机器学习基础知识-程序员宅基地
机器学习(Machine Learning) 是让计算机能够自动地从某些数据中总结出规律,并得出某种预测模型,进而利用该模型对未知数据进行预测的方法。它是一种实现人工智能的方式,是一门交叉学科,综合了统计学、概率论、逼近论、凸分析、计算复杂性理论等。
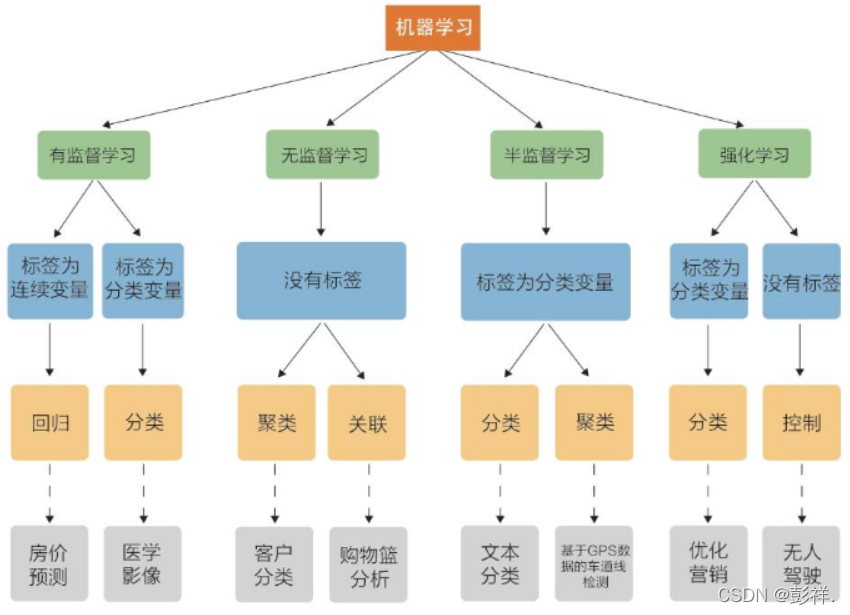
机器学习分类
目前,机器学习大致可以分为以下几类:
(1) 有监督学习(Supervised Learning) :当我们已经拥有–些数据及数据对应的类标时,就可以通过这些数据训练出一个模型,再利用这个模型去预测新数据的类标,这种情况称为有监督学习。有监督学习可分为回归问题和分类问题两大类。在回归问题中,我们预测的结果是连续值;而在分类问题中,我们预测的结果是离散值。常见的有监督学习算法包括线性回归、逻辑回归、K-近邻、朴素贝叶斯、决策树、随机森林、支持向量机等。
(2) 无监督学习(Unsupervised Learning):在无监督学习中是没有给定类标训练样本的,这就需要我们对给定的数据直接建模。常见的无监督学习算法包括K-means、EM算法等。
(3) 半监督学习(Semi-supervised Learn-ing):半监督学习介于有监督学习和无监督学习之间,给定的数据集既包括有类标的数据,也包括没有类标的数据,需要在工作量(例如数据的打标)和模型的准确率之间取一个平衡点。
(4)强化学习( Reinforcement Learning):从不懂到通过不断学习、总结规律,最终学会的过程便是强化学习。强化学习很依赖于学习的“周围环境”,强调如何基于“周围环境”而做出相应的动作。
机器学习的一般流程
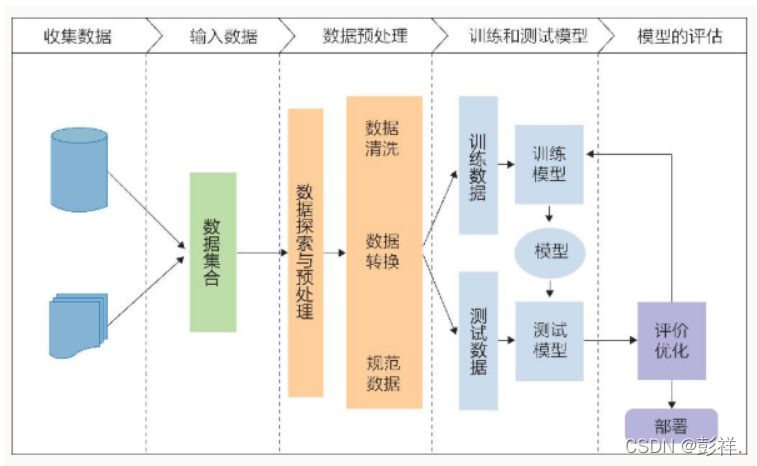
一个机器学习任务的成功与否往往在很大程度上取决于特征工程。简单来说,特征工程的任务是从原始数据中抽出最具代表性的特征,从而让模型能够更有效地学习这些数据。通常我们可以使用scikit-learn这个库来处理数据和提取特征,scikit-learn是机器学习中使用非常广泛的第三方模块,本身封装了很多常用的机器学习算法,同时还有很多数据处理和特征提取相关的方法。
数据预处理
根据数据类型的不同,数据预处理的方式和内容也不尽相同,这里简单介绍几种较常用的方式。**
(1)归一化
归一化指将不同变化范围内的值映射到一个固定的范围里,例如,常使用min-max等方法将数值归一化到[0,1]的区间内(有些时候也会归一化到[-1,1]的区间内)。归一化的作用包括无量纲化一、加快模型的收敛速度,以及避免小数值的特征被忽略等。
(2)标准化
标准化指在不改变数据原分布的前提下,将数据按比例缩放,使之落入一个限定的区间,让数据之间具有可比性。需要注意的是,归一化和标准化各有其适用的情况,例如在涉及距离度量或者数据符合正态分布的时候,应该使用标准化而不是归一化。常用的标准化方法有z- score等。
(3)离散化
离散化指把连续的数值型数据进行分段,可采用相等步长或相等频率等方法对落在每一个分段内的数值型数据赋予一个新的统一的符号或数值。离散化是为了适应模型的需要,有助于消除异常数据,提高算法的效率。
(4)二值化
二值化指将数值型数据转换为0和1两个值,例如通过设定一个阈值,当特征的值大于该阈值时转换为1,当特征的值小于或等于该阈值时转换为0。二值化的目的在于简化数据,有些时候还可以消除数据(例如图像数据)中的“杂音”。
特征工程
特征工程的目的是把原始的数据转换为模型可用的数据,主要包括三个子问题:特征构造、特征提取和特征选择。
特征构造一般是在原有特征的基础上做“组合”操作,例如,对原有特征进行四则运算,从而得到新的特征。
特征提取指使用映射或变换的方法将维数较高的原始特征转换为维数较低的新的特征。如主成分分析
特征选择即从原始的特征中挑选出一些具有代表性、使模型效果更好的特征。
其中,特征提取和特征选择最为常用。
模型性能判别与选择
基础概念
在分类任务中,通常把错分的样本数占样本总数的比例称为错误率(error rate)。比如m个样本有a个预测错了,错误率就是 E = a/m;与错误率相对的 1 - a/m 称为精度(accuracy),或者说正确率,数值上 精度 = 1 - 错误率。
更一般地,我们通常会把学习器的实际预测输出与样本的真实输出之间的差异称为误差(error)。学习器在训练集上的误差称为训练误差(training error)或者经验误差(empirical error)。而在新样本上的误差则称为泛化误差(generalization error)或者测试误差(test error;)。显然,我们希望得到泛化误差小的学习器。所以我们希望模型的泛化误差尽可能小,但现实是,我们无法知道新样本是怎样的,所以只能尽可能地利用训练数据来最小化经验误差。
L loss function 损失函数



过(欠)拟合
对于经验误差很小,而在新样本中泛化误差很大的情况,多是由于在测试集中将训练样本中的一些本身特征看作为整个样本空间的特征,从而导致泛化能力下降。而欠拟合则是相反。
有多种因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由于学习能力低下而造成的。
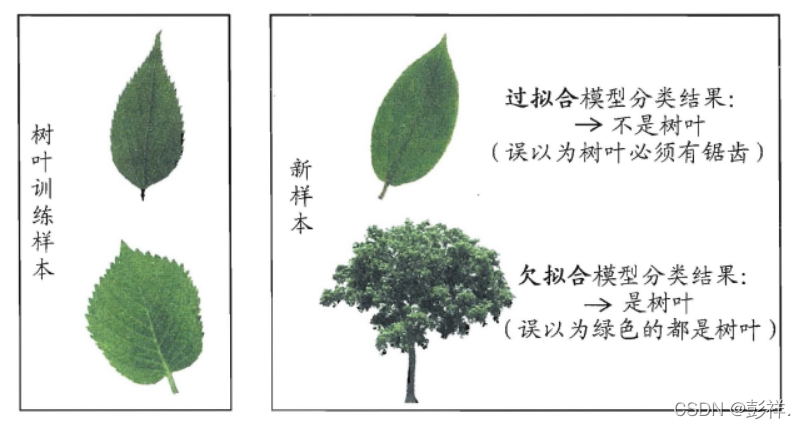
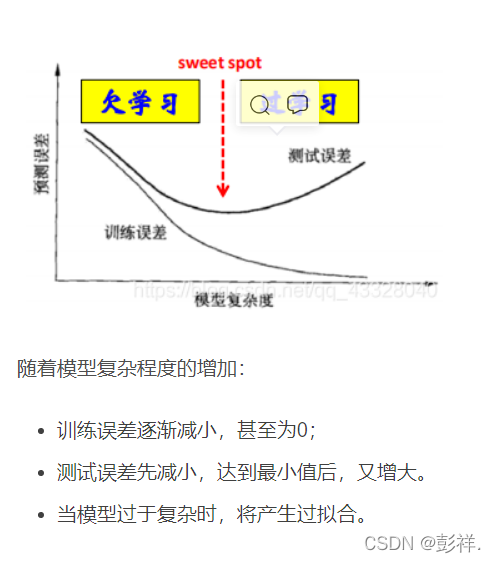
欠拟合比较容易克服,只要适当地增加模型复杂度(比方说增加神经网络的层数或者训练轮数,扩展决策树学习中的分支)就好。但过拟合是无法彻底避免的,我们所能做的只是缓解,或者说减小其风险(比如减少模型复杂度/增加训练数据),这也是机器学习发展中的一个关键阻碍。
这样,在学习时就要防止过拟合,进行最优的模型选择,即选择复杂度相当的模型,以达到使测试误差最小的学习目的。下面介绍几种常用的模型选择方法。
留出法,正则化,交叉验证,自助法
模型性能评价
错误率与精度
查准率,查全率,F1,P-R曲线


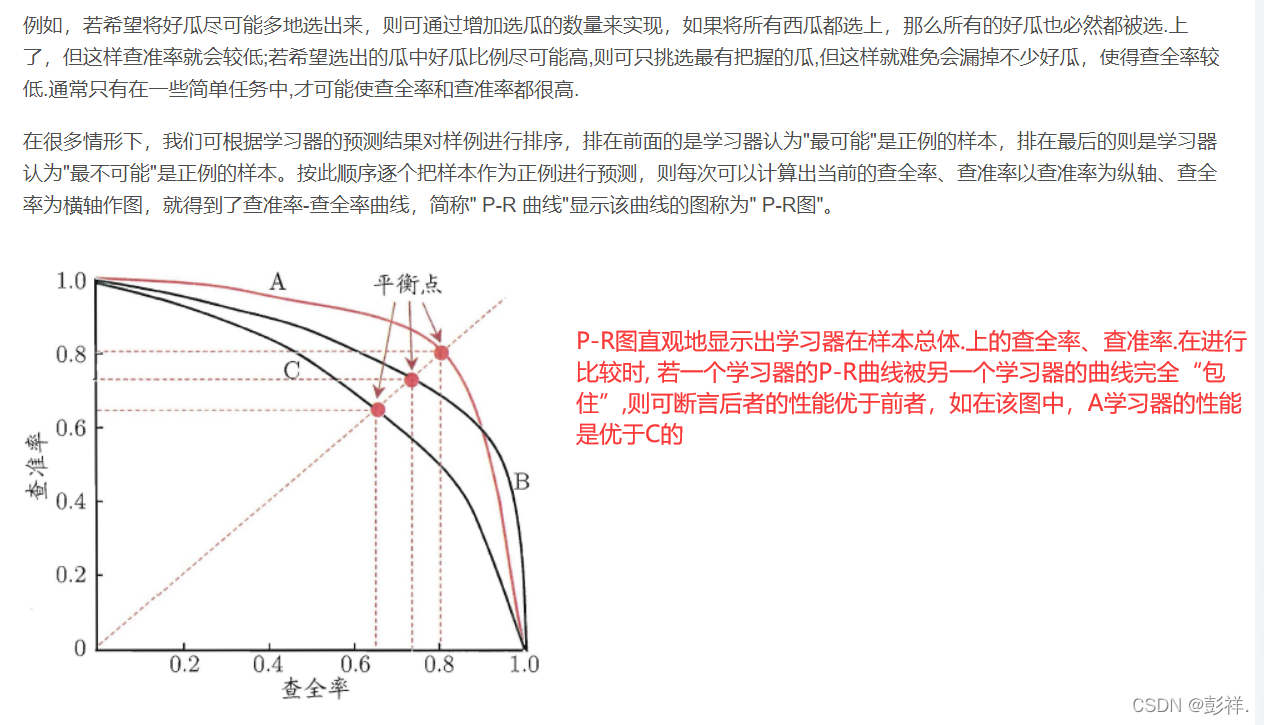
ROC曲线
在不同的应用任务中,我们可根据任务需求来采用不同的截断点,例如若我们更重视“查准率”,则可选择排序中靠前的位置进行截断;若更重视“查全率",则可选择靠后的位置进行截断.因此,排序本身的质量好坏,体现了综合考虑学习器在不同任务下的“期望泛化性能”的好坏,或者说,“一般情况下”泛化性能的好坏. ROC曲线则是从这个角度出发来研究学习器泛化性能的有力工具.
ROC曲线的纵轴是“真正例率”(True Positive Rate,简称TPR),横轴是“假正例率”(False PositiveRate,简称FPR)
智能推荐
解决win10/win8/8.1 64位操作系统MT65xx preloader线刷驱动无法安装_mt65驱动-程序员宅基地
文章浏览阅读1.3w次。转载自 http://www.miui.com/thread-2003672-1-1.html 当手机在刷错包或者误修改删除系统文件后会出现无法开机或者是移动定制(联通合约机)版想刷标准版,这时就会用到线刷,首先就是安装线刷驱动。 在XP和win7上线刷是比较方便的,用那个驱动自动安装版,直接就可以安装好,完成线刷。不过现在也有好多机友换成了win8/8.1系统,再使用这个_mt65驱动
SonarQube简介及客户端集成_sonar的客户端区别-程序员宅基地
文章浏览阅读1k次。SonarQube是一个代码质量管理平台,可以扫描监测代码并给出质量评价及修改建议,通过插件机制支持25+中开发语言,可以很容易与gradle\maven\jenkins等工具进行集成,是非常流行的代码质量管控平台。通CheckStyle、findbugs等工具定位不同,SonarQube定位于平台,有完善的管理机制及强大的管理页面,并通过插件支持checkstyle及findbugs等既有的流..._sonar的客户端区别
元学习系列(六):神经图灵机详细分析_神经图灵机方法改进-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏27次。神经图灵机是LSTM、GRU的改进版本,本质上依然包含一个外部记忆结构、可对记忆进行读写操作,主要针对读写操作进行了改进,或者说提出了一种新的读写操作思路。神经图灵机之所以叫这个名字是因为它通过深度学习模型模拟了图灵机,但是我觉得如果先去介绍图灵机的概念,就会搞得很混乱,所以这里主要从神经图灵机改进了LSTM的哪些方面入手进行讲解,同时,由于模型的结构比较复杂,为了让思路更清晰,这次也会分开几..._神经图灵机方法改进
【机器学习】机器学习模型迭代方法(Python)-程序员宅基地
文章浏览阅读2.8k次。一、模型迭代方法机器学习模型在实际应用的场景,通常要根据新增的数据下进行模型的迭代,常见的模型迭代方法有以下几种:1、全量数据重新训练一个模型,直接合并历史训练数据与新增的数据,模型直接离线学习全量数据,学习得到一个全新的模型。优缺点:这也是实际最为常见的模型迭代方式,通常模型效果也是最好的,但这样模型迭代比较耗时,资源耗费比较多,实时性较差,特别是在大数据场景更为困难;2、模型融合的方法,将旧模..._模型迭代
base64图片打成Zip包上传,以及服务端解压的简单实现_base64可以装换zip吗-程序员宅基地
文章浏览阅读2.3k次。1、前言上传图片一般采用异步上传的方式,但是异步上传带来不好的地方,就如果图片有改变或者删除,图片服务器端就会造成浪费。所以有时候就会和参数同步提交。笔者喜欢base64图片一起上传,但是图片过多时就会出现数据丢失等异常。因为tomcat的post请求默认是2M的长度限制。2、解决办法有两种:① 修改tomcat的servel.xml的配置文件,设置 maxPostSize=..._base64可以装换zip吗
Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字-程序员宅基地
文章浏览阅读1k次,点赞17次,收藏22次。Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字
随便推点
ESXi 快速复制虚拟机脚本_exsi6.7快速克隆centos-程序员宅基地
文章浏览阅读1.3k次。拷贝虚拟机文件时间比较长,因为虚拟机 flat 文件很大,所以要等。脚本完成后,以复制虚拟机文件夹。将以下脚本内容写入文件。_exsi6.7快速克隆centos
好友推荐—基于关系的java和spark代码实现_本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。-程序员宅基地
文章浏览阅读2k次。本文主要实现基于二度好友的推荐。数学公式参考于:http://blog.csdn.net/qq_14950717/article/details/52197565测试数据为自己随手画的关系图把图片整理成文本信息如下:a b c d e f yb c a f gc a b dd c a e h q re f h d af e a b gg h f bh e g i di j m n ..._本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。
南京大学-高级程序设计复习总结_南京大学高级程序设计-程序员宅基地
文章浏览阅读367次。南京大学高级程序设计期末复习总结,c++面向对象编程_南京大学高级程序设计
4.朴素贝叶斯分类器实现-matlab_朴素贝叶斯 matlab训练和测试输出-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏12次。实现朴素贝叶斯分类器,并且根据李航《统计机器学习》第四章提供的数据训练与测试,结果与书中一致分别实现了朴素贝叶斯以及带有laplace平滑的朴素贝叶斯%书中例题实现朴素贝叶斯%特征1的取值集合A1=[1;2;3];%特征2的取值集合A2=[4;5;6];%S M LAValues={A1;A2};%Y的取值集合YValue=[-1;1];%数据集和T=[ 1,4,-1;..._朴素贝叶斯 matlab训练和测试输出
Markdown 文本换行_markdowntext 换行-程序员宅基地
文章浏览阅读1.6k次。Markdown 文本换行_markdowntext 换行
错误:0xC0000022 在运行 Microsoft Windows 非核心版本的计算机上,运行”slui.exe 0x2a 0xC0000022″以显示错误文本_错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行-程序员宅基地
文章浏览阅读6.7w次,点赞2次,收藏37次。win10 2016长期服务版激活错误解决方法:打开“注册表编辑器”;(Windows + R然后输入Regedit)修改SkipRearm的值为1:(在HKEY_LOCAL_MACHINE–》SOFTWARE–》Microsoft–》Windows NT–》CurrentVersion–》SoftwareProtectionPlatform里面,将SkipRearm的值修改为1)重..._错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行“slui.ex