线索二叉树和哈夫曼树_ltag是什么-程序员宅基地
目录
一、线索二叉树的类型定义
typedef struct BTNode
{
ElemType data;//数据域
struct BTNode* lchild;//左孩子或线索指针
struct BTNode* rchild;//右孩子或线索指针
int ltag, rtag;
}BTNode, * BTree;- 左标志ltag=0,表示lchild指向左孩子结点;ltag=1,表示lchild指向前驱结点
- 右标志rtag=0,表示rchild指向右孩子结点;rtag=1,表示rchild指向后继结点
- 二叉树线索化的基本思想:
- 二叉树的线索化实质上是遍历一棵二叉树。在遍历过程中,访问结点的操作是检查此结点的左、右指针域是否为空,如果为空,将它指向其前驱或后继结点的线索
二、各种线索化的二叉树


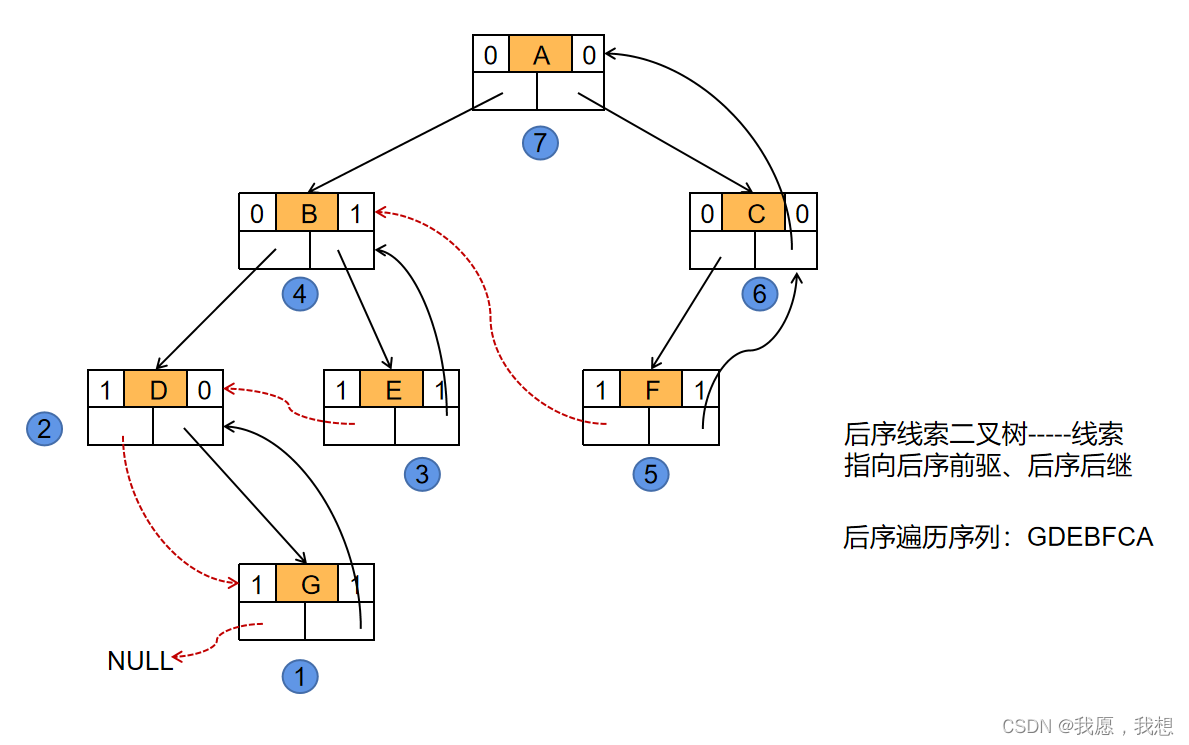
- 为了操作方便,在存储线索二叉树的时候增设一个头结点,其结构与其他的线索二叉树的结点相同,只是数据域不存储任何数据,其左指针域指向二叉树的根结点,右指针指向遍历的最后一个结点,而二叉树在某种遍历下的第一个结点的前驱和最后一个结点的后继线索都指向头结点。
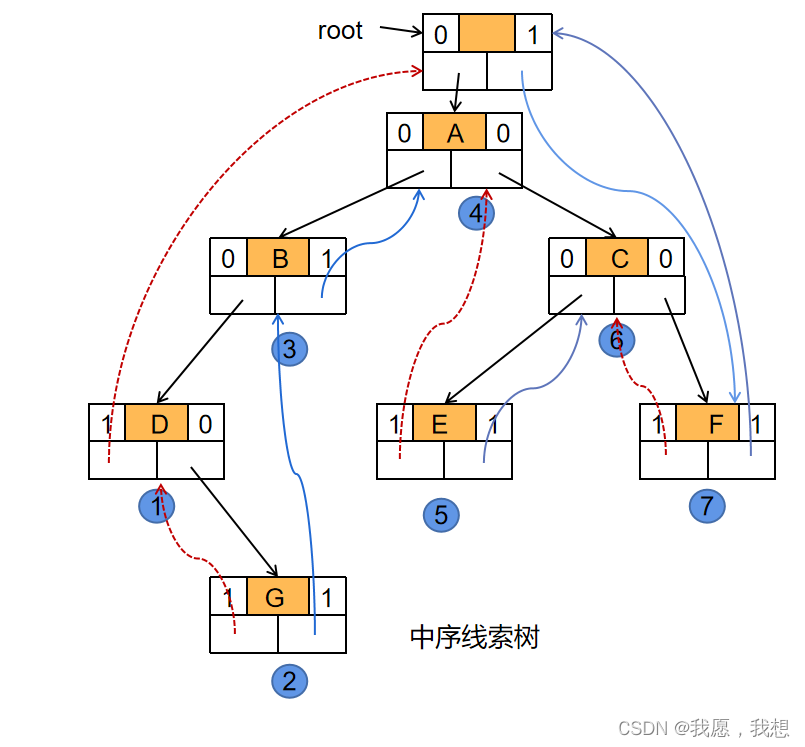
三、中序线索二叉树的算法
- 第一种方法建立并且遍历中序线索二叉树:
//第一种方法
void CreatInThread(BTree &T);建立中序线索树
void InThread(BTree& T);//中序遍历二叉树,一边遍历一边线索化
void visit(BTree& q);//访问根结点
void visit2(BTree T);//遍历输出中序线索二叉树BTNode* pre = NULL;//定义全局变量
void CreatInThread(BTree& T)//建立中序线索树
{
pre = NULL;
if (T != NULL)
{
InThread(T);//中序线索化二叉树
if (pre!=NULL&&pre->rchild == NULL)
{
pre->rtag = 1;
}
}
}
void InThread(BTree& T)//中序遍历二叉树,一边遍历一边线索化
{
if (T != NULL)
{
InThread(T->lchild);//左子树递归线索化
visit(T);//访问根结点同时线索化
InThread(T->rchild);//右子树递归线索化
}
}
void visit(BTree& q)//访问根结点
{
if (q->lchild == NULL)//左子树为空的时候,让其前驱线索指向空
{
q->lchild = pre;
q->ltag = 1;
}
else
{
q->ltag = 0;
}
if (pre != NULL && pre->rchild == NULL)
{
pre->rchild = q;//建立前驱结点的后继线索(让前驱结点的rchild域存放后继结点的地址)
pre->rtag = 1;
}
else
{
q->rtag = 0;
}
pre = q;
}
void visit2(BTree T)//遍历中序线索二叉树
{
BTNode* p = T;
while (p != NULL)
{
while (p->ltag == 0)//找开始结点
{
p = p->lchild;
}
cout << p->data << " ";//找到中序遍历最开始的结点并输出其data的值
while (p->rtag == 1 && p->rchild != NULL)
{
p = p->rchild;
cout << p->data << " ";
}
p = p->rchild;
}
return;
}
- 第二种方法建立并且遍历中序线索二叉树:
//第二种方法
BTree CreatBTree(BTree& T);//中序线索化二叉树,先创建头结点root
void Thread(BTree& T);//中序线索化二叉树
void ThInOrder(BTree T);//在中序线索化二叉树中实现中序遍历(输出)BTree CreatBTree(BTree & T)//中序线索化二叉树,先创建头结点root
{
BTNode* root = (BTNode*)malloc(sizeof(BTNode));//创建一个头结点
if (root == NULL)
{
exit(0);
}
root->ltag = 0;
root->rtag = 1;
root->rchild = T;
if (T == NULL)//空二叉树
{
root->lchild = root;
}
else
{
root->lchild = T;//头结点的lchild域存放二叉树根结点的地址
pre = root;
Thread(T);//中序线索化二叉树
pre->rchild = root;//最后处理加入头结点的线索
pre->rtag = 1;
root->rchild = pre;//头结点线索化
}
return root;
}
void Thread(BTree& T)//中序线索化二叉树
{
if (T != NULL)
{
Thread(T->lchild);//左子树线索化
if (T->lchild == NULL)
{
T->lchild = pre;//建立当前结点的前驱线索
T->ltag = 1;
}
else
{
T->ltag = 0;
}
if (pre != NULL && pre->rchild == NULL)
{
pre->rchild = T;//建立前驱结点的后继线索
pre->rtag = 1;
}
else
{
if (pre != NULL)
{
pre->rtag = 0;
}
}
pre = T;
Thread(T->rchild);//右子树线索化
}
}
void ThInOrder(BTree tb)//tb指向中序线索二叉树的头结点
{
BTNode* p = tb->lchild;
while (p != tb)
{
while (p->ltag == 0)//找中序二叉树的开始结点(开始结点在最左下方)
{
p = p->lchild;
}
cout << p->data << " ";
while (p->rtag == 1 && p->rchild != tb)
//p->rtag=1并且p->rchild!=头结点表示p结点的rchild域存放的是中序遍历的后继结点的地址(线索)
{
p = p->rchild;//沿右线索访问后继结点
cout << p->data << " ";
}
p = p->rchild;//转向p的右子树
}
}-
完整代码
#pragma once
#include<iostream>
#include<cstdlib>
#include<stdbool.h>
using namespace std;
#define MAXSIZE 100
typedef char ElemType;
typedef struct BTNode
{
ElemType data;//数据域
struct BTNode* lchild;//左孩子或线索指针
struct BTNode* rchild;//右孩子或线索指针
int ltag, rtag;
}BTNode, * BTree;
BTree Creat(char str[]);//先序序列建立二叉链表
void PreOrder(BTree T);//先序遍历
void InOrder(BTree T);//中序遍历
void PostOrder(BTree T);//后序遍历
void LevelOrder(BTree T);//层序遍历
//第一种方法
void CreatInThread(BTree &T);建立中序线索树
void InThread(BTree& T);//中序遍历二叉树,一边遍历一边线索化
void visit(BTree& q);//访问根结点
void visit2(BTree T);//遍历输出中序线索二叉树
//第二种方法
BTree CreatBTree(BTree& T);//中序线索化二叉树,先创建头结点root
void Thread(BTree& T);//中序线索化二叉树
void ThInOrder(BTree T);//在中序线索化二叉树中实现中序遍历(输出)
//找后继结点
bool InPostNode(BTree& s);//寻找中序线索二叉树的的后继结点#include"TBTree.h"
BTree Creat(char str[])//先序序列建立二叉链表(方法1)
{
BTree T;
static int i = 0;
ElemType c = str[i++];
if (c == '#')//输入#表示此结点下不存在分支
{
T = NULL;
}
else
{
T = (BTree)malloc(sizeof(BTree));
if (T == NULL)
{
exit(0);
}
T->data = c;
T->lchild = Creat(str);//递归创建左子树
T->rchild = Creat(str);//到上一个结点的右边递归创建左右子树
}
return T;
}
BTNode* pre = NULL;//定义全局变量
void CreatInThread(BTree& T)//建立中序线索树
{
pre = NULL;
if (T != NULL)
{
InThread(T);//中序线索化二叉树
if (pre!=NULL&&pre->rchild == NULL)
{
pre->rtag = 1;
}
}
}
void InThread(BTree& T)//中序遍历二叉树,一边遍历一边线索化
{
if (T != NULL)
{
InThread(T->lchild);//左子树递归线索化
visit(T);//访问根结点同时线索化
InThread(T->rchild);//右子树递归线索化
}
}
void visit(BTree& q)//访问根结点
{
if (q->lchild == NULL)//左子树为空的时候,让其前驱线索指向空
{
q->lchild = pre;
q->ltag = 1;
}
else
{
q->ltag = 0;
}
if (pre != NULL && pre->rchild == NULL)
{
pre->rchild = q;//建立前驱结点的后继线索(让前驱结点的rchild域存放后继结点的地址)
pre->rtag = 1;
}
else
{
q->rtag = 0;
}
pre = q;
}
bool InPostNode(BTree& s)//寻找中序线索二叉树的的后继结点
{
BTNode* post;
post = s->rchild;
if (s->rtag != 1)//结点s有右孩子
{
while (post->ltag == 0)//从右子树的根结点开始,沿左指针域往下查找,
//直到没有左孩子为止
{
post = post->lchild;
}
}
s = post;
return true;
}
void visit2(BTree T)//遍历中序线索二叉树
{
BTNode* p = T;
while (p != NULL)
{
while (p->ltag == 0)//找开始结点
{
p = p->lchild;
}
cout << p->data << " ";//找到中序遍历最开始的结点并输出其data的值
while (p->rtag == 1 && p->rchild != NULL)
{
p = p->rchild;
cout << p->data << " ";
}
p = p->rchild;
}
return;
}
BTree CreatBTree(BTree & T)//中序线索化二叉树,先创建头结点root
{
BTNode* root = (BTNode*)malloc(sizeof(BTNode));//创建一个头结点
if (root == NULL)
{
exit(0);
}
root->ltag = 0;
root->rtag = 1;
root->rchild = T;
if (T == NULL)//空二叉树
{
root->lchild = root;
}
else
{
root->lchild = T;//头结点的lchild域存放二叉树根结点的地址
pre = root;
Thread(T);//中序线索化二叉树
pre->rchild = root;//最后处理加入头结点的线索
pre->rtag = 1;
root->rchild = pre;//头结点线索化
}
return root;
}
void Thread(BTree& T)//中序线索化二叉树
{
if (T != NULL)
{
Thread(T->lchild);//左子树线索化
if (T->lchild == NULL)
{
T->lchild = pre;//建立当前结点的前驱线索
T->ltag = 1;
}
else
{
T->ltag = 0;
}
if (pre != NULL && pre->rchild == NULL)
{
pre->rchild = T;//建立前驱结点的后继线索
pre->rtag = 1;
}
else
{
if (pre != NULL)
{
pre->rtag = 0;
}
}
pre = T;
Thread(T->rchild);//右子树线索化
}
}
void ThInOrder(BTree tb)//tb指向中序线索二叉树的头结点
{
BTNode* p = tb->lchild;
while (p != tb)
{
while (p->ltag == 0)//找中序二叉树的开始结点(开始结点在最左下方)
{
p = p->lchild;
}
cout << p->data << " ";
while (p->rtag == 1 && p->rchild != tb)
//p->rtag=1并且p->rchild!=头结点表示p结点的rchild域存放的是中序遍历的后继结点的地址(线索)
{
p = p->rchild;//沿右线索访问后继结点
cout << p->data << " ";
}
p = p->rchild;//转向p的右子树
}
}
void PreOrder(BTree T)//先序遍历
{
if (T != NULL)
{
cout << T->data << " ";//访问根结点
PreOrder(T->lchild);//先序遍历左子树
PreOrder(T->rchild);//先序遍历右子树
}
}
void InOrder(BTree T)//中序遍历
{
if (T != NULL)
{
InOrder(T->lchild);
cout << T->data << " ";
InOrder(T->rchild);
}
}
void PostOrder(BTree T)//后序遍历
{
if (T != NULL)
{
PostOrder(T->lchild);
PostOrder(T->rchild);
cout << T->data << " ";
}
}
void LevelOrder(BTree T)//层序遍历
{
BTNode* p;
BTNode* qu[MAXSIZE];//定义循环队列,存放结点指针
int front, rear;//定义头指针和尾指针
front = rear = 0;//置队列为空队列
rear++;
qu[rear] = T;//根结点指针进队
rear++;//队尾指针指向队尾元素的后一个位置
front = (front + 1) % MAXSIZE;//队头指针加1取模
while (front != rear)//队列不为空
{
p = qu[front];//取队头元素
front = (front + 1) % MAXSIZE;//队头元素出队,队头指针后移
cout << p->data << " ";
if (p->lchild != NULL)
{
qu[rear] = p->lchild;//p结点的左孩子进栈
rear = (rear + 1) % MAXSIZE;//队尾指针加1取模
}
if (p->rchild != NULL)
{
qu[rear] = p->rchild;//p结点的右孩子进栈
rear = (rear + 1) % MAXSIZE;
}
}
}
#include"TBTree.h"
int main()
{
cout << "二叉树建立的第一种方法" << endl;
BTree T;//T为指向根结点的指针
T = (BTree)malloc(50*sizeof(BTree));
char str[] = { 'a','b','d','#','g','#','#','#','c','e','#','#','f','#','#' };
T = Creat(str);
cout << "先序遍历结果:";
PreOrder(T);//先序遍历
cout << endl;
cout << "中序遍历结果:";
InOrder(T);//中序遍历
cout << endl;
cout << "后序遍历结果:";
PostOrder(T);//后序遍历
cout << endl;
cout << "层次遍历的结果:";
LevelOrder(T);
cout << endl << endl;
/*cout << "中序线索树遍历结果:";
CreatInThread(T);
visit2(T);
cout << endl << endl;*/
cout << "中序遍历结果2:";
BTree tb;
tb = (BTree)malloc(50*sizeof(BTree));
tb = CreatBTree(T);
ThInOrder(tb);
//system("pause");
return 0;
}
四、有关哈夫曼树的定义
- 路径:是指从一个结点到另一个结点之间的分支序列。
- 路径长度:是指从一个结点到另一个结点所经过的分支数目。
- 哈夫曼树:也称最优二叉树,是指对于一组带有确定权值的叶结点,构造的具有最小带权路径长度的二叉树

- 哈夫曼树的构造步骤:
给定n个权值分别为w1,w2...wn的结点
1.将这n个结点分别作为n棵仅含一个结点的二叉树,构成森林F
2.构造一个新的结点,从F中选取两棵根结点权值最小的树作为新结点的左,右子树,并且将
新结点的权值置为左、右子树上根结点的权值之和。
3.从F中删除刚才选出的两棵树,同时将新得到的树加入F中。
4.重复步骤2和3,直至F中只剩下一棵树为止。


哈夫曼编码
- 固定长度编码:每个字符用相等长度的二进制位表示
例如:A--00;B--01;C--10;D--11
- 可变长度编码:允许对不同字符用不等长的二进制位表示
例如:C--0;A--10;B--111;D--110
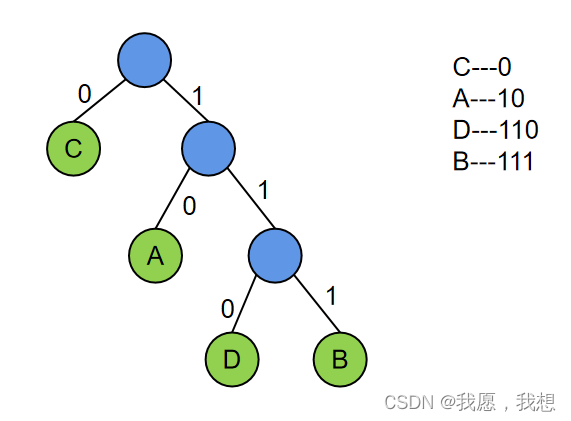
- 前缀编码:若没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码
由哈夫曼树得到的哈夫曼编码--字符集中每个字符作为一个叶子结点,各个字符出现的频度作为
结点的权值。
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象