机器学习Sklearn学习总结_from sklearn.metrics-程序员宅基地
技术标签: 数据分析与数据挖掘 python 机器学习 编程语言 sklearn 人工智能 回归
Sklearn学习资料推荐:
Sklean介绍
sklearn是机器学习中一个常用的python第三方模块,里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务。
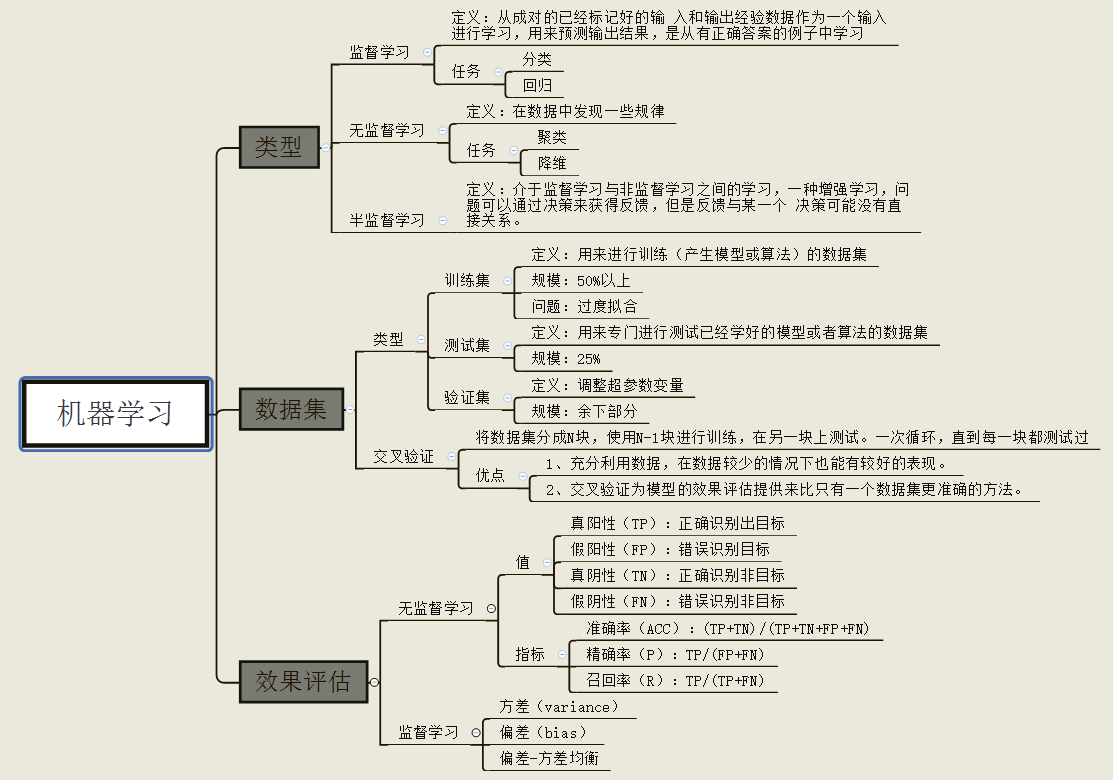
机器学习任务通常包括分类(Classification)和回归(Regression),常用的分类器包括SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN。常见的降维方法包括TF-IDF、主题模型LDA、主成分分析PCA等等。

Sklearn速查表

scikit-learn是数据挖掘与分析的简单而有效的工具。依赖于NumPy, SciPy和matplotlib。Scikit-learn 中,所有的估计器都带有 fit() 和 predict() 方法。fit() 用来分析模型参数(拟合),predict() 是通过 fit() 算出的模型参数构成的模型,对解释变量(特征)进行预测获得的值(预测)。
它主要包含以下几部分内容:
- 从功能来分:
- classification 分类
- Regression 回归
- Clustering 聚类
- Dimensionality reduction 降维
- Model selection 模型选择
- Preprocessing 预处理
- 从API模块来分:
sklearn.base: Base classes and utility functionsklearn.cluster: Clusteringsklearn.cluster.bicluster: Biclusteringsklearn.covariance: Covariance Estimatorssklearn.model_selection: Model Selectionsklearn.datasets: Datasetssklearn.decomposition: Matrix Decompositionsklearn.dummy: Dummy estimatorssklearn.ensemble: Ensemble Methodssklearn.exceptions: Exceptions and warningssklearn.feature_extraction: Feature Extractionsklearn.feature_selection: Feature Selectionsklearn.gaussian_process: Gaussian Processessklearn.isotonic: Isotonic regressionsklearn.kernel_approximation: Kernel Approximationsklearn.kernel_ridge: Kernel Ridge Regressionsklearn.discriminant_analysis: Discriminant Analysissklearn.linear_model: Generalized Linear Modelssklearn.manifold: Manifold Learningsklearn.metrics: Metricssklearn.mixture: Gaussian Mixture Modelssklearn.multiclass: Multiclass and multilabel classificationsklearn.multioutput: Multioutput regression and classificationsklearn.naive_bayes: Naive Bayessklearn.neighbors: Nearest Neighborssklearn.neural_network: Neural network modelssklearn.calibration: Probability Calibrationsklearn.cross_decomposition: Cross decompositionsklearn.pipeline: Pipelinesklearn.preprocessing: Preprocessing and Normalizationsklearn.random_projection: Random projectionsklearn.semi_supervised: Semi-Supervised Learningsklearn.svm: Support Vector Machinessklearn.tree: Decision Treesklearn.utils: Utilities
cluster聚类
阅读sklearn.cluster的API,可以发现里面主要有两个内容:一个是各种聚类方法的class如cluster.KMeans,一个是可以直接使用的聚类方法的函数如
sklearn.cluster.k_means(X, n_clusters, init='k-means++',
precompute_distances='auto', n_init=10, max_iter=300,
verbose=False, tol=0.0001, random_state=None,
copy_x=True, n_jobs=1, algorithm='auto', return_n_iter=False)所以实际使用中,对应也有两种方法。
在sklearn.cluster共有9种聚类方法,分别是
- AffinityPropagation: 吸引子传播
- AgglomerativeClustering: 层次聚类
- Birch
- DBSCAN
- FeatureAgglomeration: 特征聚集
- KMeans: K均值聚类
- MiniBatchKMeans
- MeanShift
- SpectralClustering: 谱聚类
拿我们最熟悉的Kmeans举例说明:
采用类构造器,来构造Kmeans聚类器,首先API中KMeans的构造函数为:
sklearn.cluster.KMeans(n_clusters=8,
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances='auto',
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm='auto'
)参数的意义:
n_clusters:簇的个数,即你想聚成几类init: 初始簇中心的获取方法n_init: 获取初始簇中心的更迭次数max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)tol: 容忍度,即kmeans运行准则收敛的条件precompute_distances:是否需要提前计算距离verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)random_state: 随机生成簇中心的状态条件。copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。n_jobs: 并行设置algorithm: kmeans的实现算法,有:'auto','full','elkan', 其中'full'表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。下面给一个简单的例子:
import numpy as np
from sklearn.cluster import KMeans
data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3
#假如我要构造一个聚类数为3的聚类器
estimator = KMeans(n_clusters=3)#构造聚类器
estimator.fit(data)#聚类
label_pred = estimator.label_ #获取聚类标签
centroids = estimator.cluster_centers_ #获取聚类中心
inertia = estimator.inertia_ # 获取聚类准则的最后值直接采用kmeans函数:
import numpy as np
from sklearn import cluster
data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3
k = 3 # 假如我要聚类为3个clusters
[centroid, label, inertia] = cluster.k_means(data, k)- 当然其他方法也是类似,具体使用要参考API。(学会阅读API,习惯去阅读API)
classification分类
分类是数据挖掘或者机器学习中最重要的一个部分。不过由于经典的分类方法机制比较特性化,所以好像sklearn并没有特别定制一个分类器这样的class。
常用的分类方法有:
- KNN最近邻:
sklearn.neighbors - logistic regression逻辑回归:
sklearn.linear_model.LogisticRegression - svm支持向量机:
sklearn.svm - Naive Bayes朴素贝叶斯:
sklearn.naive_bayes - Decision Tree决策树:
sklearn.tree - Neural network神经网络:
sklearn.neural_network
那么下面以KNN为例(主要是Nearest Neighbors Classification):
KNN
from sklearn import neighbors, datasets
# import some data to play with
iris = datasets.load_iris()
n_neighbors = 15
X = iris.data[:, :2] # we only take the first two features. We could
# avoid this ugly slicing by using a two-dim dataset
y = iris.target
weights = 'distance' # also set as 'uniform'
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
# if you have test data, just predict with the following functions
# for example, xx, yy is constructed test data
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # Z is the label_predsvm:
from sklearn import svm
X = [[0, 0], [1, 1]]
y = [0, 1]
#建立支持向量分类模型
clf = svm.SVC()
#拟合训练数据,得到训练模型参数
clf.fit(X, y)
#对测试点[2., 2.], [3., 3.]预测
res = clf.predict([[2., 2.],[3., 3.]])
#输出预测结果值
print res
#get support vectors
print "support vectors:", clf.support_vectors_
#get indices of support vectors
print "indices of support vectors:", clf.support_
#get number of support vectors for each class
print "number of support vectors for each class:", clf.n_support_ 当然SVM还有对应的回归模型SVR
from sklearn import svm
X = [[0, 0], [2, 2]]
y = [0.5, 2.5]
clf = svm.SVR()
clf.fit(X, y)
res = clf.predict([[1, 1]])
print res-
逻辑回归
from sklearn import linear_model
X = [[0, 0], [1, 1]]
y = [0, 1]
logreg = linear_model.LogisticRegression(C=1e5)
#we create an instance of Neighbours Classifier and fit the data.
logreg.fit(X, y)
res = logreg.predict([[2, 2]])
print respreprocessing
这一块通常我要用到的是Scale操作。而Scale类型也有很多,包括:
StandardScalerMaxAbsScalerMinMaxScalerRobustScalerNormalizer- 等其他预处理操作
对应的有直接的函数使用:scale(), maxabs_scale(), minmax_scale(), robust_scale(), normaizer()。
例如:
import numpy as np
from sklearn import preprocessing
X = np.random.rand(3,4)
#用scaler的方法
scaler = preprocessing.MinMaxScaler()
X_scaled = scaler.fit_transform(X)
#用scale函数的方法
X_scaled_convinent = preprocessing.minmax_scale(X)decomposition降维
说一下NMF与PCA吧,这两个比较常用。
import numpy as np
X = np.array([[1,1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]])
from sklearn.decomposition import NMF
model = NMF(n_components=2, init='random', random_state=0)
model.fit(X)
print model.components_
print model.reconstruction_err_
print model.n_iter_这里说一下这个类下面fit()与fit_transform()的区别,前者仅训练一个模型,没有返回nmf后的分支,而后者除了训练数据,并返回nmf后的分支。
PCA也是类似,只不过没有那些初始化参数,如下:
import numpy as np
X = np.array([[1,1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]])
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model.fit(X)
print model.components_
print model.n_components_
print model.explained_variance_
print model.explained_variance_ratio_
print model.mean_
print model.noise_variance_metrics评估
上述聚类分类任务,都需要最后的评估。
分类
比如分类,有下面常用评价指标与metrics:
accuracy_scoreaucf1_scorefbeta_scorehamming_losshinge_lossjaccard_similarity_scorelog_lossrecall_score- …
下面例子求的是分类结果的准确率:
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
ac = accuracy_score(y_true, y_pred)
print ac
ac2 = accuracy_score(y_true, y_pred, normalize=False)
print ac2其他指标的使用类似。
回归
回归的相关metrics包含且不限于以下:
mean_absolute_errormean_squared_errormedian_absolute_error- …
聚类
有以下常用评价指标(internal and external):
adjusted_mutual_info_scoreadjusted_rand_scorecompleteness_scorehomogeneity_scorenormalized_mutual_info_scoresilhouette_scorev_measure_score- …
下面例子求的是聚类结果的NMI(标准互信息),其他指标也类似。
from sklearn.metrics import normalized_mutual_info_score
y_pred = [0,0,1,1,2,2]
y_true = [1,1,2,2,3,3]
nmi = normalized_mutual_info_score(y_true, y_pred)
print nmi当然除此之外还有更多其他的metrics。参考API。
datasets 数据集
sklearn本身也提供了几个常见的数据集,如iris, diabetes, digits, covtype, kddcup99, boson, breast_cancer,都可以通过sklearn.datasets.load_iris类似的方法加载相应的数据集。它返回一个数据集。采用下列方式获取数据与标签。
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target 除了这些公用的数据集外,datasets模块还提供了很多数据操作的函数,如load_files, load_svmlight_file,以及很多data generators。
panda.io还提供了很多可load外部数据(如csv, excel, json, sql等格式)的方法。
还可以获取mldata这个repos上的数据集。
python的功能还是比较强大。
当然数据集的load也可以通过自己写readfile函数来读写文件。
其余Sklearn优秀博文推荐:
Python机器学习笔记:sklearn库的学习 - 战争热诚 - 博客园
Python机器学习库——Sklearn_韩明宇-程序员宅基地_python sklearn库
智能推荐
Linux驱动开发: USB驱动开发_linux usb 通信从设备开发-程序员宅基地
文章浏览阅读7k次,点赞86次,收藏192次。一、USB简介1.1 什么是USB? USB是连接计算机系统与外部设备的一种串口总线标准,也是一种输入输出接口的技术规范,被广泛地应用于个人电脑和移动设备等信息通讯产品,USB就是简写,中文叫通用串行总线。最早出现在1995年,伴随着奔腾机发展而来。自微软在Windows 98中加入对USB接口的支持后,USB接口才推广开来,USB设备也日渐增多,如数码相机、摄像头、扫描仪、游戏杆、打印机、键盘、鼠标等等,其中应用最广的就是摄像头和U盘了。 USB包括老旧的USB 1.1标准..._linux usb 通信从设备开发
注意: 如果你使用的是zsh,终端启动时 ~/.bash_profile 将不会被加载,解决办法就是修改 ~/.zshrc ,在其中添加:source ~/.bash_profile_如果你使用终端是zsh,终端启动时 ~/.bash_profile 将不会被加载,解决办法就是修改-程序员宅基地
文章浏览阅读2.6k次。Mac搭建Flutter环境_如果你使用终端是zsh,终端启动时 ~/.bash_profile 将不会被加载,解决办法就是修改
Qt知识点梳理 —— 代码实现菜单栏工具栏-程序员宅基地
文章浏览阅读379次,点赞5次,收藏9次。在清楚了各个大厂的面试重点之后,就能很好的提高你刷题以及面试准备的效率,接下来小编也为大家准备了最新的互联网大厂资料。《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》点击传送门即可获取!家准备了最新的互联网大厂资料。[外链图片转存中…(img-VMQDYeXz-1712056340129)][外链图片转存中…(img-JqBcGpUE-1712056340130)][外链图片转存中…(img-7Rrt8dF9-1712056340130)]
《设计模式入门》 9.代理模式_cglib需要引入第三方包-程序员宅基地
文章浏览阅读448次。代理模式可以说是我们在java学习中非常常见的一个设计模式了,在很多地方我们都可以看到代理模式的影子。比如:Spring 的 Proxy 模式(AOP编程 )AOP的底层机制就是动态代理 mybatis中执行sql时mybatis会为mapper接口通过jdk动态代理的方法生成接口的实现类 Feign对于加了@FeignClient 注解的类会在Feign启动时,为其创建一个本地JDK Proxy代理实例,并注册到Spring IOC容器可以看出,代理模式就是给..._cglib需要引入第三方包
前端开发:JS中向对象中添加对象的方法_一个对象如何添加另一个对象-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏6次。在前端开发过程中,一切皆对象,尤其是在数据处理的时候,大部分时候也是处理对象相关的数据,所以对象在JS中是很重要的一个内容,也是必用的内容。本篇博文来分享一下关于在JS中对象里面添加对象的操作,虽然知识点不难,但是常用,所以总结一下存起来,方便查阅使用。通过本文的介绍,关于在JS中对象里面添加对象的操作就得心应手了,虽然该知识点不难但是重要和常用,尤其是对于刚接触前端开发不久的开发者来说更是如此,所以绝对掌握该知识点还是很有必要的,重要性不再赘述。欢迎关注,共同进步。_一个对象如何添加另一个对象
迁移学习在自然语言生成中的研究-程序员宅基地
文章浏览阅读257次,点赞3次,收藏8次。1.背景介绍自然语言生成(Natural Language Generation, NLG)是一种将计算机理解的结构化信息转换为自然语言文本的技术。自然语言生成可以用于多种应用,如机器翻译、文本摘要、对话系统等。随着深度学习技术的发展,自然语言生成的表现力得到了显著提高。迁移学习(Transfer Learning)是一种机器学习技术,它可以将在一个任务上学到的知识应用于另一个相关任务。在...
随便推点
SpringBoot引入第三方jar包或本地jar包的处理方式_springboot idea 直接启动 target 第三方 jar 包-程序员宅基地
文章浏览阅读262次。在开发过程中有时会用到maven仓库里没有的jar包或者本地的jar包,这时没办法通过pom直接引入,那么该怎么解决呢一般有两种方法第一种是将本地jar包安装在本地maven库 第二种是将本地jar包放入项目目录中这篇文章主要讲第二种方式,这又分两种情况,一种是打包jar包,第二种是打包war包jar包 先看看jar包的结构 用压缩工具打开一个jar包 打包后jar包的路径在BOOT-INF\lib目录下 ..._springboot idea 直接启动 target 第三方 jar 包
软件压力测试图片60张,Win10 64位用鲁大师界面cpu温度60上下,显卡40多。用压力测试7-8分钟cpu75左右,...-程序员宅基地
文章浏览阅读1.4k次。CPU正常情况下45-65℃或更低,夏天或者玩游戏时,温度会高点,不超过80都属于正常温度。高于80℃时,需要采取措施:要检查CPU和风扇间的散热硅脂是否失效;更换CPU风扇;给风扇除尘;在通风或者空调间中使用机器。显卡温度:显卡一般是整个机箱里温度最高的硬件,常规下50-70℃(或更低),运行大型3D游戏或播放高清视频的时候,温度可达到100℃左右,一般高负载下不超过110℃均视为正常范畴。如有..._windows cpu gpu 压测
Mac系统制作U盘安装盘,不能识别U盘的情况_making disk bootable不动-程序员宅基地
文章浏览阅读2.3w次,点赞2次,收藏5次。遇到的问题:OS10.12系统,使用Mac系统自带的磁盘工具,通过恢复来制作的U盘安装盘,开机按住option键,没有U盘的这个选项。原因:使用磁盘工具恢复,没有创建启动文件,使用命令行能创建。U盘抹掉,分区名为1。sudo /Applications/Install\ OS\ X\ El\ Capitan.app/Contents/Resources/createinstal_making disk bootable不动
LOJ6089 小Y的背包计数问题 背包、根号分治-程序员宅基地
文章浏览阅读129次。题目传送门题意:给出$N$表示背包容量,且会给出$N$种物品,第$i$个物品大小为$i$,数量也为$i$,求装满这个背包的方案数,对$23333333$取模。$N \leq 10^5$$23333333=17 \times 1372549$竟然不是质数性质太不优秀了(雾直接跑背包$O(N^2)$,于是咱们考虑挖掘性质、分开计算发现当$i < \sqrt{N}$时就是一个多..._背包 根号
验证码-程序员宅基地
文章浏览阅读110次。用.net实现网站验证码功能 收藏 一、验证码简介验证码功能一般是用于防止批量注册的,不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。所谓验证码,就是将一串随机产生的数字或字母或符号或文字,生成一幅图片, 图片里加上一些干扰象素(防止OCR),由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。常见的验证码有如下几种: 1、纯..._验证码的样本标签,是5个字符,每个字符的可能 取值范围是'0'~'9'、'a'~'z'共36
ImportError: undefined symbol: cudaSetupArgument_undefinded symbol: cudasetupargument-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏3次。ImportError: undefined symbol: cudaSetupArgumentubuntu16.04How to solve?Step1.pip install -U torchvision==0.4.0链接: link.Step2.Problem:ImportError: cannot import name ‘PILLOW_VERSION’ from ‘PI..._undefinded symbol: cudasetupargument