从头开发一个BurpSuite数据收集插件_burp datacollector-程序员宅基地
技术标签: burpsuite插件开发 burpsuite插件 Web安全 信息安全 burpsuite
一段时间没写公众号了,最近写了个 burpsuite 数据收集的插件,于是想出一篇从头编写一个 burpsuite 插件的教程。
这个插件的目的收集 burpsuite 请求中的数据,如请求中的子域名、文件名、目录名、参数名等,保存到数据库,然后根据出现的次数进行排序,出现次数多的排在前面,从而强化我们的字典。
插件效果演示
先来看看插件的效果图:

该插件会在 burp 上面新建一个标签页,用来保存一些配置,如数据库 ip 地址、端口、账号密码等。还可以从数据库导出数据到文件作为字典,或者从文件中导入数据到数据库中,用于和别人分享及备份数据库。
导出的文件效果如下:
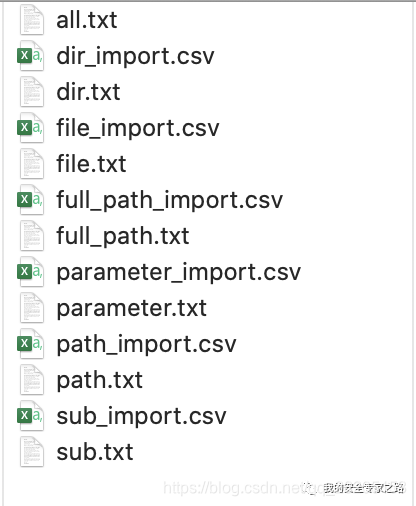
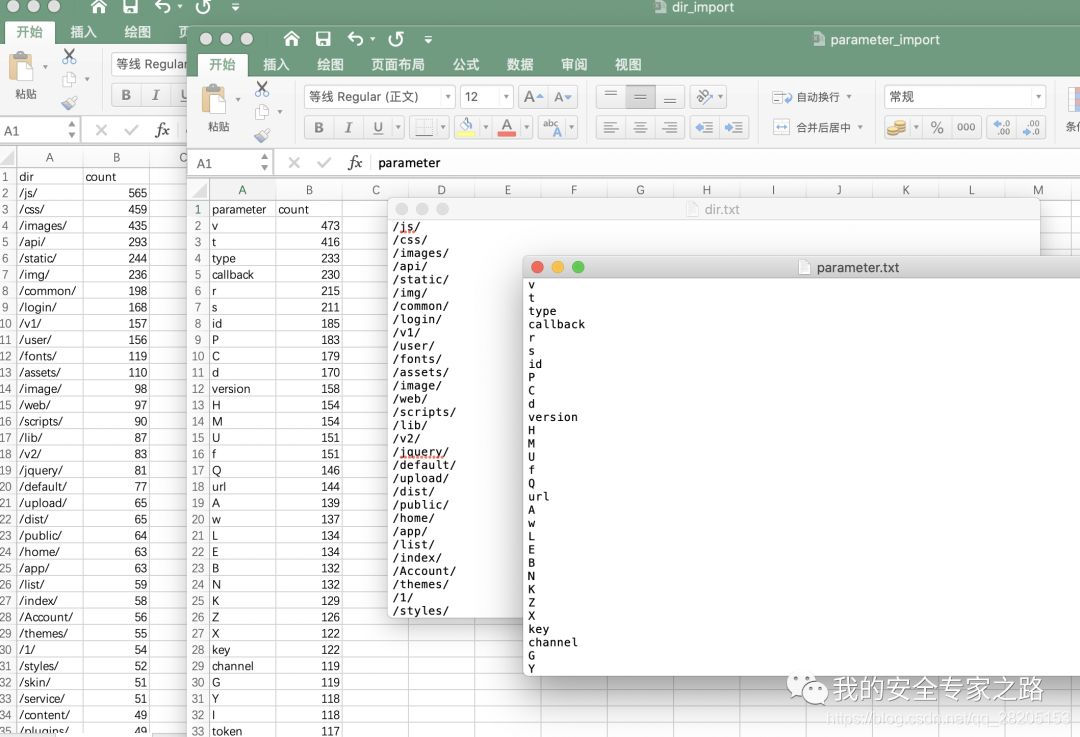
导出的字典文件是 txt 文件,主要是作为字典来使用,其中的内容是根据出现的次数来排序的, 如 /test/ 目录在 a.baidu.com 出现了一次,然后在 b.baidu.com 出现了一次,那么它的 count 值就是 2 。
目录在不同网站出现的次数越多,那么排名就会越前,证明该目录是最常现出的,因此应该把它放在前面提高命中率。
同理,对于请求中的参数名、文件名、子域名等数据,也是通过出现的次数来排序。
上图中,导出的还有 csv 文件,该文件含有出现的次数,可以通过该文件通过插件导入其它数据库,以实现备份或分享的功能。
插件开发
现在开始插件的开发,开发插件需要些前置的知识。
编写 burpsuite 插件需要对 Java 或 Python 语言有一定的基础,在这里我使用的是 Java,因为 Java 编写的插件在 burpsuite 加载得更快,性能更好。
在这里我使用的开发环境是 IDEA ,因为 IDEA 的智能补全功能就像知道我想打什么代码一样,十分强大。
在 IDEA 新建一个 gradle 项目,点击 Create New Project

选择 Gradle 项目, Gradle 是一个构建工具,可以方便加载所需的代码仓库。点击下一步。

给项目起个名称

新建完后,在 build.gradle 文件中添加以下依赖,也就是加载 burpsuite 插件API ,如果提示 auto import, 可以点击,从而自动从远程仓库加载 burpsuite API 。
compile('net.portswigger.burp.extender:burp-extender-api:1.7.13')
同时在 plugins 里面添加 shadow 插件,该插件可以方便把项目打包成 jar 包。
id 'com.github.johnrengelman.shadow' version '5.2.0'

接着在 /src/main/java 目录处创建一个名为 burp 的包名,在 java 目录处右键 -> New -> Package

接着在该包上右键,新建一个名为 BurpExtender 的类。
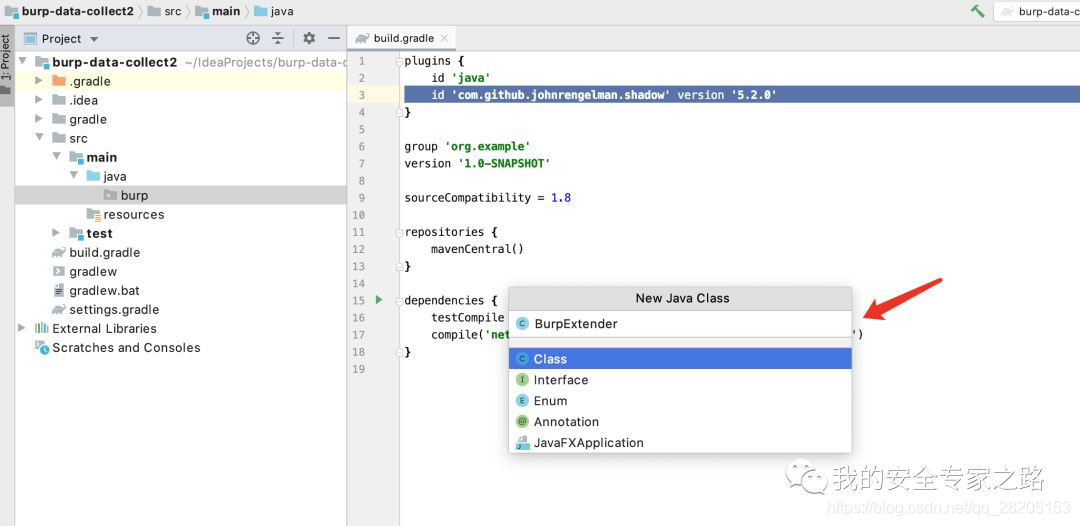
这个包名和类名是固定的,burpsuite 加载插件时就是通过 burp.BurpExtender 来查找的,如果不这样起名,会报 ClassNotFoundException 。
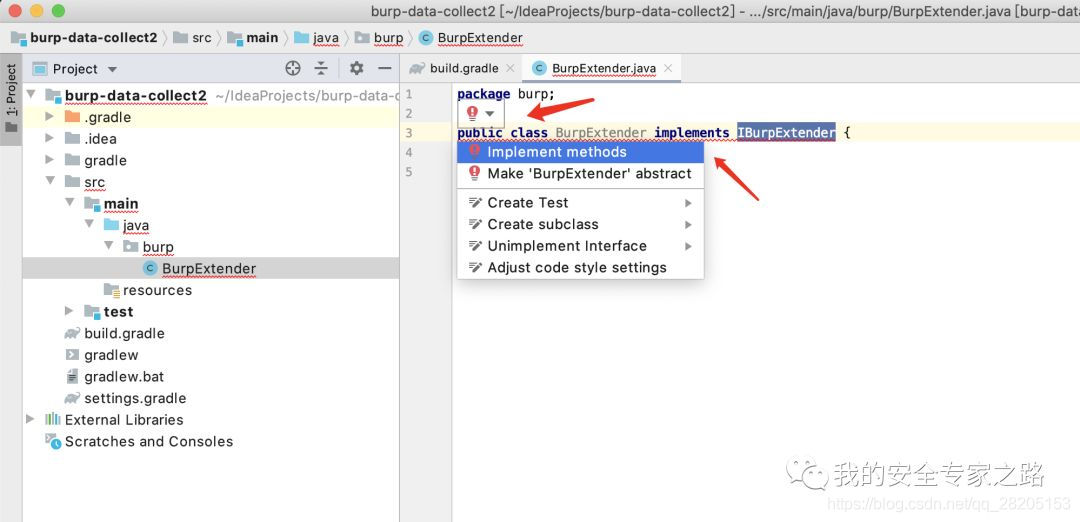
BurpExtender 类需要实现 IBurpExtender 接口,burp 在加载插件时,会调用该接口,并传递 IBurpExtenderCallbacks 接口仅我们使用。
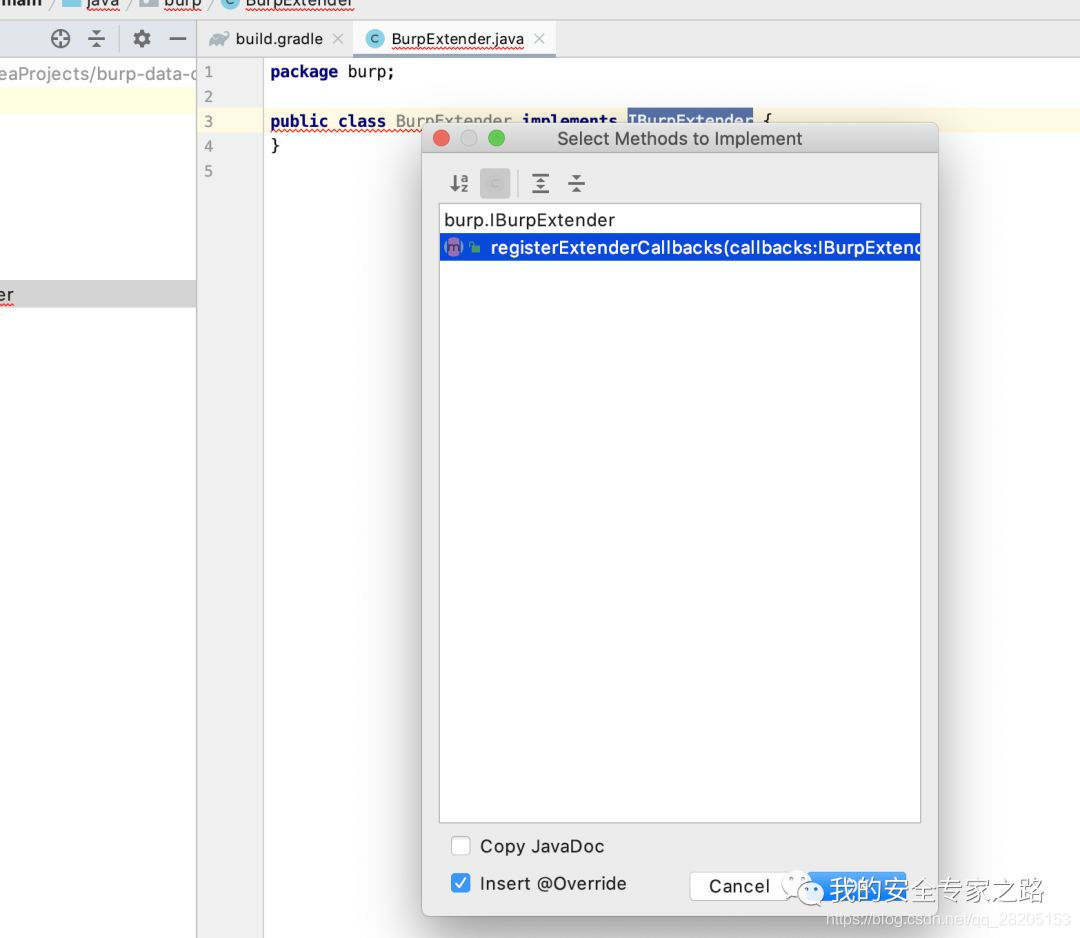
点击错误提示,实现接口中的方法
然后我们添加下面的代码为插件设置名称,并打印一 success 字符串
callbacks.setExtensionName("data-collect2");
callbacks.printOutput("load success");

接着可以编译该项目成 jar 包,然后让 burp 加载看看效果。
点击右侧的 gradle 菜单,展开菜单,双击 shadowjar ,gradle 会自动编译项目成 jar 包,jar 包位于 build 目录中的 libs 目录中。

接着在 burp 的扩展选项卡添加该 jar 包,点击 add

选择 Java 扩展类型,选择我们的 jar 包,点击下一步

可以看到加载插件后成功打印了 success 字符串。

添加标签页
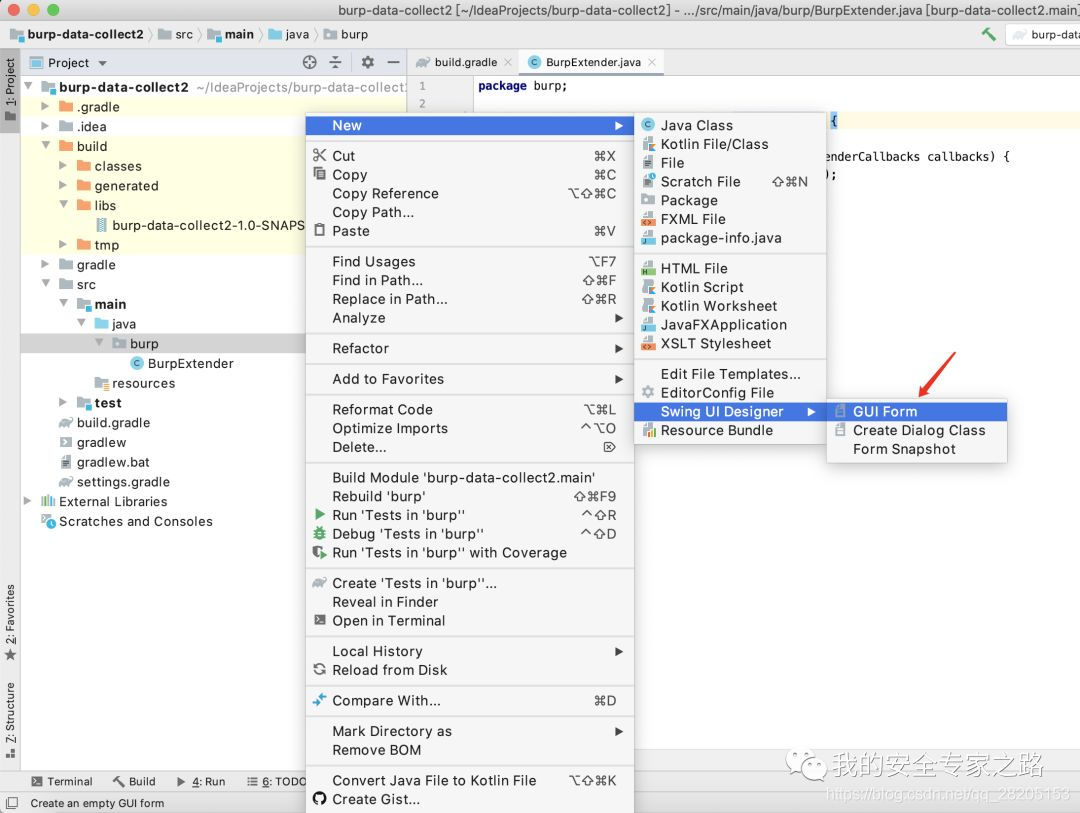
接着我们要为插件创建一个标签页,先在IDEA中创建一个 Form,用于设计UI
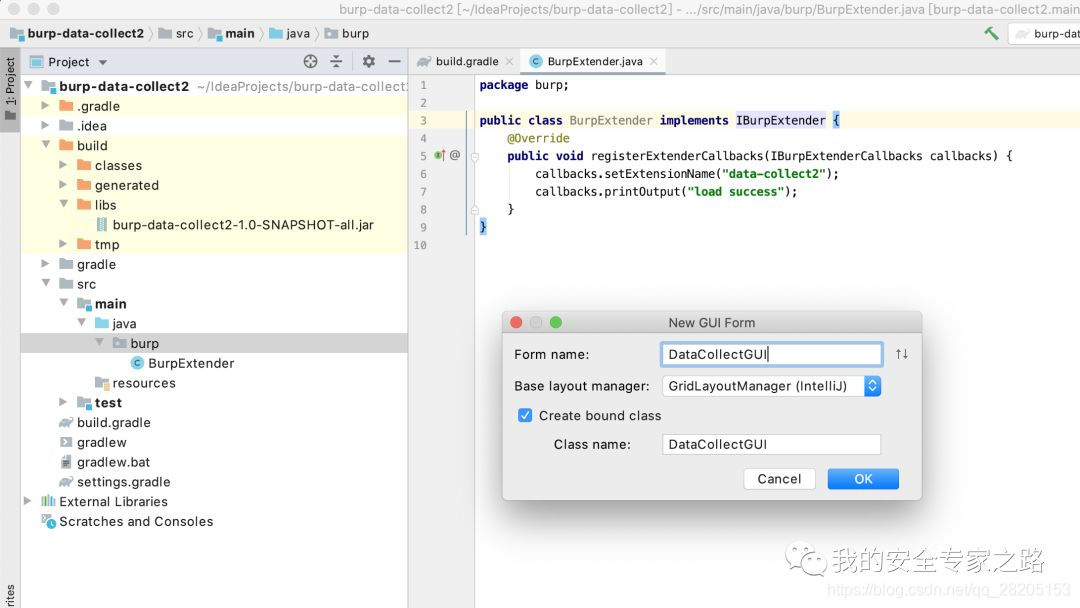
创建的界面如下,左边的窗口中创建了两个文件,一个是 DataCollectGUI.java 文件,该文件与 form 文件绑定,一个是 DataCollectGUI.form 文件,可以在此文件上拖动控件来设计 UI 界面,当界面更新时,会自动生成代码插入 DataCollectGUI.java 文件中。

接着从右边拖一个 JLabel(标签)、一个 JTextField(输入框)和 JButton(按钮) 到设计面板中,效果如下:

然后给根面板设置个变量名,用于后面生成代码:

为了让 IDEA 打包 GUI 界面的类,需要在 build.gradle 添加以下依赖
compile('com.intellij:forms_rt:7.0.3')

接着在设置中设置根据 Form 界面自动生成 Java 源码:
然后在 Gradle 的编译选项中设置编译器是 IDEA 自带的编译器,这样才能自动更新 form 文件中的控件到代码中:

设置好后,点击构建图标,就会自动生成和 form 文件相关的代码,可以看到在 $$$setupUI$$$() 方法中自动生成了我们拖到界面中的3个控件。
注意,$$$getRootComponent$$$() 方法需要给界面中的JPanel 控件设置变量名才可以生成,参考上面的步骤。

接着需要回到 BurpExtender 类中,要为插件添加一个标签页,需要实现 ITab 接口

实现 ITab 接口后,会有两个方法需要实现,其中 getTabCaption() 方法返回标签页的名称, getUiComponent() 方法返回我们创建的 UI 面板。
注意,需要在14行下调用
callbacks.addSuiteTab(this) 来注册接口。
接着双击 gradle 中的 shadowjar 按钮重新打包 jar 包,然后在 burp 重新加载插件,就可以看到效果图了:

获取标签页设置内容
接下来我们需要获取标签页中的配置内容,可以通过添加事件监听器来实现。
回到 IDEA 的 form 文件中,在按钮上右键,点击 Create Listener,选择 ActionListener


创建好后就可以编写点击按键时的代码逻辑了

在这里简单地把输入框中的内容打印在插件日志中,要把内容打印到插件日志中,我们需要获取 IBurpExtenderCallbacks 对象,可以修改构造函数,在初始化时传入:

还需要修改 BurpExtender 中的代码,传入 callbacks 对象

接着在监听器中实现获取标题内容并打印到日志的代码,代码中29行通过 getText()方法获取输入框架的内容,然后在30行处通过 callbacks.printOutput()方法打印内容到日志中。

接着双击 gradle 中的 shadowjar 按钮重新打包 jar 包,然后在 burp 重新加载插件,在插件输入框中输入 hello world, 点击按钮,就会在插件日志中打印输入框中的内容了。
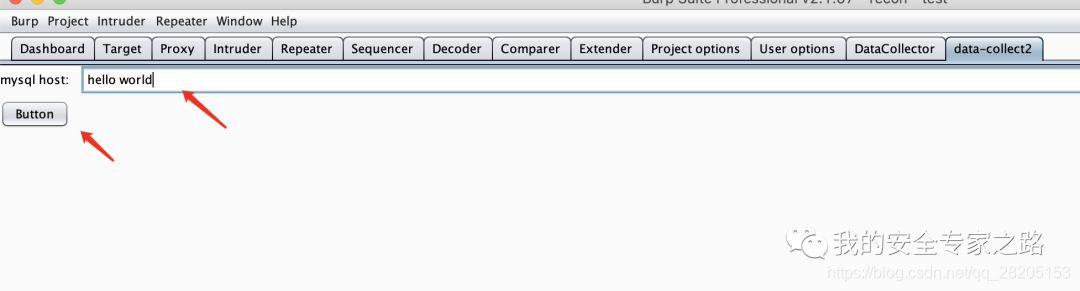
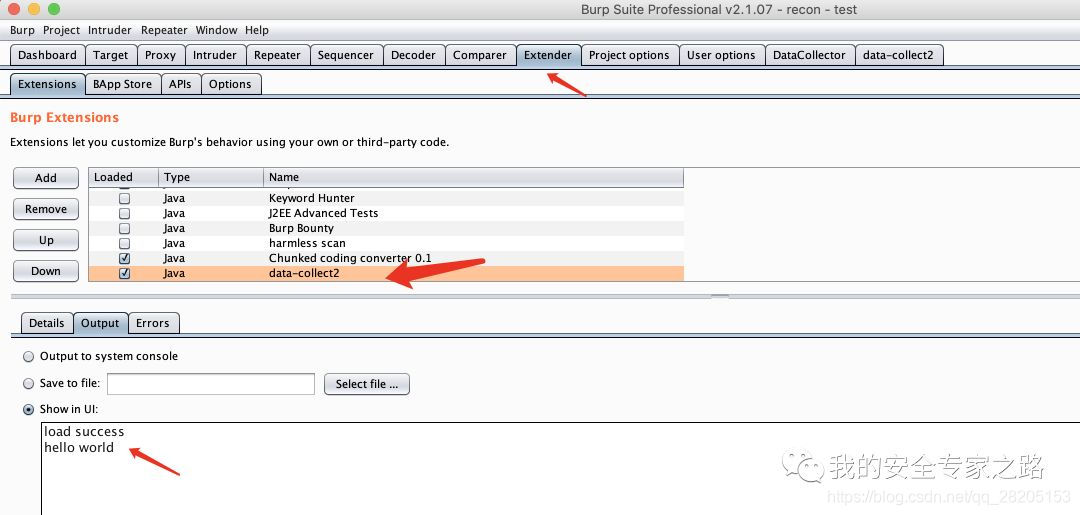
到此,我们可以获取插件输入框中的内容,这样我们就可以开始开发数据收集的插件了。
开发核心功能
由于插件代码比较多,这里就不一一介绍了,先导入开发完成的代码,可以到我的 github 上下载:
https://github.com/QdghJ/burp_data_collector
使用 IDEA 导入项目

选择 gradle 项目

导入后,我们来看看开发数据收集插件需要用到哪些库,首先需要 mysql 的 jdbc 驱动,然后是导出 csv 文件时用到的库:

接着来看看项目的文件结构,在 dao 包中的主要是数据库的操作类,封装了数据库操作的代码,每个表一个类来插入和查询数据。而 gui 包中的就是界面类。

核心要点
这个插件的核心要点如下:
解析功能,解析请求中的各种数据,然后插入到数据库中。
数据库设计,关键体现在查询和插入数据的性能上,在被我的开发朋友调教后,重新设计SQL语句,从导入一次数据需要十几分钟,优化到了几秒内完成。
内存去重,在内存中保存已经插入的数据,如果重复了,就不插入数据库,可以极大地减少数据库的操作。
定时收集数据,每10分钟收集一次数据。
退出时收集数据,当 burp 退出时会进行最后一次数据收集,不用人工收集。
解析请求
首先是解析功能,该功能在 BurpExtender 类的 saveData() 方法中,该方法会在点击 export data to database 按钮后或定时收集时调用,用于解析请求历史中的数据,并保存到数据库中。
在 329 行处调用 callbacks.getProxyHistory() 方法获取请求历史中的所有请求, 接着在 332 行处使用 for 循环遍历所有的请求, 在333行处解析请求内容,并在 334行处获取请求的 host,也就是主机名,如 www.baidu.com。
在 335 行处获取请求的路径,如 /aaa/bbb/ccc.php ,这里就收集到了请求中的路径。然后在339行处插入到内存中,等到最后一次性插入数据库。
接着在 334 行到 359 行之间收集分离的目录,如 /aaa/bbb/ccc/ 目录,会收集
/aaa/bbb/ccc/, /aaa/bbb/ , /aaa/ 三个目录。

接着在 361 行处从 path 中分离出目录,如 /aaa/bbb/ccc/, 那么会收集 /aaa/, /bbb/, /ccc/ 。
接着在 370 行处收集文件名, 如 /js/jquery.js, 那么会收集 jquery.js 。
然后在 376 行处分离主机名,也就是分离域名,只获取子域名,如域名是 aa.bb.cc.dd.ee ,那么会收集先收集分离后的子域名,如 aa, bb, cc, 然后收集 aa.bb.cc, bb.cc, cc 几个子域名。

最后在 400 行处获取请求中的所有参数,402 行处的 2 代表 cookie 参数名,暂时不收集 cookie, 然后收集符合条件的参数名。

数据库设计
数据库设计主要包括表结构的设计,导出语句的的设计,插入语句的设计。数据库的设计对性能的影响很大,开始时我写的SQL语句收集一次数据需要20分钟,经过做开发的朋友改进后,只需1秒,所以写数据库代码就是写SQL语句。
首先是表的设计,本次要收集的数据上面已经介绍过,主要的表如下:
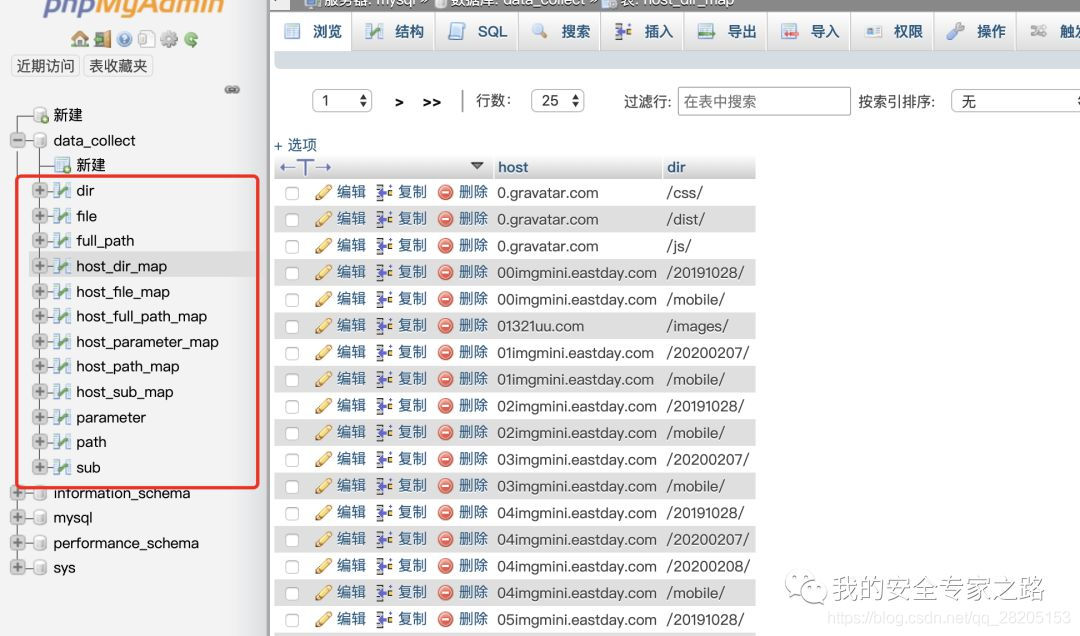
表的类型有两种,一种是 host_xxx_map 表,如 host_dir_map 表用于收集 host 信息及其对应的内容,表的字段有 host 和 dir ,上图可以看出 0.gravatar.com 这个 host 对应的目录有3个。
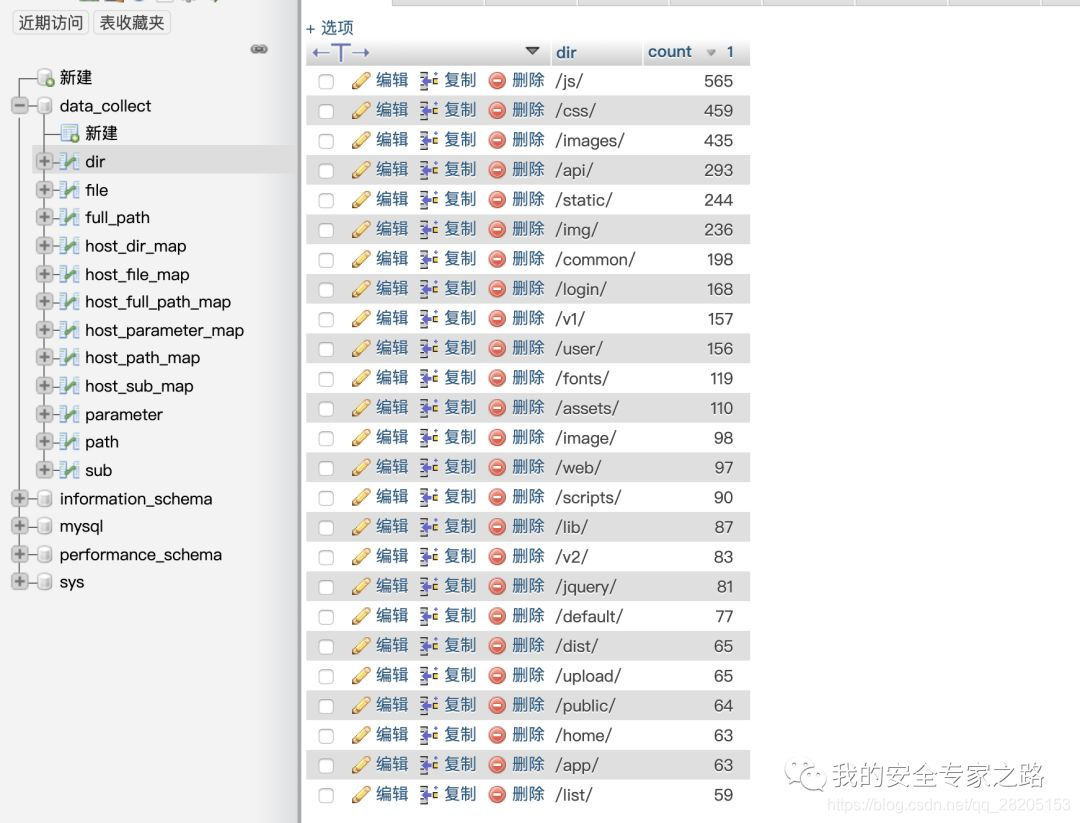
另一种表如,dir 表,用于导入 csv 文件中的数据,表的字段是 dir , count,分别是目录名和出现的数目,主要用于导入别人导出的 dir_import.csv, 当导出数据时,会合并这种表中的数据,再进行导出。
创建表的代码在 dao/DatabaseUtil 类中

接下来说下插入数据时的语句,插入数据时应该怎么处理呢,我一开始的时候设计的是这样的:
假设要插入一条数据, host 值是 www.baidu.com, dir 值是 /js/
下面是伪代码
数据库是否存在该记录 // 此处一条查询语句
如果存在不插入
如果不存在,插入该记录 //此处一条插入语句
假设最坏的情况,我们访问的网站是从来没访问过的,第一次收集数据的时候所有数据都不存在,当该网站有1000条请求时,这里就会进行2000次数据库处理操作。
这样必然是分钟级别的插入,在这样设计时,我需要20分钟才完成一次数据收集。
当我的开发朋友看到这种操作时,内心是崩溃的,于是给我优化了下。首先是数据库是否存在记录的问题,可以使用 INSERT IGNORE 来解决,该语句在插入数据时,如果存在,则不插入。
接着可以使用一条语句插入所有数据,语句如下:
INSERT IGNORE INTO host_dir_map(host, dir) VALUES
("www.baidu.com", "dir1"),
("www.baidu.com", "dir2"),
...
("www.baidu.com", "dir1000")
这样,2000条语句的操作就变成了一条语句完成,从20分钟的插入时间变成了1秒。
接着是导出数据的语句,如果要统计一个目录在所有 host 中出现的次数,需要使用到 group by 语句,语句如下:
SELECT hdm.dir, COUNT(*) AS dirCount FROM host_dir_map hdm GROUP BY hdm.dir ORDER BY `dirCount` DESC
通过使用 dir 字段来分组,然后通过 count(*) 来统计出现的次数,查询结果如下:

具体的导出代码如下:

内存去重
插件是可以定时获取请求内容中的数据并插入数据库的,但每次定时操作时,不知道数据是否插入过数据库了,如果每次都插入全部数据到数据库,还是会影响性能。
因此有必要在每插入一个数据的时候,在内存中记录下该数据已经被插入,在第二次定时收集的时候,遇到已经插入过数据库的数据,就可以跳过此数据。
在内存中检查比在数据库中快很多,这样在导出一次全量的数据后,第二次定时收集的时候会快很多,因为只需要收集新出现的请求。
具体怎样实现呢?我们需要使用 HashMap 和 HashSet 数据结构相结合。
HashMap 是一个键值对数据结构,也就是一个哈希桶,可以把一些键值对保存到该结构中进行快速查找。
HashSet 是一个集合,里面的数据是不重复的元素,也就是说 ,里面只会出现 aa,bb,cc ,而不会出现 aa,aa,bb,cc。
我们可以组合两个数据结构来实现保存 host 对应的 dir 。具体结构如下图:

上图中,www.baidu.com 是一个键,对应的值是一个 hashset 结构,hashset里面装有这个 host 所有的目录。
由于有多个表的内容要保存,只要加多一层 HashMap 就可以实现保存所有表了。

具体实现代码如下:
private boolean addToMemory(String host, String value, String flag) {
boolean result = true;
HashMap<String, HashSet<String>> hostHashMap = memoryHostValueMap.get(host);
if (hostHashMap == null) {
hostHashMap = new HashMap<>();
HashSet<String> hostHashSet = new HashSet<>();
hostHashSet.add(value);
hostHashMap.put(flag, hostHashSet);
memoryHostValueMap.put(host, hostHashMap);
result = false;
} else {
HashSet<String> hostHashSet = hostHashMap.get(flag);
if (hostHashSet == null) {
hostHashSet = new HashSet<>();
hostHashSet.add(value);
hostHashMap.put(flag, hostHashSet);
result = false;
} else {
if (!hostHashSet.contains(value)) {
hostHashSet.add(value);
result = false;
}
}
}
return result;
}
flag 值代表保存的是哪种类型的数据,如 dir、path。以上代码的逻辑是判断内存中是否存在该数据,不存在则插入并返回 false。
在解析数据的时候,可以根据 addToMemory() 函数的返回值来决定是否把数据添加到插入队列中。
具体流程如下:
解析数据时,先通过 checkDir 函数检查是否需要插入数据库

checkDir() 函数调用 addToMemory() 函数判断内存中是否存在该数据了

回到上面的367行处,接着调用 addToInsertMap() 函数把数据保存到插入队列中,addToInsertMap() 函数和 addToMemory() 相似,区别是只保存新增的数据:

在 saveData() 函数的最后会取出内存中保存的新增数据,一次性插入数据库中:

小细节
这个插件比较方便的是会定时保存数据以及在退出 burp 时保存数据。
定时保存数据使用 ScheduledExecutorService 对象定时执行任务:
service = Executors.newSingleThreadScheduledExecutor();
service.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
BurpExtender.this.saveData();
callbacks.printOutput("Scheduled export execution completed");
}
}, 0, 10, TimeUnit.MINUTES);
退出 burp 时保存数据需要实现 IExtensionStateListener,
并在 extensionUnloaded() 方法中保存数据

插件的开发到这里就完成了,具体的实现可以下载源码来查看,喜欢我的文章的可以关注下我的公众号,以后可能会继续发些工具开发的文章。
https://github.com/QdghJ/burp_data_collector
这个插件的开发要感谢我的基友,让我的数据库性能得到了极大的提升。
本文章也在我的公众号发布

智能推荐
android支付宝动画,android仿照支付宝支付成功的动画一-程序员宅基地
文章浏览阅读217次。上边是效果图 上边是依据两种方式实现的,先说地一个效果的实现要实现地一个效果,肯定需要掌握path,patnMeasure,valueAnimator这里跟自定义view关系不是很大思路1 先实现一个静态的效果(用path来绘制) (为什么使用path呢?因为使用path我们可以用pathMeasure来测量出path没一个点的坐标)2 然后用pathMeasure来测量path然后结合value..._安卓支付宝点击最小化的动效
前端将二进制数据流转为文件_JavaScript前端开发之实现二进制读写操作-程序员宅基地
文章浏览阅读2.3k次。关于javascript前端开发之实现二进制读写操作的相关介绍,请看以下内容详解,本文介绍的非常详细,具有参考价值。由于种种原因,在浏览器中无法像nodejs那样操作二进制。最近写了一个在浏览器端操作读写二进制的帮助类!function (entrance) {"use strict";if ("object" === typeof exports && "undefined" !..._js实现多条二进制转成完整的数据
剑指offer-数组中的逆序对_倒转数组为什么要取mid-程序员宅基地
文章浏览阅读957次。数组中的逆序对题目描述 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。例如: 例如,有一个数组为Array[0..n] 其中有元素a[i],a[j].如果 当i< j时,a[i]>a[j],那么我们就称(a[i],a[j])为一个逆序对。在数组{7,5,6,4}中一共存在5对逆序对,分别是(7,6),(7,5),_倒转数组为什么要取mid
绕过cdn探测真实ip方法大全_cdn nmap-程序员宅基地
文章浏览阅读7.3k次,点赞17次,收藏77次。渗透测试过程中,需要寻找真实IP的情况,就是目标使用了cdn。CDN现在大多数的网站都开启了CDN加速,导致我们获取到的IP地址不一定是真实的IP地址。CDN的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息_cdn nmap
DEDE整站动态化或整站静态化设置方法,织梦栏目批量静态/动态方法-程序员宅基地
文章浏览阅读187次。跟版网建站接到一个朋友提问,100多各栏目全部要从动态变成静态,里面的文章也要静态化,如何更快捷的设置dede的静态化或者动态化呢?直接用DEDE后台的SQL命令行工具,SQL语句:DEDE整站动态化:将所有文档设置为“仅动态”,update dede_archives set ismake=-1将所有栏目设置为“使用动态页”,update ded..._织梦怎样把每个栏目都静态化
数理逻辑之 horn公式-程序员宅基地
文章浏览阅读5.3k次,点赞2次,收藏9次。Horn公式,中文名一般翻译成“霍恩公式”,也是范式的一种。Horn原子有三:P::= ┴ | T |p Horn原子 分别是底公式、顶公式和命题原子。 Horn原子合取后的蕴含称为Horn字句:A::= P | PΛA C::= A → P Horn子句 继续合取就是Horn公式:H::= C | CΛH Horn公..._霍恩公式
随便推点
AWS S3 实现预签名上传_aws 签名上传-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏9次。步骤:1、前端上传文件,将要上传的文件名称传到后台2、后台通过该文件名称生成预上传URL返回前端3、前端请求该URL,并携带文件上传至S3后端代码 /** * AWS预签名上传 * @return */ @GetMapping("/uploadFile") public Object generatePreSignedUrlAndUploadObject(String fileName){ Map<St._aws 签名上传
UnrealEngine4蓝图功能_关卡切换后的玩家出身点定位功能实现_ue切换关卡后改变位置-程序员宅基地
文章浏览阅读5.9k次,点赞3次,收藏28次。 (文章为自己制作学习过程中的技术总结,如有不正确的理解,欢迎批评指正) 对于很多游戏都存在多个关卡,而每个关卡之间也是会有进有出,当然除去利用levelstreaming技术通过程序控制动态载入载出的情况,因为那种情况互相之间不存在出生点的设置,基本都是在一个父关卡里无缝衔接的,所以本篇不谈此类关卡流的情形,只谈及针对不同关卡切换时如何实现出生点的设置(比如level01是家..._ue切换关卡后改变位置
如何查看Linux服务器中所有正在运行的进程服务?_colord.service-程序员宅基地
文章浏览阅读4.2k次。有许多方法和工具可以查看 Linux 中所有正在运行的服务。大多数管理员会在 System V(SysV)初始化系统中使用 service service-name status 或 /etc/init.d/service-name status,而在 systemd 初始化系统中使用 systemctl status service-name。查看服务进程:ps aux查看服务cpu利用:top查看服务对应端口:netstat -nlp以上命令可以清楚地显示该服务是否在服务器上运行,这也是每个 L_colord.service
YOLOV5之提高模型评估和测试方法(TTA、Ensemble、WBF)_yolo tta-程序员宅基地
文章浏览阅读5.3k次,点赞4次,收藏45次。本指南解释了如何在测试和推断改进的mAP和Recall过程中使用YOLOv5模型集成。2022年1月25日更新。集成建模是一个过程,通过使用许多不同的建模算法或使用不同的训练数据集,创建多个不同的模型来预测结果。然后,集合模型将每个基本模型的预测聚合起来,并对未见数据产生一次最终预测。使用集成模型的动机是为了减少预测的泛化误差。当采用集成方法时,只要基本模型是不同的和独立的,模型的预测误差就会减小。这种方法在预测中寻求群体的智慧。尽管集成模型在模型中有多个基本模型,但它作为单个模型进行操作和执行。1_yolo tta
数据结构——树的遍历(包含递归算法和非递归算法,先序遍历、中序遍历、后序遍历、层次遍历)_数据结构树的遍历-程序员宅基地
文章浏览阅读1.4k次。数据结构——树的遍历(包含递归算法和非递归算法,先序遍历、中序遍历、后序遍历、层次遍历)_数据结构树的遍历
浙江大学ZOJ 1005题 解题报告_jzoj1005-程序员宅基地
文章浏览阅读544次。第四篇解题报告,这道题十分十分十分的坑题目大意大概是说你有两个壶,分别告诉你壶的容量是多大,默认A壶要比B壶小然后给你一个目标值,你要用两个壶量出最终的目标值,你能够进行的操作一共有以下几种fill A fill B empty A empty B pour A B pour B A success fill A 把A装满 fill B 把B装满 empty A 清空A em_jzoj1005