SparkSQL之Join原理_spark sql join原理-程序员宅基地
技术标签: sparksql 自学大数据之路 Sort-Merge Join join原理 ShuffleHashJoin Hive&Spark SQL总结 Broadcast Hash
文章目录
前言:
写SQL的时候很多时候都有用到join语句,但是我们真的有仔细想过数据在join的过程到底是怎么样的吗?今天借这位大神的文章来交接下sql中join的原理。同样,如有冒犯,请联系。
Join背景介绍
Join是数据库查询永远绕不开的话题,传统查询SQL技术总体可以分为简单操作(过滤操作-where、排序操作-limit等),聚合操作-groupBy等以及Join操作等。其中Join操作是其中最复杂、代价最大的操作类型,也是OLAP场景中使用相对较多的操作。因此很有必要聊聊这个话题。
另外,从业务层面来讲,用户在数仓建设的时候也会涉及Join使用的问题。通常情况下,数据仓库中的表一般会分为”低层次表”和“高层次表”。
所谓”低层次表”,就是数据源导入数仓之后直接生成的表,单表列值较少,一般可以明显归为维度表或者事实表,表和表之间大多存在外健依赖,所以查询起来会遇到大量Join运算,查询效率相对比较差。而“高层次表”是在”低层次表”的基础上加工转换而来,通常做法是使用SQL语句将需要Join的表预先进行合并形成“宽表”,在宽表上的查询因为不需要执行大量Join因而效率相对较高,很明显,宽表缺点是数据会有大量冗余,而且生成相对比较滞后,查询结果可能并不及时。
因此,为了获得实效性更高的查询结果,大多数场景还是需要进行复杂的Join操作。Join操作之所以复杂,不仅仅因为通常情况下其时间空间复杂度高,更重要的是它有很多算法,在不同场景下需要选择特定算法才能获得最好的优化效果。关系型数据库也有关于Join的各种用法,姜承尧大神之前由浅入深地介绍过MySQL Join的各种算法以及调优方案(关注公众号InsideMySQL并回复join可以查看相关文章)。本文接下来会介绍SparkSQL所支持的几种常见的Join算法以及其适用场景。
Join常见分类以及基本实现机制
**当前SparkSQL支持三种Join算法-shuffle hash join、broadcast hash join以及sort merge join。**其中前两者归根到底都属于hash join,只不过在hash join之前需要先shuffle还是先broadcast。其实,这些算法并不是什么新鲜玩意,都是数据库几十年前的老古董了(参考),只不过换上了分布式的皮而已。不过话说回来,SparkSQL/Hive…等等,所有这些大数据技术哪一样不是来自于传统数据库技术,什么语法解析AST、基于规则优化(CRO)、基于代价优化(CBO)、列存,都来自于传统数据库。就拿shuffle hash join和broadcast hash join来说,hash join算法就来自于传统数据库,而shuffle和broadcast是大数据的皮,两者一结合就成了大数据的算法了。因此可以这样说,大数据的根就是传统数据库,传统数据库人才可以很快的转型到大数据。好吧,这些都是闲篇。
继续来看技术,既然hash join是’内核’,那就刨出来看看,看完把’皮’再分析一下。
Hash Join
先来看看这样一条SQL语句:
select * from order,item where item.id = order.i_id,
很简单一个Join节点,参与join的两张表是item和order,join key分别是item.id以及order.i_id。现在假设这个Join采用的是hash join算法,整个过程会经历三步:
1、 确定Build Table以及Probe Table:这个概念比较重要,Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table,大表作为Probe Table。此事例中item为Build Table,order为Probe Table。
2、 构建Hash Table:依次读取Build Table(item)的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket,生成hash table中的一条记录。数据缓存在内存中,如果内存放不下需要dump到外存。(这里是先利用join key hash到对应的bucket中,然后利用相同的hash规则去连接另一张表中相同的key数据)
3、探测:再依次扫描Probe Table(order)的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件(item.id = order.i_id),如果匹配成功就可以将两者join在一起。
总结:
确定小表为build table,大表为probe table;之后利用小表的join key构建hash table。扫描小表全表,不同的join key被分发到不同的bucket下,之后再依次扫描probe table,按照同样的hash规则,将数据hash到不同的bucket下,之后在bucket下扫描小表数据,若join条件一致,则可将两者join在一起。
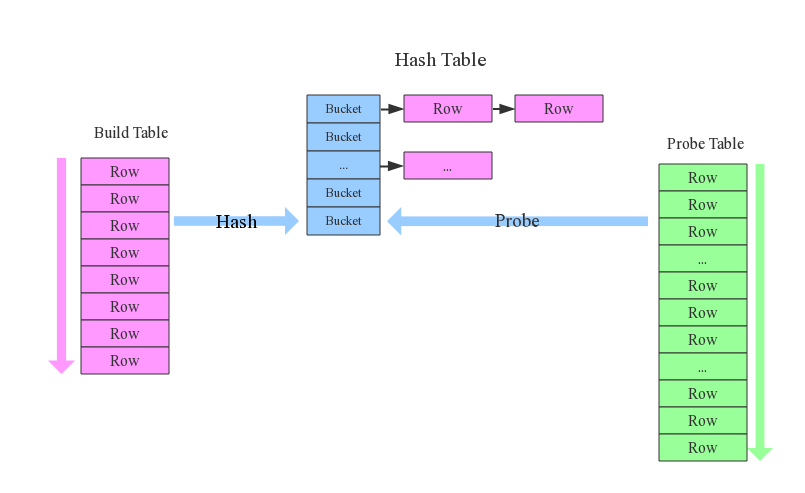
基本流程可以参考上图,这里有两个小问题需要关注:
1、 hash join性能如何?很显然,hash join基本都只扫描两表一次,可以认为o(a+b),较之最极端的笛卡尔集运算a*b,不知甩了多少条街。
2、为什么Build Table选择小表?道理很简单,因为构建的Hash Table最好能全部加载在内存,效率最高;这也决定了hash join算法只适合至少一个小表的join场景,对于两个大表的join场景并不适用;
上文说过,hash join是传统数据库中的单机join算法,在分布式环境下需要经过一定的分布式改造,说到底就是尽可能利用分布式计算资源进行并行化计算,提高总体效率。hash join分布式改造一般有两种经典方案:
1、broadcast hash join:将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行hash join。broadcast适用于小表很小,可以直接广播的场景。
2、shuffler hash join:
一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之,划分为很多小join,充分利用集群资源并行化。(相当于在map端将大小按照key进行拆分重新组织分区,然后根据key分发到reduce端进行分别大小表的处理,最终再将结果进行汇总。)
Broadcast Hash Join
如下图所示,broadcast hash join可以分为两步:
1、broadcast阶段:将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给driver,driver再统一分发给所有executor;要不就是基于bittorrete的p2p思路;
基于bittorrete的p2p思路可参考:
https://zhidao.baidu.com/question/9782615.html
https://baike.baidu.com/item/BitTorrent/142795?fr=aladdin
2、hash join阶段:在每个executor上执行单机版hash join,小表映射,大表试探;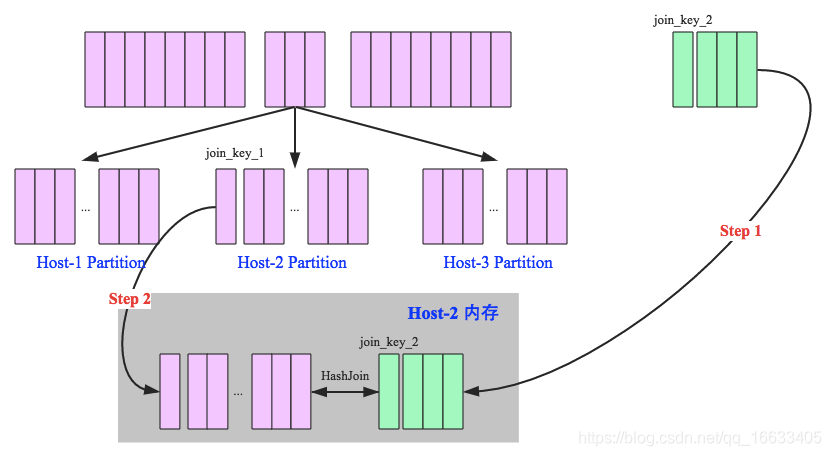
SparkSQL规定broadcast hash join执行的基本条件为被广播小表必须小于参数spark.sql.autoBroadcastJoinThreshold,默认为10M。
Shuffle Hash Join
在大数据条件下如果一张表很小,执行join操作最优的选择无疑是broadcast hash join,效率最高。但是一旦小表数据量增大,广播所需内存、带宽等资源必然就会太大,broadcast hash join就不再是最优方案。此时可以按照join key进行分区,根据key相同必然分区相同的原理,就可以将大表join分而治之,划分为很多小表的join,充分利用集群资源并行化。如下图所示,shuffle hash join也可以分为两步:
1、shuffle阶段:分别将两个表按照join key进行分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle
2、hash join阶段:每个分区节点上的数据单独执行单机hash join算法。(最后应该还要做一个union all的操作将之前处理的内容进行合并)
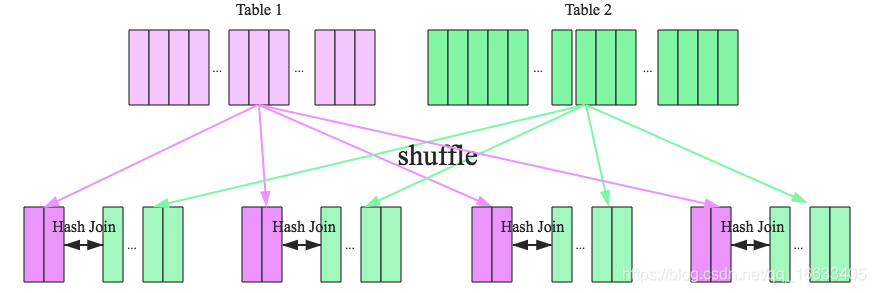
看到这里,**可以初步总结出来如果两张小表join可以直接使用单机版hash join;如果一张大表join一张极小表,可以选择broadcast hash join算法;**而如果是一张大表join一张小表,则可以选择shuffle hash join算法;那如果是两张大表进行join呢?
Sort-Merge Join
SparkSQL对两张大表join采用了全新的算法-sort-merge join,如下图所示,整个过程分为三个步骤:
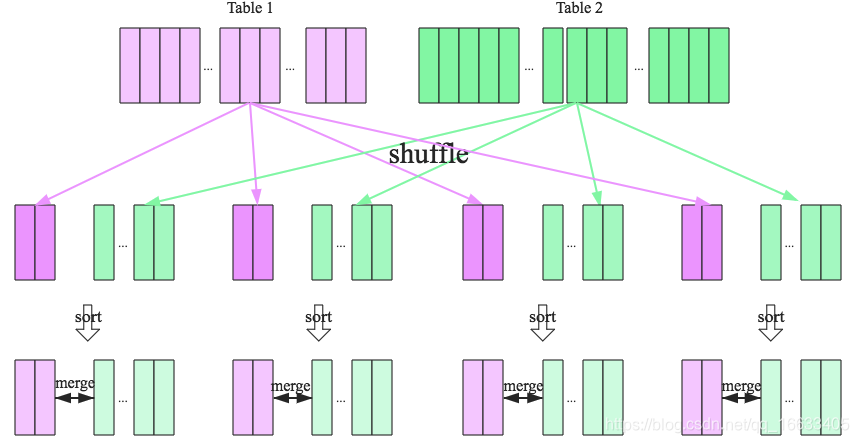
1、shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理
2、sort阶段:对单个分区节点的两表数据,分别进行排序
3、merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边(两张分区表进行join的过程中,会不断的比较索引的大小,一直以索较小的索引值遍历分区表数据。),见下图示意:
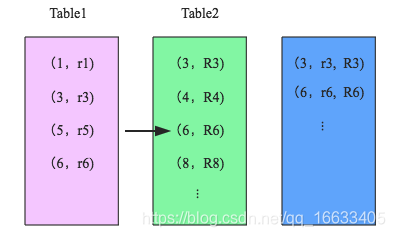
仔细分析的话会发现,sort-merge join的代价并不比shuffle hash join小,反而是多了很多。那为什么SparkSQL还会在两张大表的场景下选择使用sort-merge join算法呢?这和Spark的shuffle实现有关,目前spark的shuffle实现都适用sort-based shuffle算法,因此在经过shuffle之后partition数据都是按照key排序的。因此理论上可以认为数据经过shuffle之后是不需要sort的,可以直接merge(也就是说sort-merge-join实际只需要执行shuffle和merge阶段,而shuffle-hash-join需要执行shuffle和hash-join阶段。而对于大表join大表来说,merge阶段比hash-join阶段更优!
为什么更优:hash-join的复杂度O(a+b);而merge小于O(a+b)。a,b代表数组的长度)。
经过上文的分析,可以明确每种Join算法都有自己的适用场景,数据仓库设计时最好避免大表与大表的join查询,SparkSQL也可以根据内存资源、带宽资源适量将参数spark.sql.autoBroadcastJoinThreshold调大,让更多join实际执行为broadcast hash join。
总结
Join操作是传统数据库中的一个高级特性,尤其对于当前MySQL数据库更是如此,原因很简单,MySQL对Join的支持目前还比较有限,只支持Nested-Loop Join算法,因此在OLAP场景下MySQL是很难吃的消的,不要去用MySQL去跑任何OLAP业务,结果真的很难看。不过好消息是MySQL在新版本要开始支持Hash Join了,这样也许在将来也可以用MySQL来处理一些小规模的OLAP业务。
和MySQL相比,PostgreSQL、SQLServer、Oracle等这些数据库对Join支持更加全面一些,都支持Hash Join算法。由PostgreSQL作为内核构建的分布式系统Greenplum更是在数据仓库中占有一席之地,这和PostgreSQL对Join算法的支持其实有很大关系。
总体而言,传统数据库单机模式做Join的场景毕竟有限,也建议尽量减少使用Join。然而大数据领域就完全不同,Join是标配,OLAP业务根本无法离开表与表之间的关联,对Join的支持成熟度一定程度上决定了系统的性能,夸张点说,’得Join者得天下’。本文只是试图带大家真正走进Join的世界,了解常用的几种Join算法以及各自的适用场景。
智能推荐
FutureTask设置方法执行的超时时间_futuretask 超时-程序员宅基地
文章浏览阅读5k次。import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.FutureTask;import java.util.concurrent.TimeUnit;import java.util.concurrent.TimeoutEx..._futuretask 超时
Go语言基础之指针_go语言指针偏移-程序员宅基地
文章浏览阅读237次。一、Go语言中的指针不能进行偏移和运算,因此Go语言中的指针操作非常简单,我们只需要记住两个符号:&(取地址)和*(根据地址取值二、要搞明白Go语言中的指针需要先知道3个概念:指针地址、指针类型和指针取值。a := 10ptr := &ab := *ptr..._go语言指针偏移
为什么至少三个哨兵_一文带你了解Redis哨兵模式和高可用集群解析(万字长文)...-程序员宅基地
文章浏览阅读778次。前言 Redis 的 主从复制 模式下,一旦 主节点 由于故障不能提供服务,需要手动将 从节点 晋升为 主节点,同时还要通知 客户端 更新 主节点地址,这种故障处理方式从一定程度上是无法接受的。Redis 2.8 以后提供了 Redis Sentinel 哨兵机制 来解决这个问题。正文1. Redis高可用概述在 Web 服务器中,高可用 是指服务器可以 正常访问 的时间,衡量的标准是在 多长时间..._为什么高可用都是3个
Windows 11频繁更新,网友:越更越难用_win11 频繁更新 影响工作-程序员宅基地
文章浏览阅读1.1w次,点赞5次,收藏3次。Windows 11带来“倒退式”用户体验?_win11 频繁更新 影响工作
汇编除法运算-程序员宅基地
文章浏览阅读3.4w次,点赞10次,收藏45次。汇编的除法指令是div, 实际上相对高级语言的除法, 汇编指令的div是同时得到商和余数的, 结果分别保存在不同的寄存器.除数: 有8位和16位两种, 在一个寄存器或者内存单元中被除数: 如果除数是8位则被除数为16位, 默认放在AX中, 如果除数是16位, 则被除数为32位, 默认高位放在DX, 低位放在AX结果: 如果除数是8位, 那么执行div后, 余数存放在AH, 商存放在AL中; 如_汇编除法
数组的基本操作_cin>>l.elem[i];什么意思-程序员宅基地
文章浏览阅读153次。#include <iostream>#include <stdlib.h>using namespace std;struct SqList { int *elem; int length;};int InitList(SqList &L,int num){ L.elem = new int[num]; if (!L..._cin>>l.elem[i];什么意思
随便推点
微动探测原理及仪器介绍-程序员宅基地
文章浏览阅读1.3w次,点赞4次,收藏16次。微动探测原理及仪器介绍1、微动探测原理1.1 基本理论微动是由体波和面波组成,其中微动能量的百分之七十以上都来自于面波,并且它与体波的主要区别是在不均匀的介质中传播时面波会发生频散,而体波不存在频散现象,因此面波是微动探测的主要对象。对于介质的弹性参数(如横波速度、层薄厚、压缩波速度、密度等),面波传播速度相对比较敏感,特别是对横波的敏感性很高,因此可以利用面波来反演横波速度。在时间和空间上,微动信号具有以下特性:高度变化、无规律性、无重复性等,有研究发现全世界各处记录的微动信号都有相似_微动探测
C语言实现整数质因数分解_正整数分解质因数c语言-程序员宅基地
文章浏览阅读482次。在C语言中,我们可以编写程序来将给定的正整数分解为其质因数。在本文中,我将展示一个简单的C语言程序,用于分解正整数的质因数,并提供相应的源代码和解析。希望通过这个示例程序和解析,您能够理解如何在C语言中实现正整数的质因数分解。这是一个基本的算法,可以用于解决数论和因数分解相关的问题。在函数内部,我们使用一个循环来迭代从2到给定正整数的所有可能的因数。是否等于1,如果不等于1,则打印" × ",表示这个因数还没有完全分解。在这个例子中,我们将正整数84分解为其质因数:2、2、3和7。如果可以整除,我们将。_正整数分解质因数c语言
C++对象数组的正确创建方式-程序员宅基地
文章浏览阅读1.2w次,点赞7次,收藏16次。类类型数组和数据类型数组的创建方式相同。分为栈中创建和堆中创建_c++对象数组
解决:jupyter notebook内核总是死亡_内核死亡-程序员宅基地
文章浏览阅读2.4k次。其实就是不知道为什么电脑缺了tornado,或者就是tornado有问题。此时可以通过运行下面的代码进行解决(两个中任选一个就行,一个不行的话就试试另外一个)系统:Windows11。_内核死亡
requests模块-代理proxies使用_requests proxy-程序员宅基地
文章浏览阅读1.7k次。反向代理不为浏览器或客户端转发请求,而是为最终处理请求的服务器转发请求。客户端不知道服务器的真实地址,请求发送给反向代理服务器,然后由反向代理服务器转发给最终处理请求的服务器,例如nginx。_requests proxy
SparkStreaming实时计算的框架和执行过程_实时计算框架 spark streaming实施方案-程序员宅基地
文章浏览阅读860次。SparkStreaming 为每一个数据源启动对应的Reciver(接收器),接收器以任务的形式运行在应用的Executor(执行器)进程中,从输入源接收数据 ,把数据分组为小的批次(batch),保存为RDD。然后把数据复制到另一个Executor中备份,保障容错性。然后我们根据这框架来谈一谈SparkStreaming运行的具体流程:1、客户端提交作业后启动Driver,通过Driver来启..._实时计算框架 spark streaming实施方案