2=0, i3=0, i5=0;
while (res.size() < index){
int i2_value = res.get(i2) * 2;
int i3_value = res.get(i3) * 3;
int i5_value = res.get(i5) * 5;
// 找到最小的值
int minValue = Math.min(i2_value, Math.min(i3_value, i5_value));
res.add(minValue);
if (i2_value == minValue) i2++; // 将index往后移动
if (i3_value == minValue) i3++;
if (i5_value == minValue) i5++;
}
return res.get(res.size()-1);
}
}34.第一次只出现一次的字符
在一个字符串(0<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置, 如果没有则返回 -1(需要区分大小写)
使用哈希解题,遍历字符串,哈希key值为遍历的单个字符,value为出现次数;最后重新遍历,找到一开始value为1的key值
import java.util.HashMap;
public class Solution {
public int FirstNotRepeatingChar(String str) {
int size = str.length();
if (size == 0) return -1;
HashMap<Character, Integer> map = new HashMap();
for (int i = 0; i < size; i++){
char value = str.charAt(i);
if (!map.containsKey(value)){ // 如果key 值不存在,则新建key值,value为1
map.put(value, 1);
}else{
map.put(value, map.get(value)+1); // value 值加一
}
}
for (int i=0; i < size; i++){
if (map.get(str.charAt(i)) == 1){
return i;
}
}
return -1;
}
}另外一种比较巧妙的方法:
主要还是hash,利用每个字母的ASCII码作hash来作为数组的index。首先用一个58长度的数组来存储每个字母出现的次数,为什么是58呢,主要是由于A-Z对应的ASCII码为65-90,a-z对应的ASCII码值为97-122,而每个字母的index=int(word)-65,比如g=103-65=38,而数组中具体记录的内容是该字母出现的次数,最终遍历一遍字符串,找出第一个数组内容为1的字母就可以了,时间复杂度为O(n)
public class Solution {
public int FirstNotRepeatingChar(String str) {
int size = str.length();
if (size == 0) return -1;
int[] array = new int[58];
for (int i = 0; i< size; i++){
array[(int)str.charAt(i)-65]++;
}
for (int i= 0; i < size; i++){
if (array[(int)str.charAt(i)-65] == 1){
return i;
}
}
return -1;
}
}35.数组的逆序对
首先我们先复习一下归并算法
归并排序算法流程:
(1)申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
(2)设定两个指针,最初位置分别为两个已经排序序列的起始位置
(3)比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
(4)重复步骤3直到某一指针达到序列尾
(5)将另一序列剩下的所有元素直接复制到合并序列尾
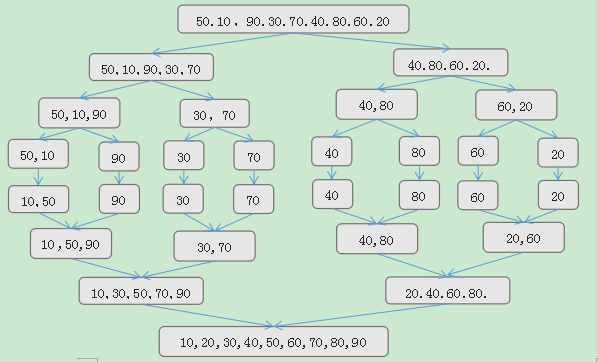
归并排序过程如下:
以数组{50,10,90,30,70,40,80,60,20}为例,
public class Main {
public static void MergeSort(int[] array, int low, int high){
int mid = (low + high) / 2;
if (low < high){
MergeSort(array, low, mid);
MergeSort(array, mid+1, high);
// 排序
Merge(array, low, mid, high);
}
}
public static void Merge(int[] array, int low, int mid, int high){
// 对两个有序数组进行排序
int left = low; // 左边数组第一个值
int right = mid + 1; // 右边数组第一个值
int tmpIndex = 0;
int[] tempArray = new int[high-low+1]; // 创建一个临时数组
while (left <= mid && right <= high){
if (array[left] < array[right]){ // 排序,如果左边值小于右边值,则先将左边数值放进临时数组
tempArray[tmpIndex++] = array[left++];
}else{
tempArray[tmpIndex++] = array[right++];
}
}
// 如果左边还有数值,则还需将其全部放入临时数组中
while (left <= mid){
tempArray[tmpIndex++] = array[left++];
}
// 如果右边还有数值,则还需将其全部放入临时数组中
while (right <= high){
tempArray[tmpIndex++] = array[right++];
}
// 将temp 临时数组放在array 待排数组中
for (int index = 0; index < tempArray.length; index++){
array[low + index] = tempArray[index];
}
}
public static void main(String[] args) {
// 实现一个归并排序算法
int[] array = {1, 4, 2, 7, 9, 5, 0};
int size = array.length;
Main.MergeSort(array, 0, size-1);
for (int i=0; i<size; i++){
System.out.println(array[i]);
}
}
}
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数P。并将P对1000000007取模的结果输出。 即输出P%1000000007
输入描述:
题目保证输入的数组中没有的相同的数字
数据范围:
对于%50的数据,size<=10^4
对于%75的数据,size<=10^5
对于%100的数据,size<=2*10^5
示例1
输入
1,2,3,4,5,6,7,0输出
7要找到数组中的逆序对,可以看做对数据进行排序,需要交换数组中的元素的次数,但是防止相同大小的元素发生交换,因此需要选择一个稳定的排序方法,记录发生交换的次数。
插入、冒泡、归并排序都是稳定的,这里使用归并算法
我们以数组arr[4]={7,5,6,4}为例来分析统计逆序对的过程。为了避免上述情况,我们考虑先比较两个相邻的数字。
我们先把数组分解成两个长度为2的子数组,再把这两个子数组分别拆分成两个长度为1的子数组。
即arr[start,end]可不断拆分成arr[start,mid],arr[mid+1,end]两个相邻的数组,其中mid=(start+end)/2;
直到start>=end,即arr当前子数组中最多只剩下一个元素,则不需要再次拆分了,此时一个元素内部不可能存在逆序对。
接下来一边合并相邻的子数组,一边统计逆序对的数目,最简单的方式是建立全局变量count。
在第一对长度为1的子数组{7}、{5}中,7大于5,因此(7,5)组成一个逆序对。同样,在第二对长度为1的子数组{6}、{4}中,也有逆序对(6,4)。
由于已经统计了这两对子数组内部的逆序对,需要把这两对子数组排序并合并,即形成两个长度为2的有序子数组{5,7},{4,6},以免之后再次重复统计。{5,7}在前,{4,6}在后,我们可以在初始数组上进行排序操作,此时原数组变为{5,7,4,6}。
若不能对原数组进行修改,则须对数组进行复制,注意:不能使用int[] a = arr;这种浅复制的复制形式。
接下来根据修改后的原数组arr[start,end]={5,7,4,6},统计相邻子数组arr[start,mid]{5,7},arr[mid+1,end]{4,6}之间的逆序对,并将两个相邻子数组中的数字进行排序并合并:
为了方便合并操作,采用归并排序中相邻数组排序的思路,引入参考数组tmp,为了避免多次合并中在循环中不断进行new操作,可以在一开始建立一个和初始数组一样大小的tmp数组,之后所有merge操作都共用这一个tmp;
首先建立两个指针i,j分别指向子数组的开头,即i指向5,j指向4,
此时:7大于6,即arr[i]>arr[j]时:
5 7 4 6 ,其中mid的索引值为1, (5,7,4)构成了2个逆序对,构成了 mid - i + 1个,由于左数组 5 7 是有序的,既然左边第一位都大于右边第一位,那左边第二位肯定大于右边第一位,所以先计算左边数组的距离,为mid-i, 间隔为1,再加上右边的间隔常数为1 .
public class Solution {
private int count;
public int InversePairs(int [] array) {
count = 0;
int size = array.length;
if (size == 0 || size == 1) return 0;
mergeSort(array, 0, size-1);
return count%1000000007;
}
private void mergeSort(int[] array, int low, int high){
int mid = (low + high) / 2;
if (low < high){
mergeSort(array, low, mid);
mergeSort(array, mid+1, high);
merge(array, low, mid, high);
}
}
private void merge(int[] array, int low, int mid, int high){
int i = low;
int j = mid + 1;
int tempIndex = 0;
int[] tempArray = new int[high-low+1];
while (i <= mid && j <= high){
if (array[i] <= array[j]){
tempArray[tempIndex++] = array[i++];
}else{
tempArray[tempIndex++] = array[j++];
count += mid - i + 1;
count %= 1000000007;
}
}
while (i <= mid){
tempArray[tempIndex++] = array[i++];
}
while (j <= high){
tempArray[tempIndex++] = array[j++];
}
for (int index = 0; index < tempArray.length; index++){
array[low + index] = tempArray[index];
}
}
}36.两个链表的第一个公共结点
输入两个链表,找出它们的第一个公共结点。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
公共结点的意思是两个链表相遇之后后面都是一样的
思路: 先获取到两个链表的长度,然后长的链表先走多的几步,之后一起遍历
假设两个链表公共长度为C,不公共的长度分别为A、B。 则两个链表长度分别为A+C,B+C。 设两个指针,让第一个链表走完之后,跳到第二个链表开始走,共A+C+X1距离;同理第二个链表走完后调到第一个链表开始走,走B+C+X2距离。
那么两个指针相遇时,由 A+C+X1 = B+C+X2,距离不为负,得X1=A,X2=B,所以最后两个指针走的距离都是A+B+C,刚好在第一个公共点相遇。
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
if (pHead1 == null || pHead2 == null) return null;
ListNode p1 = pHead1;
ListNode p2 = pHead2;
int size1 = getLinkLenth(p1);
int size2 = getLinkLenth(p2);
while (size1 > size2){ // 如果链表1较长,则先走 size1 - size2步
pHead1 = pHead1.next;
size1 -= 1;
}
while (size1 < size2){
pHead2 = pHead2.next;
size2 -= 1;
}
while (pHead1 != null){ // 如果找到两个节点相等,则有公共节点
if (pHead1 == pHead2){
return pHead1;
}
pHead1 = pHead1.next;
pHead2 = pHead2.next;
}
return null;
}
private int getLinkLenth(ListNode root){ // 计算链表的长度
if (root == null) return 0;
if (root.next == null) return 1;
int res = 0;
while (root != null){
res += 1;
root = root.next;
}
return res;
}
}37.数字在排序数组中出现的次数
统计一个数字在升序数组中出现的次数。
如: 1, 2, 4, 6, 7, 7, 7, 8, 10
7出现次数为3
思路:

使用二分法分别找到数组中第一个和最后一个出现的值的坐标,然后相减 + 1
public class Solution {
public int GetNumberOfK(int [] array , int k) {
int size = array.length;
if (size == 0) return 0;
int firstK = getFirstK(array, k);
int lastK = getLastK(array, k);
if (firstK == -1 && lastK == -1) return 0; //如果前后都找不到 k,则没有k
if (firstK == -1 || lastK == -1) return 1; // 如果只找到一项,则只有1个k
return lastK - firstK + 1;
}
private int getFirstK(int[] array, int k){ // 获取k值的第一个索引值
int size = array.length;
int start = 0, end = size-1;
while (start <= end){
int mid = (start + end) / 2;
if (array[mid] < k){
// 判断下一个 mid+1 是否等于 k
if (mid+1<size && array[mid+1] == k){
return mid+1;
}
start = mid + 1; // 搜索右半部分
}else if (array[mid] == k){ // 由于需要找到第一个k的索引值,所以还需要判断
//1.如果mid是0,则直接返回;2.如果前一个mis-1值小于k,则直接返回mid
if (mid - 1<0 ||(mid - 1>=0 && array[mid-1] < k)){
return mid;
}
end = mid - 1; // 此时k可能在左边, 搜索左边
}else{
end = mid-1;
}
}
return -1;
}
private int getLastK(int[] array, int k){
int size = array.length;
int start = 0, end = size-1;
while (start <= end){
int mid = (start + end) / 2;
if (array[mid] < k){
start = mid + 1;
}else if (array[mid] == k){ // 找到最右边k的索引值
// 1.如果mid在最右边,则直接返回 2.如果mid+1个值小于k,则返回mid
if (mid+1 == size || (mid + 1 < size && array[mid+1] > k)){
return mid;
}
start = mid + 1; // 搜索右边
}else{
// 如果前一个值刚好等于k
if (mid -1 >= 0 && array[mid-1] == k){
return mid -1;
}
end = mid - 1;
}
}
return -1;
}
}38.二叉树的深度
输入一棵二叉树,求该树的深度。从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。
解题思路:树结构一般都是使用递归
从根节点出发, 查询左子树的深度 、右子树的深度,取两者较大的值,再加一 ,就是整个二叉树的深度
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public int TreeDepth(TreeNode root) {
if(root == null) return 0;
if (root.left == null && root.right == null) return 1;
int leftDepth = TreeDepth(root.left); // 计算左子树深度
int rightDepth = TreeDepth(root.right);
return Math.max(leftDepth, rightDepth) + 1; // 取左右子树最大的深度
}
}39.平衡二叉树
输入一棵二叉树,判断该二叉树是否是平衡二叉树。
平衡二叉树的定义:
-
平衡二叉树要么是一棵空树
-
要么保证左右子树的高度之差不大于 1
-
子树也必须是一颗平衡二叉树

基于二叉树的深度,再次进行递归。以此判断左子树的高度和右子树的高度差是否大于1,若是则不平衡,反之平衡。
public class Solution {
public boolean IsBalanced_Solution(TreeNode root) {
if (root == null) return true;
int leftDepth = getTreeDepth(root.left);
int rightDepth = getTreeDepth(root.right);
if (Math.abs(leftDepth-rightDepth) > 1){ // 判断两颗子树深度绝对值是否大于1
return false;
}
boolean leftTree = IsBalanced_Solution(root.left);
boolean rightTree = IsBalanced_Solution(root.right); // 递归判断右子树
return (leftTree & rightTree); //需要满足左右子树都满足平衡二叉树
}
private int getTreeDepth(TreeNode root){ // 计算树的深度
if (root == null) return 0;
if (root.left == null && root.right == null) return 1;
int leftDepth = getTreeDepth(root.left);
int rightDepth = getTreeDepth(root.right);
return Math.max(leftDepth, rightDepth) + 1;
}
}40.数组中只出现一次的数字
一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。
使用哈希表,这是比较容易想到的方法
//num1,num2分别为长度为1的数组。传出参数
//将num1[0],num2[0]设置为返回结果
import java.util.HashMap;
public class Solution {
public void FindNumsAppearOnce(int [] array,int num1[] , int num2[]) {
int size = array.length;
HashMap<Integer, Integer> map = new HashMap();
for (int i = 0; i < size; i++){
if (!map.containsKey(array[i])){
map.put(array[i], 1);
}else{
map.put(array[i], map.get(array[i]) + 1);
}
}
// 获取value值为 1 的key值
boolean sign = false;
for (int i = 0; i < size; i++){
if (map.get(array[i]) == 1){
if (sign == false){
num1[0] = array[i];
sign = true;
}else{
num2[0] = array[i];
}
}
}
}
}使用异或
使用的原则是:
位运算中异或的性质:两个相同数字异或=0,一个数和0异或还是它本身。
当只有一个数出现一次时,我们把数组中所有的数,依次异或运算,最后剩下的就是落单的数,因为成对儿出现的都抵消了。
只不过这里使用两次异或,内在还是要将不同的两个数字分开,再异或。
任何一个数字异或他自己都等于0,0异或任何一个数都等于那个数。数组中出了两个数字之外,其他数字都出现两次,那么我们从头到尾依次异或数组中的每个数,那么出现两次的数字都在整个过程中被抵消掉,那两个不同的数字异或的值不为0,也就是说这两个数的异或值中至少某一位为1。
我们找到结果数字中最右边为1的那一位i,然后一次遍历数组中的数字,如果数字的第i位为1,则数字分到第一组,数字的第i位不为1,则数字分到第二组。这样任何两个相同的数字就分到了一组,而两个不同的数字在第i位必然一个为1一个不为1而分到不同的组,然后再对两个组依次进行异或操作,最后每一组得到的结果对应的就是两个只出现一次的数字。
//num1,num2分别为长度为1的数组。传出参数
//将num1[0],num2[0]设置为返回结果
public class Solution {
public void FindNumsAppearOnce(int [] array,int num1[] , int num2[]) {
int size = array.length;
if (size == 0) return ;
int num = 0;
for (int i = 0; i < size; i++){
num ^= array[i];
}
int index = getFirstBitOne(num);
for (int i = 0; i< size; i++){
if(isBitOne(array[i], index)){
num1[0] ^= array[i];
}else{
num2[0] ^= array[i];
}
}
}
private int getFirstBitOne(int num){
int index = 0;
while ((num & 1) == 0 && index < 32){
num >>= 1;
index += 1;
}
return index;
}
private boolean isBitOne(int num, int index){
// 判断num在第index位是否为 1
return (((num >> index)& 1) == 1);
}
}41.和为s 的连续正序数列
小明很喜欢数学,有一天他在做数学作业时,要求计算出9~16的和,他马上就写出了正确答案是100。但是他并不满足于此,他在想究竟有多少种连续的正数序列的和为100(至少包括两个数)。没多久,他就得到另一组连续正数和为100的序列:18,19,20,21,22。现在把问题交给你,你能不能也很快的找出所有和为S的连续正数序列? Good Luck!
输出描述:
输出所有和为S的连续正数序列。序列内按照从小至大的顺序,序列间按照开始数字从小到大的顺序
双指针技术,就是相当于有一个窗口,窗口的左右两边就是两个指针,我们根据窗口内值之和来确定窗口的位置和宽度
import java.util.ArrayList;
public class Solution {
public ArrayList<ArrayList<Integer> > FindContinuousSequence(int sum) {
ArrayList<ArrayList<Integer> > res = new ArrayList();
int low = 1, high = 2;
while (high > low){
int curSum = (high + low) * (high-low+1) / 2;
if (curSum == sum){
ArrayList<Integer> list = new ArrayList();
for (int i = low; i <= high; i++){
list.add(i);
}
res.add(list);
low += 1;
}else if (curSum < sum){
high += 1;
}else{
low += 1;
}
}
return res;
}
}
42.和为s 的两个数字
题目描述
输入一个递增排序的数组和一个数字S,在数组中查找两个数,使得他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的。
输出描述:
对应每个测试案例,输出两个数,小的先输出。
从左右一起查找
因为当两个数的和一定的时候, 两个数字的间隔越大, 乘积越小
所以直接输出查找到的第一对数即可
import java.util.ArrayList;
public class Solution {
public ArrayList<Integer> FindNumbersWithSum(int [] array,int sum) {
ArrayList<Integer> res = new ArrayList<Integer>();
int low = 0, high = array.length-1;
while (high > low){
int curSum = array[low] + array[high];
if (curSum < sum){
low += 1;
}else if (curSum > sum){
high -= 1;
}else{
res.add(array[low]);
res.add(array[high]);
return res;
}
}
return res;
}
}43. 左旋转字符串
汇编语言中有一种移位指令叫做循环左移(ROL),现在有个简单的任务,就是用字符串模拟这个指令的运算结果。对于一个给定的字符序列S,请你把其循环左移K位后的序列输出。
例如,字符序列S=”abcXYZdef”,要求输出循环左移3位后的结果,即“XYZdefabc”。是不是很简单?OK,搞定它!
解题思路:
原理:YX = (X^T Y ^T) ^T,初始看这种想法还是蛮有技巧的
假设输入str为abcXYZdef,n=3
反转前3个字符,得到cbaXYZdef
反转第n个字符后面所有的字符cbafedZYX
反转整个字符串XYZdefabc
public class Solution {
public String LeftRotateString(String str,int n) {
int size = str.length();
if (size == 0 || n < 0) return "";
n = n % size;
char[] strChar = str.toCharArray();
reverse(strChar, 0, n-1); // 前n 个字符反转
reverse(strChar, n, size-1); // n个字符后反转
reverse(strChar, 0, size-1); // 将反转了的字符串再反转
return new String(strChar);
}
// 二分法将数组反转
private void reverse(char[] strChar, int start, int end){
while (start < end){
char temp = strChar[start];
strChar[start] = strChar[end];
strChar[end] = temp;
start += 1;
end -= 1;
}
}
}第二种方法:拼接方法
public class Solution {
public String LeftRotateString(String str,int n) {
int size = str.length();
if (size == 0 || n < 0) return "";
n = n % size;
str += str;
return str.substring(n, size+n);
}
}44.翻转单词序列
牛客最近来了一个新员工Fish,每天早晨总是会拿着一本英文杂志,写些句子在本子上。同事Cat对Fish写的内容颇感兴趣,有一天他向Fish借来翻看,但却读不懂它的意思。
例如,“student. a am I”。后来才意识到,这家伙原来把句子单词的顺序翻转了,正确的句子应该是“I am a student.”。Cat对一一的翻转这些单词顺序可不在行,你能帮助他么?
1.将 字符串转换成字符串数组
2. 新建一个空间
3. 从字符串数组尾部开始遍历
4.将其字符存放到新的空间,并每次增加空格
public class Solution {
public String ReverseSentence(String str) {
if (str.trim().equals("")) return str;
String[] s = str.split(" ");
StringBuffer sb = new StringBuffer();
for (int i = s.length-1; i >= 0; i--){
sb.append(s[i]);
if (i > 0){
sb.append(" ");
}
}
return sb.toString();
}
}45.扑克牌的顺子
LL今天心情特别好,因为他去买了一副扑克牌,发现里面居然有2个大王,2个小王(一副牌原本是54张^_^)...他随机从中抽出了5张牌,想测测自己的手气,看看能不能抽到顺子,如果抽到的话,他决定去买体育彩票,嘿嘿!!“红心A,黑桃3,小王,大王,方片5”,“Oh My God!”不是顺子.....LL不高兴了,他想了想,决定大\小 王可以看成任何数字,并且A看作1,J为11,Q为12,K为13。上面的5张牌就可以变成“1,2,3,4,5”(大小王分别看作2和4),“So Lucky!”。LL决定去买体育彩票啦。 现在,要求你使用这幅牌模拟上面的过程,然后告诉我们LL的运气如何, 如果牌能组成顺子就输出true,否则就输出false。为了方便起见,你可以认为大小王是0。
先置换特殊字符AJQK为数字,排序,然后求出大小王即0的个数,然后求出除去0之外的,数组间的数字间隔(求间隔的时候记得减去1,比如4和5的间隔为5-4-1,表示4和5是连续的数字),同时求间隔的时候需要鉴别是否出现对。最后比较0的个数和间隔的大小即可。
# 如果出现相同的数,则必定不是顺子
1、排序
2、计算所有相邻数字间隔总数
3、计算0的个数
4、如果2、3相等,就是顺子
5、如果出现对子,则不是顺子
import java.util.Arrays;
public class Solution {
public boolean isContinuous(int [] numbers) {
int size = numbers.length;
if (size < 5) return false;
int oneNums = 0;
int intervalNums = 0;
Arrays.sort(numbers); // 对数组排序
for (int i = 0; i < size-1; i++){
if (numbers[i] == 0){
oneNums += 1;
continue;
}
if (numbers[i] == numbers[i+1]) return false; // 此行代码要放在==0判断后面,防止有2个0
intervalNums += numbers[i+1] - numbers[i] - 1;
}
if (oneNums >= intervalNums) return true;
return false;
}
}
智能推荐
新建vue2.0项目_新建vue2项目,定义data和methods,使页面输出-程序员宅基地
文章浏览阅读897次。vue入门下载安装node环境安装网址:https://nodejs.org/en/ 检查安装,输出版本号则安装成功为了提高效率,可以使用淘宝镜像npm install -g cnpm -registry=https://registry.npm.taobao.org,输入即可安装npm 镜像 ,以后用到npm的地方就可以用cnpm来代替,搭建vue项目环境全局安装vue-clinpm install @vue/cli -g 使用vue -V查看版本..._新建vue2项目,定义data和methods,使页面输出
vue iframe嵌套外部网页_vue嵌套iframe外部页面-程序员宅基地
文章浏览阅读3.6k次。<template> <div> <iframe src="外部网页url" id="mobsf" frameborder="0" style="position:absolute;"></iframe> </div></template><script> export default { data () { return { } }, mounte_vue嵌套iframe外部页面
电子邮件系统原理详解-程序员宅基地
文章浏览阅读393次。电子邮件系统中一般有邮件用户代理(MUA)、邮件传输代理(MTA)、邮件投递代理(MDA)电子邮件协议包括: 1、SMTP(简单邮件传输协议),监听在tcp25号端口,用于发送邮件 2、POP3(邮局协议),监听在tcp110端口,用于接收邮件 3、IMAP(互联网邮件访问协议),监听在tcp143端口,同样用于接收邮件,但还提供摘要浏览功..._电子邮件系统由以下四个部分组成:邮件用户代理mua、邮件传输代理mta、邮件递交代
如何在Dockerfile中安装私有Git包_dockerfile git-程序员宅基地
文章浏览阅读1.2k次。前路浩浩荡荡,万物皆可期待_dockerfile git
pyecharts简单实现桑吉图_pyecharts sankey 从右往左-程序员宅基地
文章浏览阅读849次,点赞2次,收藏6次。桑吉图的简单实现主要用到的工具函数import pandas as pd from pyecharts.charts import Sankeyimport pyecharts.options as optsdt = pd.read_excel("C:/Users/ganyu/Desktop/ceshi.xlsx")数据的样子一共要将原始数据处理成两份桑吉图专用的数据。一份是所..._pyecharts sankey 从右往左
mysql 变更长度报错 1118 Row size too large._1118 - row size too large. the maximum row size fo-程序员宅基地
文章浏览阅读5k次,点赞2次,收藏2次。场景在开发过程中,需要对原有的字段varchar 扩大长度。执行更新语句sqlALTER TABLE `xxx` MODIFY `字段名` varchar(64);报错ALTER TABLE xxx MODIFY 字段名 varchar(64)1118 - Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage _1118 - row size too large. the maximum row size for the used table type, not
随便推点
2011-02-27 CLRS Chapter24 Single-Source Shortest Paths 单源点最短路径_clrs 24-3-程序员宅基地
文章浏览阅读612次。2011-02-27 CLRS Chapter24 Single-Source Shortest Paths 单源点最短路径_clrs 24-3
docker将springboot生成的jar包构建成镜像并执行_dockerfile制作基于springboot jar镜像-程序员宅基地
文章浏览阅读618次。1、编写Dockerfile文件 FROM java:latest ADD alertmanager-0.0.1-SNAPSHOT.jar app.jarRUN bash -c 'touch /app.jar'ENTRYPOINT ["java","-jar","/app.jar"]FROM 跟的是已经有的java镜像和版本号 其中倾斜部分为..._dockerfile制作基于springboot jar镜像
Machine Learning 简介与学习路线-程序员宅基地
文章浏览阅读6.9k次,点赞2次,收藏16次。Machine Learning 简介与学习路线数据挖掘:机器学习(Machine Learning)有众多的应用领域,目前比较活跃的主要是数据挖掘(data mining),计算机视觉(computer vision, CV),自然语言处理(natural language processing, NLP),机器人决策这四大领域。数据挖掘:通俗的说是从大量已获取的案例中寻找出数据的关系..._machine learning
安卓和ios针对小程序兼容以及小程序技术实现上本身遇到的一些问题_小程序安卓和ios兼容问题-程序员宅基地
文章浏览阅读3.3k次。ios:1.ios对全屏设置定位,切换闪动问题、可以上下超出滑动问题_小程序安卓和ios兼容问题
过分!虾皮被曝大范围毁约;深度学习技巧全辑;MongoDB开源替代 4.7K★;剑指Offer解题代码;大数据算法笔记汇总;前沿论文 | ShowMeAI资讯日报-程序员宅基地
文章浏览阅读9.6k次。ShowMeAI资讯日报 08-27 期,lm-debugger 检查和调整基于transformer的语言模型、camviz 对单目深度估计结果进行可视化、surgeon-pytorch 检视PyTorch模型中间层、xh 发送HTTP请求、FerretDB 完美替代MongoDB的开源工具、大数据算法基础课·笔记集锦、剑指 Offer解题代码·Python&Java&C++、MedMCQA 医学入学考试问答数据集、深度学习过程加速技巧集、前沿论文…点击获取全部资讯...
vue3 + crypto-js加密解密(普通版本/TS版本)_vue3 crypto-js-程序员宅基地
文章浏览阅读1.1w次,点赞8次,收藏17次。前言:在vue中使用crypto-js 来实现对密码的加密和解密。vue3:1、安装:npm install crypto-js2、封装方法 aes.jsimport CryptoJS from 'crypto-js'/** * AES 加密 * @param word: 需要加密的文本 * KEY: // 需要前后端保持一致 * mode: ECB // 需要前后端保持一致 * pad: Pkcs7 //前端 Pkcs7 对应 后端 Pkcs5 ..._vue3 crypto-js