5、【办公自动化】Python实现PDF转Word_python pdf转word-程序员宅基地
技术标签: PDF转Word 办公自动化 pdf2doxc Python
这周 HR 小姐姐让我提供一份可编辑的简历,于是,我找了半天发现只留存了 PDF 格式的简历,这显然不符合小姐姐的要求。
为了省事,我从网上顺手下了一个声称免费文档的转换器应用程序,没想到只给我免费转一页,超过一页需要充值会员,这不是坑吗?打着免费的幌子诱导用户注册和充值,哎,不是厂商的套路太深就是自己想的太天真啊,哈哈哈哈,果断卸载了!!!
白嫖不易,冷静了一下,决定自己写个 Python 程序实现这个需求,前面自己动手实现过 Word 转 PDF ,现在再搞一个 PDF 转 Word 吧。
于是,去 Pypi 官网搜索一下是否存在类似 pdf2word、pdf2doxc 等名称的第三方库,果然发现了一个 pdf2doxc,而且安装、入门示例、API 文档也很详细,赶紧去学习下吧!
经过一番研究,这个依赖库有三种转换方式可以选择使用,下面逐一介绍下:
1、写代码实现
支持将PDF所有页进行转换,也支持指定页的转换。
<1>. 转换PDF所有页
from pdf2docx import Converter
from pdf2docx import parse
# 测试用例1
pdf_filename = 'D:\\XXX\\简历-wxx.pdf'
docx_filename_all = 'D:\\XXX\\简历-wxx_all.docx'
"""默认转换pdf所有页"""
# 方式1:
parse(pdf_filename, docx_filename_all)
# 方式2:
# pdf = Converter(pdf_filename)
# pdf.convert(docx_filename_all)
# pdf.close()转换过程中,日志如下:
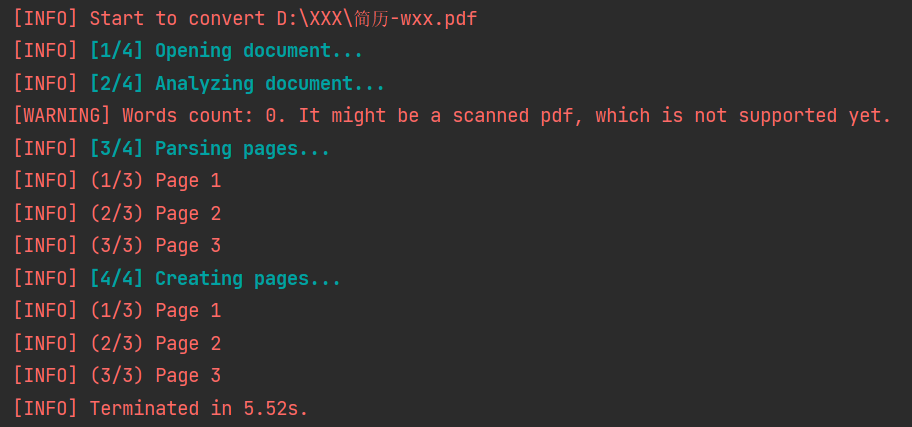
<2>. 转换PDF指定页
from pdf2docx import Converter
# 测试用例1
pdf_filename = 'D:\\XXX\\简历-wxx.pdf'
docx_filename_part = 'D:\\XXX\\简历-wxx_part.docx'
"""
转换pdf指定页(比如:只转换第三页到第五页):
start=0表示第一页,end=5表示第六页但不包括
"""
pdf = Converter(pdf_filename)
# 方式1:使用start~end参数,转换前两页简历,start=0可省略
pdf.convert(docx_filename_part, start=0, end=2)
# 方式2:使用pages参数
# pdf.convert(docx_filename_part, pages=[2, 3, 4])
pdf.close()转换效果如下:(两页的简历)

2、命令行模式
这种方式不用编码,但需要熟悉命令行的书写方式,可以通过 help 查看下 pdf2docx 命令的用法:
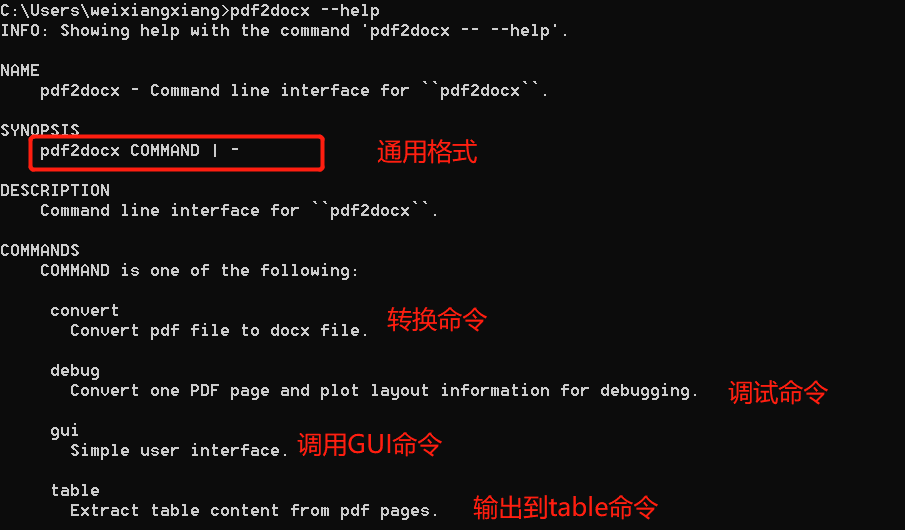
<1>. 转换PDF所有页
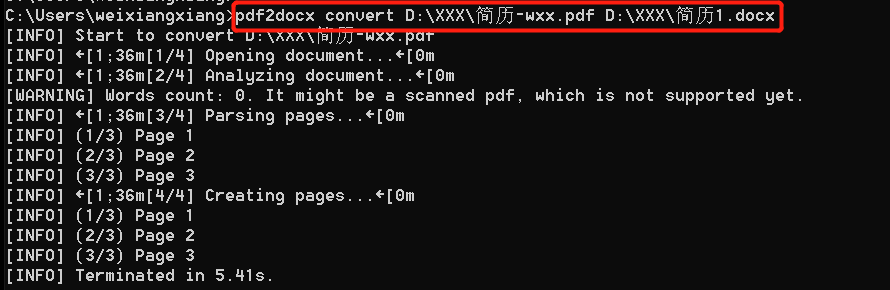
<2>. 转换PDF指定页
方式1,通过start、end参数,转换第二页到第三页
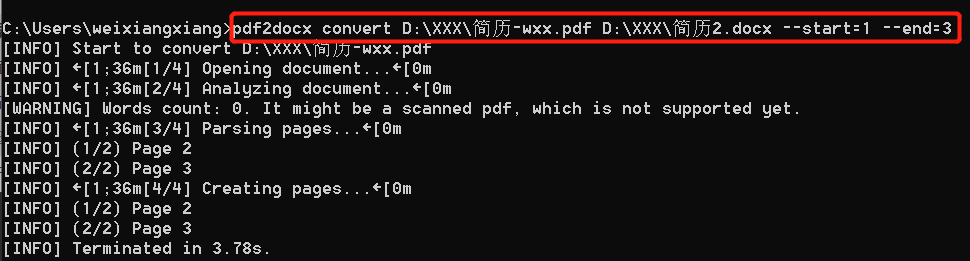
方式2,通过pages参数,转换第二页和第三页
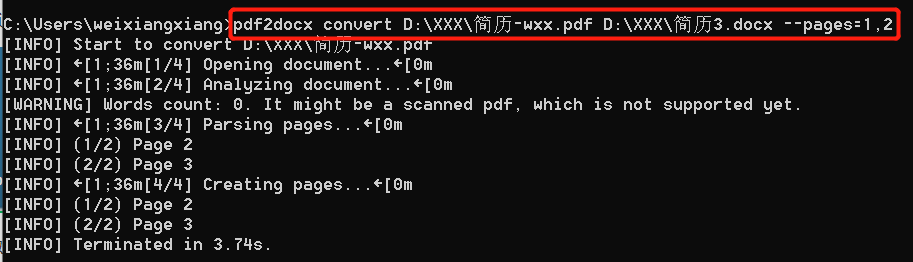
转换效果如下:
3、GUI界面模式
通过命令 pdf2docx gui 调出 GUI 界面进行转换,操作步骤如下:
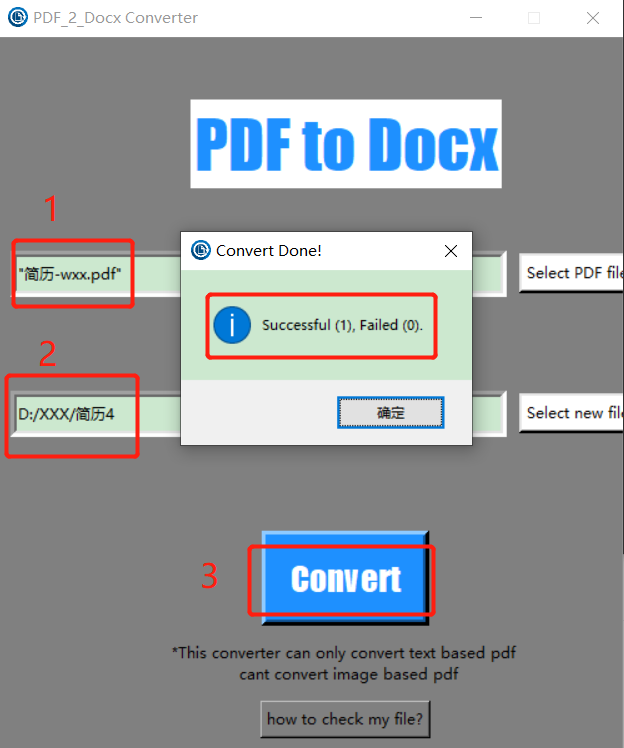
总结
至此,通过 pdf2doxc 已经实现了我的 PDF 转 Word 需求,实现效果也很棒!另外,如果再深入一点的话,会有这么几个问题值得思考:
- 如果 PDF 是加密类型的怎么办?
- 如果PDF含有大量的图片,表格、代码块等特殊区域是否也可以完美转换呢?
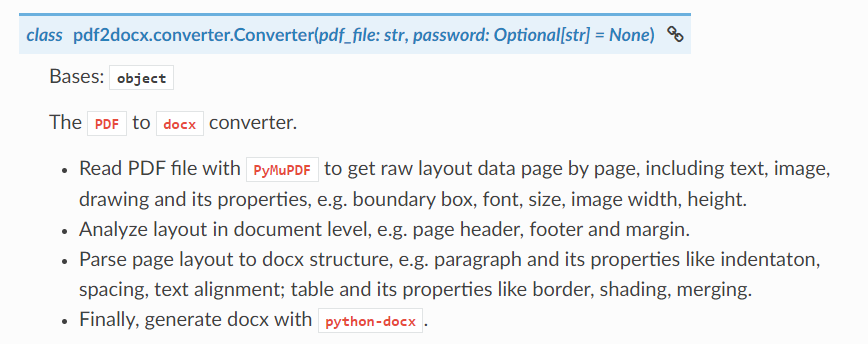
<1>. 加密场景转换
查看 API 文档可知,通过 Converter() 函数加入打开 PDF 文档的密码参数password
<2>. 含有大量的图片,表格、代码块等特殊区域的场景转换
这里,有一篇111页的学习笔记,存在着大量的特殊区域,测试一下转换效果~
from pdf2docx import Converter
# 测试用例
pdf_filename = 'D:\\XXX\\SpringBoot经典学习笔记.pdf'
docx_filename_all = 'D:\\XXX\\SpringBoot经典学习笔记_all.docx'
docx_filename_part = 'D:\\XXX\\SpringBoot经典学习笔记_part_3.docx'
pdf = Converter(pdf_filename)
pdf.convert(docx_filename_all)
pdf.close()效果如下:

有些没有转换过来,成为了空白页!!通过控制台输出信息可以看到:出现错误时,当前页不会转换输出的。
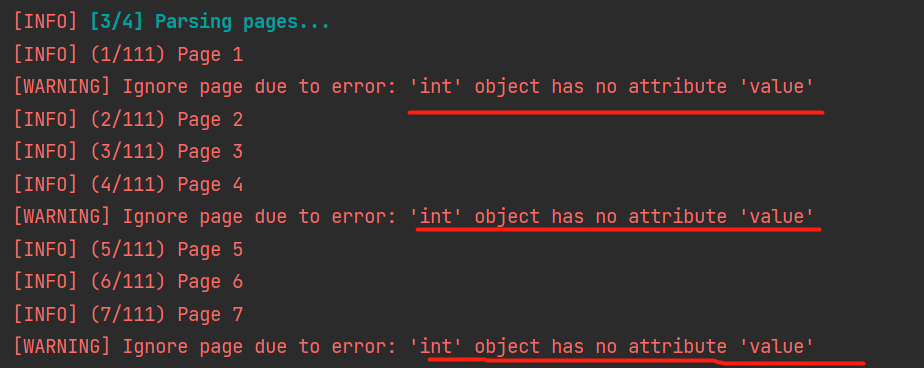
该问题主要是 PDF 存在无法识别的特殊区域导致的,因此,PDF的内容尽量不要太复杂,不要太花里胡哨。通常情况下,pdf2doxc 库已经可以满足常见的转换需求了。
最后,Pypi官网还能搜索到 pdfminer、pdfminer1、pdfminer2、pdfminer3、pdfminer3k 等 PDF 转换/分析器的第三方库,看着都混乱,这里不再考虑使用这些库了,感兴趣的话可以再研究研究~
智能推荐
element ui 表格中的字太长,想要把多余的字变成...解决方法,一个属性即可_element ui table文字变多转换...-程序员宅基地
文章浏览阅读3.4k次,点赞5次,收藏4次。问题描述如下相应代码段 <el-table style="width: 100%" height="330px" :data="tableData" border stripe> <el-table-column align="center" type="index" label="#"></el-table-column> <el-table-column align="center" label="社团编号" prop="a_element ui table文字变多转换...
详解Java泛型机制-程序员宅基地
文章浏览阅读598次,点赞29次,收藏13次。分享一份自己整理好的Java面试手册,还有一些面试题pdf。
DOCTYPE的作用,常见声明,删除<!DOCTYPE>发生什么?严格模式和混杂模式_<!doctype>-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏10次。在HTML文档首部往往会有这样一行代码:<!DOCTYPE html>由于常见而且一般可能自己使用编辑器设置了默认模板(包含这一句代码),可能很多时候我们会忽略它的存在,不知道它的作用以及重要性。实际上,这行代码是一个声明, 其作用是告诉浏览器按照哪一种HTML文档规范解析HTML文档。Web 世界中存在许多不同的文档。只有了解文档的类型,浏览器才能正确地显示文档。HTML 也有多个不同的版本,只有完全明白页面中使用的确切 HTML 版本,浏览器才能完全正确地显示出 HTML 页面。H_
Java中使用FFmpeg进行视频图像的人脸检测_java 视频识别人-程序员宅基地
文章浏览阅读106次。在Java中,我们可以使用FFmpeg库来进行视频图像的处理和分析。其中一个常见的应用是人脸检测,通过识别视频中的人脸,我们可以进行人脸识别、情感分析等各种应用。总结起来,本文介绍了如何在Java中使用FFmpeg进行视频图像的人脸检测。通过使用外部进程和FFmpeg命令,我们可以方便地在Java应用程序中集成人脸检测功能。安装和配置FFmpeg的详细步骤超出了本文的范围,您可以在FFmpeg的官方网站上找到相关的文档和指南。然后,我们构建了一个FFmpeg的命令字符串,该命令使用了FFmpeg的。_java 视频识别人
时差问题-程序员宅基地
文章浏览阅读567次。Problem4:时差问题。一个地方和北京相差17个小时(比北京慢17h),输入北京时间,输出当地时间;输入格式:年 月 日 时 分,输出格式一样。此题注意输出格式控制(后四项数字位数为两位)#include <iostream>#include <iomanip>using namespace std;bool isLeap(int year);...
【车间调度】基于matlab樽海鞘算法求解带小车的车间调度AGV-fjsp问题【含Matlab源码 3283期】-程序员宅基地
文章浏览阅读62次。樽海鞘算法求解带小车的车间调度AGV-fjsp问题完整的代码,方可运行;可提供运行操作视频!适合小白!
随便推点
保姆级爬虫无水印视频大全 最新版java+selenium_java爬取抖音视频-程序员宅基地
文章浏览阅读1k次,点赞8次,收藏8次。抖音、快手视频无水印爬虫,以及通过请求网页获取html页面数据_java爬取抖音视频
ruby on rails win下安装-程序员宅基地
文章浏览阅读4k次。ruby on rails win下安装发现新的技术ruby on rails,关于他一些介绍就不说了,我说下今天的我的安装过程!首先是下载http://rubyforge.org/projects/rubyinstaller/我弄的是最新的!然后安装,跟安装其他软件一样本地安装没学会,需要下载gemhttp://rubyforge.org/frs/?group_id=126还要下载一个配套的ap
Python Challenge笔记 - 1-程序员宅基地
文章浏览阅读93次。http://www.pythonchallenge.com/pc/def/map.html图片中提示 K->M O->Q E->G下面给了一段话 看起来是加密过了的 根据提示可以知道 每个字母后移了2位使用string和maketrans可以解决此问题解密出来的文字提示使用这个规律解密地址 将map解密后得到 ocr即下一关地址http://www.pythonchall..._maketrans(l,l[2:]+l[:2])
markdown合并单元格、设置单元格背景颜色和字体颜色_markdown表格颜色-程序员宅基地
文章浏览阅读2.6k次。markdown 编辑器通过HTML实现:设置单元格背景颜色、设置字体颜色和合并单元格的两种方式_markdown表格颜色
【Halcon轮廓提取】-程序员宅基地
文章浏览阅读1.6w次,点赞13次,收藏137次。edges_image算子:edges_image(Image : ImaAmp, ImaDir : Filter, Alpha, NMS, Low, High : )功能:使用Deriche, Lanser, Shen或者Canny 滤波器进行边缘提取参数:Image (input_object) : 单通道图像(数组)ImaAmp (output_object):多通道图像(数组),边缘振幅或梯度大小图像。ImaAmp输出变量,说的是edges的amplitude,其实就是梯度的大小(因为边缘_halcon轮廓提取
【PLS预测】基于PCA主成分分析结合PLS实现近红外光谱检测的菠萝含水率预测附matlab代码_近红外数据pca分析-程序员宅基地
文章浏览阅读967次,点赞26次,收藏24次。近红外光谱技术(NIRS)是一种快速、无损的分析技术,已广泛应用于水果品质检测中。本文提出了一种基于主成分分析(PCA)和偏最小二乘回归(PLS)相结合的近红外光谱预测菠萝含水率的方法。该方法利用PCA降维提取光谱特征,并通过PLS建立光谱与含水率之间的定量关系模型.数据预处理:对光谱数据进行标准正态变换和一阶导数处理利用PCA对光谱数据进行降维处理,提取主成分PLS模型建立:采用PLS算法建立光谱与含水率之间的定量关系模型交叉验证法优化PLS模型参数,包括成分数和正则化参数。_近红外数据pca分析