训练集准确率很高,验证集准确率低问题_训练集准确率高,测试集准确率低-程序员宅基地
训练集在训练过程中,loss稳步下降,准确率上升,最后能达到97%
验证集准确率没有升高,一直维持在50%左右(二分类问题,随机概率)
测试集准确率57%
在网上搜索可能打的原因:
1.learning rate太小,陷入局部最优
2.训练集和测试集数据没有规律
3.数据噪声太大
4.数据量太小(总共1440个样本,80%为训练集)
5.训练集和测试集数据分布不同:如训练集正样本太少(如果训练集和测试集每次运行随机选择,则排除)
6.数据集存在问题,如标注有问题(如采用公开数据集,则排除)
7.学习率过大
8.模型参数量过多而数据量过少
9.过拟合,数据量太小但是模型的结构较为复杂
解决办法:降低模型的复杂度,增大L2正则项,在全连接层加入Dropout层;有了dropout,网络不会为任何一个特征加上很高的权重(因为那个特征的输入神经元有可能被随机删除),最终dropout产生了收缩权重平方范数的效果
10.输入到网络中的特征有问题,特征与label之间没有很明确的关联,或特征太少
11.数据没有归一化
12.修改学习率,使得每次梯度下降低于某个值或者停止下降时,降低学习率,来使得梯度进一步下降。(我使用该方法,使得问题得到解决)
【备注:
batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值。】
针对第12点,修改学习率的举例如下:(基于pytorch)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1) # 设定优优化器更新的时刻表
def train(...):
for i, data in enumerate(train_loader):
......
y_ = model(x)
loss = criterion(y_,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
......
# 开始训练
for epoch in range(epochs):
scheduler.step() #在每轮epoch之前更新学习率
train(...)
veritf(...)
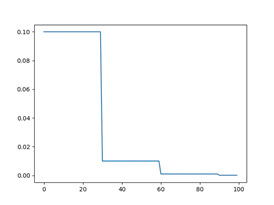
等间隔调整学习率 StepLR
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
每训练step_size个epoch,学习率调整为lr=lr*gamma.
参数:
optimizer: 神经网络训练中使用的优化器,如optimizer=torch.optim.SGD(…)
step_size(int): 学习率下降间隔数,单位是epoch,而不是iteration.
gamma(float): 学习率调整倍数,默认为0.1
last_epoch(int): 上一个epoch数,这个变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整;当为-1时,学习率设置为初始值。
学习率变化如下图所示:
当然调整学习率的方式还有很多:
多间隔调整学习率 MultiStepLR
指数衰减调整学习率 ExponentialLR
余弦退火函数调整学习率:
根据指标调整学习率 ReduceLROnPlateau
自定义调整学习率 LambdaLR
网上都可以查到,这里就不一一列举了。
欢迎留言讨论~ ^ _ ^
# 前面省略了一部分代码,下面的代码仅供代码格式参考:
args = parser.parse_args()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
best_acc = 0
start_epoch = 0
# Data
print('==> Preparing data..')
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
dict_datasets={
'CIFAR10':torchvision.datasets.CIFAR10, 'CIFAR100':torchvision.datasets.CIFAR100}
trainset = dict_datasets[args.datasets](
root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=args.batchsize, shuffle=True, num_workers=0)
testset = dict_datasets[args.datasets](
root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(
testset, batch_size=args.batchsize_test, shuffle=False, num_workers=0)
global_x.plot_lr=[]
best_acc=0
# Model
print('==> Building model..')
net = dict_model[args.model]
net = net.to(device)
if device == 'cuda':
net = torch.nn.DataParallel(net)
cudnn.benchmark = True
criterion = nn.CrossEntropyLoss()
#####################################################
optimizer = optim.SGD(net.parameters(), lr=args.lr,
momentum=0.8, weight_decay=5e-4)
scheduler = lr_scheduler.Warmup_lineardecay(optimizer, T_max=args.epochs, improved=args.improved)
##################################################
# Training
train_Acc=np.array([])
train_Loss=np.array([])
def train(epoch):
global train_Acc
global train_Loss
print('\nEpoch: %d' % epoch)
net.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
##################梯度更新
optimizer.step()
##################
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
train_Acc=np.append(train_Acc,100.*correct/total)
train_Loss=np.append(train_Loss,train_loss/(batch_idx+1))
if not os.path.exists(args.model):
os.mkdir(args.model)
np.savetxt(args.model+'/result_of_train_acc.txt',train_Acc,fmt='%f')
np.savetxt(args.model+'/result_of_train_loss.txt',train_Loss,fmt='%f')
test_Acc=np.array([])
test_Loss=np.array([])
def test(epoch):
global test_Acc
global test_Loss
global best_acc
net.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
DATA_predict=np.empty([0,10])
DATA_predict_index=np.empty([0,1])
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
DATA_predict=np.append(DATA_predict,outputs.cpu(),axis=0)
DATA_predict_index=np.append(DATA_predict_index,targets.view(-1,1).cpu(),axis=0)
progress_bar(batch_idx, len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss/(batch_idx+1), 100.*correct/total, correct, total))
test_Acc=np.append(test_Acc,100.*correct/total)
global_x.reference_acc = correct/total
test_Loss=np.append(test_Loss,test_loss/(batch_idx+1))
np.savetxt(args.model+'/result_of_test_acc.txt',test_Acc,fmt='%f')
np.savetxt(args.model+'/result_of_test_loss.txt',test_Loss,fmt='%f')
# Save checkpoint.
acc = 100.*correct/total
if acc > best_acc:
np.savetxt(args.model+'_DATA_predict.txt',DATA_predict,fmt='%f')
np.savetxt(args.model+'_DATA_predict_index.txt',DATA_predict_index,fmt='%d')
print('Saving..')
state = {
'net': net.state_dict(),
'acc': acc,
'epoch': epoch,
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/ckpt.pth')
best_acc = acc
for epoch in range(start_epoch, start_epoch+args.epochs):
train(epoch)
test(epoch)
################学习率更新,每轮更新一次,有些学习率的更新是每次迭代更新一次,注意区分,如果是每次迭代更新一次,可以把这一行放在梯度更新的下一行
scheduler.step()
###################
对于此问题,进行的更新:
以下内容参考
版权声明:本文为CSDN博主「TinaO-O」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013249853/article/details/89393982
0.学习率设置太高,一个epoch直接收敛,所以损失不会下降
比如学利率一开始设置为1,因为下降太快,那么很有可能在一个epoch旧完全收敛。所以看到的validation数值并不下降,第一个epoch就已经处于谷底了。所以如果使用的是系统默认的学习率,最好检查下默认值是什么。
1.最常见的原因:过拟合
过拟合值得单独开个章节。主要包括
1.数据量小,网络复杂
2.learning rate 比较高,又没有设置任何防止过拟合的机制
解决方法主要包括
1.简化模型,利用现有深度学习手段增加数据(翻转,平移,随机裁剪,imgaug)
2.利用 dropout层
3.利用正则化
2.没有把数据规格化
图片的话,img/255是肯定的
3.没有在分验证集之前打乱数据
因为validation_split操作不会为你shuffle数据,所以如果你的数据前一半标签全是1 ,后一半全是0,validation=0.5。恭喜你,你压根也分不对,你的validation准确率会一直为0.因为你拿所有的正样本训练,却想判断负样本。
4.数据和标签没有对上
有可能再读取自定义的数据库的时候出现问题,导致数据与标注不对应。比如第一张图片用第十张的标注
5.你的训练数据太少,validation数据太多,类别也太多
比如4000张训练,1000张validation,300类,这显然就是不合理的。
遇到这种情况,建议:
1.使用别的大的数据集预训练
2.使用DATA augment
3.可以考虑迁移学习
6.最好使用预训练的权重
大多数流行的backone比如resnet都有再imagenet数据集上与训练过,那么使用这种权重,比起随即重新训练,显然要可靠不少注意调整学习率。
7.网络结构有问题
可以通过使用现在流行的网络(resnet,unet等)替入你的代码,如果结果没有问题,你的结果有问题那么肯定就是你网络结构出问题了。那么可以通过逐层注释掉排查究竟哪里出了问题
7.1 网络最后一层没有使用正确的激活函数
比如多类的应该使用softmax
8.relu后面是softmax
有一些说法是relu由于对于很大的数值直接复制,所以会对softmax产生不好的影响,从而输出不好的结果。所以可以使用tanh代替relu。
9.batch normalization需要batch size至少16张
https://mp.csdn.net/postedit/89456400
由于做dense prediction图片通常比较大。所以一个batch一般都只有1-2张图片,不建议使用 BN。
因为BN一般是16张图片以上一起跑。所以吧,如果是BN,那么请用多GPU,16以上的batch size。s
另外keras TF1.x可能会出问题,https://github.com/keras-team/keras/pull/9965
10.可能设置了一些参数是不可训练的
在训练语句之前,检查以下你的trainable参数,是否设置了一些参数是不可训练的。这还可能导致你的输出只能是一个值,比如永远预测为标注0,因为你只有一点点的参数,而这并不是一个模型(比如只有100个参数是可以训练的,太简单了,无法模拟)。
11.附送一个调参论文
Bag of Tricks for Image Classification with Convolutional Neural Networks
https://arxiv.org/abs/1812.01187
智能推荐
github入门教程(非常详细)从零基础入门到精通,看完这一篇就够了-程序员宅基地
文章浏览阅读2.7w次,点赞57次,收藏514次。如果你是一枚Coder,但是你不知道Github,那么我觉的你就不是一个菜鸟级别的Coder,因为你压根不是真正Coder,你只是一个Code搬运工。说明你根本不善于突破自己!为什么这么说原因很简单,很多优秀的代码以及各种框架源码都存放于github当中!_github
c 语言a作用,C语言菜鸟基础教程之a++与++a-程序员宅基地
文章浏览阅读3.4k次。(一)a++在C语言或其它语言中,++符号表示“自加”,就是变量在原来的基础上加1。例1:a = 0;a++;则此时a的值为1。同样的道理,--表示”自减”。例2:a = 100;a--;则此时a的值为99。注意,程序语言里没有”自乘”和”自除”的概念。验证程序:#include int main(){int a = 0; // 给a赋值a++;printf("After ++, a = %d\n..._a++使用时值为多少
Elasticsearch动态模板_elasticsearch 动态模板-程序员宅基地
文章浏览阅读317次。模板规则{ "order": 0, // 模板优先级 "template": "sample_info*", // 模板匹配的名称方式 "settings": {...}, // 索引设置 "mappings": {...}, ..._elasticsearch 动态模板
Android原生态实现分享转发功能(分享图片到其他APP)_android 微信分享的图片到第三方怎么弄-程序员宅基地
文章浏览阅读8.5k次,点赞9次,收藏41次。导读:之前刚学安卓时,写过一篇“Android调用系统shareAPI实现分享转发功能”的文章,随着安卓版本的迭代更新以及其他APP的优化,安卓的这个shareAPI好像失效了,不怎么好使,已经获取不到有分享功能的APP列表,点击分享也会直接崩溃。并不是说我之前那篇文章的代码有错,只能说是时代有了变化,旧的方法已经不能满足新的需求,我并不打算删掉原来的那篇文章,旧文章地址如下(仅作参考):Android调用系统shareAPI实现分享转发功能_美奇软件开发工作室-程序员宅基地需求分析:在开发APP_android 微信分享的图片到第三方怎么弄
了解DSP的体系结构_怎么知道optisystem中dsp的组成-程序员宅基地
文章浏览阅读6.7k次,点赞3次,收藏22次。这篇其实基本上是引用 窦海霓, 朱铭锆发表在《今日电子》上的论文《DSP基本体系结构和特点》中的一些内容,主要是为了配合前一篇ARM体系结构而写,为了形成对比,加深印象。网络上很多引用这篇小论文的,但请尊重原著,注明出处。 一、DSP自身的一些优越性:DSP处理器的体系结构一直紧紧围绕着DSP算法和各种应用的不断发展而改进和优化,随着各种并行处理技术(VLIW,SIMD,超_怎么知道optisystem中dsp的组成
MPAndroidChart 饼图 数据过少时文字重叠_mpandroidchart 饼分图 重叠-程序员宅基地
文章浏览阅读1.2k次。MPAndroidChart 饼图 数据过少时文字重叠在使用MPAndroidChart这个控件来画饼图时,当有几个数据都是占比非常少的时候,伸出来的文字会重叠在一块。 这个坑花了比较多的时间填 。在网上找了一圈,都是复制的别人的文章。按照文章思路做了之后,还是会有重叠,而且有些时候线条很丑。这位大哥可能是原创的,有兴趣的可以点进去看下文章链接也有可能是我的使用姿势不对,始终没有达到我想要的效果。一番折腾后,决定自己动手改造。改造后的效果图基本思路是,找到绘制线条的类。PieChartR_mpandroidchart 饼分图 重叠
随便推点
Python去除文章首尾空格换行符_python 去掉首位的换行-程序员宅基地
文章浏览阅读6.3k次。想要批量清除文件首尾的空格,换行符等,使文件里的内容看着更规整一些,可以用python里的strip()函数。比如在这个文件里,前后都有一些空格换行符。从输出的提示内容可以看出,原来文件首尾的空白符已经被清除了,但是中间的换行符不受影响(我这里用的是VSCode,大家也可以用其他工具):再打开文件,前后的空白符都被清除了:python 代码如下:import os ..._python 去掉首位的换行
nginx: [error] invalid PID number ““ in “/app/nginx/logs/nginx.pid“_nginx: [error] invalid pid number "" in "/apps/ngi-程序员宅基地
文章浏览阅读1.3k次。需要将http://192.168.1.225:9080/building/通过代理http://192.168.1.225:8081/building/访问。[root@localhost conf]# vi nginx.conf#user nobody;worker_processes 1;#error_log logs/error.log;#error_log logs/error.log notice;#error_log logs/error.log info..._nginx: [error] invalid pid number "" in "/apps/nginx/logs/nginx.pid
一次尴尬的面试经历-程序员宅基地
文章浏览阅读71次。这段时间投了不少国外的博后岗位,好不容易收到了一个面试机会,我准备了一周多,竟然因为网络问题而被 pass 了,心里感到有点生气跟遗憾。这个海外博后,要求视频会议面试,用到一个 vidyodesktop 软件。面试前一周测试连接了一次,基本没卡顿,像打电话一样。然而,昨天正式面试时,不仅十分卡,而且一会我直接连不上了。但在面试前,或者面试后,我都能连上。总结,估..._海外博后面试软件
node.js 常用命令_node命令-程序员宅基地
文章浏览阅读1w次,点赞26次,收藏50次。废话不多说,直接开干 基础命令,npm 的一些重要命令,拿到就是赚到,有赞必回_node命令
QT——(无规则)多边形图形填充。_qt drawpath填充不同颜色-程序员宅基地
文章浏览阅读3.4k次。this可以指向类内部非静态成员。path.lineTo();用循环的话不填充。将path的轨迹写出来的话,就有填充。_qt drawpath填充不同颜色
HCLA从基础到成熟-程序员宅基地
文章浏览阅读1.6k次,点赞47次,收藏21次。9.9-DHCP静态路由的设置:1.如何开始dhcp服务:首先进入二级命令,dhcp enable 开启dhcp服务,然后创建池塘:IP pool xx为池塘取个名字 一台设备上可以有多个池塘,但一个池塘只能服务一个广播域,network ---IP----mask 24绑定接口(此处绑定的接口为所要分配的IP范围),gateway该网段的网关地址(此处填写的IP地址为接口所在的网关地址),dns-list --ip --子网掩码(144.144.144.144),服务器地址,最后进入接口dhcp se