Linux Ext2/Ext3/Ext4文件系统_linux子系统邮件网站为什么没有ext2-程序员宅基地
技术标签: Ext2 Hotspot和Linux内核 Ext4 Ext3 文件系统
目录
一、Ext2磁盘结构
Ext2文件系统的磁盘结构如下图:
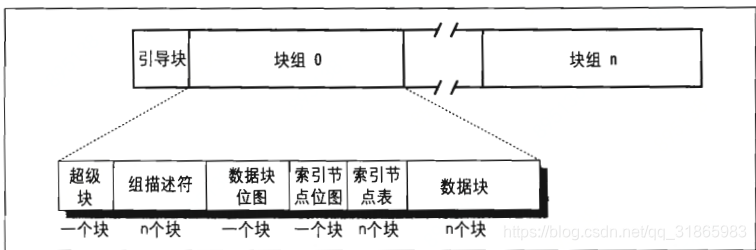
任何Ext2分区的第一个块都是引导块,引导块保存了分区和内核启动加载器相关的信息,不受文件系统管理。其余磁盘块被Ext2分成块组,每组包含的数据块和索引节点等都存放在相邻的磁道上,所有的块组大小相同且顺序的存放在磁盘上,内核可以根据块组的整数索引很快计算该块组在磁盘上的具体位置。由于内核尽可能的把同一个文件的数据块存放在同一个块组中,所以块组减少了文件碎片,减少了访问该文件的磁盘平均寻道时间。每个块组都包含如下信息:
1、超级块
是描述文件系统相关信息的超级块的一个拷贝,数据结构为ext2_super_block,主要记录了索引节点总数,块总数,空闲块数,空闲索引节点数,每块组的块数和索引节点数,分区的状态,安装操作计数器和最后一次安装时间等,用于文件系统一致性检查。
2、组描述符
记录当前块组相关信息,数据结构为ext2_group_desc,主要包含数据块位图,索引节点位图对应的块号,第一个索引节点表块的块号,组中空闲块和空闲索引节点的个数,即可以根据组描述符快速定位数据块位图,索引节点位图和索引节点表。
3、数据库块位图和索引节点位图
位图就是位的序列,其中0表示该位对应的数据块或者索引节点是空闲的,1表示占用的,每个位图都存放在单独的块中,比如块的大小是1024字节,可以描述的1024*8=8192个块的状态。根据位图可以快速定位处于空闲的数据块或者索引节点。
4、索引节点表
索引节点表就是一组连续的索引节点,存放在一组连续的磁盘块上,第一个磁盘块的块号保存在组描述符中的bg_inode_table字段中。所有的索引节点大小相同,即128字节,比如大小为4096字节的块可以包含32个索引节点。每个Ext2索引节点的数据结构为ext2_innode,主要包含了文件类型,文件访问控制列表,目录访问控制列表,文件大小,文件数据块数,最后访问时间,最后修改时间,指向第一个数据块的指针等文件属性信息。
索引节点大小有限制,如果需要增加其他的文件属性则需要使用增强属性机制,增加的属性都保存在一个单独的数据块中,索引节点的i_file_acl字段指向该数据块,linux提供setxattr(),getxattr(),listxattr()等系统调用来处理增强属性。增强属性机制主要是为了实现ACL访问控制列表而引入的,通过该列表可以限定某个文件允许访问的用户或者用户组及其对应的权限。
5、数据块
不同文件类型使用数据块的方式不同,主要有以下几种情形:
- 普通文件在创建时是空的,不需要数据块,只有写入数据时才分配数据块,也可通过truncate()系统调用清空其对应的数据块。
- 目录对应的数据块是一个特殊的数据结构,ext2_dir_entry_2,包含了索引节点号,目录项长度,文件名长度,文件类型和文件名5个属性,根据索引节点号可以快速定位对应的索引节点,根据目录项长度可以找到下一个目录项的起始地址。
- 符号链接的数据块取决于符号链接的路径名长度,如果小于60个字符则放在索引节点的i_blocks字段,如果大于60个字符则采用跟目录相同的数据块。
- 设备文件,管道和套接字都不需要数据块,相关信息都存放在索引节点中
二、Ext2 索引节点和数据块管理
Linux上通过superformat或者fdformat程序格式化磁盘,然后通过mke2fs程序创建Ext2文件系统,创建时需要指定块大小和分配的索引节点个数,保留块的百分比(默认5%),然后初始化所有的块组的组描述符,索引节点表和位图等,对有缺陷的块会用一个链表组织起来放到lost+found目录下。
创建索引节点即文件或者目录等时,会先从父目录所属的块组开始往后查找空闲索引节点足够多的合适的块组,然后根据该该块组的索引节点位图找到一个空闲的索引节点,将相应的位置位,初始化索引节点属性和访问控制列表,更新关联的计数器属性和链表,最后将包含该索引节点的磁盘块读入页高速缓存中并返回新索引节点对象的地址。
删除索引节点时会根据索引节点号和每个块组包含的索引节点数找到该索引节点所属的块组,找到对应的索引节点位图,更新关联的计数器,将位图对应的位置0。删除索引节点前必须删除内核相关的数据结构,删除指向该索引节点的硬链接并回收对应的数据块。
从相对于文件起始位置的偏移量f开始读取a字节时,需要根据f和块大小计算偏移量f的字节所处的文件块号,因为数据块在磁盘上不一定是连续存储,所以需要将文件块号同相对于磁盘分区起始位置的逻辑块号建立映射,Ext2是通过索引节点内的i_block字段保存对应映射关系,该字段是一个定长的数组,长度通过EXT2_N_BLOCKS指定,默认为15。前12个数组元素表示0-11文件块号对应的逻辑块号;下标为12的元素包含的逻辑块号指向的数据块包含一个数组,假设块大小为b字节,逻辑块号为4字节,能够映射的文件块号的范围是12~b/4+11; 下标为13的元素包含的逻辑块号指向的数据块包含一个数组,数组每个元素包含的逻辑块号对应的数据块同样包含一个数组,即二级间接映射,能够映射的文件块号范围是b/4+12~(b/4)^2+b/4+11; 下标为14的元素为三级映射,能够映射的文件块号范围是(b/4)^2+b/4+12~(b/4)^3+(b/4)^2+b/4+11,如下图所示:
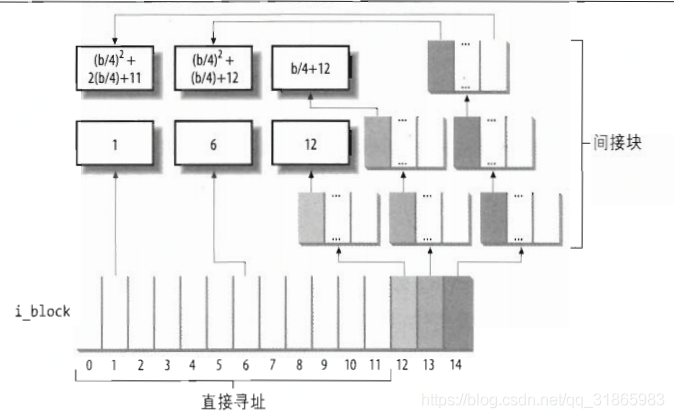
如果读取的文件块号小于12,则两次磁盘访问就可以读取目标数据,一次找到逻辑块号,一次读取逻辑块号对应的磁盘块,如果大于12个则可能需要多次访问磁盘,因为索引节点和数据块的数据都在页高速缓存中,所以可以极大的减少磁盘访问次数,提高访问效率。上述数据块的查找机制表明块的大小会直接影响寻址方式并限制文件系统支持的文件最大字节数,如下图:

文件的洞是普通文件的一部分,具体来说是一堆随机数量的空字符,但是这些空字符不存放在磁盘上,通常用于对文件做散列。每个索引节点的i_size字段定义程序所看到的文件大小,包含洞的,i_blocks字段存放实际分配给文件的以512字节为单位的有效的数据块的数量,即i_size会大于i_blocks算出来的文件大小。
进程创建一个新的文件时只是创建了一个新的索引节点,只有当有数据需要写入该文件时才会分配数据块,分配数据块通过ext2_get_block()函数完成,如果存在未写满数据的已分配数据块则返回该数据块,否则分配一个新的空闲的数据块,在获取目标块的同时,Linux也会给文件分配一组多达8个的相邻的预分配块。为了减少文件碎片,Ext2首先在预分配块中查找符合条件的目标块,如果失败则尽可能在已分配给文件的最后一个块的附近找一个新块,如果失败则尝试在包含该索引节点的块组找一个空闲的块,还是失败则从邻近的块组中查找空间的块。
当进程删除文件或者将文件大小设置为0时必须释放文件所属的所有数据块,通过ext2_truncate()函数完成。该函数会扫描i_block字段,找到该文件的所有的逻辑块号,然后循环调用ext2_free_blocks()函数来逐一释放这些块,释放时会找到数据块所属的块组的数据块位图,将对应的位置0,然后更新相关计数器即可。
参考:ext2文件系统
三、Ext3文件系统
Linux系统启动过程中会调用e2fsck程序检查文件系统超级块对象的s_mount_state字段,如果他不等于EXT2_VALID_FS,说明文件系统因为断电故障或者系统崩溃等原因未正常退出,此时保存在内存中的未及时刷新到磁盘上的相关数据结构可能处于不一致状态,e2fsck程序就开始检查并适当修正磁盘上文件系统的所有数据结构。这种文件系统一致性检查的所花费的时间取决于要检查的文件数和目录数,随着磁盘容量扩大,文件数和目录数不断增加,耗时也不断加长。为了避免这种耗时性的一致性检查引入了日志文件系统,通过一个特殊的磁盘区来记录磁盘的写操作,这种记录就叫做日志,当文件系统不一致后通过日志来修复相关数据结构就很快了,因为可以通过日志很快定位故障前发生修改的磁盘数据结构。所谓日志是指执行任何磁盘写操作时,先把待写的块的副本写入日志中,等写入日志的I/O数据传送完成时就会开始该块与对应磁盘逻辑块之间的I/O数据传输,即正常的磁盘写入,等写入完成,日志中的块副本就会被丢弃,视为无效的。当从系统故障中恢复时,e2fsck程序会将故障前已经提交到日志的未写入磁盘的块副本重新写入文件系统,故障前未提交到日志的未写入磁盘块则忽略,保证一定程度的数据一致性。
Ext3是Ext2的增强版,与Ext2兼容,其磁盘数据结构与Ext2基本相同,在Ext2的基础上重点强化了日志功能。文件系统通常有两种块,包含元数据的块和包含普通文件数据的块,Ext2和Ext3中元数据是指超级块,块组描述符,索引节点,位图块等,不同文件系统使用不同的元数据。Ext3支持将元数据块和普通文件数据块都写入日志中,具体提供了三种不同大的日志模式:
- 日志(journal),文件系统的所有文件数据和元数据的改变都写入日志中。该模式减少了文件修改丢失,但是增加了额外的磁盘开销,是最安全和最慢的模式
- 预定(ordered),只有文件系统的元数据的修改才写入日志,但是保证当元数据块和相关的文件数据块都需要写入磁盘时,文件数据块会比元数据块先写入磁盘,此时元数据块已经在日志中保存了一个副本。该模式是Linux的默认模式,可以减少普通文件修改的丢失,因为要维护元数据块和普通文件块的相关性和两者的磁盘写入顺序,相比写回模式有轻微的性能损耗。
- 写回(writeback),只有文件系统的元数据的修改才写入日志,对元数据块和普通文件数据块写入磁盘的顺序不做限制,由页高速缓存的脏页刷新机制决定。该模式是其他日志文件系统使用的方式,是最快的模式,但是当系统故障时存在文件损坏的风险。
可以通过mount命令在设备挂载的时候指定日志模式,如mount –t ext3 –odata=writeback /dev/sda2 /jdisk。
Ext3的日志通常放在根目录下名称.journal的隐藏文件中,Ext3本身不处理日志,而是借助日志块设备(JDB)的通用内核层实现,JDB本身必须保证所有的日志记录不能因系统故障而损坏。Ext3与JDB交互时基于以下三个单元:
1、日志记录,本质是对文件系统将要执行的一次低级操作的描述,JDB层使用的日志记录是由低级操作所修改的整个缓冲区组成,日志记录在日志内部表现为普通的数据块。
2、原子操作处理,即一个系统调用对磁盘数据结构的一组低级操作,当从系统故障中恢复时,文件系统确保这组低级操作要么都成功,要么都失败。
3、事务,将一个处理如一次函数调用涉及的多个原子操作处理放在一个事务中,一个事务下的所有日志记录都存放在日志的连续块中,只有当该事务下所有的日志记录的块副本都写入磁盘即事务已完成时才会回收该事务使用的块,即丢弃该事务下所有的日志记录。事务一旦被创建就能接受新的原子操作处理,当事务持续的时间超过5s或者没有空闲块保存日志记录则会停止接受新的原子处理。事务未完成时按照其是否接受新的原子操作处理分为以下几种状态:
- T_RUNNING,还在接受新的原子操作处理
- T_LOCKED,不接受新的原子操作处理,其中一部分未完成
- T_FLUSH,所有原子操作都已完成,磁盘写入未完成
- T_COMMIT,所有的日志记录都已写入磁盘,此时事务被标记为未完成
日志中可能包含多个事务,任何时刻只有一个事务出于T_RUNNING状态下,称为活动事务。
参考:《深入理解Linux内核》(第三版)
四、Ext4文件系统
Ext4完全向后兼容Ext3,其磁盘数据结构与Ext3基本一致,因为是基于Ext3做的改进,所以Ext4对Linux只是一种临时的过渡解决方案,最终会被一种全新的下一代文件系统取代。目前Ext4尚未完全成熟,部分新特性如数据校验和、一流的配额支持和大分配块等还在开发完善中,其与Ext3的主要区别如下:
- ext3 文件系统使用 32 位寻址,这限制它最大支持 2 TiB 文件大小和 16 TiB 文件系统系统大小;ext4 使用 48 位寻址,理论上可以在文件系统上分配高达 16 TiB 大小的文件,其中文件系统大小最高可达 1000000 TiB(1 EiB)
- ext3目前只支持32,000个子目录,而ext4支持无限数量的子目录。
- ext4引入区段extent,extent是存放文件块号和逻辑块号映射关系的数据结构,是对Ext3中inode数据结构的一个改进,从而节省大文件下多次访问磁盘获取索引节点表的性能开销。
- ext4增加了日志校验,检查日志文件的正确和完整性,避免被非法篡改
- ext3 提供粒度为一秒的时间戳,ext4 通过纳秒级的时间戳
- ext2 和 ext3 都不直接支持在线碎片整理 —— 即在挂载时会对文件系统进行碎片整理,ext4 通过
e4defrag提供支持
参考: Linux.ext4文件系统.inode和extent
智能推荐
pve搭建文件服务器,PVE安装NFS实现存储共享-程序员宅基地
文章浏览阅读8.5k次。1、新增硬盘(磁盘阵列)分区fdisk /dev/sdbm:显示菜单g:建立gpt分区,n:建立partion分区。w:保存磁盘分区2、格式化磁盘分区及挂载磁盘mkfs -t ext4 /dev/sdb1mount /dev/sdb1 /mnt/sdb(挂载点自定)永久挂载磁盘:输入vi /etc/fatab编辑这文件,在最后追加一行 /dev/sdb1 /mnt/sdb ext4 default..._pve nfs
对朴素贝叶斯法后验概率最大化含义的一些思考_后验概率最大化的含义-程序员宅基地
文章浏览阅读4.8k次,点赞27次,收藏41次。看李航的《统计学习方法》朴素贝叶斯章节中4.1.2后验概率对大化的含义时,对这里的理解有些困扰,参考另一篇博客在这里写下自己对这一个问题的个人见解,烦请指正。 如上图所示,书中从期望风险函数直接跳到条件取值期望,这里的推导过程如下:在这里,设:那么上式可以改为:对于上式的期望风险求最..._后验概率最大化的含义
SpringBoot框架集成Demo集合_springboot最全demo-程序员宅基地
文章浏览阅读285次。序该文档主要列举了常见的SpringBoot的基础搭建以及和其他框架的整合的基础项目搭建自己从项目中提取了认为比较着重的要点和注意事项一并列举到了文档中,后续会加以补充更多与SpringBoot整合的相关demo代码地址: SpringBootDemoAll.01, 构建一个基本的SpringBoot项目要点:@LocalServerPort 表示获取当前启动的项目端口号,一般订阅..._springboot最全demo
Matlab调用Python 无法解析名称 py.evaluation_无法解析名称 'py.runner.runner'。、-程序员宅基地
文章浏览阅读3.6k次。问题背景Matlab环境下调用Python函数,调用文件为"evaluation.py",提示"py.evaluation"。解决方案首先确认Python文件路径已被导入,如果文件路径没有导入,则执行如下语句导入路径if count(py.sys.path,'文件路径') == 0 insert(py.sys.path,int32(0),'文件路径');end和普通的Python编程模式一样,在Matlab中,除了基础函数,使用其他任何函数都需要导入相应的库。例如导入numpy_无法解析名称 'py.runner.runner'。、
中国十大用户体验设计咨询公司排名_国内咨询公司排行榜-程序员宅基地
文章浏览阅读1.8w次。中国十大用户体验设计咨询公司排名随着全球互联网产业的飞速发展,人们对于用户体验的嗅觉变得更加灵敏。用户体验对应的是体验地图,叫user experience map或者user journey map,集中于要做的产品,用来挖掘用户在跟产品的触点中的痛点,并给出对应的解决方法,让以人为本的设计理念贯穿开发的最早期甚至进入整个品牌的发展。国内不乏优秀的用户体验设计咨询公司,今天就盘点一下:既有中..._国内咨询公司排行榜
XML,WSDL,SOAP,JSON的关系及区别_api接口xml、json、soap的区别-程序员宅基地
文章浏览阅读1k次。原文地址:XML,WSDL,SOAP,JSON的关系及区别1.XML与JSON比较首先,XML与JSON的目前主要的两种数据交换格式。其结构如下:<?xml version="1.0" encoding="utf-8"><country> <name>中国</name> <province> <name&..._api接口xml、json、soap的区别
随便推点
Ueditor自定义图片上传路径,以及图片回显路径_ueditor上传路径和读取路径-程序员宅基地
文章浏览阅读2.9w次,点赞6次,收藏28次。最近发现Ueditor有个小bug,每次图片都上传到项目路径下,当重新发布一个版本后,图片就没了,所以决心修改结构如下:1. 首先,进入config.json,修改如下:其他的都不改,只改选中部分,这个是图片访问路径前缀我们要关注的是【文件访问路径】和【文件上传路径】然后,分析就开始了【分析1】:查找上传路径在哪里用到了,即【imagePathFormat】,只要找到他,就可以找到上传的绝对路径,..._ueditor上传路径和读取路径
Java事务处理是指什么_java 事务处理的概念-程序员宅基地
文章浏览阅读195次。一、什么是Java事务通常的观念认为,事务仅与数据库相关。事务必须服从ISO/IEC所制定的ACID原则。ACID是原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)的缩写。事务的原子性表示事务执行过程中的任何失败都将导致事务所做的任何修改失效。一致性表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。..._java什么叫事务,处理步骤
Unable to locate element: {“method“:“css selector“,“selector“:“.oRhbg“}_no such element: unable to locate element: {"metho-程序员宅基地
文章浏览阅读1.2w次,点赞9次,收藏6次。今天遇到一个比较傻的问题,其实就是思维的问题。一时间没有反应过来。刚上手用Python Selenium做自动化测试的同学应该会遇到类似这样的问题Unabletolocateelement:"method":"cssselector","selector":".oRhbg"Unable to locate element: {"method":"css selector","selector":".oRhbg"}Unabletolocateelement:"method":"cssselector"_no such element: unable to locate element: {"method":"css selector","selecto
MFC双缓冲绘图-程序员宅基地
文章浏览阅读2.3k次,点赞3次,收藏26次。双缓冲绘图的核心是将所有绘图操作的屏幕设备CDC pDC 用自定义的内存设备CDC MemDC来代替,然后通过在内存的位图CBitmap中作图,然后将作好的图复制到屏幕MemDC来显示,同时禁止背景刷新,从而消除闪烁。一、原因窗体在响应WM_PAINT消息的时候要进行复杂的图形处理,那么窗体在重绘时由于过频的刷新而引起闪烁现象。因为窗体在刷新时会有一个擦除原来图象的过程OnEraseBkgnd,它利用背景色填充窗体绘图区,然后在调用新的绘图代码进行重绘,这样一擦一写造成了图象颜色的反差。当WM_PA_mfc双缓冲绘图
Leetcode--easy系列1_leetcode easy pdf-程序员宅基地
文章浏览阅读1.2k次。#6 ZigZag ConversionThe string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)_leetcode easy pdf
jmeter控制请求执行顺序_jmeter怎么控制请求之间的顺序-程序员宅基地
文章浏览阅读9.6k次,点赞3次,收藏44次。一、同一个线程组内可通过jmeter-Critical Section Controller (临界部分控制器)来控制业务逻辑: 根据锁名来控制并发,同一个锁名之下,在同一时间点只能存在一个运行中,适用于控制并发的场景。锁名类型: 锁名为空,认为每个锁为不同的锁锁名相同,多个锁认为是同一个锁,同一个时间点只能存在一个运行中锁名为变量,根据变量值来判断是不是属于同一个锁,变量值为相同时,则认为是同一个锁作用临界区控制器确保其子节点下的取样器或控制器将被执行(只有一个线程作为一个锁)_jmeter怎么控制请求之间的顺序