Solr搜索引擎详细教程及Java API使用(SolrJ-8.11)_java连接solr8-程序员宅基地
技术标签: 中文分词 spring boot solr 全文检索 搜索引擎
一、Solr 安装
在 Unix 兼容或 Windows 服务器上安装 Solr 通常需要简单地提取(或解压)下载包。请务必在Solr 安装前准备好运行必备环境(如:JDK ),在准备安装必备环境时需要注意环境版本是否与你所安装的 Solr 兼容 Solr 系统要求(文档选用8.11版本)。
番外篇:很多人在安装 Solr 会纠结 Tomcat 和 Jetty 怎么选,都说 Solr 内置的 Jetty 不稳定有问题;我就想说就你们用到的那点功能 Jetty 要真有问题也响应不到你们,在说了要是 Jetty 真有问题 Solr 官方也不会选用,如果你领导还是说 Jetty 不行,你就把这个给你领导看Google 为 App Engine 选择了 Jetty;不过又说回来选择用什么就因人而异,用着顺手开心就行。
1、下载 Solr 安装包
Solr 可从 Solr 网站获得:最新版 Solr 下载。
也可以直接使用 Linux 命令下载: wget https://downloads.apache.org/lucene/solr/8.11.0/solr-8.11.0.tgz。
有三个独立的包:
-
solr-8.11.0.tgz适用于 Linux/Unix/OSX 系统 -
solr-8.11.0.zip适用于 Microsoft Windows 系统 -
solr-8.11.0-src.tgz包 Solr 源代码。如果您想在不使用官方 Git 存储库的情况下在 Solr 上进行开发,这将非常有用。
2、准备安装
将下载好的 Solr 压缩包解压就行。
tar -zxvf solr-8.11.0.tgz解压后目录布局
- bin
此目录中包含几个重要的脚本,这些脚本将使使用 Solr 更容易。
- solr 和 solr.cmd
这是 Solr 的控制脚本,也称为
bin/solr(对于 * nix)或者bin/solr.cmd(对于 Windows)。这个脚本是启动和停止 Solr 的首选工具。您也可以在运行 SolrCloud 模式时创建集合或内核、配置身份验证以及配置文件。 - post
Post Tool,它提供了用于发布内容到 Solr 的一个简单的命令行界面。
- solr.in.sh 和 solr.in.cmd
这些分别是为 * nix 和 Windows 系统提供的属性文件。在这里配置了 Java、Jetty 和 Solr 的系统级属性。许多这些设置可以在使用
bin/solr或者bin/solr.cmd时被覆盖,但这允许您在一个地方设置所有的属性。 - install_solr_services.sh
该脚本用于 * nix 系统以安装 Solr 作为服务。在 “将 Solr 用于生产 ” 一节中有更详细的描述。
- solr 和 solr.cmd
- contrib
Solr 的
contrib目录包含 Solr 专用功能的附加插件。 - dist
该
dist目录包含主要的 Solr .jar 文件。 - docs
该
docs目录包括一个链接到在线 Javadocs 的 Solr。 - example
该
example目录包括演示各种 Solr 功能的几种类型的示例。有关此目录中的内容的详细信息,请参阅下面的 Solr 示例。 - licenses
该
licenses目录包括 Solr 使用的第三方库的所有许可证。 - server
此目录是 Solr 应用程序的核心所在。此目录中的 README 提供了详细的概述,但以下是一些特点:
-
Solr 的 Admin UI(
server/solr-webapp) -
Jetty 库(
server/lib) -
日志文件(
server/logs)和日志配置(server/resources)。有关如何自定义 Solr 的默认日志记录的详细信息,请参阅配置日志记录一节。 -
示例配置(
server/solr/configsets)
-
2、启动 Solr
我们下载的 Solr 文件都会带有实例。可以直接运行启动,或者也可以自己重新创建核心。Solr 创建核心命令为 ./solr create -c active。启动命令为 ./solr start (默认端口为8983),端口也可以自定义 ./solr start -p 8888 这样端口就为8888了。运行顺序为启动 Sol r项目,然后再创建 Solr 核心。
#进入到 /solr-8.11.0/bin目录
启动命令:./solr start -force
启动命令:./solr start -e cloud -force #SolrCloud 模式下启动默认两个节点在同一台机器上启动
停止命令:./solr stop -all
重启命令:./solr restart -force
创建核心:./solr create -c <name> #name自定义
删除核心:./solr delete -c <name> #需要删除的核心名称如果启动成功后远程依然无法访问服务说明服务器防火墙没有关。
#关闭防火墙:
systemctl stop firewalld.service
#开启防火墙:
systemctl start firewalld.service
#关闭防火墙开机启动:
systemctl disable firewalld.service
#开启防火墙开机启动:
systemctl enable firewalld.service在使用命令创建核心的时候可能会出现以下错误
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin/solr config -c test_core -p 8983 -action set-user-property -property update.autoCreateFields -value false
WARNING: Creating cores as the root user can cause Solr to fail and is not advisable. Exiting.
If you started Solr as root (not advisable either), force core creation by adding argument -force这个时候只需要在创建命令后加-force强制创建接口。如:./solr create -c test_core -force
番外篇:除了使用 ./solr create -c <name> 命令创建核心以外还可以通过启动后的 Solr Admin UI 窗口创建和通过 API 的方式创建。Solr Admin UI - Core Admin 创建经常出错不推荐使用。
通过 API 创建核心:通过 API 创建核心必须在 SolrCloud 模式下启动 Solr 才行
http://localhost:8983/solr/admin/collections?action=CREATE&name=new_core&numShards=2&replicationFactor=2&maxShardsPerNode=2&collection.configName=harvewifiname:collection(索引)名称,也可以理解为核心名称
numShards:分片数
replicationFactor:每个分片的复本数
maxShardsPerNode:每个Solr服务器节点上最大分片数(Solr 4.2新增)
collection.configName:使用的配置文件名
4、Solr 配置安全验证
由于启动后默认是不用登入即可访问 Solr 管理界面,这样暴露了Solr核心库,易引起他人删除索引库数据,故配置登入权限才可访问 Solr 管理界面,步骤如下
1、新建配置文件security.json
创建该 security.json 文件并将其放在 $SOLR_HOME 您的安装目录中(这与您所在的位置相同solr.xml,通常为 server/solr )。以下配置用户名密码是:solr:SolrRocks
{
"authentication":{
"blockUnknown": true,
"class":"solr.BasicAuthPlugin",
"credentials":{
"solr":"IV0EHq1OnNrj6gvRCwvFwTrZ1+z1oBbnQdiVC3otuq0= Ndd7LKvVBAaZIF0QAVi1ekCfAJXr1GGfLtRUXhgrF8c="
},
"realm":"My Solr users",
"forwardCredentials": false
},
"authorization":{
"class":"solr.RuleBasedAuthorizationPlugin",
"permissions":[
{
"name":"security-edit",
"role":"admin"
}
],
"user-role":{
"solr":"admin"
}
}
}用户的增删改:
请求方式:post,Content-Type:application/json
请求路径:http://已有用户名:密码@127.0.0.1:8983/solr/admin/authentication
#新增或修改密码(如果用户名存在,就修改密码,否则就创建用户)
curl --user solr:SolrRocks http://localhost:8983/solr/admin/authentication -H 'Content-type:application/json' -d '{"set-user": {"tom":"TomIsCool", "harry":"HarrysSecret"}}'
#删除用户
curl --user solr:SolrRocks http://localhost:8983/solr/admin/authentication -H 'Content-type:application/json' -d '{"delete-user": ["tom", "harry"]}'
#设置属性
curl --user solr:SolrRocks http://localhost:8983/solr/admin/authentication -H 'Content-type:application/json' -d '{"set-property": {"blockUnknown":false}}'注意:用户名和密码尽量不要带特殊字符,否则使用地址栏传用户名密码的时候访问不了
配置说明:
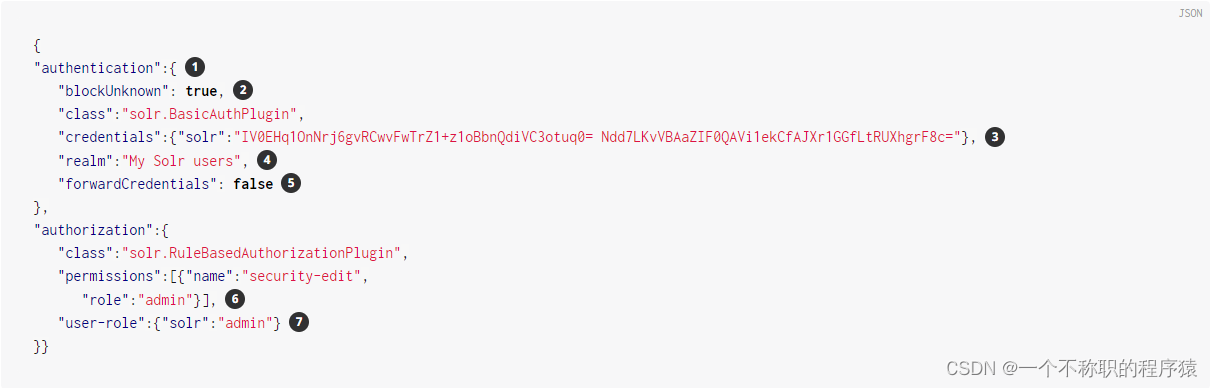
在这个文件中定义了几件事:
| 1 | 启用了基本身份验证和基于规则的授权插件。 |
| 2 | 该参数"blockUnknown":true表示不允许未经身份验证的请求通过。 |
| 3 | 'SolrRocks'已经定义了一个名为“solr”的用户,并带有密码。 |
| 4 | 我们覆盖该realm属性以在登录提示上显示另一个文本。 |
| 5 | 该参数"forwardCredentials":false表示我们让 Solr 的 PKI 身份验证处理分布式请求,而不是转发 Basic Auth 标头。 |
| 6 | 'admin' 角色已被定义,它有权编辑安全设置。 |
| 7 | 'solr' 用户已被定义为 'admin' 角色。 |
完成 Solr 安全验证配置后重新启动 Solr 就需要登录账号密码了。
5、AdminUI 简单使用
访问方式 http://ip:端口号/solr
查询页面参数说明
1、基本查询
| 参数 | 意义 |
|---|---|
| q | 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=:, |
| fl | 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort |
| start | 返回结果的第几条记录开始,一般分页用,默认0开始 |
| rows | 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页 |
| sort | 排序方式,例如id desc 表示按照 “id” 降序 |
| wt | (writer type)指定输出格式,有 xml, json, php等 |
| fq | (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。 |
| df | 默认的查询字段,一般默认指定。 |
| qt | (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。 |
| indent | 返回的结果是否缩进,默认关闭,用 indent=true |
| version | 查询语法的版本,建议不使用它,由服务器指定默认值。 |
2、Solr 的检索运算符
| 符号 | 意义 |
|---|---|
| “:” | 指定字段查指定值,如返回所有值: |
| “?” | 表示单个任意字符的通配 |
| “*” | 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号) |
| “~” | 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。 |
| AND || | 布尔操作符 |
| OR、&& | 布尔操作符 |
| NOT、!、- | (排除操作符不能单独与项使用构成查询) |
| “+” | 存在操作符,要求符号”+”后的项必须在文档相应的域中存在² |
| ( ) | 用于构成子查询 |
| [] | 包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510] |
| {} | 不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510} |
3、高亮
| 符号 | 意义 |
|---|---|
| h1 |
|
| hl.fl |
|
| hl.requireFieldMatch |
|
| hl.usePhraseHighlighter |
|
| hl.highlightMultiTerm |
|
| hl.fragsize | -返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。 |
4、分组(Field Facet)
facet 参数字段必须被索引,facet=on 或 facet=true
| 符号 | 意义 |
|---|---|
| facet.field | 分组的字段 |
| facet.prefix | 表示Facet字段前缀 |
| facet.limit | Facet字段返回条数 |
| facet.offict | 开始条数,偏移量,它与facet.limit配合使用可以达到分页的效果 |
| facet.mincount | Facet字段最小count,默认为0 |
| facet.missing | 如果为on或true,那么将统计那些Facet字段值为null的记录 |
| facet.sort | 表示 Facet 字段值以哪种顺序返回 .格式为 true(count)|false(index,lex),true(count) 表示按照 count 值从大到小排列,false(index,lex) 表示按照字段值的自然顺序 (字母 , 数字的顺序 ) 排列 . 默认情况下为 true(count) |
5、分组(Date Facet)
对日期类型的字段进行 Facet. Solr 为日期字段提供了更为方便的查询统计方式 .注意 , Date Facet的字段类型必须是 DateField( 或其子类型 ). 需要注意的是 , 使用 Date Facet 时 , 字段名 , 起始时间 , 结束时间 , 时间间隔这 4 个参数都必须提供 。
| 符号 | 意义 |
|---|---|
| facet.date | 该参数表示需要进行 Date Facet 的字段名 , 与 facet.field 一样 , 该参数可以被设置多次 , 表示对多个字段进行 Date Facet. |
| facet.date.start | 起始时间 , 时间的一般格式为 ” 2015-12-31T23:59:59Z”, 另外可以使用 ”NOW”,”YEAR”,”MONTH” 等等 , |
| facet.date.end | 结束时间 |
| facet.date.gap | 时间间隔,如果 start 为 2015-1-1,end 为 2016-1-1,gap 设置为 ”+1MONTH” 表示间隔1 个月 , 那么将会把这段时间划分为 12 个间隔段 . |
| facet.date.hardend | 表示 gap 迭代到 end 时,还剩余的一部分时间段,是否继续去下一个间隔. 取值可以为 true |
6、番外篇 Solr+Tomcat
1、如果你选用 Tomcat 就将解压后 \solr-8.11.0\server\solr-webapp 目录下的 webapp 整个文件夹复制到下载安装好的 Tomcat 中,并将 webapp 文件夹改名为 solr(想叫其它名也可以)。
2、在将解压后 \solr-8.11.0\server\lib\ext 全部 jar 包和 \server\lib 下 merteics 和 http2 为前缀的 jar 包全部 copy 到 Tomcat 的 webapp\solr\WEB-INF\lib 下。
3、创建新的 Solr 核心(也可以用自带的)拷贝解压后 \solr-8.11.0\server\solr 目录下的所有内容或只拷贝 \solr-8.11.0\server\solr\configsets\_default 下的 conf 文件夹到你的新位置,在将新位置文件夹重命名为 active(名字可以自定义),这样就完成了新核心创建。
4、配置 Tomcat 下 webapps\solr\WEB-INF 中的 web.xml
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solr/active</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>5、将 web.xml 中的权限验证 注释掉就行
<!-- Get rid of error message -->
<!-- <security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint> -->6、如果要增加账号密码验证就忽略第5步,首先在 tomcat/conf 下的 tomcat-users.xml 文件中增加以下代码
<role rolename="solr"/>
<user username="admin" password="new-password" roles="admin,manager"/>在 webapps/solr/WEB-INF/web.xml 文件权限验证配置后增加以下代码
<security-constraint>
<web-resource-collection>
<web-resource-name>Restrict access to Solr admin</web-resource-name>
<url-pattern>/admin/*</url-pattern>
<http-method>DELETE</http-method>
<http-method>GET</http-method>
<http-method>POST</http-method>
<http-method>PUT</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>manager</role-name>
</auth-constraint>
<user-data-constraint>
<transport-guarantee>NONE</transport-guarantee>
</user-data-constraint>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>default</realm-name>
</login-config>7、启动 Tomcat 访问http://localhost:8080/solr/index.html
二、Solr 基本配置
在 Solr 中有几个配置文件,您将在执行过程中与之交互。
这些文件中的很多都是 XML 格式的,尽管与配置设置交互的 API 在需要时往往接受 JSON 以进行编程访问。
-
solr.xml指定 Solr 服务器实例的配置选项。有关solr.xml请参阅Solr 核心和 solr.xml 的更多信息。 -
每个 Solr 核心:
-
core.properties定义每个核心的特定属性,例如其名称、核心所属的集合、模式的位置和其他参数。有关更多详细信息core.properties,请参阅定义 core.properties部分。 -
solrconfig.xml控制高层行为。例如,您可以为数据目录指定一个备用位置。有关更多信息solrconfig.xml,请参阅配置 solrconfig.xml。 -
managed-schema(或schema.xml改为)描述您将要求 Solr 索引的文档。Schema 将文档定义为字段的集合。您可以定义字段类型和字段本身。字段类型定义功能强大,包括有关 Solr 如何处理传入字段值和查询值的信息。有关 Solr 架构的更多信息,请参阅文档、字段和架构设计以及架构 API。 -
data/包含低级索引文件的目录。
-
1、 域中常用标签介绍
域(managed-schema)相当于数据库的表字段,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。
域的常用属性:
- name:指定域的名称
- type:指定域的类型
- indexed:是否索引
- stored:是否存储
- required:是否必须
- multiValued:是否多值
1、域(managed-schema)
Solr中默认定义唯一主键key为id域
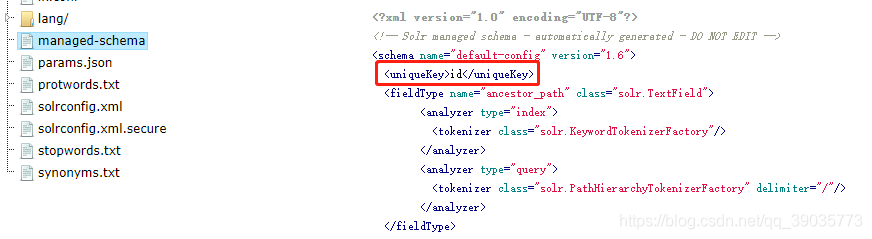
Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束
<field name="id" type="long" indexed="true" stored="true"/>
<field name="name" type="text_smartcn" indexed="true" stored="true"/>
<field name="content" type="text_ik" multiValued="true" indexed="true" stored="true"/>2、copyField (复制域)
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索。
比如,根据关键字只搜索 item_keywords 域的内容就相当于搜索 name、content,即将 name、content 复制到 item_keywords 域中。
目标域必须是多值的。
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="name" dest="item_keywords"/>
<copyField source="content" dest="item_keywords"/>3、dynamicField(动态字段)
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*_i,定义它的 type 为 text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
自定义 Field 名为:product_title_t,“product_title_t” 和 managed-schema 文件中的 dynamicField 规则匹配成功。
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />2、Solr 添加中文分词器
其实 Solr 已经自带了中文分词器 lucene-analyzers-smartcn 在解压后 \solr-8.11\solr-8.11.0\contrib\analysis-extras\lucene-libs 目录下 lucene-analyzers-smartcn.jar 这就是 Solr 自带的中文分词器,我们只需要将该文件拷贝到 Solr 服务 Jetty 或 Tomcat 的 webapp/WEB-INF/lib/ 目录下就可以了。
cp /solr-8.11.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-8.11.0.jar /solr-8.11.0/server/solr-webapp/webapp/WEB-INF/lib
在你指定 Solr 核心的 conf 目录下 managed-schema 文件中添加以下内容就ok了
<!-- 配置中文分词器 -->
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
如果你觉得 Solr 自带的中文分词器满足不了你预期的分词效果,那你也可以添加外部的分词器。
首先我们先去下载你要添加的外部分词器IK 分词器下载(ik-analyzer-solr)。
在将该文件拷贝到 Solr 服务 Jetty 或 Tomcat 的 webapp/WEB-INF/lib/ 目录下,最后配置在 managed-schema 文件中添加以下内容就ok了
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
最后在 managed-schema 文件中给要分词的字段指定分词器
<field name="name" type="text_smartcn" indexed="true" stored="true"/>
<field name="content" type="text_ik" multiValued="true" indexed="true" stored="true"/>注意:indexed="true",solr默认下content这个字段的indexed的值是false,需要改成true,在搜索时这个字段才能用到上面的分词器。
配置完重启 Solr 就 ok 了。
3、Solr 配置数据库
1、配置数据源
如果想要导入数据库,需要将相应的数据库驱动的 jar 包导入到 Solr 服务 Jetty 或 Tomcat 的 webapp/WEB-INF/lib/ 目录下。
然后在你自己的核心源文件夹打开 conf 文件夹,我们需要配置 solrconfig.xml,managed-schema 文件增加一个数据库配置文件。
2、配置 solrconfig.xml
数据库 Solr 的 jar 包引入,找到对应配置位置加入如下配置,在 solrconfig.xml 文件75行左右。
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-\d.*\.jar" />增加数据源配置 xml 文件,找到 name 为 /select 的 requestHandler 节点,在上面加入以下配置,其中 config 里面为数据源配置文件名字。
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>在 Solr 核心 conf 文件夹下新增配置数据源的 xml 文件(也就是 solrconfig.xml 文件中 name 为 /dataimport 的 requestHandler 节点中 config 指定的文件)。
- dataSource:中配置数据库数据
- type:为类型
- driver:为对应数据库的驱动类
- url:为数据库地址
- user:为数据库账户
- password:为数据库密码
- entity:为需要的查询数据源语句
其中 entity 节点下 field 为查出的数据需要向 Solr 中存储的字段已经对应存入到 Solr 中的字段名称。
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.1.11:3306/solr_xt?characterEncoding=utf-8&useUnicode=true&zeroDateTimeBehavior=convertToNull"
user="root"
password="root" />
<document>
<entity name="solrTest" query="SELECT name,content FROM solrTest">
<!-- 查询的数据和数据库索引意义对应 column 是查询的字段 name 是 Solr 索引对应的字段 -->
<field column="id" name="id"/>
<field column="name" name="id" />
<field column="content" name="title" />
</entity>
</document>
</dataConfig>最后记得修改 Solr 核心 core/conf 目录下 managed-schema 文件 <field/> 标签,新增需要索引的列。
完成所有配置后记得要重启 Solr 服务。
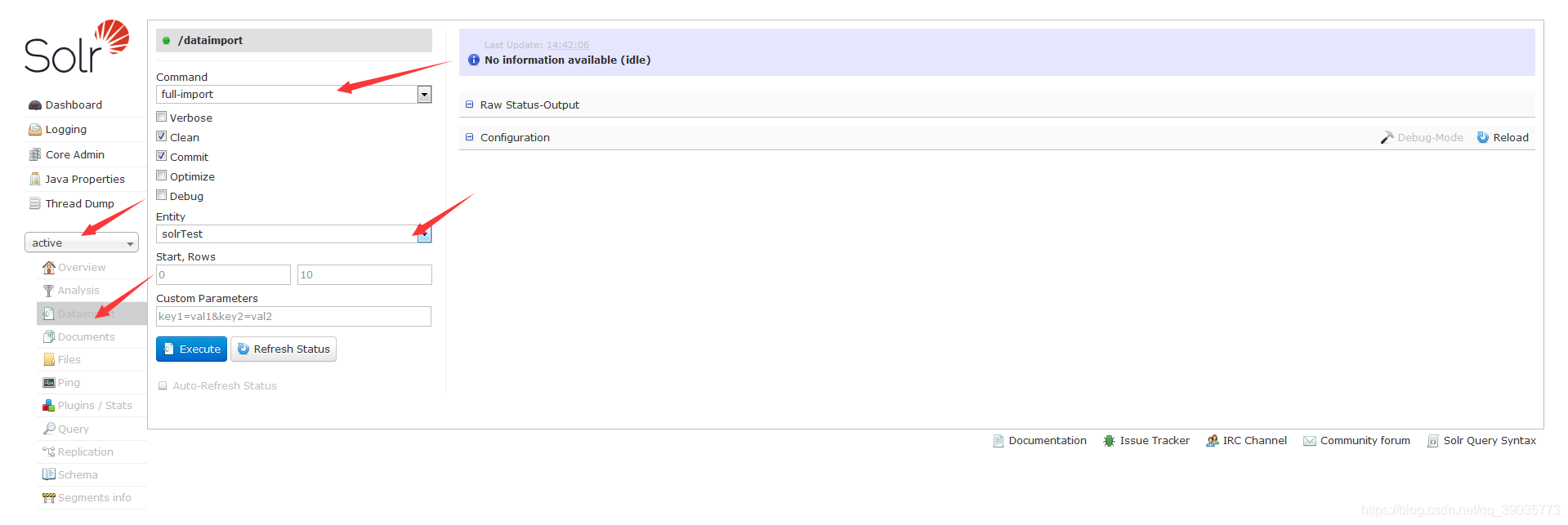
4、Solr 配置全量更新
完成以上第2步数据源配置后,直接在 Solr AdminUI 管理页面就行数据全量更新就行了。
5、Solr 配置增量更新
在做数据增量更新时,需要做增量更新的数据源表几个增量必要条件必须存在。
- 如果只涉及添加,与修改业务,那么数据库里只需额外有一个 timpstamp 字段就可以了,默认值为当前系统时间,CURRENT_TIMESTAMP。
- 如果还涉及删除业务,那么数据里就需额外再多添加一个字段 isdelete,int 类型的用0,1来标识,此条记录是否被删除。
增量更新就是在全量更新的基础上加上一些配置:
- query:查询数据库表符合记录数据。
- deltaQuery:增量索引查询主键ID,注意这个只能返回ID字段。
- deltaImportQuery:增量索引查询导入数据。
- deletedPkQuery:增量索引删除主键ID查询。
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<!--数据源-->
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.1.11:3306/solr_xt?characterEncoding=utf-8&useUnicode=true&zeroDateTimeBehavior=convertToNull"
user="root"
password="root"/>
<document>
<entity name="solrTest"
query="SELECT id,name,content FROM solrTest where flag = '0'"
deltaImportQuery = "SELECT id,name,content FROM solrTest where fid = '${dataimporter.delta.fid}'"
deltaQuery = "SELECT id FROM solrTest where flastupdatetime > '${dataimporter.last_index_time}' and flag = '0'"
deletedPkQuery = "SELECT id FROM solrTest where flag = '1'"
>
<!-- 查询的数据和数据库索引意义对应 column 是查询的字段 name 是 Solr 索引对应的字段 -->
<field column="id" name="id"/>
<field column="name" name="name"/>
<field column="content" name="content"/>
</entity>
</document>
</dataConfig>完成配置在 Solr AdminUI 管理页面就行数据增量更新就行了
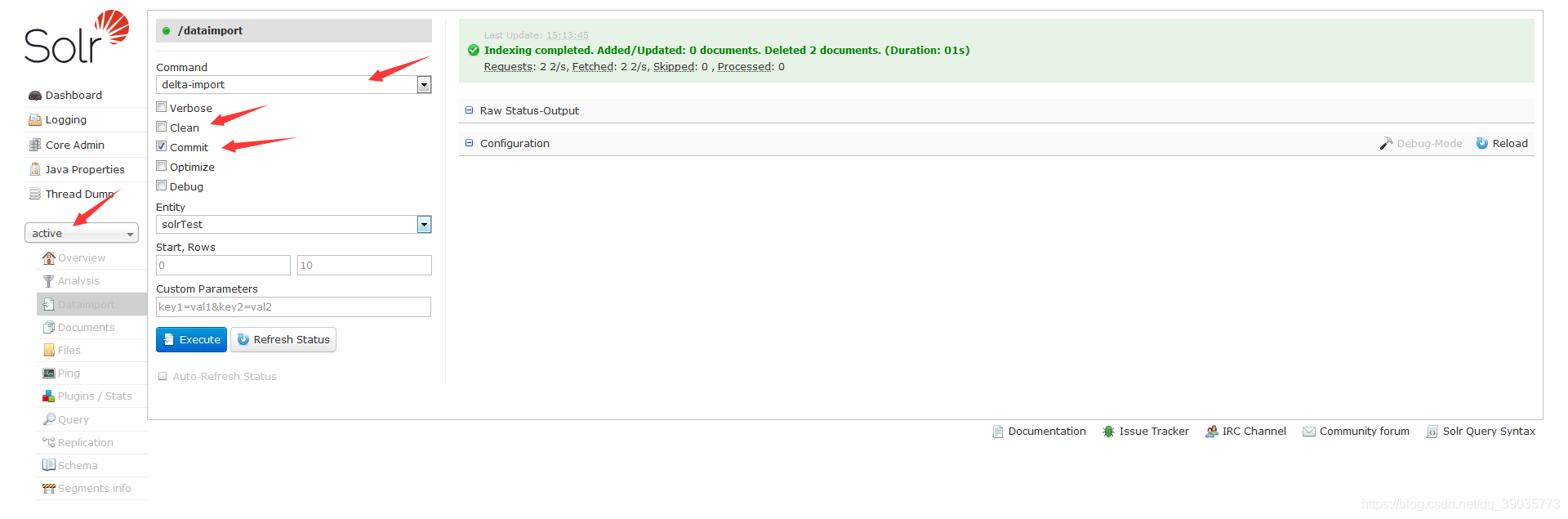
如果以上配置还不满足你的需求,那就请看使用数据导入处理程序上传结构化数据存储数据官方文档。
三、Java API SolrJ 的使用
1、SolrJ 简介
SolrJ 是操作 Solr 的 Java 客户端,它提供了增加、修改、删除、查询 Solr 索引的 Java 接口。通过 SolrJ 提供的 API 接口来操作 Solr 服务,SolrJ 底层是通过使用 httpClient 中的方法来完成 Solr的操作。
2、SolrJ 核心类 SolrClient
SolrClient 有一些具体的实现,每个实现都针对不同的使用模式或弹性模型:
-
HttpSolrClient- 面向以查询为中心的工作负载,但也是一个很好的通用客户端。直接与单个 Solr 节点通信。
-
Http2SolrClient- 利用 HTTP/2 的异步、非阻塞和通用客户端。这个类是实验性的,因此它的 API 可能会在 SolrJ 的次要版本中更改或删除。
-
LBHttpSolrClient- 在 Solr 节点列表之间平衡请求负载。根据节点健康状况调整“服务中”节点列表。
-
LBHttp2SolrClient- 就像
LBHttpSolrClient而是使用Http2SolrClient。这个类是实验性的,因此它的 API 可能会在 SolrJ 的次要版本中更改或删除。 -
CloudSolrClient- 面向与 SolrCloud 部署通信。使用已经记录的 ZooKeeper 状态来发现请求并将其路由到健康的 Solr 节点。
-
ConcurrentUpdateSolrClient- 面向以索引为中心的工作负载。在将更大的批次发送到 Solr 之前在内部缓冲文档。
-
ConcurrentUpdateHttp2SolrClient- 就像
ConcurrentUpdateSolrClient而是使用Http2SolrClient。这个类是实验性的,因此它的 API 可能会在 SolrJ 的次要版本中更改或删除。
SolrJ 所有 API 接口Solr 8.11.0 solr-solrj API。
3、SolrClient 类的简单使用(增删改查)
在使用前先引入 SolrJ 依赖
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>8.11.0</version>
</dependency>1、添加文档
@Test
public void testAdd() throws Exception{
//1.创建连接
HttpSolrClient solrServer = new HttpSolrClient.Builder("http://localhost:8983/solr/solrTest").build();
for (int i = 1; i <= 10; i++){
//2.创建一个文档对象
SolrInputDocument inputDocument = new SolrInputDocument();
//向文档中添加域以及对应的值(注意:所有的域必须在schema.xml中定义过,前两篇导入时已定义)
inputDocument.addField("id", i);
inputDocument.addField("name", "名称"+i);
inputDocument.addField("content", "内容"+i);
//3.将文档写入索引库中
solrServer.add(inputDocument);
}
//4.提交
solrServer.commit();
}
2、更新文档(其实更新的内容不存在则是新增)
@Test
public void testUpdate() throws Exception{
//1.创建连接
HttpSolrClient solrServer = new HttpSolrClient.Builder("http://localhost:8983/solr/solrTest").build();
//2.创建一个文档对象
SolrInputDocument inputDocument = new SolrInputDocument();
inputDocument.addField("id", "1");
//修改id为1的信息(信息存在则更新,不存在则新增)
inputDocument.addField("name", "名称1");
inputDocument.addField("content", "内容1");
//3.将文档写入索引库中
solrServer.add(inputDocument);
//4.提交
solrServer.commit();
}
3、查询单个
@Test
public void testQuery() throws Exception{
//1.创建连接
HttpSolrClient solrServer = new HttpSolrClient.Builder("http://localhost:8983/solr/solrTest").build();
//2.创建查询语句
SolrQuery query = new SolrQuery();
//3.设置查询条件
query.set("q", "id:1");
//4.执行查询
QueryResponse queryResponse = solrServer.query(query);
//5.取文档列表(public class SolrDocumentList extends ArrayList<SolrDocument>)
SolrDocumentList documentList = queryResponse.getResults();
for (SolrDocument solrDocument : documentList) {
System.out.println("id:"+solrDocument.get("id")+" ");
System.out.println("名称:"+solrDocument.get("name")+" ");
System.out.println("内容:"+solrDocument.get("content")+" ");
}
}
4、多条件查询带分页
@Test
public void testQueryByCon() throws Exception{
//创建连接
HttpSolrClient solrServer = new HttpSolrClient.Builder("http://localhost:8983/solr/solrTest").build();
//创建查询语句
SolrQuery query = new SolrQuery();
//设置查询条件
//设置查询关键字
query.set("q", "*称");
//按照id降序排列
query.setSort("id", SolrQuery.ORDER.desc);
//分页条件
query.setStart(0);
query.setRows(2);
//默认在名称域进行查询
query.set("df", "name");
//设置高亮
solrQuery.setHighlight(true);
//设置高亮的字段
solrQuery.addHighlightField("name,content");
//设置高亮的样式
solrQuery.setHighlightSimplePre("<font color='red'>");
solrQuery.setHighlightSimplePost("</font>");
//执行查询
QueryResponse queryResponse = solrServer.query(query);
//返回高亮显示结果
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
//获取文档列表
SolrDocumentList documentList = queryResponse.getResults();
System.out.println("总记录数:" + documentList.getNumFound());
for (SolrDocument solrDocument : documentList) {
System.out.println("id:"+solrDocument.get("id")+" ");
System.out.println("名称:"+solrDocument.get("name")+" ");
System.out.println("内容:"+solrDocument.get("content")+" ");
}
}
5、删除文档
/**
* 根据id删除文档
*/
@Test
public void testDeleteById() throws Exception{
//1.创建连接
HttpSolrClient solrServer = new HttpSolrClient.Builder("http://localhost:8983/solr/solrTest").build();
//2.删除文档
solrServer.deleteById("1");
//3.提交
solrServer.commit();
}
/**
* 根据条件删除文档
*/
@Test
public void testDeleteById() throws Exception{
//1.创建连接
HttpSolrClient solrServer = new HttpSolrClient.Builder("http://localhost:8983/solr/solrTest").build();
//2.删除文档
solrServer.deleteByQuery("name:名称");
//3.提交
solrServer.commit();
}4、SolrJ 整合 Spring Boot
1、引入 Maven 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>2、配置 yml 文件
持续更新中。。。。。。(有时间了就写一点)
智能推荐
BASE64、MD5、SHA、HMAC几种加密算法-程序员宅基地
文章浏览阅读106次。BASE64编码算法不算是真正的加密算法。 MD5、SHA、HMAC这三种加密算法,可谓是非可逆加密,就是不可解密的加密方法,我们称之为单向加密算法。我们通常只把他们作为加密的基础。单纯的以上三种的加密并不可靠。 BASE64 按照RFC2045的定义,Base64被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式。(The ..._base 64编码 和mad5 和雪花算法
住宅IP、家庭宽带IP以及原生IP,它们有什么区别?谷歌开发者账号应选择哪种IP?-程序员宅基地
文章浏览阅读1.1k次。IP地址(Internet Protocol Address)是互联网协议地址的简称,是互联网通信的基础,互联网上每一个网络设备的唯一标识符每个在线的设备都需要一个IP地址,这样才能在网络中找到它们并进行数据交换。IP地址有很多种类型,今天跟大家简单分享一下住宅IP、家庭宽带IP以及原生IP的区别。住宅IP通常是指由互联网服务提供商(ISP)分配给家庭的或小型办公室使用的互联网连接IP地址,并可能随着网络连接的变化而变化。此类IP地址主要用于日常网络活动,如浏览网页、发送接收电子邮件、上网冲浪等。
如何更改layui form表单位置,宽度,颜色等_layui-form-item 宽度-程序员宅基地
文章浏览阅读2.6w次,点赞14次,收藏30次。如何更改layui form表单位置,宽度,颜色等_layui-form-item 宽度
【翻译】Efficient Data Loader for Fast Sampling-Based GNN Training on Large Graphs_pagraph: scaling gnn training on large graphs via -程序员宅基地
文章浏览阅读612次。写的非常好_pagraph: scaling gnn training on large graphs via computation-aware caching
炫酷的HTML代码-程序员宅基地
文章浏览阅读2.7w次,点赞61次,收藏285次。很炫酷的html代码:<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml" lang="en"><head><title>star</title><script type="text/javascript">window.onload = function () {C = Math.cos; // cache Math objectsS = Math.si.._炫酷的html
【HDU - 1166】敌兵布阵 (线段树模板 单点更新+ 区间查询)-程序员宅基地
文章浏览阅读204次。题干:C国的死对头A国这段时间正在进行军事演习,所以C国间谍头子Derek和他手下Tidy又开始忙乎了。A国在海岸线沿直线布置了N个工兵营地,Derek和Tidy的任务就是要监视这些工兵营地的活动情况。由于采取了某种先进的监测手段,所以每个工兵营地的人数C国都掌握的一清二楚,每个工兵营地的人数都有可能发生变动,可能增加或减少若干人手,但这些都逃不过C国的监视。 中央情报局要研究敌人究竟演习什...
随便推点
【免费题库】华为OD机试C卷 - 数字字符串组合倒序(Java 代码+解析)-程序员宅基地
文章浏览阅读2.3k次。题目描述对数字,字符,数字串,字符串,以及数字与字符串组合进行倒序排列。字符范围:由 a 到 z, A 到 Z,数字范围:由 0 到 9符号的定义:“-”作为连接符使用时作为字符串的一部分,例如“20-years”作为一个整体字符串呈现;连续出现 2 个 “-” 及以上时视为字符串间隔符,如“out--standing”中的”–“视为间隔符,是 2 个独立整体字符串”out”和”standing”;除了 1,2 里面定义的字符以外其他的所有字符,都是非法字符,作为字符串的间隔符处理,倒序后
Android(14) ArrayAdapter(数组适配器)的三种方法-程序员宅基地
文章浏览阅读5w次,点赞36次,收藏138次。ArrayAdapter数组适配器用于绑定格式单一的数据,数据源可以是集合或者数组列表视图(ListView)以垂直的形式列出需要显示的列表项。实现过程:新建适配器->添加数据源到适配器->视图加载适配器第一种:直接用ListView组件创建列表每一行只有一行文字效果如图:activity_list布局:<?xml version="1.0" e..._arrayadapter
助力商家健康经营 创业者为水滴直播点赞-程序员宅基地
文章浏览阅读43次。近日,水滴直播平台登上了舆论的风口浪尖。有人认为水滴直播涉嫌侵犯隐私,但也有人表示这种互联网新生事物可以有效规避很多风险,值得鼓励,不应一棒子打死。记者采访时发现,很多商家、创业者对于水滴直播纷纷表示支持,并直言水滴直播为他们的经营带来了很大帮助。 邹志泉在北京丰台区经营着一家批发厂家直销男女内衣裤的店铺,平时就打开水滴直播,分享他在店铺的经营画面。面对水滴直播涉及隐私的提问,邹志泉明确表...
java毕业设计宠物收养管理系统Mybatis+系统+数据库+调试部署-程序员宅基地
文章浏览阅读67次。springboot基于SpringBoot的电影社区网站。springboot基于springboot食品销售网站。ssm基于微信平台的校园汉服租赁系统的设计与实现。ssm基于SSM高校教师个人主页网站的设计与实现。ssm基于SSM框架的在线健康系统设计与实现。ssm基于HTML的武昌理工学院二手交易网站。ssm基于JavaEE的网上图书分享系统。ssm基于Javaee的项目任务跟踪系统。
Nginx使用之反向代理、负载均衡、动静分离教程。_php动静分离-程序员宅基地
文章浏览阅读61次。负载均衡是指将客户端的请求分发到多个后端服务器,以平衡服务器的负载。反向代理是指将客户端的请求转发到后端服务器,并将响应返回给客户端。通过配置反向代理,Nginx将转发所有来自客户端的请求到后端服务器,并将响应返回给客户端。通过这样的配置,Nginx将根据请求的URL路径选择是将请求转发到后端服务器还是直接返回静态资源文件。通过配置负载均衡,Nginx将按照指定的策略将客户端的请求分发到后端服务器上,从而实现负载均衡。配置反向代理:编辑Nginx配置文件(通常是nginx.conf),在。_php动静分离
HTML5有哪些新特性_谈谈html5的一些新特性-程序员宅基地
文章浏览阅读9.5k次,点赞3次,收藏18次。(一) 语义标签(二)增强型表单(三)视频和音频(四)Canvas绘图(五)SVG绘图(六)地理定位(七)拖放API(八) WebWorker(九) WebStorage(十)Web..._谈谈html5的一些新特性