ES(Elasticsearch)入门学习教程_elasticsearch菜鸟教程-程序员宅基地
Elasticsearch 入门学习教程
- 0x02 参考链接
1.1 为什么要学Elasticsearch
为什么要学Elasticsearch(ES)
我想这是一个存留于很多初学者内心比较困惑的问题。
但是在回答之前,我们还需要先大致了解下它是啥。
毕竟如果一个技术你都不了解它是啥,何谈为什么要学它?
那么, 什么是ES呢?
Elasticsearch 简称ES, 经常与Logstash 和Kibana 一起使用,江湖人称ELK.
- 这E 自然指的就是Elasticsearch,简称ES, 具有分布式存储,搜索和分析的功能。
- L 指的就是Logstash,分布式日志收集框架
- K 指的就是Kibana,可视化分析框架。
接下来我们聊聊为什么我们要学传说中的ES。
这个问题的本质其实是ES 可以做啥?回答清楚这个问题,问题的答案自然就有了。
我翻开了官方文档,在网络中流浪,终于寻找到了答案。
其中分享一些经典的使用案例如下:
- 使用案例一:
ELK 结合使用,用于微服务架构下不同机器上微服务的日志聚合,日志分析。- 使用案例二:
当我们打开淘宝,京东,等电商网站的时候,尝试输入一些关键词,然后系统就会给我们提供一些搜索建议。
这种场景其实也是ES 使用的一个经典案例。- 使用案例三:
Github使用Elasticsearch检索1300亿行的代码- 使用案例四:
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-as-you-type)和搜索纠错(did-you-mean)等搜索建议功能。- 使用案例五:
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案
1.2 如何下载安装使用ES
ES 官网: https://www.elastic.co/cn/
1.2.1 ES 安装使用条件
ES 的安装需要JDK 8+
- 下载地址一:Oracle JDK 英文官网下载
- 下载地址二:JDK中文网下载
- 下载地址三:Open JDK

1.2.2 ES 下载须知
如果是企业需要注意的是ES 的下载安装包默认包含一个基础的免费许可证,它包含开源和免费的部分商业功能。
如果想30天试用一些完整的付费商业功能,可以去这里申请,传送门
关于免费和付费版本的区别见:

1.2.3 ES 官方下载
- 我们可以从 Download Elasticsearch获取最新的ES 官方下载安装包。
1.2.3.1 Windows 系统下载安装
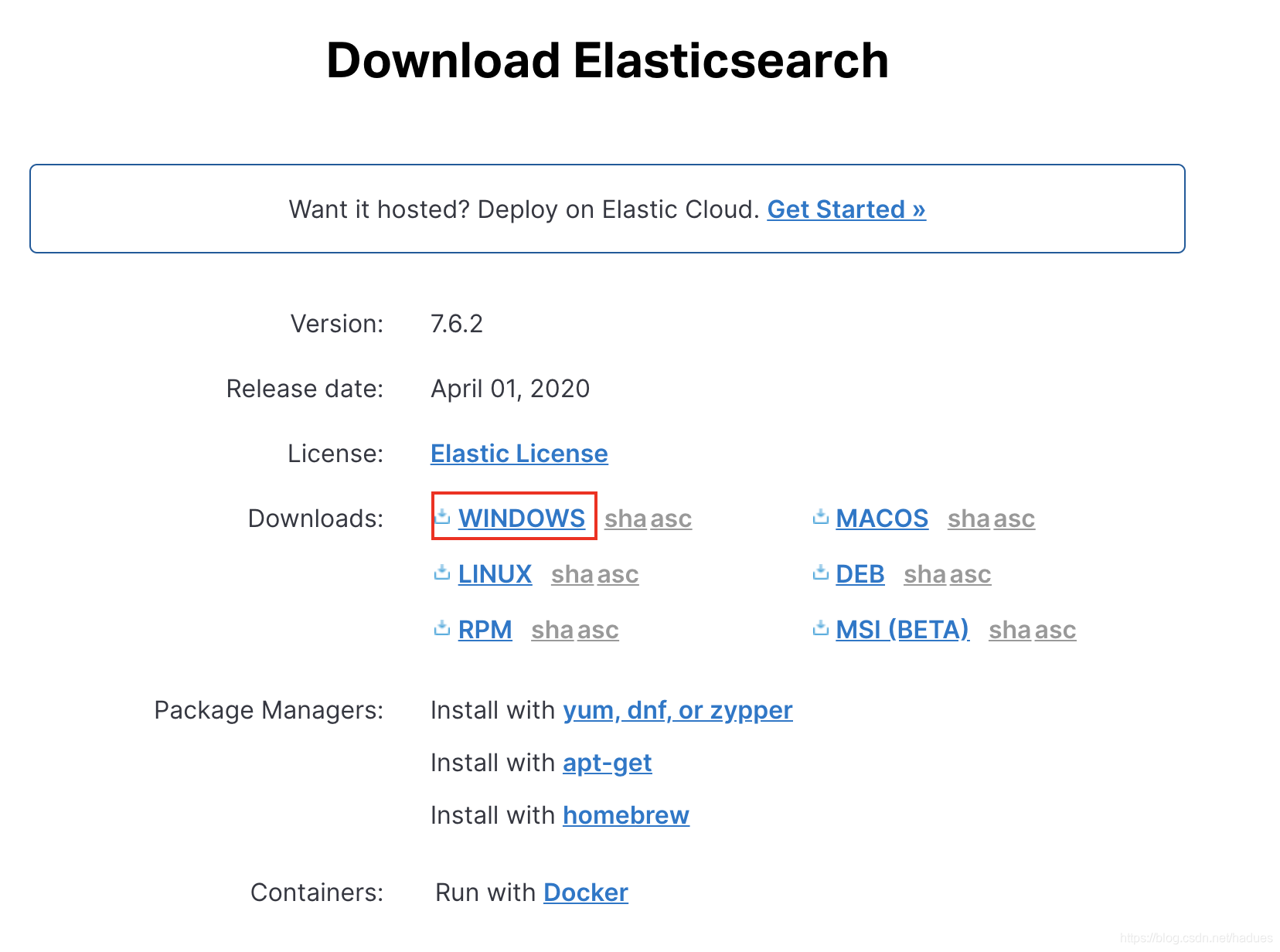
Windows 系统可以直接点击下图中WINDOWS 超链接 即可下载安装包。
1.2.3.1 Mac OSX 系统下载安装
Mac OSX 自带了HomeBrew ,因此可以通过包管理器方式进行下载安装。
-
首先输入命令:
brew tap elastic/tap
-
然后输入命令:
brew install elastic/tap/elasticsearch-full
当然Mac OSX 系统也可以通过输入如下命令进行下载安装
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-darwin-x86_64.tar.gz
解压命令如下:
tar -xzf elasticsearch-7.6.2-linux-x86_64.tar.gz
- 或点击进行直接下载
1.2.3.2 Docker方式下载安装
除了上面列举的方法之外,使用Docker 下载安装是一个更棒的选择。
-
首先需要安装好Docker,如果没有安装可以查看Docker 入门学习教程
-
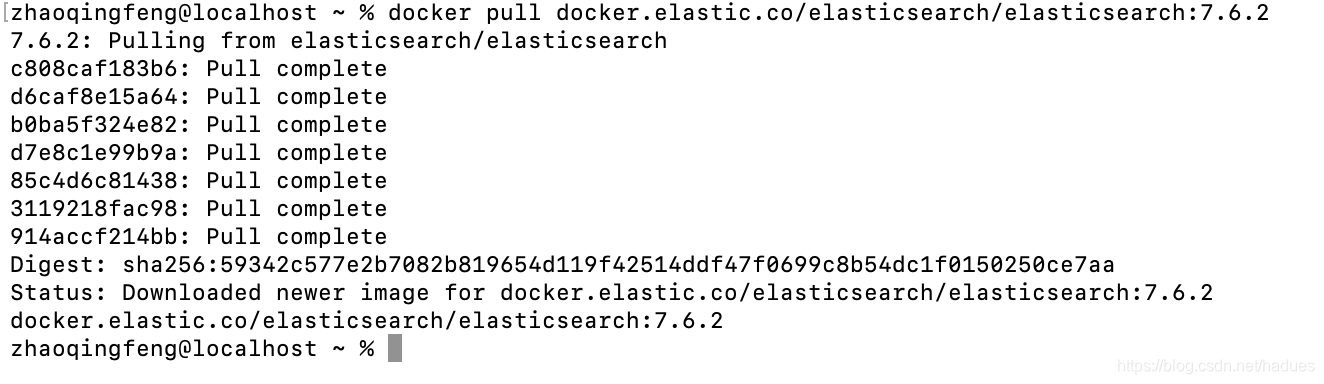
然后输入如下命令从远程Docker仓库下载ES
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.6.2
执行成功如下图所示:
1.2.4 使用Docker 启动ES单节点实例
上面通过Docker 安装好ES之后我们可以通过输入如下命令启动一个单节点的ES实例:
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.6.2
运行成功如下所示:

-
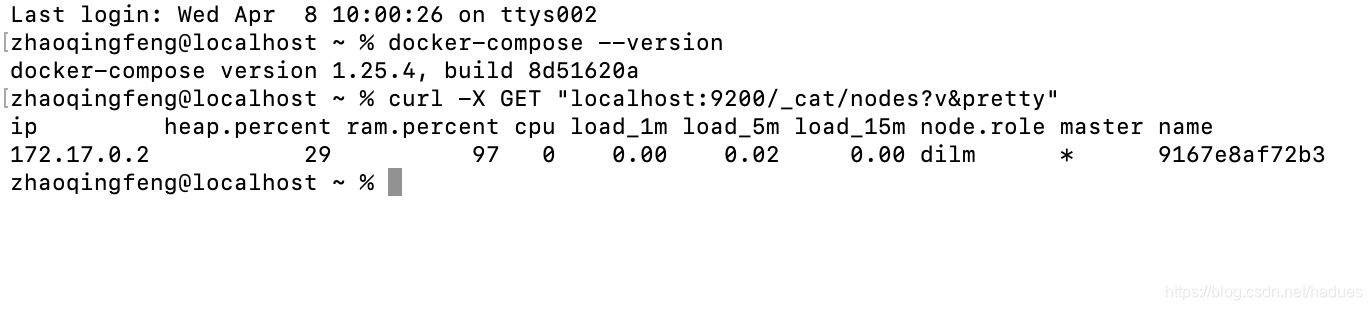
输入如下命令调用接口测试
curl -X GET “localhost:9200/_cat/nodes?v&pretty”
执行成功后输出内容如下:
Mac OSX 自带了curl命令,Windows用户如果也想用可以点击下载并配置环境变量
1.2.5 使用Docker启动ES多节点实例
-
为了方便文件管理,我们首先在
/Users/zhaoqingfeng/documents/app目录下创建一个叫做es 的文件夹
Mac OSX 可以通过输入mkdir es命令进行创建,Windows 可以图形用户界面创建即可。 -
创建一个docker-compose.yml 配置文件内容如下:
version: ‘2.2’
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elasticvolumes:
data01:
driver: local
data02:
driver: local
data03:
driver: localnetworks:
elastic:
driver: bridge -
输入如下命令启动集群
docker-compose up
这里科普下
docker-compose的用法
- 格式为
docker-compose up [options] [SERVICE...]- 该命令可以自动完成包括构建镜像,(重新)创建服务,启动服务,并关联服务相关容器的一系列操作
docker-compose up启动的容器都在前台,方便调试和查看- 如果想后台启动它,可以通过输入如下命令
bash docker-compose up -d
-
执行一个Restful API 请求测
curl -X GET “localhost:9200/_cat/nodes?v&pretty”
-
执行成功如下

1.2.6 ES 在生产环境配置
1.2.6.1 vm.max_map_count 必须至少设置262144
- Linux 服务器
首先需要编辑这个/etc/sysctl.conf文件
grep vm.max_map_count /etc/sysctl.conf
vm.max_map_count=262144
vm.max_map_count至少要设置26214
然后如果想要配置立即生效,需要输入如下命令
sysctl -w vm.max_map_count=262144
1.2.6.2 elasticsearch 用户必须拥有读取配置文件权限
默认情况下,Elasticsearch使用uid:gid 1000:0作为elasticsearch用户在容器内运行。
如果您要绑定安装本地目录或文件,则elasticsearch用户必须可以读取它。 此外,该用户必须对数据和日志目录具有写权限。 一个好的策略是授予组对本地目录的gid 0的访问权限。
例如,要准备一个本地目录以通过绑定安装存储数据:
mkdir esdatadir
chmod g+rwx esdatadir
chgrp 0 esdatadir
作为最后的选择,您可以通过环境变量TAKE_FILE_OWNERSHIP强制容器更改用于数据和日志目录的任何绑定安装的所有权。 执行此操作时,它们将由uid:gid 1000:0拥有,它提供对Elasticsearch进程的必需读/写访问权限。
1.2.6.3 增加nofile和nprocedit的ulimit
nofile和nproc的增加的ulimit必须对Elasticsearch容器可用。
验证Docker守护程序的初始化系统是否将它们设置为可接受的值。
要检查Docker守护程序默认值是否为ulimits,请运行:
docker run --rm centos:7 /bin/bash -c 'ulimit -Hn && ulimit -Sn && ulimit -Hu && ulimit -Su'
如果需要,请在守护程序中调整它们,或对每个容器覆盖它们。 例如,当使用docker run时,设置:
--ulimit nofile=65535:65535
1.2.6.4 禁用交换
为了性能和节点稳定性,需要禁用交换。 有关执行此操作的方法的信息,请参阅禁用交换。
如果您选择bootstrap.memory_lock:true方法,则还需要在Docker Daemon中定义memlock:true ulimit,或为示例组成文件中所示的容器显式设置。 使用docker run时,您可以指定:
-e "bootstrap.memory_lock=true" --ulimit memlock=-1:-1
1.2.6.5 随机发布已发布的端口
该映像公开了TCP端口9200和9300。对于生产集群,建议使用–publish-all将发布的端口随机化,除非您要为每个主机固定一个容器。
1.2.6.6 设置堆大小
使用ES_JAVA_OPTS环境变量来设置堆大小。
例如,要使用16GB,请在运行docker run时指定-e ES_JAVA_OPTS="-Xms16g -Xmx16g。 请注意,尽管默认配置文件jvm.options设置了1GB的默认堆,但是您在ES_JAVA_OPTS中设置的任何值都将覆盖它。
即使要限制对容器的内存访问,也必须配置堆大小。
虽然建议通过环境变量设置堆大小,但也可以通过将自己的jvm.options文件绑定安装在/usr/share/elasticsearch/config/下来进行配置。
Elasticsearch提供的文件包含一些重要的设置,因此您应该首先从Elasticsearch容器中获取jvm.options的副本,然后根据需要对其进行编辑。
1.2.6.7 将部署固定到特定的映像版本
将您的部署固定到Elasticsearch Docker映像的特定版本。
例如docker.elastic.co/elasticsearch/elasticsearch:7.6.2。
1.2.6.8 始终绑定数据卷
出于以下原因,您应该使用/ usr / share / elasticsearch / data上绑定的卷:
如果容器被杀死,您的Elasticsearch节点的数据将不会丢失
Elasticsearch对I / O敏感,而Docker存储驱动程序对于快速I / O而言并不理想
它允许使用高级Docker卷插件
1.2.6.9 避免使用loop-lvm模式
如果使用devicemapper存储驱动程序,请不要使用默认的loop-lvm模式。 将docker-engine配置为使用direct-lvm。
1.2.6.10 集中您的日志
考虑使用其他日志记录驱动程序集中化日志。 还要注意,默认的json文件日志记录驱动程序不适合用于生产环境。
1.2.7 在Docker中配置ES
在Docker中运行时,Elasticsearch配置文件从/usr/share/elasticsearch/config/加载。
要使用自定义配置文件,请将文件绑定安装在映像中的配置文件上。
您可以使用Docker环境变量来设置各个Elasticsearch配置参数。 样本撰写文件和单节点示例都使用此方法。
要使用文件的内容设置环境变量,请在环境变量名后加上_FILE。 这对于将密码之类的机密传递给Elasticsearch而无需直接指定它们很有用。
例如,要从文件设置Elasticsearch引导程序密码,您可以绑定安装文件并将ELASTIC_PASSWORD_FILE环境变量设置为安装位置。 如果将密码文件安装到/run/secrets/password.txt,请指定
-e ELASTIC_PASSWORD_FILE=/run/secrets/bootstrapPassword.txt
您还可以覆盖图像的默认命令,以将Elasticsearch配置参数作为命令行选项传递。 例如:
docker run <various parameters> bin/elasticsearch -Ecluster.name=mynewclustername
虽然绑定安装配置文件通常是生产中的首选方法,但您也可以创建一个包含配置的自定义Docker映像。
1.2.7.1 挂载Elasticsearch配置文件
创建自定义配置文件,并将其绑定安装在Docker映像中的相应文件上。 例如,要将docker run绑定到custom_elasticsearch.yml,请指定:
-v full_path_to/custom_elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
容器使用uid:gid 1000:0作为elasticsearch用户运行Elasticsearch。 该用户必须可以访问绑定的已挂载主机目录和文件,并且该用户必须可以写数据和日志目录。
1.2.7.2 使用自定义Docker镜像
在某些环境中,准备包含您的配置的自定义映像可能更有意义。
一个用于实现此目的的Dockerfile可能很简单:
FROM docker.elastic.co/elasticsearch/elasticsearch:7.6.2
COPY --chown=elasticsearch:elasticsearch elasticsearch.yml /usr/share/elasticsearch/config/
然后,您可以使用以下命令构建映像:
docker build --tag=elasticsearch-custom .
运行镜像
docker run -ti -v /usr/share/elasticsearch/data elasticsearch-custom
一些插件需要其他安全权限。 您必须通过以下方式明确接受它们:
- 运行Docker映像时附加
tty,并在出现提示时允许权限。 - 通过在插件安装命令中添加
--batch标志,检查安全权限并接受(如果适用)。
0x02 参考链接
- ES 官网首页
- ES 文档
- Getting Stared Guide
- Install Elasticsearch with Dockeredit
- docker-compose up命令
- Elasticsearch权威指南(中文版)
- 滴滴ElasticSearch平台跨版本升级以及平台重构之路
本篇完~
智能推荐
Spring Boot 获取 bean 的 3 种方式!还有谁不会?,Java面试官_springboot2.7获取bean-程序员宅基地
文章浏览阅读1.2k次,点赞35次,收藏18次。AutowiredPostConstruct 注释用于在依赖关系注入完成之后需要执行的方法上,以执行任何初始化。此方法必须在将类放入服务之前调用。支持依赖关系注入的所有类都必须支持此注释。即使类没有请求注入任何资源,用 PostConstruct 注释的方法也必须被调用。只有一个方法可以用此注释进行注释。_springboot2.7获取bean
Logistic Regression Java程序_logisticregression java-程序员宅基地
文章浏览阅读2.1k次。理论介绍 节点定义package logistic;public class Instance { public int label; public double[] x; public Instance(){} public Instance(int label,double[] x){ this.label = label; th_logisticregression java
linux文件误删除该如何恢复?,2024年最新Linux运维开发知识点-程序员宅基地
文章浏览阅读981次,点赞21次,收藏18次。本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。下面我们来进行文件的恢复,执行下文中的lsof命令,在其返回结果中我们可以看到test-recovery.txt (deleted)被删除了,但是其存在一个进程tail使用它,tail进程的进程编号是1535。我们看到文件名为3的文件,就是我们刚刚“误删除”的文件,所以我们使用下面的cp命令把它恢复回去。命令进入该进程的文件目录下,1535是tail进程的进程id,这个文件目录里包含了若干该进程正在打开使用的文件。
流媒体协议之RTMP详解-程序员宅基地
文章浏览阅读10w+次,点赞12次,收藏72次。RTMP(Real Time Messaging Protocol)实时消息传输协议是Adobe公司提出得一种媒体流传输协议,其提供了一个双向得通道消息服务,意图在通信端之间传递带有时间信息得视频、音频和数据消息流,其通过对不同类型得消息分配不同得优先级,进而在网传能力限制下确定各种消息得传输次序。_rtmp
微型计算机2017年12月下,2017年12月计算机一级MSOffice考试习题(二)-程序员宅基地
文章浏览阅读64次。2017年12月的计算机等级考试将要来临!出国留学网为考生们整理了2017年12月计算机一级MSOffice考试习题,希望能帮到大家,想了解更多计算机等级考试消息,请关注我们,我们会第一时间更新。2017年12月计算机一级MSOffice考试习题(二)一、单选题1). 计算机最主要的工作特点是( )。A.存储程序与自动控制B.高速度与高精度C.可靠性与可用性D.有记忆能力正确答案:A答案解析:计算...
20210415web渗透学习之Mysqludf提权(二)(胃肠炎住院期间转)_the provided input file '/usr/share/metasploit-fra-程序员宅基地
文章浏览阅读356次。在学MYSQL的时候刚刚好看到了这个提权,很久之前用过别人现成的,但是一直时间没去细想, 这次就自己复现学习下。 0x00 UDF 什么是UDF? UDF (user defined function),即用户自定义函数。是通过添加新函数,对MySQL的功能进行扩充,就像使..._the provided input file '/usr/share/metasploit-framework/data/exploits/mysql
随便推点
webService详细-程序员宅基地
文章浏览阅读3.1w次,点赞71次,收藏485次。webService一 WebService概述1.1 WebService是什么WebService是一种跨编程语言和跨操作系统平台的远程调用技术。Web service是一个平台独立的,低耦合的,自包含的、基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准...
Retrofit(2.0)入门小错误 -- Could not locate ResponseBody xxx Tried: * retrofit.BuiltInConverters_已添加addconverterfactory 但是 could not locate respons-程序员宅基地
文章浏览阅读1w次。前言照例给出官网:Retrofit官网其实大家学习的时候,完全可以按照官网Introduction,自己写一个例子来运行。但是百密一疏,官网可能忘记添加了一句非常重要的话,导致你可能出现如下错误:Could not locate ResponseBody converter错误信息:Caused by: java.lang.IllegalArgumentException: Could not l_已添加addconverterfactory 但是 could not locate responsebody converter
一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践_linux 18.04 synergy-程序员宅基地
文章浏览阅读1k次。一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践Synergy简介准备工作(重要)Windows服务端配置Ubuntu客户端配置配置开机启动Synergy简介Synergy能够通过IP地址实现一套键鼠对多系统、多终端进行控制,免去了对不同终端操作时频繁切换键鼠的麻烦,可跨平台使用,拥有Linux、MacOS、Windows多个版本。Synergy应用分服务端和客户端,服务端即主控端,Synergy会共享连接服务端的键鼠给客户端终端使用。本文_linux 18.04 synergy
nacos集成seata1.4.0注意事项_seata1.4.0 +nacos 集成-程序员宅基地
文章浏览阅读374次。写demo的时候遇到了很多问题,记录一下。安装nacos1.4.0配置mysql数据库,新建nacos_config数据库,并根据初始化脚本新建表,使配置从数据库读取,可单机模式启动也可以集群模式启动,启动时 ./start.sh -m standaloneapplication.properties 主要是db部分配置## Copyright 1999-2018 Alibaba Group Holding Ltd.## Licensed under the Apache License,_seata1.4.0 +nacos 集成
iperf3常用_iperf客户端指定ip地址-程序员宅基地
文章浏览阅读833次。iperf使用方法详解 iperf3是一款带宽测试工具,它支持调节各种参数,比如通信协议,数据包个数,发送持续时间,测试完会报告网络带宽,丢包率和其他参数。 安装 sudo apt-get install iperf3 iPerf3常用的参数: -c :指定客户端模式。例如:iperf3 -c 192.168.1.100。这将使用客户端模式连接到IP地址为192.16..._iperf客户端指定ip地址
浮点性(float)转化为字符串类型 自定义实现和深入探讨C++内部实现方法_c++浮点数 转 字符串 精度损失最小-程序员宅基地
文章浏览阅读7.4k次。 写这个函数目的不是为了和C/C++库中的函数在性能和安全性上一比高低,只是为了给那些喜欢探讨函数内部实现的网友,提供一种从浮点性到字符串转换的一种途径。 浮点数是有精度限制的,所以即使我们在使用C/C++中的sprintf或者cout 限制,当然这个精度限制是可以修改的。比方在C++中,我们可以cout.precision(10),不过这样设置的整个输出字符长度为10,而不是特定的小数点后1_c++浮点数 转 字符串 精度损失最小