hadoop之MapReduce详解【转】-程序员宅基地
技术标签: Shuffle Mapreduce优化 hadoop MapReduce
转自:https://blog.csdn.net/weixin_44591209/article/details/88049264
MapReduce源于Google一篇论文,它充分借鉴了“分而治之”的思想,将一个数据处理过程拆分为主要的Map(映射)与Reduce(归约)两步。简单地说,MapReduce就是"任务的分解与结果的汇总"。
MapReduce (MR) 是一个基于磁盘运算的框架,贼慢,慢的主要原因:1)MR是进程级别的,一个MR任务会创建多个进程(map task和reduce task都是进程),进程的创建和销毁等过程需要耗很多的时间。 2)磁盘I/O问题, MapReduce作业通常都是数据密集型作业,大量的中间结果需要写到磁盘上并通过网络进行传输,这耗去了大量的时间。
注:mapreduce 1.x架构有两个进程:JobTracker :负责资源管理和作业调度。TaskTrachker:任务的执行者。运行 map task 和 reduce task。在2.x的时候由yarn取代他们的工作了。
MapReduce工作流程
input.txt—>InputFormat—>Map阶段—>shuffle阶段(横跨Mapper和Reducer,在Mapper输出数据之前和Reducer接收数据之后都有进行)—>Reduce阶段 —>OutputFormat —>HDFS:output.txt
InputFormat接口:将我们的输入数据进行分片(split),输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。输入分片的大小一般和hdfs的blocksize相同(128M),可以改,但最好不要。
Map阶段: Map会读取输入分片数据,一个输入分片(input split)针对一个map任务,进行map逻辑处理(用户自定义)
Reduce阶段:对已排序输出中的每个键调用reduce函数。此阶段的输出直接写到输出文件系统,一般为hdfs。
MapReduce Shffle详解(2.x)
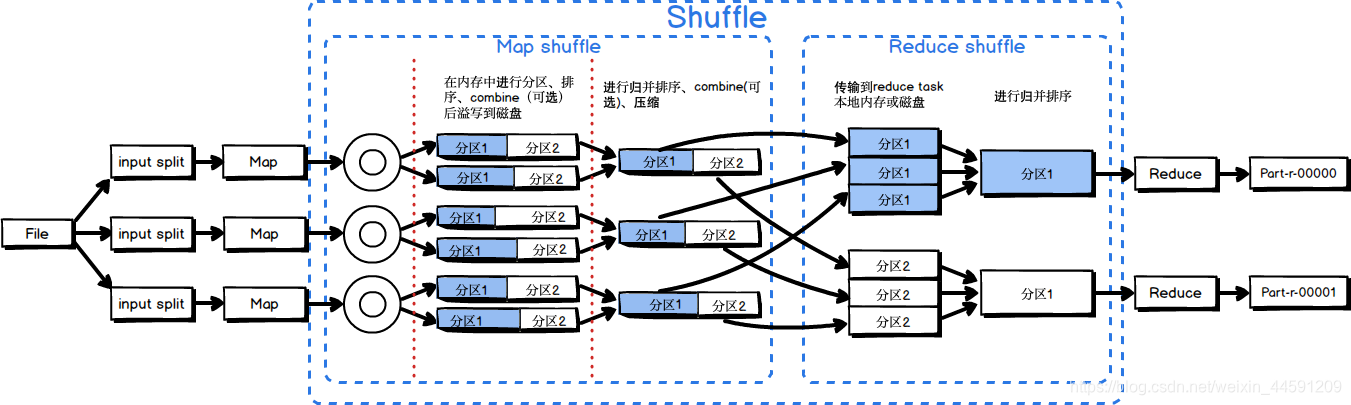
为了确保每个reducer的的输入都是按键排序的,系统执行排序的过程,即将map task的输出通过一定规则传给reduce task,这个过程成为shuffle。
Shuffle阶段一部分是在map task 中进行的, 这里成为Map shuffle , 还有一部分是在reduce task 中进行的, 这里称为Reduce shffle。
Map Shuffle 阶段
Map在做输出时候会在内存里开启一个环形缓冲区,默认大小是100M(参数:mapreduce.task.io.sort.mb),Map中的outputCollect会把输出的所有kv对收集起来,存到这个环形缓冲区中。
环形缓冲区:本质上是一个首尾相连的数组,这个数组会被一分为二,一边用来写索引,一边用来写数据。一旦这个环形缓冲区中的内容达到阈值(默认是0.8,参数:mapreduce.map.sort.spill.percent),一个后台线程就会把内容溢写(spill)到磁盘上,在这过程中,map输出并不会停止往缓冲区写入数据(反向写,到达阈值后,再反向,以此类推),但如果在此期间缓冲区被写满,map会被阻塞直到写磁盘过程完成。溢写过程按照轮询方式将缓冲区的内容写到mapred.local.dir指定的作业特定子目录中的目录中,map任务结束后删除。

先介绍两个概念:
Combiner: 本地的reducer,运行combiner使得map输出结果更紧凑,可以减少写到磁盘的数据和传递给reducer的数据。可通过编程自定义(没有定义默认没有)。适用场景:求和、次数等 (做 ‘’+‘’ 法的场景) 【如平均数等场景不适合用】。
Partitioner:分区,按照一定规则,把数据分成不同的区,Partitioner决定map task输出的数据交由哪个reduce task处理,一个partition对应一个reduce task。 分区规则可通过编程自定义,默认是按照key的hashcode进行分区。
在数据溢写到磁盘之前,线程首先根据partitioner将数据划成相应的分区,然后在每个分区中按键进行区内排序。如果设置了combiner,它就在排序后的输出上运行。所以每次溢写到磁盘上的数据应该是 分区且区内有序的。
每次溢写会生成一个溢写文件(spill file),因此在map任务写完其最后一个输出记录之后,会有多个溢写文件。在Map 任务完成前,所有的spill file将会进行归并排序为一个分区且有序的文件。这是一个多路归并过程,最大归并路数由默认是10(参数:mapreduce.task.io.sort.factor)。如果有定义combiner,且至少存在3个(参数:mapreduce.map.combine.minspills )溢出文件时,则combiner就会在输出文件写到磁盘之前再次运行。
在将压缩map输出写到磁盘的过程中对它进行压缩加快写磁盘的速度、更加节约时间、减少传给reducer的数据量。将mapreduce.output.fileoutputformat.compress设置为true(默认为false),就可以启用这个功能。使用的压缩库由参数mapreduce.output.fileoutputformat.compress.codec指定。
当spill 文件归并完毕后,Map 将删除所有的临时spill 文件,通知appmaster, map task已经完成。
Reduce Shuffle 阶段
Reducer是通过HTTP的方式得到输出文件的分区。使用netty进行数据传输,默认情况下netty的工作线程数是处理器数的2倍。一个reduce task 对应一个分区。
在reduce端获取所有的map输出之前,Reduce端的线程会周期性的询问appmaster 关于map的输出。appmaster是知道map的输出和host之间的关系。在reduce端获取所有的map输出之前,Reduce端的线程会周期性的询问master 关于map的输出。Reduce并不会在获取到map输出之后就立即删除hosts,因为reduce有可能运行失败。相反,是等待appmaster的删除消息来决定删除host。
当map任务的完成数占总map任务的0.05(参数:mapreduce.job.reduce.slowstart.completedmaps),reduce任务就开始复制它的输出,复制阶段把Map输出复制到Reducer的内存或磁盘。复制线程的数量由mapreduce.reduce.shuffle.parallelcopies参数来决定,默认是 5。
如果map输出相当小,会被复制到reduce任务JVM的内存(缓冲区大小由mapreduce.reduce.shuffle.input.buffer.percent属性控制,指定用于此用途的堆空间的百分比,默认为0.7),如果缓冲区空间不足,map输出会被复制到磁盘。一旦内存缓冲区达到阈值(参数:mapreduce.reduce.shuffle.merge.percent,默认0.66)或达到map的输出阈值(参数:mapreduce.reduce.merge.inmem.threshold,默认1000)则合并后溢写到磁盘中。如果指定combiner,则在合并期间运行它已降低写入磁盘的数据量。随着磁盘上副本的增多,后台线程会将它们合并为更大的,排序好的文件。注:为了合并,压缩的map输出都必须在内存中解压缩。
复制完所有的map输出后,reduce任务进入归并排序阶段,这个阶段将合并map的输出,维持其顺序排序。这是循环进行的。目标是合并最小数据量的文件以便最后一趟刚好满足合并系数(参数:mapreduce.task.io.sort.factor,默认10)。
因此,如果有40个文件(包括磁盘和内存),不会在四趟中每趟合并10个文件而得到4个文件,再将4个文件合并到reduce。而是第一趟只合并4个文件,随后的三塘合并10个文件。最后一趟中,4个已经合并的文件和剩余的6个文件合计十个文件直接合并到reduce。
这并没有改变合并的次数,它只是一个优化措施,尽量减少写到磁盘的数据量。因为最后一趟总是直接合并到reduce,没有磁盘往返。
至此,Shuffle阶段结束。
Shuffle总结
1)map task收集map()方法输出的kv对,放到内存环形缓冲区中
2)从内存环形缓冲区不断将文件经过分区、排序、combine(可选)溢写(spill)到本地磁盘
3)多个溢出文件会归并排序成大的spill file
4)reduce task根据自己的分区号,去各个map task机器上取相应的结果分区数据
5)reduce task会取到同一个分区的来自不同maptask的结果文件,reduce task会将这些文件再进行归并排序
6)合并成大文件后,shuffle过程结束
MapReduce 调优
输入阶段:
处理小文件问题:
Map阶段:
1)减少溢写(spill)次数。
2)减少合并(merge)次数。
3)不影响业务逻辑前提下,设置combine。
4)启用压缩。
Reduce阶段:
1)合理设置map和reduce数。
2)合理设置map、reduce共存。
3)规避使用reduce:因为reduce在用于连接数据集的时候将会产生大量的网络消耗。
4)合理设置reduce端的buffer:默认情况下,数据达到一个阈值的时候,buffer中的数据就会写入磁盘,然后reduce会从磁盘中获得所有的数据。也就是说,buffer和reduce是没有直接关联的,中间多个一个写磁盘->读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少IO开销。
| 配置参数 |
参数说明 |
| mapreduce.task.io.sort.mb | shuffle的环形缓冲区大小,默认100M。如果能估算map输出大小,就可以合理设置该值来尽可能减少溢出写的次数,这对调优很有帮助。 |
| mapreduce.map.sort.spill.percent | 环形缓冲区溢出的阈值,默认0.8。 |
| mapreduce.task.io.sort.factor |
归并因子,默认为10。 一般调高,增大merge的文件数目,减少merge的次数,从而缩短mr处理时间。将此值增加到100是很常见的。 |
| mapreduce.map.combine.minspills | 默认为3。运行combiner所需的最少溢出写文件数(如果已指定combiner) |
| mapreduce.output.fileoutputformat.compress |
map输出是否压缩,默认为false。如果map输出的数据量非常大,那么在写入磁盘时压缩数据往往是个很好的主意,因为这样会让写磁盘的速度更快,节约磁盘空间,并且减少传给reducer的数据量。 |
| mapreduce.output.fileoutputformat.compress.codec |
用于map输出的压缩编解码器,默认为org.apache.Hadoop.io.compress.DefaultCodec。推荐设置为LZO压缩。 |
| mapreduce.job.reduce.slowstart.completedmaps | 调用reduce之前,map必须完成的最少比例,默认为0.05。 |
| mapreduce.reduce.shuffle.parallelcopies | reducer在复制阶段复制线程的数量,默认为5。 |
| mapreduce.reduce.shuffle.input.buffer.percent | 在shuffle的复制阶段,分配给map输出的缓冲区占JVM堆空间的百分比,默认为0.7。 |
| mapreduce.reduce.shuffle.merge.percent | reduce输入缓冲区溢写的阈值。默认是0.66。 |
| mapreduce.reduce.merge.inmem.threshold |
reduce输入缓存区的文件数阈值。默认是1000。0或者小于0意味着此参数不生效。 |
| mapreduce.map.maxattempts |
每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.reduce.maxattempts |
每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.task.timeout |
Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该task处于block状态,可能是卡住了,也许永远会卡主,为了防止因为用户程序永远block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。 |
MapReduce 常用命令
[hadoop@hadoop002 bin]$ mapred --help
Usage: mapred [--config confdir] COMMAND
where COMMAND is one of:
pipes run a Pipes job
job manipulate MapReduce jobs
queue get information regarding JobQueues
classpath prints the class path needed for running
mapreduce subcommands
historyserver run job history servers as a standalone daemon
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
archive-logs combine aggregated logs into hadoop archives
hsadmin job history server admin interfacemapred job -list : 查看当前运行的job
mapred job -kill jobId : 杀掉某个job
mapred job -kill-task taskid : 杀掉某个task
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法