Bootstrap重采样进行参数估计 - 置信区间_bootstrap重采样法-程序员宅基地
技术标签: 机器学习 # python 重采样 Bootstrap # 数据分析 置信区间
Bootstrap重采样进行参数估计 - 置信区间
文章目录
参考
主要是在看SCRFD论文时,看到作者在寻找网络结构各模块的计算开销比例时,分别使用Empirical Bootstrap求解computation ratio的置信区间,用于下一步的网络配置自动生成(很好奇作者在对320个模型进行采样时,为什么要使用重采样,整体采样研究数据分布,求解置信空间不行吗?不行,因为数据不一定满足正态分布的假设,利用查表方式求解置信区间不奏效,因此需要考虑使用中心极限定理)。因此这里抽空记录一下Bootstrap重采样是如何进行参数估计的。

一、Bootstrap简介
Bootstrap又称自展法、自举法、自助法、靴带法 , 是统计学习中一种重采样(Resampling)技术,用来估计标准误差、置信区间和偏差。
Bootstrap是现代统计学较为流行的一种统计方法,在小样本时效果很好。机器学习中的Bagging,AdaBoost等方法其实都蕴含了Boostrap的思想,在集成学习的范畴里 Bootstrap直接派生出了Bagging模型。
举个栗子 :我要统计鱼塘里面的鱼的条数,怎么统计呢?假设鱼塘总共有鱼1000条,我是开了上帝视角的,但是你是不知道里面有多少。
步骤:
- 承包鱼塘,不让别人捞鱼(规定总体分布不变)。
- 自己捞鱼,捞100条,都打上标签(构造样本)
- 把鱼放回鱼塘,休息一晚(使之混入整个鱼群,确保之后抽样随机)
- 开始捞鱼,每次捞100条,数一下,自己昨天标记的鱼有多少条,占比多少(一次重采样取分布)。
- 重复3,4步骤n次。建立分布。
假设一下,第一次重新捕鱼100条,发现里面有标记的鱼12条,记下为12%,放回去,再捕鱼100条,发现标记的为9条,记下9%,重复重复好多次之后,假设取置信区间95%,你会发现,每次捕鱼平均在10条左右有标记,所以,我们可以大致推测出鱼塘有1000条左右。
原理是中心极限定理:
- 中心极限定理(CLT):样本的平均值约等于总体的平均值。不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的整体平均值周围,并且呈正态分布。参考https://www.zhihu.com/question/22913867/answer/250046834
- 大数定律(LLN):如果统计数据足够大,那么事物出现的频率就能无限接近他的期望(均值)。参考https://www.zhihu.com/question/19911209/answer/245487255
理解一下定理和定律的区别:http://www.gaosan.com/gaokao/254891.html
这两者容易混,其实两者都是在讨论一个问题:当样本个数n趋向于无穷时,均值表现出什么样的行为。但在侧重点上存在不同:CLT告诉我们的是样本均值相对于总体均值的呈正态分布情况(mean,var),而LLN告诉我们的是,当样本个数足够大时样本的均值可以近似整体的均值。
定理,用推理的方法判断为真的命题叫做定理。定律,是由实践和事实所证明,反映事物在一定条件下发展变化的客观规律的论断。定律是由实验总结得来的规律,定理是由定律出发,通过数学证明得来的命题。
大数定律(1713)是在中心极限定理(1901)出现之前,中心极限定理是对大数定律的归纳,因此中心极限定理说:样本的平均值约等于总体的平均值也不过分。
二、为什么要使用Bootstrap
在量化投资领域,有大量需要进行参数估计(parameter estimation)的场景。 比如在按照马科维茨的均值方差框架配置资产时,就必须计算投资品的收益率均值和协方差矩阵。很多时候,对于需要的统计量,仅有点估计(point estimate)是不够的,我们更感兴趣的是从样本数据得到的点估计和该统计量在未知总体中的真实值之间的误差。在这方面,区间估计 —— 即计算出目标统计量的置信区间(confidence interval)—— 可以提供我们需要的信息。
谈到置信区间,人们最熟悉的当属计算总体均值(population mean)的置信区间。这是因为在中心极限定理(Central Limit Theorem) 和正态分布假设(Normal distribution) 下,总体均值的置信区间存在一个优雅的解析表达。利用样本均值和其 standard error 求出的 test statistic 满足 t 分布(Student’s t-distribution),通过查表找到置信区间两边各自对应的 t 统计量的临界值(critical value)便可以方便的求出置信区间。由于 t 分布是对称的,因此总体均值的置信区间是关于样本均值对称的。
让我们称上述计算置信区间的方法为传统的 Normal Theory 方法。我想花点时间来聊聊该方法背后的两个强大假设:中心极限定理和正态分布。
假设总体满足正态分布,而我们想计算均值的置信区间。如果总体的标准差 σ \sigma σ 已知,则可以使用正态分布计算均值的置信区间;如果 σ \sigma σ 未知,则使用样本的标准差 s s s 代替,并且利用 t 分布来代替正态分布计算均值的计算区间。这就是 t 分布被提出来的初衷。因此,使用 t 分布计算均值的置信区间隐含着总体分布满足正态分布这个假设。
但是,对于实际中的问题,总体并不满足正态分布,因此看起来我们不能使用 t 分布计算均值的置信区间。好消息是,我们还有另外一个“大招”:中心极限定理。中心极限定理告诉我们,不管总体的分布是什么样,总体的均值近似满足正态分布,因此我们仍然可以使用 t 分布计算置信区间。
中心极限定理是概率论中的一组定理。中心极限定理说明,大量相互独立的随机变量,其均值的分布以正态分布为极限。这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量之和近似服从正态分布的条件。
可见,对于一个未知分布总体均值的推断,我们必须倚赖中心极限定理和正态分布的假设。如果未知分布非常不规则或样本数不足,则中心极限定理指出的均值近似为正态分布便难以成立,而基于 t 分布计算出来的均值置信区间也不够准确。
除了均值外,对于人们关心的许多其他统计量,比如中位数、分位数、标准差、或者相关系数,它们与均值不同,无法从 Normal Theory 中可以得到优雅的解析表达式来计算其置信区间,因此上述传统方法无能为力。
从上面的分析可知,仅仅掌握传统的 Normal Theory 方法局限性很大,使得我们在求解置信区间的很多问题面前举步维艰。因此,今天就给大家介绍一个利器 —— Bootstrap 方法。它在计算统计量的置信区间时大有可为。
三、经验Bootstrap
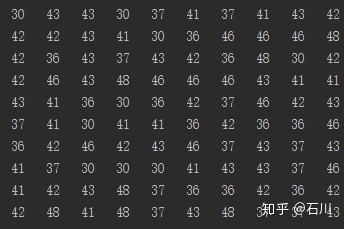
我们以计算某未知分布均值的置信区间为例说明经验 Bootstrap 方法。假设我们从某未知分布的总体中得到下面 10 个样本数据:30,37,36,43,42,48,43,46,41,42。
我们的问题有两个:(1)估计总体的均值(点估计),(2)计算置信水平为 80% 的 Bootstrap 置信区间。
第一个问题很容易回答,样本均值 40.8(经验均值) 就是总体均值 μ \mu μ 的点估计。对于第二个问题,由于样本点太少(仅有 10 个)且总体分布未知(无法做正态分布假设),因此我们摒弃传统的方法,而采用经验 Bootstrap 方法计算其置信区间。
计算 μ \mu μ 的置信区间的本质是回答这样一个问题:样本均值 x ‾ \overline{x} x 的分布是如何围绕总体均值 μ \mu μ 变化的。换句话说,我们想知道 $\delta = \overline{x} - \mu $ 的分布。 δ \delta δ 就是当我们使用 x ‾ \overline{x} x 来估计 μ \mu μ时的误差。(中心极限定理)
如果我们知道 δ \delta δ 的分布,则可以找到待求置信区间左右两端的临界值。在本例中,因为我们关心的是置信水平为 80% 的置信区间,因此 δ \delta δ 的临界值是 10% 和 90% 分位对应的 δ 0.9 \delta_{0.9} δ0.9 和 δ 0.1 \delta_{0.1} δ0.1 。由此计算出 μ \mu μ 置信区间为
[ x ‾ − δ 0.1 , x ‾ − δ 0.9 ] [\overline{x} - \delta_{0.1},\overline{x} - \delta_{0.9}] [x−δ0.1,x−δ0.9]
这是因为:

值得一提的是,上面的概率是条件概率,它表示假设总体均值为 μ \mu μ 的条件下,样本均值 x ‾ \overline{x} x 围绕总体均值 μ \mu μ 的变化在 δ 0.1 \delta_{0.1} δ0.1 和 δ 0.9 \delta_{0.9} δ0.9 之间的概率。
不幸的是,由于来自总体的样本只有一个(上面的 10 个数)且 μ \mu μ 的真实值未知,我们并不知道 δ \delta δ 的分布(因此也就不知道 δ 0.9 \delta_{0.9} δ0.9和 δ 0.1 \delta_{0.1} δ0.1)。但是我们仍然利器在手,那就是 Bootstrap 原则。它指出虽然我们不知道 x ‾ \overline{x} x 如何围绕 μ \mu μ 变化(即 δ \delta δ的分布),但是它可以由 x ‾ ⋆ \overline{x}^\star x⋆ 如何围绕 x ‾ \overline{x} x 变化(即 δ ⋆ \delta^{\star} δ⋆ 的分布)来近似,这里 δ ⋆ \delta^{\star} δ⋆ 是利用 Bootstrap 样本计算的均值与原始样本均值之间的差:

通过进行多次有置换的重采样,得到多个 Bootstrap 样本,每一个样本中都可以计算出一个均值。使用每一个 Bootstrap 样本均值减去原始样本均值(40.8)就得到 δ ⋆ \delta^{\star} δ⋆ 的一个取值。利用计算机,很容易产生足够多的 Bootstrap 样本,即足够多的 δ ⋆ \delta^{\star} δ⋆ 的取值。根据大数定理(law of large numbers), 当样本个数足够多时, δ ⋆ \delta^{\star} δ⋆ 的分布是 δ \delta δ 的分布好的近似。
有了 δ ⋆ \delta^{\star} δ⋆ 的分布,就可以找到 δ 0.9 ⋆ \delta^\star_{0.9} δ0.9⋆和 δ 0.1 ⋆ \delta^\star_{0.1} δ0.1⋆,并用它们作为 δ 0.9 \delta_{0.9} δ0.9和 δ 0.1 \delta_{0.1} δ0.1 的估计,从而计算出 μ \mu μ 的置信区间:

上述思路就是经验 Bootstrap 方法的强大所在。
回到上面这个例子中。利用计算机产生 200 个 Bootstrap 样本(下图显示了前 10 个 Bootstrap 样本,每列一个)。
由这 200 个 Bootstrap 样本计算出 200 个 δ ⋆ \delta^{\star} δ⋆ ,它们的取值范围在 -4.4 到 4.0 之间, δ ⋆ \delta^{\star} δ⋆ 的累积密度函数如下图所示。
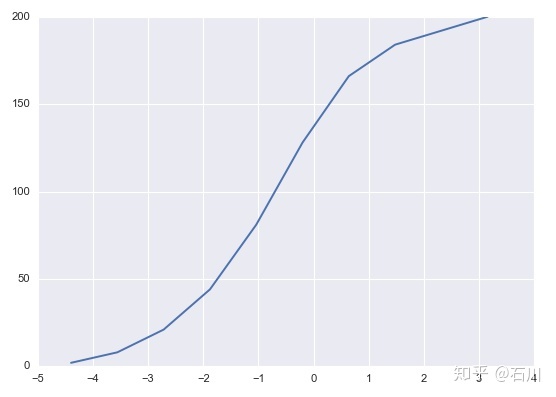
接下来,从这 200 个 δ ⋆ \delta^{\star} δ⋆ 中找出 δ 0.9 ⋆ \delta^{\star}_{0.9} δ0.9⋆ 和 δ 0.1 ⋆ \delta^{\star}_{0.1} δ0.1⋆ 。由于 δ 0.9 ⋆ \delta^{\star}_{0.9} δ0.9⋆ 对应的是 10% 分位数,而 δ 0.1 ⋆ \delta^{\star}_{0.1} δ0.1⋆对应的是 90% 分位数(方差小越集中),我们将 200 个 δ ⋆ \delta^{\star} δ⋆ 从小到大排序,其中第 20 个和第 181 个就是我们需要的数值: δ 0.9 ⋆ = − 1.9 \delta^{\star}_{0.9} = -1.9 δ0.9⋆=−1.9 以及 δ 0.1 ⋆ = 2.2 \delta^{\star}_{0.1} = 2.2 δ0.1⋆=2.2。由于原始样本均值为 40.8,因此求出 μ \mu μ 的 80% 的置信区间为:

四、Bootstrap百分位法
详细介绍参考 用 Bootstrap 进行参数估计大有可为
1)百分位数法简单易懂,无须复杂计算,只要有了Bootstrap 样本及每个样本的统计量,找到相应的百分位数即可。
2)它必须满足一个潜在的假定,即Bootstrap 抽样分布是样本统计量分布的一个无偏估计,当有偏的时候,估计结果可能也会有偏,因此会用百分位数t法。
3)t法对于95%置信区间,确定0.025和0.975的百分位数,则95%置信区间为:
经验 Bootstrap 法和 Bootstrap 百分位法的区别如下:
- 经验 Bootstrap 法用 δ ⋆ \delta^{\star} δ⋆ 的分布去近似 δ \delta δ 的分布;之后再把误差加到原始样本均值的两侧,该置信区间是以样本均值 x ‾ \overline{x} x 为中心的。
- Bootstrap 百分位法直接用 x ‾ ⋆ \overline{x}^\star x⋆ 的分布来近似 x ‾ \overline{x} x 的分布(由于我们只有一个来自于总体的样本,因此我们没有 x ‾ \overline{x} x 的分布,而这种方法说我们可以是使用 x ‾ ⋆ \overline{x}^\star x⋆ 的分布代替);它直接用从 x ‾ ⋆ \overline{x}^\star x⋆ 的分布找到的置信区间作为总体均值的置信区间。这里一个很强的假设是 x ‾ ⋆ \overline{x}^\star x⋆ 的分布是 x ‾ \overline{x} x 分布的一个很好的近似。然而在现实中这是无法保证的,因此这种方法不好,它的准确性存疑。
五、python代码
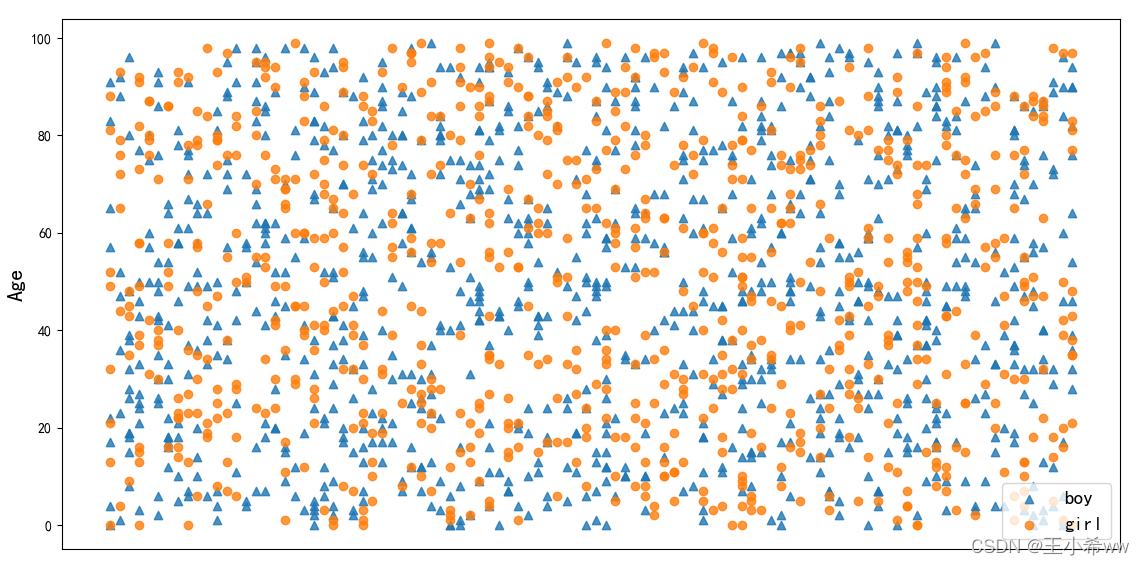
我们举个例子:假设我们的蓝色点代表男生;黄色点代表女生,我们想知道他们的比例是否大体相当。那么我们采用bootstrap的步骤则是:
- 每次采样10个人,看男女比例。
- 重复上述过程10000次,把每次的男女比例求平均,代表最终的男女比例。
这里设置男女比例为1 : 0.8
import numpy as np
from sklearn.utils import resample
import matplotlib.pyplot as plt
# 参考 https://blog.csdn.net/mingyuli/article/details/81223463
'''绘制男女年龄散点图'''
def boy_girl_plot(boys,girls):
'''
:param boys: [ndarray[x,y]]
:param girls: [ndarray[x,y]]
:return:
'''
boy_x,boy_y = [],[]
for boy in boys:
boy_x.append(boy[0])
boy_y.append(boy[1])
girl_x, girl_y = [], []
for girl in girls:
girl_x.append(girl[0])
girl_y.append(girl[1])
p1 = plt.scatter(boy_x,boy_y,marker='^',alpha=0.8)
p2 = plt.scatter(girl_x,girl_y,marker='o',alpha=0.8)
plt.xticks([])
plt.ylabel("Age",fontsize=16)
plt.legend([p1, p2], ['boy', 'girl'], loc='lower right', scatterpoints=1,fontsize=14)
plt.show()
'''Bootstrap点估计'''
def bootstrap(samples):
'''
:param samples: samples type = list[]
:return:
'''
count = 0.0
total = len(samples)
for sample in samples:
if (sample[2] == 0): #0为女生
count += 1.0
print(count)
return count / (total - count)
if __name__ == '__main__':
# 指定seed
m_seed = 20
# 设置seed
np.random.seed(m_seed)
boys = np.random.randint(100, size=(1000, 2)) #生成 0 ~ 100 的随机数,用于表示年龄,共1000个人
girls = np.random.randint(100, size=(800, 2)) #生成 0 ~ 100的随机数,用于表示年龄,共800人
#给出生的孩子打上男女生标签,男为1,女为0
boys_annotate = []
girls_annotate = []
for boy in boys:
temp = boy.tolist()
temp.append(1)
boys_annotate.append(temp)
for girl in girls:
temp = girl.tolist()
temp.append(0)
girls_annotate.append(temp)
#男女生年龄分布情况绘制
boy_girl_plot(boys_annotate,girls_annotate)
all = []
all.extend(boys_annotate)#合并boys,girls
all.extend(girls_annotate)#合并boys,girls
'''男女比例点估计(均值)'''
scale = 0.0
iter = 10000
mean_iter = []
for i in range(iter): #重复实验10000次
bootstrapSamples = resample(all, n_samples=100, replace=True) #每次有放回地抽取100个人
# print(bootstrapSamples)
tempscale = bootstrap(bootstrapSamples)
# print(tempscale)
mean_iter.append(tempscale)
scale += tempscale #女生/男生
#估计均值(Bootstrap点估计)
mean = scale / iter
print(f"female count / male count = {
mean}") # 对统计量求个平均值
---
female count / male count = 0.813314354093438
1)经验Bootstrap
'''
Bootstrap置信空间估计:经验Bootstrap法(Bootstrap回归)
通过进行多次有置换的重采样,得到多个 Bootstrap 样本,每一个样本中都可以计算出一个均值。
使用每一个 Bootstrap 样本均值减去原始样本均值(40.8,第一次Bootstrap计算的均值)就得到 \sigma* 的一个取值(\sigma* = x* - x_mean)。
利用计算机,很容易产生足够多的 Bootstrap 样本,即足够多的 \sigma* 的取值。
根据大数定理(law of large numbers),当样本个数足够多时, \sigma* 的分布是 \sigma 的分布好的近似。
'''
def empirical_bootstrap(mean,samples):
'''
:param mean: 第一次bootstrap的点估计(mean)
:param samples: 第二次bootstrap
:return: Bootstrap 样本计算的均值与原始样本均值之间的差
'''
ratio = bootstrap(samples)
sigma = ratio - mean
return sigma
if __name__ == '__main__':
...
'''80%置信空间估计'''
sigma_iter = []
for i in range(iter): #重复实验10000次
bootstrapSamples = resample(all, n_samples=100, replace=True) #每次有放回地抽取100个人
# print(bootstrapSamples)
sigma = empirical_bootstrap(mean, bootstrapSamples)
# print(tempscale)
sigma_iter.append(sigma)
#80%置信空间估计,则计算sigma_iter的(100 - 80) / 2 和 80 + (100 - 80) / 2分位数
confidence_range = 0.8
lower,upper = (100 - (0.8 * 100)) / 2, (0.8 * 100 + (100 - (0.8 * 100)) / 2)
sigma_lower = np.percentile(sigma_iter,upper) #sigma_0.1对应90%分位数(方差小越集中)
sigma_upper = np.percentile(sigma_iter,lower) #sigma_0.9对应10%分位数
print(f"{
confidence_range * 100}%的置信区间 = {
mean - sigma_lower} ~ {
mean - sigma_upper}")
---
80.0%的置信区间 = 0.5858123816562637 ~ 1.0137254823804245
2)Bootstrap百分位法
if __name__ == '__main__':
...
lower = np.percentile(mean_iter,10)
upper = np.percentile(mean_iter,90)
print(f"80%的置信区间 = {
lower} ~ {
upper}")
---
80%的置信区间 = 0.6129032258064516 ~ 1.0408163265306123
发现经验Bootstrap和Bootstrap百分位法计算的置信区间还是有一定区别的,但是个人建议使用经验Bootstrap。
智能推荐
Jetson TX2如何使用SDK Manager下载Jetpack 4.6.4_jetpack下载-程序员宅基地
文章浏览阅读969次,点赞25次,收藏19次。纳尼难道被制裁了,后来去某管看了看美国的一位老哥也爆这种错误,后来想了想也有可能是年龄写小了(当时随便写的),于是又用QQ邮箱重新注册了一个(某些博主用Gmail注册似乎解决了这个问题),摇身一变成为剑桥40岁老大爷注册成功。升级了一下VM版本(15Pro→16Pro),还是不行,顺便说一下如何判断板子如何进入recovery mode:是否重新上电无所谓,按住载板rec键(长按),再按一下rst键(短按),再松开rec就行了。之前安双系统的时候还跑过小海龟呢,不过那个是20.04的。_jetpack下载
Spring3.0 学习-AOP面向切面编程_Spring AOP的XML配置模式_spring3.0 切面aop annotation-程序员宅基地
文章浏览阅读6.8k次。1、通行理论在软件中,有些行为是通用的。比如日志、安全和事务管理,他们有一个共同的特点,分布于应用中的多处,这种功能被称为横切关注点(cross-cutting concerns)。DI(依赖注入)有助于应用对象之间的解耦,而AOP可以实现横切关注点与他们所影响的对象之间的解耦。应用切面的常见范例:日志、声明式事务、安全和缓存。下面涉及的内容包括Spring对切面的支持,包括如何把..._spring3.0 切面aop annotation
FL Studio中文版如何升级21.2最新版本_flstudio到哪里升级-程序员宅基地
文章浏览阅读375次,点赞10次,收藏9次。FL Studio带有强大的音符编辑器和音效编辑器,它具有出色的音效及强大的编曲能力,强大的混音效果,能兼容各种插件。FL Studio升级都是免费的,但是版本不一样,从基本升级到进阶,进阶升级到完整版,但高级版根本没必要升到完全版。FL Studio目前有4个版本,分别是基础版、进阶版、高端版、完整版。下表是它们部分功能的对比图,大家可根据自己的需要选择适合自己的版本。相对而言,进阶版的性价比更高一点,而且进阶版搭配全插件包使用,和完整版的功能并没有多少区别。进阶版与高级版的差别也是在插件上。_flstudio到哪里升级
2020牛客寒假算法基础集训营1 J题 u's的影响力【矩阵快速幂+欧拉降幂】(全网最详细题解,完整思路)_已知斐波那契数列 f n =f n 1 f n 2 (n>=3),f 1 =1,f 2 =1 求解该-程序员宅基地
文章浏览阅读1.5k次。题目传送门:https://ac.nowcoder.com/acm/contest/3002/J牛客“基础”算法训练营出的题很有意思啊,非常适合我这种萌新学习(真的十分“基础”,我差点就信了)。今天终于把这题给补了,这相当于是一个模板套模板的题,下面说说我的思路。完整思路:首先写出前几项的表达式,找一下规律。f(1)=xf(1)=xf(1)=xf(2)=yf(2)=yf(2)=yf..._已知斐波那契数列 f n =f n 1 f n 2 (n>=3),f 1 =1,f 2 =1 求解该数列的第n
sap清账使用反记账_解决SAP系统自动清帐的方法.pdf-程序员宅基地
文章浏览阅读1k次。解决SAP系统自动清帐的方法2012年第 1期 安 徽 冶 金 7解决 SAP系统 自动清帐的方法袁 丰(马鞍山钢铁股份有限公司)摘 要 在 SAP中通过二次开发实现财务模块往来项的 自动清账 ,减少对系统资源的大量 占用,解决 了在 马钢的实际业务无法使 用SAP标准功能 自动完成清账 ..._sap二次开发清账
mfc中 CWinApp::GetProfileInt 相关 配置文件的位置_cwinapp::getprofileinta-程序员宅基地
文章浏览阅读3.4k次。CWinApp下有一系列读取/写入配置文件的函数这个配置文件不是自己制定路径和文件名的随意的配置文件是在特定目录下的一个配置文件 ------------------------------------win7下这个路径是:(假设登录名为###, 应用程序_cwinapp::getprofileinta
随便推点
重置 Macbook 中MySQL 的 root 用户密码_mac mysql root用户密码-程序员宅基地
文章浏览阅读821次。Mac上好久前安装测试用的MySQL的Root密码忘记,猜了些常用密码都不对,只能重置密码。1、关闭MySQL服务,可以直接在系统偏好里关闭。3、再开一个终端(Command + N)2、进入安装目录,启动安全模式。4、进入MySQL修改密码。_mac mysql root用户密码
window下实现类似LINUX的程序全局别名| 避免每个应用都要配置全局环境变量_windows环境变量不支持快捷-程序员宅基地
文章浏览阅读770次。对于需要在命令行执行的程序,每次都需要设置环境变量很是麻烦,而且也会导致非必要的文件也在环境变量里并且如果多版本共存软件也会导致只能一个存在环境变量里不然会冲突,这时候如果可以通过快捷方式那不就完美解决了么?快捷方式的方法应该很多人想到了,但实操后却发现根本找不到快捷程序,调用不到。这是因为微软的快捷方式默认后缀是.ink,而支持可省略后缀里并没有".ink"的配置_windows环境变量不支持快捷
一个用于批量给图片增加水印的Python库_python 加水印开源库-程序员宅基地
文章浏览阅读386次,点赞4次,收藏9次。给图片、视频增加水印以确认版权或者增加效果,是在媒体内容信息经常需要用到的技术。本文推荐一个开源免费Python脚本,可以在指定目录及其子目录中批量给图像添加水印,当然,你也可以集成到你的Web应用中。本文推荐一个开源免费Python脚本,可以在指定目录及其子目录中批量给图像添加水印,当然,你也可以集成到你的Web应用中。源码地址:https://github.com/theitrain/watermark。除了以上位置,其他位置都将报错。_python 加水印开源库
自然语言处理(NLP)语义分析--文本分类、情感分析、意图识别_nlp语义识别-程序员宅基地
文章浏览阅读2.3w次,点赞12次,收藏109次。文章目录第一部分:文本分类 一、文本预处理(解决特征空间高维性、语义相关性和特征分布稀疏) 二、文本特征提取 三、分类模型 第二部分:情感分析 一、概述 二、基于情感词典的情感分类方法 三、基于机器学习的情感分类方法 第三部分:意图识别 一、概述 二、意图识别的基本方法 三、意图识别的难点 转载来源:https://blog.csdn.net/weixin_41657760/article/details/93163519第一部分:文._nlp语义识别
计算机网络基本概念<三>UDP和TCP协议详解_udp需要知道对方ip地址吗-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏19次。UDP和TCP都是传输层的重要协议,也是学习网络的必备内容了,接下来这篇我们就详细分析一下这两者的内容,以及这两者的区别_udp需要知道对方ip地址吗
南航计算机系复试内容,2010年南航计算机专业复试真题-程序员宅基地
文章浏览阅读342次。2010年南航计算机专业复试真题题型有1)填空 如 DDR SDRAM的中文名称是___; 主流压缩软件RAR采用何种校验码;处理器为core2 DUO,采用windows Vista 32位系统,则最大访问内存___GB;汉子显示技术的两种方法;还有一些别的题比较基本,应该都会2)判断题,注意要写出错的话是哪里错,如USB与IEEE1394都是串行的通用总线;微机原理的,南桥北桥基本概念等;3)..._s->btc|a t->r