(三)描述性统计分析与绘图_from stack2dim import *-程序员宅基地
描述性统计分析与绘图
1 描述性统计分析
1.1 概念
- 数据变量度量类型
名义: 字符(原义)、数值(编码)
等级 :字符、数值 有排序 ‘小中大’ 差值无意义
连续 :数值 ‘age’
#连续变量分组,当成等级变量使用,可使数据更稳健
#名义变量和等级变量统称为分类变量。
统计量:频次、百分比
- 描述名义变量的分布
频次、百分比
#python所用包都不支持字符,需要编码,0/1(关注的量编为1)
- 描述连续变量的分布
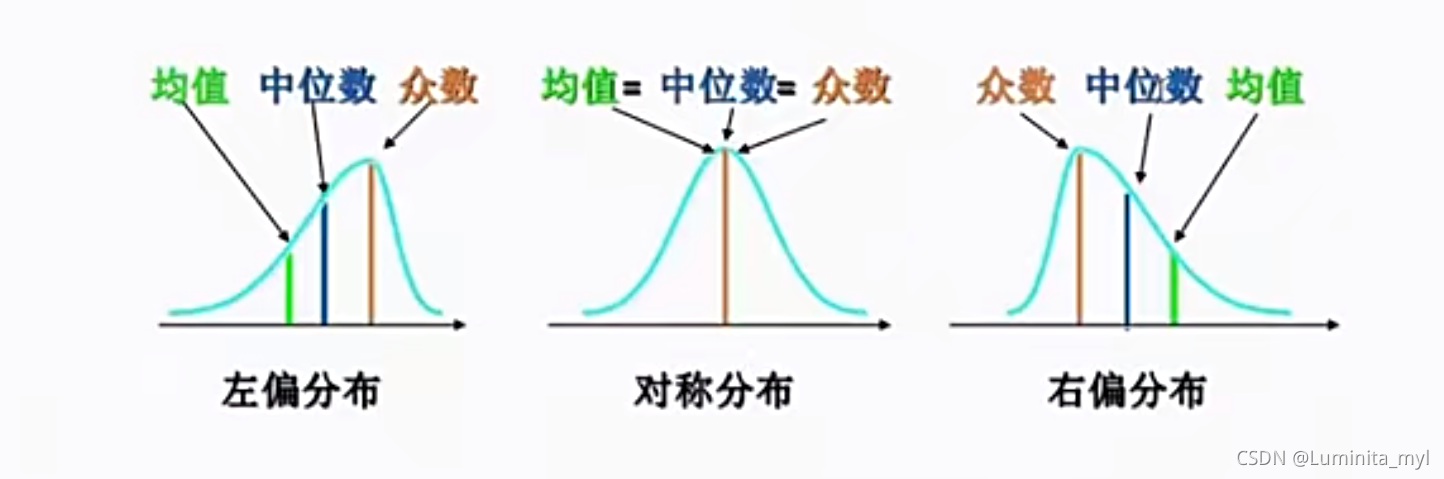
- 集中趋势(位置)—中心的度量:均值、中位数、众数
#看偏度确定选择均值还是中位数,右偏选择中位数,不偏选择均值
- 离散程度(分散程度):方差、标准差、极差、四分位差IQR
方差Variance:
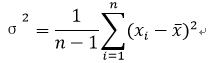
标准差Standard Deviation:
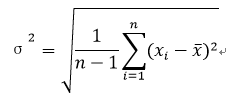
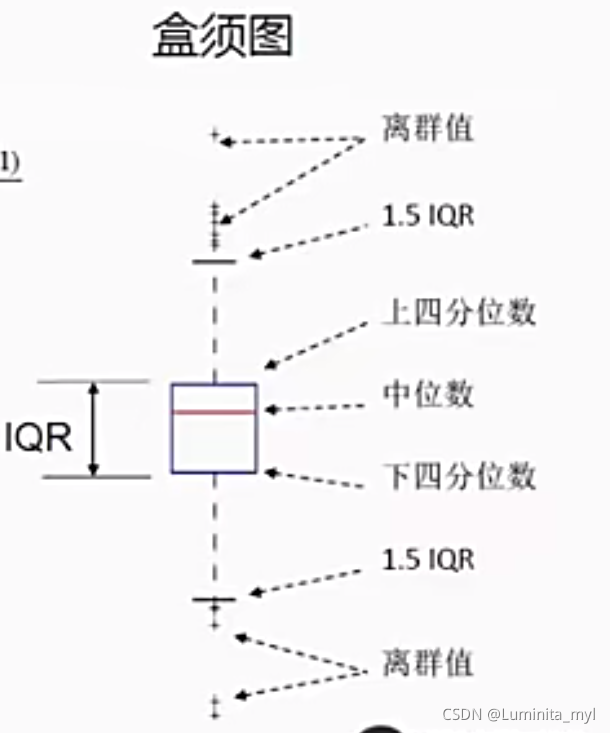
四分位差IQR:上分位数-下分位数
盒须图 :变量分布、内分位距IQR、异常点
- 偏度(形状):正态不偏skewness=0、右偏skewness正值
- 常见连续分布
1)对数正态分布 :运用广泛,收入的分布,右偏
描述性统计分析:取中位数
建模:取对数
2)伽玛分布:灾难造成损失金额
3)泊松分布:队伍长度
4)正态分布:自然界分布,均值代表中心水平
1.2 描述统计/案例
导入所需的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import os #os:Operating System操作系统
读取数据
os.chdir(r'D:\python商业实践\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\源代码\Python_book\4Describe')
snd=pd.read_csv("sndHsPr.csv")
snd.head()
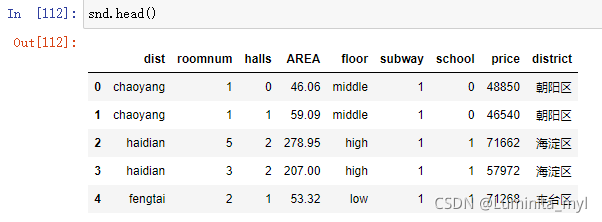
更改区名
district={
'fengtai':'丰台区','haidian':'海淀区','chaoyang':'朝阳区','dongcheng':'东城区','shijingshan':'石景山区','xicheng':'西城区'}
snd['district']=snd.dist.map(district)在这里插入代码片
1.2.1 单因子频数
一个分类变量
value_counts() 每个数值的频次
snd.district.value_counts()

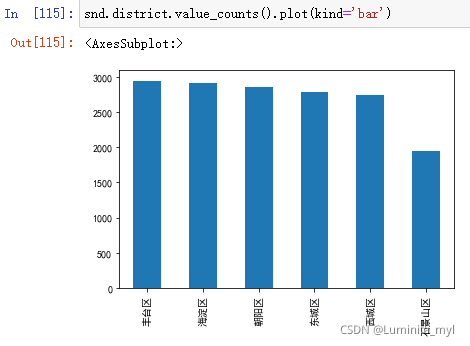
- 绘制柱状图
.plot(kind='bar')
snd.district.value_counts().plot(kind='bar')
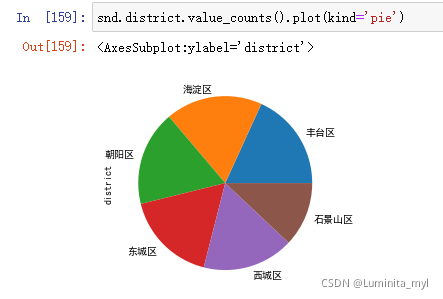
- 绘制饼状图
kind='pie'
snd.district.value_counts().plot(kind='pie')
1.2.2 表分析
两个分类变量
pd.crosstab(分类变量1,分类变量2)
生成数据框,频次表
sub_sch=pd.crosstab(snd.district,snd.school)
sub_sch

- 分类柱形图
pd.crosstab(snd.district,snd.school).plot(kind='bar')
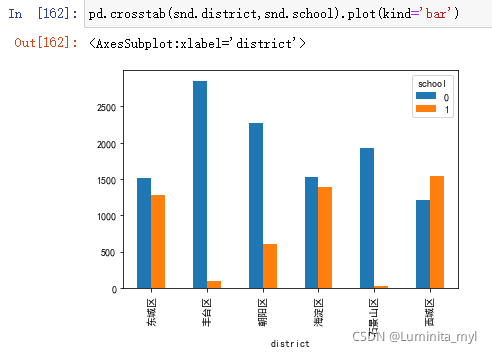
- 堆叠柱形图,可以看出资源分配
t1=pd.crosstab(snd.district,snd.school)
t1.plot(kind='bar',stacked=True)

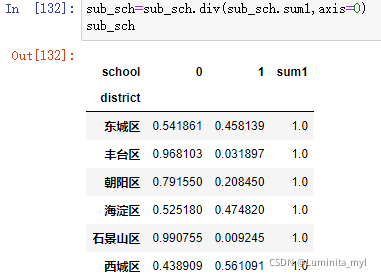
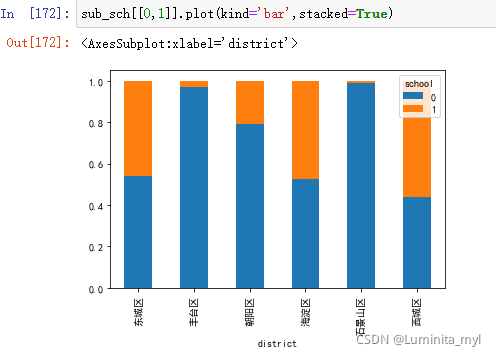
- 标准化堆叠柱形图
用于比较两个分类变量是否有关系 ,直观,明显看出资源分配
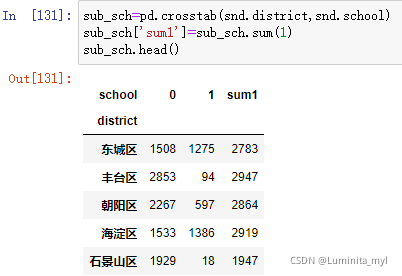
sub_sch=pd.crosstab(snd.district,snd.school)
sub_sch['sum1']=sub_sch.sum(1) #1代表列,汇总出一列
sub_sch.head()
sub_sch=sub_sch.div(sub_sch.sum1,axis=0) #按行求百分比
sub_sch
sub_sch[[0,1]].plot(kind='bar',stacked=True)
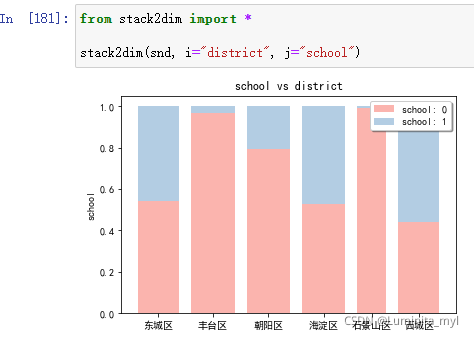
- 两个维度标准化的堆积柱状图,柱形的宽度代表数量,更直观。
def stack2dim (raw,i,j,rotation=0,location='upper right'):
raw:pandas的DataFrame数据框
i、j:两个分类变量名称,横纵轴名称
rotation:水平标签旋转角度,默认水平方向,若标签过长,可设置一定角度,如rotation=40
location:分类标签位置,如果被主题图形挡住,可更改为‘upper left’
需要调用函数*
from stack2dim import *
stack2dim(snd, i="district", j="school")
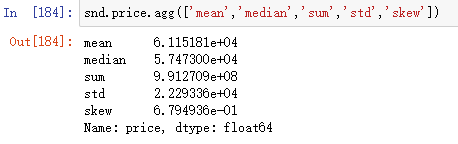
1.2.3 单连续变量描述
snd.price.agg(['mean','median','sum','std','skew']) #得多个统计量
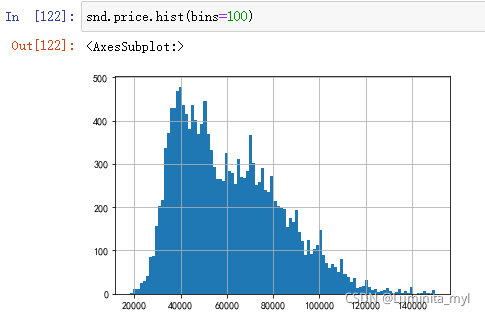
绘制直方图,查看分布情况,类似正态分布
snd.price.hist(bins=100) #bins为分组数
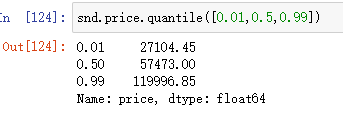
snd.price.mean() #均值
snd.price.median() #中位数
snd.price.std() #标准差
snd.price.skew() #偏度
snd.price.quantile([0.01,0.5,0.99]) #取分位点
1.2.4 分类汇总
一个分类变量、一个连续变量统计量
groupby() 分类汇总
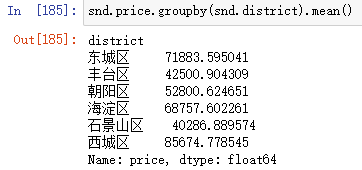
snd.price.groupby(snd.district).mean() #取连续变量的均值,可替换
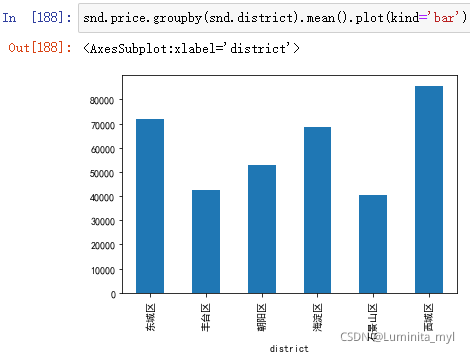
- 柱形图
snd.price.groupby(snd.district).mean().plot(kind='bar')
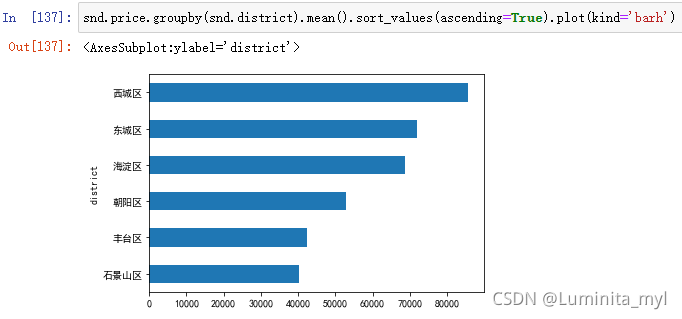
- 排序可得条形图
kind='barh'加h为横向条形图
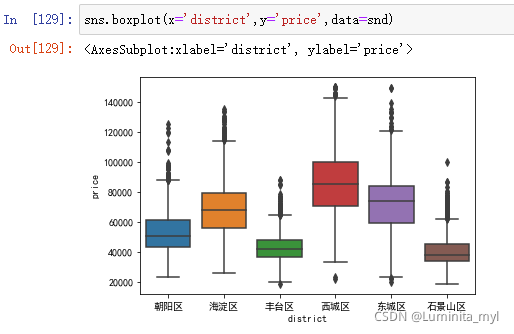
- 分类盒须图
体现分类变量和连续变量关系,比较不同分类水平上,连续变量的变化情况,比较中位数,直观。
sns.boxplot(x='district',y='price',data=snd)
1.2.5 汇总表
两个分类变量(分别在x、y轴)、一个连续变量统计量
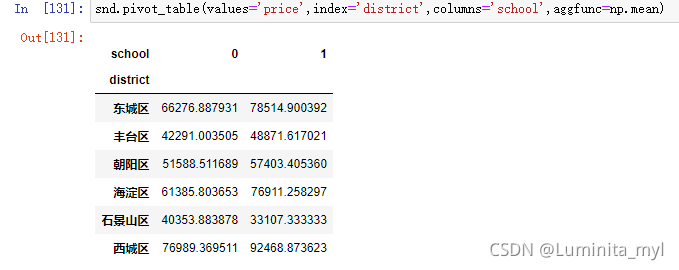
pivot_table()
snd.pivot_table(values='price',index='district',columns='school',aggfunc=np.mean) #mean是numpy的函数 np.mean
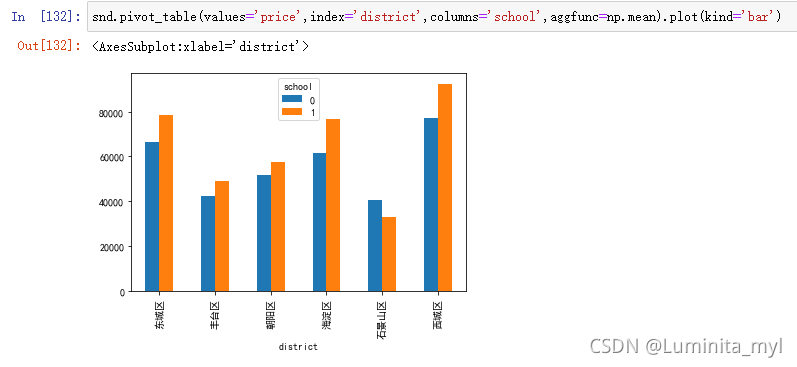
柱形图
snd.pivot_table(values='price',index='district',columns='school',aggfunc=np.mean).plot(kind='bar')
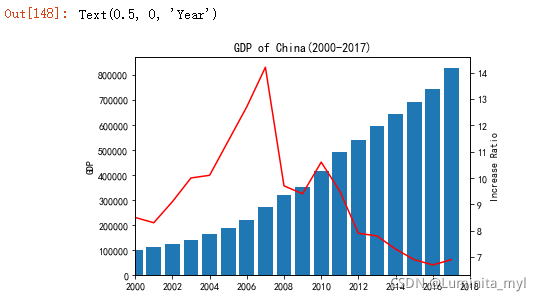
1.2.5 时间序列——双轴图
按年度汇总GDP,计算GDP增长率。GDP为柱子,GDP增长率为线
导入gdp数据
gdp=pd.read_csv('gdp_gdpcr.csv',encoding='gbk')
x=list(gdp.year)
GDP=list(gdp.GDP)
GDPCR=list(gdp.GDPCR)
fig=plt.figure() #设置绘图区域
ax1=fig.add_subplot(111)
ax1.bar(x,GDP) #主轴表示GDP
ax1.set_ylabel('GDP') #设置主轴标题
ax1.set_title("GDP of China(2000-2017)") #设置图标题
ax1.set_xlim(2000,2018) #设置横坐标数值范围
ax2=ax1.twinx() #拷贝的副轴
ax2.plot(x,GDPCR,'r') #‘r’表示为红色red
ax2.set_ylabel('Increase Ratio')
ax2.set_xlabel('Year')
##所有代码要写在一个cell,否则得不到图
附:
若横坐标乱码,显示出方块,可能原因是默认字体不能打印汉字,修改字体加入以下代码
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei'] #指定默认字体 SimHei表示简体中文
mpl.rcParams['axes.unicode_minus']=False #解决横坐标显示方块的问题
snd.district.value_counts().plot(kind='bar')
2 绘图原理
数据->信息->相对关系->图像
表达关联性的图标
一个分类一个连续:盒须图
多分类:堆叠柱形图
两个连续变量:散点图
3 案例
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
os.chdir(r'D:\python商业实践\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\源代码\Python_book\4Describe')
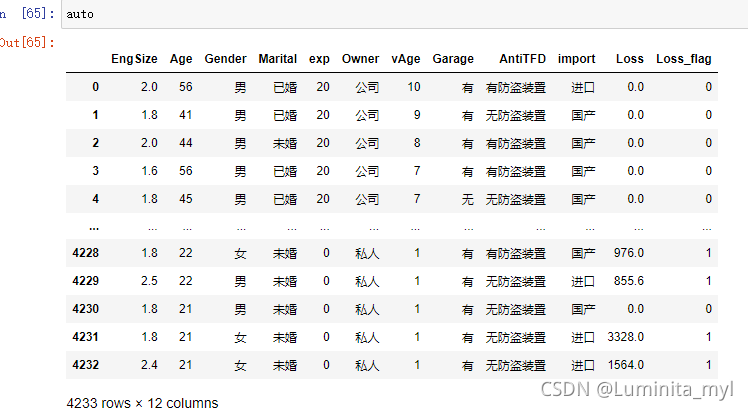
auto=pd.read_csv('auto_ins.csv',encoding='gbk')

- 对Loss重新编码1/0,有数值命名为1,命名为Loss_flag
def codeMy(x):
if x>0:
return 1
else:
return 0
auto['Loss_flag']=auto.Loss.map(codeMy) #map:codeMy返回的数值分别对应Loss进行替换
#######################令
auto['Loss_flag']=auto.Loss.map(lambda x:1 if x>0 else 0)
- 对Loss_flag的分布进行分析
分类变量—>频次分布
value_counts()
查看百分比
auto.Loss_flag.value_counts()/auto.Loss_flag.count()
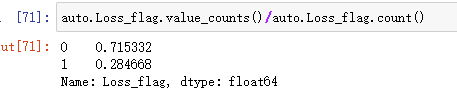
可视化
auto.Loss_flag.value_counts().plot(kind='pie')
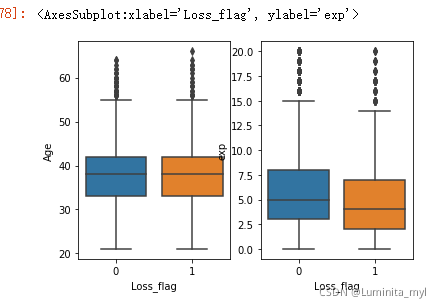
- 分析出险和年龄、驾龄、性别、婚姻状况等变量之间的关系
年龄、驾龄—>一个分类变量、一个连续变量 —>盒须图
fig=plt.figure()
ax1=fig.add_subplot(1,2,1)
ax2=fig.add_subplot(1,2,2)
sns.boxplot(x='Loss_flag',y='Age',data=auto,ax=ax1)
sns.boxplot(x='Loss_flag',y='exp',data=auto,ax=ax2)
可以看出出险与年龄无关,与驾龄有关
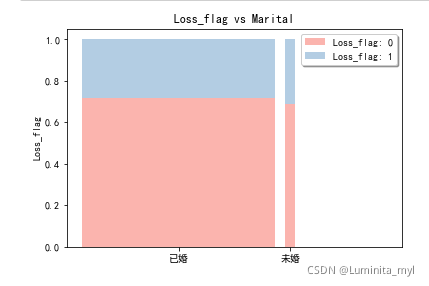
性别、婚姻状况—>两个分类变量的关系 —>标准化了的堆叠柱形图,宽度代表样本量
from stack2dim import *
stack2dim(auto,'Gender','Loss_flag')
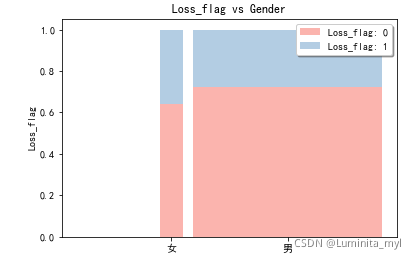
from stack2dim import *
stack2dim(auto,'Marital','Loss_flag')
智能推荐
Windows shell 扩展编程教程详解_microsoft.windows.shell.dll怎么引用-程序员宅基地
文章浏览阅读3k次。所谓的Shell扩展就是能够添加某种功能到Windows Shell的COM对象。Windows里有着各种各样的扩展,但关于Shell扩展的原理以及如何编写Shell扩展的文档却很少。如果你想深入地了解Shell各方面的细节,危险漫步特别推荐Dino Esposito的著作《Visual C++ Windows Shell Programming》。不过这些是英文的书籍,当然你可以参照词典进行阅读。_microsoft.windows.shell.dll怎么引用
解决《CPU设计实战》第四章实践交叉编译时报错mipsel-linux-ld: section .MIPS.abiflags LMA overlaps section .data LMA_section .arm.__at_0x00070000 lma [00001bdc,00001be-程序员宅基地
文章浏览阅读1.6k次。解决《CPU设计实战》4.3.1节快速上手CPU设计的开发环境的第4步,编译测试程序时,报错mipsel-linux-ld: section .MIPS.abiflags LMA overlaps section .data LMA的问题,或是其他相似的问题也可参考。_section .arm.__at_0x00070000 lma [00001bdc,00001beb] overlaps section .code
QR二维码编码原理_二维码qr编码算法是什么-程序员宅基地
文章浏览阅读8.4k次,点赞4次,收藏17次。QR码生成原理(一)一、什么是QR码QR码属于矩阵式二维码中的一个种类,由DENSO(日本电装)公司开发,由JIS和ISO将其标准化。QR码的样子其实在很多场合已经能够被看到了,我这还是贴个图展示一下:这个图如果被正确解码,应该看到我的名字和邮箱。二、QR码的特点说到QR码的特点,一是高速读取(QR就是取自“Quick Response”的首字母),对读取速度的体验源自于我..._二维码qr编码算法是什么
初步解析小程序前端框架vant-ui源码_微信小程序vantpopup源码-程序员宅基地
文章浏览阅读4.9k次,点赞2次,收藏2次。初步解析小程序前端框架vant-ui源码本学期的系统分析课程要求我们做一个小项目,我们以微信小程序为框架进行了项目的前端搭建,在UI上以开源组件库vant-ui为基础进行了设计,其中用到了许多该开源库的设计,对于项目前端起到了很大的帮助。组件库的使用教程在 https://youzan.github.io/vant-weapp/#/intro ,介绍说明比较详细且简单,因此这里不再赘述,这里..._微信小程序vantpopup源码
树状数组上二分-程序员宅基地
文章浏览阅读3.2k次。树状数组+二分考虑一个简单的问题,维护一个数组,支持每次修改一个数的值,保证每时每刻每个数都为非负数。每次查询求前缀和kkk lower_bound 的值。对于修改,可以用树状数组、线段树等数据结构维护。二分查找可以在[l,r][l,r][l,r]的范围上二分答案,mid=⌊l+r2⌋mid = \lfloor \frac{l+r}{2} \rfloormid=⌊2l+r⌋,验证midmidmid的前缀和是否大于kkk,并调整midmidmid。时间复杂度O(log22n)O(log^2_2n)O_树状数组上二分
数据结构——顺序串(定义初始化、赋值、遍历、两串比较)_串的初始化-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏47次。S;串的组成1length用length记录串的长度是为了减少后期的遍历串获取串长度的时间复杂度。如果不设置length的话,每一次获取字符串长度都需要一次循环,时间复杂度为O(n),如果设置了length的话,给串新增字符的过程中就记录当前串的长度,未来需要串的长度的时候直接获取length就可以了,时间复杂度降低为O(1)。2chch是串里的字符串。......_串的初始化
随便推点
STM32GPIO固件库点亮LED灯_stm32 gpio亮灯-程序员宅基地
文章浏览阅读1k次。STM32F103指南者用GPIO固件库点亮LED灯使用两个按键分别控制两种灯的亮灭,原来是按下去松开的时候灯亮,怎么改成按下去不用松开就亮啊_stm32 gpio亮灯
虚拟内存_matlab2010 虚拟内存-程序员宅基地
文章浏览阅读138次。程序代码和数据。对所有的进程来说,代码是从同一固定地址开始,紧接着的是和C 全局变量相对应的数据位置。堆。代码和数据区在进程一开始运行时就被指定了大小,与此不同,当调用像 malloc 和 free 这样的 C 标准库函数时,堆可以在运行时动态地扩展和收缩。共享库。大约在地址空间的中间部分是一块用来存放像 C 标准库和数学库这样的共享库的代码和数据的区域。栈。位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。特别地,每次我们调用..._matlab2010 虚拟内存
npm运行报错Error: EEXIST: file already exists解决办法_npm run dev error: eexist: file already exists, mk-程序员宅基地
文章浏览阅读6.5k次。如果你百度了很多方法都没有解决的话,请用管理员权限打开cmd,然后再输入npm安装命令试一试。反正我解决了_npm run dev error: eexist: file already exists, mkdir 'c:\windows\system32\c
物联网能为企业带来哪些创新?看看这些成功案例!-程序员宅基地
文章浏览阅读108次。物联网(Internet of Things,IoT)是指通过互联网连接各种设备和物品,使它们能够相互通信和交换数据的网络。在这个数字化时代,物联网已经成为了企业数字化转型的重要驱动力。通过物联网技术,企业可以实现对企业数据的实时监控、数据分析和智能化决策,从而提高企业的效率和效益,实现更高的商业价值。下面,我们将介绍一些成功的物联网应用案例,以帮助您更好地了解物联网的潜力。
阶次跟踪的角域重采样matlab,一种基于包络提取的高精度无键相信号阶次跟踪方法及系统与流程...-程序员宅基地
文章浏览阅读1.7k次。本发明涉及一种基于包络提取的高精度无键相信号阶次跟踪方法及系统,属于故障诊断技术与信号处理分析技术领域。背景技术:传统的阶次齿轮箱故障信号特征提取针对的是恒定转速运转下的测试信号,但对于工程机械等现代大型复杂机械装备中,恶劣的工作环境导致其运行工况复杂,转速和负荷等工况参数的变化将导致其振动信号具有明显的非平稳性,因此其采集的振动信号不直接满足傅里叶变换的平稳性要求。针对此问题出现了阶次跟踪方法,..._matlab阶次跟踪
python高阶知识之——字典/集合推导式_字典推导式 key自增怎么写-程序员宅基地
文章浏览阅读205次。什么是推导式:推导式是用来快速的生成数据1、推导式类型2、字典推导式推导式结合条件语句语法:dict = { key:value for i in xxx if 条件}推导式结合三元运算符语法:dict = { key:value if 条件 else key2:value2 for i in xxx}3、字典推导式原则4、注意事项5、集合推导式......_字典推导式 key自增怎么写