删除异常值方法总结_python删除异常值-程序员宅基地
技术标签: python 机器学习 # python # 机器学习 # 统计学
推荐资料:14种异常检测方法总结
前提:
import pandas as pd
import numpy as np
import os
import seaborn as sns
from pyod.models.mad import MAD
from pyod.models.knn import KNN
from pyod.models.lof import LOF
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
1.IQR
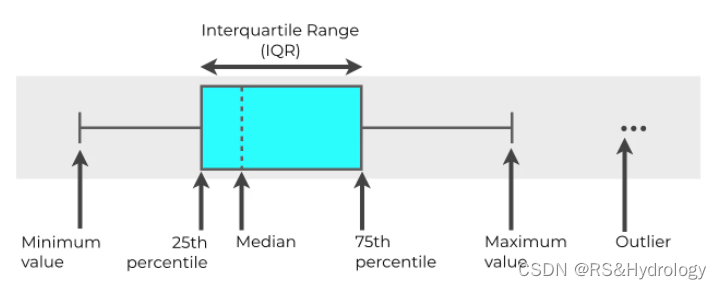
python基于IQR删除异常值:
df = pd.read_excel('./7.xlsx')
def fit_model(model, data, column='Area'):
# fit the model and predict it
df = data.copy()
data_to_predict = data[column].to_numpy().reshape(-1, 1)
predictions = model.fit_predict(data_to_predict)
df['Predictions'] = predictions
return df
def plot_anomalies(df, x='Date', y='Area'):
# categories will be having values from 0 to n
# for each values in 0 to n it is mapped in colormap
categories = df['Predictions'].to_numpy()
colormap = np.array(['g', 'r'])
f = plt.figure(figsize=(12/2.54, 6/2.54))
f = plt.scatter(df[x], df[y], c=colormap[categories])
f = plt.xlabel(x)
f = plt.ylabel(y)
f = plt.xticks(rotation=0)
plt.show()
#IQR
def find_anomalies(value, lower_threshold, upper_threshold):
if value < lower_threshold or value > upper_threshold:
return 1
else: return 0
def area_anomaly_detector(data, column='Area', threshold=1.1):
df = data.copy()
quartiles = dict(data[column].quantile([.25, .50, .75]))
quartile_3, quartile_1 = quartiles[0.75], quartiles[0.25]
area = quartile_3 - quartile_1
lower_threshold = quartile_1 - (threshold * area)
upper_threshold = quartile_3 + (threshold * area)
print(f"Lower threshold: {lower_threshold}, \nUpper threshold: {upper_threshold}\n")
df['Predictions'] = data[column].apply(find_anomalies, args=(lower_threshold, upper_threshold))
return df
area_df = area_anomaly_detector(df)
plot_anomalies(area_df)
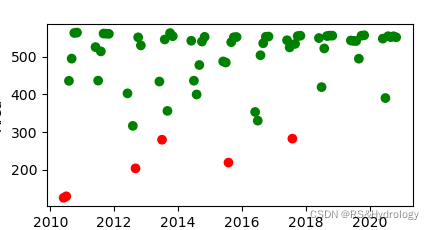
(红色为异常值)
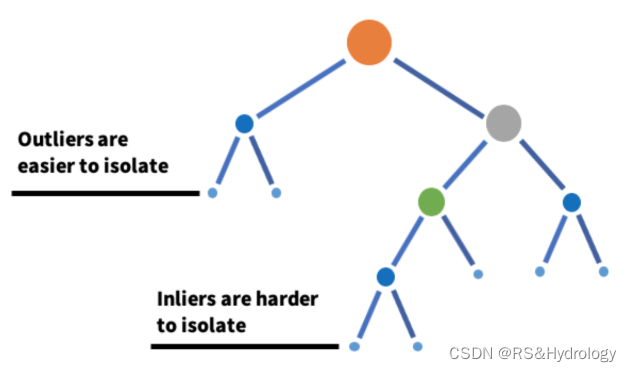
2.Isolation Forest(隔离森林算法)
- 孤立森林是基于决策树的算法。从给定的特征集合中随机选择特征,然后在特征的最大值和最小值间随机选择一个分割值,来隔离离群值。这种特征的随机划分会使异常数据点在树中生成的路径更短,从而将它们和其他数据分开。
- 在高维数据集中执行离群值检测的一种有效方法是使用随机森林。
- 属于无监督学习算法。
模型参数: - 评估器数量:n_estimators 表示集成的基评估器或树的数量,即孤立森林中树的数量。这是一个可调的整数参数,默认值是 100;
- 最大样本:max_samples 是训练每个基评估器的样本的数量。如果 max_samples
比样本量更大,那么会用所用样本训练所有树。max_samples 的默认值是『auto』。如果值为『auto』的话,那么
max_samples=min(256, n_samples); - 数据污染问题:算法对这个参数非常敏感,它指的是数据集中离群值的期望比例,根据样本得分拟合定义阈值时使用。默认值是『auto』。如果取『auto』值,则根据孤立森林的原始论文定义阈值;
- 最大特征:所有基评估器都不是用数据集中所有特征训练的。这是从所有特征中提出的、用于训练每个基评估器或树的特征数量。该参数的默认值是 1。
model=IsolationForest(n_estimators=50, max_samples='auto', contamination=float(0.1),max_features=1.0)
model.fit(df[['area']])
算法实现:
直接调用包: from sklearn.ensemble import IsolationForest
iso_forest = IsolationForest(n_estimators=125)
iso_df = fit_model(iso_forest, df)
iso_df['Predictions'] = iso_df['Predictions'].map(lambda x: 1 if x==-1 else 0)
plot_anomalies(iso_df)

3.MAD(Median Absolute Deviation)
中位数绝对偏差是每个观测值与这些观测值中位数之间的差值。
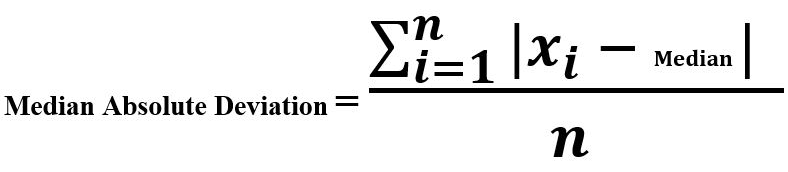
算法实现:调用from pyod.models.mad import MAD
#MAD
#threshold : float, optional (default=3.5)
# The modified z-score to use as a threshold. Observations with
# a modified z-score (based on the median absolute deviation) greater
# than this value will be classified as outliers.
mad_model = MAD()
mad_df = fit_model(mad_model, df)
plot_anomalies(mad_df)
Z-score分布图
What is a Modified Z-Score? (Definition & Example):https://www.statology.org/modified-z-score/
(1) 在统计学中,z分数表示一个值离均值有多少个标准差。公式为:
Z-Score = (xi – μ) / σ
- xi: A single data value;
- μ: The mean of the dataset;
- σ: The standard deviation of the dataset.
(2) z分数通常用于检测数据集中的异常值。例如,z分数小于-3或大于3的观察结果通常被认为是离群值。然而,z分数可能会受到异常大或小的数据值的影响,所以需要修正的Z值:
Modified z-score = 0.6745(xi – x̃) / MAD
- x̃: The median of the dataset;
- MAD: The median absolute deviation of the dataset;
Iglewicz和Hoaglin建议,修改后的z值小于-3.5或大于3.5的值被标记为潜在的离群值。
修改后的z-score更稳健,因为它使用中值来计算z-score,而不是已知的受异常值影响的平均值。
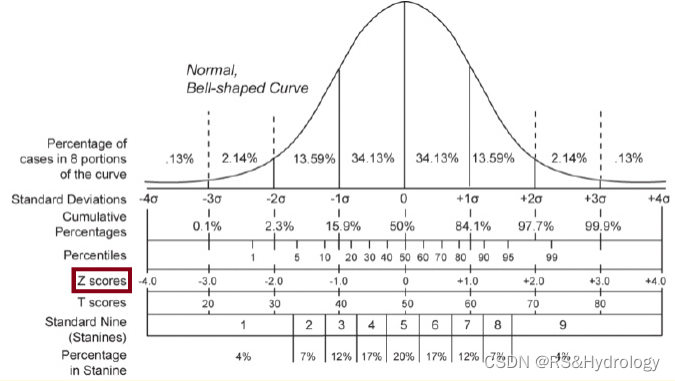
(转载自wikipedia)
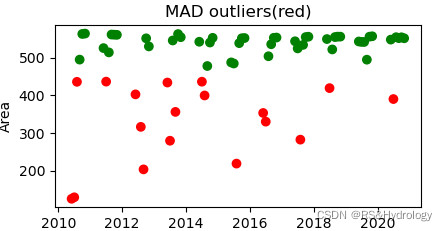
更新:整体代码
#test
df = pd.read_excel(r'./1.xlsx')
filter_data = df[(df['1']==0)]
# print(filter_data)
#filter data by MAD
#threshold : float, optional (default=3.5)
# The modified z-score to use as a threshold. Observations with
# a modified z-score (based on the median absolute deviation) greater
# than this value will be classified as outliers.
def fit_model(model, data, column='Area'):
# fit the model and predict it
df = data.copy()
data_to_predict = data[column].to_numpy().reshape(-1, 1)
predictions = model.fit_predict(data_to_predict)
df['Predictions1'] = predictions
return df
def plot_anomalies(df, x='Date', y='Area'):
# categories will be having values from 0 to n
# for each values in 0 to n it is mapped in colormap
categories = df['Predictions1'].to_numpy()
colormap = np.array(['g', 'r'])
f = plt.figure(figsize=(12/2.54, 6/2.54))
f = plt.scatter(df[x], df[y], c=colormap[categories])
f = plt.xlabel(x)
f = plt.ylabel(y)
f = plt.xticks(rotation=0)
plt.show()
mad_model = MAD()
mad_df = fit_model(mad_model, df)
plot_anomalies(mad_df)
MAD算法:
def _mad(self, X):
"""
Apply the robust median absolute deviation (MAD)
to measure the distances of data points from the median.
Returns
-------
numpy array containing modified Z-scores of the observations.
The greater the score, the greater the outlierness.
"""
obs = np.reshape(X, (-1, 1))
# `self.median` will be None only before `fit()` is called
self.median = np.nanmedian(obs) if self.median is None else self.median
diff = np.abs(obs - self.median)
self.median_diff = np.median(diff) if self.median_diff is None else self.median_diff
return np.nan_to_num(np.ravel(0.6745 * diff / self.median_diff))
R语言中实现MAD算法:
mad(x, center = median(x), constant = 1.4826, na.rm = FALSE,
low = FALSE, high = FALSE)
参数说明:https://www.math.ucla.edu/~anderson/rw1001/library/base/html/mad.html

总结:
PyOD是一个全面的、可扩展的Python工具包,可以用来检测异常值。可以直接调用里面的模型。
PyOD网址:https://github.com/yzhao062/pyod
使用方法:如调用MAD模型
# train the MAD detector
from pyod.models.mad import MAD
clf = MAD()
clf.fit(X_train)
# get outlier scores
y_train_scores = clf.decision_scores_ # raw outlier scores on the train data
y_test_scores = clf.decision_function(X_test) # predict raw outlier scores on test
参考资料:
A walkthrough of Univariate Anomaly Detection in Python(很好学习资料):https://www.analyticsvidhya.com/blog/2021/06/univariate-anomaly-detection-a-walkthrough-in-python/
隔离森林算法:https://blog.csdn.net/ChenVast/article/details/82863750
异常值检测总结pyod包:https://blog.csdn.net/weixin_43822124/article/details/112523303
更新20220729
1.参考资料:异常检测专题(2)- 统计学方法 https://zhuanlan.zhihu.com/p/343748853
这里提到一种非参数方法,基于直方图的算法,Histogram-based Outlier Score (HBOS)。
它的思路是假定每个维度之间相互独立,分别计算每个维度的概率密度,最后合并成总体的概率密度,再根据概率密度计算异常分数值。
优点:HBOS方法的优势是计算速度较快,对大数据集友好。
缺点:但是异常识别的效果一般,且针对特征间比较独立的场景。
总之,HBOS在全局异常检测问题上表现良好,但不能检测局部异常值。但是HBOS比标准算法快得多,尤其是在大数据集上。
公式:
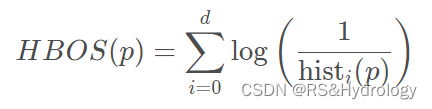
2.几种过滤数据的方法:http://cms.dt.uh.edu/faculty/delavinae/F03/3309/Ch03bHandout.PDF

图片截取自:http://cms.dt.uh.edu/faculty/delavinae/F03/3309/Ch03bHandout.PDF

智能推荐
【Scikit-Learn 中文文档】流形学习 - 监督学习 - 用户指南 | ApacheCN-程序员宅基地
文章浏览阅读143次。中文文档:http://sklearn.apachecn.org/cn/stable/modules/manifold.html 英文文档:http://sklearn.apachecn.org/en/stable/modules/manifold.html 官方文档:http://..._arpack用户指南,
分布式基础(四)——分布式理论之分布式一致性:Paxos算法-程序员宅基地
文章浏览阅读793次,点赞14次,收藏17次。通过本章的讲解 ,我们应该理解了Paxos算法的核心内容:Basic Paxos算法和Multi-Paxos 思想。Basic Paxos 是经过证明的,而 Multi-Paxos 是一种思想,缺失实现算法的必须编程细节,这就导致Multi-Paxos 的最终算法实现,是建立在一个未经证明的基础之上的,正确性是个问号。所以在实际使用时,不推荐设计和实现新的 Multi-Paxos 算法,而是建议优先考虑 Raft 算法,因为 Raft 的正确性是经过证明的。
传统TCP拥塞控制算法详解一(TCP Reno传统拥塞控制算法)_用matlab比较慢启动算法和tcp reno算法-程序员宅基地
文章浏览阅读164次。传统的TCP拥塞控制算法AIMD,TCP Reno算法_用matlab比较慢启动算法和tcp reno算法
Python淘宝手机爬虫数据可视化分析大屏全屏系统 开题报告_基于python爬虫的淘宝手机可视化-程序员宅基地
文章浏览阅读541次,点赞10次,收藏14次。*:进度安排** 2023.09.10—2023.10.15 查看大量的文献,收集课题有关资料,确定论文选题;2023.12.23—2023.12.27 根据指导老师提出的建议再进行修改,完善系统功能设计 2023.12.28—2024.04.10 在查阅大量文献之后,运用多种研究方案,完成系统开发并基本完成论文初稿。2024.04.16—2024.05.14 在导师指导下,对论文进行反复修改形成终稿,装订成册上交学院,同时为毕业论文答辩做准备工作 2024.05.15 进行毕业论文答辩。
计算机毕业设计springboot羊养殖管理平台m68sg9【附源码+数据库+部署+LW】_springboot + vue 养羊管理系统-程序员宅基地
文章浏览阅读134次。选题背景:随着人们对健康食品的需求不断增加,养殖业成为了一个备受关注的行业。而羊养殖作为一种传统的畜牧业形式,在农村地区具有广泛的发展空间和潜力。然而,传统的羊养殖管理方式存在着许多问题,如信息不对称、技术水平低下、资源浪费等,制约了养殖业的发展。因此,建立一套科学、高效的羊养殖管理平台势在必行。选题意义:建立羊养殖管理平台具有重要的意义。首先,通过平台可以实现信息共享和交流,使养殖户能够及时获取到行业动态、市场信息以及养殖技术等方面的知识,提高其经营管理水平。其次,平台可以提供科学的养殖指导和技术_springboot + vue 养羊管理系统
HTML——jQuery—动画特效之淡入淡出案例_html 淡入淡出-程序员宅基地
文章浏览阅读370次。案例 <!DOCTYPE html><html> <head> <meta charset="utf-8"> <title></title> <style> *{ margin: 0; padding: 0; } .box{ width: 300p..._html 淡入淡出
随便推点
【内网开发之pkg打包nodejs项目踩坑实践】_nodejs pkg 指定node-程序员宅基地
文章浏览阅读1.3k次,点赞22次,收藏25次。最近新入职新公司,内网开发()。将现有nodejs服务打包成指定平台(国产麒麟系统V10,arm64架构)可执行文件交付,避免源代码泄露。在我完完全全掌握了他的原理后,我终于解决了我所遇到的坑,特此记录学习,参考(基于es6规范封装 Express + DM8 + WebSocket + PKG )_nodejs pkg 指定node
python - 简单算法题 - 列表偏移_列表偏移:现有lst = [1,2,3,4,5],将列表向右偏移2位后,变成lst = [4,5,1-程序员宅基地
文章浏览阅读887次。列表偏移来源:http://www.coolpython.net/python_primary/algorithm_exercises/easy_list_shift.html题目要求lst = [1,2,3,4,5],列表向右偏移两位后,变成lst = [4,5,1,2,3]思路分析第一种方式:用切片将 [1,2,3] 和 [4,5] 取出来,之后合并在一起lst = [1,2,3,4,5]result = lst[3:]+lst[:3]print(result)或者lst = [_列表偏移:现有lst = [1,2,3,4,5],将列表向右偏移2位后,变成lst = [4,5,1,2,3]
MySQL之PXC集群搭建_gcomm://-程序员宅基地
文章浏览阅读366次。一、PXC 介绍1.1 PXC 简介PXC是一套MySQL高可用集群解决方案,与传统的基于主从复制模式的集群架构相比 PXC 最突出特点就是解决了诟病已久的数据复制延迟问题,基本上可以达到实时同步。而且节点与节点之间,他们相互的关系是对等的。PXC 最关注的是数据的一致性,对待事物的行为时,要么在所有节点上执行,要么都不执行,它的实现机制决定了它对待一致性的行为非常严格,这也能非常完美的保证 MySQL 集群的数据一致性;1.2 PXC特性和优点完全兼容 MySQL。 同步复制,事务..._gcomm://
动力电池MES系统方案_锂电池mes系统-程序员宅基地
文章浏览阅读487次,点赞5次,收藏4次。总之,MES系统是一种强大的生产管理工具,可以帮助企业提高生产效率、优化生产流程、降低成本、提高产品质量和客户满意度。_锂电池mes系统
JavaScript原型详解:原型对象prototype,对象原型__proto__,constructor 属性,原型链-程序员宅基地
文章浏览阅读239次,点赞5次,收藏4次。1.为什么出现原型2.原型对象和对象原型以及构造函数之间的关系3.constructor 属性。
APP备案避坑指南,值得收藏_app备案收费-程序员宅基地
文章浏览阅读845次。但是要注意,这类APP里面的业务不允许涉及经营性内容,如 “购买”、“买卖”、“交易”、“优惠券”、“电子商务” 等,也不能涉及到 “某公司”、“某俱乐部”等。省级通信管理局在收到 APP 备案材料后,材料准确无误的,在二十个工作日内完成审批,发放备案号,并通过短信、邮件形式告知主办者。若 APP 在不同的运行平台使用不同的名称,则需要按照不同的 APP 完成多个备案,最终管局会根据不同名称下发不同的备案号。如果企业的APP架设的服务器在国内,或者要上架国内的应用商店,就必须要备案。_app备案收费