第二章 Flink集成Iceberg的集成方式及基本SQL使用_iceberg0.1 hive3.12 flink1.14-程序员宅基地
技术标签: flink hive # Iceberg专题 sql
- 注意事项:一般都是用基于Flink的Hive Catalog,使用HMS存储表模型数据

1、集成方式
(1)下载jar包
iceberg-flink-runtime-1.14-1.0.0jar
flink-sql-connector-hive-2.3.6_2.12-1.11.2.jar
- 下载地址
https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/connectors/table/hive/overview/
(2)启动FlinkSQL
①StandLone模式启动
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./bin/sql-client.sh embedded -j <flink-runtime-directory>/iceberg-flink-runtime-xxx.jar shell
②Flink On Yarn模式启动
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
# 第一步 - 在Yarn集群上生成一个Standlone集群
./yarn-session.sh -s 2 -jm 2048 -tm 2048 -nm flinksql1 -d
# 第二步 - 指定yarn-session模式启动sql-client
./sql-client.sh embedded -s yarn-session -j ../lib/iceberg-flink-runtime-1.14-0.14.1.jar shell
2、基本使用
2.1、创建catalog
- 核心:可创建hive、hadoop、自定义等目录,创建模板如下
CREATE CATALOG <catalog_name> WITH (
'type'='iceberg',
`<config_key>`=`<config_value>`
);
type: 必须的iceberg。(必需的)catalog-type:hive或hadoop用于内置目录,或未设置用于使用 catalog-impl 的自定义目录实现。(可选的)catalog-impl:自定义目录实现的完全限定类名。如果未设置,则必须catalog-type设置。(可选的)property-version: 描述属性版本的版本号。如果属性格式发生变化,此属性可用于向后兼容。当前的属性版本是1. (可选的)cache-enabled: 是否启用目录缓存,默认值为true
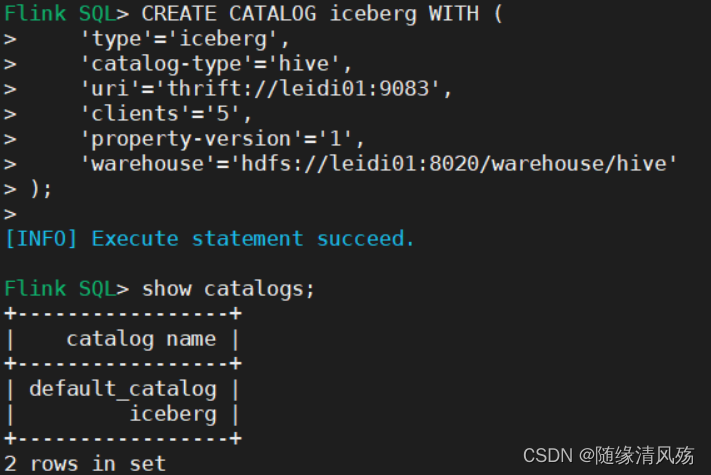
2.2、创建基于Hive的Catalog
(1)创建Catalog
CREATE CATALOG hive_iceberg WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://leidi01:9083',
'clients'='5',
'property-version'='1',
'hive-conf-dir'='/usr/hdp/3.1.0.0-78/hive/conf'
);
show catalogs;
uri: Hive 元存储的 thrift URI。(必需的)clients:Hive Metastore 客户端池大小,默认值为 2。(可选)warehouse:Hive 仓库位置,如果既不设置hive-conf-dir指定包含hive-site.xml配置文件的位置也不添加正确hive-site.xml的类路径,用户应指定此路径。hive-conf-dir``hive-site.xml:包含将用于提供自定义 Hive 配置值的配置文件的目录的路径。如果同时设置和创建冰山目录时,hive.metastore.warehouse.dirfrom/hive-site.xml(或来自类路径的 hive 配置文件)的值将被该值覆盖。warehouse``hive-conf-dir``warehouse
- 创建结果
(2)多客户端共享验证
- 客户端一对应库表
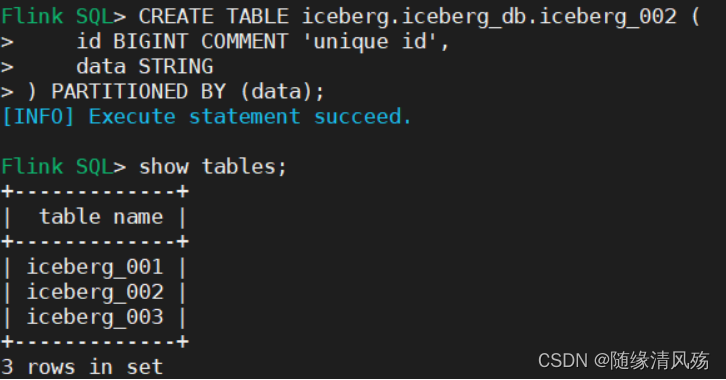
- 客户端二可见对应库表

2.3、创建基于Hadoop的calalog
(1)创建Catalog
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://leidi01:8020/warehouse/iceberg_catalog',
'property-version'='1'
);
warehouse:HDFS目录,存放元数据文件和数据文件。(必需的)
- 创建结果

2.4、其余创建方式
(1)创建自定义目录
- 核心:通过指定
catalog-impl属性来加载自定义的 Iceberg实现
REATE CATALOG my_catalog WITH (
'type'='iceberg',
'catalog-impl'='com.my.custom.CatalogImpl',
'my-additional-catalog-config'='my-value'
);
(2)通过SQL文件创建目录
-- define available catalogs
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://leidi01:9083',
'warehouse'='hdfs://leidi01:8020/user/flink/iceberg'
);
USE CATALOG hive_catalog;
- 注意事项:
sql-client-defaults.yaml在 flink 1.14 中删除了该文件,需要初始化才能有文件。
3、Flink SQL语句
3.1、DDL语句
(1)建库建表
use catalog iceberg;
CREATE DATABASE iceberg_db;
USE iceberg_db;
CREATE TABLE iceberg.iceberg_db.iceberg_001 (
id BIGINT COMMENT 'unique id',
data STRING
) WITH ('connector'='iceberg','write.format.default'='ORC');
(2)创建分区table
CREATE TABLE iceberg.iceberg_db.iceberg_003 (
id BIGINT COMMENT 'unique id',
data STRING
) PARTITIONED BY (data);
(3)更改table
--1、CREATE TABLE LIKE
CREATE TABLE `hive_catalog`.`default`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING
);
CREATE TABLE `hive_catalog`.`default`.`sample_like` LIKE `hive_catalog`.`default`.`sample`
--2、alter table
ALTER TABLE `hive_catalog`.`default`.`sample` SET ('write.format.default'='avro')
--3、ALTER TABLE .. RENAME TO
ALTER TABLE `hive_catalog`.`default`.`sample` RENAME TO `hive_catalog`.`default`.`new_sample`;
--4、DROP TABLE
DROP TABLE `hive_catalog`.`default`.`sample`;
3.2、DML语句
(1)插入数据
- insert into
INSERT INTO `iceberg`.`iceberg_db`.`iceberg_001` VALUES (1, 'a');
--分区表插入语句
INSERT INTO `iceberg`.`iceberg_db`.`iceberg_001`() values(2,'b')
- insert overwrite
INSERT OVERWRITE sample VALUES (1, 'a');
(2)查询数据
- 执行类型:流模式 VS 批模式
-- Execute the flink job in streaming mode for current session context
SET execution.runtime-mode = streaming;
-- Execute the flink job in batch mode for current session context
SET execution.runtime-mode = batch;
Ⅰ、批量读取:通过提交 flink批处理作业来检查 iceberg 表中的所有行
SET execution.runtime-mode = batch;
SELECT * FROM sample;
Ⅱ、流式读取:支持处理从历史快照 id 开始的 flink 流作业中的增量数据
- monitor-interval:连续监控新提交的数据文件的时间间隔(默认值:‘10s’)。
- start-snapshot-id:流作业开始的快照 id。
-- Submit the flink job in streaming mode for current session.
SET execution.runtime-mode = streaming;
-- Enable this switch because streaming read SQL will provide few job options in flink SQL hint options.
SET table.dynamic-table-options.enabled=true;
-- Read all the records from the iceberg current snapshot, and then read incremental data starting from that snapshot.
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
-- Read all incremental data starting from the snapshot-id '3821550127947089987' (records from this snapshot will be excluded).
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
(3)更新数据
-
前提:启动更新模式
-
模式一:启用
UPSERT模式作为表级属性write.upsert.enabled
CREATE TABLE `hive_catalog`.`default`.`sample` (
`id` INT UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with ('format-version'='2', 'write.upsert.enabled'='true');
- 模式二:在
write options中使用启用UPSERT模式upsert-enabled提供了比表级配置更大的灵活性。
INSERT INTO tableName /*+ OPTIONS('upsert-enabled'='true') */
...
4、Flink集成Iceberg的Hadoop Catalog实战案例
4.1、创建catalog的存储格式
(1)创建Catalog
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://leidi01:8020/warehouse/iceberg_catalog',
'property-version'='1'
);
- 创捷结果:
一个catalog + 一个默认的default数据库
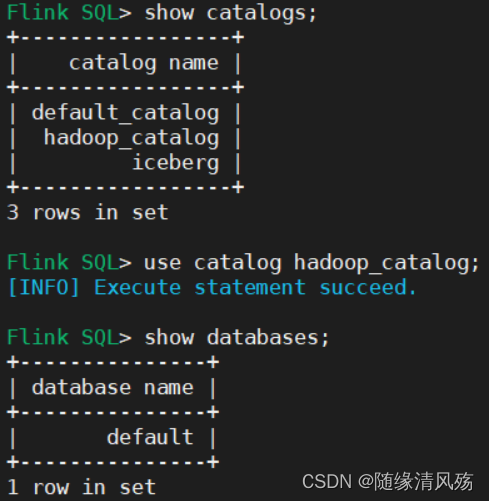
(2)查看HDFS结构目录

4.2、建库建表
(1)建库建表
create database hadoop_test;
use hadoop_test;
CREATE TABLE `hadoopdemo` (
> id BIGINT COMMENT 'unique id',
> data STRING
> );
- 创建结果
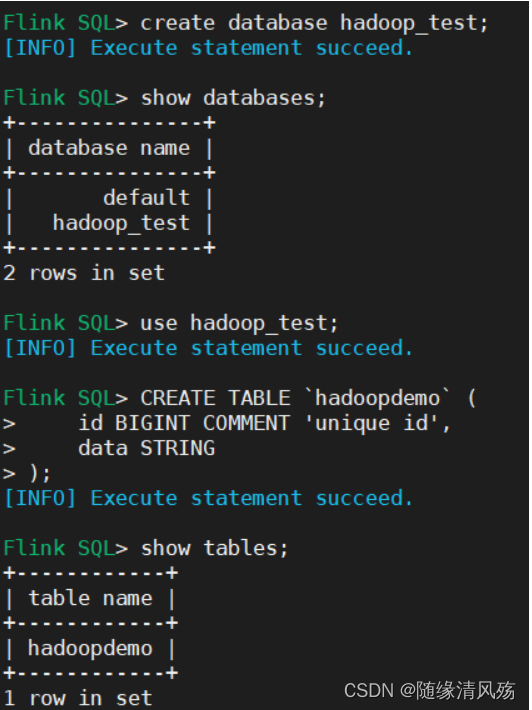
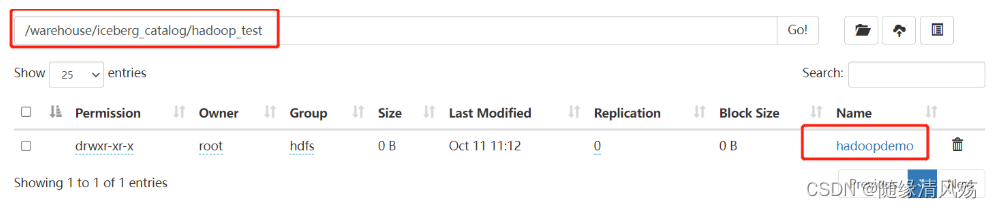
(2)查看对应HDFS目录
- 验证:
catalog为一级目录、数据库为二级目录、表为三级目录,建Catalog、建库、建表时没有flink任务生成。
4.3、插入数据
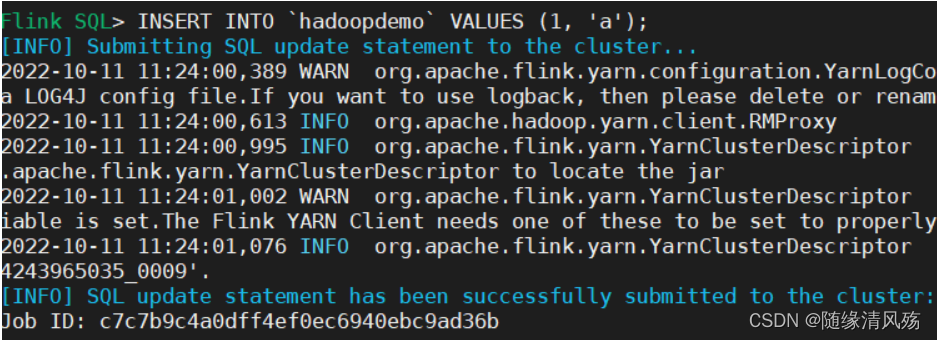
(1)插入数据
INSERT INTO `iceberg`.`iceberg_db`.`iceberg_001` VALUES (1, 'a');
- 运行结果
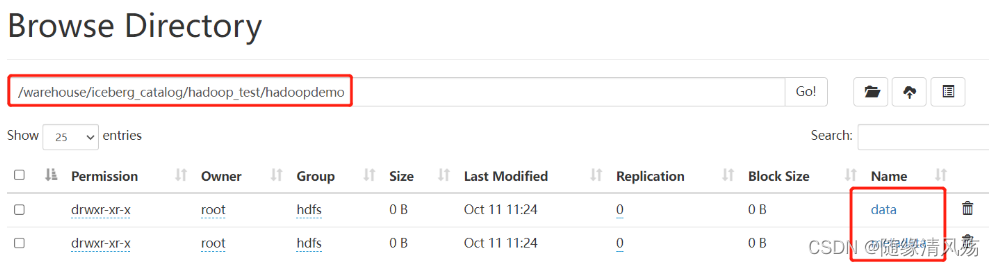
(2)HDFS目录
- 验证结果:分别生成data和metadata两个目录
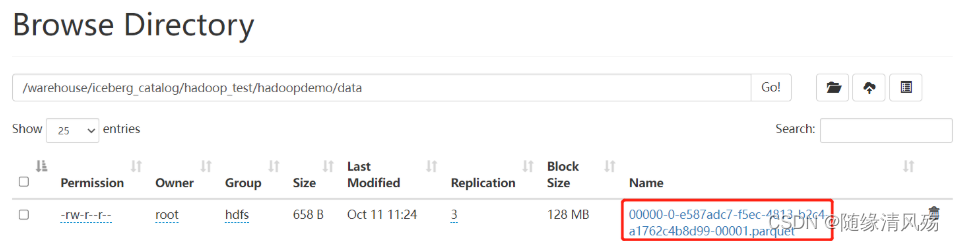
①data目录文件结构
- 存储:以parquent格式存储的数据文件
②metadata目录文件结构
- 存储:metadata目录存放元数据管理层的数据,表的元数据是不可修改的,并且始终向前迭代;当前的快照可以回退。
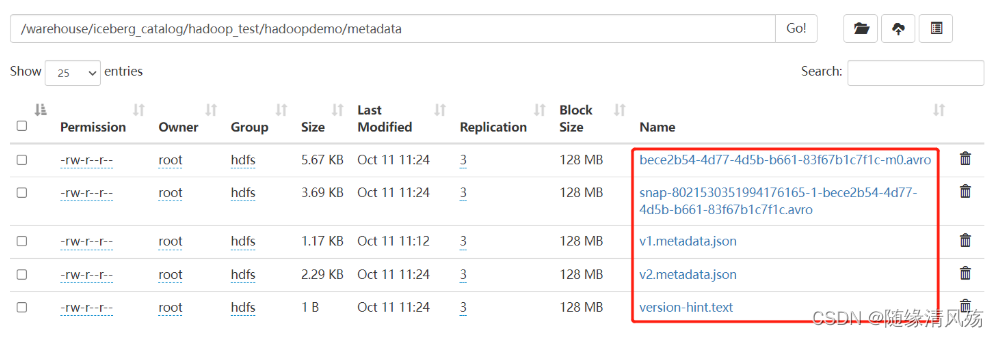
- 文件详述
| 文件名称 | 文件描述 | 备注 |
|---|---|---|
| version[number].metadata.json | 存储每个版本的数据更改项 | |
| snap-[snapshotID]-[attemptID]-[commitUUID].avro | 存储快照snapshot文件; | |
| [commitUUID]-[attemptID]-[manifestCount].avro | 清单文件,每次更新操作都会产生清单文件 | |
| version-hint.text |
5、Catalog设置相关
Hive metastore 中的表可以表示加载 Iceberg 表的三种不同方式,具体取决于表的iceberg.catalog属性:
5.1、不指定任何Catalog类型,直接创建表
如果在Hive中创建Iceberg格式表时不指定Iceberg.catalog属性,将使用HiveCatalog与 Hive 环境中配置的 Metastore 相对应的表加载该表iceberg.catalog,那么数据存储在对应的Hive Warehouse路径下。
-- 1、在Hive中创建Iceberg格式表
create table test_iceberg_tbl1(
id int,
name string,
age int)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
-- 2、在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到
add jar /usr/hdp/3.1.0.0-78/hive/lib/iceberg-hive-runtime-0.14.1.jar
add jar /usr/hdp/3.1.0.0-78/hive/lib/libfb303-0.9.3.jar
-- 3、向表中插入数据
insert into test_iceberg_tbl1 values(1,"sz",18,"beijing")
-- 4、查询表中数据
select * from test_iceberg_tbl1
- 查看表元数据存储信息

5.2、iceberg.catalog如果设置为Hive目录名称,将使用自定义目录加载该表
在Hive中创建Iceberg格式表时,如果指定了iceberg.catalog属性值,那么数据存储在指定的catalog名称对应配置的目录下。
-- 1、注册一个HiveCatalog叫another_hive
set iceberg.catalog.another_hive.type=hive;
SET iceberg.catalog.another_hive.uri=thrift://10.201.0.202:49153;
SET iceberg.catalog.another_hive.warehouse=s3a://faas-ethan/warehouse/;
SET hive.vectorized.execution.enabled=false;
-- 2、在Hive中创建iceberg格式表
create table test_iceberg_tbl2(
id int,
name string,
age int
)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 's3a://faas-ethan/warehouse/default/sample_hive_table_1'
tblproperties ('iceberg.catalog'='another_hive');
-- 3、插入数据,并查询
hive> insert into test_iceberg_tbl2 values (2,"ls",20,"20211212");
hive> select * from test_iceberg_tbl2;
- 查看本地HMS中表元数据存储信息:

- 查看远端HMS中表数据存储信息
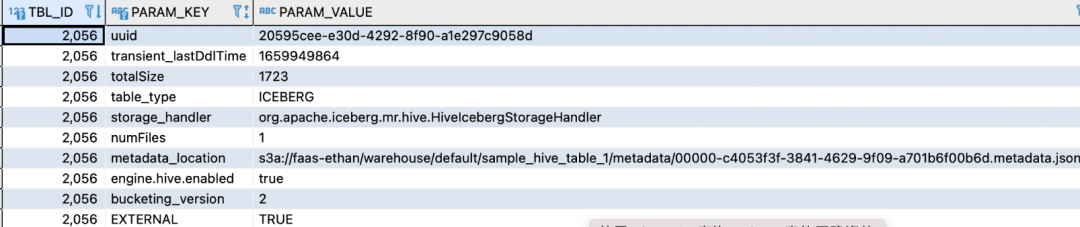
在Hive中创建Iceberg表,会在两边HMS分别存储一份元数据,只有这样,远端HMS中的Iceberg表才对本地HMS可见,所以必须保证远端HMS存在对应的数据库。
-
问题:如果只有远端HMS的Iceberg表,如何在本地HMS访问?
-
解决方案:通过如下创建external外表的形式在本地HMS生成元数据。
CREATE EXTERNAL TABLE default.sample_hive_table_1(
id bigint, name string
)
PARTITIONED BY(
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 's3a://faas-ethan/warehouse/default/sample_hive_table_1'
TBLPROPERTIES ('iceberg.catalog'='another_hive');
- 震惊:通过以下Hive SQL实现了跨HMS的联邦查询!!!
select * from default.sample_local_hive_table_1,sample_hive_table_1;
5.3、iceberg.catalog如果设置为location_based_table,则可以使用表的根位置直接加载表location_based_table
如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据。
CREATE TABLE test_iceberg_tbl4 (
id int,
name string,
age int,
dt string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://leidi01:8020/flinkiceberg/iceberg_db/flink_iceberg_tbl2'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');
--指定的location路径下必须是iceberg格式表数据,并且需要有元数据目录才可以。不能将其他数据映射到Hive iceberg格式表。
- 注意事项
由于Hive建表语句分区语法Partitioned by的限制,如果使用Hive创建Iceberg格式表,目前只能按照Hive语法来写,底层转换成Iceberg标识分区,这种情况下不能使用Iceberge的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表。
5.4、附加:注册Hadoop类型的Catalog
SET iceberg.catalog.hadoop_cat.type=hadoop;
SET iceberg.catalog.hadoop_cat.warehouse=s3a://faas-ethan/warehouse;
- 使用Hadoop Catalog建表
CREATE TABLE default.sample_hadoop_table_1(
id bigint, name string
) PARTITIONED BY (
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 's3a://faas-ethan/warehouse/default/sample_hadoop_table_1'
TBLPROPERTIES ('iceberg.catalog'='hadoop_cat');
- 查看HMS中表元数据存储信息

Hadoop Catalog相比Hive Catalog建立的表相比,少了metadata_location属性,同时元数据文件多了 version-hint.text。

智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数