Kubernetes Pod自动扩容和缩容 基于自定义指标_the kubernetes api could not find version "v2beta2-程序员宅基地
技术标签: kubernetes
[root@master ~]# kubectl get hpa -o yaml
apiVersion: v1
items:
- apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:这两个版本的区别是 autoscaling/v1支持了 :
- Resource Metrics(资源指标)
- Custom Metrics(自定义指标)
要使用自定义指标,也就是用户提供的指标,去参考着并且扩容,这个时候就需要用到其v2版本。
而在 autoscaling/v2beta2的版本中额外增加了External Metrics(扩展指标)的支持。
(基于Prometheus来获取资源指标,基于微软云服务获取指标等)
目前最成熟的就是Prometheus adapter,现在很多都是基于其实现hpa扩展。
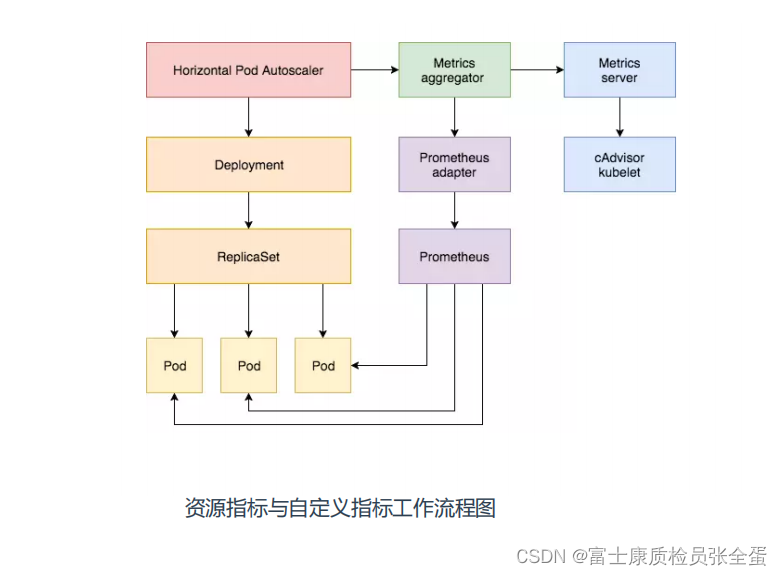
和之前的HPA扩容类似。
之前基于cpu实现HPA扩容:metrics server从kubelet cadvisor里面获取数据,获取完数据注册到api server的聚合层里面,hpa请求的是聚合层。(图最右边的步骤)
同理现在要基于自定义的指标,就图上面中间的步骤,基于自定义指标,那么指标就需要用户来提供,通过应用程序来提供,也就是要从pod当中获取应用程序暴露出来的指标,暴露出来的数据由Prometheus采集到,Prometheus adapater充当适配器,即中间转换器的作用,因为hpa是不能直接识别Prometheus当中的数据的,要想获取Prometheus当中的数据就需要一定的转换,这个转换就需要使用Prometheus adapter去做的。
prometheus adapter注册到聚合层,api server代理当中,所以当你访问custom.metrics.k8s.io API这个接口的时候会帮你转发到prometheus adapter当中,就类似于metric server,然后从Prometheus当中去查询数据,再去响应给hpa,hap拿到指标数据就开始对比的你阈值,是不是触发了,触发了就扩容。
示例
假设我们有一个网站,想基于每秒接收到的HTTP请求对其Pod进行自动缩放,实现HPA大概步骤:
制作好demo
先模拟自己开发一个网站,采用Python Flask Web框架,写两个页面:
- / 首页
- /metrics 指标
可以看到制作镜像和启动容器是没有问题的
[root@master metrics-app]# ls
Dockerfile main.py metrics-flask-app.yaml
[root@master metrics-app]# docker run -itd metrics-flask-app:latest
[root@master metrics-app]# docker logs 51d5afe9d7f8
* Serving Flask app 'main' (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on all addresses (0.0.0.0)
WARNING: This is a development server. Do not use it in a production deployment.
* Running on http://127.0.0.1:80
* Running on http://172.17.0.2:80 (Press CTRL+C to quit)访问该服务的接口,有两个,一个是正常提供的服务hello world,另外一个是暴露的指标接口,这个指标是由prometheus 客户端去组织的。
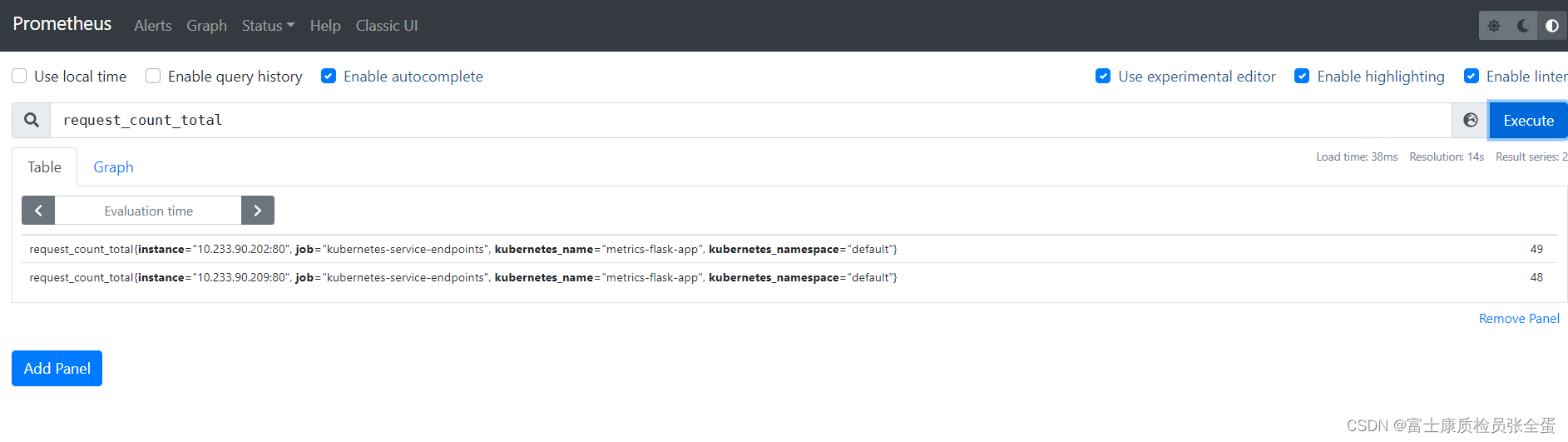
下面是基于request_count_total 2.0这个指标去扩容的。这个是记录访问这个接口的次数
[root@master metrics-app]# docker inspect 51d5afe9d7f8 | grep IPAddress
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.2",
"IPAddress": "172.17.0.2",
[root@master metrics-app]# curl 172.17.0.2
Hello World[root@master metrics-app]# curl 172.17.0.2/metrics
# HELP request_count_total 缁..HTTP璇锋?
# TYPE request_count_total counter
request_count_total 2.0
# HELP request_count_created 缁..HTTP璇锋?
# TYPE request_count_created gauge
request_count_created 1.6555203522592156e+09部署
[root@master metrics-app]# cat metrics-flask-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-flask-app
spec:
replicas: 3
selector:
matchLabels:
app: flask-app
template:
metadata:
labels:
app: flask-app
# 澹版.Prometheus?..
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics"
spec:
containers:
- image: lizhenliang/metrics-flask-app
name: web
---
apiVersion: v1
kind: Service
metadata:
name: metrics-flask-app
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: flask-app这里加了一个注解,这个注解就声明了让Prometheus去采集,这里采用了pod的服务发现
apiVersion: v1
kind: Service
metadata:
name: metrics-flask-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics" 在访问的时候pod是轮询的方式,代理到后面某些pod,所以每个pod当中的请求总数是不一样的。
Prometheus监控 对应用暴露指标
Endpoints: 10.233.90.202:80,10.233.90.209:80,10.233.96.110:80
可以看到指标都被统计到了,次数也在里面
Prometheus Adapter
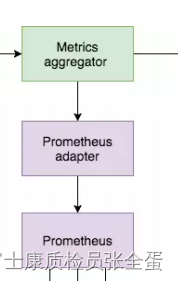
需要adapter从里面去查询指标,并且可以以metrics aggregator的方式去获取到指标。metrics aggregator充当着和metrics server的功能。
spec:
service:
name: prometheus-adapter
namespace: "kube-system"
group: custom.metrics.k8s.io可以看到使用的是这个接口custom.metrics.k8s.io
Adapter作用是用于k8s与Prometheus进行通讯,充当两者之间的翻译器。
不管是metrics server还是metrics aggreator都是一个注册在k8s当中的一个接口,接口代理到prometheus adapter,然后它向prometheus去查询数据。查询完数据返回给接口,最后给到hpa。
所以prometheus adapter是k8s和prometheus之间的桥梁,metrics aggreator接口是不支持直接从prometheus当中拿数据的。因为hpa metrics的数据接口它是不支持从prometheus当中获取数据。
[root@master prometheus_adapter]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
prometheus-adapter-7f94cc997d-xk9w8 1/1 Running 0 12m验证是否正常工作
(1)验证是否正常注册到api server
[root@master prometheus_adapter]# kubectl get apiservices |grep custom
v1beta1.custom.metrics.k8s.io kube-system/prometheus-adapter True 13mv1beta1.custom.metrics.k8s.io 这个是它的接口,访问不同的接口,会代理到后面不同的服务。
(2)调用其api,看看是否能够返回监控的数据
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1"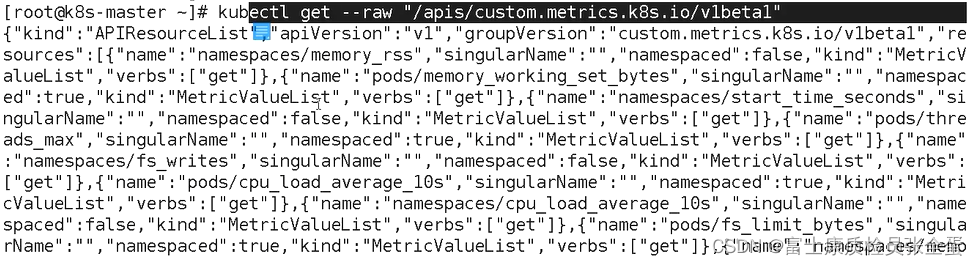
为指定HPA配置Prometheus Adapter
虽然充当了翻译器的角色,建立了k8s和Prometheus的一个桥梁,但是你得和他说明需要针对哪个应用去实现这么一个翻译,这个要明确告诉adapter的,而不是默认将Prometheus当中所有的数据都帮你去翻译。
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-adapter
labels:
app: prometheus-adapter
chart: prometheus-adapter-2.5.1
release: prometheus-adapter
heritage: Helm
namespace: kube-system
data:
config.yaml: |
rules:
- seriesQuery: 'request_count_total{app="flask-app"}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: "request_count_total"
as: "qps"
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'- seriesQuery:Prometheus查询语句,查询应用系列指标。(做hpa的指标,范围越小越好,精确到某个应用)
- resources:Kubernetes资源标签映射到Prometheus标签。(这块配置是将namespace pod以标签的形式发在seriesQuery要查询的指标里面,这样更加精确)
- name:将Prometheus指标名称在自定义指标API中重命名, matches正则匹配,as指定新名称。
- metricsQuery:一个Go模板,对调用自定义指标API转换为 Prometheus查询语句
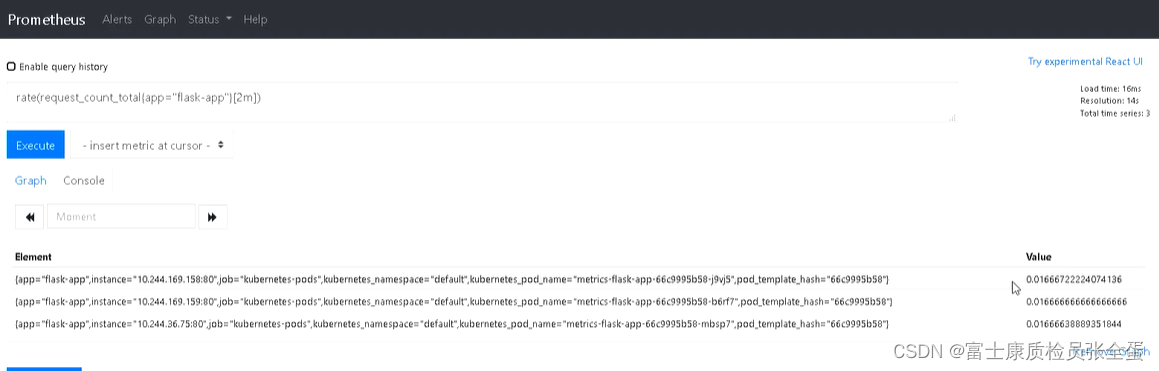
sum(rate(request_count_total{app="flask-app", kubernetes_namespace="default",
求出了速率再加上sum那么就是每秒所有的请求数,即qps。最后查询语句如下:
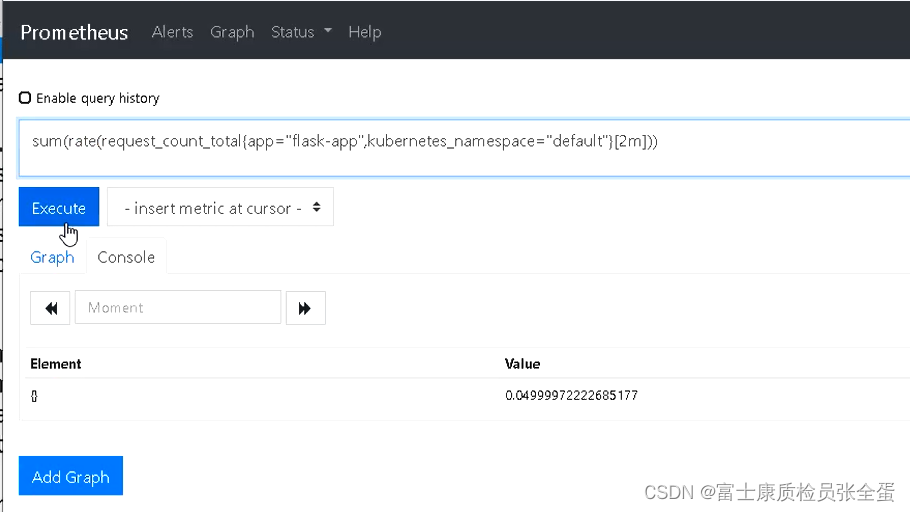 由于HTTP请求统计是累计的,对HPA自动缩放不是特别有用,因此将其转为速率指标。
由于HTTP请求统计是累计的,对HPA自动缩放不是特别有用,因此将其转为速率指标。

向自定义指标API访问:
创建HPA
这个使用的是v2版本
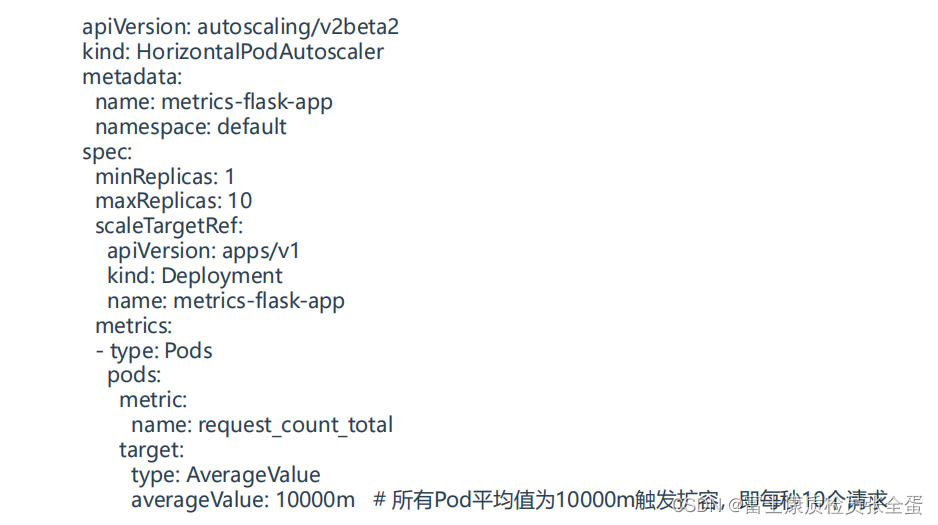
name这个地方改为qps
average value 指的是平均值,会采集所有pod的指标,拿到这个值求一个平均,然后再去对比这个阈值。
你可以定义任意的指标,只要能够被Prometheus采集到,同时指标的值是动态变化的根据实际负载,这个值可以反应负载的变化,最后决定需不需要扩容。或者500类的错误指标都行。
智能推荐
微信支付在项目targetSdkVersion>=30 报错解决办法。_android r(11) app targetsdkversion30遇到的那些坑之——相册选择图-程序员宅基地
文章浏览阅读1.2k次。在manifest的application节点外加入<queries> <package android:name="com.tencent.mm" /></queries>同理,支付宝也一样<queries> <package android:name="com.eg.android.AlipayGphone" /> <package android:name="hk.alipay.wallet.._android r(11) app targetsdkversion30遇到的那些坑之——相册选择图片黑屏现象
信息学奥赛C++编程:奥运奖牌计数-程序员宅基地
文章浏览阅读3.8k次。信息学奥赛C++编程:(循环结构)奥运奖牌计数_信息学奥赛c++编程
Springboot RabbitMq源码解析之RabbitListener的MessageListener#onMessage解析_rabbitmq onmessage-程序员宅基地
文章浏览阅读6.5k次。Springboot RabbitMq源码解析之配置类Springboot RabbitMq源码解析之消息发送Springboot RabbitMq源码解析之消费者容器SimpleMessageListenerContainerSpringboot RabbitMq源码解析之consumer管理和AmqpEventSpringboot RabbitMq源码解析之RabbitListener..._rabbitmq onmessage
pascal语言难还是python语言_lisp语言代替python_Lisp 语言优点那么多,为什么国内很少运用?...-程序员宅基地
文章浏览阅读140次。为什么Lisp没有流行起来本文探讨的是为什么Lisp语言不再被广泛使用的。很久以前,这种语言站在计算机科学研究的前沿,特别是人工智能的研究方面。现在,它很少被用到,这一切并不是因为古老,类似古老的语言却被广泛应用.其他类似的古老的语言有 FORTRAN, COBOL, LISP, BASIC, 和ALGOL 家族,这些语言的唯一不同之处在于,他们为谁设计,FORTRAN是为科学家和工程师设计的,他..._pascal 没有过时
进入 Tomcat 应用程序管理界面和部署Web应用_应用管理中心web页面-程序员宅基地
文章浏览阅读3.6k次,点赞2次,收藏9次。1 前言apache-tomcat-9.0.35我们都知道 Tomcat 可以部署 war包和静态资源,一般都是放在webapps下面;但是我们还应该知道,有个界面会帮我们去完成这个操作的,当然这个界面一般是不开放的,自己用的时候可以开放出来。开启 Tomcat服务(直接到tomcat服务器的bin目录下运行startup.sh脚本);浏览器访问 http://localhost:8080 ,如图:上述就是Tomcat的三个控制台界面的入口按钮,分别是Server Status控_应用管理中心web页面
hive详解(一)_desc extended table_name; 解析-程序员宅基地
文章浏览阅读1.3k次。1、Hive简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能。Hive是由Facebook开源用于解决海量结构化日志的数据统计的工具。 在Hadoop生态系统中,HDFS用于存储数据,Yarn用于资源管理,MapReduce用于数据处理,而Hive是构建在Hadoop之上的数据仓库,包括以下方面: (1)使用HQL作..._desc extended table_name; 解析
随便推点
【R语言】RStudio中如何撤销上一步操作_r语言撤回上一步-程序员宅基地
文章浏览阅读4.2w次,点赞13次,收藏12次。有时候一不小心,就把在编辑好的的代码在脚本窗口误删了 那这个时候应该怎么办呢? 一般运行过的程序都会在History中有保存 只需要在其中将想要恢复的代码选中,然后点上面绿色的箭头(To Source),这样代码就会重新回到脚本窗口里面 To Source 前面的按键是To Console,如果选中代码然后按这个的话,代码会立即运行!..._r语言撤回上一步
Unity下平面反射实现_unity 平面反射-程序员宅基地
文章浏览阅读6.2k次,点赞5次,收藏21次。平面反射通常指的是在镜子或者光滑地面的反射效果上,如下图所示,上图是一个光滑的平面,平面上的物体在平面上有对称的投影。一、平面反射的原理对于光照射到物体表面然后发生完美镜面反射的示意图,如下所示,对于平面反射,假设平面上任意一点都会发生完美的镜面反射。因此,眼睛看到物体的一点的反射信息是从反射向量处得到的,这个可以用下图来表示,这个实际上相当于,眼睛从平面的下面看向反射向量,如下图所示,因此,如上图所示,我们可以把摄像机根据平面对称变换到A点所示的位置,然后再渲染一遍场景到RenderT_unity 平面反射
shiro 实现多种方式登录_Shiro 使用多个 Realm 实现多种登录方式-程序员宅基地
文章浏览阅读1.6k次。前言大部分场景下,我们都会在项目中实现自定义 Realm 搭配 UsernamePasswordToken 来完成用户的登录认证流程,但是如果登录方式包括“第三方登录”、“手机号登录”等,仅凭 UsernamePasswordToken 就难以实现了,因为以上的两种登录方式都是免密登录,而 UsernamePasswordToken 却必须要有 username 和 password,因此需要自定..._shiro 多种登录验证
倒置函数reverse的用法_完成函数reverse-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏2次。倒置字符串函数reverse:用于倒置字符串s中的各个字符的位置,如原来字符串中如果初始值为123456,则通过reverse函数可将其倒置为654321,程序如下:#include#includevoid reverse(char s[]){ int c,j,i; for(i=0,j=strlen(s)-1;i { c=s[i]; s[i]=s[j];_完成函数reverse
Git详解之一 Git起步-程序员宅基地
文章浏览阅读3.9k次,点赞4次,收藏5次。起步本章介绍开始使用 Git 前的相关知识。我们会先了解一些版本控制工具的历史背景,然后试着让 Git 在你的系统上跑起来,直到最后配置好,可以正常开始开发工作。读完本章,你就会明白为什么 Git 会如此流行,为什么你应该立即开始使用它。 1.1 关于版本控制什么是版本控制?我真的需要吗?版本控制是一种记录若干文件内容变化,以便将来查阅特定版本修订情况的系统。在本书_git详解之一 git起步
IAR超过32KB之后代码编译出错问题解决办法之一_error[lp011]-程序员宅基地
文章浏览阅读1.1k次。信息栏显示 Error[Lp011]:解决办法:更改项目配置,General Options->Target中的Code改为Mediue或者LargeCode的small是64K byte寻址范围,medium是16M byte范围,但函数不允许跨越64K byte边界, large模式下是16M byte寻址范围,函数不存在跨界限制,随便放Date的small是256 byte寻址..._error[lp011]