“知识图谱+”系列:知识图谱+强化学习_图强化学习-程序员宅基地
技术标签: 人工智能遇上知识图谱 机器学习 人工智能 自然语言处理 强化学习 知识图谱
泽宇个人一直认为强化学习是建模动态系统最好的方法之一,通过与环境的不断交互,在动作选择和状态更新的动态过程中逐渐达到优化目标。因此,本期泽宇将从知识图谱结合强化学习的角度介绍几个不同的研究方向的内容,包括知识图谱推理、自动驾驶、时序推理、对话式问答系统和推荐系统。
1 知识图谱推理
DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning. EMNLP 2017.
Wenhan Xiong, Thien Hoang, and William Yang Wang
核心贡献:这篇论文是最早将强化学习应用于知识图谱推理的研究。由于基于路径的知识图谱推理需要在知识图谱中找到能够从头实体走到尾实体的一条多跳路径,这个路径搜索的过程就可以看成是一个马尔可夫决策过程,因此很自然的可以想到用强化学习来建模这个马尔可夫决策过程。这篇论文通过巧妙的设计了一个奖励函数,保证在知识图谱推理中能够同时考虑精度、多样性和效率。
这个任务简单来说可以看成是一个简单的问答系统,给定一个实体和关系,智能体在不断交互中从知识图谱中找到一条连通给定实体和答案实体的路径,且这条路径能够很好的表示给定的关系。
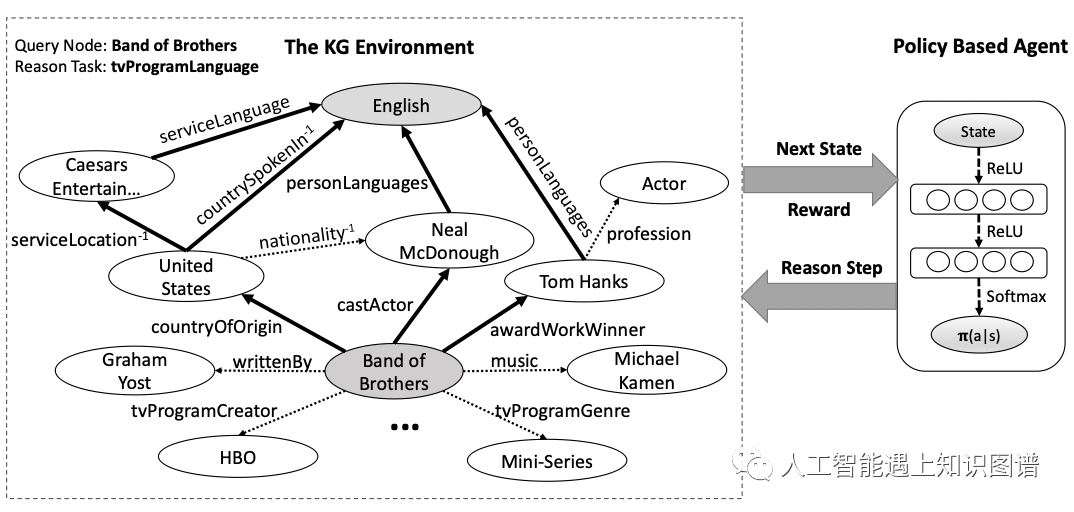
了解强化学习基本概念的朋友应该知道,强化学习具体的方法主要有深度Q网络(DQN)和基于策略梯度的方法(Policy-based),其中基于策略梯度的方法更满足知识图谱路径搜索的任务要求,而基于策略梯度的方法最核心的几个组成部分包括:环境、动作(Actions)、状态(States)、奖励(Rewards)、策略网络(Policy Network)。接下来,针对这篇论文分别介绍这几个部分对应的内容。
环境:整个知识图谱就是强化学习任务中的环境,需要从知识图谱中找到满足目标的路径。
动作:所有的关系组成动作空间,每一步智能体选择“下一步走向何方”其实就是在选择当前实体关联的哪一个关系。
状态:智能体的状态就是智能体当前在知识图谱中所处的位置,状态向量包括当前实体embedding和当前实体与目标实体embedding的距离。
奖励:奖励可以评价当前所处状态的质量,这篇论文中用三种评价指标来定义奖励,包括:
-
全局精度:站在全局的角度来看,如果智能体走到这一步之后的路径能否到达目标实体。
-
路径效率:通过观察发现短路径比长路径更加可靠,因此可以用路径的长度来衡量推理效率。
-
路径多样性:为了让每一次训练选择的路径能够更加多样,而不是重复选择到之前已经走过的路径,定义当前路径与已存在路径之间的多样性。
策略网络:这里策略网络的设计就是一个两层的全连接网络,将当前状态向量映射为可能动作的分布概率。
训练过程中,为了加速强化学习的收敛,类似于AlphaGo,这篇论文也采用了广度优先搜索学习有监督的策略,然后用蒙特卡洛策略梯度更新参数,更多的训练细节详见论文。
之后也有一些研究在这篇论文的基础上进行了改进,总体框架都是一样的,知识加入了一些训练策略,例如action drupout和reward shaping,可以增加动作选择的多样性和提供更有效的奖励函数。此外,还有一些在强化学习的基础上引入逻辑规则来引导路径的搜索。
2 自动驾驶
Reinforcement Learning for Autonomous Driving with Latent State Inference and Spatial-Temporal Relationships. ICRA 2021.
Xiaobai Ma, Jiachen Li, Mykel J. Kochenderfer, David Isele, Kikuo Fujimura
核心贡献:这篇论文发表在机器人顶会ICRA,研究了在自动驾驶领域,驾驶员会受到周围车辆的影响的现实情况,通过对驾驶员隐状态中编码先验知识来优化强化学习,并结合周围车辆构建知识图谱进一步采用基于图神经网络的图表示学习方法来更新驾驶员的隐状态,在自动导航任务中加速强化学习的过程。
对应强化学习过程中的几个概念,本研究分别定义:
状态:这里特别的是定义了一个联合状态,包括进入或离开环境的每个车辆自身的位置和速度,及每个车辆邻域车辆信息的表示。
观测值:每个车辆自身状态叠加一个高斯噪声组成观测值。
动作:控制车辆自身速度的选择空间。
转移:车辆自身是通过一个PD控制器跟踪期望的速度来实现轨迹控制。
奖励:奖励函数由任务完成是否完成的打分和速度组成,目标是在尽量快的速度下完成车辆右转。
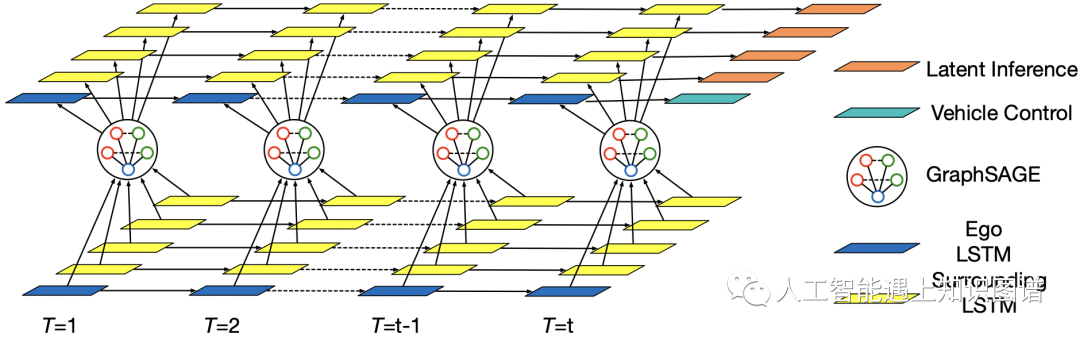
这里特别的是,论文中将建模时间序列模型的LSTM和图表示学习中的GraphSAGE结合,实现对于动态车辆及周围邻域车辆状态的表示学习,顶层LSTM网络的输出就是动作分布,这个时空GNN网络结构在整个模型的策略网络和隐式推理中都会用到。
3 时序推理
Search from History and Reason for Future: Two-stage Reasoning on Temporal KnowledgeGraphs. ACL 2021.
Zixuan Li, Xiaolong Jin, Saiping Guan, Wei Li, Jiafeng Guo, Yuanzhuo Wang, Xueqi Cheng
核心贡献:这篇论文研究了动态知识图谱的时序推理。通过设计了包含线索搜索和时序推理的两阶段模式,预测未来将发生的事件。在线索搜索阶段,通过强化学习来训练一个集束搜索策略,以从历史事件中推断多条线索。在时序推理阶段,使用基于GCN的时序模型从线索中推理答案。
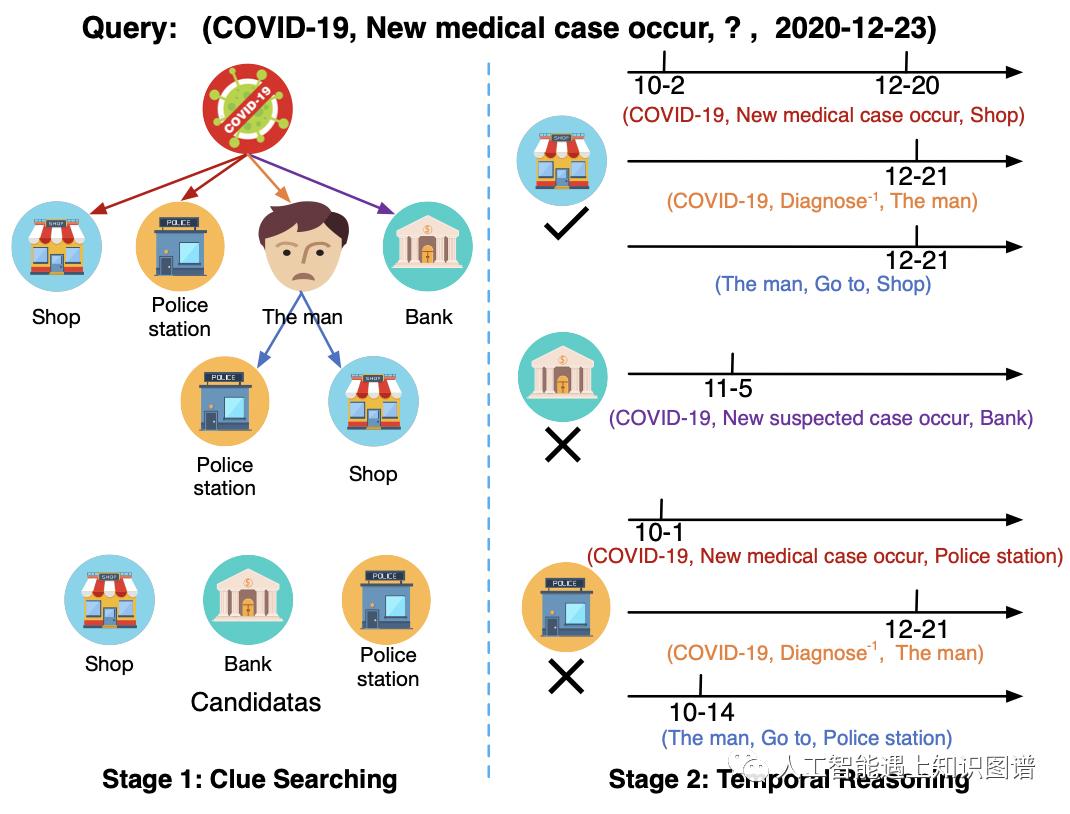
这里我们重点讨论基于强化学习的线索搜索部分,对应强化学习过程中的几个概念,本研究分别定义:
环境:整个知识图谱就是强化学习任务中的环境。
状态:智能体的状态是一个五元组,其中包含给定需要查询的头实体、关系、时间点和智能体当前到达的实体和时间点。
时间约束的动作:与静态知识图谱不同,动态知识图谱中的时间维度会极大的增加动作空间的规模,并且人类记忆集中在最近的一段时间内。因此,这里动作定义为在智能体当前到达的实体,一段时间区间内的能够到达的(实体,关系,时间点)组成的三元组。
转移:智能体通过动作选择从当前状态更新到新的实体。
奖励:奖励由评价是否达到正确的尾实体的二值奖励和在阶段二中得到的实值奖励组成。
策略网络包括:
-
编码线索路径的LSTM网络。
-
计算动作分布的多层感知器。
论文中介绍的随机集束搜索策略和时序推理部分可以详见论文。
 4 对话式问答系统
4 对话式问答系统
Reinforcement Learning from Reformulations in Conversational Question Answering over Knowledge Graphs. SIGIR 2021
Magdalena Kaiser, Rishiraj Saha Roy, Gerhard Weikum
核心贡献:类似于多轮对话系统,这篇论文研究了对话式问答。利用强化学习从提问和复述的对话流中学习有效信息以从知识图谱中找到正确的答案。论文中设计的模型通过将回答的过程建模为在知识图谱中多个智能体并行游走,如何游走通过策略网络选择的动作决定,策略网络的输入包括对话上下文和知识图谱中的路径。
对应强化学习过程中的几个概念,本研究分别定义:
状态:第t轮的问句表示+之前对话的一个子集作为上下文问句+上下文实体中的其中一个作为智能体出发的起始点。
动作:从当前实体出发的所有路径,每条路径到达的end point实体都是候选答案。
转移:转移函数将状态更新为智能体到达的end point实体。
奖励:奖励函数为二值奖励,如果用户下一次说的是一个新的问题,说明模型给出的回答解决了用户的问题给正向奖励,如果用户下一次说的是相近意图的复述内容,说明没有回答用户的问题给负向奖励。
这篇论文中采用策略梯度训练强化学习模型,由于这个模型中涉及多智能体,动作选择是从每个智能体选择top-k个动作。多个智能体都可能得到候选答案,按照被智能体选择为候选答案的次数对实体进行排序,排名最高的实体为预测的答案。
5 推荐系统
Interactive Recommender System via Knowledge Graph-enhanced Reinforcement Learning. Arxiv 2021.
Sijin Zhou, Xinyi Dai, Haokun Chen, Weinan Zhang, Kan Ren, Ruiming Tang, Xiuqiang He, Yong Yu
核心贡献:这篇论文研究了能够和用户交互的推荐系统。为了处理用户的兴趣变化和逐渐积累的项目,将交互式推荐看成一个决策制定和长期规划的马尔科夫决策问题,就可以将强化学习引入交互式推荐系统。然而强化学习的训练效率较低,为了解决这一问题,利用知识图谱中项目相关的先验知识来指导候选推荐项的选择。
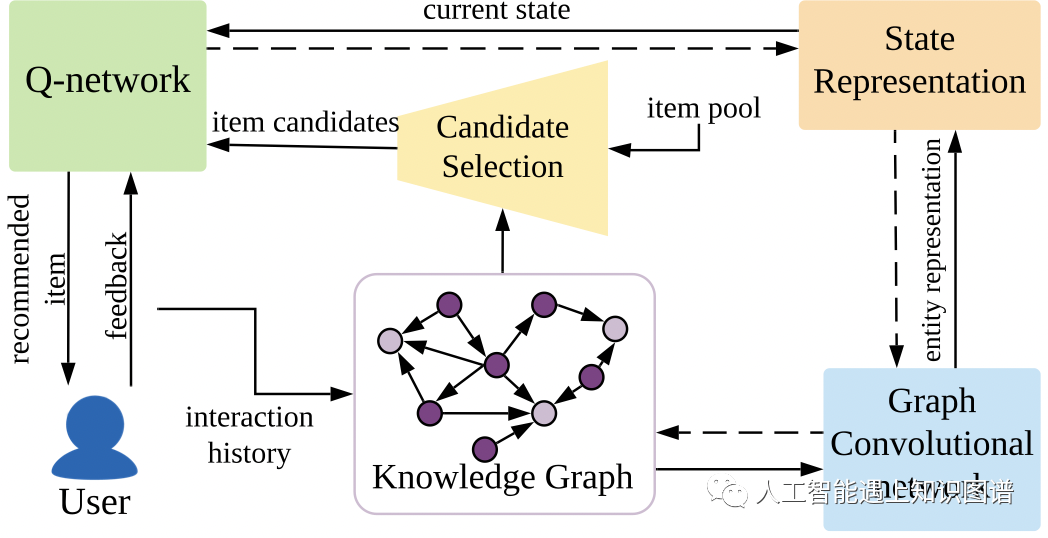
对应强化学习过程中的几个概念,本研究分别定义:
状态:当前项目及其多跳邻域组成的子图。
动作:接下来选择推荐的项目。
转移:转移函数将状态更新为智能体到达的end point实体。
奖励:对于系统传递给用户的推荐项目,根据用户的反馈是“点击”,“购买”还是“跳过”来给定奖励。
由于在强化学习中,状态的表示是非常关键的,这篇论文中提出一个知识图谱增强的状态表示机制。其中,将已经点击的项目转换为embedding表示,并利用GCN对项目在知识图谱中的邻域信息进行聚合更新项目的embedding,得到邻域表示。
进一步,为了编码对用户的观测信息,采用GRU聚合用户的历史行为并蒸馏用户的状态表示,其中得到的当前用户状态的表示可以输入Q网络中。
此外,论文中提出了的一个基于邻域的候选选择机制,从已点击项目在知识图谱中多跳邻域中选择候选推荐项目,可以利用知识图谱提供的语义相关性有效缩小动作空间的大小,便于提高模型的计算效率。
这篇论文采用DQN来学习最优策略,训练整个强化学习模型。
从以上几个不同领域的研究内容可以发现,只要是需要和环境交互的动态系统,都有可能通过强化学习的方法来进行建模,知识图谱不仅可以是强化学习的对象例如知识图谱推理,也可能为强化学习的状态和动作选择提供语义信息得到更好的表示来优化强化学习的过程。
以上就是本期所有对于知识图谱+强化学习的学习分享了。所有内容都是泽宇经过调研和学习理解总结的,之后还会陆续分享知识图谱+各类方向的技术介绍,如果大家有对某个方向感兴趣的可以联系泽宇,敬请关注啊。
往期精选:
如果对文章感兴趣欢迎关注知乎专栏“人工智能遇上知识图谱“,也可以扫描下方二维码关注同名微信公众号“人工智能遇上知识图谱”,让我们一起学习并交流讨论人工智能与知识图谱技术。

智能推荐
【SVM回归预测】基于鹈鹕算法优化卷积神经网络结合支持向量机实现POA-CNN-SVM实现数据回归预测附matlab代码-程序员宅基地
文章浏览阅读903次,点赞19次,收藏20次。本文提出了一种基于鹈鹕算法优化卷积神经网络结合支持向量机(POA-CNN-SVM)的数据回归预测方法。该方法首先利用鹈鹕算法优化卷积神经网络的参数,然后将优化后的卷积神经网络与支持向量机相结合,构建POA-CNN-SVM回归模型。最后,利用POA-CNN-SVM回归模型对数据进行回归预测。实验结果表明,该方法能够有效提高数据回归预测的准确性。
YOLO_V2的region_layer LOSS损失计算源码解读_yolov2–region层源码-程序员宅基地
文章浏览阅读3.1k次,点赞3次,收藏5次。region_layer.cbox get_region_box(float *x, float *biases, int n, int index, int i, int j, int w, int h, int stride){ box b; b.x = (i + x[index + 0*stride]) / w; b.y = (j + x[index + 1*st_yolov2–region层源码
GPRC 和RPC 有什么区别?GPRC和RPC的区别是什么?-程序员宅基地
文章浏览阅读2k次。RPC(Remote Procedure Call)是远程过程调用,rpc是一种协议,grpc是基于rpc协议实现的一种框架。_gprc
H.265的参考帧管理_x265 dpb的作用-程序员宅基地
文章浏览阅读4.3k次,点赞3次,收藏15次。HM参考帧管理分析HEVC采用了参考帧集(RPS)的技术来管理已解码的帧,用作后续图像的参考。与之前的视频编码标准中参考帧管理策略不同的是,HEVC中的RPS技术,通过直接在每一帧开始的片头码流中传输DPB中各个帧的状态变化,而H.264/AVC中的滑动窗和MMCO(Memory Management Control Opreation) 这两种参考帧管理技术,是通过传输每一个片的DPB的相对..._x265 dpb的作用
毕设开源 机器学习二手房价格预测及可视化系统(源码+论文)-程序员宅基地
文章浏览阅读996次,点赞33次,收藏10次。 通过整个项目的实践,我们亲身体会了数据挖掘的那张路线图,预处理、分析之后发现问题(Knowledge),再进行新的处理,再重新分析挖掘,做评估,然后发现新的问题,再从头开始,在这几个过程的循环往复中完成了整个项目。
Cognos11中关于CJAP第三方认证的相关配置-程序员宅基地
文章浏览阅读253次。cognos11同样适用于自定义java程序的第三方认证,而且在测试方面给了直观的测试接口,如下图所示当用户配置好了自定义java程序的认证之后,程序会提示用户输入我们自己的认证库用户信息例如admin 123456,通过认证以后,测显示如下启动服务可以在启动详情里面看到启动的过程中已经创建了新的命名空间说明第三方认证功能第一步已经配置OK了,是否成功还要接下来去cogno..._cjap
随便推点
UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xf9 in position 56: illegal multibyte sequence_gbk' codec can't decode byte 0xf9 in position 56: -程序员宅基地
文章浏览阅读864次。抽空慢慢把载入数据csv/txt文件时出现的UnicodeDecodeError报错问题的解决方案整理出来,虽然是玄学问题,但是多试试方法总还是可以解决的(特别是处理出来几十万量级的数据集出现这个问题,心态比较容易稳不住)方法一:将文件用txt文本格式打开,另存为时选择utf-8编码格式,然后转回csv格式方法二:直接用office或wps将报错的csv文件打开,然后另存一份替换原文件..._gbk' codec can't decode byte 0xf9 in position 56: illegal multibyte sequenc
万众瞩目,谷歌的反击来了!全新PaLM 2反超GPT-4,办公全家桶炸裂升级,Bard史诗进化...-程序员宅基地
文章浏览阅读423次。Datawhale干货最新:谷歌 PaLM 2,来源:量子位万众瞩目,谷歌的反击来了。现在,谷歌搜索终于要加入AI对话功能了,排队通道已经开放。当然这还只是第一步。大的还在后面:全新大语言模型PaLM 2正式亮相,谷歌声称它在部分任务超越GPT-4。Bard能力大更新,不用再排队等候,并支持新语言。谷歌版AI办公助手也一并推出,将在Gmail中抢先亮相。谷歌云也上线多个基础大模型,为行业提供更..._连通应用全家桶,谷歌推出bard拓展程序,追赶gpt
ARMv9新特性:虚拟内存系统架构 (VMSA) 的增强功能-程序员宅基地
文章浏览阅读599次,点赞10次,收藏10次。ARMv8/ARMv9架构精选系列
TWS蓝牙耳机_蓝牙芯片方案 引流-程序员宅基地
文章浏览阅读2.6k次,点赞4次,收藏30次。1. TWS 耳机概述TWS - True Wireless Stereo,即真正无线立体声。从技术上来说是指手机通过连接主耳机,再由主耳机通过蓝牙无线方式连接从耳机,实现真正的蓝牙左右声道无线分离使用。1.1 爆发原因手机取消 3.5mm 耳机插头,有线耳机需配转接线、缠绕等问题。1.2 TWS耳机优缺点优势真无线结构,完全摒弃了有线烦恼一机能当做两机用劣势关键问题在于蓝..._蓝牙芯片方案 引流
阿里java开发规范(6)---MySQL数据库_java 数据库的字段isdelete-程序员宅基地
文章浏览阅读2.2k次。五、 MySQL 数据库(一)建表规约1. 【强制】表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint( 1 表示是, 0 表示否)。说明: 任何字段如果为非负数,必须是 unsigned。注意: POJO 类中的任何布尔类型的变量,都不要加 is 前缀,所以,需要在<resultMap>设置从 is_xxx 到 Xxx 的映射关系。..._java 数据库的字段isdelete
kibana dashboard如何设置dashboard只读_elk创建能登陆kibana的只读用户-程序员宅基地
文章浏览阅读1.7k次。有的时候我们想对特定的dashboard进行分享,但是又担心浏览者会对dashboard进行修改或删除,所以可以新建一个user对其赋予只读权限:kibana-management-security-users-create new user输入相应的信息,然后赋予它下面这几个role:kibana_dashboard_only_userkibana_read_onlyreadonly如果不加第三个role,只能进到界面中,看不到图。这样在用此用户账号登陆时kibana左边的导航栏里就是_elk创建能登陆kibana的只读用户